시각적 직관적 감각 7 가지 일반적인 분류 알고리즘 (글쓰기 전략)
저자:발명가들의 수량화 - 작은 꿈, 2016-12-06 10:23:16, 업데이트:시각적 직관적 감각 7가지 일반적인 분류 알고리즘
정책 작성 시, 프로그램 코드에 데이터 정렬이 필요한 상황이 불가피한 경우, 우리는 최소한의 시스템 비용 (시간, 시스템 자원) 으로 과학적인 프로그램을 어떻게 설계할 수 있을까요?
-
1. 빠른 분류
소개: 빠른 정렬은 토니 홀에 의해 개발된 정렬 알고리즘이다. 평균 상태에서 정렬 n 개 항목은 0 (n log n) 번 비교를 필요로 한다. 최악의 상태에서는 0 (n2) 번 비교가 필요하지만, 이러한 상황은 흔하지 않다. 사실, 빠른 정렬은 일반적으로 다른 n log n 알고리즘보다 훨씬 빠르다. 왜냐하면 그것의 내부 루프 (inner loop) 이 대부분의 구조에서 매우 효율적으로 구현될 수 있기 때문에, 그리고 대부분의 실제 세계 데이터에서, 필요한 시간을 줄이는 두 번째 항목의 가능성을 줄여서, 설계 선택에 대한 결정이 가능하다. 다음 단계: 숫자의 열에서 하나의 요소를 선택하면, 이 요소는
기준 (pivot) 이라고 불립니다. 다시 정렬하면, 기준값보다 작은 모든 요소가 기준값 앞에 있고, 기준값보다 큰 모든 요소가 기준값 뒤에 있습니다. 이 분할이 빠져나간 후, 기준값은 열의 중간에 있습니다. 이 작업을 분할 (partition) 이라고 합니다. 회귀적으로 (recursive) 기준값 요소보다 작은 소수열과 기준값 요소보다 큰 소수열을 정렬한다. 순서 효과: 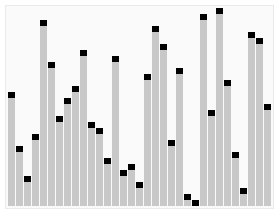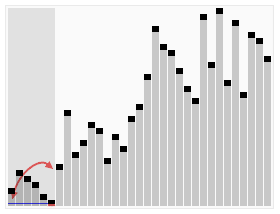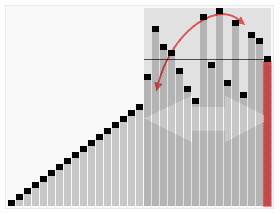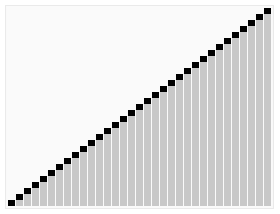
-
2. 분류 및 분류
소개: 병합 정렬 (Merge sort, 타이완어 번역: 병합 정렬) 은 병합 작업에 기반한 효과적인 정렬 알고리즘이다. 이 알고리즘은 분할 및 정복 방식을 사용하는 매우 대표적인 응용 프로그램이다. 다음 단계: 두 개의 정렬된 시퀀스의 합으로 된 크기로 공간을 요청합니다. 두 개의 포인터를 설정하여 두 개의 정렬된 시퀀스의 시작 위치로 시작 위치 두 개의 지표가 가리키는 요소를 비교하고, 상대적으로 작은 요소를 선택하여 결합 공간에 넣고, 지표를 다음 위치로 이동합니다. 세 번째 단계를 반복합니다. 다른 일련의 나머지 모든 요소를 직접 합동 일련의 끝으로 복사합니다. 순서 효과:

-
3. 겹처기
소개: 무더기 정렬 (Heapsort) 은 무더기의 이러한 데이터 구조를 활용하여 설계된 정렬 알고리즘을 의미한다. 무더기는 거의 완전한 이차 나무의 구조이며 동시에 무더기의 특성을 만족시킨다: 즉, 자중자기의 키값 또는 인덱스는 항상 그 부모의 노드보다 작거나 크다. 다음 단계: (더 복잡해, 인터넷에서 직접 찾아보세요.) 순서 효과:
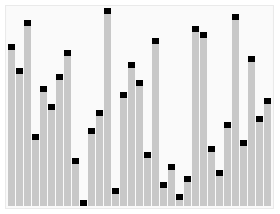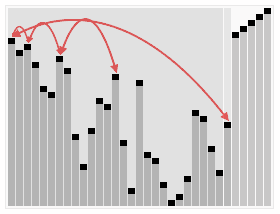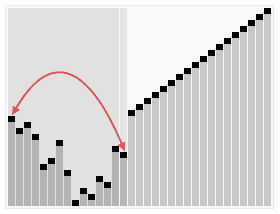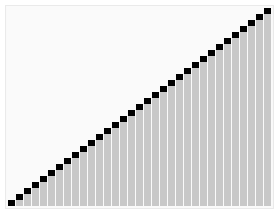
-
4. 순서를 선택하세요
소개: 선택 정렬 (Selection sort) 은 간단한 직관적인 정렬 알고리즘이다. 그것은 다음과 같이 작동한다. 먼저 정렬되지 않은 정렬에서 가장 작은 요소를 찾아서 정렬된 정렬의 시작 위치에 저장하고, 그 다음, 나머지 정렬되지 않은 요소에서 가장 작은 요소를 계속 찾아서 정렬된 정렬의 끝으로 놓는다. 그리고 이렇게 모든 요소가 정렬 될 때까지. 순서 효과:

-
5. 펌프 정렬
소개: 거품 정렬 (Bubble Sort, 타이완어: 버블 정렬 또는 버블 정렬) 은 간단한 정렬 알고리즘이다. 정렬하고자 하는 숫자의 행을 반복적으로 탐색하고, 두 요소를 한 번 비교하고, 순서가 잘못되면 교체한다. 탐색 열의 작업은 더 이상 교환이 필요하지 않는 한 반복적으로 수행된다. 즉, 순서가 완료되었다. 이 알고리즘의 이름은 느린 요소가 교환을 통해 느리게 떠있는 것으로 숫자의 정점에 올라갈 수 있기 때문입니다. 다음 단계: 서로 인접한 요소를 비교하십시오. 첫 번째 요소가 두 번째보다 크면 두 가지를 교환하십시오. 모든 인접한 요소 쌍에 동일한 작업을 수행합니다. 첫 번째 쌍을 시작하여 마지막 쌍까지. 이 시점에서 마지막 요소는 최대 숫자가어야합니다. 모든 요소를 위해 위의 단계를 반복하십시오. 마지막 요소를 제외하고. 숫자의 한 쌍도 비교할 필요가 없을 때까지 점점 더 적은 요소에 대해 위의 단계를 반복하십시오. 순서 효과:

-
6. 정렬을 삽입합니다.
소개: 삽입 정렬의 알고리즘 설명은 단순하고 직관적인 정렬 알고리즘이다. 그것의 작동 원리는 정렬된 순서를 구축하여, 정렬되지 않은 데이터에 대해 정렬된 순서에서 후진으로 스캔하여, 해당 위치를 찾아서 삽입하는 것이다. 삽입 정렬의 구현은 일반적으로 in-place 정렬을 사용한다 (즉, 단지 O까지의 추가 공간의 정렬을 사용한다). 후진으로 스캔하는 과정에서, 정렬된 요소를 반복적으로 후진으로 이동시켜 최신 요소에 삽입 공간을 제공해야 하기 때문이다. 다음 단계: 첫 번째 요소를 시작으로, 그 요소는 정렬된 것으로 간주 될 수 있습니다. 다음 요소를 꺼내서 정렬된 요소의 연속에서 앞으로 스캔합니다. 이 요소가 새 요소보다 크면 다음 위치로 이동합니다. 세 번째 단계를 반복하여 정렬된 요소가 새 요소보다 작거나 같을 때까지 반복합니다. 새로운 요소를 그 위치에 삽입합니다. 2단계 반복 순서 효과: (잠깐만)
-
7. 힐 분류
소개: 힐 정렬 (Hill sorting), 또한 감소량 정렬 알고리즘 (decreasing incremental sorting algorithm) 이라고도 하며, 삽입 정렬의 빠르고 안정적인 개선된 버전이다. 힐 정렬은 다음 두 가지 특성들에 기초하여 개선 방법을 제안합니다: 1, 삽입 정렬은 거의 정렬된 데이터에 대한 작업에서 효율성이 높습니다. 즉, 선형 정렬의 효율성을 달성 할 수 있습니다. 2, 하지만 삽입 정렬은 일반적으로 비효율적이기 때문에 삽입 정렬은 한 번에 하나의 데이터를 이동시킬 수 있습니다.
제가 가장 자주 사용하는 것은 (최소한)
- 재미있는 소재 - 다중과 빈
- 모의 재검토의 분산 옵션은 자신의 서버를 사용하여 오류를 표시합니다.
- 프로그래머가 알아야 할 10 가지 기본 실용 알고리즘과 설명
- 확률에 대한 거래 철학
- 자금 암호를 입력해야 합니다.
- BTCTRADE.com에서 GetRecords에 액세스 할 수 없습니다
- 이 지표의 가격이 위축되어 있고, 옵션에 돈을 버는 대신 돈을 잃습니다.
- 증축 전략의 정량 분석
- 재미있는 기계 학습: 가장 간단한 소개 가이드
거래법 - 하이프레크 트레이딩 전략: 삼각 스프레드
- 창의적인 사고를 키우기 위한 20가지 팁
- 기계 학습 8가지 알고리즘 비교
- 투자로 승자: 반 직관적 사고의 비밀
- 거래 시스템의 기본 요구 사항에 대해 이야기
- 실제 변동 규모 ATR 지표 사용
- 로봇 오류 코드 조사는 있나요?
- 흥미로운 투자 수학!
- 수학과 도박 (1)
- 평선체계를 재고하는 것
노력하는 양성자바스크립트 분류 알고리즘 코드를 찾았습니다. https://www.w3cschool.cn/wqcota/
노력하는 양성감사합니다.