機械学習の3大カテゴリー6大アルゴリズムのメリットとデメリット
作者: リン・ハーン発明者 量化 - 微かな夢, 作成日: 2017-10-30 12:01:59, 更新日: 2017-11-08 13:55:03機械学習の3大カテゴリー6大アルゴリズムのメリットとデメリット
機械学習では,目標は予測 (prediction) やクラスタリング (clustering) である.この記事の焦点は予測である.予測は,入力変数の集合から出力変数の値を予測するプロセスである.例えば,関連する家具の特性の集合を得て,その販売価格を予測することができる.予測問題は,2つのカテゴリーに分けられる. このことを理解した上で,次に,機械学習における最も顕著で,最もよく使われるアルゴリズムを見てみましょう. これらのアルゴリズムを3つのカテゴリーに分けます. 線形モデル,樹木ベースのモデル,神経ネットワーク. 6つの一般的なアルゴリズムに焦点を当てます.
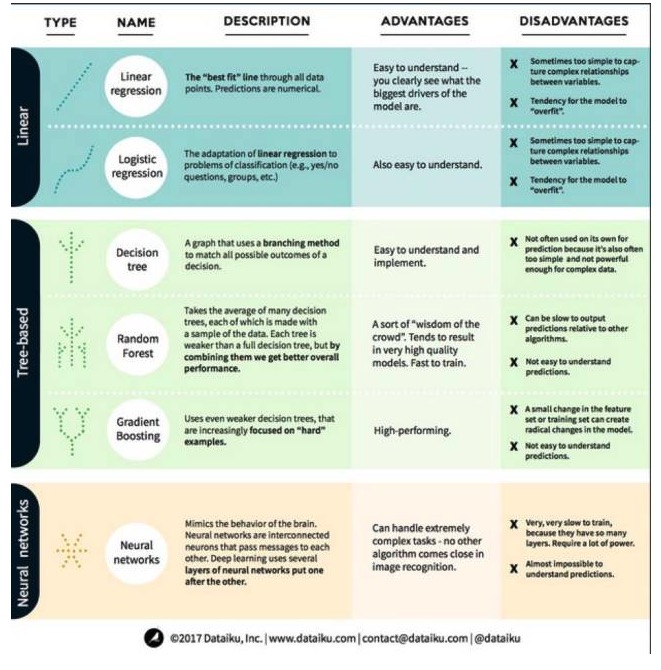
一,線形モデルのアルゴリズム:線形モデルは,簡単な式を使って,データ点の集合を介して,に最適なをみつける.この方法は200年以上前に遡り,統計学と機械学習の両分野で広く使用されている.そのシンプルさのために,それは統計学に有用である.あなたが予測したい変数 (因変数) は,あなたがすでに知っている変数 (自変数) の方程式として表されるので,予測は単に変数を入力して,方程式の答えを計算する問題である.
- 線形回転を
線形回帰,またはより正確に言うなら
線形モデルのもう一つの欠点は,非常に単純であるため,入力変数が独立していないとき,より複雑な行動を予測することが容易ではないことである.
- ####2 論理的回帰
論理回帰は,線形回帰が分類問題への適応である.論理回帰の欠点は線形回帰と同じである.論理関数は分類問題に対して非常に良い,それは
2 ツリーモデルのアルゴリズム
- ###############################################################################################################################################################################################################################################################
意思決定ツリーとは,分岐式方法を使って決定のあらゆる可能な結果を表示する図である. 例えば,サラダを注文すると決めたとき,最初の決定は,おそらく生菜の種類,次に菜菜,次にサラダの種類である.私たちはすべての可能な結果を決定ツリーで表現することができます.
意思決定ツリーを訓練するには,トレーニングデータセットを使用して,目標に最も有用な属性を特定する必要があります. 例えば,詐欺検出の例では,詐欺リスクの予測に最も影響する属性は国家であることが判明するかもしれません. 最初の属性で分岐した後,最初の属性だけが知られていると仮定すると最も正確に予測できる2つのサブセットが得られます. 次に,これらの2つのサブセットに分岐できる第2の良い属性を再利用し,再分割を行います. そして,十分な属性があれば目標のニーズを満たすまで繰り返します.
- ####2 ランダムな森
ランダムな森は,多くの意思決定樹の平均であり,それぞれの意思決定樹はランダムなデータサンプルで訓練されている.ランダムな森のそれぞれの樹は,完全な意思決定樹よりも弱いが,すべての樹を一緒にすると,多様性の優位性により,よりよい全体的な性能を得ることができる.
ランダムフォレストは,今日機械学習で非常に人気のあるアルゴリズムである.ランダムフォレストは,訓練が容易で,かなりうまく機能している.その欠点は,他のアルゴリズムと比較して,ランダムフォレストの出力予測は遅い可能性があるため,急速な予測が必要な場合,ランダムフォレストを選択しない可能性があるということだ.
- ####3 昇降する
梯度増強 (GradientBoosting) は,ランダムな森林のように弱小な
梯度アップのトレーニングも迅速で,非常に良いパフォーマンスである.しかし,トレーニングデータセットの小さな変更はモデルに根本的な変化をもたらす可能性があるため,その結果が最も実行可能ではない可能性があります.
3 ニューラルネットワークアルゴリズム:ニューラルネットワークは,脳内のニューロンで構成される生物学的現象で,脳内のニューロン同士が相互に情報を交換する.この考えは,今や機械学習分野にも適用され,ANN (人工ニューラルネットワーク) と呼ばれている.深層学習は,重ねた複数の層のニューラルネットワークである.ANNは,学習によって人間の脳に似た認知能力を獲得するモデルの一種である.
ビッグデータ・プレイスから
- 発明者による量化 huobiとOKEXのコイン取引とUSDT取引をサポートする?
- デジタル通貨の取引庫に統合された公的な返済機能
- 戦略の収益や変動などのデータを 量化して その戦略の最大資金容量を 計算するにはどうすればいいですか?
- シャノンの悪魔
- 複雑なのは技術ではなく,人間の心です! 取引能力は取引システムとマッチする必要があります.
- Bitfinexのインターフェイスへのアクセスが遅いです. サーバーの配置について,皆さんの意見はありますか?
- Bitfinexはエラーで動いています. 分析を手伝って下さい. ありがとうございました.
- 復習時に呼び出すAPIが取得したデータは,どの時間点に基づいているのですか?
- 仮想通貨のコードを求めます.
- Bitfinexの取引ペアには,BCH_USD,BTC_USD,ETH_USD,LTC_USDが4種類しかないのはなぜか.
- 爆破5000円:BTCを増やし,空きokex1229契約,1ヶ月で,コイン毎5000円!
- 究極の監視機構
- 報告 バグ: ポリシー作成時にデフォルトのパラメータ値がないインタラクションボタンが保存失敗
- 返信システムで他の通貨を選択できないか?
- 購入プランのページを翻訳してください.
- Bitfinexには3つの市場があります. ロボットにどのように選択させるか?
- ダイナミックな視点で選択肢は共赢
- bitfinexの反測と検証通貨単位が一致しない
- 背信と金
の有効性についてどう考えるか? - Bithumbはアカウント情報を入手したエラー