क्रिप्टोकरेंसी फैक्टर मॉडल
 12
12173
12
12173
[TOC]

फैक्टर मॉडल ढांचा
शेयर बाजार के बहु-कारक मॉडल पर कई शोध रिपोर्टें उपलब्ध हैं, जिनमें समृद्ध सिद्धांत और व्यवहार शामिल हैं। डिजिटल मुद्रा बाजार मुद्राओं की संख्या, कुल बाजार मूल्य, लेनदेन की मात्रा और डेरिवेटिव बाजार के संदर्भ में कारक अनुसंधान के लिए पर्याप्त है। यह लेख मुख्य रूप से मात्रात्मक रणनीतियों के शुरुआती लोगों के लिए है और इसमें जटिल गणितीय सिद्धांत और सांख्यिकीय विश्लेषण शामिल नहीं होंगे। वायदा बाजार को डेटा स्रोत के रूप में उपयोग करते हुए, कारक संकेतकों के मूल्यांकन को सुविधाजनक बनाने के लिए एक सरल कारक अनुसंधान ढांचे का निर्माण किया जाता है।
फैक्टर को एक संकेतक के रूप में देखा जा सकता है और इसे एक अभिव्यक्ति के रूप में लिखा जा सकता है। फैक्टर लगातार बदलते रहते हैं और भविष्य के रिटर्न की जानकारी को दर्शाते हैं। आमतौर पर, फैक्टर एक निवेश तर्क का प्रतिनिधित्व करते हैं।
उदाहरण के लिए, समापन मूल्य कारक इस धारणा पर आधारित है कि स्टॉक की कीमतें भविष्य के रिटर्न की भविष्यवाणी कर सकती हैं। स्टॉक की कीमत जितनी अधिक होगी, भविष्य का रिटर्न उतना ही अधिक होगा (या रिटर्न उतना ही कम होगा)। इस कारक के आधार पर पोर्टफोलियो बनाना वास्तव में एक निवेश है उच्च मूल्य वाले स्टॉक खरीदने के लिए नियमित रूप से स्थिति बदलने का मॉडल/रणनीति। सामान्यतः, ऐसे कारक जो लगातार अतिरिक्त रिटर्न उत्पन्न कर सकते हैं, उन्हें अक्सर अल्फा कहा जाता है। उदाहरण के लिए, बाजार पूंजीकरण कारक और गति कारक को अकादमिक जगत और निवेश समुदाय द्वारा प्रभावी कारक के रूप में सत्यापित किया गया है।
चाहे वह शेयर बाजार हो या डिजिटल मुद्रा बाजार, यह एक जटिल प्रणाली है। कोई भी कारक भविष्य के रिटर्न की पूरी तरह से भविष्यवाणी नहीं कर सकता है, लेकिन फिर भी इसमें कुछ हद तक पूर्वानुमान की संभावना है। जैसे-जैसे अधिक धनराशि का निवेश होता है, प्रभावी अल्फा (निवेश मॉडल) धीरे-धीरे अप्रभावी हो जाता है। लेकिन इस प्रक्रिया से बाजार में अन्य मॉडल उत्पन्न होंगे, जिससे नए अल्फाज़ का जन्म होगा। बाजार पूंजीकरण कारक एक समय में ए-शेयर बाजार में एक बहुत ही प्रभावी रणनीति थी। बस सबसे कम बाजार पूंजीकरण वाले 10 शेयर खरीदें और उन्हें दिन में एक बार समायोजित करें। 2007 से दस साल का बैकटेस्ट 400 गुना से अधिक रिटर्न अर्जित करेगा, अब तक समग्र बाजार से अधिक.. हालांकि, 2017 में ब्लू-चिप शेयर बाजार में छोटे बाजार पूंजीकरण कारक की अप्रभावीता परिलक्षित हुई, जबकि इसके बजाय मूल्य कारक लोकप्रिय हो गया। इसलिए, अल्फा के सत्यापन और उपयोग के बीच लगातार संतुलन और प्रयोग करना आवश्यक है।
हम जिन कारकों की तलाश कर रहे हैं, वे रणनीति बनाने का आधार हैं। कई असंबंधित प्रभावी कारकों को मिलाकर बेहतर रणनीति बनाई जा सकती है।
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
डेटा स्रोत
अब तक, 2022 की शुरुआत से लेकर वर्तमान तक Binance USDT सदा वायदा का प्रति घंटा K-लाइन डेटा 150 मुद्राओं को पार कर गया है। जैसा कि पहले बताया गया है, कारक मॉडल एक मुद्रा चयन मॉडल है जो किसी विशिष्ट मुद्रा के बजाय सभी मुद्राओं को लक्षित करता है। के-लाइन डेटा में उच्च आरंभिक और निम्न समापन मूल्य, ट्रेडिंग वॉल्यूम, लेन-देन की संख्या, सक्रिय खरीद वॉल्यूम आदि जैसे डेटा शामिल होते हैं। ये डेटा निश्चित रूप से सभी कारकों का स्रोत नहीं हैं, जैसे कि अमेरिकी स्टॉक इंडेक्स, ब्याज दर वृद्धि की उम्मीदें , लाभप्रदता, ऑन-चेन डेटा, सोशल मीडिया का ध्यान, आदि। कम लोकप्रिय डेटा स्रोत भी प्रभावी अल्फा को प्रकट कर सकते हैं, लेकिन बुनियादी मात्रा और मूल्य डेटा भी पर्याप्त हैं।
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
Out:
153
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
हम प्रारंभ में के-लाइन डेटा से रुचि के डेटा निकालते हैं: समापन मूल्य, प्रारंभिक मूल्य, ट्रेडिंग वॉल्यूम, लेनदेन की संख्या और सक्रिय खरीद अनुपात, और आवश्यक कारकों को संसाधित करने के लिए आधार के रूप में इन डेटा का उपयोग करते हैं।
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
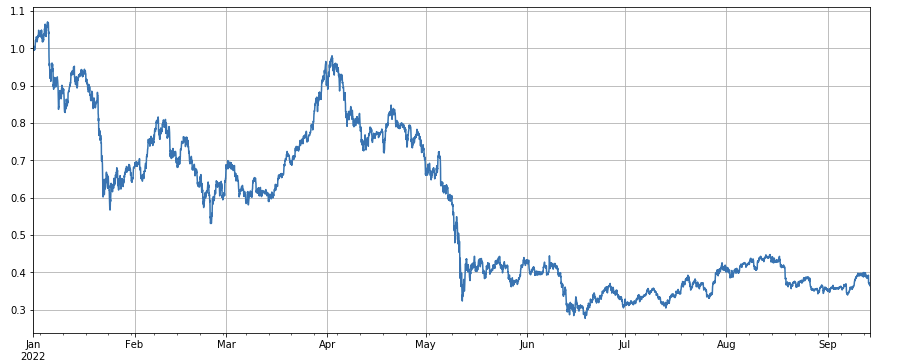
बाजार सूचकांक के प्रदर्शन को देखते हुए, इसे काफी निराशाजनक कहा जा सकता है, जिसमें वर्ष की शुरुआत से 60% की गिरावट आई है।
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
कारक वैधता निर्धारण
प्रतिगमन विधि अगली अवधि की वापसी की दर को आश्रित चर के रूप में लिया जाता है, परीक्षण किए जाने वाले कारक को स्वतंत्र चर के रूप में लिया जाता है, और प्रतिगमन द्वारा प्राप्त गुणांक कारक की वापसी की दर होती है। प्रतिगमन समीकरण के निर्माण के बाद, हम आम तौर पर गुणांक टी मूल्य के पूर्ण माध्य, गुणांक टी मूल्य के पूर्ण मूल्य अनुक्रम का अनुपात 2 से अधिक, वार्षिक कारक रिटर्न, वार्षिक कारक रिटर्न अस्थिरता, शार्प अनुपात का उल्लेख करते हैं कारक प्रतिफल और अन्य पैरामीटर। कारक प्रभावशीलता और अस्थिरता। आप एक साथ कई कारकों को पुनः प्राप्त कर सकते हैं, विवरण के लिए बारा दस्तावेज़ देखें।
आईसी, आईआर और अन्य संकेतक तथाकथित IC कारक और अगली अवधि की वापसी की दर के बीच सहसंबंध गुणांक है। RANK_IC का उपयोग अब आम तौर पर किया जाता है, जो कारक रैंकिंग और अगली अवधि की स्टॉक वापसी की दर के बीच सहसंबंध गुणांक है। आईआर सामान्यतः आईसी अनुक्रम का माध्य/आईसी अनुक्रम का मानक विचलन होता है।
पदानुक्रमित प्रतिगमन यह लेख इस पद्धति का उपयोग करेगा, जिसमें परीक्षण किए जाने वाले कारकों को क्रमबद्ध करना, समूह बैकटेस्टिंग के लिए मुद्राओं को N समूहों में विभाजित करना, और पदों को समायोजित करने के लिए एक निश्चित अवधि का उपयोग करना शामिल है। यदि स्थिति आदर्श है, तो मुद्राओं के N समूहों की पैदावार अच्छी एकरसता दर्शाएगी, एकरसतापूर्वक बढ़ेगी या घटेगी, तथा प्रत्येक समूह के बीच पैदावार का अंतर बड़ा होगा। ऐसे कारक बेहतर भेदभाव में परिलक्षित होते हैं। यदि पहले समूह में सबसे अधिक रिटर्न है और अंतिम समूह में सबसे कम रिटर्न है, तो पहले समूह पर लॉन्ग और अंतिम समूह पर शॉर्ट करें। रिटर्न की अंतिम दर शार्प अनुपात का संदर्भ संकेतक है।
वास्तविक बैकटेस्टिंग ऑपरेशन
कारकों के अनुसार, चयनित मुद्राओं को छोटे से बड़े तक के वर्गीकरण के अनुसार 3 समूहों में विभाजित किया जाता है। मुद्राओं के प्रत्येक समूह का लगभग 1⁄3 हिस्सा होता है। यदि कोई कारक प्रभावी है, तो प्रत्येक समूह का अनुपात जितना छोटा होगा, उतना ही अधिक होगा उपज, लेकिन इसका मतलब यह भी है कि प्रत्येक मुद्रा को आवंटित धन अपेक्षाकृत बड़ा है। यदि लंबी और छोटी स्थितियाँ प्रत्येक 1x लीवरेज्ड हैं, और पहला और अंतिम समूह क्रमशः 10 मुद्राएँ हैं, तो प्रत्येक का 10% हिस्सा है। यदि कोई मुद्रा है शॉर्टेड राइज, यदि निवेश की राशि 2 गुना बढ़ जाती है, तो रिट्रेसमेंट 20% होगा; तदनुसार, यदि समूहों की संख्या 50 है, तो रिट्रेसमेंट 4% होगा। मुद्राओं में विविधता लाने से ब्लैक स्वान्स का जोखिम कम हो सकता है। पहले समूह (सबसे छोटे कारक मान वाले) पर लंबे समय तक निवेश करें और तीसरे समूह पर छोटे समय तक निवेश करें। यदि कारक जितना बड़ा होगा, रिटर्न भी उतना ही अधिक होगा, तो आप लंबी और छोटी स्थिति को उलट सकते हैं या कारक को नकारात्मक या व्युत्क्रम बना सकते हैं।
किसी कारक की पूर्वानुमान क्षमता का आकलन आमतौर पर अंतिम बैकटेस्ट रिटर्न और शार्प अनुपात के आधार पर किया जा सकता है। इसके अलावा, यह भी संदर्भित करना आवश्यक है कि क्या कारक अभिव्यक्ति सरल है, समूहीकरण के आकार के प्रति असंवेदनशील है, स्थिति समायोजन अंतराल के प्रति असंवेदनशील है, बैकटेस्ट के प्रारंभिक समय के प्रति असंवेदनशील है, आदि।
स्थिति समायोजन की आवृत्ति के बारे में, शेयर बाजार में अक्सर 5 दिन, 10 दिन और एक महीने का चक्र होता है, लेकिन डिजिटल मुद्रा बाजार के लिए, ऐसा चक्र निस्संदेह बहुत लंबा है, और वास्तविक बाजार में बाजार की स्थितियों की निगरानी की जाती है। वास्तविक समय में, इसलिए किसी विशिष्ट चक्र पर टिके रहना मुश्किल है। पोजीशन को फिर से एडजस्ट करने की आवश्यकता नहीं है, इसलिए वास्तविक ट्रेडिंग में हम पोजीशन को वास्तविक समय में या कम समय अवधि में एडजस्ट करते हैं।
किसी स्थिति को कैसे बंद किया जाए, इस संबंध में, पारंपरिक विधि के अनुसार, यदि अगली छंटाई के दौरान वह स्थिति समूह में नहीं है, तो आप उसे बंद कर सकते हैं। हालाँकि, वास्तविक समय स्थिति समायोजन के मामले में, कुछ मुद्राएँ विभाजन रेखा पर हो सकती हैं, और स्थितियाँ आगे-पीछे बंद हो सकती हैं। इसलिए, यह रणनीति समूहीकरण परिवर्तनों की प्रतीक्षा करने और विपरीत दिशा में पोजीशन खोलने की आवश्यकता होने पर पोजीशन बंद करने के दृष्टिकोण को अपनाती है। उदाहरण के लिए, यदि आप पहले समूह में लंबे समय तक जाते हैं, जब लंबी स्थिति में मुद्रा को दूसरे में विभाजित किया जाता है। तीसरे समूह में, आप स्थिति को बंद कर सकते हैं और शॉर्ट जा सकते हैं। यदि आप एक निश्चित अवधि पर पोजीशन बंद करते हैं, जैसे कि हर दिन या हर 8 घंटे पर, तो आप समूह में शामिल हुए बिना भी पोजीशन बंद कर सकते हैं। आप और भी प्रयास कर सकते हैं.
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
सरल कारक परीक्षण
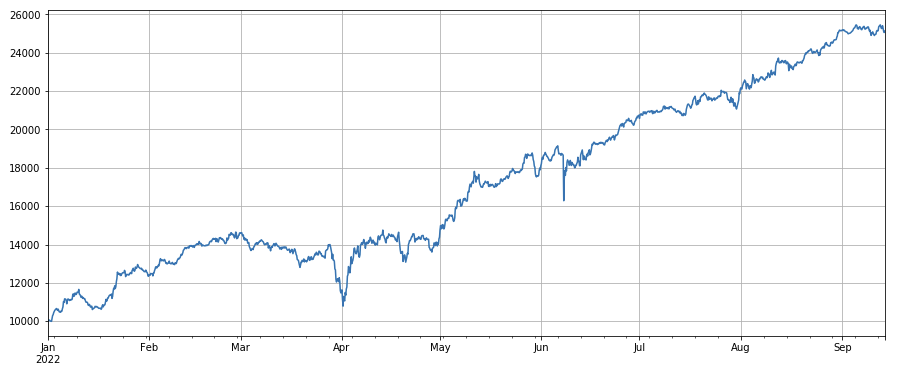
वॉल्यूम फैक्टर: कम वॉल्यूम वाले सिक्कों पर लॉन्ग और अधिक वॉल्यूम वाले सिक्कों पर शॉर्ट करना बहुत अच्छा प्रदर्शन करता है, जो दर्शाता है कि लोकप्रिय सिक्कों के गिरने की संभावना अधिक है।
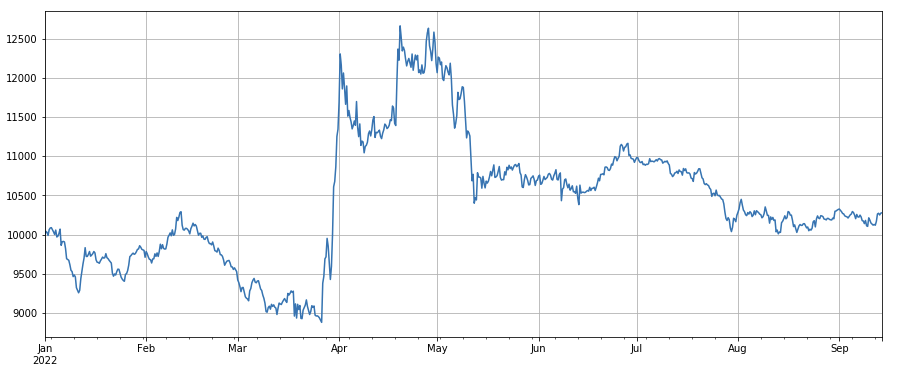
लेन-देन मूल्य कारक: लंबी कम कीमत वाली मुद्राएं, छोटी उच्च कीमत वाली मुद्राएं, प्रभाव औसत है।
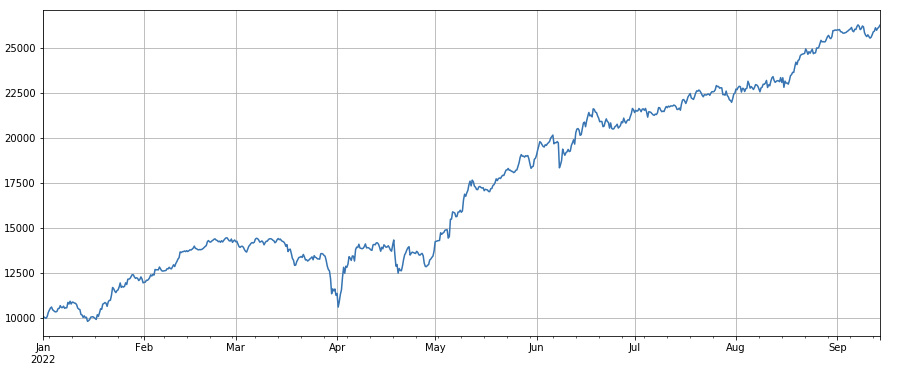
लेन-देन की संख्या कारक: प्रदर्शन मात्रा के बहुत समान है। यह स्पष्ट है कि वॉल्यूम फैक्टर और ट्रांजैक्शन फैक्टर की संख्या के बीच सहसंबंध बहुत अधिक है। वास्तव में, विभिन्न मुद्राओं में उनके बीच औसत सहसंबंध 0.97 है, जो दर्शाता है कि ये दोनों कारक बहुत समान हैं। इस कारक को ध्यान में रखना चाहिए ध्यान में रखें।
3h गति कारक: (df_close - df_close.shift(3))/df_close.shift(3). यानी कारक की 3 घंटे की वृद्धि। बैकटेस्ट के परिणाम बताते हैं कि 3 घंटे की वृद्धि में एक स्पष्ट प्रतिगमन विशेषता है, यानी, अगली अवधि में वृद्धि में गिरावट की अधिक संभावना है। कुल मिलाकर प्रदर्शन अच्छा है, लेकिन इसमें लम्बे समय तक पुलबैक और दोलन की अवधि भी है।
24 घंटे की गति कारक: 24 घंटे के पुनर्संतुलन चक्र के परिणाम बहुत अच्छे हैं, जिनमें रिटर्न 3 घंटे की गति के समान है तथा गिरावट भी कम है।
टर्नओवर परिवर्तन कारक: df_volume.rolling(24).mean() / df_volume.rolling(96).mean(), जो कि सबसे हाल के दिन के टर्नओवर का सबसे हाल के तीन दिनों के टर्नओवर से अनुपात है। स्थिति हर 8 घंटे में समायोजित किया जाता है. बैकटेस्ट के परिणाम अपेक्षाकृत अच्छे हैं और रिट्रेसमेंट अपेक्षाकृत कम है, जो दर्शाता है कि सक्रिय ट्रेडिंग वॉल्यूम वाले शेयरों में गिरावट की संभावना अधिक है।
लेन-देन संख्या परिवर्तन कारक: df_count.rolling(24).mean() / df_count.rolling(96).mean(), जो कि पिछले दिन के लेन-देन की संख्या और पिछले तीन दिनों के लेन-देन की संख्या का अनुपात है . स्थिति हर 8 घंटे में समायोजित की जाती है. बैकटेस्ट के परिणाम अपेक्षाकृत अच्छे हैं और रिट्रेसमेंट अपेक्षाकृत कम है, जो दर्शाता है कि जैसे-जैसे लेनदेन की संख्या बढ़ती है, बाजार में अधिक सक्रिय रूप से गिरावट आती है।
एकल लेनदेन मूल्य परिवर्तन कारक: -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean()) , जो कि सबसे हाल के दिन के लेनदेन मूल्य और सबसे हाल के तीन दिनों के लेनदेन मूल्य का अनुपात है, और स्थिति को हर 8 घंटे में समायोजित किया जाता है। यह कारक आयतन कारक के साथ भी अत्यधिक सहसम्बन्धित है।
सक्रिय लेनदेन अनुपात परिवर्तन कारक: df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean(), अर्थात, लेनदेन के अंतिम दिन में कुल लेनदेन मात्रा के लिए सक्रिय खरीद मात्रा का अनुपात पिछले तीन दिनों में मूल्य, हर 8 घंटे में स्थिति समायोजित करें। यह कारक अच्छा प्रदर्शन करता है और इसका आयतन कारक के साथ बहुत कम सहसम्बन्ध है।
अस्थिरता कारक: (df_close/df_open).rolling(24).std(), जिसका कम अस्थिरता वाली मुद्राओं पर लंबे समय तक चलने पर एक निश्चित प्रभाव पड़ता है।
ट्रेडिंग वॉल्यूम और समापन मूल्य के बीच सहसंबंध कारक: df_close.rolling(96).corr(df_volume), पिछले 4 दिनों में समापन मूल्य और ट्रेडिंग वॉल्यूम के बीच सहसंबंध कारक, समग्र प्रदर्शन अच्छा है।
यहाँ मात्रा और कीमत के आधार पर कुछ कारक सूचीबद्ध हैं। वास्तव में, कारक सूत्रों का संयोजन बहुत जटिल हो सकता है और इसमें स्पष्ट तर्क नहीं हो सकता है। आप प्रसिद्ध ALPHA101 कारक निर्माण विधि का संदर्भ ले सकते हैं: https://github.com/STHSF/alpha101.
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
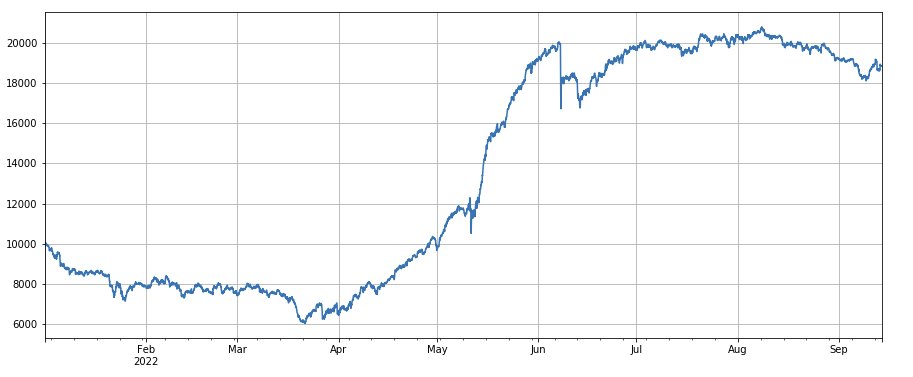
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
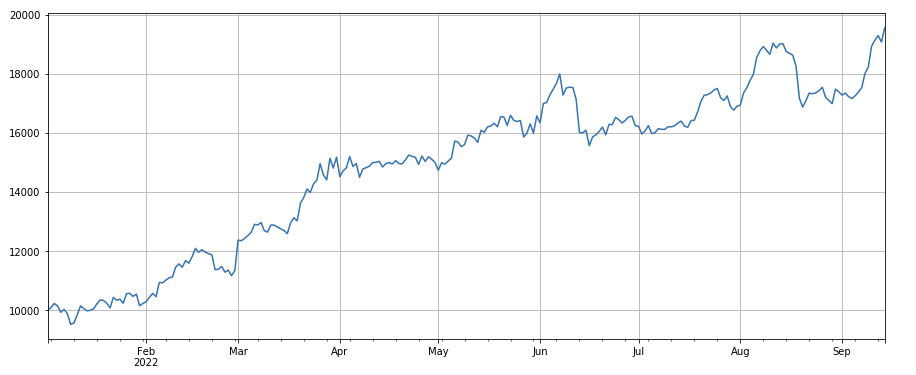
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
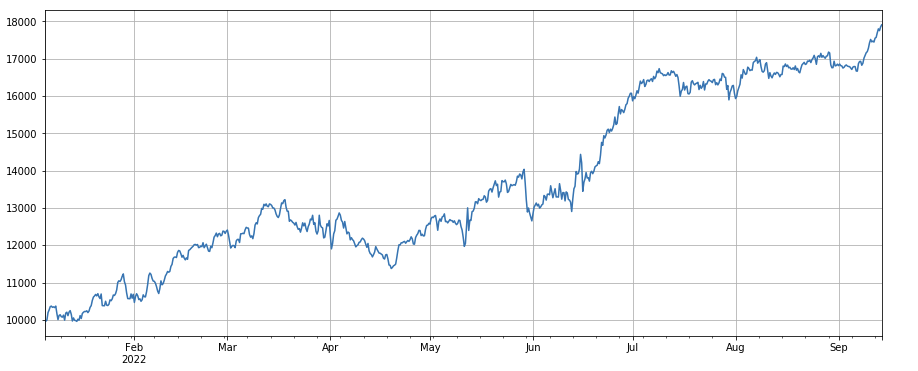
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
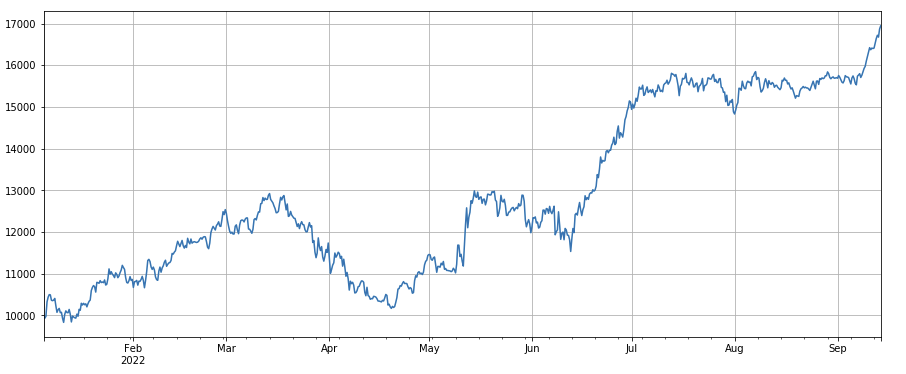
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
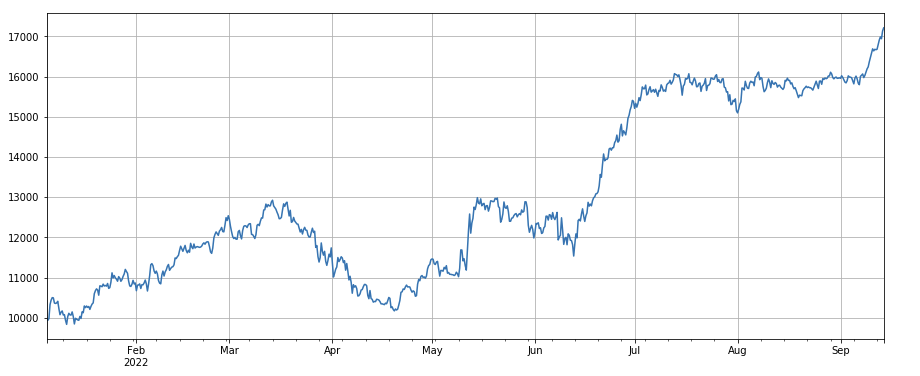
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
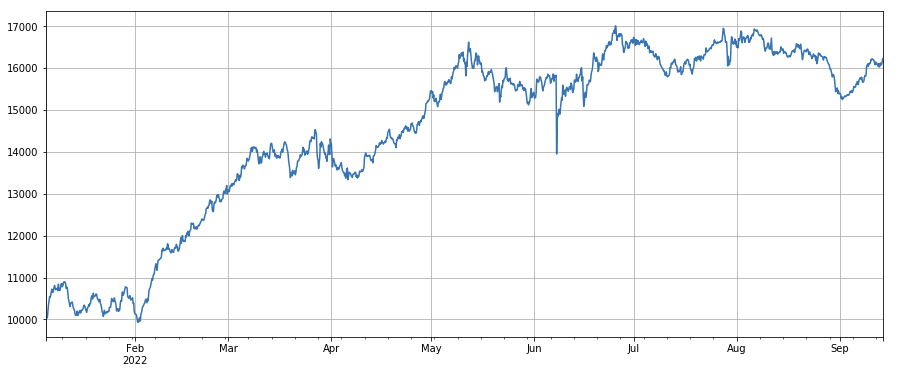
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
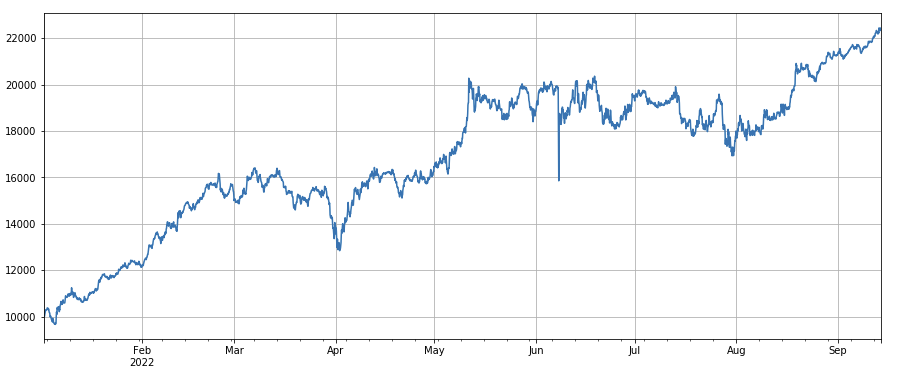
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
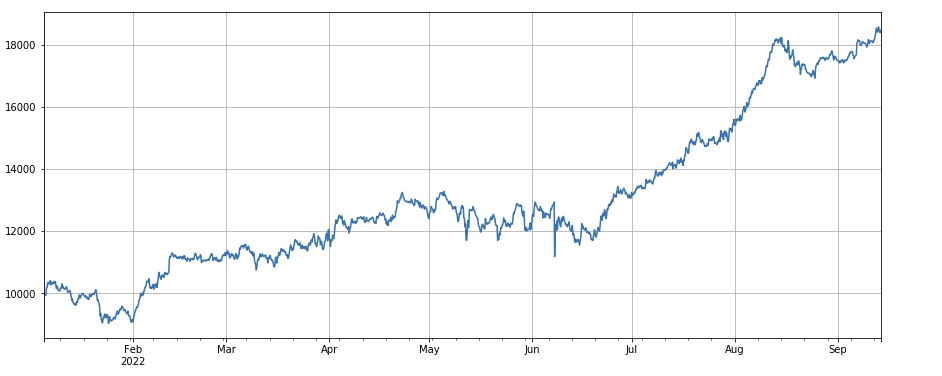
मल्टीफैक्टर संश्लेषण
लगातार नए प्रभावी कारकों की खोज करना निश्चित रूप से रणनीति निर्माण प्रक्रिया का सबसे महत्वपूर्ण हिस्सा है, लेकिन एक अच्छे कारक संश्लेषण विधि के बिना, एक उत्कृष्ट एकल अल्फा कारक अपनी अधिकतम भूमिका नहीं निभा सकता है। सामान्य बहु-कारक संश्लेषण विधियों में शामिल हैं:
समान भार विधि: संश्लेषित किए जाने वाले सभी कारकों को समान भार के साथ जोड़ा जाता है ताकि नए संश्लेषित कारक प्राप्त किए जा सकें।
ऐतिहासिक कारक प्रतिफल की भारित विधि: संश्लेषित किए जाने वाले सभी कारकों को नए संश्लेषित कारक प्राप्त करने के लिए भार के रूप में सबसे हाल की अवधि में ऐतिहासिक कारक प्रतिफल के अंकगणितीय माध्य के अनुसार एक साथ जोड़ा जाता है। यह विधि उन कारकों को अधिक महत्व देती है जो अच्छा प्रदर्शन करते हैं।
अधिकतम IC_IR भारित विधि: इतिहास की एक अवधि में समग्र कारक का औसत IC मान अगली अवधि में समग्र कारक के IC मान के अनुमान के रूप में उपयोग किया जाता है, और ऐतिहासिक IC मान के सहप्रसरण मैट्रिक्स का उपयोग अनुमान के रूप में किया जाता है अगली अवधि में समग्र कारक की अस्थिरता का। यह आईसी के अपेक्षित मूल्य को आईसी के मानक विचलन से विभाजित करने के बराबर है, और समग्र कारक IC_IR को अधिकतम करने के लिए इष्टतम भार समाधान प्राप्त किया जा सकता है।
प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए) विधि: पीसीए डेटा डाइमेंशनलिटी रिडक्शन के लिए आमतौर पर इस्तेमाल की जाने वाली विधि है। कारकों के बीच सहसंबंध अपेक्षाकृत अधिक हो सकता है, और डाइमेंशनलिटी रिडक्शन के बाद प्रिंसिपल घटकों को संश्लेषित कारकों के रूप में उपयोग किया जाता है।
यह आलेख मैन्युअल रूप से कारक वैधता भार का संदर्भ देगा। ऊपर वर्णित विधि निम्नलिखित को संदर्भित कर सकती है:ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
एकल कारक का परीक्षण करते समय, क्रम निश्चित होता है, लेकिन बहु-कारक संश्लेषण के लिए पूरी तरह से अलग-अलग डेटा को एक साथ विलय करने की आवश्यकता होती है, इसलिए सभी कारकों को मानकीकृत करने की आवश्यकता होती है, और आम तौर पर चरम मूल्यों और लापता मूल्यों को हटाने की आवश्यकता होती है। यहाँ हम संश्लेषण के लिए df_volume\factor_1\factor_7\factor_6\factor_8 का उपयोग करते हैं।
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
संक्षेप
यह लेख एकल कारक परीक्षण विधि का परिचय देता है और सामान्य एकल कारकों का परीक्षण करता है, और प्रारंभिक रूप से बहु-कारक संश्लेषण की विधि का परिचय देता है। हालाँकि, बहु-कारक अनुसंधान की सामग्री बहुत समृद्ध है। लेख में उल्लिखित प्रत्येक बिंदु को गहराई से विस्तारित किया जा सकता है . इस तरह के रणनीति अनुसंधान को अल्फा कारकों की खोज में बदलना एक व्यवहार्य दृष्टिकोण है। कारक पद्धति का उपयोग करने से ट्रेडिंग विचारों के सत्यापन में बहुत तेजी आ सकती है, और बहुत सारी संदर्भ सामग्री उपलब्ध है।
वास्तविक पता: https://www.fmz.com/robot/486605