Application de la technologie d'apprentissage automatique dans le commerce
Auteur:FMZ~Lydia, Créé: 2022-12-30 10:53:07, Mis à jour: 2023-09-20 09:30:09
Application de la technologie d'apprentissage automatique dans le commerce
L'inspiration de cet article vient de mon observation de quelques avertissements et pièges courants après avoir essayé d'appliquer la technologie d'apprentissage automatique aux problèmes de transaction lors de la recherche de données sur la plateforme FMZ Quant.
Si vous n'avez pas lu mes articles précédents, nous vous suggérons de lire le guide de l'environnement de recherche de données automatisée et la méthode systématique pour formuler des stratégies de trading que j'ai établi sur la plateforme FMZ Quant avant cet article.
Les adresses de ces deux articles sont ici:https://www.fmz.com/digest-topic/9862ethttps://www.fmz.com/digest-topic/9863.
À propos de la mise en place de l'environnement de recherche
Ce tutoriel est destiné aux passionnés, ingénieurs et scientifiques des données à tous les niveaux de compétence. Que vous soyez un leader de l'industrie ou un novice en programmation, les seules compétences dont vous avez besoin sont une compréhension de base du langage de programmation Python et une connaissance suffisante des opérations de ligne de commande (être en mesure de configurer un projet de science des données est suffisant).
- Installez le docker FMZ Quant et installez Anaconda
La plateforme FMZ QuantFMZ.COMIl fournit non seulement des sources de données de haute qualité pour les principaux échanges traditionnels, mais fournit également un ensemble d'interfaces API riches pour nous aider à effectuer des transactions automatiques après avoir terminé l'analyse des données. Cet ensemble d'interfaces comprend des outils pratiques, tels que la requête d'informations de compte, la requête de prix élevé, ouvert, bas, reçu, volume de négociation et divers indicateurs d'analyse technique couramment utilisés de divers échanges traditionnels. En particulier, il fournit un fort support technique pour les interfaces API publiques reliant les principaux échanges traditionnels dans le processus de négociation réel.
Toutes les fonctionnalités mentionnées ci-dessus sont encapsulées dans un système similaire à Docker. Nous devons acheter ou louer nos propres services de cloud computing et déployer le système Docker.
Dans le nom officiel de la plateforme FMZ Quant, le système Docker est appelé le système Docker.
Veuillez consulter mon précédent article sur le déploiement d'un docker et d'un robot:https://www.fmz.com/bbs-topic/9864.
Les lecteurs qui veulent acheter leur propre serveur de cloud computing pour déployer des dockers peuvent se référer à cet article:https://www.fmz.com/digest-topic/5711.
Après avoir déployé avec succès le serveur de cloud computing et le système docker, nous allons ensuite installer le plus grand artefact actuel de Python: Anaconda.
Afin de réaliser tous les environnements de programme pertinents (bibliothèques de dépendances, gestion de version, etc.) requis dans cet article, le moyen le plus simple est d'utiliser Anaconda.
Puisque nous installons Anaconda sur le service cloud, nous recommandons que le serveur cloud installe le système Linux plus la version en ligne de commande d'Anaconda.
Pour la méthode d'installation d'Anaconda, veuillez consulter le guide officiel d'Anaconda:https://www.anaconda.com/distribution/.
Si vous êtes un programmeur Python expérimenté et si vous pensez que vous n'avez pas besoin d'utiliser Anaconda, ce n'est pas un problème du tout. Je suppose que vous n'avez pas besoin d'aide pour installer l'environnement dépendant nécessaire. Vous pouvez sauter cette section directement.
Développer une stratégie commerciale
Le résultat final d'une stratégie de négociation devrait répondre aux questions suivantes:
-
Direction: déterminer si l'actif est bon marché, coûteux ou à juste valeur.
-
Conditions d'ouverture de position: si l'actif est bon marché ou cher, vous devriez aller long ou short.
-
Transaction de position de clôture: si l'actif a un prix raisonnable et que nous avons une position dans l'actif (achat ou vente antérieur), devriez-vous clôturer la position?
-
L'indice de change est le prix (ou la fourchette) auquel la position a été ouverte.
-
Quantité: la quantité de monnaie négociée (par exemple, le montant de la monnaie numérique ou le nombre de lots de contrats à terme sur matières premières).
L'apprentissage automatique peut être utilisé pour répondre à chacune de ces questions, mais pour le reste de cet article, nous nous concentrerons sur la première question, qui est la direction du commerce.
Approche stratégique
Il existe deux types d'approches pour construire des stratégies: l'une est basée sur un modèle; l'autre est basée sur l'exploration de données. Ces deux méthodes sont fondamentalement opposées.
Dans la construction de la stratégie basée sur le modèle, nous partons du modèle d'inefficacité du marché, construisons des expressions mathématiques (telles que le prix et le profit) et testons leur efficacité sur une longue période de temps. Ce modèle est généralement une version simplifiée d'un modèle réel complexe, et sa signification et sa stabilité à long terme doivent être vérifiées.
D'autre part, nous recherchons d'abord des modèles de prix et essayons d'utiliser des algorithmes dans les méthodes d'exploration de données. Les raisons de ces modèles ne sont pas importantes, car seuls les modèles identifiés continueront à se répéter à l'avenir. Il s'agit d'une méthode d'analyse à l'aveugle, et nous devons vérifier strictement pour identifier les modèles réels à partir de modèles aléatoires.
Évidemment, l'apprentissage automatique est très facile à appliquer aux méthodes d'exploration de données.
L'exemple de code utilise un outil de backtesting basé sur la plateforme FMZ Quant et une interface API de transaction automatisée. Après avoir déployé le docker et installé Anaconda dans la section ci-dessus, il vous suffit d'installer la bibliothèque d'analyse de la science des données dont nous avons besoin et le célèbre modèle d'apprentissage automatique scikit-learn.
pip install -U scikit-learn
Utiliser l'apprentissage automatique pour créer des signaux de stratégie de trading
- L'extraction de données. Avant de commencer, un système de problème d'apprentissage automatique standard est montré sur la figure suivante:
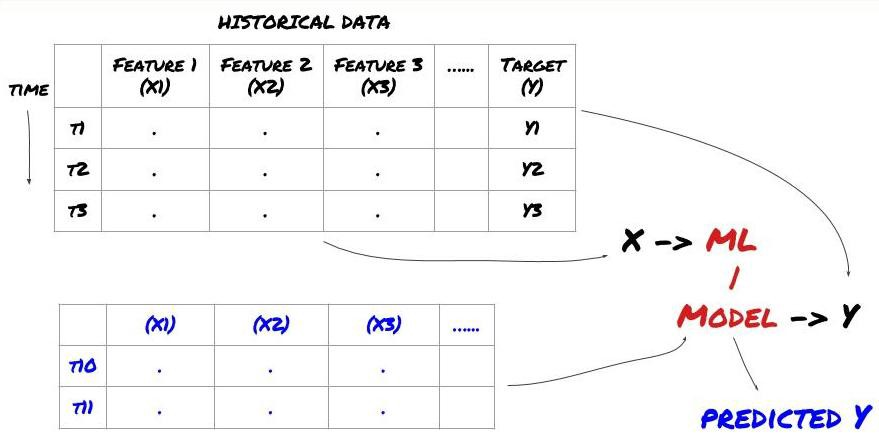
Système de problème d'apprentissage automatique
La fonctionnalité que nous allons créer doit avoir une certaine capacité de prédiction (X). Nous voulons prédire la variable cible (Y) et utiliser les données historiques pour former le modèle ML qui peut prédire Y aussi près que possible de la valeur réelle. Enfin, nous utilisons ce modèle pour faire des prédictions sur de nouvelles données où Y est inconnu. Cela nous amène à la première étape:
Étape 1: Posez votre question
- Que voulez-vous prédire? Quelle est une bonne prédiction? Comment évaluez-vous les résultats de la prédiction?
C'est-à-dire, dans notre cadre ci-dessus, ce qui est Y?
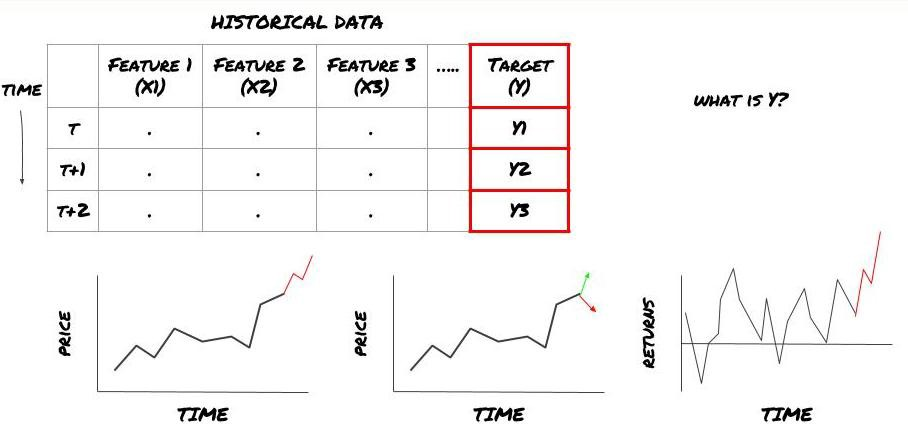
Que voulez-vous prédire?
Voulez-vous prédire les prix futurs, les rendements futurs / Pnl, acheter / vendre des signaux, optimiser l'allocation du portefeuille et essayer d'exécuter les transactions efficacement?
Supposons que nous essayions de prévoir les prix sur le prochain horodatage. dans ce cas, Y (t) = prix (t + 1).
Notez que Y (t) n'est connu que dans le backtest, mais lorsque nous utilisons notre modèle, nous ne connaîtrons pas le prix (t + 1) du temps t. Nous utilisons notre modèle pour prédire Y (prédit, t) et le comparer à la valeur réelle seulement au temps t + 1. Cela signifie que vous ne pouvez pas utiliser Y comme une caractéristique dans le modèle de prédiction.
Une fois que nous connaissons la cible Y, nous pouvons également décider comment évaluer nos prédictions. C'est important pour différencier les différents modèles des données que nous allons essayer. Sélectionnez un indicateur pour mesurer l'efficacité de notre modèle en fonction du problème que nous résolvons. Par exemple, si nous prévoyons des prix, nous pouvons utiliser l'erreur carrée moyenne racine comme indicateur. Certains indicateurs couramment utilisés (EMA, MACD, score de variance, etc.) ont été pré-codés dans la boîte à outils FMZ Quant. Vous pouvez appeler ces indicateurs globalement via l'interface API.
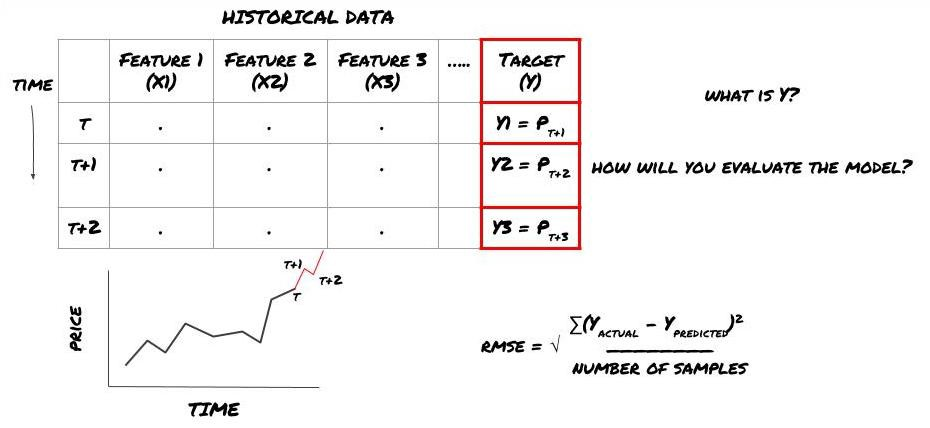
Cadre ML pour la prévision des prix futurs
À des fins de démonstration, nous créerons un modèle de prévision pour prédire la valeur de référence (base) future attendue d'un objet d'investissement hypothétique, où:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Comme il s'agit d'un problème de régression, nous évaluerons le modèle sur RMSE (erreur carrée moyenne de la racine).
Remarque: veuillez vous référer à l'encyclopédie Baidu pour les connaissances mathématiques pertinentes de RMSE.
- Notre objectif: créer un modèle pour rendre la valeur prédite aussi proche que possible de Y.
Étape 2: Rassembler des données fiables
Rassemblez et éliminez les données qui peuvent vous aider à résoudre le problème.
Si nous prévoyons le prix, vous pouvez utiliser les données de prix de l'objet d'investissement, les données de quantité de négociation de l'objet d'investissement, les données similaires de l'objet d'investissement associé, le niveau d'indice de l'objet d'investissement et d'autres indicateurs globaux du marché, ainsi que le prix d'autres actifs associés.
Vous devez définir des autorisations d'accès aux données pour ces données et vous assurer que vos données sont exactes, et résoudre les données perdues (un problème très courant). En même temps, assurez-vous que vos données sont impartiales et pleinement représentatives de toutes les conditions du marché (par exemple, le même nombre de scénarios de profit et de perte) pour éviter les biais dans le modèle. Vous devrez peut-être également nettoyer les données pour obtenir des dividendes, des objectifs d'investissement fractionnés, des continuations, etc.
Si vous utilisez la plate-forme FMZ Quant (FMZ. COM), nous pouvons accéder gratuitement aux données mondiales de Google, Yahoo, NSE et Quandl; aux données de profondeur des contrats à terme sur matières premières nationaux tels que CTP et Esunny; aux données des principaux échanges de devises numériques tels que Binance, OKX, Huobi et BitMex. La plate-forme FMZ Quant pré-nettoie et filtre également ces données, telles que la division des objectifs d'investissement et des données de marché approfondies, et les présente aux développeurs de stratégies dans un format facile à comprendre pour les praticiens quantitatifs.
Pour faciliter la démonstration de cet article, nous utilisons les données suivantes comme
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Avec le code ci-dessus, Auquan
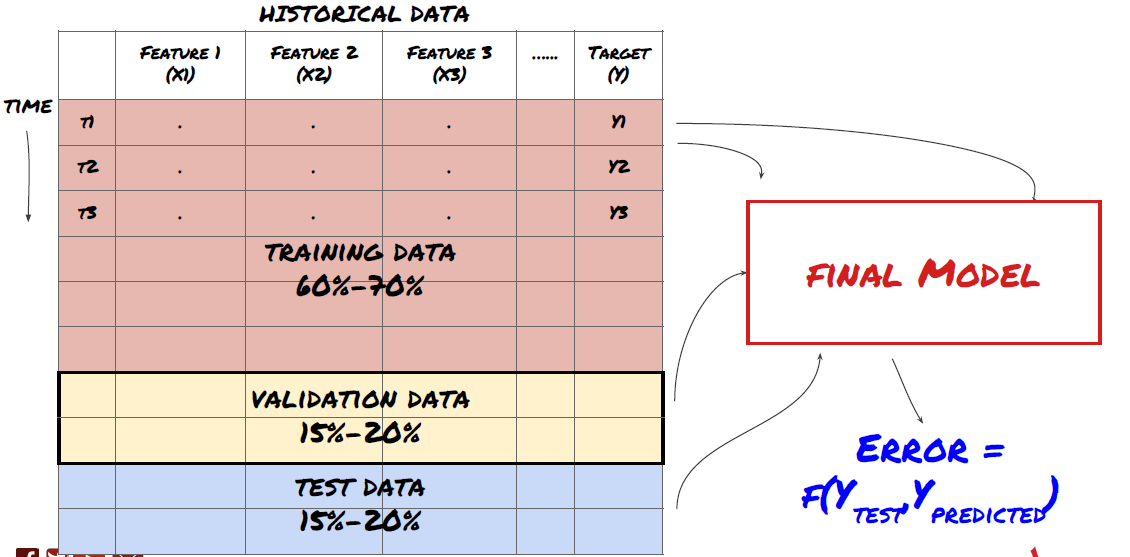
Étape 3: diviser les données
- Créer des ensembles de formation, vérifier et tester ces ensembles de données à partir de données.
C'est une étape très importante!Avant de continuer, nous devrions diviser les données en ensembles de données de formation pour former votre modèle; Ensembles de données de test pour évaluer les performances du modèle.
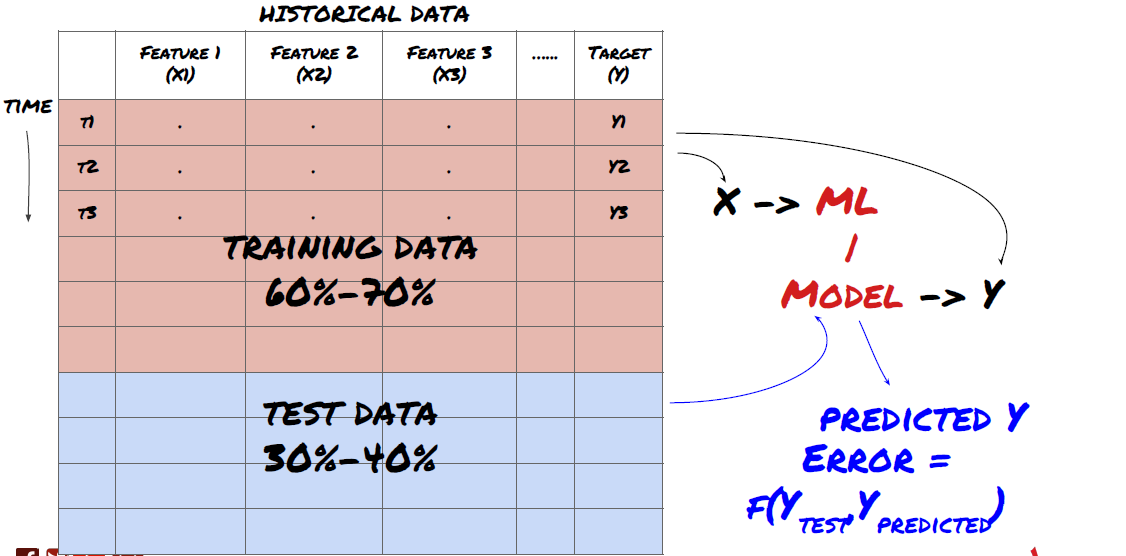
Diviser les données en ensembles de formation et en ensembles de test
Puisque les données de formation sont utilisées pour évaluer les paramètres du modèle, votre modèle peut trop s'adapter à ces données de formation, et les données de formation peuvent induire en erreur les performances du modèle. Si vous ne conservez pas de données de test individuelles et n'utilisez pas toutes les données pour la formation, vous ne saurez pas à quel point votre modèle fonctionne bien ou mal sur les nouvelles données invisibles. C'est l'une des principales raisons de l'échec du modèle ML formé dans les données en temps réel: les gens entraînent toutes les données disponibles et sont excités par les indicateurs des données de formation, mais le modèle ne peut pas faire de prédiction significative sur les données en temps réel non formées.
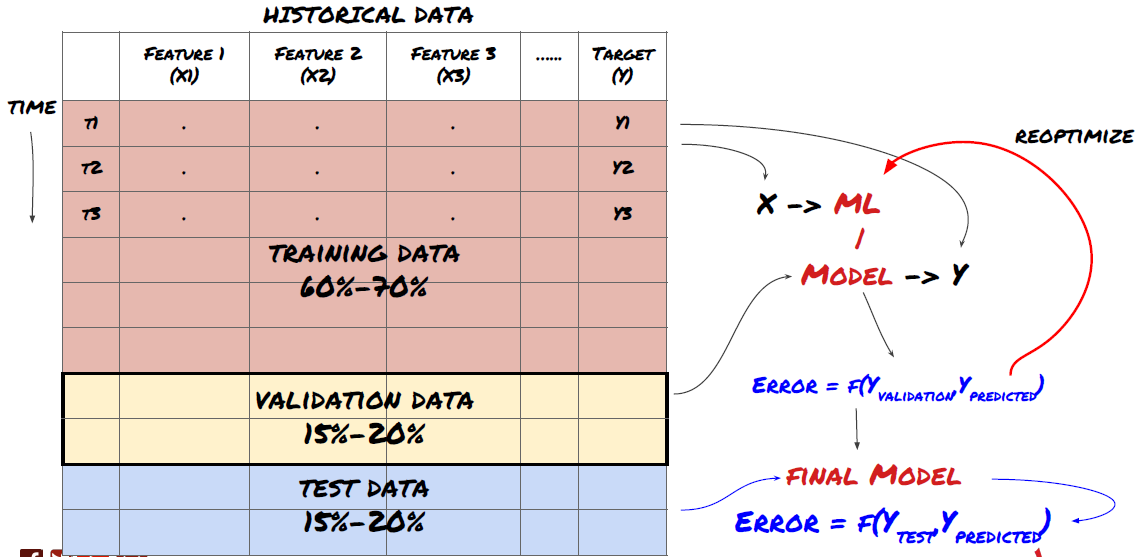
Diviser les données en séries de formation, de vérification et de test
Il y a des problèmes avec cette méthode. Si nous entraînons les données d'entraînement à plusieurs reprises, évaluons la performance des données d'essai et optimisons notre modèle jusqu'à ce que nous soyons satisfaits de la performance, nous prenons les données d'essai comme une partie des données d'entraînement implicitement. À la fin, notre modèle peut bien fonctionner sur cet ensemble de données d'entraînement et de test, mais il ne peut pas garantir qu'il peut bien prédire de nouvelles données.
Pour résoudre ce problème, nous pouvons créer un ensemble de données de validation séparé. Maintenant, vous pouvez entraîner les données, évaluer la performance des données de validation, optimiser jusqu'à ce que vous soyez satisfait de la performance, et finalement tester les données de test. De cette façon, les données de test ne seront pas polluées, et nous n'utiliserons aucune information dans les données de test pour améliorer notre modèle.
Rappelez-vous, une fois que vous avez vérifié la performance de vos données de test, ne revenez pas et essayez d'optimiser davantage votre modèle. Si vous constatez que votre modèle ne donne pas de bons résultats, jetez complètement le modèle et recommencez. Il est suggéré que 60% des données de formation, 20% des données de validation et 20% des données de test puissent être divisées.
Pour notre question, nous avons trois ensembles de données disponibles. Nous utiliserons l'un comme ensemble d'entraînement, le second comme ensemble de vérification, et le troisième comme notre ensemble de test.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Pour chacune d'elles, nous ajoutons la variable cible Y, qui est définie comme la moyenne des cinq valeurs de base suivantes.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Étape 4: Ingénierie des caractéristiques
Analyser le comportement des données et créer des fonctionnalités prédictives
Maintenant, la construction réelle du projet a commencé. La règle d'or de la sélection des fonctionnalités est que la capacité de prédiction provient principalement des fonctionnalités, et non des modèles. Vous constaterez que la sélection des fonctionnalités a un impact beaucoup plus important sur les performances que la sélection des modèles.
-
Ne sélectionnez pas un grand ensemble de caractéristiques au hasard sans explorer la relation avec la variable cible.
-
Une faible ou aucune relation avec la variable cible peut entraîner un surajustement.
-
Les caractéristiques que vous sélectionnez peuvent être fortement liées les unes aux autres, auquel cas un petit nombre de caractéristiques peut également expliquer la cible.
-
Je crée généralement des fonctionnalités intuitives, je vérifie la corrélation entre la variable cible et ces fonctionnalités, et la corrélation entre elles pour décider laquelle utiliser.
-
Vous pouvez également essayer d'effectuer une analyse des composants principaux (PCA) et d'autres méthodes pour trier les caractéristiques candidates en fonction du coefficient d'information maximal (MIC).
Transformation/normalisation des caractéristiques:
Les modèles ML ont tendance à bien fonctionner en termes de normalisation. Cependant, la normalisation est difficile lorsqu'il s'agit de données de séries temporelles, car la plage de données future est inconnue. Vos données peuvent être en dehors de la plage de normalisation, ce qui entraîne des erreurs de modèle. Mais vous pouvez toujours essayer de forcer un certain degré de stabilité:
-
Étalonnage: division des caractéristiques par écart type ou gamme de quartiles.
-
Centrage: soustraire la valeur moyenne historique de la valeur actuelle.
-
Normalization: deux périodes rétrospectives de ce qui précède (x - moyenne) /stdev.
-
Normalisation régulière: normaliser les données dans la plage de -1 à +1 et redéterminer le centre dans la période de rétroaction (x-min) / ((max min).
Notez que puisque nous utilisons la valeur moyenne continue historique, l'écart type, les valeurs maximales ou minimales au-delà de la période de retracement, la valeur de normalisation normalisée de la caractéristique représentera des valeurs réelles différentes à des moments différents. Par exemple, si la valeur actuelle de la caractéristique est de 5 et la valeur moyenne pour 30 périodes consécutives est de 4,5, elle sera convertie en 0,5 après centralisation. Après cela, si la valeur moyenne de 30 périodes consécutives devient 3, la valeur de 3,5 deviendra 0,5.
Pour la première itération de notre problème, nous avons créé un grand nombre de caractéristiques en utilisant des paramètres mixtes.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Étape 5: Sélection du modèle
Sélectionnez le modèle statistique/ML approprié en fonction des questions sélectionnées.
Le choix du modèle dépend de la façon dont le problème est formé. Est-ce que vous résolvez supervisé (chaque point X dans la matrice de caractéristiques est mappé à la variable cible Y) ou apprentissage non supervisé (sans une cartographie donnée, le modèle tente d'apprendre un modèle inconnu)?

Apprentissage supervisé ou non supervisé

Régression ou classification
Quelques algorithmes d'apprentissage supervisé communs peuvent vous aider à commencer:
-
Régression linéaire (paramètres, régression)
-
Régression logistique (paramètre, classification)
-
L'algorithme K-Nearest Neighbor (KNN) (basé sur les cas, régression)
-
SVM, SVR (paramètres, classification et régression)
-
Arbre de décision
-
Forêt de décision
Je suggère de commencer par un modèle simple, comme la régression linéaire ou logistique, et de construire des modèles plus complexes à partir de là selon les besoins.
Étape 6: Formation, vérification et optimisation (répéter les étapes 4-6)
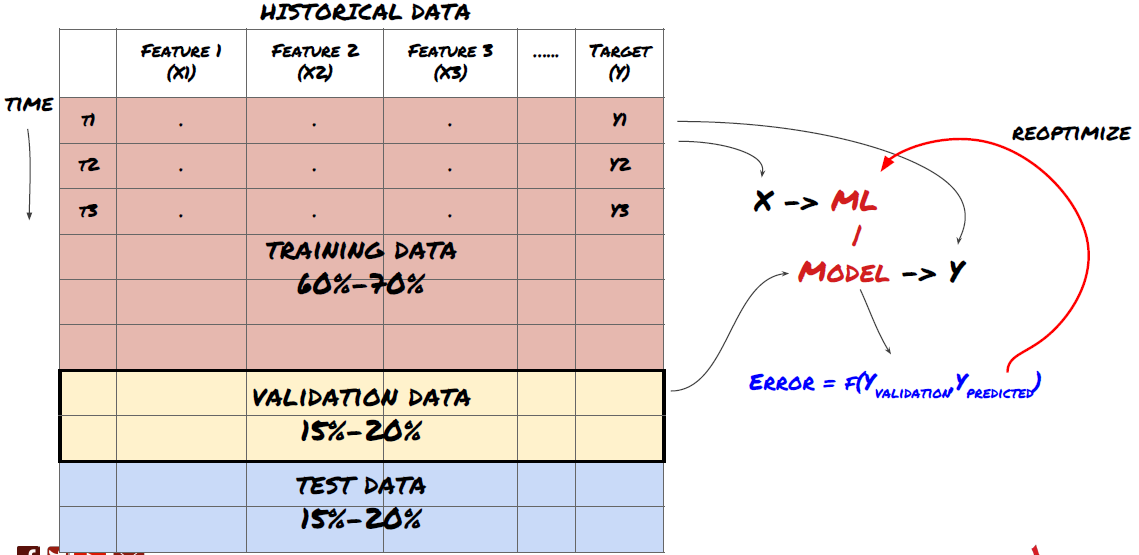
Utiliser des ensembles de données de formation et de vérification pour former et optimiser votre modèle
Maintenant, vous êtes prêt à construire le modèle. À ce stade, il vous suffit d'itérer le modèle et les paramètres du modèle. Entraînez votre modèle sur les données de formation, mesurez sa performance sur les données de vérification, puis revenez, optimisez, re-entraînez et évaluez-le. Si vous n'êtes pas satisfait de la performance du modèle, veuillez essayer un autre modèle.
Seulement quand vous avez votre modèle préféré, puis passer à l'étape suivante.
Pour notre problème de démonstration, commençons par une simple régression linéaire:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
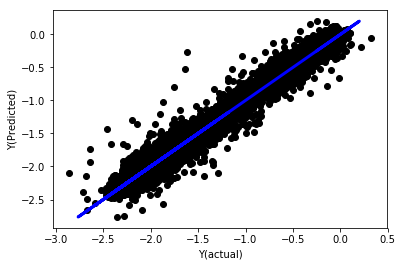
Régression linéaire sans normalisation
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Regardez les coefficients du modèle. nous ne pouvons pas vraiment les comparer ou dire lequel est important, parce qu'ils appartiennent tous à des échelles différentes. essayons la normalisation pour les rendre conformes à la même proportion et aussi imposer une certaine douceur.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
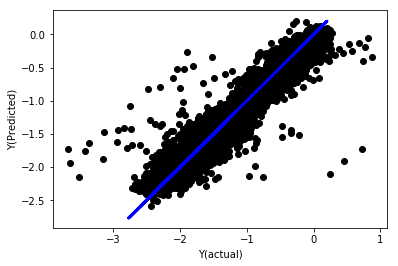
Régression linéaire avec normalisation
Mean squared error: 0.05
Variance score: 0.90
Ce modèle n'améliore pas le modèle précédent, mais il n'est pas pire.
Regardons les coefficients:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Les résultats sont les suivants:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Nous pouvons voir clairement que certaines caractéristiques ont des coefficients plus élevés que d'autres, et qu'elles peuvent avoir une capacité de prédiction plus forte.
Voyons la corrélation entre les différentes caractéristiques.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
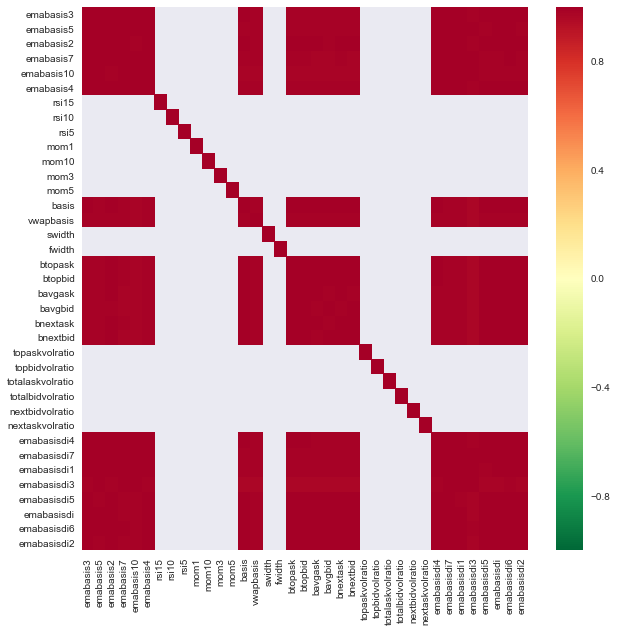
Corrélation entre les caractéristiques
Les zones rouges foncées représentent des variables fortement corrélées.
Par exemple, je peux éliminer facilement des caractéristiques comme emabasisdi7, qui ne sont que des combinaisons linéaires d'autres caractéristiques.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
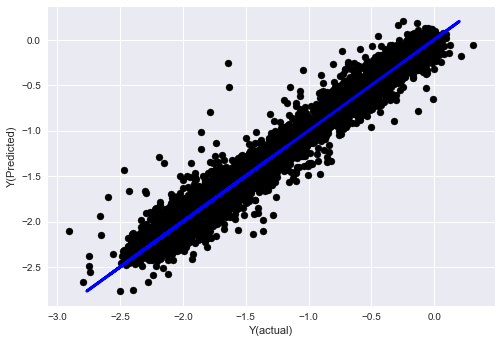
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Écoutez, les performances de notre modèle n'ont pas changé. Nous avons seulement besoin de quelques caractéristiques pour expliquer nos variables cibles. Je vous suggère d'essayer plus des caractéristiques ci-dessus, essayer de nouvelles combinaisons, etc., pour voir ce qui peut améliorer notre modèle.
Nous pouvons également essayer des modèles plus complexes pour voir si les modifications apportées aux modèles peuvent améliorer les performances.
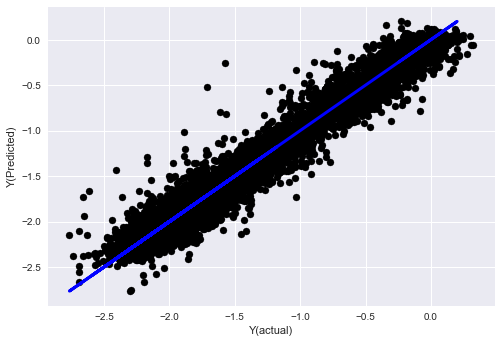
- L'algorithme du voisin le plus proche (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
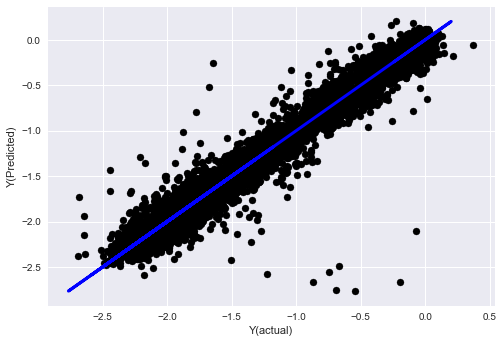
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Arbre de décision
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
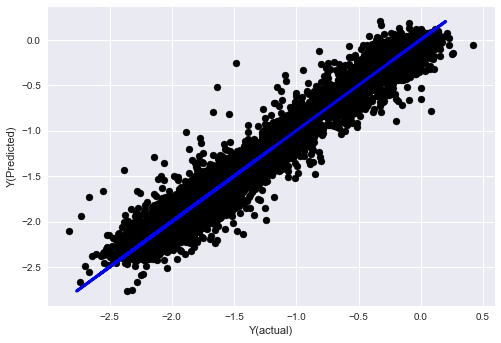
Étape 7: vérification des données d'essai
Vérifiez la performance des données d'échantillonnage réelles
Résultats des tests antérieurs sur des ensembles de données d'essai (non modifiés)
C'est un moment critique. Nous avons exécuté notre modèle d'optimisation final à partir de la dernière étape des données de test, nous l'avons mis de côté au début et nous n'avons pas touché aux données jusqu'à présent.
Cela vous donne une attente réaliste de la façon dont votre modèle s'exécutera sur les données nouvelles et invisibles lorsque vous commencez le trading en temps réel.
Si vous n'aimez pas les résultats des backtests des données de test, veuillez éliminer le modèle et recommencer. Ne jamais revenir en arrière ou réoptimiser votre modèle, ce qui conduira à un sur-ajustement! (Il est également recommandé de créer un nouvel ensemble de données de test, car cet ensemble de données est maintenant pollué; lors de l'élimination du modèle, nous connaissons déjà le contenu de l'ensemble de données implicitement).
Ici, nous continuerons à utiliser la boîte à outils Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
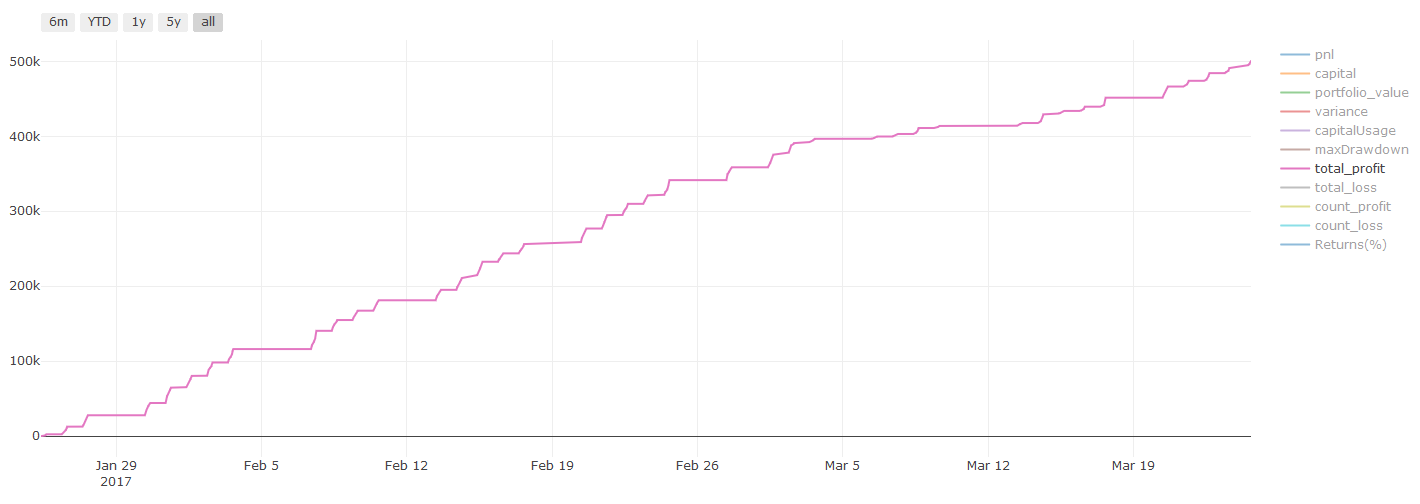
Résultats du backtesting, Pnl est calculé en USD (Pnl n'est pas inclus dans les frais de transaction et autres frais)
Étape 8: Autres méthodes d'amélioration du modèle
Vérification du roulement, apprentissage des ensembles, emballage et renforcement
En plus de recueillir plus de données, de créer de meilleures fonctionnalités ou d'essayer plus de modèles, il y a quelques autres points que vous pouvez essayer d'améliorer.
1. vérification du roulement
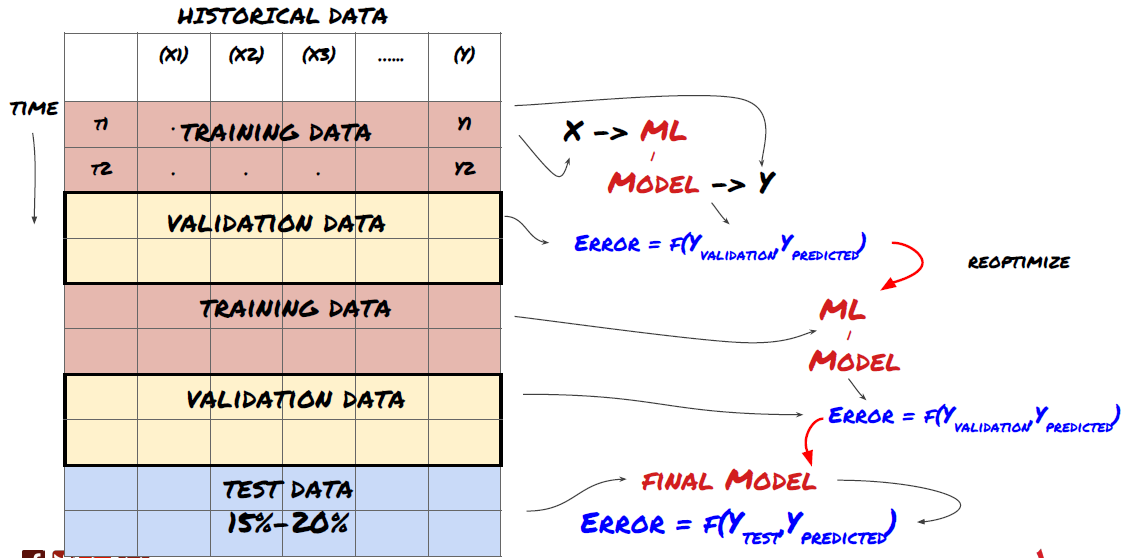
Vérification du roulement
Les conditions du marché restent rarement les mêmes. Supposons que vous ayez des données d'un an, et que vous utilisiez les données de janvier à août pour la formation, et utilisez les données de septembre à décembre pour tester votre modèle. Vous pouvez éventuellement vous entraîner pour un ensemble très spécifique de conditions du marché. Peut-être qu'il n'y a pas eu de fluctuation du marché dans la première moitié de l'année, et certaines nouvelles extrêmes ont conduit à une forte hausse du marché en septembre. Votre modèle ne sera pas en mesure d'apprendre ce modèle, et il vous apportera des résultats de prédiction de déchets.
Il peut être préférable d'essayer une vérification continue, telle que la formation de janvier à février, la vérification en mars, la reconversion d'avril à mai, la vérification en juin, etc.
2. L'apprentissage par lots
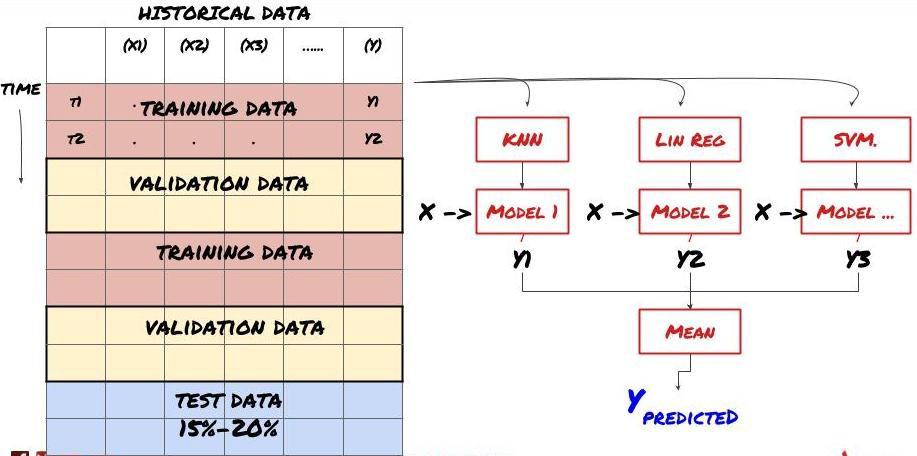
Apprentissage par jeu
Certains modèles peuvent être très efficaces pour prédire certains scénarios, tandis que les modèles peuvent être extrêmement sur-adaptés pour prédire d'autres scénarios ou dans certaines circonstances. Une façon de réduire les erreurs et le sur-adaptation est d'utiliser un ensemble de modèles différents. Votre prédiction sera la moyenne des prédictions faites par de nombreux modèles, et les erreurs de différents modèles peuvent être compensées ou réduites. Certaines méthodes d'ensemble courantes sont le sachetage et le boosting.
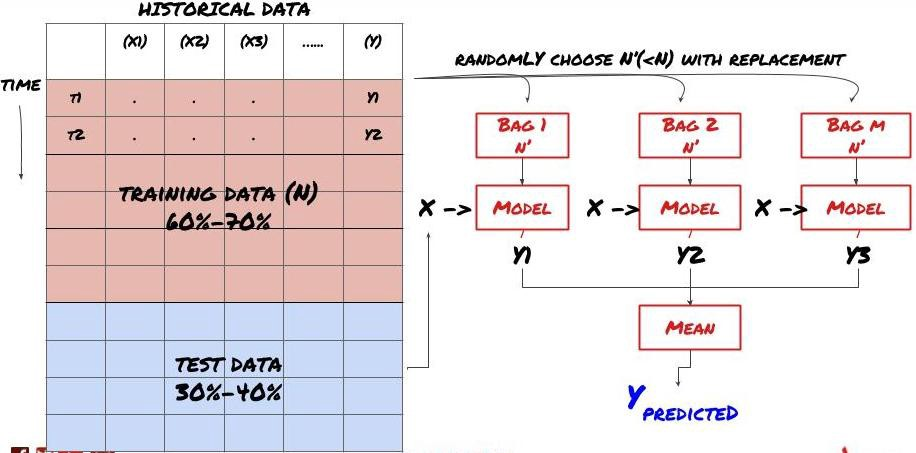
Emportement en sac
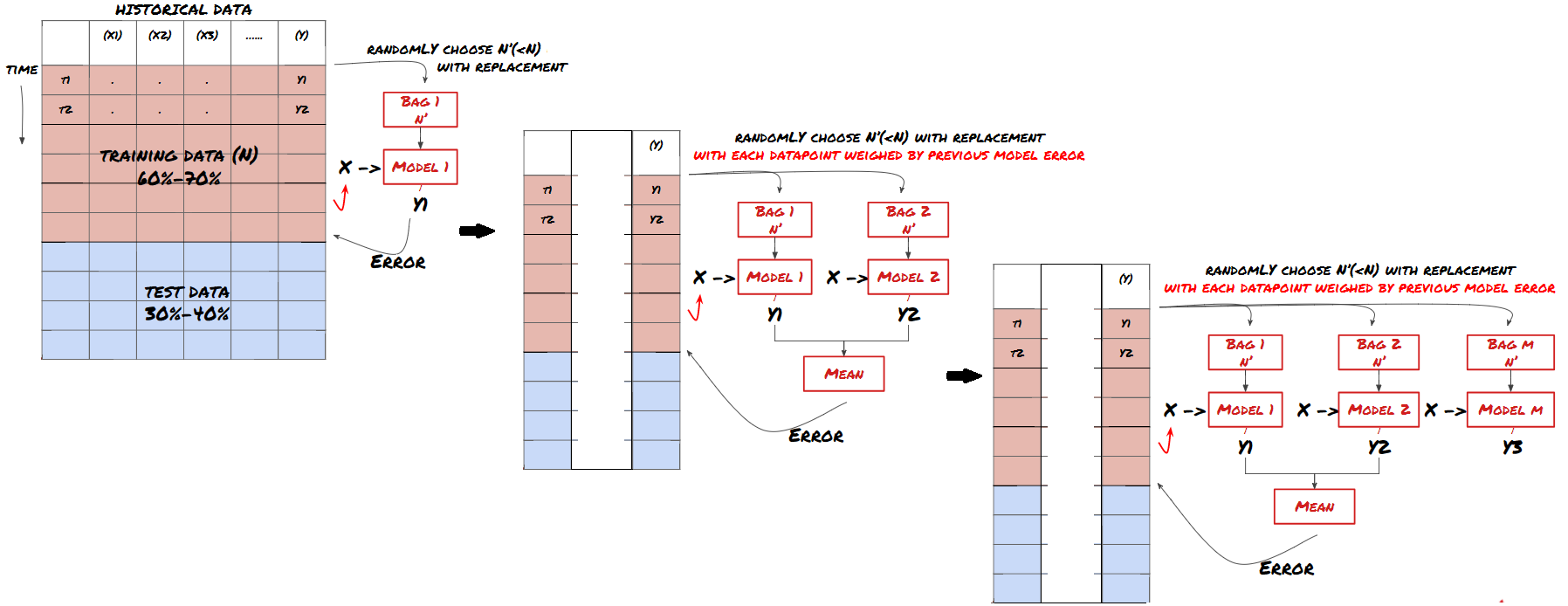
Le renforcement
Pour des raisons de brièveté, je vais sauter ces méthodes, mais vous pouvez trouver plus d'informations en ligne.
Essayons une méthode de jeu pour notre problème:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Pour l'instant, nous avons accumulé beaucoup de connaissances et d'informations.
-
Résolvez votre problème;
-
collecter des données fiables et les nettoyer;
-
Diviser les données en ensembles de formation, de vérification et d'essai;
-
Créer des caractéristiques et analyser leurs comportements;
-
Sélectionner le modèle d'entraînement approprié en fonction du comportement;
-
Utiliser les données de formation pour former votre modèle et faire des prédictions;
-
vérifier les performances du jeu de vérification et réoptimiser;
-
Vérifier les performances finales de l'ensemble d'essai.
N'avez-vous pas compris? Mais ce n'est pas encore fini. Vous n'avez qu'un modèle de prédiction fiable.
-
Développer des signaux basés sur des modèles prédictifs pour identifier les directions de négociation;
-
Élaborer des stratégies spécifiques pour identifier les positions ouvertes et fermées;
-
Exécuter le système pour identifier les positions et les prix.
Le programme de développement de la plateforme FMZ Quant (FMZ.COMSur la plateforme FMZ Quant, il existe des interfaces API très encapsulées et parfaites, ainsi que des fonctions de commande et de trading qui peuvent être appelées globalement. Vous n'avez pas besoin de connecter et d'ajouter les interfaces API de différents échanges une par une. Dans le carré de stratégie de la plateforme FMZ Quant, il existe de nombreuses stratégies alternatives matures et parfaites qui correspondent à la méthode d'apprentissage automatique de cet article, ce qui rendra votre stratégie spécifique plus puissante.https://www.fmz.com/square.
**Note importante sur les coûts de transaction: ** Votre modèle vous indiquera quand l'actif sélectionné va long ou court. Cependant, il ne prend pas en compte les frais / coûts de transaction / quantité de trading disponible / stop loss, etc. Les coûts de transaction transforment généralement les transactions rentables en pertes. Par exemple, un actif avec une augmentation de prix attendue de 0,05 $ est un achat, mais si vous devez payer 0,10 $ pour cette transaction, vous obtiendrez une perte nette de 0,05 $ éventuellement. Après avoir pris en compte la commission du courtier, les frais de change et la différence de point, notre excellent graphique de profit ci-dessus ressemble à ceci:
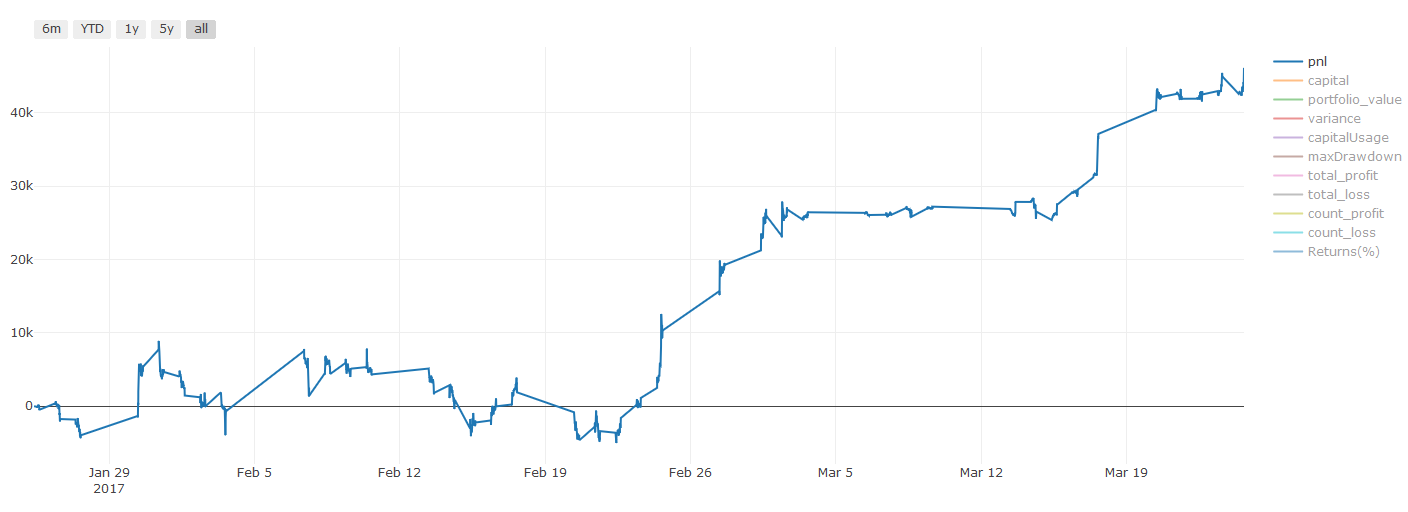
Le résultat du backtest après frais de négociation et différence de points, Pnl est USD.
Les frais de transaction et les différences de prix représentent plus de 90% de notre PNL!
Enfin, examinons quelques pièges courants.
Ce qu'il faut faire et ne pas faire
-
Évitez de vous sur-adapter de toutes vos forces!
-
Ne pas re-trainer après chaque point de données: c'est une erreur courante que les gens font dans le développement de l'apprentissage automatique. Si votre modèle doit être re-trainé après chaque point de données, il peut ne pas être un très bon modèle. C'est-à-dire qu'il doit être re-trainé régulièrement et ne doit être formé qu'à une fréquence raisonnable (par exemple, si une prédiction intra-journée est faite, il doit être re-trainé à la fin de chaque semaine).
-
Évitez les biais, en particulier les biais prospectifs: C'est une autre raison pour laquelle le modèle ne fonctionne pas, et assurez-vous de ne pas utiliser d'informations futures. Dans la plupart des cas, cela signifie que la variable cible Y n'est pas utilisée comme fonctionnalité dans le modèle. Vous pouvez l'utiliser pendant le backtesting, mais elle ne sera pas disponible lorsque vous exécutez le modèle réellement, ce qui rendra votre modèle inutilisable.
-
Méfiez-vous du biais de l'exploration de données: Comme nous essayons de mener une série de modélisations sur nos données pour déterminer si c'est approprié, s'il n'y a pas de raison particulière, assurez-vous d'exécuter des tests stricts pour séparer le mode aléatoire du mode réel qui peut se produire. Par exemple, la régression linéaire explique bien le modèle de tendance à la hausse, mais il est probable qu'il devienne une fraction des plus grandes errances aléatoires!
Évitez de trop le fixer
C'est très important, je pense qu'il est nécessaire de le rappeler.
-
Le sur-ajustement est le piège le plus dangereux dans les stratégies de trading;
-
Un algorithme complexe peut très bien fonctionner dans le backtest, mais il échoue misérablement sur les nouvelles données invisibles. Cet algorithme ne révèle pas vraiment aucune tendance des données, ni n'a de réelle capacité de prédiction. Il est très adapté aux données qu'il voit;
-
Si vous trouvez que vous avez besoin de beaucoup de fonctions complexes pour interpréter les données, vous pourriez être trop adapté;
-
Divisez vos données disponibles en données de formation et de test, et vérifiez toujours les performances des données d'échantillons réels avant d'utiliser le modèle pour les transactions en temps réel.
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (1)
- Discussion sur la réception de signaux externes de la plateforme FMZ: API étendue VS stratégie intégrée au service HTTP
- Débat sur la réception de signaux externes sur la plateforme FMZ: API étendue contre stratégie de service HTTP intégré
- Discussion sur la méthode de test de stratégie basée sur le générateur de tickers aléatoires
- Une méthode de test stratégique basée sur un générateur de marché aléatoire
- Nouvelle fonctionnalité de FMZ Quant: Utilisez la fonction _Serve pour créer facilement des services HTTP
- Réseaux neuronaux et série de négociation quantitative de monnaie numérique (1) - LSTM prédit le prix du Bitcoin
- Application de la stratégie combinée de l'indice de force relative SMA et de l'indice de force relative RSI
- Développement de la stratégie CTA et de la bibliothèque de classes standard de la plateforme FMZ Quant
- Stratégie de négociation quantitative avec analyse de la dynamique des prix en Python
- Mettre en œuvre une stratégie de négociation quantitative de monnaie numérique à double poussée en Python
- La meilleure façon d'installer et de mettre à niveau pour Linux docker
- Réalisation de stratégies équilibrées de capitaux propres pour les positions longues à court terme avec un alignement ordonné
- Analyse des données de séries temporelles et vérification des données de tics
- Analyse quantitative du marché des monnaies numériques
- Le trading par paire basé sur une technologie basée sur les données
- Utiliser l'environnement de recherche pour analyser les détails de la couverture triangulaire et l'impact des frais de traitement sur la différence de prix couverte
- Réforme de l'API des contrats à terme Deribit pour l'adapter à la négociation quantitative des options
- Les meilleurs outils font du bon travail - apprenez à utiliser l'environnement de recherche pour analyser les principes du trading
- Stratégies de couverture par devises dans le cadre de la négociation quantitative d'actifs de la chaîne de blocs
- Acquérir le guide de la stratégie de la monnaie numérique de FMex sur FMZ Quant
- Apprendre à écrire des stratégies - transplanter une stratégie MyLanguage (Advanced)
- Apprendre à écrire des stratégies -- transplanter une stratégie MyLanguage
- Apprendre à ajouter un support multi-graphique à la stratégie
- Apprendre à écrire une fonction de synthèse de ligne K dans la version Python
- Analyse de la stratégie du canal de Donchian dans le cadre de la recherche