Penjelasan tentang Keunggulan dan Kelemahan Algoritma Pembelajaran Mesin
Penulis:Penemu Kuantitas - Mimpi Kecil, Dibuat: 2017-10-30 12:01:59, Diperbarui: 2017-11-08 13:55:03Penjelasan tentang Keunggulan dan Kelemahan Algoritma Pembelajaran Mesin
Dalam pembelajaran mesin, tujuan adalah untuk membuat prediksi (prediction) atau mengelompokkan (clustering). Fokus artikel ini adalah pada prediksi. Prediksi adalah proses untuk memperkirakan nilai variabel output dari seperangkat variabel input. Sebagai contoh, dengan mendapatkan seperangkat karakteristik tentang sebuah rumah, kita dapat memprediksi harga jualnya. Setelah mengetahui hal ini, mari kita lihat algoritma yang paling menonjol dan paling umum digunakan dalam pembelajaran mesin. Kami akan membaginya menjadi tiga kategori: model linier, model berbasis pohon, dan jejaring saraf.
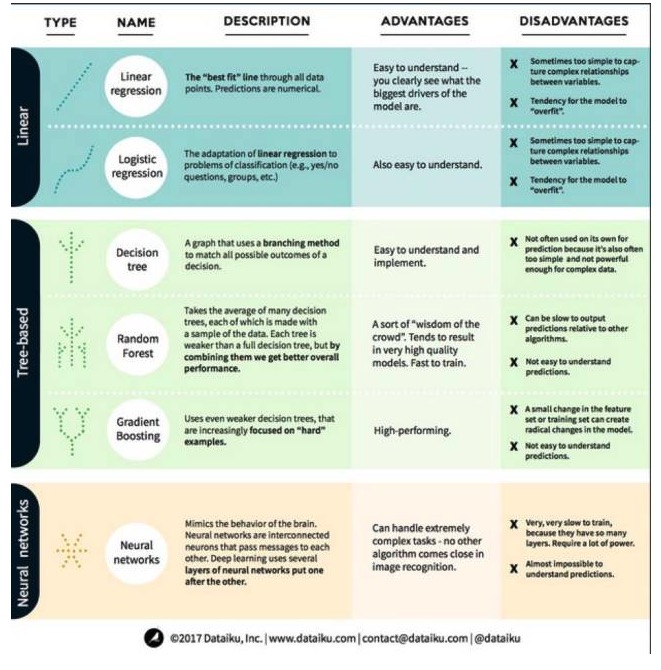
Algoritma model linier: model linier menggunakan rumus sederhana untuk menemukan baris yang paling cocok untuk pasangan melalui satu set titik data. Metode ini berasal dari lebih dari 200 tahun yang lalu dan banyak digunakan dalam bidang statistik dan pembelajaran mesin. Karena kesederhanaannya, ini berguna untuk statistik. Variabel yang ingin Anda prediksi (karena variabel) dinyatakan sebagai persamaan dari variabel yang sudah Anda ketahui (karena variabel), sehingga prediksi hanyalah masalah memasukkan variabel sendiri dan kemudian menghitung jawaban dari persamaan.
- ### # 1. Regresi linier
Regresi linier, atau lebih tepatnya regresi dua kali lipat terendah, adalah bentuk paling standar dari model linier. Untuk masalah regresi, regresi linier adalah model linier termudah. Kekurangannya adalah model mudah overfitting, yaitu model sepenuhnya beradaptasi dengan data yang telah dilatih, dengan mengorbankan kemampuan untuk menyebarkan ke data baru. Oleh karena itu, regresi linier dalam pembelajaran mesin (dan regresi logis yang akan kita bicarakan di bawah ini) seringkali adalah regresi linier, yang berarti model memiliki hukuman tertentu untuk mencegah overfitting.
Kelemahan lain dari model linier adalah karena mereka sangat sederhana, mereka tidak mudah memprediksi perilaku yang lebih kompleks ketika variabel input tidak independen.
- #### # 2. Kembali logis
Regresi logis adalah adaptasi regresi linear terhadap masalah klasifikasi. Kelemahan dari regresi logis adalah sama dengan regresi linear. Fungsi logis sangat bagus untuk masalah klasifikasi karena ia memperkenalkan efek ambang batas.
Kedua, model pohon.
- ### ## 1 ##, Pohon Keputusan
Pohon keputusan adalah ilustrasi dari setiap kemungkinan hasil dari keputusan yang digunakan untuk menunjukkan metode percabangan. Misalnya, Anda memutuskan untuk memesan salad, dan keputusan pertama Anda mungkin adalah jenis lobak mentah, kemudian sayur-sayuran, dan kemudian jenis lobak. Kita dapat menunjukkan semua kemungkinan hasil dalam pohon keputusan.
Untuk melatih pohon keputusan, kita perlu menggunakan dataset pelatihan dan mencari atribut yang paling berguna untuk tujuan tersebut. Misalnya, dalam contoh penggunaan deteksi penipuan, kita mungkin menemukan bahwa atribut yang paling berpengaruh pada prediksi risiko penipuan adalah negara. Setelah bercabang dengan atribut pertama, kita mendapatkan dua subset, yang merupakan prediksi yang paling akurat jika kita hanya mengetahui atribut pertama. Kemudian kita mencari atribut kedua yang paling baik yang dapat bercabang dengan dua subset ini, menggunakan pembagian lagi, dan seterusnya sampai cukup banyak atribut dapat memenuhi kebutuhan target.
- ### ## 2 ## ## ## ## ## ## ## ## ## ## ### ### ### ### #### #### ### #### ##########################################################################################################################################################################################################
Hutan acak adalah rata-rata dari banyak pohon keputusan, di mana setiap pohon keputusan dilatih dengan sampel data acak. Setiap pohon dalam hutan acak lebih lemah daripada pohon keputusan yang utuh, tetapi menempatkan semua pohon bersama, kita bisa mendapatkan kinerja keseluruhan yang lebih baik karena keuntungan dari keragaman.
Hutan acak adalah algoritma yang sangat populer dalam pembelajaran mesin saat ini. Hutan acak mudah dilatih, dan tampil cukup baik. Kelemahannya adalah bahwa, dibandingkan dengan algoritma lain, hutan acak dapat menghasilkan prediksi yang lambat, sehingga mungkin tidak memilih hutan acak ketika Anda membutuhkan prediksi cepat.
- #### ## 3, naikkan ketinggian
Gradient Boosting, seperti hutan acak, juga terdiri dari pohon keputusan yang lemah. Perbedaan terbesar dari hutan acak adalah bahwa dalam gradient boosting, pohon-pohon yang dilatih secara berurutan. Setiap pohon di belakang dilatih terutama oleh pohon di depan yang mengidentifikasi data yang salah.
Pelatihan untuk meningkatkan gradien juga cepat dan sangat baik. Namun, perubahan kecil dalam kumpulan data pelatihan dapat menyebabkan perubahan mendasar pada model, sehingga hasilnya mungkin tidak paling praktis.
Algoritma jejaring saraf: jejaring saraf adalah fenomena biologis yang terdiri dari neuron yang saling terhubung di otak untuk bertukar informasi satu sama lain. Ide ini sekarang diterapkan ke bidang pembelajaran mesin, yang disebut ANN. Pembelajaran mendalam adalah jejaring saraf berlapis-lapis. ANN adalah serangkaian model yang memperoleh kemampuan kognitif yang mirip dengan otak manusia melalui pembelajaran.
Dipindahkan dari Big Data Landscape
- Apakah penemu kuantitatif mendukung perdagangan koin huobi dan OKEX dan perdagangan USDT?
- Fungsi pengembalian dana terbuka yang terintegrasi ke dalam direktori perdagangan mata uang digital
- Bagaimana kita menghitung potensi maksimum dana dari strategi yang kita gunakan untuk mengukur laba, volatilitas, dan lain-lain?
- Setan Shannon.
- Yang rumit bukanlah teknologi, tapi pikiran manusia! Kemampuan trading harus sesuai dengan sistem trading.
- Bitfinex memiliki antarmuka akses yang lambat, apakah ada rekomendasi untuk menempatkan server?
- Bitfinex berjalan dengan salah, tolong analisis, terima kasih!
- Data yang diambil pada waktu panggilan API berdasarkan titik waktu apa?
- Saya ingin mendapatkan kode untuk Bitcoin.
- Mengapa hanya ada empat pasangan perdagangan di bitfinex, yaitu BCH_USD, BTC_USD, ETH_USD, dan LTC_USD?
- Blitz 5000 per koin: melakukan lebih banyak BTC, melakukan kontrak kosongokex1229, sebulan, 5000 yuan per koin!
- Mekanisme Pengamatan Akhir
- Bug yang diajukan: Tombol interaksi yang tidak memiliki parameter default saat membuat kebijakan gagal disimpan
- Apakah sistem retargeting tidak dapat memilih mata uang lain?
- Tolong terjemahkan halaman rencana pembelian
- Bitfinex memiliki tiga pasar, bagaimana membuat robot memilih?
- Opsi bersama-sama menang dari perspektif dinamis
- Bitfinex memverifikasi dan memverifikasi unit mata uang yang berbeda
- Apa yang Anda pikirkan tentang efektivitas dari pertikaian dan garpu emas?
- Bithumb mendapatkan informasi akun yang salah