暗号通貨ファクターモデル
 12
12172
12
12172
[TOC]

因子モデルフレームワーク
株式市場のマルチファクターモデルについては、豊富な理論と実践に基づいた研究レポートが数多くあります。デジタル通貨市場は、通貨数、市場総額、取引量、デリバティブ市場の面で要因研究に十分である。この記事は主に定量戦略の初心者を対象としており、複雑な数学的原理や統計分析は取り上げません。先物市場をデータソースとして利用することで、因子指標の評価を容易にするシンプルな因子研究フレームワークが構築されます。
ファクターは指標として捉えられ、式として記述することができます。ファクターは継続的に変化し、将来のリターン情報を反映します。通常、ファクターは投資ロジックを表します。
例えば、終値ファクターは、株価が将来のリターンを予測できるという仮定に基づいています。株価が高ければ、将来のリターンは高くなります(または低くなります)。このファクターに基づいてポートフォリオを構築することは、実際には投資です。定期的にポジションをローテーションして高値の株を買うモデル/戦略。一般的に、継続的に超過収益を生み出すことができる要因は、アルファと呼ばれることがよくあります。例えば、時価総額ファクターやモメンタムファクターは、学界や投資コミュニティによって有効なファクターであることが検証されています。
株式市場であろうとデジタル通貨市場であろうと、それは複雑なシステムです。将来の収益を完全に予測できる要素はありませんが、それでもある程度の予測可能性はあります。投資資金が増えるにつれて、実効アルファ(投資モデル)は徐々に効果が低下します。しかし、このプロセスにより市場に他のモデルが生成され、新たなアルファが誕生することになります。時価総額ファクターは、かつてA株市場で非常に効果的な戦略でした。時価総額が最も低い10銘柄を購入し、1日1回調整するだけです。2007年からの10年間のバックテストでは、400倍以上のリターンが得られ、市場全体を上回る。しかし、2017年の優良株式市場では、小型時価総額ファクターの無効性が反映され、代わりにバリューファクターが人気を博しました。そのため、アルファの検証と使用の間で常にバランスを取り、実験する必要があります。
私たちが求める要素は戦略を立てるための基礎となります。関連性のない複数の効果的な要素を組み合わせることで、より良い戦略を構築することができます。
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
データソース
現在までに、2022年の初めから現在までのBinance USDT永久先物の1時間ごとのKラインデータは150通貨を超えています。前述したように、ファクターモデルは特定の通貨だけでなくすべての通貨を対象とする通貨選択モデルです。 Kラインデータには、始値と終値の高値、取引量、取引数、アクティブな購入量などのデータが含まれます。これらのデータは、米国株価指数、金利上昇期待など、すべての要因のソースではありません。 、収益性、オンチェーンデータ、ソーシャルメディアの注目度など。あまり人気のないデータソースでも有効なアルファが明らかになる場合がありますが、基本的なボリュームと価格のデータでも十分です。
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
Out:
153
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
まず、K ライン データから、終値、始値、取引量、取引数、アクティブ購入比率などの関心のあるデータを抽出し、これらのデータを基に必要な要素を処理します。
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
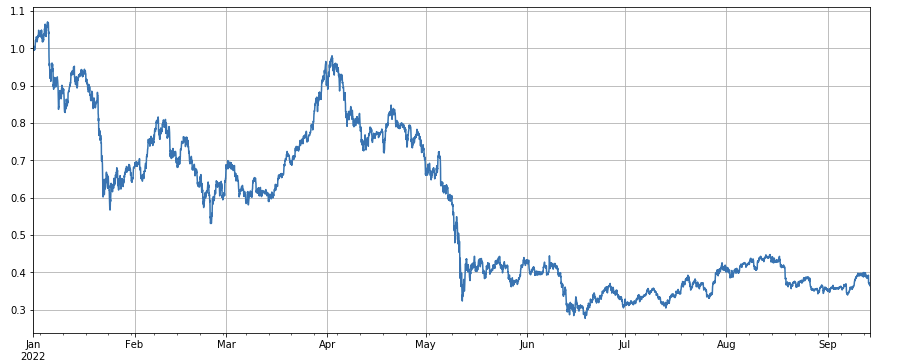
市場指数の動向を見ると、年初から60%下落しており、かなり厳しい状況にあると言えます。
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
因子妥当性の判定
回帰法 次の期間の収益率を従属変数とし、テストする要因を独立変数とし、回帰によって得られる係数がその要因の収益率となります。回帰式を構築した後、通常は係数t値の絶対平均、係数t値が2より大きい絶対値シーケンスの割合、年間ファクターリターン、年間ファクターリターンボラティリティ、シャープ比を参照します。ファクターリターンとその他のパラメータ。ファクターの有効性とボラティリティ。一度に複数の要因を回帰することができます。詳細については、barra のドキュメントを参照してください。
IC、IRおよびその他の指標 いわゆる IC は、ファクターと次の期間の収益率との相関係数です。現在一般的に使用されているのは、ファクターランキングと次の期間の株式収益率との相関係数である RANK_IC です。 IR は通常、IC シーケンスの平均/IC シーケンスの標準偏差です。
階層的回帰 この記事では、テストする要素を分類し、通貨を N グループに分割してグループ バックテストを行い、固定期間を使用してポジションを調整するというこの方法を使用します。状況が理想的であれば、N グループの通貨の利回りは良好な単調性を示し、単調に増加または減少し、各グループ間の利回りの差は大きくなります。こうした要素は、より優れた識別力に反映されます。最初のグループの収益が最も高く、最後のグループの収益が最も低い場合は、最初のグループでロングポジションを取り、最後のグループでショートポジションを取ります。最終的な収益率は、シャープレシオの参照指標です。
実際のバックテスト操作
要因に応じて、選択された通貨は小さいものから大きいものまで3つのグループに分けられます。各通貨グループは約1/3を占めています。要因が有効である場合、各グループの割合が小さいほど、利回りは高いが、各通貨に割り当てられた資金が比較的大きいことも意味します。ロングポジションとショートポジションがそれぞれ1倍のレバレッジで、最初のグループと最後のグループがそれぞれ10通貨の場合、それぞれが10%を占めます。ショートが上昇した場合、投資額が2倍に増えるとリトレースメントは20%になります。同様に、グループ数が50の場合、リトレースメントは4%になります。通貨を多様化することでブラックスワンのリスクを軽減できます。最初のグループ(係数値が最も小さい)をロングし、3 番目のグループをショートします。係数が大きいほどリターンが高くなる場合は、ロングポジションとショートポジションを逆にするか、係数を単純にマイナスまたは逆にすることができます。
要因の予測力は通常、最終的なバックテストのリターンとシャープ比に基づいて大まかに評価できます。また、ファクターの表現が単純かどうか、グループ分けの大きさに鈍感かどうか、ポジション調整間隔に鈍感かどうか、バックテストの初期時間に鈍感かどうかなども参考にする必要があります。
ポジション調整の頻度については、株式市場では5日、10日、1か月のサイクルが多いが、デジタル通貨市場ではそのようなサイクルは明らかに長すぎるため、実際の市場での市況を監視している。リアルタイムなので、特定のサイクルに固執することは困難です。ポジションを再度調整する必要がないため、実際の取引ではリアルタイムまたは短い期間でポジションを調整します。
ポジションのクローズ方法については、従来の方法に従い、次のソート時にグループに含まれていない場合はポジションをクローズすることができます。ただし、リアルタイムのポジション調整の場合、一部の通貨が境界線上にある可能性があり、前後してポジションがクローズされる可能性があります。したがって、この戦略は、グループの変更を待って、反対方向にポジションを開く必要があるときにポジションを閉じるというアプローチを採用しています。たとえば、最初のグループでロングした場合、ロングポジションの通貨が3 番目のグループでは、ポジションをクローズしてショートすることができます。毎日や8時間ごとなど、決まった期間ごとにポジションをクローズする場合は、グループに属さずにポジションをクローズすることもできます。さらに試してみることもできます。
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
単純因子検定
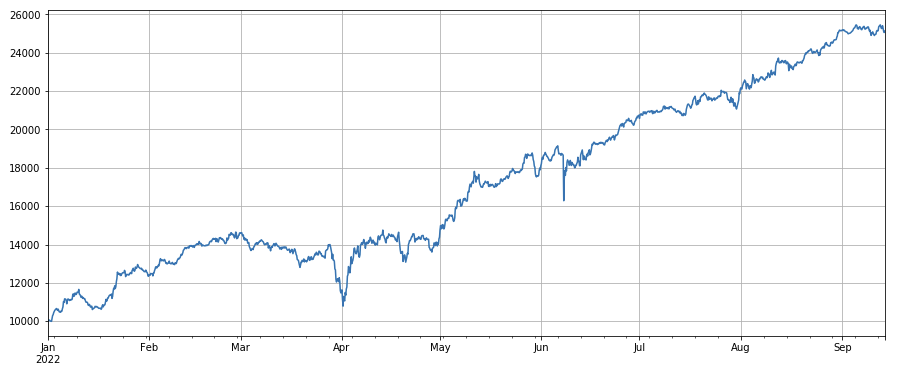
ボリューム係数: 単純に、取引量の少ないコインをロングし、取引量の多いコインをショートすると、パフォーマンスが非常に良くなります。これは、人気のあるコインは下落する可能性が高いことを示しています。
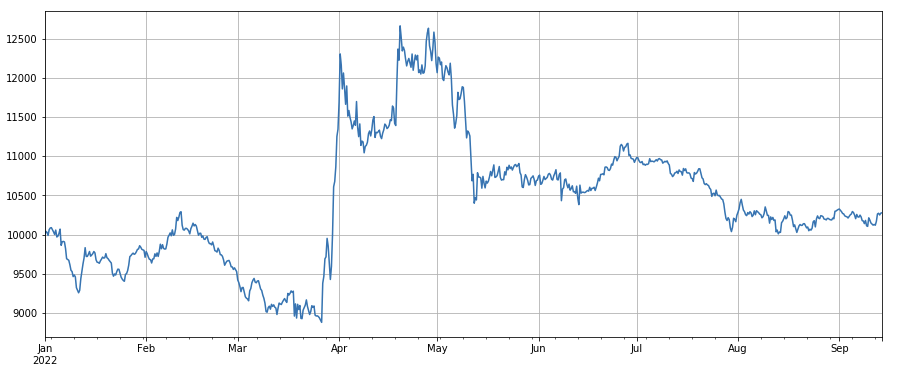
取引価格要因:低価格通貨をロング、高価格通貨をショート、効果は平均的。
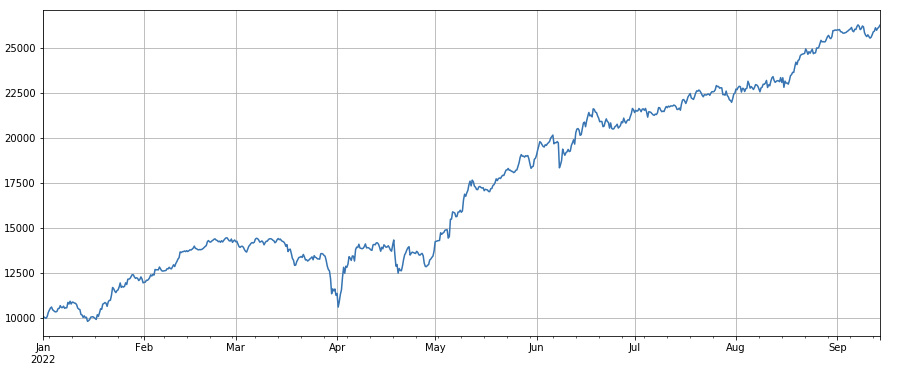
トランザクション数要因: パフォーマンスはボリュームと非常に似ています。ボリューム要因と取引数要因の相関が非常に高いことは明らかです。実際、異なる通貨間の平均相関は0.97であり、これら2つの要因が非常に似ていることを示しています。この要因は考慮する必要があります。考慮に入れます。
3時間モメンタム係数: (df_close - df_close.shift(3))/df_close.shift(3)。つまり、要因の 3 時間の増加です。バックテストの結果は、3 時間の増加には明らかな回帰特性があり、つまり、増加は次の期間に低下する可能性が高いことを示しています。全体的なパフォーマンスは良好ですが、引き戻しと振動の期間も長くなっています。
24 時間モメンタム係数: 24 時間リバランス サイクルの結果は非常に良好で、リターンは 3 時間モメンタムと同等でドローダウンは小さくなっています。
売上高変化係数: df_volume.rolling(24).mean() / df_volume.rolling(96).mean()、これは直近1日の売上高と直近3日間の売上高の比率です。ポジション8時間ごとに調整されます。バックテストの結果は比較的良好で、リトレースメントは比較的低く、取引量が活発な株は下落する可能性が高いことを示しています。
取引数の変化係数: df_count.rolling(24).mean() / df_count.rolling(96).mean()、これは過去 1 日間の取引数と過去 3 日間の取引数の比率です。位置は8時間ごとに調整されます。バックテストの結果は比較的良好で、リトレースメントは比較的低く、取引数が増えるにつれて市場がより積極的に下落する傾向があることがわかります。
単一取引値の変化要因: -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean()) は、直近1日の取引額と直近3日間の取引額の比率で算出され、8時間ごとにポジション調整が行われます。この要因はボリューム要因とも高い相関関係にあります。
アクティブ取引比率の変化係数: df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()、つまり、過去1日間のアクティブ購入量と総取引量の比率。過去 3 日間の値に基づいて、8 時間ごとに位置を調整します。この要素はパフォーマンスが良好で、ボリューム要素との相関性はほとんどありません。
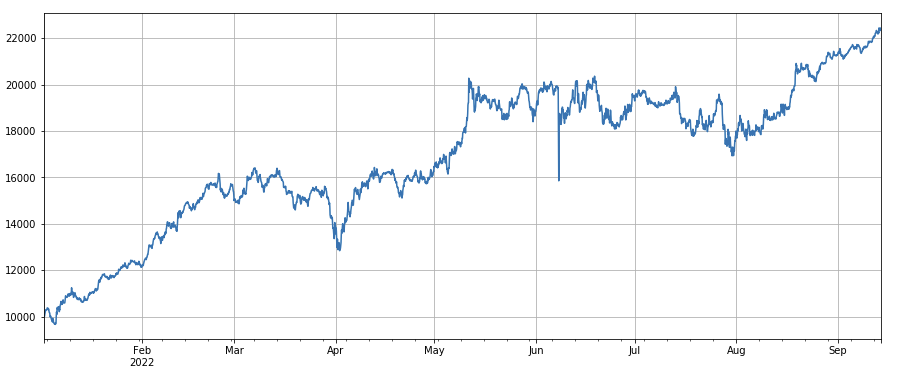
ボラティリティ係数: (df_close/df_open).rolling(24).std()。これは、ボラティリティの低い通貨をロングするときに一定の効果があります。
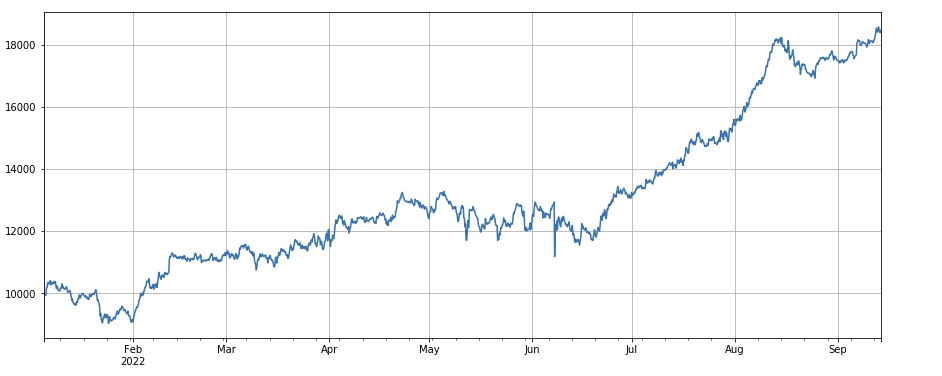
取引量と終値の相関係数: df_close.rolling(96).corr(df_volume)、過去4日間の終値と取引量の相関係数、全体的なパフォーマンスは良好です。
ここでリストされているのは、数量と価格に基づく要素の一部にすぎません。実際には、要素の計算式の組み合わせは非常に複雑で、明確なロジックがない場合があります。有名な ALPHA101 因子構築方法を参照できます: https://github.com/STHSF/alpha101。
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
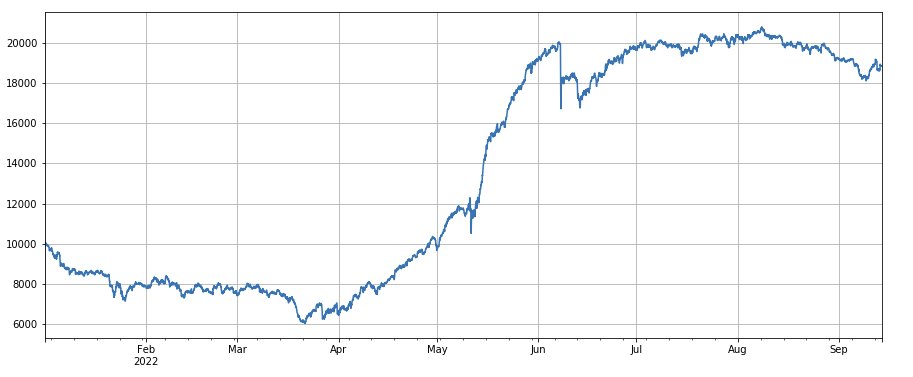
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
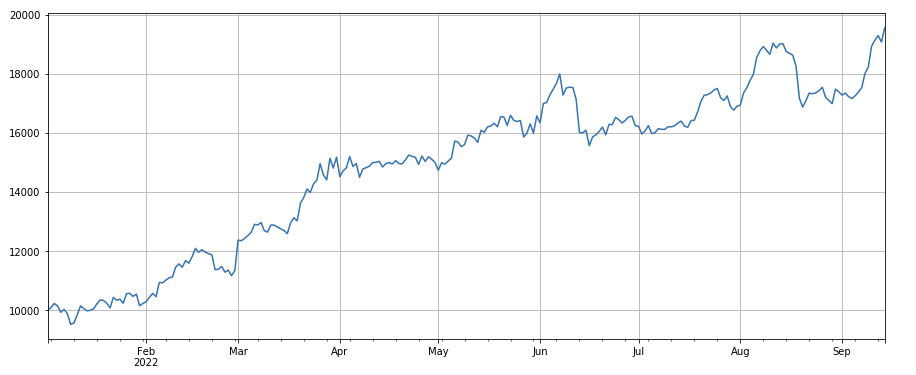
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
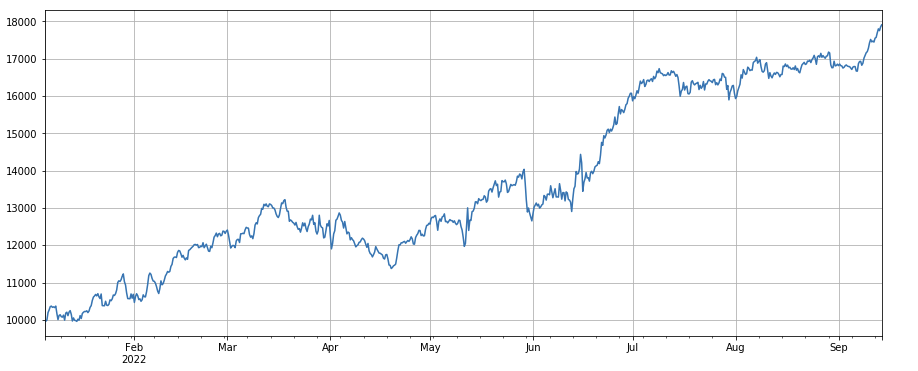
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
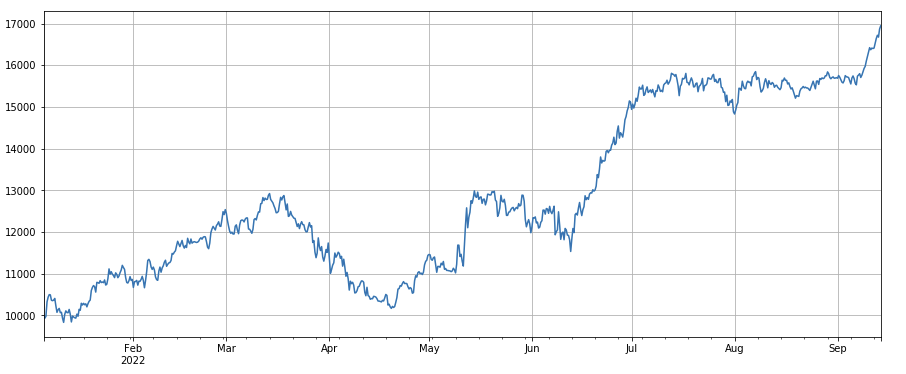
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
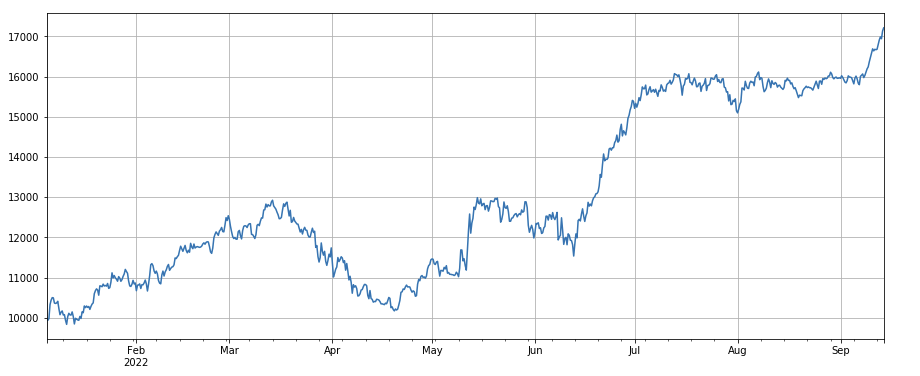
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
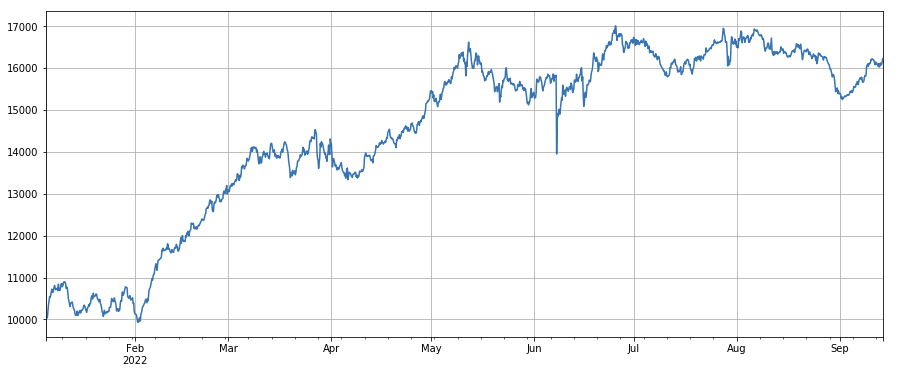
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
多因子合成
継続的に新しい有効な要因を発見することは、確かに戦略構築プロセスの最も重要な部分ですが、適切な要因合成方法がなければ、優れた単一のアルファ要因が最大限の役割を果たすことはできません。一般的な多因子合成法には以下のものがあります。
等重み法: 合成するすべての要素を等しい重みで追加して、新しい合成要素を取得します。
ヒストリカル ファクター リターンの加重法: 合成されるすべてのファクターは、最新の期間のヒストリカル ファクター リターンの算術平均に従って加重として加算され、新しい合成ファクターが得られます。この方法では、パフォーマンスが良好な要素に高い重み付けが与えられます。
IC_IR加重法の最大化:複合因子の履歴期間の平均IC値は、次の期間の複合因子のIC値の推定値として使用され、履歴IC値の共分散行列は、次の期間のIC値の推定値として使用されます。次の期間の複合因子のボラティリティの予測値。これはICの期待値をICの標準偏差で割った値に等しく、複合因子IC_IRを最大化するための最適な重み解が得られます。
主成分分析(PCA)法:PCAは、データの次元削減によく使用される方法です。因子間の相関は比較的高い場合があり、次元削減後の主成分が合成因子として使用されます。
この記事では、因子妥当性の重み付けを手動で参照します。上記の方法は以下を参照できます。ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
単一因子をテストする場合、順序は固定されていますが、多因子合成ではまったく異なるデータを結合する必要があるため、すべての因子を標準化する必要があり、一般に極端な値や欠損値を削除する必要があります。ここでは、合成に df_volume\factor_1\factor_7\factor_6\factor_8 を使用します。
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
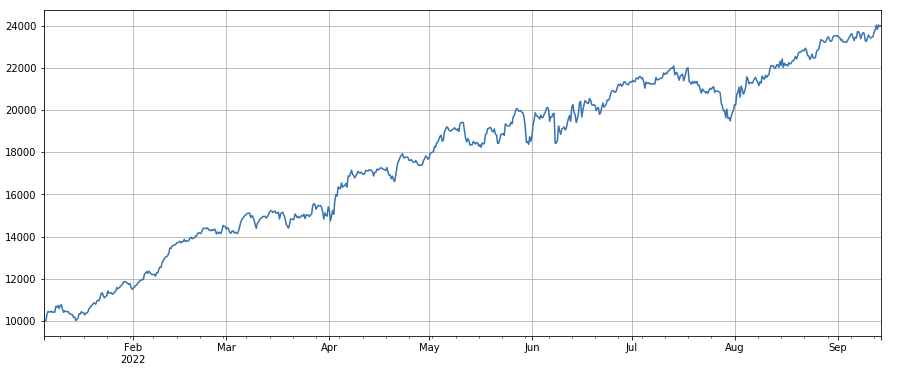
要約する
本稿では、単一因子テスト法を紹介し、一般的な単一因子をテストし、多因子合成法を予備的に紹介した。しかし、多因子研究の内容は非常に豊富であり、本稿で言及されている各ポイントは、さらに深く掘り下げることができる。このような戦略研究をアルファ要因の発見に転換することは実現可能なアプローチです。要因方法論を使用すると、取引アイデアの検証を大幅にスピードアップでき、利用可能な参考資料も多数あります。
実際のアドレス: https://www.fmz.com/robot/486605