ランダム市場生成器に基づく戦略テスト方法について
作者: リン・ハーン発明者 量化 - 微かな夢, 作成: 2024-11-29 16:35:44, 更新: 2024-12-02 09:12:43[TOC]

前言
発明者による量化取引プラットフォームのリトゲーションシステムは,リトゲーションシステムの継続的な更新とアップグレードであり,初期的な基本的なリトゲーション機能から機能や性能を徐々に増やし,最適化します. プラットフォームの発展とともにリトゲーションシステムが継続的に最適化され,今日,リトゲーションシステムに基づくテーマについて探します: "ランダム市場に基づく戦略テスト".
需要
量化取引の分野では,戦略の開発と最適化の検証は,実際の市場データから分離できない.しかし,実用的な応用では,市場環境が複雑で多変しているため,極端な市場や特殊なシナリオへのカバー不足などの歴史的データに依存した再測が不足することがあります.したがって,効率的なランダムな行情生成器を設計することは量化戦略開発者の有効なツールになります.
取引所や通貨の歴史を遡る戦略を必要とする場合,FMZプラットフォームの公式データソースを使用して再テストすることができます. 時には,完全に知らない市場で戦略がどのように機能するか見たい場合もあります.
ランダムな市場データを使用すると,次の意味があります:
-
- 戦略の強さを評価する ランダムな市場ジェネレーターは,極端な波動,低波動,トレンド市場,波動市場など,さまざまな可能な市場シナリオを作成することができる.これらの模擬環境で戦略をテストすることは,異なる市場条件下で安定しているかどうかを評価するのに役立ちます.例えば:
戦略は動向と変動に適応できるのか? 戦略は極端な市場では大きな損失をもたらすのか?
-
- 戦略の潜在的弱点を認識する 戦略の潜在的弱点を発見し,改善を行うには,いくつかの異常な市場状況 (例えば,仮のブラック・スワン事件) をシミュレートすることが可能である.例えば:
戦略は市場構造に過度に依存するのでしょうか? 参数が過度に適合するリスクはありますか?
-
- 戦略パラメータを最適化 ランダムに生成されたデータは,戦略パラメータ調整のために,完全に歴史的データに依存する必要のない,より多様なテスト環境を提供します.これは,戦略のパラメータ範囲をより包括的に見つけ,歴史的なデータ内の特定の市場パターンに限定されないようにします.
-
- 歴史の不十分を補う 一部の市場 (例えば,新興市場または小通貨取引市場) では,歴史的なデータがすべての可能な市場状況をカバーするのに不十分である可能性があります.ランダムな市場生成器は,より包括的なテストを行うのに役立つ大量の補充データを提供できます.
-
- スピード・アイレリゼーション開発 ランダムなデータを使って迅速なテストを行うことで,リアルタイムな市場状況や時間がかかるデータ清掃と整理に頼ることなく,戦略開発のイラスト速度を高速化することができます.
しかし,合理的な評価戦略も必要であり,ランダムに生成された市場データについては注意点があります.
- 1 ランダムな行情生成器が有用であるにもかかわらず,その意味は生成されたデータの質とターゲットシナリオの設計に依存します:
- 2,生成ロジックは現実市場に近いもので,ランダムに生成された市場が現実から完全に切り離されている場合,テスト結果は参照値が欠けている可能性があります.例えば,実際の市場統計特性を (例えば波動率分布,トレンド比率) 組み合わせて生成物を設計することができます.
- 3. リアルデータテストを完全に代用できない:ランダムデータは戦略の開発と最適化に補完するのみで,最終戦略は,実際の市場データで有効性を検証する必要がある.
簡単に,速く,使いやすい方法で,データを作り出し,復習システムで使えるようにするにはどうすればいいのか?
デザインのアイデア
本文は,比較的に簡素なランダム行情生成計算を提示するために,この項目の設計を投げかけています.実際には,さまざまな模擬アルゴリズムやデータモデルなどの技術が適用され,特に複雑なデータ模擬方法を使用しないため,議論の範囲は限られています.
プラットフォームの回帰システムのカスタムデータソース機能と組み合わせて,Pythonでプログラムを作成しました.
- 1, K線データの一組をCSVファイルに書き込み,生成されたデータを記録することができるように,ランダムに生成する.
- 2、その後,データ源をサポートするサービスを作成します.
- 3、生成されたK線データをグラフで表示する.
K線データの生成基準,ファイル保存などには,以下のパラメータ制御が定義される.
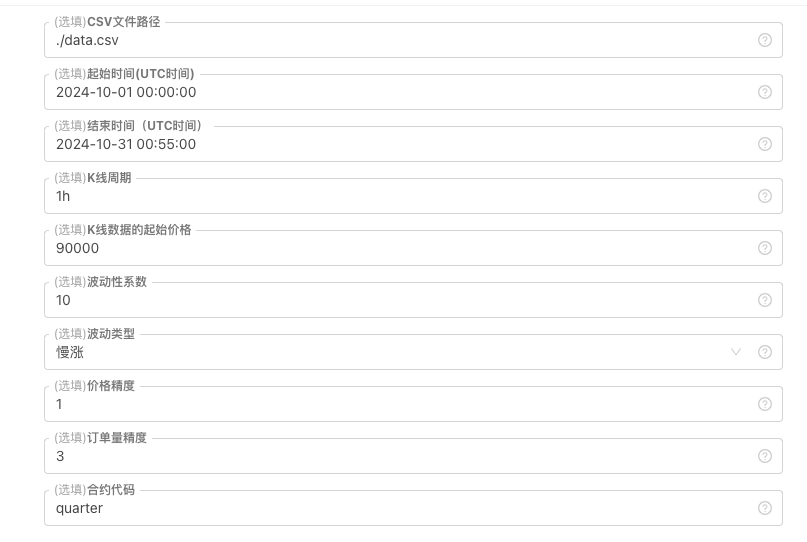
-
データをランダムに生成するパターン K線データを模倣する波動型については,単にランダム数と正の負の確率の違いを単純に使うだけで,生成されたデータが少ない場合,必要な行事のパターンを反映できないかもしれない.より良い方法があれば,このコードの一部を入れ替えることができる. このシンプルなデザインに基づいて,コード内のランダム数生成範囲といくつかの係数を変更することで,生成されたデータ効果に影響を与えることができる.
-
データチェック 生成されたK線データの合理性検査も必要であり,高値低値値が定義に反するかどうかをチェックし,K線データの連続性をチェックするなどである.
復習システム ランダム行情生成器
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
復習システムでの実践
1、上記のポリシーインスタンスを作成,パラメータを配置,実行する. 2, リアルディスク (政策例) は,サーバーに配置されたホストで実行する必要があります. データを取得するには,公共のIPが必要です. 3 インタラクションボタンをクリックすると,戦略は自動的にランダムな市場データを生成します.

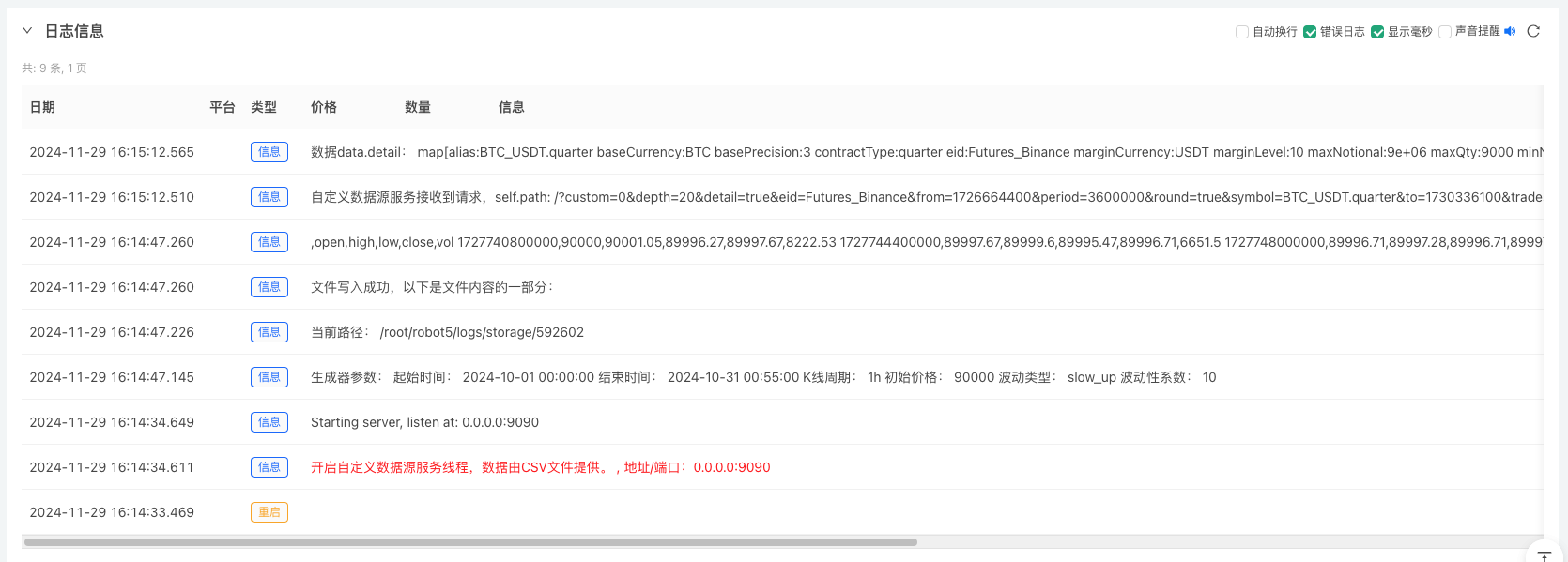
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
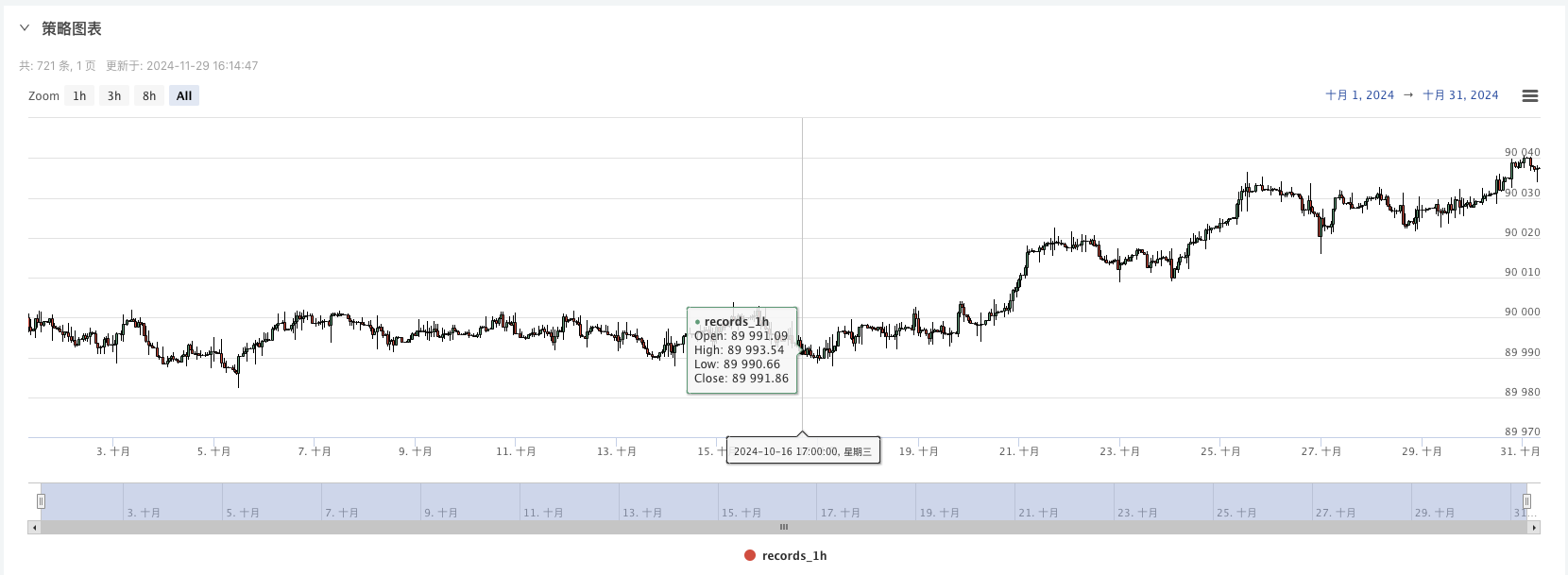
ランダムに生成されたデータを使って, 任意の戦略で復習することができます.
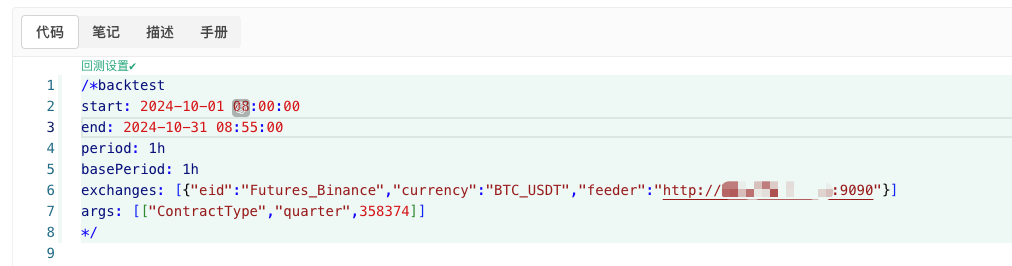
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
詳細は,この記事のページに掲載されています.http://xxx.xxx.xxx.xxx:9090ランダムに生成されたポリシー実盤のサーバーIPアドレスと開いたポートである.
これはカスタムデータソースです. プラットフォームAPIのドキュメントのカスタムデータソースセクションで調べることができます.
6 復習システムで適切なデータ源を設定すると,ランダムな行情データをテストできます.
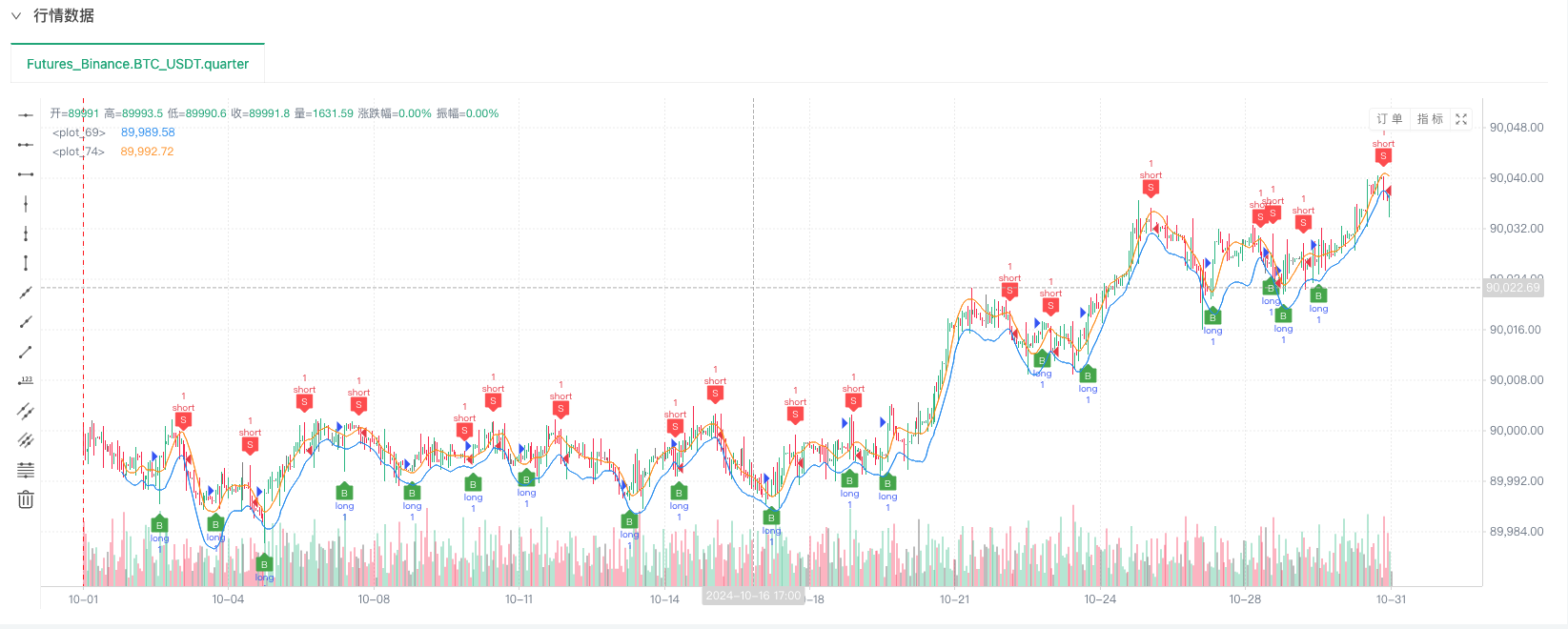
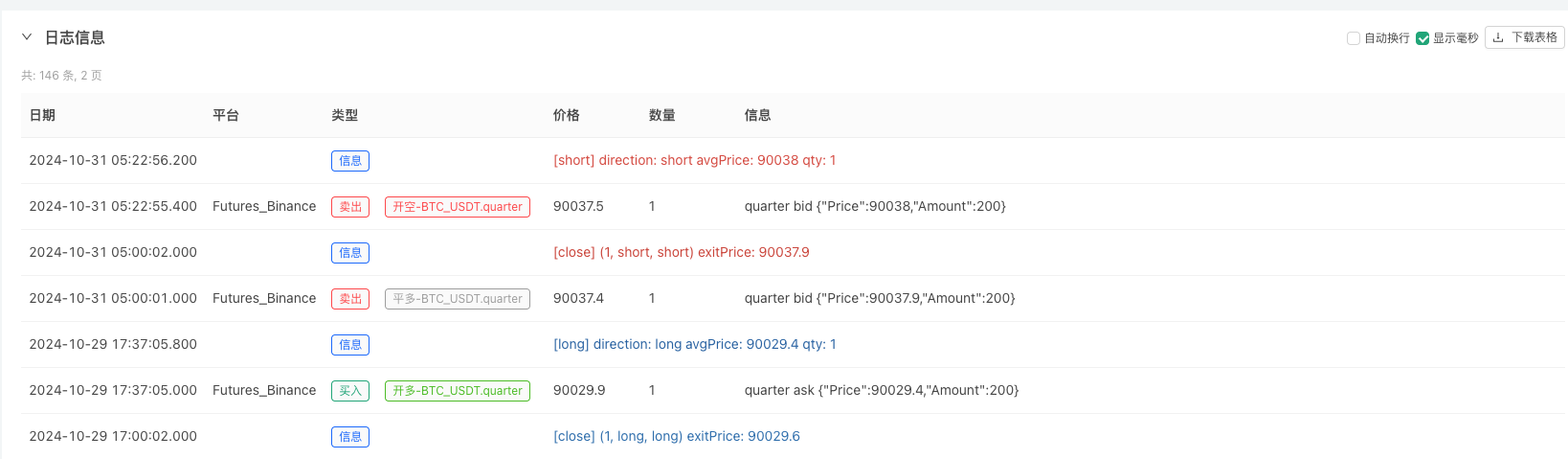
このとき,回測システムは,我々の
7、ああそう,ほぼ忘れてしまった!このランダムな行程生成器のpythonプログラムは,実演,操作,生成されたK線データを表示する便利のために実盘を作成する.実際のアプリケーションでは,独立したpythonスクリプトを完全に書くことができ,実盘を実行する必要はありません.
戦略のソースコード:復習システム ランダム行情生成器
支持と読書ありがとうございました.
- デジタル通貨におけるリード-ラグ套路の紹介 (3)
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (2)
- デジタル通貨におけるリード-ラグ套路の紹介 (2)
- FMZプラットフォームの外部信号受信に関する議論: 戦略におけるHttpサービス内蔵の信号受信のための完全なソリューション
- FMZプラットフォームの外部信号受信に関する探求:戦略内蔵Httpサービス信号受信の完全な方案
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (1)
- デジタル通貨におけるリード-ラグ套路の紹介 (1)
- FMZプラットフォームの外部信号受信に関する議論:拡張API VS戦略内蔵HTTPサービス
- FMZプラットフォームの外部信号受信に関する探究:拡張API vs 戦略内蔵HTTPサービス
- ランダム・ティッカー・ジェネレーターに基づく戦略テスト方法に関する議論
- FMZ Quant の新しい機能: _Serve 機能を使用して HTTP サービスを簡単に作成する
- 発明者による新機能の量化: _Serve関数を使用して簡単にHTTPサービスを作成する
- FMZ 量子取引プラットフォーム カスタム プロトコル アクセスガイド
- FMZ 資金調達の利子獲得と監視戦略
- FMZの資金調達・監視戦略
- WebSocket Market をシームレスに利用できるようにする戦略テンプレート
- ウェブソケットをシームレスに使える ポリシーテンプレート
- 発明者定量化取引プラットフォームの通用プロトコルへのアクセスガイド
- FMZのアップグレード後に迅速にユニバーサルマルチ通貨取引戦略を構築する方法
- FMZのアップグレード後,一般的な多通貨取引戦略を迅速に構築する方法