रैंडम टिकर जनरेटर पर आधारित रणनीति परीक्षण पद्धति पर चर्चा
लेखक:FMZ~Lydia, बनाया गयाः 2024-12-02 11:26:13, अद्यतनः 2024-12-02 21:39:39
प्रस्तावना
एफएमजेड क्वांट ट्रेडिंग प्लेटफ़ॉर्म का बैकटेस्टिंग सिस्टम एक बैकटेस्टिंग सिस्टम है जो लगातार पुनरावृत्ति, अद्यतन और उन्नयन कर रहा है। यह प्रारंभिक बुनियादी बैकटेस्टिंग फ़ंक्शन से कार्यों को जोड़ता है और प्रदर्शन को धीरे-धीरे अनुकूलित करता है। प्लेटफ़ॉर्म के विकास के साथ, बैकटेस्टिंग सिस्टम को अनुकूलित और अपग्रेड किया जाना जारी रहेगा। आज हम बैकटेस्टिंग सिस्टम पर आधारित एक विषय पर चर्चा करेंगेः
मांग
मात्रात्मक व्यापार के क्षेत्र में, रणनीतियों के विकास और अनुकूलन को वास्तविक बाजार डेटा के सत्यापन से अलग नहीं किया जा सकता है। हालांकि, वास्तविक अनुप्रयोगों में, जटिल और बदलते बाजार वातावरण के कारण, बैकटेस्टिंग के लिए ऐतिहासिक डेटा पर भरोसा करना अपर्याप्त हो सकता है, जैसे कि चरम बाजार स्थितियों या विशेष परिदृश्यों की कवरेज की कमी। इसलिए, एक कुशल यादृच्छिक बाजार जनरेटर का डिजाइन मात्रात्मक रणनीति डेवलपर्स के लिए एक प्रभावी उपकरण बन गया है।
जब हमें रणनीति को एक निश्चित एक्सचेंज या मुद्रा पर ऐतिहासिक डेटा का पता लगाने की आवश्यकता होती है, तो हम बैकटेस्टिंग के लिए एफएमजेड प्लेटफॉर्म के आधिकारिक डेटा स्रोत का उपयोग कर सकते हैं। कभी-कभी हम यह भी देखना चाहते हैं कि रणनीति पूरी तरह से अपरिचित बाजार में कैसे प्रदर्शन करती है, ताकि हम रणनीति का परीक्षण करने के लिए कुछ डेटा बना सकें।
यादृच्छिक टिकर डेटा का उपयोग करने का महत्व हैः
-
- रणनीतियों की मजबूती का आकलन करें रैंडम टिकर जनरेटर विभिन्न संभावित बाजार परिदृश्यों को बना सकता है, जिसमें चरम अस्थिरता, कम अस्थिरता, ट्रेंडिंग बाजार और अस्थिर बाजार शामिल हैं। इन अनुकरणीय वातावरणों में परीक्षण रणनीतियाँ यह मूल्यांकन करने में मदद कर सकती हैं कि क्या उनका प्रदर्शन विभिन्न बाजार स्थितियों में स्थिर है। उदाहरण के लिएः
क्या रणनीति प्रवृत्ति और अस्थिरता में बदलाव के अनुकूल हो सकती है? क्या चरम बाजार स्थितियों में रणनीति में बड़ा नुकसान होगा?
-
- रणनीति में संभावित कमजोरियों की पहचान करें कुछ असामान्य बाजार स्थितियों (जैसे काल्पनिक ब्लैक स्वान घटनाओं) का अनुकरण करके, रणनीति में संभावित कमजोरियों की खोज और सुधार किया जा सकता है। उदाहरण के लिएः
क्या रणनीति एक निश्चित बाजार संरचना पर बहुत अधिक निर्भर करती है? क्या मापदंडों को ओवरफिट करने का खतरा है?
-
- रणनीति मापदंडों का अनुकूलन यादृच्छिक रूप से उत्पन्न डेटा रणनीति पैरामीटर अनुकूलन के लिए एक अधिक विविध परीक्षण वातावरण प्रदान करता है, बिना पूरी तरह से ऐतिहासिक डेटा पर भरोसा किए। यह आपको रणनीति के पैरामीटर रेंज को अधिक व्यापक रूप से खोजने की अनुमति देता है और ऐतिहासिक डेटा में विशिष्ट बाजार पैटर्न तक सीमित होने से बचता है।
-
- ऐतिहासिक आंकड़ों में अंतर को भरना कुछ बाजारों (जैसे उभरते बाजार या छोटे मुद्रा व्यापार बाजार) में, सभी संभावित बाजार स्थितियों को कवर करने के लिए ऐतिहासिक डेटा पर्याप्त नहीं हो सकता है। यादृच्छिक टिकर जनरेटर अधिक व्यापक परीक्षण करने में मदद करने के लिए बड़ी मात्रा में पूरक डेटा प्रदान कर सकता है।
-
- तेजी से पुनरावर्ती विकास रैपिड टेस्टिंग के लिए यादृच्छिक डेटा का उपयोग वास्तविक समय के बाजार टिकर स्थितियों या समय लेने वाली डेटा सफाई और संगठन पर भरोसा किए बिना रणनीति विकास के पुनरावृत्ति को तेज कर सकता है।
हालांकि, रणनीति का तर्कसंगत मूल्यांकन करना भी आवश्यक है। यादृच्छिक रूप से उत्पन्न टिकर डेटा के लिए, कृपया ध्यान देंः
-
- यद्यपि यादृच्छिक बाजार जनरेटर उपयोगी हैं, लेकिन उनका महत्व उत्पन्न डेटा की गुणवत्ता और लक्ष्य परिदृश्य के डिजाइन पर निर्भर करता हैः
-
- जनरेशन लॉजिक को वास्तविक बाजार के करीब होने की आवश्यकता हैः यदि यादृच्छिक रूप से उत्पन्न बाजार वास्तविकता से पूरी तरह से संपर्क में नहीं है, तो परीक्षण परिणामों में संदर्भ मूल्य की कमी हो सकती है। उदाहरण के लिए, जनरेटर को वास्तविक बाजार सांख्यिकीय विशेषताओं (जैसे अस्थिरता वितरण, प्रवृत्ति अनुपात) के आधार पर डिज़ाइन किया जा सकता है।
-
- यह वास्तविक डेटा परीक्षण को पूरी तरह से प्रतिस्थापित नहीं कर सकता है: यादृच्छिक डेटा केवल रणनीतियों के विकास और अनुकूलन का पूरक हो सकता है। अंतिम रणनीति को अभी भी वास्तविक बाजार डेटा में इसकी प्रभावशीलता के लिए सत्यापित करने की आवश्यकता है।
इतना कहकर, हम कुछ डेटा कैसे बना सकते हैं? हम बैकटेस्टिंग प्रणाली के लिए डेटा कैसे बना सकते हैं ताकि इसे आसानी से, जल्दी और आसानी से इस्तेमाल किया जा सके?
डिजाइन विचार
यह लेख चर्चा के लिए एक प्रारंभिक बिंदु प्रदान करने के लिए डिज़ाइन किया गया है और अपेक्षाकृत सरल यादृच्छिक टिकर पीढ़ी गणना प्रदान करता है। वास्तव में, विभिन्न प्रकार के सिमुलेशन एल्गोरिदम, डेटा मॉडल और अन्य प्रौद्योगिकियां हैं जिन्हें लागू किया जा सकता है। चर्चा के सीमित स्थान के कारण, हम जटिल डेटा सिमुलेशन विधियों का उपयोग नहीं करेंगे।
प्लेटफ़ॉर्म बैकटेस्टिंग सिस्टम के कस्टम डेटा स्रोत फ़ंक्शन को मिलाकर, हमने पायथन में एक प्रोग्राम लिखा।
-
- के-लाइन डेटा का एक सेट यादृच्छिक रूप से उत्पन्न करें और उन्हें निरंतर रिकॉर्डिंग के लिए एक सीएसवी फ़ाइल में लिखें, ताकि उत्पन्न डेटा को सहेजा जा सके।
-
- फिर बैकटेस्टिंग प्रणाली के लिए डेटा स्रोत समर्थन प्रदान करने के लिए एक सेवा बनाएँ।
-
- चार्ट में उत्पन्न K-लाइन डेटा प्रदर्शित करें।
के-लाइन डेटा के कुछ पीढ़ी मानकों और फ़ाइल भंडारण के लिए निम्नलिखित पैरामीटर नियंत्रण परिभाषित किए जा सकते हैंः
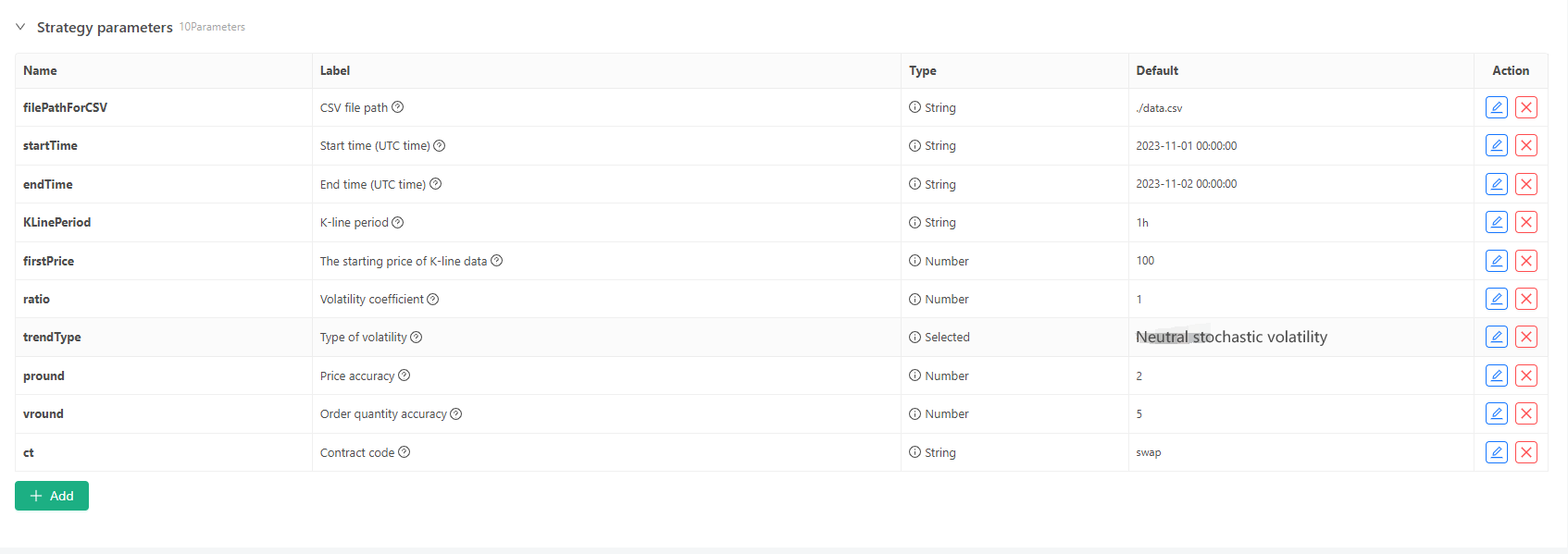
-
यादृच्छिक डेटा जनरेशन मोड के-लाइन डेटा के उतार-चढ़ाव प्रकार के अनुकरण के लिए, सकारात्मक और नकारात्मक यादृच्छिक संख्याओं की संभावना का उपयोग करके एक सरल डिजाइन बनाया जाता है। जब उत्पन्न डेटा बहुत अधिक नहीं होता है, तो यह आवश्यक बाजार पैटर्न को प्रतिबिंबित नहीं कर सकता है। यदि कोई बेहतर विधि है, तो कोड के इस हिस्से को प्रतिस्थापित किया जा सकता है। इस सरल डिजाइन के आधार पर, यादृच्छिक संख्या जनरेशन रेंज और कोड में कुछ गुणांक को समायोजित करने से उत्पन्न डेटा प्रभाव प्रभावित हो सकता है।
-
डेटा सत्यापन उत्पन्न के-लाइन डेटा को तर्कसंगतता के लिए भी परीक्षण करने की आवश्यकता है, यह जांचने के लिए कि क्या उच्च उद्घाटन और निम्न समापन मूल्य परिभाषा का उल्लंघन करते हैं, और के-लाइन डेटा की निरंतरता की जांच करने के लिए।
बैकटेस्टिंग सिस्टम रैंडम टिकर जनरेटर
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
बैकटेस्टिंग प्रणाली में अभ्यास
- उपरोक्त रणनीति उदाहरण बनाएँ, पैरामीटर कॉन्फ़िगर करें, और इसे चलाएँ.
- लाइव ट्रेडिंग (स्ट्रैटेजी इंस्टेंस) को सर्वर पर तैनात डॉकर पर चलाने की आवश्यकता है, इसे सार्वजनिक नेटवर्क आईपी की आवश्यकता है, ताकि बैकटेस्टिंग सिस्टम इसे एक्सेस कर सके और डेटा प्राप्त कर सके।
- बातचीत बटन पर क्लिक करें, और रणनीति स्वचालित रूप से यादृच्छिक टिकर डेटा उत्पन्न करना शुरू कर देगा।
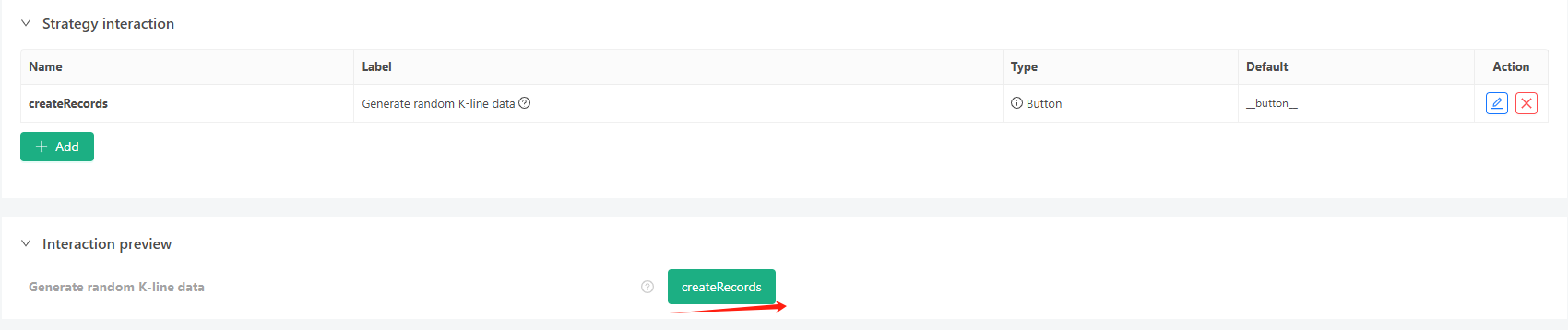
- उत्पन्न डेटा को आसानी से देखने के लिए चार्ट पर प्रदर्शित किया जाएगा, और डेटा स्थानीय data.csv फ़ाइल में दर्ज किया जाएगा।
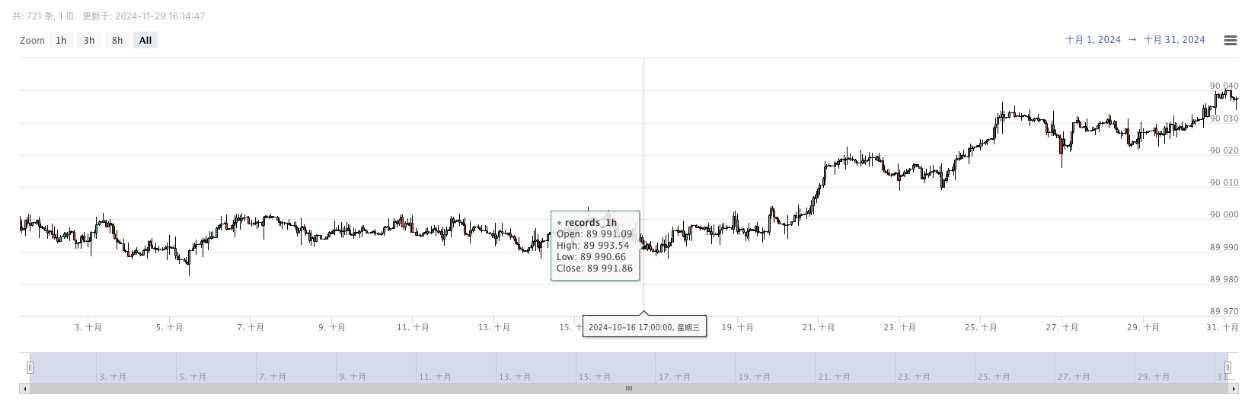
- अब हम इस यादृच्छिक रूप से उत्पन्न डेटा का उपयोग कर सकते हैं और बैकटेस्टिंग के लिए किसी भी रणनीति का उपयोग कर सकते हैंः

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
उपरोक्त जानकारी के अनुसार, कॉन्फ़िगर करें और समायोजित करें।http://xxx.xxx.xxx.xxx:9090सर्वर का आईपी पता और यादृच्छिक टिकर जनरेशन रणनीति का खुला पोर्ट है.
यह कस्टम डेटा स्रोत है, जिसे प्लेटफ़ॉर्म एपीआई दस्तावेज़ के कस्टम डेटा स्रोत अनुभाग में पाया जा सकता है.
- बैकटेस्ट सिस्टम डेटा स्रोत सेट करने के बाद, हम यादृच्छिक बाजार डेटा का परीक्षण कर सकते हैंः
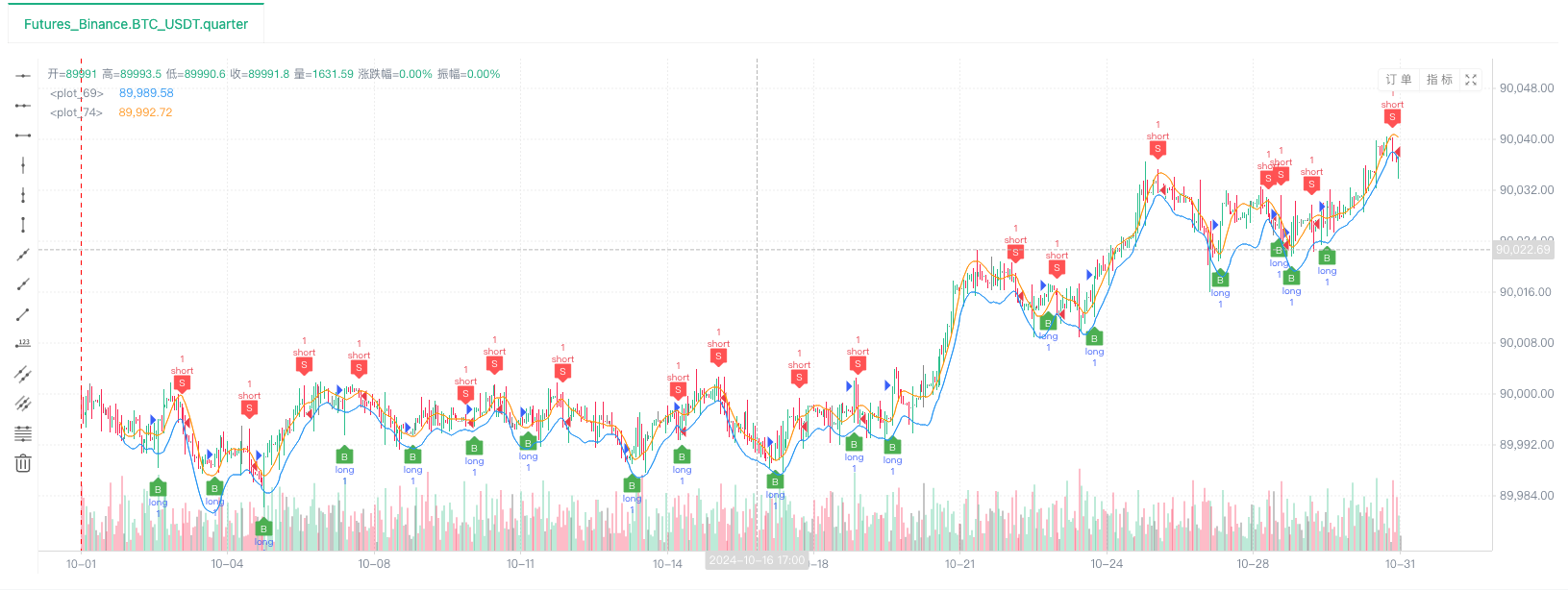
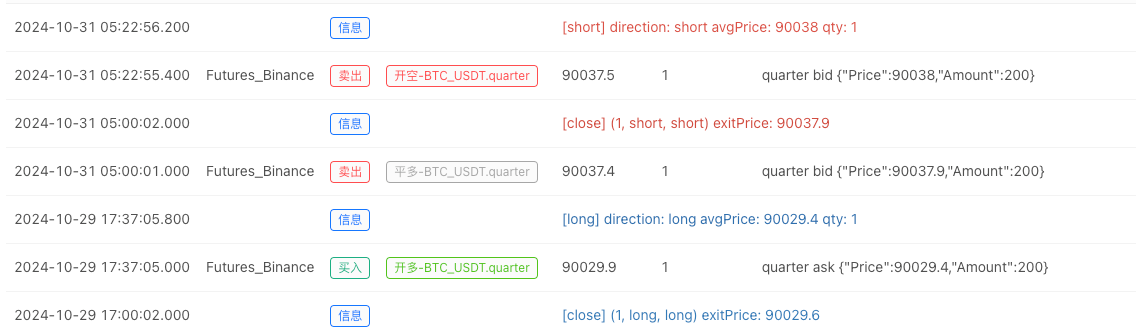
इस समय, बैकटेस्ट सिस्टम का परीक्षण हमारे
- ओह, हाँ, मैं लगभग यह उल्लेख करना भूल गया! कारण है कि इस पायथन कार्यक्रम के यादृच्छिक टिकर जनरेटर बनाता है एक लाइव व्यापार के प्रदर्शन, संचालन, और सुविधाजनक बनाने के लिए है, और प्रदर्शन के लिए K-लाइन डेटा. वास्तविक आवेदन में, आप एक स्वतंत्र पायथन स्क्रिप्ट लिख सकते हैं, तो आप नहीं है चलाने के लिए लाइव व्यापार.
रणनीति स्रोत कोडःबैकटेस्टिंग सिस्टम रैंडम टिकर जनरेटर
आपके समर्थन और पढ़ने के लिए धन्यवाद।
- DEX एक्सचेंज क्वांटिफाइड प्रैक्टिस ((1)-- dYdX v4 उपयोग गाइड
- डिजिटल मुद्रा में लीड-लैग सूट का परिचय (3)
- क्रिप्टोकरेंसी में लीड-लैग आर्बिट्रेज का परिचय (2)
- डिजिटल मुद्राओं में लीड-लैग सूट का परिचय (2)
- एफएमजेड प्लेटफॉर्म के बाहरी सिग्नल रिसेप्शन पर चर्चाः रणनीति में अंतर्निहित एचटीपी सेवा के साथ सिग्नल प्राप्त करने के लिए एक पूर्ण समाधान
- एफएमजेड प्लेटफॉर्म के लिए बाहरी सिग्नल प्राप्त करने का अन्वेषणः रणनीति अंतर्निहित एचटीटीपी सेवा के लिए सिग्नल प्राप्त करने के लिए पूर्ण समाधान
- क्रिप्टोकरेंसी में लीड-लैग आर्बिट्रेज का परिचय (1)
- डिजिटल मुद्रा में लीड-लैग सूट का परिचय (1)
- एफएमजेड प्लेटफॉर्म के बाहरी सिग्नल रिसेप्शन पर चर्चाः विस्तारित एपीआई बनाम रणनीति अंतर्निहित एचटीटीपी सेवा
- एफएमजेड प्लेटफॉर्म के लिए बाहरी संकेत प्राप्त करने की खोजः विस्तार एपीआई बनाम रणनीति अंतर्निहित एचटीटीपी सेवा
- यादृच्छिक बाजार जनरेटर पर आधारित रणनीति परीक्षण के तरीकों का पता लगाना
- एफएमजेड क्वांट की नई विशेषताः आसानी से HTTP सेवाएँ बनाने के लिए _Serve फ़ंक्शन का प्रयोग करें
- आविष्कारकों ने नई सुविधाओं को मापाः _Serve फ़ंक्शन का उपयोग करके आसानी से HTTP सेवाएं बनाएं
- FMZ क्वांट ट्रेडिंग प्लेटफॉर्म कस्टम प्रोटोकॉल एक्सेस गाइड
- एफएमजेड फंडिंग रेट अधिग्रहण और निगरानी रणनीति
- एफएमजेड के लिए धनराशि प्राप्त करने और निगरानी के लिए रणनीति
- एक रणनीति टेम्पलेट आपको वेबसॉकेट मार्केट का उपयोग करने की अनुमति देता है
- एक नीति टेम्पलेट जो आपको वेबसॉकेट के क्षेत्र का उपयोग करने के लिए अनुमति देता है
- आविष्कारकों के लिए क्वांटिफाइड ट्रेडिंग प्लेटफॉर्म के लिए सामान्य प्रोटोकॉल एक्सेस गाइड
- एफएमजेड उन्नयन के बाद एक सार्वभौमिक बहु-मुद्रा व्यापार रणनीति कैसे बनाएं