ビットコインの取引ロボットの作成
作者: リン・ハーン優しさ作成日:2019年06月27日 10:58:40 更新日:2024年12月24日 20:16:45
デジタル通貨取引ロボットを作るために 強化学習をAIに活用しましょう
この記事では,Bitcoin取引ロボットの作成方法を学ぶために,強化学習
OpenAIとDeepMindが過去数年間,ディープラーニング研究者に提供してきたオープンソースソフトウェアに感謝します. AlphaGo,OpenAI Five,AlphaStarなどの技術で彼らが成し遂げた驚くべき成果をまだ見ていないなら,あなたは去年ずっと隔離生活を送っていたかもしれません.
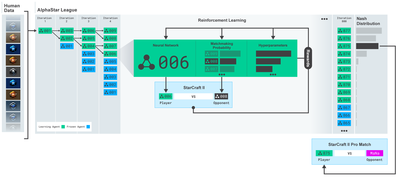
アルファスター訓練https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
しかし,テディ・ルーズフォードがかつて言ったように,ビットコインの取引は,日常的な取引において,簡単ではありません.
簡単に手に入るものは価値がない.
自動取引を学ぶだけでなく...ロボットが私たちの代わりに取引することを学ぶ必要があります.
計画

1.为我们的机器人创建gym环境以供其进行机器学习
2.渲染一个简单而优雅的可视化环境
3.训练我们的机器人,使其学习一个可获利的交易策略
もし,ジム環境を最初からどのように作るか,あるいは,これらの環境を単純にどのように映し出すかを知らないのであれば,これらをGoogleで調べて下さい.
入り口
在本教程中,我们将使用Zielak生成的Kaggle数据集。如果您想下载源代码,我的Github仓库中会提供,同时也有.csv数据文件。好的,让我们开始吧。
まず,必要なすべてのライブラリをインポートしましょう. Pipで欠けているライブラリをインストールしてください.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
次に,環境のために自分のクラスを作成します. パンダのデータベクトルを入力し,オプションの initial_balance と lookback_window_size を入力し,ロボットがそれぞれのステップで観察した過去時間のステップを指示します. 取引毎の手数料をデフォルトで0.075%,つまりBitmexの現在の為替レートとして設定し,文字列参数をデフォルトでfalseとして設定します.
また,dropna (注) とreset_index (注) を呼び出し, NaN の値を持つ行を削除し,データを削除したため,
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
選択肢の1つのグループ (買おう,売ろう,持っていこう) と10のグループ (1/10) の間で,2⁄103/10など) 買おうとすると,buy amount * self.balance worth of BTC を使います.売ろうとすると,sell amount * self.btc_held worth of BTC を使います.もちろん,持てるとすると,その金額を無視して何もしません.
私たちのobservation_spaceは0から1の間の連続した浮点集合として定義され,その形は ((10,lookback_window_size + 1) ー + 1です. 現在のタイムスケープを計算するために使用されます. ウィンドウ内の各タイムスケープに対して,OHCLV値を観察します.
次に,環境を初期化するために,リセット方法を書く必要があります.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
この例では,self._reset_session とself._next_observation を使いますが,定義されていません.
取引会談
我们环境的一个重要部分是交易会话的概念。如果我们将这个机器人部署到市场外,我们可能永远不会一次运行它超过几个月。出于这个原因,我们将限制self.df中连续帧数的数量,也就是我们的机器人连续一次能看到的帧数。
この方法では,まず,current_step を 0 にリセットします.次に, steps_left を 1 から MAX_TRADING_SESSION までのランダムな数値に設定します.
MAX_TRADING_SESSION = 100000 # ~2个月
次は,連続的に回転をしたい場合は,全回転を設定する必要があります. そうでなければ,frame_start をself.df のランダムな点に設定し,新しいデータ回転を active_df と呼び,それはframe_start からframe_start + steps_left までのself.df の切片です.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
ランダムな切片でデータキット数を横切る重要な副作用は,私たちのロボットは長時間の訓練のために使用するためのより多くのユニークなデータを持つことです.例えば,私たちがデータキットを連続的に横切るだけであれば (すなわち0からlen (fdf) の順序),私たちはデータキット数と同じ数の単一のデータポイントしか持たないでしょう.私たちの観測空間は,各時間ステップで離散数値のみの状態さえ採用します.
しかし,データセットをランダムに切断することで,最初のデータセットの各時間軸に,より意味のある取引結果集合を作成できます. つまり,取引行動と以前に見た価格行動の組み合わせにより,よりユニークなデータセットを作ることができます. 例を挙げて説明します.
連続環境をリセットした後の時間ステップは10で,私たちのロボットは常にデータセット内で同時に動作し,各時間ステップ後に3つの選択があります. 購入,売却,または保持. これらの3つの選択肢のそれぞれには,10%,20%,......または100%の特定の実用性のある別の選択が必要です. これは,私たちのロボットは103の10回のうちのいずれかの状態に遭遇する可能性があり,合計1030の状況です.
現在,我々のランダム切片の環境に戻ります. 10 時間のスケープでは,我々のロボットがデータ回数内の任意の len (df) タイムスケープの中にいる可能性があります. 各タイムスケープの後も同じ選択を行うことを仮定すると,同じ 10 時間のスケープの中で,このロボットが任意の len (df) の 30 秒間の唯一状態を経験することがあります.
大規模なデータセットに相当な騒音をもたらすかもしれませんが,ロボットが私たちの限られたデータからより多くのことを学ぶことを許すべきだと私は信じています.私たちはまだ,アルゴリズムの有効性によってより正確な理解を得るために,最新の,リアルタイムで
ロボットの目で見たもの
効果的な視覚環境を観察することで,私たちのロボットが使用する機能の種類を理解することがしばしば役立ちます.例えば,ここではOpenCV染色を使用した観察可能な空間の可視化です.

OpenCVのビジュアライゼーション環境の観察
画像の各行は,私たちのobservation_space内の1行を表しています.前4行の類似周波数の赤い線はOHCLデータを表し,下にあるオレンジと黄色い点が取引量を表します.下にある波動する青い線はロボットによる純額であり,下にある軽い線はロボットによる取引を表します.
注意深く観察すれば,自分でもシミュレーションを作成することもできます. 取引量バーの下には,取引履歴を示すモールスコードのようなインターフェースがあります. 私たちのロボットは,私たちのobservation_spaceのデータから十分に学ぶことができると見えます.
- 重要なことは,ロボットがこれまで観測したデータだけを拡張して,超前向き偏差を防ぐことです.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
行動する
観察空間を確立し,今度は梯子の関数を書いて,ロボットに指示された動作を行う時間です. 当時の取引時間のself.steps_left == 0 のたびに,私たちは持っていたBTCを売却し,リセットsession ((() ;;そうでなければ, reward を現在の純額に設定し,done を True に設定します.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
取引行動をとることは,現在の_価格を取得し,実行すべき行動と,購入または販売する数値を決定するほど簡単です.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
最后,在同一方法中,我们会将交易附加到self.trades并更新我们的净值和账户历史。
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
私たちのロボットは,新しい環境を起動し,その環境を段階的に完成させ,環境に影響を与える操作を行うことができます.
ロボット取引を見てください
染色法はprint (self.net_worth) を呼び出すほど簡単ですが,それだけでは面白くありません.代わりに,取引量
我们将从我上一篇文章中获取StockTradingGraph.py中的代码,并重新设计它以适应比特币环境。你可以从我的Github中获取代码。
まず,self.df [
from datetime import datetime
まず,datetimeを輸入し,その後,utcfromtimestampmethodを使用して,各時間軸とstrftimeからUTC文字列を取得し,Y-m-d H:M形式の文字列にフォーマットします.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
最後に,self.df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
ワオ!私たちは今,ロボットがビットコインを取引するのを見ることができます.

取引をMatplotlibで視覚化する
緑の幻のタグはBTCの購入,赤の幻のタグは販売を代表します. 右上の白いタグはボットの現在の純額,右下のラベルはビットコインの現在の価格です. シンプルでエレガントです.
訓練時間
前回の記事で私が受けた批判の一つは,データをトレーニングセットとテストセットに分割していないため,クロス検証が不足していることでした.この目的は,これまで見られなかった新しいデータに対する最終モデルの正確性をテストすることです.これは記事の焦点ではありませんが,非常に重要です.私たちは時間列データを使用しているため,クロス検証に関してはあまり選択肢がありません.
例えば,一般的なクロス検証形態は,k-fold検証と呼ばれるもので,データをkつの等しいグループに分割し,それぞれをテストグループとして,1つのグループを個別に使用し,残りのデータをトレーニンググループとして使用します.しかし,タイムシーケンスデータは高度に時間に依存しているため,後のデータは高度に前のデータに依存している.したがって,k-foldは機能しないので,私たちのロボットは取引の前に将来のデータから学習するので,これは不公平な利点です.
タイムシーケンスデータに適用すると,同じ欠陥が他のほとんどのクロス検証戦略にも当てはまります.したがって,私たちは単に完全なデータ
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
次に,私たちの環境は単一のデータ回数を処理するだけ設定されているので,私たちは2つの環境を作成します. 1つはトレーニングデータ,もう1つはテストデータ.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
现在,训练我们的模型就像使用我们的环境创建机器人并调用model.learn一样简单。
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
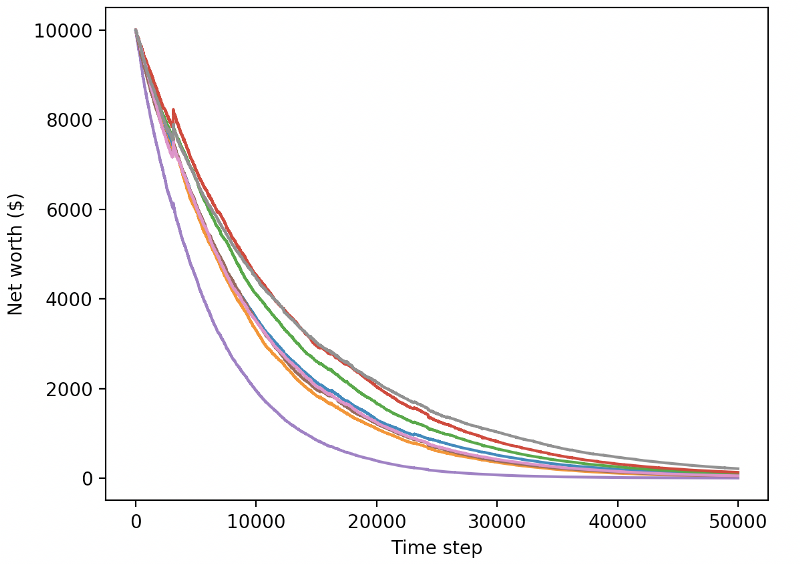
ここでは,張力表を使用しているので,私たちの張力フローグラフを簡単に視覚化し,私たちのロボットに関するいくつかの定量指標を見ることができます.例えば,以下は,多くのロボットが200,000以上の時間歩を走った値下げ報酬のグラフです.
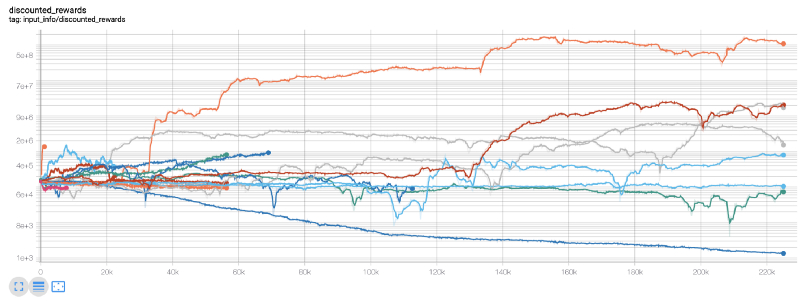
200万歩で"000倍のバランスを達成し,残りの平均を少なくとも30倍に増やすことができる!
このとき,私は環境に間違いがあることに気づきました...その間違いを修正した後,これは新しい報酬グラフです:
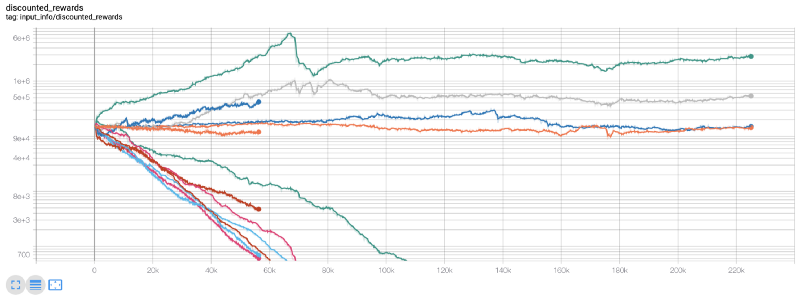
ご覧の通り,私たちのロボットのいくつかはうまくやっていて,残りは自発的に破産します. しかし,良いロボットは,最初のバランスの10倍,あるいは60倍まで到達します. 私は認めなければならない,すべての有利なロボットは,手数料なしで訓練とテストを受け,私たちのロボットは,本当のお金を稼ぐことは不可能です. しかし,少なくとも我々は方向性を見つけました!
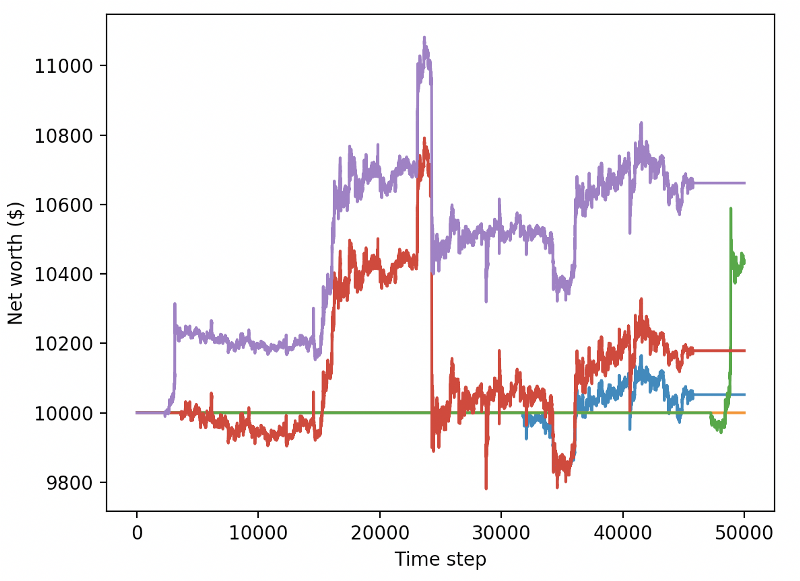
実験環境でロボットをテストしてみましょう (以前には見たことのない新しいデータを使って) 実験がどうなっていくか.
訓練されたロボットが 新しいテストデータと取引する際に破産します
明らかに,私たちはまだ多くの作業をしなければならない. モデルを単に現在のPPO2ロボットではなく安定した基線のA2Cを使用するように切り替えたら,このデータセットでのパフォーマンスを大幅に向上させることができます. 最後に,Sean O'Gormanの提案に従って,私たちは報酬機能をわずかに更新することができ,高純度で報酬を増やし,単に高純度を達成してそこに留まるのではなく,
reward = self.net_worth - prev_net_worth
この2つの変更だけで,テストデータセットの性能が大幅に向上し,訓練データセットに欠けている新しいデータから利益を得ることができました.
しかし,我々はもっとうまくやれる.これらの結果を改善するために,我々は超パラメータを最適化し,ロボットに長い時間を訓練する必要がある.GPUを稼働させ,火力満開にする時が来た.
ここまで,この記事は少し長くなりましたが,まだ多くの詳細を考慮する必要があるので,ここで休むつもりです. 次の記事では,ベイエス最適化を使用して,私たちの問題空間に最適な超パラメータを区分し,CUDAを使用してGPUでトレーニング/テストを準備します.
結論
この記事では,強化学習を使って,ゼロから収益性の高いビットコイン取引ロボットを作成します.
1.使用OpenAI的gym从零开始创建比特币交易环境。
2.使用Matplotlib构建该环境的可视化。
3.使用简单的交叉验证对我们的机器人进行训练和测试。
4.略微调整我们的机器人以实现盈利
私たちの取引ロボットは,私たちが望んでいたほど利益を得ていないが,私たちは正しい方向に向かっている.次回は,私たちのロボットが常に市場を倒せるようにし,私たちの取引ロボットのリアルタイムデータ処理方法を見るようにする.私の次の記事,そしてBitcoinに祝福を!
- DEX取引所の定量実践 (2) -- ハイパーリキッドユーザーガイド
- DEX取引所の量化実践 (2) -- Hyperliquidの使用ガイド
- DEX取引所の定量実践 (1) -- dYdX v4 ユーザーガイド
- 暗号通貨におけるリード・レイグ・アービトラージへの導入 (3)
- DEX取引所の量化実践 ((1)-- dYdX v4 ユーザーガイド
- デジタル通貨におけるリード-ラグ套路の紹介 (3)
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (2)
- デジタル通貨におけるリード-ラグ套路の紹介 (2)
- FMZプラットフォームの外部信号受信に関する議論: 戦略におけるHttpサービス内蔵の信号受信のための完全なソリューション
- FMZプラットフォームの外部信号受信に関する探求:戦略内蔵Httpサービス信号受信の完全な方案
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (1)
- デジタル通貨自適性均線取引システムとKAMAアルゴリズム解析パック 発明者ベースの定量化取引ソフトウェア
- FMZの発明者 定量化プラットフォーム 復習説明
移動平均線 操作の簡単なデモンストレーション (My language version) - 産業大廈がアルゴリズム取引を明らかに:発明家が市場戦略として定量化プラットフォーム
- DMI指標の計算と応用
- SPYとIWM間の均等値回帰を利用した日中取引戦略
- アロン (Aroon) 技術指標の量化取引における応用
- JavaScript を使って量化ポリシーを同時に実行する
包装 Go 機能 - 19人の専門家がデジタル通貨取引に関するアドバイスをシェア
- デジタル通貨における
香ノンの魔法の応用 - 取引量化から資産管理へのCTA戦略開発
- 取引の9つのルールは,1年以内に1千ドルから4万6千ドルに成長させるのに役立ちます
- 発明者による量化取引の紹介 - 基礎から実戦まで
- 5.5 取引戦略の最適化
- 5.4 なぜ抽出外試験が必要なのか
- 5.3 戦略バックテストの業績報告の読み方
- 5.2 定量的な取引のバックテストをどのように行うか
- 5.1 バックテストの意味と罠
- 4.6 C++言語で戦略を実装する方法
- 4.5 C++ 言語 早いスタート