Perbandingan 8 algoritma pembelajaran mesin
Penulis:Penemu Kuantitas - Mimpi Kecil, Dibuat: 2016-12-05 10:42:02, Diperbarui:Perbandingan 8 algoritma pembelajaran mesin
Artikel ini membahas skenario adaptasi dari beberapa algoritma yang umum digunakan dan kelebihan dan kekurangannya!
Ada begitu banyak algoritma pembelajaran mesin, di bidang klasifikasi, regresi, pengelompokan, rekomendasi, pengenalan gambar, dan sebagainya, untuk menemukan algoritma yang tepat sangat sulit, jadi dalam aplikasi praktis, kami biasanya menggunakan metode pembelajaran inspiratif untuk bereksperimen.
Biasanya, kita akan mulai dengan memilih algoritma yang umum digunakan, seperti SVM, GBDT, Adaboost, dan sekarang pembelajaran mendalam sangat populer, dan jaringan saraf juga merupakan pilihan yang bagus.
Jika Anda peduli dengan akurasi, cara terbaik adalah dengan menguji masing-masing algoritma secara individual melalui cross-validation, membandingkannya, lalu menyesuaikan parameter untuk memastikan bahwa masing-masing algoritma mencapai yang optimal, dan akhirnya memilih yang terbaik.
Tetapi jika Anda hanya mencari algoritma yang cukup bagus untuk memecahkan masalah Anda, atau ada beberapa tips untuk Anda gunakan, berikut adalah analisis tentang kelebihan dan kekurangan masing-masing algoritma, dan berdasarkan kelebihan dan kekurangan algoritma, lebih mudah untuk memilihnya.
-
Perbedaan
Dalam statistik, model yang baik dan buruk diukur berdasarkan kesesuaian dan perbedaan, jadi mari kita umumkan kesesuaian dan perbedaan:
Deviasi: menggambarkan selisih antara nilai ekspektasi (nilai perkiraan) yang diharapkan (E
) dan nilai nyata (Y).
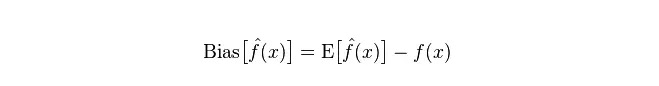
Perbedaan: menggambarkan rentang perubahan nilai P yang diprediksi, tingkat disintegrasi, adalah perbedaan dari nilai yang diprediksi, yaitu jarak dari nilai E yang diharapkan.
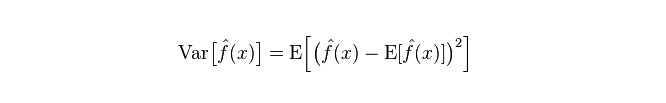
Kesalahan sebenarnya dari model adalah jumlah keduanya, seperti yang ditunjukkan di bawah ini:
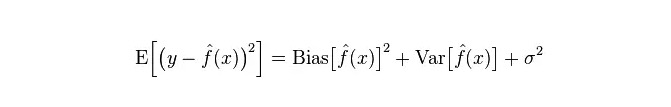
Jika sebuah training set kecil, pembagi dengan bias tinggi/desis rendah (misalnya, Bayes NB sederhana) akan lebih menguntungkan daripada pembagi dengan bias rendah/desis tinggi (misalnya, KNN) karena yang terakhir akan terlalu cocok.
Namun, seiring dengan pertumbuhan training set Anda, semakin baik kemampuan model untuk memprediksi data asli, semakin berkurang kesesuaian, dan pada titik ini, klasifikasi kesesuaian rendah/tinggi secara bertahap menunjukkan keunggulannya (karena mereka memiliki kesesuaian mendekat yang lebih rendah), dan pada titik ini klasifikasi kesesuaian tinggi tidak lagi cukup untuk memberikan model yang akurat.
Tentu saja, Anda juga dapat menganggap ini sebagai perbedaan antara model generasi (NB) dan model penilaian (KNN).
-
Mengapa Bayes yang sederhana memiliki bias tinggi dan bias rendah?
Di bawah ini adalah informasi yang kami terima:
Pertama, asumsikan Anda tahu hubungan antara training set dan test set. Secara sederhana, kita akan mempelajari model pada training set dan kemudian mengambil test set untuk digunakan, dan hasilnya baik atau buruk akan diukur berdasarkan tingkat kesalahan test set.
Tapi banyak kali, kita hanya bisa mengasumsikan bahwa testset dan trainingset sesuai dengan distribusi data yang sama, tetapi tidak mendapatkan data test yang sebenarnya.
Karena jumlah sampel yang dilatih sangat sedikit (setidaknya tidak cukup banyak), maka model yang diperoleh melalui training set tidak selalu benar-benar benar. Bahkan jika 100% benar pada training set, itu tidak berarti bahwa itu menggambarkan distribusi data yang sebenarnya.
Selain itu, dalam praktiknya, sampel pelatihan seringkali memiliki kesalahan kebisingan, sehingga jika terlalu mengejar kesempurnaan pada kumpulan pelatihan, model yang sangat rumit dapat membuat model memperlakukan semua kesalahan dalam kumpulan pelatihan sebagai karakteristik distribusi data yang sebenarnya, sehingga mendapatkan perkiraan distribusi data yang salah.
Dengan kata lain, pada testset yang sebenarnya akan terjadi kesalahan besar (fenomena ini disebut fit) ; tetapi juga tidak bisa menggunakan model yang terlalu sederhana, karena jika tidak maka model tidak akan cukup untuk melukiskan distribusi data ketika distribusi data relatif kompleks (menunjukkan bahwa bahkan pada trainingset, tingkat kesalahan yang tinggi, fenomena ini kurang fit).
Overfitting menunjukkan bahwa model yang digunakan lebih kompleks daripada distribusi data yang sebenarnya, sedangkan model yang tidak sesuai menunjukkan bahwa model yang digunakan lebih sederhana daripada distribusi data yang sebenarnya.
Dalam kerangka belajar statistik, ketika orang menggambar kompleksitas model, ada pendapat bahwa Error = Bias + Variance. Di sini, Error mungkin dapat dipahami sebagai tingkat kesalahan prediksi model, yang terdiri dari dua bagian, salah satunya adalah bias yang disebabkan oleh model yang terlalu sederhana, dan yang lainnya adalah ruang perubahan dan ketidakpastian yang lebih besar yang disebabkan oleh model yang terlalu kompleks.
Jadi, ini adalah analisis Bayesian sederhana yang mudah dilakukan. Ini adalah model yang sangat disederhanakan, karena asumsi sederhana bahwa data tidak terkait. Jadi, untuk model sederhana seperti itu, sebagian besar kasus akan memiliki Bias bagian yang lebih besar dari Variance bagian, yaitu bias tinggi dan bias rendah.
Dalam prakteknya, untuk membuat Error seminimal mungkin, kita perlu menyeimbangkan rasio Bias dan Variance dalam memilih model, yaitu menyeimbangkan over-fitting dan under-fitting.
Hubungan antara kesesuaian dan perbedaan dengan kompleksitas model lebih jelas dengan menggunakan gambar berikut:
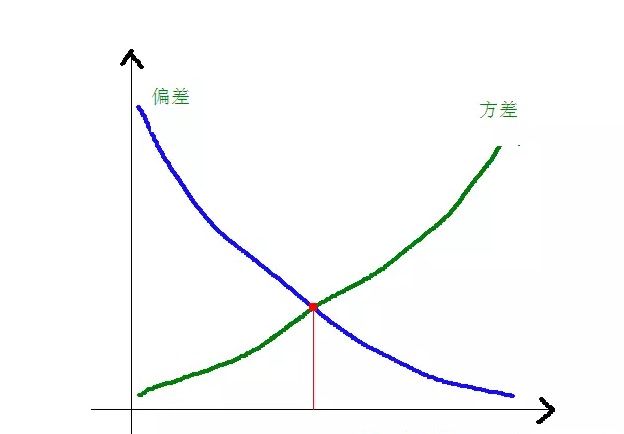
Dengan meningkatnya kompleksitas model, kesesuaian akan semakin kecil, sedangkan kesesuaian akan semakin besar.
-
Keunggulan dan Kekurangan Algoritma Umum
-
1.朴素贝叶斯
Bayes yang sederhana adalah model generatif (untuk model generatif dan model deterministik, terutama tentang apakah itu membutuhkan distribusi gabungan), sangat sederhana, Anda hanya melakukan banyak hitungan.
Jika Anda bertaruh pada asumsi kemandirian bersyarat (kondisi yang lebih ketat), kecepatan konvergensi pembagi Bayesian sederhana akan lebih cepat daripada model yang dapat diidentifikasi, seperti regresi logis, sehingga Anda hanya memerlukan data pelatihan yang lebih sedikit. Bahkan jika asumsi kemandirian bersyarat NB tidak berlaku, pembagi NB masih berkinerja sangat baik dalam praktik.
Kelemahan utamanya adalah tidak dapat mempelajari interaksi antara fitur, yang dalam mRMR disebut R, yaitu fitur redundant. Mengutip contoh yang lebih klasik, misalnya, meskipun Anda menyukai film Brad Pitt dan Tom Cruise, tetapi tidak dapat mempelajari film yang tidak Anda sukai bersama mereka.
Keuntungan:
Model Bayesian sederhana berasal dari teori matematika klasik, memiliki dasar matematika yang kuat, dan efisiensi klasifikasi yang stabil. Berkinerja baik untuk data berskala kecil, dapat menangani tugas multi-kelas secara individu, cocok untuk pelatihan kuantitatif; Algorithm yang lebih sederhana dan tidak terlalu sensitif terhadap data yang hilang sering digunakan untuk mengklasifikasikan teks. Kemunduran:
Perkiraan sebelumnya harus dihitung. Ada tingkat kesalahan dalam pengambilan keputusan klasifikasi. Mereka sangat sensitif terhadap bentuk ekspresi data yang mereka masukkan.
-
2.逻辑回归
Ada banyak metode untuk model normalisasi (L0, L1, L2, dll), dan Anda tidak perlu khawatir tentang apakah karakteristik Anda terkait seperti dengan Bayesian sederhana.
Anda juga mendapatkan penjelasan probabilitas yang bagus dibandingkan dengan pohon keputusan dan mesin SVM, dan Anda bahkan dapat dengan mudah menggunakan data baru untuk memperbarui model (menggunakan algoritma penurunan gradien online, descent gradien online).
Jika Anda membutuhkan arsitektur probabilitas (misalnya, hanya untuk menyesuaikan batas klasifikasi, menunjukkan ketidakpastian, atau untuk mendapatkan interval kepercayaan), atau Anda ingin mengintegrasikan lebih banyak data pelatihan ke dalam model dengan cepat di kemudian hari, gunakanlah.
Fungsi Sigmoid:
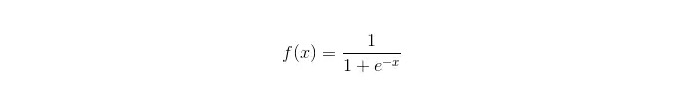
Keuntungan: Membuat aplikasi sederhana dan luas untuk masalah industri; Perhitungan yang sangat kecil, kecepatan yang cepat, dan sumber daya penyimpanan yang rendah saat diklasifikasikan; Skor Probabilitas Sampel Pengamatan yang Mudah Untuk regresi logis, multi-kom linearitas bukanlah masalah, yang dapat diselesaikan dengan L2 normalisasi; Kemunduran: Ketika ruang fitur besar, kinerja regresi logis tidak baik; Mudah kurang cocok, umumnya kurang akurat Tidak dapat menangani banyak karakteristik atau variabel multi-kategori dengan baik; Hanya dapat menangani dua masalah klasifikasi (softmax yang berasal dari hal ini dapat digunakan untuk beberapa klasifikasi) dan harus dapat dibagi secara linier; Untuk fitur non-linear, perlu konversi;
-
3.线性回归
Regresi linier digunakan untuk regresi, tidak seperti regresi logistik yang digunakan untuk klasifikasi. Ide dasarnya adalah untuk mengoptimalkan fungsi kesalahan bentuk minimal dua kali lipat dengan metode penurunan gradien, dan tentu saja juga dapat mencari solusi parameter langsung dengan persamaan normal, yang menghasilkan:
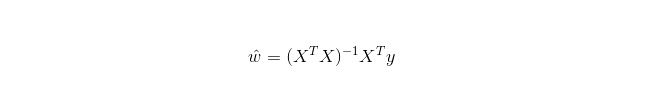
Dalam LWLR (Local weighted linear regression), ekspresi perhitungan parameter adalah:
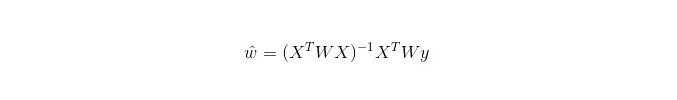
Oleh karena itu, LWLR berbeda dengan LR, LWLR adalah model non-parameter karena setiap kali melakukan perhitungan regresi, sampel pelatihan harus dijelajahi setidaknya sekali.
Keuntungan: Implementasi sederhana, perhitungan sederhana;
Kelemahan: Tidak dapat menyesuaikan data non-linear.
-
4.最近邻算法——KNN
KNN adalah algoritma tetangga terdekat, dan proses utamanya adalah:
-
Menghitung jarak dari masing-masing titik sampel dalam sampel pelatihan dan sampel uji (ukuran jarak yang umum adalah jarak Eropa, jarak Mars, dll.);
-
Periksa semua nilai jarak di atas.
-
Sampel dengan jarak minimal k sebelum dipilih;
-
Dengan memilih tag dari sampel k ini, Anda akan mendapatkan kategori peringkat akhir.
Cara memilih nilai K yang optimal tergantung pada data. Biasanya, nilai K yang lebih besar dapat mengurangi dampak kebisingan saat mengklasifikasikan. Namun, batas antara kategori akan menjadi kabur.
Sebuah nilai K yang lebih baik dapat diperoleh melalui berbagai teknik inspiratif, misalnya, verifikasi silang. Selain itu, adanya kebisingan dan vektor karakteristik yang tidak terkait dapat mengurangi akurasi algoritma K-neighborhood.
Algoritma tetangga memiliki hasil konsistensi yang lebih kuat. Dengan data yang cenderung tak terbatas, algoritma menjamin bahwa tingkat kesalahan tidak akan melebihi dua kali tingkat kesalahan algoritma Bayesian. Untuk beberapa nilai K yang baik, algoritma tetangga K menjamin bahwa tingkat kesalahan tidak akan melebihi tingkat kesalahan teoretis Bayesian.
Keuntungan dari algoritma KNN
Teori yang matang, pemikiran yang sederhana, yang dapat digunakan untuk klasifikasi dan regresi; Dapat digunakan untuk klasifikasi non-linear; Kompleksitas waktu pelatihan adalah O ((n); Tidak ada asumsi terhadap data, akurasi tinggi, tidak sensitif terhadap outlier; Kelemahan
Perhitungan besar; Masalah ketidakseimbangan sampel (misalnya, beberapa kategori memiliki banyak sampel, sedangkan yang lain memiliki sedikit); "Saya tidak tahu apa yang akan terjadi", katanya.
-
-
5.决策树
Mudah dijelaskan. Hal ini dapat menangani hubungan interaksi antara fitur tanpa stres dan non-parameter sehingga Anda tidak perlu khawatir tentang nilai-nilai yang aneh atau apakah data dapat dibagi secara linier (misalnya, pohon keputusan dapat dengan mudah menangani kategori A di ujung dimensi x dari suatu fitur, kategori B di tengah, dan kemudian kategori A muncul di ujung depan dimensi x dari suatu fitur).
Salah satu kekurangannya adalah tidak mendukung pembelajaran online, sehingga pohon keputusan harus dibangun kembali setelah sampel baru tiba.
Kelemahan lain adalah mudahnya terjadinya overfitting, tetapi ini juga merupakan titik masuk untuk metode integrasi seperti RF hutan acak (atau pohon yang didorong pohon).
Selain itu, hutan acak sering menjadi pemenang dari banyak masalah klasifikasi (biasanya sedikit lebih baik dari mesin pendukung vektor), karena ia melatih dengan cepat dan dapat disesuaikan, dan Anda tidak perlu khawatir tentang mengatur banyak parameter seperti mesin pendukung vektor, jadi sangat populer di masa lalu.
Hal yang penting dalam pohon keputusan adalah memilih sebuah atribut untuk bercabang, jadi perhatikan rumus perhitungan keuntungan informasi dan mengerti secara mendalam.
Rumus perhitungan untuk informasi ini adalah sebagai berikut:
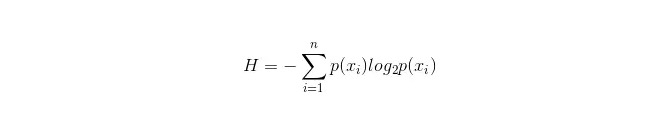
Di mana n mewakili n kategori pembagian (misalnya, asumsikan adalah masalah kategori 2, maka n = 2) ; menghitung probabilitas kedua sampel ini muncul dalam sampel keseluruhan masing-masing p1 dan p2, sehingga dapat menghitung batang informasi sebelum cabang atribut yang tidak dipilih.
Sekarang pilih properti xixi yang digunakan untuk melakukan branching, pada saat ini aturan branching adalah: jika xi = vxi = v, sampingan dibagi menjadi satu cabang pohon; jika tidak sama, masuk ke cabang lain.
Jelas, sampel dalam cabang kemungkinan besar terdiri dari 2 kategori, yaitu H1 dan H2 yang masing-masing menghitung H1 dan H2 yang masing-masing menghitung H1 H1 + H2 H2 yang menghitung H1 H1 + H2 H2, maka akan terjadi peningkatan informasi ΔH = H - H
. Dengan prinsip peningkatan informasi, semua atribut diuji, dan pilih atribut yang memberikan peningkatan terbesar sebagai atribut cabang ini. Keuntungan dari Pohon Keputusan Sendiri
Perhitungan yang sederhana, mudah dimengerti, dan kuat untuk dijelaskan; Perbandingan sampel yang cocok untuk diproses dengan sifat yang hilang; Berbicara tentang hal-hal yang tidak relevan. Hasil yang layak dan efektif dapat dibuat pada sumber data besar dalam waktu yang relatif singkat. Kelemahan
Pohon-pohon yang mudah tergenang (hutan acak dapat sangat mengurangi tergenang); Di sisi lain, ada beberapa hal yang perlu diperhatikan. Untuk data yang memiliki jumlah sampel yang tidak konsisten di berbagai kategori, di dalam pohon keputusan, hasil dari peningkatan informasi lebih cenderung pada karakteristik yang memiliki nilai lebih banyak (yang memiliki kelemahan ini jika Anda menggunakan peningkatan informasi, seperti RF).
-
5.1 Adaptasi
Adaboost adalah sebuah model penjumlahan, di mana setiap model dibangun berdasarkan tingkat kesalahan model sebelumnya, dengan terlalu banyak perhatian pada sampel yang salah, dan kurang perhatian pada sampel yang diklasifikasikan dengan benar, sehingga setelah beberapa iterasi, model yang relatif lebih baik dapat diperoleh.
Keuntungan
Adaboost adalah alat pengurut yang memiliki presisi tinggi. Ada berbagai cara untuk membangun sub-katalog, Adaboost Algorithm menyediakan framework. Hasil yang dihitung dapat dimengerti ketika menggunakan pengurut sederhana, dan konstruksi pengurut lemah sangat sederhana. Cara ini sangat mudah, tidak perlu melakukan penyaringan fitur. Tidak mudah terjadi overfitting. Untuk algoritma kombinasi seperti Random Forest dan GBDT, lihat artikel ini: Machine Learning - Summary of Combination Algorithms
Kelemahan: Lebih sensitif terhadap outlier
-
6.SVM支持向量机
Keakuratan tinggi memberikan jaminan teoritis yang baik untuk menghindari overfitting, dan data dapat berjalan dengan baik jika diberikan fungsi inti yang tepat, bahkan jika data tidak dapat dipisahkan secara linier di ruang karakteristik asli.
Ini sangat populer dalam masalah klasifikasi teks dengan dimensi yang sangat tinggi. Sayangnya, memori yang sangat besar dan sulit dijelaskan, operasi dan penyesuaian juga sedikit merepotkan, sementara hutan acak hanya menghindari kekurangan ini dan lebih praktis.
Keuntungan Ada beberapa hal yang dapat dilakukan untuk mengatasi masalah dimensi tinggi, yaitu ruang fitur besar. Fitur-fitur yang dapat ditangani adalah interaksi dengan fitur non-linear; Tidak perlu mengandalkan data secara keseluruhan. Ini bisa meningkatkan kemampuan generalisasi.
Kelemahan Jika Anda melihat banyak sampel, maka efisiensi tidak terlalu tinggi. Tidak ada solusi universal untuk masalah non-linear, dan kadang-kadang sulit untuk menemukan fungsi inti yang sesuai. Dia juga mengatakan, "Saya tidak tahu apa yang akan terjadi. Untuk memilih kernel juga rumit (libsvm memiliki empat fungsi kernel: kernel linier, kernel multipolar, kernel RBF, dan kernel sigmoid):
Pertama, jika jumlah sampel kurang dari jumlah karakteristik, maka tidak perlu untuk memilih inti non-linier, yang sederhana adalah menggunakan inti linier.
Kedua, jika jumlah sampel lebih besar dari jumlah karakteristik, maka kernel non-linear dapat digunakan untuk memetakan sampel ke dimensi yang lebih tinggi, yang umumnya menghasilkan hasil yang lebih baik.
Ketiga, jika jumlah sampel dan jumlah karakteristik sama, maka inti non-linier dapat digunakan, prinsipnya sama dengan yang kedua.
Untuk kasus pertama, data dapat dimensionerkan terlebih dahulu dan kemudian menggunakan kernel non-linear, yang juga merupakan metode.
-
7. Kelemahan dari jaringan saraf buatan
Perangkat lunak ini memiliki fitur yang sangat baik. Klasifikasi sangat akurat; Perangkat lunak ini memiliki kemampuan pengolahan terdistribusi paralel yang kuat, penyimpanan terdistribusi dan kemampuan belajar yang kuat. Dengan kemampuan yang lebih kuat terhadap saraf kebisingan dan toleransi terhadap kesalahan, dapat mendekati hubungan non-linear yang kompleks; Dia juga mengatakan bahwa dia memiliki kemampuan untuk mengenang kenangan.
Perbedaan antara jaringan saraf buatan dan jaringan saraf buatan adalah: Jaringan saraf membutuhkan sejumlah besar parameter, seperti struktur topologi jaringan, nilai berat dan nilai awal ambang batas. Proses belajar yang tidak dapat diamati, hasil output yang sulit untuk dijelaskan, yang mempengaruhi kredibilitas dan penerimaan hasil; Dia mengatakan, "Selama beberapa hari, saya belajar di sebuah sekolah yang sangat sibuk dan sulit untuk mencapai tujuan belajar.
-
8 K-Means kelompok
Saya pernah menulis artikel sebelumnya tentang K-Means Clustering, link blog: Machine Learning Algorithm - K-Means Clustering.
Keuntungan Algorithmnya sederhana dan mudah diterapkan; Untuk menangani set data besar, algoritma ini relatif dapat diskalakan dan efisien karena kompleksitasnya sekitar O ((nkt), di mana n adalah jumlah semua objek, k adalah jumlah kerucut, dan t adalah jumlah iterasi. Biasanya k<
Kelemahan Permintaan yang lebih tinggi untuk jenis data yang cocok untuk jenis data numerik; Mungkin berkonsentrasi pada minimal lokal, dan lebih lambat pada data besar. K-value lebih sulit dipilih; Sensitivitas terhadap nilai awal yang sensitif terhadap nilai awal yang berbeda dapat menyebabkan hasil pengelompokan yang berbeda; Tidak cocok untuk menemukan kerucut yang bentuknya tidak konkrit, atau kerucut yang ukurannya sangat berbeda. Data yang sensitif terhadap kerucut dan titik terisolasi dapat memiliki pengaruh besar pada rata-rata.
Algoritma memilih referensi
Sebelumnya, saya telah menerjemahkan beberapa artikel dari luar negeri, salah satunya memberikan trik pemilihan algoritma yang sederhana:
Yang pertama yang harus dipilih adalah regresi logis, dan jika hasilnya tidak baik, maka hasilnya dapat digunakan sebagai acuan untuk perbandingan dengan algoritma lain.
Kemudian cobalah pohon keputusan (Random Forest) untuk melihat apakah Anda dapat meningkatkan kinerja model Anda secara drastis. Bahkan jika Anda akhirnya tidak menganggapnya sebagai model akhir, Anda juga dapat menggunakan Random Forest untuk menghapus variabel kebisingan, membuat pilihan fitur;
Jika jumlah karakteristik dan sampel yang diamati sangat banyak, maka penggunaan SVM adalah pilihan yang baik ketika sumber daya dan waktu cukup (premis ini penting).
Biasanya:
GBDT>=SVM>=RF>=Adaboost>=Other... Oh, sekarang pembelajaran mendalam sangat populer, banyak bidang yang digunakan, itu didasarkan pada jaringan saraf, saat ini saya sendiri belajar, hanya saja pengetahuan teoritis tidak cukup tebal, pemahaman tidak cukup dalam, maka saya tidak akan mengulasnya di sini. Algoritma penting, tetapi data yang baik lebih baik daripada algoritma yang baik, dan desain fitur yang baik sangat bermanfaat. Jika Anda memiliki dataset yang sangat besar, algoritma mana pun yang Anda gunakan mungkin tidak terlalu mempengaruhi kinerja klasifikasi (di saat ini Anda dapat membuat pilihan berdasarkan kecepatan dan kemudahan penggunaan).
-
-
Referensi
- Filsafat perdagangan dalam Probabilitas
- Di mana Anda harus memasukkan kode dana
- BTCTRADE.com tidak dapat mengakses GetRecords
- Di sisi lain, jika Anda membeli opsi, Anda akan kehilangan uang.
- Analisis Kuantitatif Strategi Pemasangan
- Pembelajaran Mesin yang Menyenangkan: Panduan Pendahuluan Paling Singkat
- Hukum Perdagangan Besi
- 7 algoritma pemesanan yang umum digunakan (menulis strategi yang umum digunakan)
- Strategi perdagangan frekuensi tinggi: Triangle leverage
- 20 tips untuk mengembangkan pemikiran kreatif
- Investasi untuk Pemenang: Rahasia Berpikir Berlawanan dengan Intuisi
- Berbicara tentang persyaratan dasar sistem perdagangan
- Ukuran fluktuasi yang sebenarnya menggunakan indikator ATR
- Apakah ada pertanyaan kode kesalahan robot?
- Ini adalah matematika investasi yang menarik!
- Matematika dan perjudian (1)
- Pemikiran ulang tentang sistem linier
- Instrumen untuk mengontrol posisi rumus Kelly
- Pikiran tentang perdagangan tren burung tua, sistem perdagangan kuantitatif
- Tips Strategi Frekuensi Tinggi untuk Bitcoin