Diskusi tentang Metode Pengujian Strategi Berdasarkan Generator Random Ticker
Penulis:FMZ~Lydia, Dibuat: 2024-12-02 11:26:13, Diperbarui: 2024-12-02 21:39:39
Pengantar
Sistem backtesting dari FMZ Quant Trading Platform adalah sistem backtesting yang terus-menerus diulang, diperbarui dan ditingkatkan. Ini menambahkan fungsi dan mengoptimalkan kinerja secara bertahap dari fungsi backtesting dasar awal. Dengan pengembangan platform, sistem backtesting akan terus dioptimalkan dan ditingkatkan. Hari ini kita akan membahas topik berdasarkan sistem backtesting:
Permintaan
Dalam bidang perdagangan kuantitatif, pengembangan dan pengoptimalan strategi tidak dapat dipisahkan dari verifikasi data pasar riil. Namun, dalam aplikasi yang sebenarnya, karena lingkungan pasar yang kompleks dan berubah, mengandalkan data historis untuk backtesting mungkin tidak cukup, seperti kurangnya cakupan kondisi pasar ekstrem atau skenario khusus. Oleh karena itu, merancang generator pasar acak yang efisien telah menjadi alat yang efektif bagi pengembang strategi kuantitatif.
Ketika kita perlu membiarkan strategi melacak kembali data historis pada bursa atau mata uang tertentu, kita dapat menggunakan sumber data resmi dari platform FMZ untuk backtesting.
Pentingnya menggunakan data ticker acak adalah:
-
- Mengevaluasi kekuatan strategi Generator ticker acak dapat menciptakan berbagai skenario pasar yang mungkin, termasuk volatilitas ekstrem, volatilitas rendah, pasar tren, dan pasar yang tidak stabil.
Apakah strategi dapat beradaptasi dengan perubahan tren dan volatilitas? Akankah strategi ini menimbulkan kerugian besar dalam kondisi pasar yang ekstrim?
-
- Mengidentifikasi potensi kelemahan dalam strategi Dengan mensimulasikan beberapa situasi pasar yang tidak normal (seperti peristiwa angsa hitam hipotetis), potensi kelemahan dalam strategi dapat ditemukan dan ditingkatkan.
Apakah strategi terlalu bergantung pada struktur pasar tertentu? Apakah ada risiko overfit parameter?
-
- Mengoptimalkan parameter strategi Data yang dihasilkan secara acak menyediakan lingkungan pengujian yang lebih beragam untuk optimasi parameter strategi, tanpa harus sepenuhnya bergantung pada data historis.
-
- Mengisi celah dalam data historis Di beberapa pasar (seperti pasar berkembang atau pasar perdagangan mata uang kecil), data historis mungkin tidak cukup untuk mencakup semua kondisi pasar yang mungkin.
-
- Pengembangan iteratif yang cepat Menggunakan data acak untuk pengujian cepat dapat mempercepat iterasi pengembangan strategi tanpa bergantung pada kondisi pasar waktu nyata atau pembersihan dan organisasi data yang memakan waktu.
Namun, juga perlu untuk mengevaluasi strategi secara rasional.
-
- Meskipun generator pasar acak berguna, signifikansi mereka tergantung pada kualitas data yang dihasilkan dan desain skenario target:
-
- Logika generasi harus dekat dengan pasar nyata: Jika pasar yang dihasilkan secara acak benar-benar tidak berhubungan dengan realitas, hasil tes mungkin tidak memiliki nilai referensi.
-
- Hal ini tidak dapat sepenuhnya menggantikan pengujian data nyata: data acak hanya dapat melengkapi pengembangan dan optimalisasi strategi. strategi akhir masih perlu diverifikasi untuk keefektifannya dalam data pasar nyata.
Setelah mengatakan begitu banyak, bagaimana kita bisa "memproduksi" beberapa data? Bagaimana kita bisa "memproduksi" data untuk sistem backtesting untuk digunakan dengan mudah, cepat dan mudah?
Ide Desain
Artikel ini dirancang untuk memberikan titik awal untuk diskusi dan memberikan perhitungan generasi ticker acak yang relatif sederhana. Sebenarnya, ada berbagai algoritma simulasi, model data dan teknologi lain yang dapat diterapkan. Karena ruang diskusi terbatas, kami tidak akan menggunakan metode simulasi data yang kompleks.
Menggabungkan fungsi sumber data kustom dari sistem backtesting platform, kami menulis program dalam Python.
-
- Menghasilkan seperangkat data K-line secara acak dan menuliskannya ke dalam file CSV untuk rekaman permanen, sehingga data yang dihasilkan dapat disimpan.
-
- Kemudian buat layanan untuk memberikan dukungan sumber data untuk sistem backtesting.
-
- Tampilkan data K-line yang dihasilkan dalam grafik.
Untuk beberapa standar generasi dan penyimpanan file data K-line, kontrol parameter berikut dapat didefinisikan:
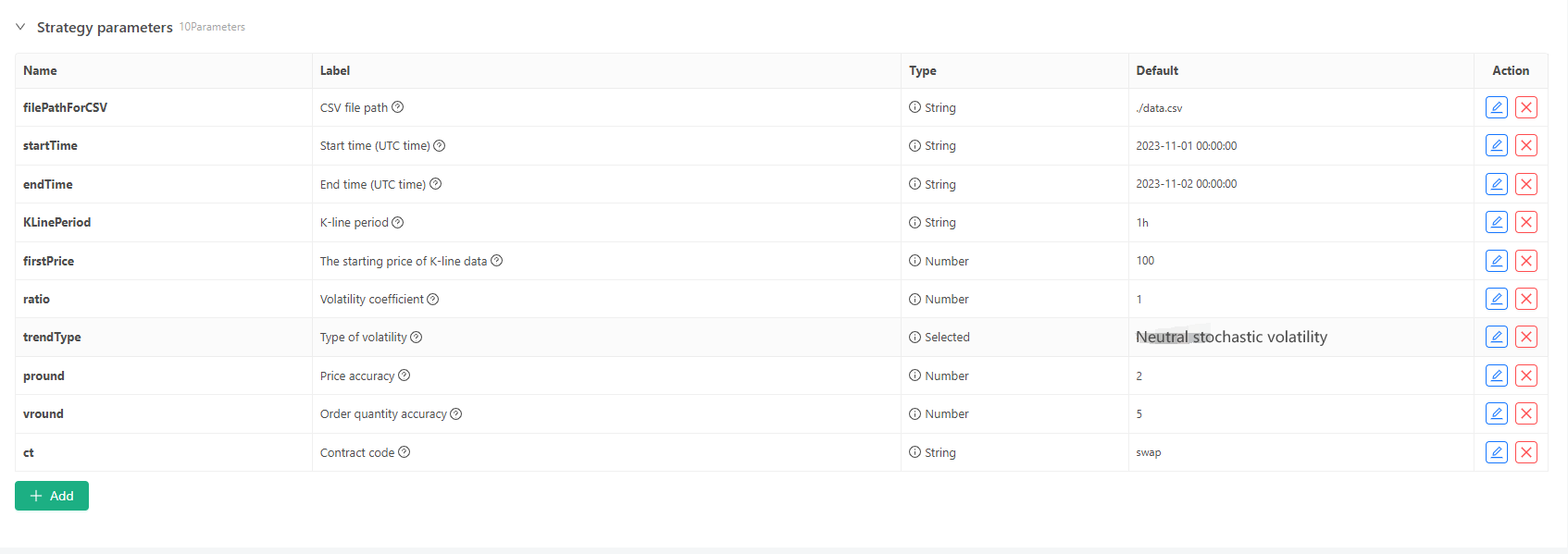
-
Modus generasi data acak Untuk simulasi jenis fluktuasi data K-line, desain sederhana hanya dibuat menggunakan probabilitas bilangan acak positif dan negatif. Ketika data yang dihasilkan tidak banyak, mungkin tidak mencerminkan pola pasar yang diperlukan. Jika ada metode yang lebih baik, bagian kode ini dapat diganti. Berdasarkan desain sederhana ini, menyesuaikan kisaran generasi angka acak dan beberapa koefisien dalam kode dapat mempengaruhi efek data yang dihasilkan.
-
Verifikasi data Data K-line yang dihasilkan juga perlu diuji untuk rasionalisasi, untuk memeriksa apakah harga pembukaan yang tinggi dan harga penutupan yang rendah melanggar definisi, dan untuk memeriksa kontinuitas data K-line.
Backtesting System Random Ticker Generator
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Praktik dalam Sistem Backtesting
- Buat contoh strategi di atas, konfigurasi parameter, dan jalankan.
- Perdagangan langsung (contoh strategi) perlu dijalankan pada docker yang digunakan pada server, ia membutuhkan IP jaringan publik, sehingga sistem backtesting dapat mengaksesnya dan memperoleh data.
- Klik tombol interaksi, dan strategi akan mulai menghasilkan data ticker secara otomatis.
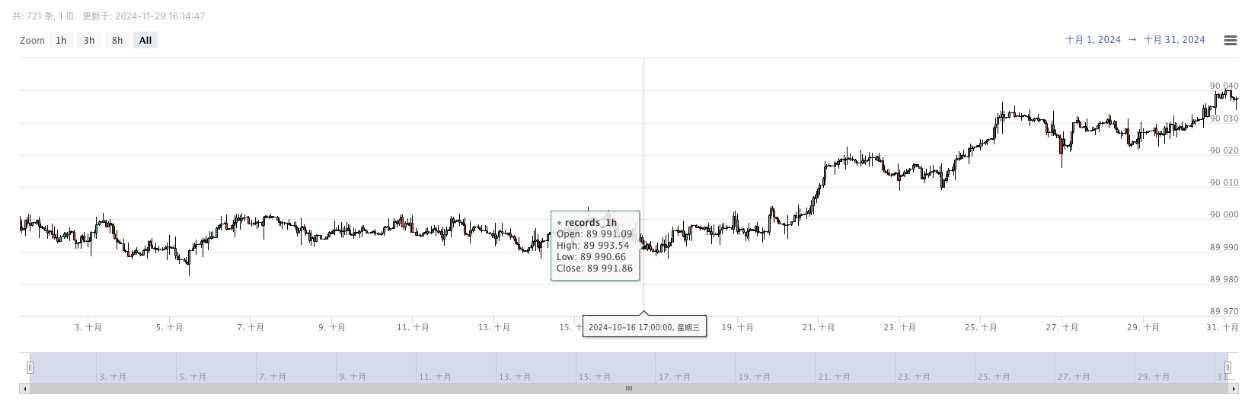
- Data yang dihasilkan akan ditampilkan pada grafik untuk pengamatan yang mudah, dan data akan dicatat dalam file data.csv lokal.
- Sekarang kita bisa menggunakan data yang dihasilkan secara acak dan menggunakan strategi apapun untuk backtesting:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Sesuai dengan informasi di atas, konfigurasi dan atur.http://xxx.xxx.xxx.xxx:9090adalah alamat IP server dan port terbuka dari strategi generasi ticker acak.
Ini adalah sumber data khusus, yang dapat ditemukan di bagian Sumber Data Khusus dari dokumen API platform.
- Setelah sistem backtest mengatur sumber data, kita dapat menguji data pasar acak:
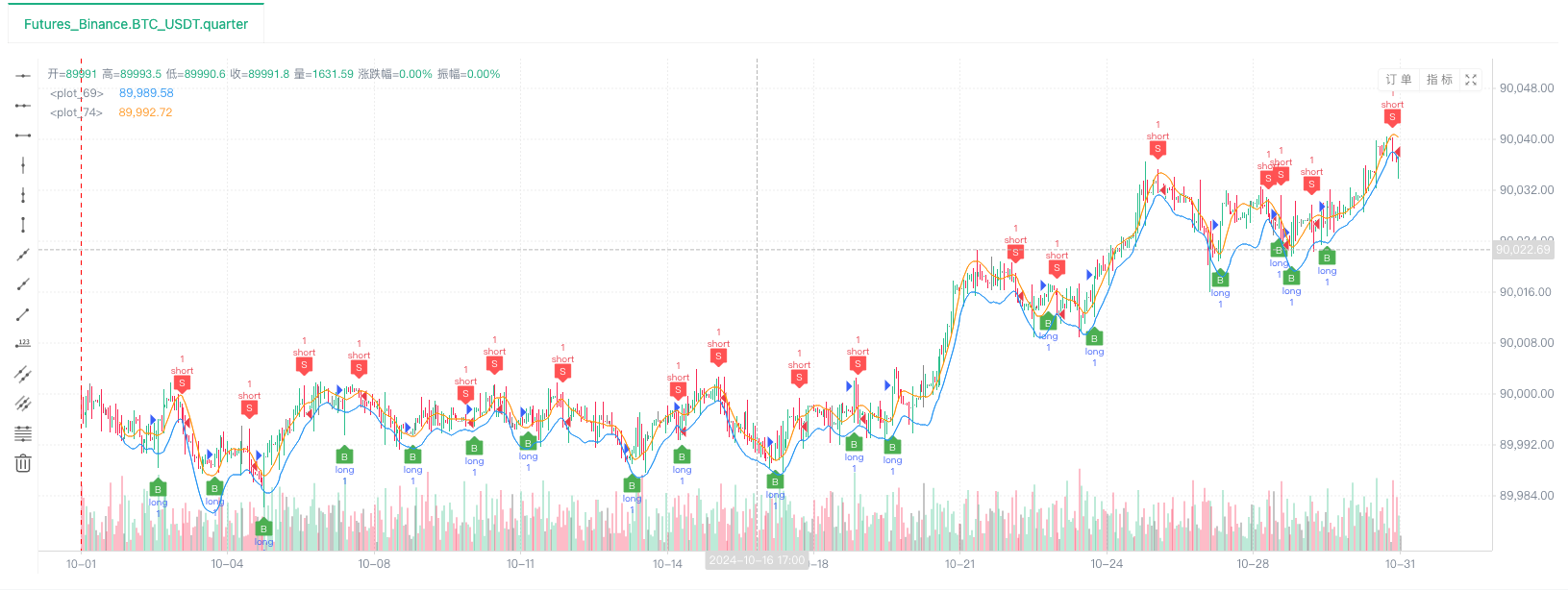
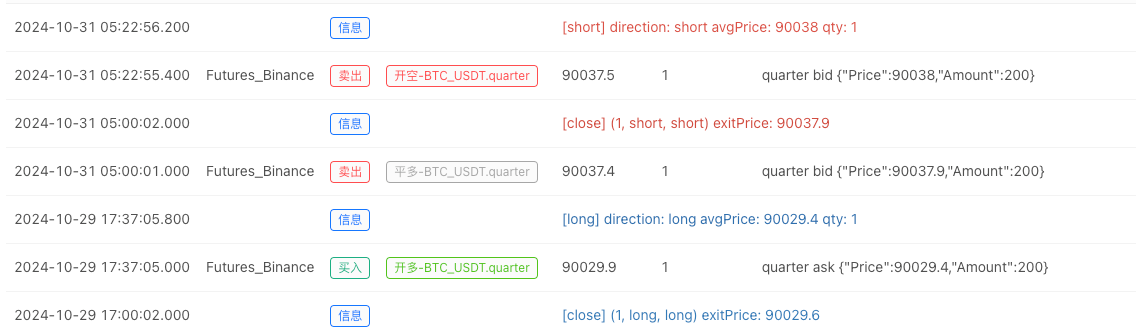
Pada saat ini, sistem backtest diuji dengan data simulasi
- Oh, ya, saya hampir lupa untuk menyebutkannya! Alasan mengapa program Python ini dari generator ticker acak membuat perdagangan langsung adalah untuk memfasilitasi demonstrasi, operasi, dan tampilan data K-line yang dihasilkan.
Kode sumber strategi:Backtesting System Random Ticker Generator
Terima kasih atas dukungan dan pembacaanmu.
- Praktik Kuantitatif DEX Exchange ((1)-- dYdX v4 Panduan Penggunaan
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (3)
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (2)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (2)
- Pembahasan Penerimaan Sinyal Eksternal Platform FMZ: Solusi Lengkap untuk Penerimaan Sinyal dengan Layanan Http Terbina dalam Strategi
- FMZ platform eksplorasi penerimaan sinyal eksternal: strategi built-in https layanan solusi lengkap untuk penerimaan sinyal
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (1)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (1)
- Diskusi tentang Penerimaan Sinyal Eksternal dari Platform FMZ: API Terluas VS Strategi Layanan HTTP Terintegrasi
- FMZ Platform Eksternal Signal Reception: Extension API vs Strategi Layanan HTTP Terbentuk
- Metode pengujian strategi berdasarkan generator pasar acak
- Fitur Baru FMZ Quant: Gunakan Fungsi _Serve untuk Membuat Layanan HTTP dengan Mudah
- Penemu mengkuantifikasi fitur baru: dengan mudah membuat layanan HTTP menggunakan fungsi _Serve
- FMZ Quant Trading Platform Panduan Akses Protokol Khusus
- Strategi Akuisisi dan Pemantauan Tingkat Pembiayaan FMZ
- Strategi untuk mendapatkan dan memantau tingkat dana FMZ
- Template Strategi Memungkinkan Anda Menggunakan WebSocket Market Seamlessly
- Sebuah template kebijakan yang memungkinkan Anda untuk menggunakan WebSocket secara mulus
- Inventor Quantitative Trading Platforms General Protocol Access Guide (Penggunaan Protokol Umum untuk Pemasaran Kuantitatif)
- Bagaimana Membangun Strategi Perdagangan Multi-Valuta Universal dengan Cepat Setelah Peningkatan FMZ