고빈도 알고리즘보다 사고방식이 더 중요하다
 1
2545
1
2545
고빈도 알고리즘보다 사고방식이 더 중요하다
프로그램 거래가 대중의 시선에 진입하게 된 것은 2년 전 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도 경상북도
중국 금융 선물 거래소의 7·31 새정치에서, 深 거래소가 연속적으로 발표한 3개의 계정들에 대한 거래 제한 조치를 취하기, 그리고 최근에는 融券T+0 거래가 T+1로 바뀌기, 규제층이 절차적 거래에 대해 연속적으로 무장한다. 특히, 중화은행이 7월 31일 발표한 신고 수수료 징수 조치는 절차적 거래자에 대한 최후의 재앙이라고 할 수 있다.
이 글은 2014년 8월, 董可人 (董可人) 의 高频交易 (高频交易) 에 대한 유명한 알고리즘이 무엇인지 알고 있는지 알고 있는지 알고 있는지 알고 있는지에 관한 것입니다.
제목에서 언급한 빙산 알고리즘에 대해 조금만 알고 있는데, 여러분께 말씀드릴 수 있습니다. 많은 사람들이 양적 거래 에 대한 이해가 너무 편향되어 있고, 기본적으로 돈을 버는 도구와 동일시하고 있습니다. 거래는 거래 자체이며, 그 자체의 경제적 의미가 있습니다.
저는 알고리즘 자체에 특별한 점이 있다고 생각하지 않습니다. 좋은 알고리즘은 죽습니다. 진정한 핵심 가치는 알고리즘을 이해하고 사용하는 사람이어야합니다. 사실 제가 말하는 것은 공개 정보입니다. 그러나 기술적인 세부 사항을 알고도 실제로 잘하는 사람은 거의 없습니다.
이 질문에 대한 답이 양적 거래와 고주파 거래에 대한 더 나은 이해를 돕기를 바랍니다.
우선, 저는 많은 사람들이 생각하는 초음파 거래는 다음과 같습니다.
하지만, 이 정보는 HFT 거래에 있어서 매우 거칠다. 그래서, 이 부분에 대해 잘 모르는 학생들에게 Order Book이란 무엇인가를 소개해 드리겠습니다. 현재 주요 거래소는 오더 북을 사용하며, 거래소 내부의 오더 북에는 모든 구매자와 판매자의 제안을 기록하고 있습니다.
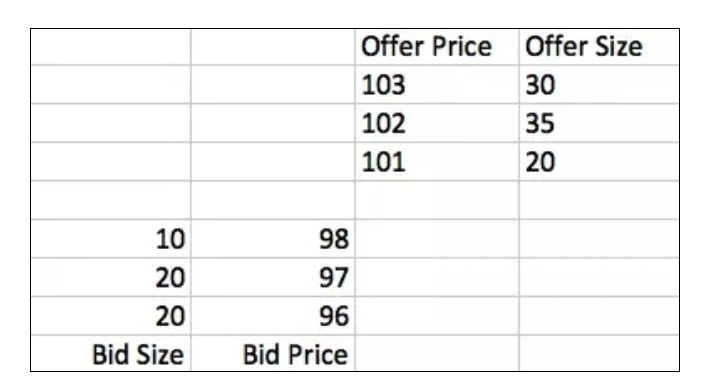
Bid는 구매자를 나타내고, Offer는 판매자를 나타내고, 이 제안서는 구매자와 판매자가 발신한 모든 제안서를 나타낸다. 이 표는 고주파 거래에 가장 관심있는 정보이다. 임의의 순간에 구매자의 제안은 항상 판매자보다 낮다.
거래가 언제 일어날까요? 두 가지 상황이 있습니다. 첫째, 어느 한쪽이 시장 주문을 발송합니다. 예를 들어, 구매자가 10의 시장 주문을 발송하면 판매자가 101의 가격에 매달린 10 개를 구입할 수 있습니다. 거래가 성공하면, 주문서는 다음과 같이됩니다.
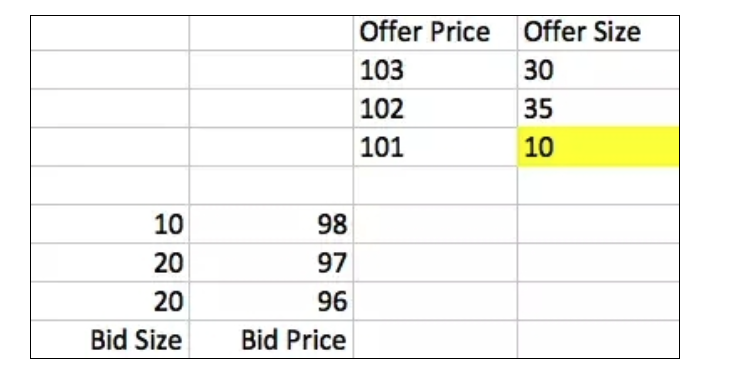
두번째는, 상대방의 최우수 제안에 해당하는 가격으로 한정된 주문을 발급하는 것입니다.
강조해야 할 점은, 실제 주문서는 거래소 내에서만 존재하며 모든 거래가 거래소 내에서 이루어지지만, 거래소는 모든 제안과 시가표를 모든 사람에게 전달하므로 모든 구매자와 판매자가 거래소 주문서의 거울에 해당하는 동일한 데이터 구조를 스스로 유지할 수 있다는 것입니다. 자신의 손에 있는 이 거울의 변화를 추적하고 분석하여 거래 전략을 수립하는 것은 고주파 거래 알고리즘의 핵심 아이디어입니다.
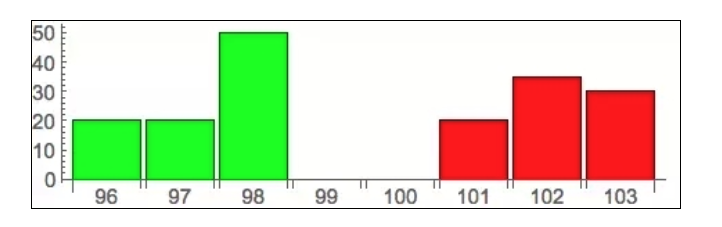
기본에 대한 설명이 끝나고, 아래의 그림은 오더북을 좀 더 형상적으로 표현한 것입니다.
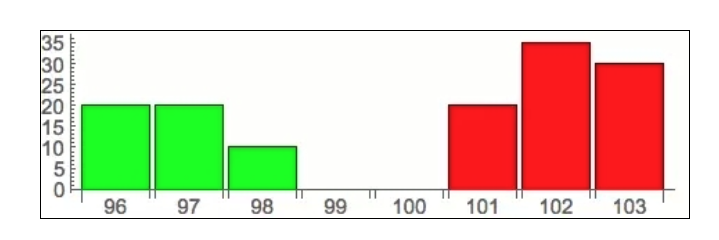
이 그림은 기사의 시작에 있는 주문서에 해당하는 그림으로, 가로축은 가격을, 세로축은 주문량을, 녹색은 구매자를, 빨간색은 판매자를 나타내고 있는 것을 분명하게 볼 수 있어야 합니다.
위의 기본 분석을 통해 거래소 내의 거래 데이터는 완전히 공개되어 있으며, 시장에서 임의의 시간에, 누가 얼마나 많이 사고 / 팔고 싶은지, 모든 사람이 한눈에 볼 수 있으며, 비밀이 없습니다. 이것은 자체적으로 경제적으로 의미가 있습니다. 왜냐하면 구매 / 판매의 요구를 보여주는 것 만이 잠재적인 상인이 거래하도록 유치하기 때문에 시장에서 자신의 요구를 어느 정도 공개하는 것이 필요합니다. 그러나 이것은 심각한 결과를 초래합니다.
이것은 그에게 매우 불리하다, 왜냐하면 모든 사람들이 이 정보를 이용해 그를 옳게 할 것이기 때문이다. 사람들은 시장에 많은 구매 압력이 존재한다고 판단하고, 그래서 돈을 벌기 위해 많은 사람들이 몰려들게 되고, 가격이 급격히 상승하게 되고, 그래서 원래 이 사람이 98달러에 살 수 있는 것은 곧 더 높은 가격에 살 수 있게 된다. 이런 경우, 나중에 사람들이 하는 것은 프론트 러닝이고, 원래의 사람은 역으로 선택의 위험에 직면한다. 이 문제를 해결하기 위해 거래소는 ‘아이스버그 오더’라고 불리는 타겟팅된 도구를 제공했습니다. 이 오더는 매우 커질 수 있지만, 작은 부분만 공개되며, 대부분은 숨겨져 있습니다. 거래소와 발송자 자신 이외에는 아무도 볼 수 없습니다.
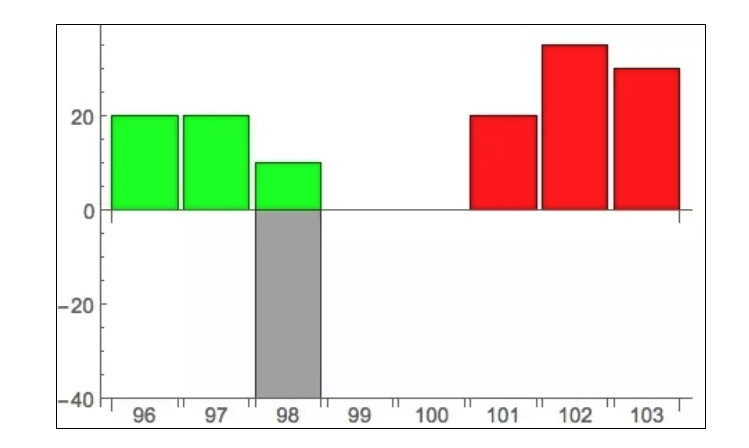
회색 부분은 빙산 주문이 숨겨진 부분이다. 따라서 거래소가 다른 사람들에게 알리는 것은 숨겨진 거래량이 발생했을 때만이며, 다른 사람들이 주문을 표시하는 정보를 사용하여 Front running을하는 것을 방지합니다.
어떤 장점이 있더라도 단점이 있을 것이다. 빙산 명령은 발신자의 이익을 보호하지만, 다른 시장 참가자들에게는 불공평한 규칙이 된다. 실제 거래 요구가 있는 참가자들은 상황을 잘못 판단하여 큰 손실을 입을 수 있다.
우선 가장 간단한 방법이 있습니다. 때때로, 빙산 주문은 최적의 구매 가격과 판매 가격 사이의 스프레드 (spread) 에 매달려 있습니다.
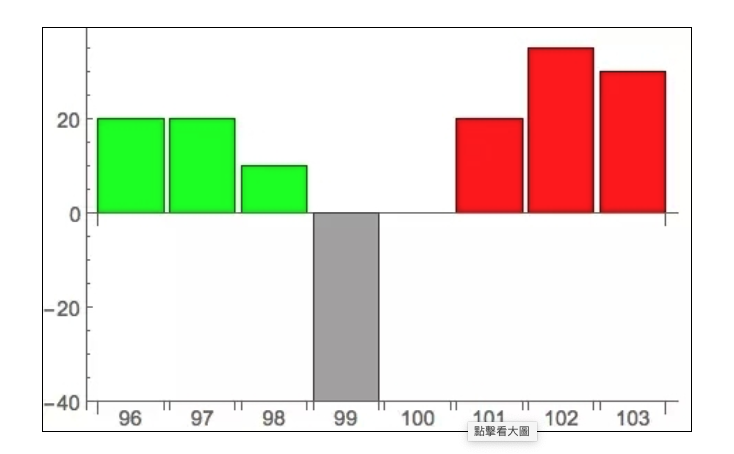
이 경우, 매우 간단한 탐지 방법이 있습니다. 스프레드에 최소 한계 가격을 발송하고, 그 다음에는 그 주문을 취소합니다. 예를 들어, 99의 판매 가격을 발송한 후 취소합니다. 왜냐하면 이 가격은 직접적으로 구매 가격에 부합하지 않기 때문에, 아이스 버그가 없으면 거래가 이루어지지 않을 것입니다. 그러나 아이스 버그가있는 경우, 거래소가 그 판매 목록을 수신하면, 아이스 버그의 대응량을 즉시 거래하고, 그 후의 취소 명령은 유효하지 않습니다.
이런 혼란에 대처하기 위해 사람들은 보통 스프레드에 직접적으로 상장하지 않습니다. 이전처럼 보통의 제한 가격 상장과 함께 상장합니다. 거래가 발생하면, 당신이 소비한 것이 정상 제한 가격 상장인지, 빙산 주문인지 추측하기가 어렵습니다. 그렇다면 어떻게 해야 할까요?
먼저 직관적인 생각이다. 빙산 주문의 존재는 어느 정도 상장자가 시장 상황을 해석하여 빙산 주문을 사용하는 것이 필요하다고 판단한 판단을 반영한다. 강조할 필요가 있는데, 빙산 주문을 사용하는 것은 비용이 들지 않습니다. 왜냐하면 당신은 실제 요구를 숨기고 잠재적인 공격자를 차단하는 동시에 실제 거래자를 차단하기 때문입니다.
어떤 시기가 적절한가? 어떤 데이터가 관련되어 있어야 한다. 예를 들어, 매매비스 스프레드, 매매량에 매매량 비율 등이 있다. 이러한 데이터에 대해, 당신은 역사적인 데이터에 대한 회귀 분석을 하고, 그들과 빙산 주문 사이의 선형/비선형 모델을 구축할 수 있다. 역사적인 데이터에 의해 훈련된 이 모델은, 당신이 실시간 거래할 때 사용할 수 있는 빙산 주문 탐지기로 작용한다.
기본 모형은 다음과 같이 정의될 수 있습니다: F (spread, bidSize/offerSize, …) = Probability (Iceberg)
HMM, SVM, 신경망과 같은 고급 모델을 만들 수도 있습니다. 하지만 기본 아이디어는 동일합니다. 계산을 통해 빙산 순서가 존재하는 확률을 계산하는 것입니다.
위에서 말한 이 방법은 매우 고급스럽게 보이지만 실제 효과는 어떨까요? 여러분도 보시다시피, 이 모델링은 매우 정확하지 않습니다. 사후 분석 수단으로 어떤 상황에서 빙산 주문이 발생할 수 있는지 설명하는 데는 괜찮지만, 실시간 거래의 탐지기로서는 그다지 안심할 수 없습니다. 사용 된 정보가 너무 모호하고, 모델링 된 객체는 단지 연관성일 뿐이기 때문에 빙산 주문의 발신자가 반드시 이 논리에 따라 출장해야한다는 보장은 없습니다.
그래서 다음 글은 GLOBEX Futures의 제한 순서 책에서 숨겨진 유동성의 예측에 관한 논문에서 나온 정말 고 주파수 플레이어의 놀라운 방법입니다.
高频世界里,有一条永恒的建模准则值得铭记:先看数据再建模。如果你看了上面的介绍就开始天马行空的思考数学模型,那基本上是死路一条。我见过很多年轻人,
特别有热情,一上来就开始做数学定义,然后推导偏微分方程,数学公式写满一摞纸,最后一接触数据才发现模型根本行不通,这是非常遗憾的。
그리고 데이터를 보는 사람은 어떻게 될까요? 그는 빙산 주문을 처리하는 거래소의 규칙이 매우 흥미롭다는 것을 발견 할 것입니다. 어떤 거래소는 이렇게합니다. 빙산 주문은 두 개의 변수를 포함합니다. V는 주문의 총량을 나타냅니다. p는 공개적으로 표시되는 양을 나타냅니다. 예를 들어, V = 100, p = 10의 빙산은 실제로 숨겨진 양은 90입니다.
10
오더 북의 Top bid size -10
새로운 입찰 +10
이 세 가지 정보는 반드시 연속적으로 나타나고, 제3항과 제1항의 시간적 차이는 매우 작다. 이것은 빙산 명령에 숨겨진 양이 있음에도 불구하고, 매번 거래가 표시된 양에 대해서만 일어날 수 있기 때문이다. p가 소모되고 나서야, 남은 숨겨진 양에서 새로운 p량을 새로 만들 수 있다. 따라서, 거래소에서 수신된 모든 정보는 여전히 빙산 명령이 존재하지 않는 것처럼 논리적으로 올바른 Order Book을 업데이트 할 수 있다. 따라서, 일단 이 법칙을 데이터에서 관찰하면, 우리는 매우 확실하게 시장에 빙산 주문이 존재하고, p의 값을 알 수 있다! 다음의 중요한 문제는, V의 값을 어떻게 알 수 있는가, 즉, 빙산 주문의 잔여가 얼마나 되는지 판단하는 것이다. 이 문제는 본질적으로 정확하게 풀 수 없다. 왜냐하면 V와 p는 개인이 스스로 결정하기 때문에 임의의 값이 될 수 있다. 그러나 두 가지 점에서 고려할 수 있다. 첫째, 두 값은 정수이다. 둘째, 인간은 완벽한 무작위 수 생성기가 아니며, 결정은 일정한 법칙을 따른다.
이 두 점에서 출발하여, V와 p에 대한 확률 모형을 만들 수 있습니다, 즉, 주어진 ((V,p) 값의 조합이 나타나는 확률이 얼마입니까? 여기서는 수학 분석에 깊이 들어가지는 않지만, 관심있는 친구는 본문을 볼 수 있습니다. 간단히 말해서, 역사적인 데이터에서 커널 추정 기술을 통해 그들의 확률 밀도 함수의 모양을 추정 할 수 있습니다.
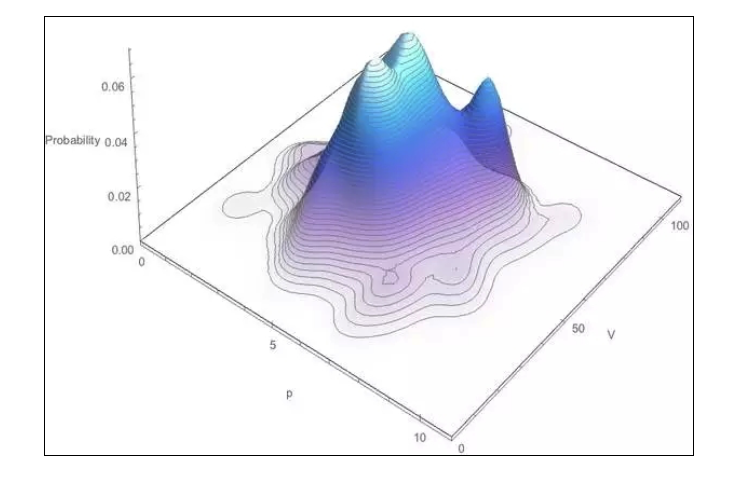
이렇게, 실시간 데이터에서 p의 값을 관찰할 때, 위 그림에서 p = 8과 같은 절단면과 같은 V 값의 조건부 확률 밀도 함수를 얻을 수 있습니다.
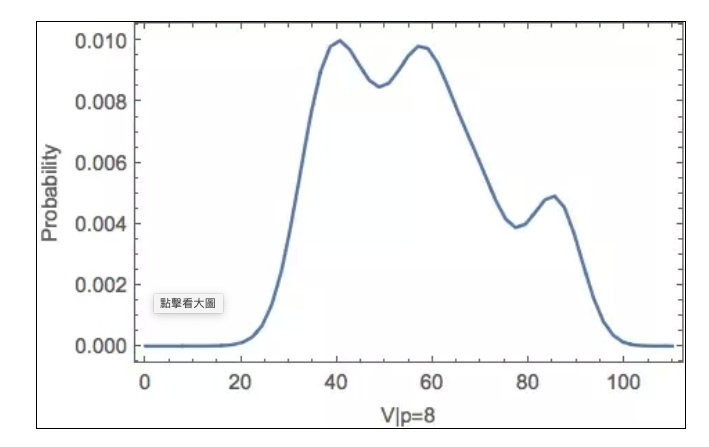
다음으로 V의 가장 가능성이 높은 값을 계산하는 것은 분명하다. 이 함수 곡선은 또한 중요한 역할을 한다. 그것은 당신이 잔존량을 동적으로 평가하는 데 도움이 된다. 예를 들어, 당신이 이미 5개의 p가 소모되었음을 관찰했을 때, V>=40을 추론할 수 있고, 위의 그림에서 새로운 V값과 잔존량을 추론할 수 있다.
종합적으로, 알고리즘의 핵심은, 실시간 데이터에서 짧은 시간 동안 연속적으로 나타나는 3개의 관련 기록을 모니터링하여 빙산 명령의 존재를 판단하는 데 있으며, 빙산 명령의 정량화는 역사적 데이터에 의해 훈련된 확률 모델에 의해 이루어진다.
이 알고리즘은 사기꾼이 아닙니다. 그것은 단지 시장에서 공개 된 데이터를 사용하여 만들어진 추측입니다. 그리고 이것은 단지 확률에 기반한 것입니다. 더 많은 것은 참고로 사용되어야합니다. 그것은 시장 사업자의 유동성 제공자에게 의미가 있으며, 상황에 대한 잘못된 판단으로 인해 손실을 입지 않도록 할 수 있습니다. 그러나 만약 당신이 그것을 공격 수단으로 사용하기를 원한다면, 숨겨진 예산을 발견하고 프론트 런에 갈 수 있다고 생각하면, 그것은 매우 무리한 선택입니다.
마지막으로, 이 알고리즘은 특정 거래소에만 적용됩니다. 다른 거래소는 동일한 빙산 주문 처리를 사용하지 않을 수도 있습니다. 그래서 실제 데이터에서 출발한 이러한 모델링 아이디어가 실제로 가치있는 것은 특정 알고리즘이 가치가 없다는 것입니다.
이 작은 알고리즘은 당신에게 고주파 거래의 빙산의 한쪽 끝을 보여줍니다. 그것은 복잡하지 않을 수도 있지만, 나는 그것을 좋아합니다. 왜냐하면 그것은 먼저 생각, 다음 수량이라고 부르는 것을 명확하게 보여주기 때문입니다. 왜냐하면 빙산의 주문이 있기 때문입니다. 경제학의 기본 공급과 수요 관계에서 출발하는 실제 요구, 실제 데이터를 분석하여 실마리를 찾으며, 마지막으로 수량 전략을 수립하는 수학 모델을 통해, 이것은 아름다운 전략 연구입니다.
이 원칙을 어기면, 모든 고급 모델을 이동시켜 데이터를 제거하고, 자동으로 거래 신호를 생성하도록 기대하는 것은, 제 생각에는, 바보가 말하는 꿈과 다를 바 없다. 불행히도, 이 꿈은 너무 매력적이지만, 이 세상에는 겁쟁이가 결코 부족하지 않다. 그리고 그것을 소중히 여기세요.
7 Heat Network에서 리뉴얼을 게재했습니다. 링크