मशीन लर्निंग एल्गोरिदम की एक यात्रा
 0
3101
0
3101
मशीन लर्निंग एल्गोरिदम की एक यात्रा
मशीन सीखने की समस्या को समझने के बाद, हम सोच सकते हैं कि हमें क्या डेटा इकट्ठा करने की आवश्यकता है और हम किस तरह के एल्गोरिदम का उपयोग कर सकते हैं। इस लेख में हम सबसे लोकप्रिय मशीन सीखने के एल्गोरिदम के बारे में बात करेंगे और यह देखने में मदद करेंगे कि कौन से तरीके काम कर सकते हैं। मशीन सीखने के क्षेत्र में कई एल्गोरिदम हैं, और प्रत्येक एल्गोरिथ्म के लिए कई एक्सटेंशन हैं, इसलिए किसी विशेष समस्या के लिए सही एल्गोरिथ्म का निर्धारण करना बहुत मुश्किल है। इस लेख में मैं आपको वास्तविक दुनिया में आने वाले एल्गोरिथ्म को शामिल करने के लिए दो तरीकों के बारे में बताऊंगा।
- #### सीखने का तरीका
एल्गोरिदम को विभिन्न प्रकारों में वर्गीकृत किया जाता है, जो कि अनुभव, वातावरण या किसी भी डेटा को हम इनपुट कहते हैं, के अनुसार हैं। मशीन सीखने और कृत्रिम बुद्धिमत्ता की पाठ्यपुस्तकों में, आमतौर पर यह माना जाता है कि एल्गोरिदम किस प्रकार सीख सकते हैं।
यहां केवल कुछ प्रमुख शैलियों या सीखने के मॉडल पर चर्चा की गई है, और कुछ बुनियादी उदाहरण दिए गए हैं। यह वर्गीकरण या संगठन का तरीका अच्छा है क्योंकि यह आपको इनपुट डेटा की भूमिका और मॉडल तैयार करने की प्रक्रिया के बारे में सोचने के लिए मजबूर करता है, और फिर एक एल्गोरिथ्म चुनता है जो आपके लिए सबसे उपयुक्त है ताकि आप सबसे अच्छा परिणाम प्राप्त कर सकें।
पर्यवेक्षित सीखनाः इनपुट डेटा को प्रशिक्षण डेटा कहा जाता है और इसका परिणाम ज्ञात होता है या इसे चिह्नित किया जाता है। उदाहरण के लिए, यह कहना कि क्या एक ईमेल स्पैम है, या एक निश्चित समय के लिए शेयर की कीमत। मॉडल भविष्यवाणी करता है और यदि गलत है तो इसे सही किया जाता है, और यह प्रक्रिया तब तक जारी रहती है जब तक कि यह प्रशिक्षण डेटा के लिए कुछ सही मानदंडों को पूरा नहीं करता है। समस्या उदाहरणों में वर्गीकरण और वापसी समस्याएं शामिल हैं, और एल्गोरिथ्म उदाहरणों में लॉजिकल रिग्रेशन और रिवर्स न्यूरल नेटवर्क शामिल हैं। अनियंत्रित सीखनाः इनपुट डेटा को चिह्नित नहीं किया जाता है और कोई निश्चित परिणाम नहीं होता है। मॉडल डेटा की संरचना और संख्यात्मक मानों को शामिल करता है। समस्या के उदाहरणों में एसोसिएशन नियम सीखने और क्लैशिंग समस्याएं शामिल हैं, एल्गोरिदम के उदाहरणों में एप्रियोरी एल्गोरिदम और के-औसत एल्गोरिदम शामिल हैं। अर्ध-निरीक्षित सीखनाः इनपुट डेटा चिह्नित और अनचिह्नित डेटा का मिश्रण है, कुछ भविष्यवाणी की समस्याएं हैं लेकिन मॉडल को डेटा की संरचना और संरचना भी सीखनी होगी। समस्या के उदाहरणों में वर्गीकरण और प्रतिगमन समस्याएं शामिल हैं, एल्गोरिथ्म के उदाहरण मूल रूप से अनियंत्रित सीखने वाले एल्गोरिदम का विस्तार हैं। संवर्धित सीखनाः इनपुट डेटा मॉडल को उत्तेजित कर सकता है और मॉडल को प्रतिक्रिया दे सकता है। प्रतिक्रिया न केवल पर्यवेक्षित सीखने की सीखने की प्रक्रिया से प्राप्त की जाती है, बल्कि पर्यावरण में पुरस्कार या दंड से भी प्राप्त की जाती है। समस्या उदाहरण रोबोट नियंत्रण हैं, एल्गोरिथ्म के उदाहरणों में क्यू-लर्निंग और अस्थायी अंतर सीखने शामिल हैं।
जब डेटा सिमुलेशन व्यवसाय निर्णयों को एकीकृत किया जाता है, तो अधिकांश लोग पर्यवेक्षित और अनियंत्रित सीखने के तरीकों का उपयोग करते हैं। अगला गर्म विषय अर्ध-पर्यवेक्षित सीखने है, उदाहरण के लिए छवि वर्गीकरण समस्या, जिसमें एक बड़ा डेटाबेस है, लेकिन केवल एक छोटी संख्या में चित्रों को चिह्नित किया गया है। उन्नत सीखने का उपयोग ज्यादातर रोबोट नियंत्रण और अन्य नियंत्रण प्रणालियों के विकास में किया जाता है।
- #### एल्गोरिथ्म समानता
एल्गोरिदम को मुख्य रूप से कार्यात्मक या औपचारिक रूप से वर्गीकृत किया जाता है। उदाहरण के लिए, पेड़-आधारित एल्गोरिदम, तंत्रिका नेटवर्क एल्गोरिदम। यह एक उपयोगी वर्गीकरण है, लेकिन यह सही नहीं है। क्योंकि कई एल्गोरिदम को आसानी से दो श्रेणियों में विभाजित किया जा सकता है, जैसे कि लर्निंग वेक्टर क्वांटिज़ेशन, जो कि तंत्रिका नेटवर्क प्रकार के एल्गोरिदम और उदाहरण-आधारित विधि दोनों हैं। जैसे कि मशीन लर्निंग एल्गोरिदम के पास एक आदर्श मॉडल नहीं है, एल्गोरिदम के वर्गीकरण के तरीके भी सही नहीं हैं।
इस भाग में मैंने वर्गीकरण के लिए एल्गोरिदम को सूचीबद्ध किया है जो मुझे लगता है कि सबसे सहज तरीके हैं। मैं एल्गोरिदम या वर्गीकरण के तरीकों को समाप्त नहीं कर रहा हूं, लेकिन मुझे लगता है कि यह पाठकों को एक सामान्य ज्ञान देने में मददगार होगा। यदि आप जानते हैं कि मैंने क्या सूचीबद्ध नहीं किया है, तो टिप्पणी करने के लिए स्वतंत्र महसूस करें। अब हम शुरू करते हैं!
- #### Regression
Regression (वापसी विश्लेषण) चरों के बीच संबंधों के बारे में है। यह सांख्यिकीय तरीकों का उपयोग करता है। इसके कुछ उदाहरणों में शामिल हैंः
Ordinary Least Squares Logistic Regression Stepwise Regression Multivariate Adaptive Regression Splines (MARS) Locally Estimated Scatterplot Smoothing (LOESS)
- #### Instance-based Methods
उदाहरण-आधारित सीखना एक निर्णय लेने की समस्या का अनुकरण करता है, उदाहरण या उदाहरण का उपयोग मॉडल के लिए बहुत महत्वपूर्ण है। यह विधि मौजूदा डेटा के लिए एक डेटाबेस बनाती है और फिर नए डेटा को जोड़ती है, फिर एक समानता माप विधि का उपयोग करती है ताकि डेटाबेस में एक इष्टतम मिलान पाया जा सके, एक भविष्यवाणी की जा सके। इस कारण से, इस विधि को विजेता के रूप में भी जाना जाता है।
k-Nearest Neighbour (kNN) Learning Vector Quantization (LVQ) Self-Organizing Map (SOM)
- #### Regularization Methods
यह अन्य विधियों का एक विस्तार है (आमतौर पर एक रिग्रेशन विधि), जो कि सरल मॉडल के लिए अधिक अनुकूल है और अधिक अच्छा है। मैं इसे यहां सूचीबद्ध करता हूं क्योंकि यह लोकप्रिय और शक्तिशाली है।
Ridge Regression Least Absolute Shrinkage and Selection Operator (LASSO) Elastic Net
- #### Decision Tree Learning
Decision tree methods (निर्णय वृक्ष विधियाँ) एक मॉडल बनाते हैं जो डेटा में वास्तविक मानों के आधार पर निर्णय लेता है। निर्णय वृक्षों का उपयोग समावेशन और रिटर्न समस्याओं को हल करने के लिए किया जाता है।
Classification and Regression Tree (CART) Iterative Dichotomiser 3 (ID3) C4.5 Chi-squared Automatic Interaction Detection (CHAID) Decision Stump Random Forest Multivariate Adaptive Regression Splines (MARS) Gradient Boosting Machines (GBM)
- #### Bayesian
Bayesian method वर्गीकरण और प्रतिगमन की समस्याओं को हल करने के लिए Bayesian विधि का प्रयोग किया जाता है।
Naive Bayes Averaged One-Dependence Estimators (AODE) Bayesian Belief Network (BBN)
- #### Kernel Methods
Kernel Method में से सबसे प्रसिद्ध Support Vector Machines है। यह विधि इनपुट डेटा को उच्च आयामों पर मैप करती है, कुछ वर्गीकरण और प्रतिगमन समस्याओं को मॉडलिंग करना आसान है।
Support Vector Machines (SVM) Radial Basis Function (RBF) Linear Discriminate Analysis (LDA)
- #### Clustering Methods
Clustering, अपने आप में एक समस्या और एक विधि है। Clustering के तरीकों को आमतौर पर मॉडलिंग विधियों द्वारा वर्गीकृत किया जाता है। सभी clustering विधियों को डेटा को एक समान डेटा संरचना के साथ व्यवस्थित किया जाता है ताकि प्रत्येक समूह में अधिकतम समानता हो।
K-Means Expectation Maximisation (EM)
- #### Association Rule Learning
एसोसिएशन नियम सीखना (Association rule learning) डेटा के बीच नियमों को निकालने का एक तरीका है, जिसके माध्यम से विशाल बहुआयामी स्थानिक डेटा के बीच संबंध पाए जा सकते हैं, और ये महत्वपूर्ण संबंध संगठन द्वारा उपयोग किए जा सकते हैं।
Apriori algorithm Eclat algorithm
- #### Artificial Neural Networks
आर्टिफिशियल न्यूरल नेटवर्क्स की संरचना और कार्यशीलता जैविक न्यूरल नेटवर्क से प्रेरित है। यह एक प्रकार का पैटर्न मिलान है, जिसे अक्सर रिग्रेशन और वर्गीकरण की समस्याओं के लिए उपयोग किया जाता है, लेकिन इसमें सैकड़ों एल्गोरिदम और वेरिएंट शामिल हैं। इनमें से कुछ क्लासिक लोकप्रिय एल्गोरिदम हैं (मैं गहराई से सीखने को अलग से बताता हूं):
Perceptron Back-Propagation Hopfield Network Self-Organizing Map (SOM) Learning Vector Quantization (LVQ)
- #### Deep Learning
डीप लर्निंग (Deep Learning) पद्धति कृत्रिम तंत्रिका नेटवर्क का एक आधुनिक अद्यतन है। इसमें पारंपरिक तंत्रिका नेटवर्क की तुलना में अधिक और अधिक जटिल नेटवर्क संरचनाएं हैं। कई विधियां अर्ध-निगरानी वाले सीखने के बारे में हैं, इस प्रकार के सीखने की समस्या में बहुत बड़ा डेटा है, लेकिन इनमें से बहुत कम डेटा को चिह्नित किया गया है।
Restricted Boltzmann Machine (RBM) Deep Belief Networks (DBN) Convolutional Network Stacked Auto-encoders
- #### Dimensionality Reduction
आयामीकरण (Dimension Reduction), जैसे कि समूहकरण विधि, डेटा में एक एकीकृत संरचना का पीछा करती है और इसका उपयोग करती है, लेकिन यह कम जानकारी के साथ डेटा को संक्षेप में प्रस्तुत करती है। यह डेटा की कल्पना करने या इसे सरल बनाने के लिए उपयोगी है।
Principal Component Analysis (PCA) Partial Least Squares Regression (PLS) Sammon Mapping Multidimensional Scaling (MDS) Projection Pursuit
- #### Ensemble Methods
Ensemble methods कई छोटे मॉडल होते हैं, जो स्वतंत्र रूप से प्रशिक्षित होते हैं, स्वतंत्र निष्कर्ष निकालते हैं, और अंत में एक समग्र भविष्यवाणी बनाते हैं। बहुत सारे शोध इस बात पर केंद्रित हैं कि कौन से मॉडल का उपयोग किया जाता है और ये मॉडल कैसे एकत्र किए जाते हैं। यह एक बहुत ही शक्तिशाली और लोकप्रिय तकनीक है।
Boosting Bootstrapped Aggregation (Bagging) AdaBoost Stacked Generalization (blending) Gradient Boosting Machines (GBM) Random Forest
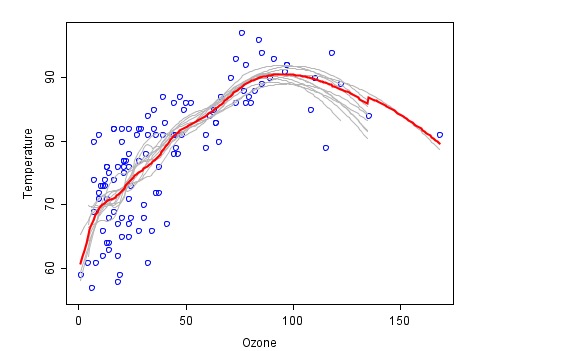
यह एक उदाहरण है जो संयोजन विधि द्वारा संकलित किया गया है (विकिपीडिया से) प्रत्येक अग्निशमन विधि को ग्रे रंग में दर्शाया गया है और अंतिम संश्लेषण का अंतिम पूर्वानुमान लाल रंग में दर्शाया गया है।
- #### अन्य संसाधन
इस मशीन लर्निंग एल्गोरिथ्म टूर का उद्देश्य आपको कुछ एल्गोरिदम और संबंधित एल्गोरिदम के कुछ टूल के बारे में जानकारी देना है।
नीचे कुछ अन्य संसाधन दिए गए हैं, कृपया ज्यादा मत सोचो, अधिक एल्गोरिदम जानने से आपको लाभ होगा, लेकिन कुछ एल्गोरिदम के बारे में गहराई से जानना भी उपयोगी हो सकता है।
- List of Machine Learning Algorithms: यह विकिपीडिया पर एक संसाधन है, हालांकि यह पूर्ण है, लेकिन मुझे लगता है कि वर्गीकरण बहुत अच्छा नहीं है।
- Machine Learning Algorithms Category: यह भी विकी पर है, ऊपर की तुलना में थोड़ा बेहतर है, वर्णमाला क्रम में
- CRAN Task View: Machine Learning & Statistical Learning: मशीन लर्निंग एल्गोरिदम के लिए R भाषा का विस्तार पैकेज, देखें कि आप दूसरों के साथ क्या कर रहे हैं।
- Top 10 Algorithms in Data Mining: यह एक प्रकाशित लेख है, जो अब एक पुस्तक है, जिसमें सबसे लोकप्रिय डेटा खनन एल्गोरिदम शामिल हैं।
ब्लेयर कॉमन्स / डेफी पायथन डेवलपर्स द्वारा पुनः प्रकाशित