Jaringan saraf dan Seri Perdagangan Kuantitatif Mata Uang Digital (2) - Pelatihan dan Pelatihan Intensif Strategi Perdagangan Bitcoin
Penulis:FMZ~Lydia, Dibuat: 2023-01-12 16:49:09, Diperbarui: 2024-12-19 21:09:28
Jaringan saraf dan Seri Perdagangan Kuantitatif Mata Uang Digital (2) - Pelatihan dan Pelatihan Intensif Strategi Perdagangan Bitcoin
1. Pambuka
Dalam artikel sebelumnya, kami memperkenalkan penggunaan jaringan LSTM untuk memprediksi harga Bitcoin:https://www.fmz.com/bbs-topic/9879, seperti yang disebutkan dalam artikel, ini hanya sebuah proyek pelatihan kecil untuk membiasakan diri dengan RNN dan pytorch. Artikel ini akan memperkenalkan penggunaan pembelajaran intensif untuk melatih strategi perdagangan secara langsung. Model pembelajaran intensif adalah OpenAI open source PPO, dan lingkungan mengacu pada gaya gym. Untuk memudahkan pemahaman dan pengujian, model PPO LSTM dan lingkungan gym untuk backtesting ditulis secara langsung tanpa menggunakan paket siap pakai. PPO, atau Proximal Policy Optimization, adalah peningkatan optimasi dari Policy Gradient. gym juga dirilis oleh OpenAI. Ini dapat berinteraksi dengan jaringan strategi dan umpan balik status dan imbalan lingkungan saat ini. Ini seperti praktik pembelajaran intensif. Ini menggunakan model PPO dari LSTM untuk membuat instruksi, seperti membeli, menjual atau tidak beroperasi secara langsung sesuai dengan informasi pasar Bitcoin. Umpan balik diberikan oleh lingkungan backtest. Melalui pelatihan, model ini dioptimalkan terus-menerus untuk mencapai tujuan keuntungan strategis. Membaca artikel ini membutuhkan dasar tertentu dari pembelajaran intensif mendalam di Python, pytorch dan DRL. Tapi tidak masalah jika Anda tidak bisa. Mudah untuk belajar dan memulai dengan kode yang diberikan dalam artikel ini. Tutorial ini diproduksi oleh platform FMZ Quant Trading (www.fmz.comSelamat datang untuk bergabung dengan kelompok QQ: 863946592 untuk komunikasi.
2. Referensi data dan pembelajaran
Data harga Bitcoin berasal dari platform FMZ Quant Trading:https://www.quantinfo.com/Tools/View/4.htmlAku tidak tahu. Sebuah artikel menggunakan DRL+gym untuk melatih strategi trading:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4Aku tidak tahu. Beberapa contoh untuk memulai dengan pytorch:https://github.com/yunjey/pytorch-tutorialAku tidak tahu. Artikel ini akan menerapkan model LSTM-PPO secara langsung:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.pyAku tidak tahu. Artikel tentang PPO:https://zhuanlan.zhihu.com/p/38185553Aku tidak tahu. Lebih banyak artikel tentang DRL:https://www.zhihu.com/people/flood-sung/postsAku tidak tahu. Tentang gym, artikel ini tidak memerlukan instalasi, tetapi sangat umum dalam pembelajaran intensif:https://gym.openai.com/.
3. LSTM-PPO
Untuk penjelasan mendalam tentang PPO, Anda dapat belajar dari bahan referensi sebelumnya. Berikut hanya pengantar sederhana untuk konsep. Edisi terakhir jaringan LSTM hanya memprediksi harga. Cara membeli dan menjual berdasarkan harga yang diprediksi harus direalisasikan secara terpisah. Adalah wajar untuk berpikir bahwa output langsung dari tindakan perdagangan akan lebih langsung. Ini adalah kasus dengan Policy Gradient, yang dapat memberikan probabilitas berbagai tindakan sesuai dengan informasi lingkungan input s. Kerugian LSTM adalah perbedaan antara harga yang diprediksi dan harga aktual, sedangkan kerugian PG adalah - log § * Q, di mana p adalah probabilitas tindakan output, dan Q adalah nilai tindakan (seperti skor imbalan intuitif). Penjelasan adalah bahwa jika nilai tindakan lebih tinggi, jaringan harus menjadi kunci untuk mengurangi kerugian. Meskipun PPO lebih kompleks, prinsipnya lebih mirip dengan bagaimana mengevaluasi nilai output setiap tindakan dan memperbarui nilai yang lebih baik.
Kode sumber LSTM-PPO diberikan di bawah ini, yang dapat dipahami dalam kombinasi dengan data sebelumnya:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Lingkungan backtesting Bitcoin
Setelah format gym, ada metode reset initialization. Step input tindakan, dan hasil yang dikembalikan adalah (status berikutnya, pendapatan tindakan, apakah akan berakhir, informasi tambahan). Seluruh lingkungan backtest juga 60 baris. Anda dapat memodifikasi versi yang lebih kompleks sendiri. Kode spesifik adalah:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Beberapa rincian penting
- Mengapa rekening awal memiliki mata uang?
Rumus untuk menghitung pengembalian lingkungan backtest adalah: current return = current account value - current value of the initial account. Ini berarti bahwa jika harga Bitcoin menurun dan strategi melakukan operasi penjualan koin, bahkan jika total nilai akun menurun, strategi tersebut sebenarnya harus dihargai. Jika backtest memakan waktu lama, akun awal mungkin memiliki sedikit dampak, tetapi akan memiliki dampak yang besar di awal. Perhitungan pengembalian relatif memastikan bahwa setiap operasi yang benar akan mendapatkan imbalan positif.
- Mengapa pasar diambil sampel selama pelatihan?
Jumlah total data lebih dari 10.000 K-line. Jika Anda menjalankan loop penuh setiap kali, itu akan memakan waktu lama, dan strategi menghadapi situasi yang sama setiap kali, mungkin lebih mudah untuk overfit. Mengambil 500 bar pada suatu waktu sebagai backtest. Meskipun masih mungkin untuk overfit, strategi menghadapi lebih dari 10.000 kemungkinan awal.
- Bagaimana jika tidak ada mata uang atau uang?
Situasi ini tidak dipertimbangkan dalam lingkungan backtest. Jika mata uang telah terjual habis atau jumlah perdagangan minimum tidak dapat dicapai, maka operasi penjualan setara dengan tidak operasi sebenarnya. Jika harga menurun, menurut metode perhitungan laba relatif, itu masih didasarkan pada laba positif strategis. Dampak dari situasi ini adalah bahwa ketika strategi menilai bahwa pasar menurun dan sisa mata uang akun tidak dapat dijual, tidak mungkin membedakan tindakan penjualan dari tindakan non-operasi, tetapi tidak berdampak pada penilaian strategi itu sendiri di pasar.
- Mengapa saya harus mengembalikan informasi akun sebagai status?
Model PPO memiliki jaringan nilai untuk mengevaluasi nilai status saat ini. Jelas, jika strategi menilai bahwa harga akan meningkat, seluruh status hanya akan memiliki nilai positif ketika akun saat ini memegang Bitcoin, dan sebaliknya. Oleh karena itu, informasi akun adalah dasar penting untuk penilaian jaringan nilai. Perlu dicatat bahwa informasi tindakan masa lalu tidak dikembalikan sebagai status. Saya menganggap tidak berguna untuk menilai nilainya.
- Kapan ia akan kembali ke non-operasi?
Ketika strategi menilai bahwa pengembalian yang dibawa oleh transaksi tidak dapat menutupi biaya penanganan, itu harus kembali ke non-operasi. Meskipun deskripsi sebelumnya menggunakan strategi berulang kali untuk menilai tren harga, itu hanya untuk kenyamanan pemahaman.
6. Pengumpulan data dan pelatihan
Seperti dalam artikel sebelumnya, metode dan format akuisisi data adalah sebagai berikut: periode satu jam K-line dari pasangan perdagangan Bitfinex Exchange BTC_USD dari 7 Mei 2018 hingga 27 Juni 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Karena penggunaan jaringan LSTM, waktu pelatihan sangat lama. Saya beralih ke versi GPU, yang sekitar tiga kali lebih cepat.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
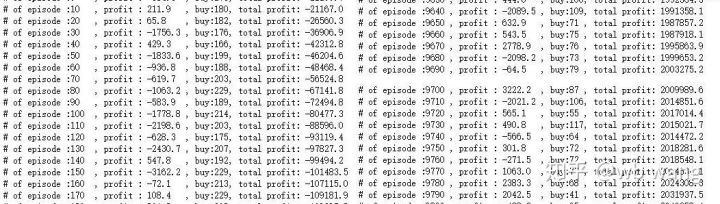
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Hasil pelatihan dan analisis
Setelah menunggu lama:

Pertama-tama, lihatlah pasar data pelatihan. Secara umum, paruh pertama adalah penurunan jangka panjang, dan paruh kedua adalah rebound yang kuat.
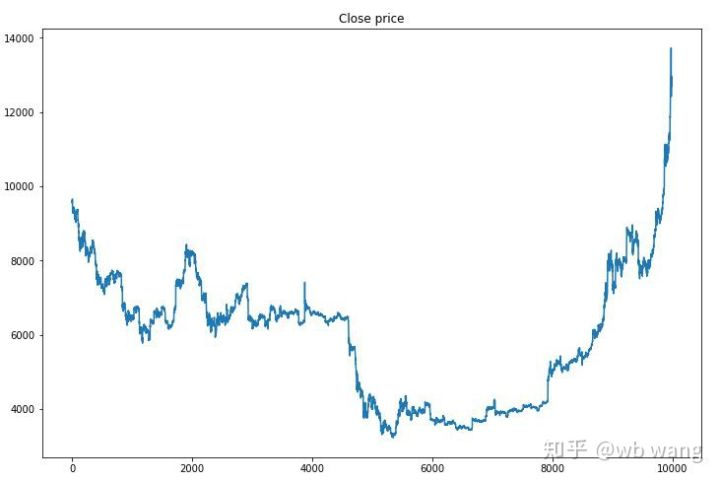
Ada banyak operasi pembelian pada tahap awal pelatihan, dan pada dasarnya tidak ada putaran yang menguntungkan. Pada pertengahan pelatihan, operasi pembelian secara bertahap menurun, dan kemungkinan keuntungan juga meningkat, tetapi masih ada kemungkinan kerugian yang besar.
Meluruskan keuntungan dari setiap putaran, dan hasilnya adalah sebagai berikut:
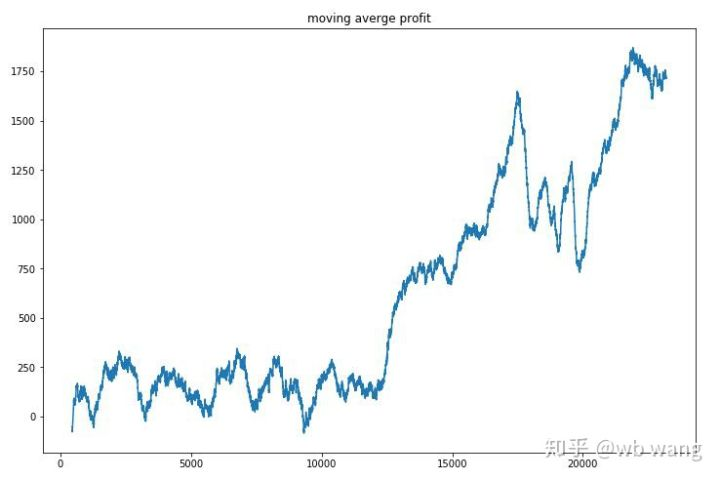
Strategi ini dengan cepat menyingkirkan situasi bahwa pengembalian awal negatif, tetapi fluktuasinya besar. pengembalian tidak tumbuh dengan cepat sampai setelah 10.000 putaran.
Setelah pelatihan akhir, biarkan model menjalankan semua data lagi untuk melihat bagaimana kinerjanya. Selama periode tersebut, catat total nilai pasar akun, jumlah Bitcoin yang dipegang, proporsi nilai Bitcoin, dan total pengembalian. Pertama adalah nilai pasar total, dan total pengembalian serupa dengan itu, mereka tidak akan diposting:
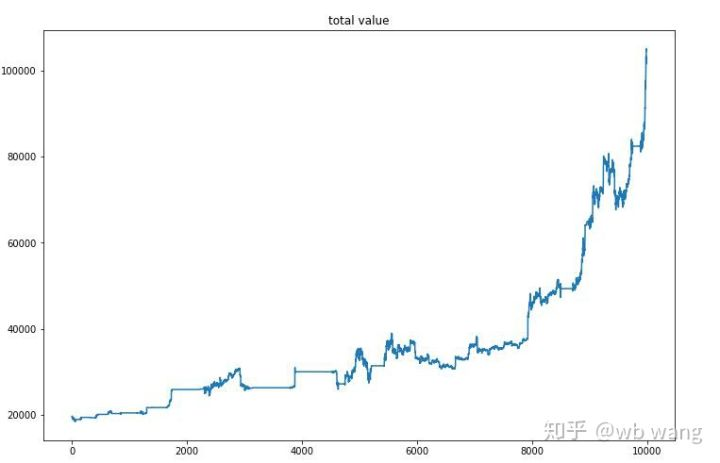
Nilai pasar total meningkat perlahan di pasar beruang awal, dan mengikuti kenaikan di pasar banteng kemudian, tetapi masih ada kerugian berkala.
Akhirnya, lihatlah proporsi posisi. sumbu kiri grafik adalah proporsi posisi, dan sumbu kanan adalah pasar. Secara awal dapat dinilai bahwa model tersebut terlalu pas. Frekuensi posisi rendah di awal pasar beruang, dan tinggi di bagian bawah pasar.
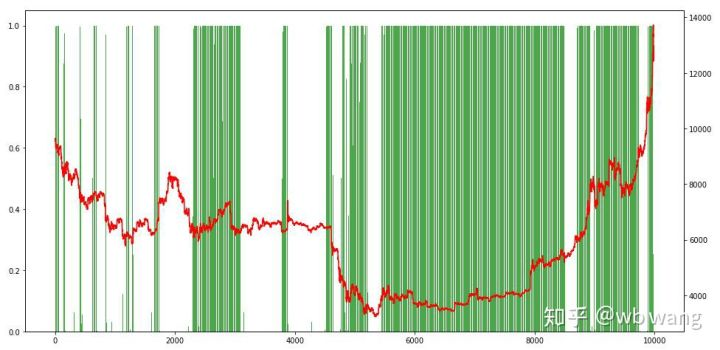
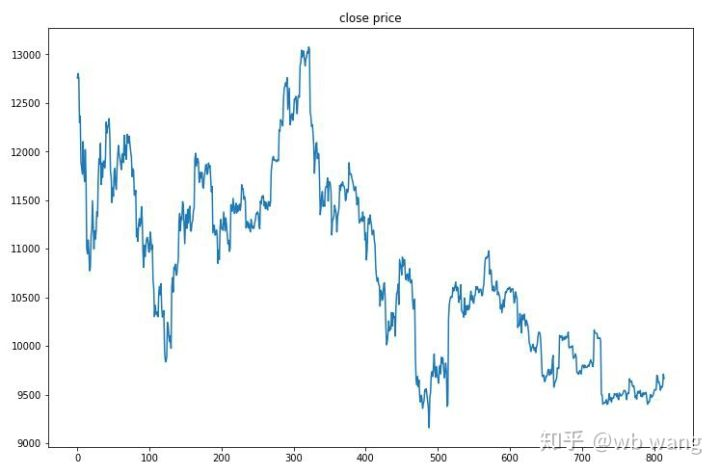
8. Analisis data uji
Pasar satu jam Bitcoin dari 27 Juni 2019 hingga sekarang diperoleh dari data tes. Dari grafik dapat dilihat bahwa harga telah turun dari $ 13.000 menjadi lebih dari $ 9.000, yang merupakan tes yang bagus untuk model.
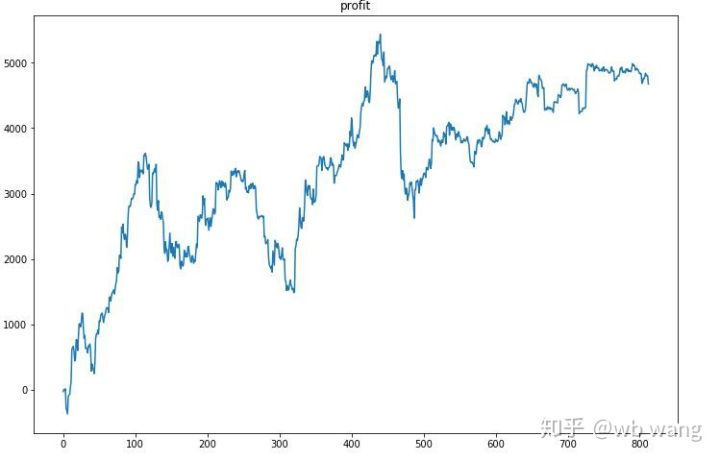
Pertama-tama, pengembalian relatif akhir dilakukan begitu-begitu, tapi tidak ada kerugian.
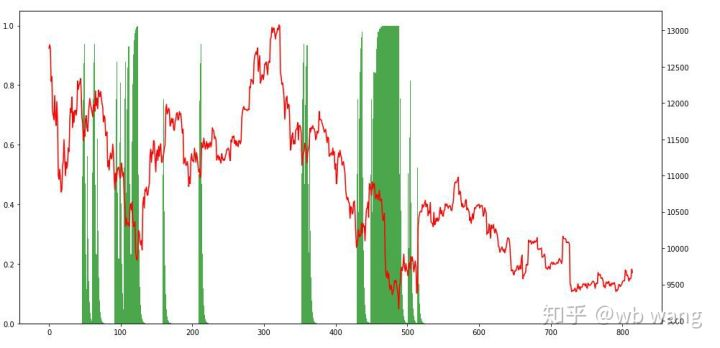
Dengan melihat situasi posisi, kita dapat menebak bahwa model cenderung membeli setelah jatuh tajam dan menjual setelah rebound.
9. Ringkasan
Dalam makalah ini, robot perdagangan otomatis Bitcoin dilatih dengan bantuan PPO, metode pembelajaran intensif yang mendalam, dan beberapa kesimpulan diperoleh. Karena waktu yang terbatas, masih ada beberapa aspek yang harus ditingkatkan dalam model. Selamat diskusi. Pelajaran terbesar adalah bahwa untuk metode standardisasi data, jangan menggunakan skala dan metode lain, jika tidak model akan dengan cepat mengingat hubungan antara harga dan pasar, dan jatuh ke dalam overfit. Tingkat perubahan standar adalah data relatif, yang membuat sulit bagi model untuk mengingat hubungan dengan pasar, dan dipaksa untuk menemukan hubungan antara tingkat perubahan dan kenaikan dan penurunan.
Pendahuluan dari artikel sebelumnya: Sebuah strategi frekuensi tinggi yang saya ungkapkan yang pernah sangat menguntungkan:https://www.fmz.com/bbs-topic/9886.
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (2)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (2)
- Pembahasan Penerimaan Sinyal Eksternal Platform FMZ: Solusi Lengkap untuk Penerimaan Sinyal dengan Layanan Http Terbina dalam Strategi
- FMZ platform eksplorasi penerimaan sinyal eksternal: strategi built-in https layanan solusi lengkap untuk penerimaan sinyal
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (1)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (1)
- Diskusi tentang Penerimaan Sinyal Eksternal dari Platform FMZ: API Terluas VS Strategi Layanan HTTP Terintegrasi
- FMZ Platform Eksternal Signal Reception: Extension API vs Strategi Layanan HTTP Terbentuk
- Diskusi tentang Metode Pengujian Strategi Berdasarkan Generator Random Ticker
- Metode pengujian strategi berdasarkan generator pasar acak
- Fitur Baru FMZ Quant: Gunakan Fungsi _Serve untuk Membuat Layanan HTTP dengan Mudah
- Tiga model potensial dalam perdagangan kuantitatif
- Sistem Perdagangan Intraday Pivot Point
- 6 Strategi dan Praktek Sederhana untuk Pemula dalam Perdagangan Kuantitatif Mata Uang Digital
- Kerangka strategi rentang rata-rata yang benar
- Praktik dan penerapan strategi termostat pada platform FMZ Quant
- Strategi perdagangan berdasarkan teori kotak, mendukung komoditas berjangka dan mata uang digital
- Strategi perdagangan kuantitatif berdasarkan harga
- Strategi perdagangan kuantitatif menggunakan indeks tertimbang volume perdagangan
- Implementasi dan penerapan strategi perdagangan PBX pada platform FMZ Quant Trading
- Berbagi akhir: Robot frekuensi tinggi Bitcoin dengan pengembalian 5% setiap hari pada tahun 2014
- Jaringan Neural dan Seri Perdagangan Kuantitatif Mata Uang Digital (1) - LSTM Memprediksi Harga Bitcoin
- Aplikasi strategi kombinasi SMA dan indeks kekuatan relatif RSI
- Pengembangan strategi CTA dan perpustakaan kelas standar dari platform FMZ Quant
- Strategi perdagangan kuantitatif dengan analisis momentum harga di Python
- Mengimplementasikan Strategi Perdagangan Kuantitatif Mata Uang Digital Dual Thrust di Python
- Cara terbaik untuk menginstal dan meningkatkan untuk Linux docker
- Mencapai strategi ekuitas yang seimbang dengan keselarasan yang teratur
- Analisis Data Seri Waktu dan Tes Balik Data Tick
- Analisis Kuantitatif Pasar Mata Uang Digital
- Perdagangan pasangan berdasarkan teknologi berbasis data