ノロ移動平均ストップロス戦略
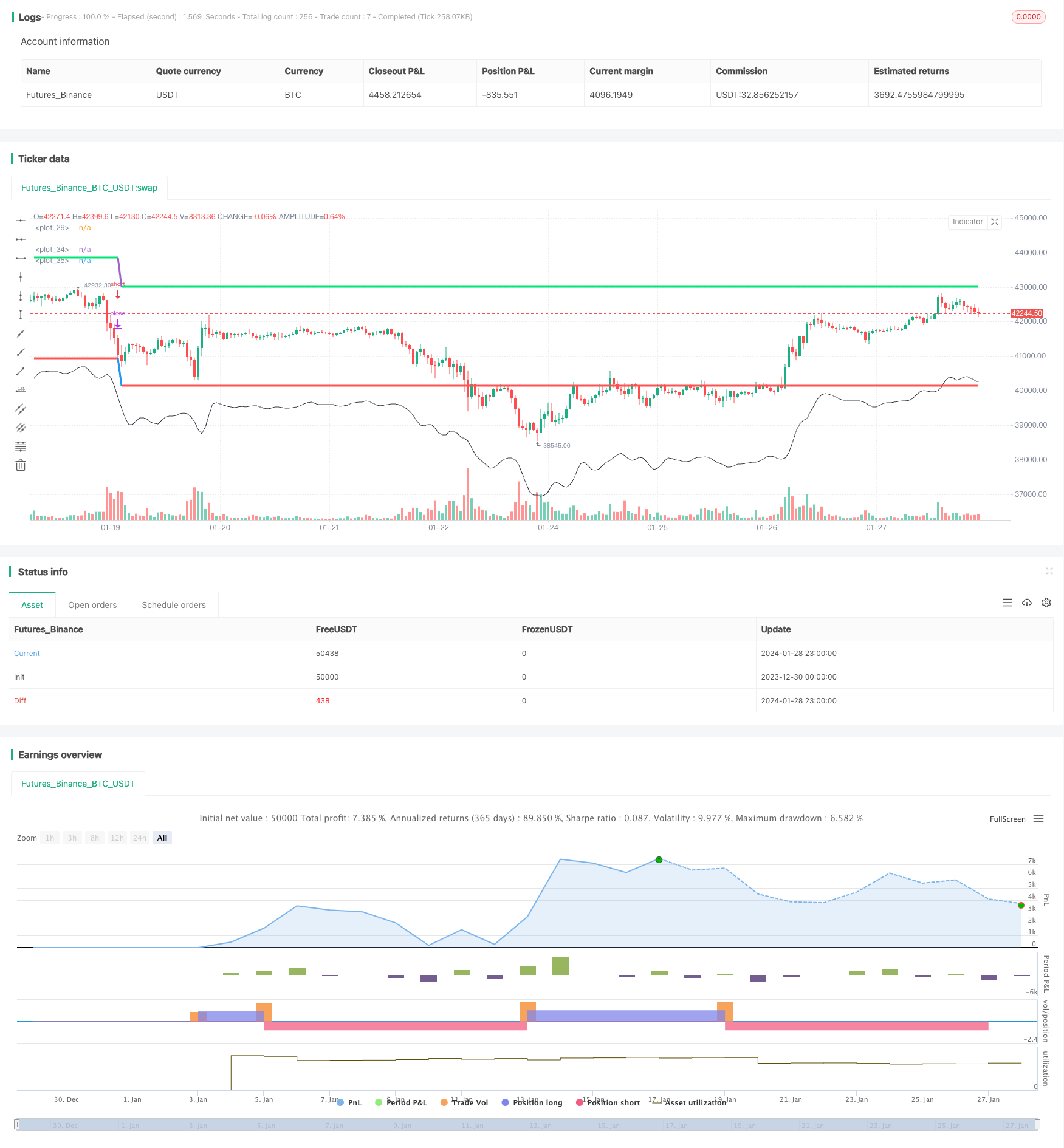
概要
Noro平面移動平均線ストップ戦略は,トレンドを追跡する戦略である.これは,3日間の単純な移動平均を計算し,その上下に開設ラインとストップラインとして比率を加えることによる.同時に,ストップを設定する.これは,トレンドの開始時にポジションを開き,トレンドが逆転するときにストップを出すことができる.
戦略原則
この戦略の核心は,3日間のシンプル・ムービング・アヴェア (MA) を計算することである.MAの上に1パーセントのLOを,開設ラインのlongとして加え,価格がロングを突破するときに多めにすること;MAの下に1パーセントのSLを,ストップラインのstopとして,価格がストップを下破するときにストップすることである.また,ストップラインのtakeを設定し,価格がストップラインに達するときにストップすることである.
具体的には以下の通りです.
- 3日間の移動平均を計算する
- ポジション開設ラインの長さは
- ストップラインtake = 現在の保有平均価格 + 現在の保有平均価格 * tp%
- ストップラインストップ = 現在の平均保有価格 - 現在の平均保有価格 * sl%
これは,maをベースに,設定可能なパーセンテージで,開設ライン,停止ライン,および停止ラインのトレンド追跡戦略を構築します.
優位分析
この戦略の最大の利点は,トレンドを自動で追跡できるという点にある. オーバーバイズや空白バイズを行い,面の形状を判断する必要なく,中間トレンドを捕捉することができる. ストップ・ストップ・損失設定と組み合わせて,トレンドの終わりに自動でストップ・損失を発生させ,過剰な引き戻しを回避することができる.
もう一つの優点は,パラメータが柔軟に調整できるということです. ポジション開設ライン,ストップライン,ストップラインのパーセントパラメータを調整することで,ポジションサイズとストップスペースを自由に制御できます.
リスク分析
この戦略の最大のリスクは,巨大な滑落が容易であることです.これはオフライン取引であるため,価格が急激に下落すると,止損価格をはるかに上回る取引が容易になる状況です.これは投資家に大きな損失をもたらすでしょう.
もう1つのリスクは,パラメータを正しく設定しないことにより,出場頻度が高くなり,取引頻度や手数料の負担が増加する可能性があることです.
最適化の方向
この戦略は以下の点で最適化できます.
- 制限価格の単一ストップを使う代わりに,巨大な滑り場を避けるリスク
- ポジション数設定を増やし,ポジションを平坦に調整し,取引頻度を低下させる
- トレンド判断指標を増やし,非トレンド市場の誤操作を避ける
- パラメータの設定を最適化して,最適なパラメータの組み合わせを見つける
要約する
ノロ平移均線ストップ戦略は,シンプルで実用的トレンド追跡戦略である.自動でトレンドを追跡し,ストップストップの設定と有効なリスクコントロールを組み合わせることができる.この戦略の最大のリスクは,大きなスライドポイントを引き起こす可能性があること,およびパラメータの設定が不適切で,あまりにも頻繁な取引を引き起こすことにある.ストップの改善方法,パラメータの設定の最適化などの手段によって,この戦略を最適化することで,より実用的にすることができる.
/*backtest
start: 2023-12-30 00:00:00
end: 2024-01-29 00:00:00
period: 1h
basePeriod: 15m
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
//2019
//Noro
//@version=4
strategy("Stop-loss", overlay = true, default_qty_type = strategy.percent_of_equity, default_qty_value = 100, pyramiding = 0)
//Settings
lo = input(-5.0, title = "Long-line, %")
tp = input(5.0, title = "Take-profit")
sl = input(2.0, title = "Stop-loss")
//SMA
ma = sma(ohlc4, 3)
long = ma + ((ma / 100) * lo)
//Orders
avg = strategy.position_avg_price
if ma > 0
strategy.entry("Long", strategy.long, limit = long)
strategy.entry("Take", strategy.short, 0, limit = avg + ((avg / 100) * tp))
strategy.entry("Stop", strategy.short, 0, stop = avg - ((avg / 100) * sl))
//Cancel order
if strategy.position_size == 0
strategy.cancel("Take")
strategy.cancel("Stop")
//Lines
plot(long, offset = 1, color = color.black, transp = 0)
take = avg != 0 ? avg + ((avg / 100) * tp) : long + ((long / 100) * tp)
stop = avg != 0 ? avg - ((avg / 100) * sl) : long - ((long / 100) * sl)
takelinecolor = avg == avg[1] and avg != 0 ? color.lime : na
stoplinecolor = avg == avg[1] and avg != 0 ? color.red : na
plot(take, offset = 1, color = takelinecolor, linewidth = 3, transp = 0)
plot(stop, offset = 1, color = stoplinecolor, linewidth = 3, transp = 0)