Modèle de facteur de crypto-monnaie
 12
12175
12
12175
[TOC]

Cadre du modèle factoriel
Il existe de nombreux rapports de recherche sur le modèle multifactoriel du marché boursier, riches en théorie et en pratique. Le marché des devises numériques est suffisant pour la recherche de facteurs, quel que soit le nombre de devises, la valeur totale du marché, le volume des transactions, le marché des produits dérivés, etc. Cet article s’adresse principalement aux débutants en stratégies quantitatives et n’impliquera pas de principes mathématiques complexes ni d’analyse statistique. le marché à terme comme source de données, un cadre de recherche factorielle simple est construit pour faciliter l’évaluation des indicateurs factoriels.
Un facteur peut être considéré comme un indicateur et peut être écrit sous forme d’expression. Les facteurs changent en permanence et reflètent les informations sur le rendement futur. En général, les facteurs représentent une logique d’investissement.
Par exemple, le facteur du cours de clôture repose sur l’hypothèse selon laquelle le cours des actions peut prédire les rendements futurs. Plus le cours de l’action est élevé, plus les rendements futurs seront élevés (ou plus les rendements seront faibles). Construire un portefeuille en fonction de ce facteur est en fait un investissement modèle/stratégie de rotation régulière des positions pour acheter des actions à prix élevé. . D’une manière générale, les facteurs qui peuvent générer systématiquement des rendements excédentaires sont souvent appelés Alpha. Par exemple, les facteurs de capitalisation boursière et les facteurs de momentum ont été vérifiés par le milieu universitaire et la communauté des investisseurs comme étant des facteurs efficaces.
Qu’il s’agisse du marché boursier ou du marché des devises numériques, il s’agit d’un système complexe. Aucun facteur ne peut prédire entièrement les rendements futurs, mais il présente néanmoins un certain degré de prévisibilité. L’alpha efficace (modèle d’investissement) devient progressivement inefficace à mesure que davantage de fonds sont investis. Mais ce processus va générer d’autres modèles sur le marché, donnant naissance à de nouveaux alphas. Le facteur de capitalisation boursière était autrefois une stratégie très efficace sur le marché des actions A. Il suffit d’acheter 10 actions ayant la plus faible capitalisation boursière et de les ajuster une fois par jour. Le test rétrospectif sur dix ans de 2007 rapportera plus de 400 fois le rendement, bien plus que dépassant le marché global. . Cependant, le marché boursier des valeurs vedettes en 2017 a reflété l’inefficacité du facteur de petite capitalisation boursière, tandis que le facteur de valeur est devenu populaire à la place. Il est donc nécessaire de constamment équilibrer et expérimenter entre la vérification et l’utilisation de l’alpha.
Les facteurs que nous recherchons constituent la base de l’élaboration des stratégies. De meilleures stratégies peuvent être élaborées en combinant plusieurs facteurs efficaces sans rapport entre eux.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
Source des données
À l’heure actuelle, les données horaires de la ligne K des contrats à terme perpétuels Binance USDT du début de 2022 à nos jours ont dépassé 150 devises. Comme mentionné précédemment, le modèle factoriel est un modèle de sélection de devises qui cible toutes les devises plutôt qu’une seule devise spécifique. Les données K-line incluent des données telles que les prix d’ouverture élevés et les prix de clôture bas, le volume des échanges, le nombre de transactions, le volume d’achat actif, etc. Ces données ne sont certainement pas la source de tous les facteurs, tels que l’indice boursier américain, les attentes de hausse des taux d’intérêt , rentabilité, données en chaîne, attention des médias sociaux, etc. Des sources de données moins populaires peuvent également révéler un alpha efficace, mais les données de base sur le volume et les prix sont également suffisantes.
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
Out:
153
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
Nous extrayons d’abord les données d’intérêt des données K-line : cours de clôture, cours d’ouverture, volume des transactions, nombre de transactions et ratio d’achat actif, et utilisons ces données comme base pour traiter les facteurs requis.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
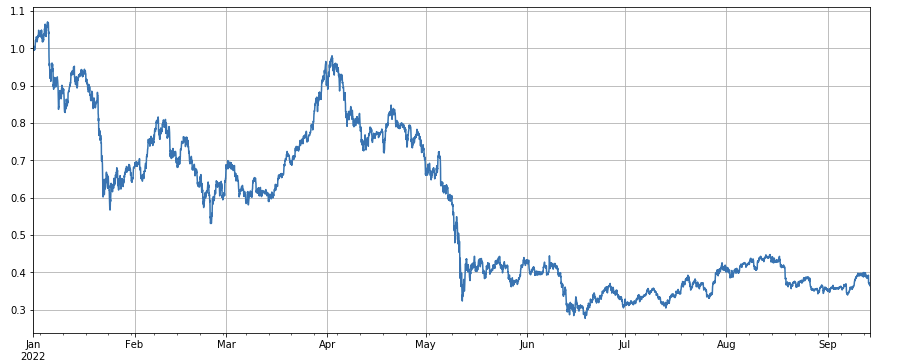
Si l’on regarde l’évolution de l’indice boursier, on peut dire qu’elle est plutôt sombre, avec une baisse de 60% depuis le début de l’année.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
Détermination de la validité des facteurs
Méthode de régression Le taux de rendement de la période suivante est pris comme variable dépendante, le facteur à tester est pris comme variable indépendante et le coefficient obtenu par régression est le taux de rendement du facteur. Après avoir construit l’équation de régression, nous nous référons généralement à la moyenne absolue de la valeur du coefficient t, à la proportion de la séquence de valeurs absolues de la valeur du coefficient t supérieure à 2, au rendement annualisé du facteur, à la volatilité du rendement annualisé du facteur, au ratio de Sharpe de le rendement du facteur et d’autres paramètres. L’efficacité et la volatilité du facteur. Vous pouvez régresser plusieurs facteurs à la fois, reportez-vous à la documentation de barra pour plus de détails.
IC, IR et autres indicateurs Le coefficient de corrélation entre le facteur et le taux de rendement de la période suivante est appelé IC. RANK_IC est généralement utilisé aujourd’hui, il s’agit du coefficient de corrélation entre le classement des facteurs et le taux de rendement de l’action de la période suivante. IR est généralement la moyenne de la séquence IC/l’écart type de la séquence IC.
Régression hiérarchique Cet article utilisera cette méthode, qui consiste à trier les facteurs à tester, à diviser les devises en N groupes pour le backtesting de groupe et à utiliser une période fixe pour ajuster les positions. Si la situation est idéale, les rendements des N groupes de devises montreront une bonne monotonie, augmentant ou diminuant de manière monotone, et l’écart de rendement entre chaque groupe sera important. De tels facteurs se traduisent par une meilleure discrimination. Si le premier groupe présente le rendement le plus élevé et le dernier le rendement le plus faible, alors prenez une position longue sur le premier groupe et une position courte sur le dernier groupe. Le taux de rendement final est un indicateur de référence du ratio de Sharpe.
Opération de backtesting réelle
Selon les facteurs, les devises sélectionnées sont divisées en 3 groupes selon le tri du plus petit au plus grand. Chaque groupe de devises représente environ 1⁄3. Si un facteur est efficace, plus la proportion de chaque groupe est faible, plus le facteur est efficace. rendement, mais cela signifie également que les fonds alloués à chaque devise sont relativement importants. Si les positions longues et courtes ont chacune un effet de levier de 1x, et que le premier et le dernier groupe sont respectivement composés de 10 devises, alors chacun représente 10 %. Si une devise est les positions courtes augmentent, si le montant de l’investissement augmente de 2 fois, le retracement sera de 20 % ; en conséquence, si le nombre de groupes est de 50, le retracement sera de 4 %. La diversification des devises peut réduire le risque de cygnes noirs. Soyez long sur le premier groupe (avec la plus petite valeur de facteur) et short sur le troisième groupe. Si plus le facteur est grand, plus le rendement est élevé, vous pouvez inverser les positions longues et courtes ou simplement rendre le facteur négatif ou inversé.
Le pouvoir prédictif d’un facteur peut généralement être évalué approximativement en fonction du rendement final du backtest et du ratio de Sharpe. De plus, il est également nécessaire de se référer à la question de savoir si l’expression du facteur est simple, insensible à la taille du regroupement, insensible à l’intervalle d’ajustement de position, insensible à l’heure initiale du backtest, etc.
En ce qui concerne la fréquence d’ajustement des positions, le marché boursier a souvent un cycle de 5 jours, 10 jours et un mois, mais pour le marché des devises numériques, un tel cycle est sans aucun doute trop long, et les conditions du marché sur le marché réel sont surveillées en permanence. En temps réel, il est donc difficile de s’en tenir à un cycle spécifique. Il n’est pas nécessaire d’ajuster à nouveau les positions, donc dans le trading réel, nous ajustons les positions en temps réel ou sur de courtes périodes de temps.
Concernant la façon de fermer une position, selon la méthode traditionnelle, vous pouvez fermer la position si elle n’est pas dans le groupe lors du prochain tri. Cependant, dans le cas d’un ajustement de position en temps réel, certaines devises peuvent se trouver sur la ligne de démarcation et les positions peuvent être fermées dans les deux sens. Par conséquent, cette stratégie adopte l’approche consistant à attendre les changements de groupement et à fermer les positions lorsqu’il est nécessaire d’ouvrir des positions dans la direction opposée. Par exemple, si vous êtes long dans le premier groupe, lorsque la devise de la position longue est divisée en troisième groupe, vous pouvez fermer la position et aller short. Si vous fermez des positions à une période fixe, par exemple tous les jours ou toutes les 8 heures, vous pouvez également fermer les positions sans faire partie d’un groupe. Vous pouvez en essayer davantage.
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
Test de facteur simple
Facteur de volume : le simple fait d’être long sur des pièces à faible volume et de vendre à découvert sur des pièces à volume élevé donne de très bons résultats, ce qui montre que les pièces populaires sont plus susceptibles de chuter.
Facteur de prix de transaction : devises longues à bas prix, devises courtes à prix élevé, l’effet est moyen.
Facteur nombre de transactions : la performance est très similaire au volume. Il est évident que la corrélation entre le facteur volume et le facteur nombre de transactions est très élevée. En fait, la corrélation moyenne entre eux dans différentes devises est de 0,97, ce qui montre que ces deux facteurs sont très similaires. Ce facteur doit être pris en compte en compte.
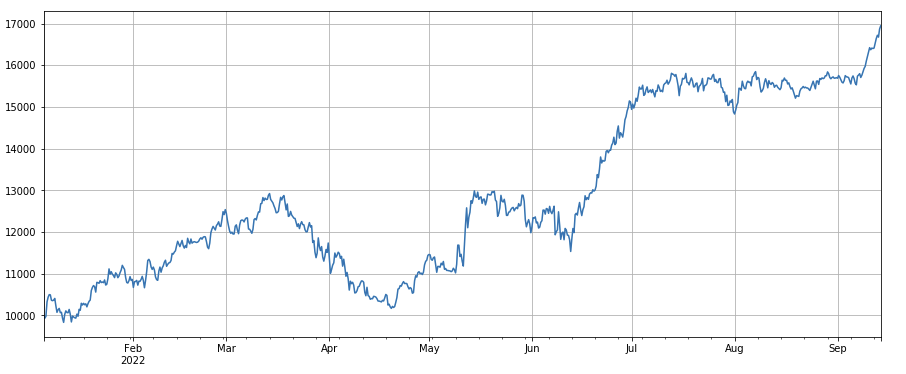
Facteur d’élan 3h : (df_close - df_close.shift(3))/df_close.shift(3). C’est-à-dire l’augmentation du facteur sur 3 heures. Les résultats du backtest montrent que l’augmentation sur 3 heures a une caractéristique de régression évidente, c’est-à-dire que l’augmentation est plus susceptible de diminuer au cours de la période suivante. Les performances globales sont bonnes, mais il y a également des périodes de retrait et d’oscillation plus longues.
Facteur Momentum 24h : Les résultats du cycle de rééquilibrage de 24 heures sont plutôt bons, avec des rendements similaires au momentum de 3 heures et un drawdown plus faible.
Facteur de variation du chiffre d’affaires : df_volume.rolling(24).mean() / df_volume.rolling(96).mean(), qui est le rapport entre le chiffre d’affaires du jour le plus récent et le chiffre d’affaires des trois jours les plus récents. La position est ajusté toutes les 8 heures. Les résultats du backtest sont relativement bons et le retracement est relativement faible, ce qui montre que les actions avec un volume de transactions actif sont plus susceptibles de chuter.
Facteur de changement du nombre de transactions : df_count.rolling(24).mean() / df_count.rolling(96).mean(), qui est le rapport entre le nombre de transactions du dernier jour et le nombre de transactions des trois derniers jours . La position est ajustée toutes les 8 heures. . Les résultats du backtest sont relativement bons et le retracement est relativement faible, ce qui montre qu’à mesure que le nombre de transactions augmente, le marché a tendance à baisser plus activement.
Facteur de changement de la valeur d’une transaction unique : -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean()) , qui est le rapport entre la valeur de la transaction du jour le plus récent et la valeur de la transaction des trois jours les plus récents, et la position est ajustée toutes les 8 heures. Ce facteur est également fortement corrélé au facteur volume.
Facteur de changement du ratio de transaction active : df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean(), c’est-à-dire le ratio du volume d’achat actif par rapport au volume total de transaction au cours du dernier jour jusqu’à la transaction valeur au cours des trois derniers jours, ajustez la position toutes les 8 heures. Ce facteur fonctionne bien et a peu de corrélation avec le facteur volume.
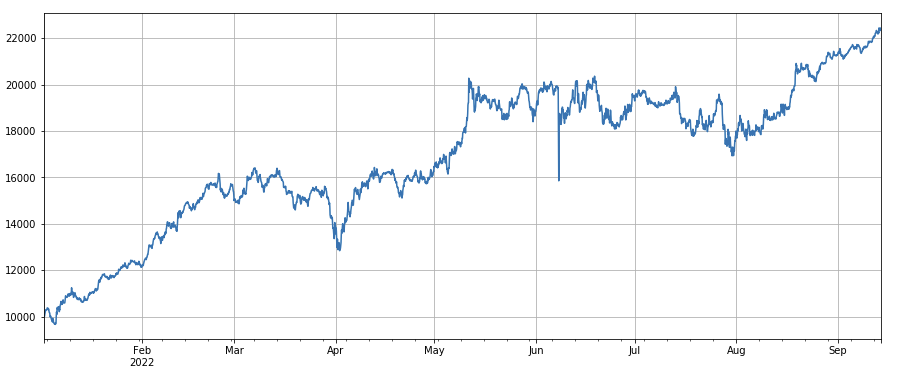
Facteur de volatilité : (df_close/df_open).rolling(24).std(), qui a un certain effet lorsque l’on est long sur des devises à faible volatilité.
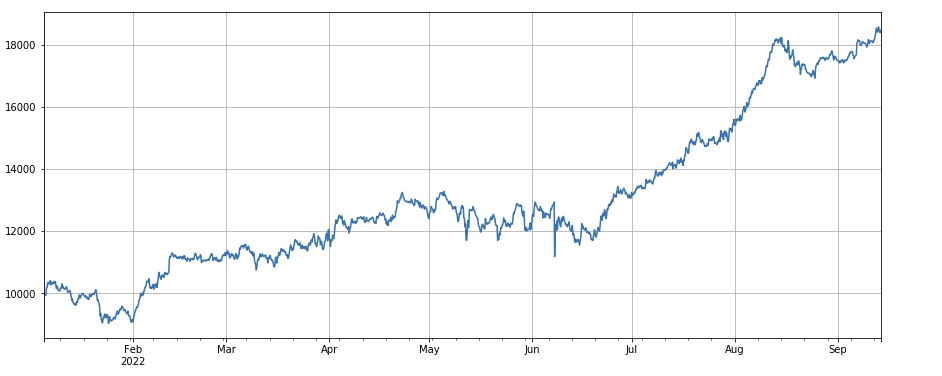
Facteur de corrélation entre le volume des transactions et le cours de clôture : df_close.rolling(96).corr(df_volume), le facteur de corrélation entre le cours de clôture et le volume des transactions au cours des 4 derniers jours, la performance globale est bonne.
Voici quelques-uns des facteurs basés sur la quantité et le prix. En fait, la combinaison des formules de facteurs peut être très complexe et ne pas avoir de logique évidente. Vous pouvez vous référer à la célèbre méthode de construction du facteur ALPHA101 : https://github.com/STHSF/alpha101.
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
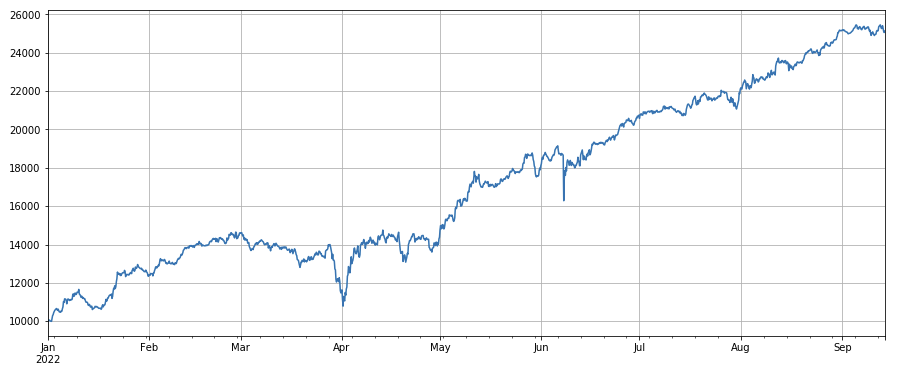
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
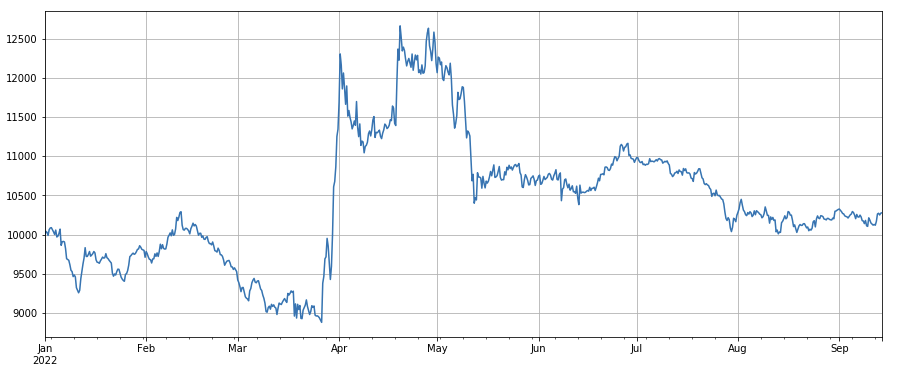
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
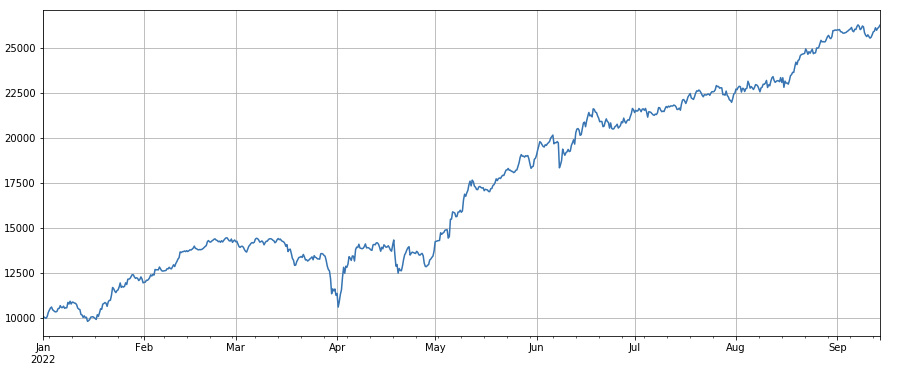
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
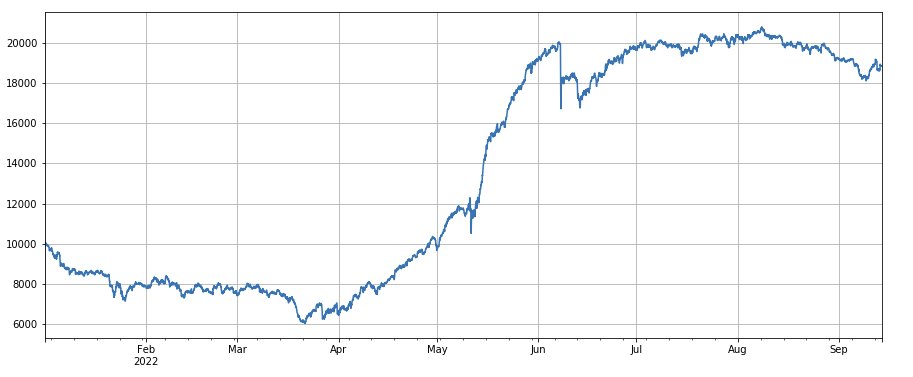
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
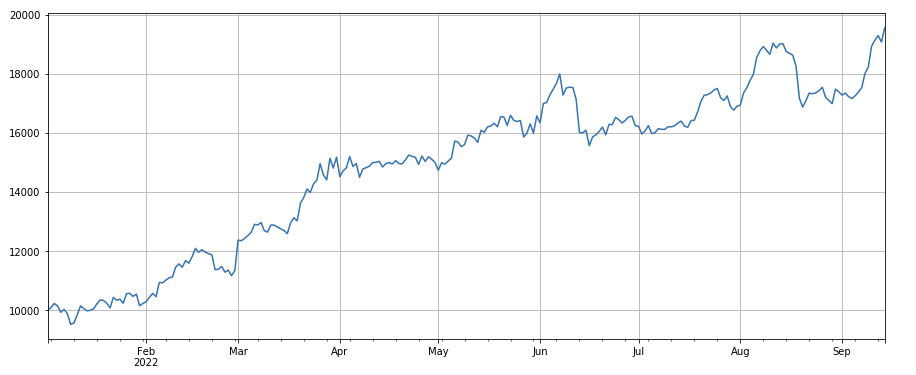
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
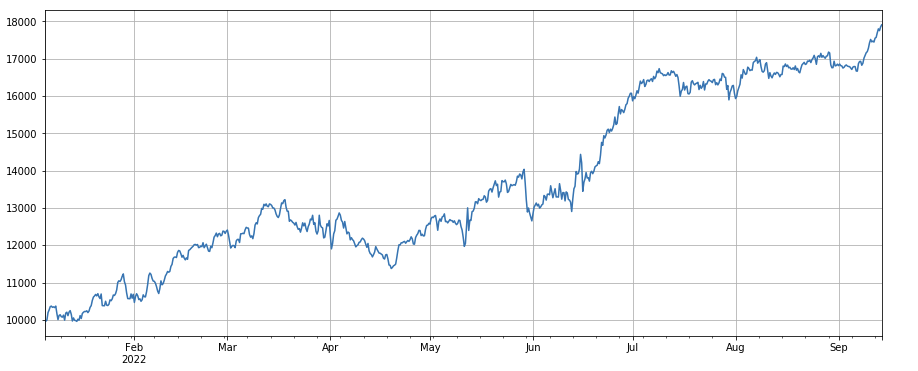
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
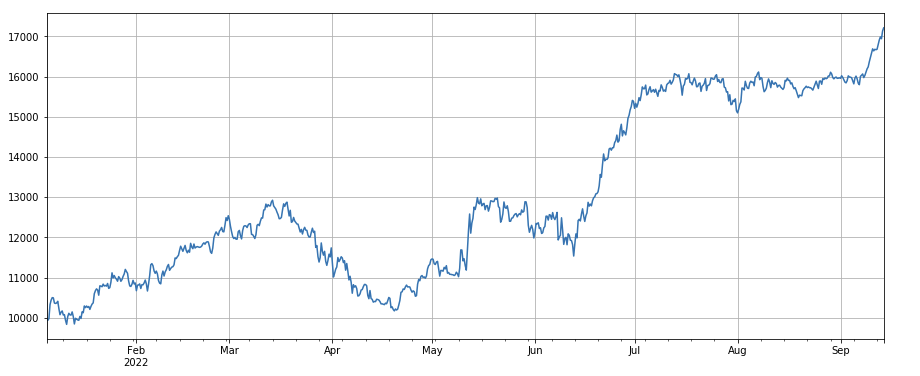
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
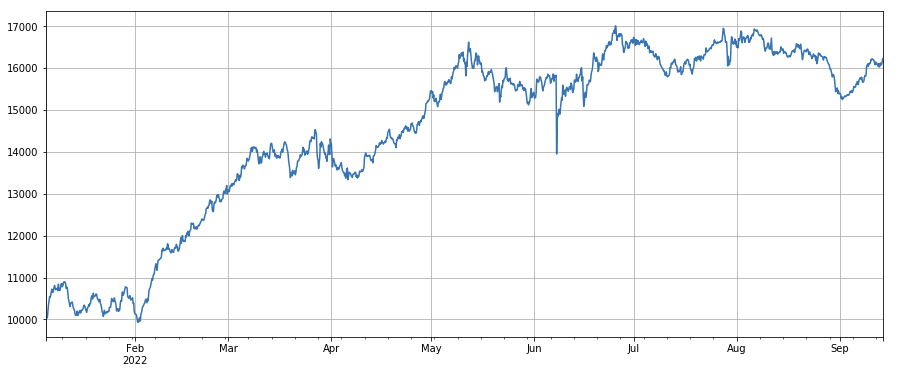
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
Synthèse multifactorielle
La découverte continue de nouveaux facteurs efficaces est certainement la partie la plus importante du processus de construction d’une stratégie, mais sans une bonne méthode de synthèse des facteurs, un excellent facteur Alpha unique ne peut pas jouer son rôle maximal. Les méthodes courantes de synthèse multifactorielle comprennent :
Méthode de pondération égale : tous les facteurs à synthétiser sont ajoutés avec des poids égaux pour obtenir de nouveaux facteurs synthétisés.
Méthode pondérée des rendements des facteurs historiques : Tous les facteurs à synthétiser sont additionnés selon la moyenne arithmétique des rendements des facteurs historiques de la période la plus récente comme poids pour obtenir de nouveaux facteurs synthétisés. Cette méthode donne un poids plus élevé aux facteurs qui fonctionnent bien.
Méthode de pondération IC_IR de maximisation : la valeur IC moyenne du facteur composite sur une période historique est utilisée comme estimation de la valeur IC du facteur composite dans la période suivante, et la matrice de covariance de la valeur IC historique est utilisée comme estimation de la volatilité du facteur composite au cours de la période suivante. Selon IC_IR, elle est égale à la valeur attendue de IC divisée par l’écart type de IC, et la solution pondérée optimale pour maximiser le facteur composite IC_IR peut être obtenue.
Méthode d’analyse en composantes principales (ACP) : l’ACP est une méthode couramment utilisée pour réduire la dimensionnalité des données. La corrélation entre les facteurs peut être relativement élevée et les composantes principales après réduction de la dimensionnalité sont utilisées comme facteurs synthétisés.
Cet article fera référence manuellement à la pondération de la validité des facteurs. La méthode décrite ci-dessus peut faire référence à :ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
Lors du test d’un seul facteur, l’ordre est fixe, mais la synthèse multifactorielle nécessite de fusionner des données complètement différentes, de sorte que tous les facteurs doivent être standardisés et que les valeurs extrêmes et les valeurs manquantes doivent généralement être supprimées. Ici, nous utilisons df_volume\factor_1\factor_7\factor_6\factor_8 pour la synthèse.
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
Résumer
Cet article présente la méthode du test à un seul facteur et teste les facteurs simples courants, et introduit de manière préliminaire la méthode de synthèse multifactorielle. Cependant, le contenu de la recherche multifactorielle est très riche. Chaque point mentionné dans l’article peut être approfondi Il est possible de transformer une telle recherche stratégique en découverte de facteurs alpha. L’utilisation de la méthodologie factorielle peut considérablement accélérer la vérification des idées de trading, et de nombreux documents de référence sont disponibles.
Adresse réelle : https://www.fmz.com/robot/486605