무작위 시장 생성기에 기반한 전략 테스트 방법을 탐구합니다.
저자:발명가들의 수량화 - 작은 꿈, 창작: 2024-11-29 16:35:44, 업데이트: 2024-12-02 09:12:43[TOC]

전문
발명자 양자 거래 플랫폼의 리테스트 시스템은 초기 기본 리테스트 기능에서 기능을 점차 증가시키고 성능을 최적화하기 위해 끊임없이 반복적으로 업그레이드되는 리테스트 시스템입니다. 플랫폼의 발전과 함께 리테스트 시스템이 지속적으로 업그레이드됩니다. 오늘 우리는 리테스트 시스템에 기반한 주제에 대해 논의합니다.
요구
양적 거래 분야에서 전략의 개발과 최적화는 실제 시장 데이터의 검증과 분리되어 있지 않다. 그러나 실제 응용에서는 시장 환경이 복잡하고 변동적이기 때문에 역사적 데이터에 의존하는 재검토가 부족할 수 있다. 예를 들어 극단적인 시장이나 특별한 시나리오에 대한 보도가 부족하다. 따라서 효율적인 무작위 거래 생성기를 설계하는 것은 양적 전략 개발자의 효과적인 도구가 된다.
어떤 거래소, 어떤 통화에서 전략이 역사적인 데이터로 거슬러 올라갈 필요가 있을 때, FMZ 플랫폼의 공식 데이터 소스를 사용하여 다시 테스트 할 수 있습니다. 때로는 전략이 완전히 낯선 시장에서 어떻게 작동하는지보고 싶어 할 때, 우리는 전략 테스트를 위해 데이터를 조작 할 수 있습니다.
이 자료를 이용하면,
-
- 전략의 무능함을 평가합니다. 무작위 시장 생성기는 극단적인 변동, 낮은 변동, 트렌드 시장 및 불안 시장 등 다양한 가능한 시장 시나리오를 만들 수 있습니다. 이러한 모형 환경에서 전략을 테스트하면 다른 시장 조건에서 안정적으로 수행하는지 평가하는 데 도움이 될 수 있습니다. 예를 들어:
전략은 트렌드와 격동 전환에 적응할 수 있습니까? 이 전략은 극단적인 시장에서 큰 손실을 줄 수 있습니까?
-
- 전략의 잠재적인 약점을 식별합니다. 몇몇 비정상적인 시장 상황을 모방함으로써 (예: 가정된 블랙 스완 사건) 전략의 잠재적인 약점을 발견하고 개선할 수 있다. 예를 들어:
이 전략은 어떤 시장 구조에 지나치게 의존하는가? 이 경우, 이 자리는 다른 자리로 이동할 수 있습니다.
-
- 전략 파라미터 최적화 무작위로 생성된 데이터는 전략 매개 변수를 조정하는 데 더 다양한 테스트 환경을 제공하며, 역사 데이터에 전적으로 의존할 필요가 없습니다. 이것은 전략의 매개 변수 범위를 더 포괄적으로 찾을 수 있으며, 역사 데이터에 특정 시장 패턴에 국한되는 것을 피합니다.
-
- 역사적인 자료의 부족 일부 시장 (예를 들어, 신흥 시장 또는 소화폐 거래 시장) 에서, 역사적 데이터는 모든 가능한 시장 상황을 포괄할 수 없을 수 있다. 무작위 시장 생성자는 더 포괄적인 테스트를 돕기 위해 많은 부가 데이터를 제공할 수 있다.
-
- 급속한 반복 개발 무작위 데이터를 사용하여 빠른 테스트를 수행하면 실시간 시장 시장 또는 시간이 많이 걸리는 데이터 청소 및 정리에 의존하지 않고 전략 개발의 반복 속도를 높일 수 있습니다.
그러나 합리적인 평가 전략도 필요합니다. 무작위로 생성된 시장 데이터에 대해 주의해야 합니다.
- 1, 무작위 시사 발생기가 유용하지만, 그 의미가 생성 데이터의 품질과 목표 시나리오의 디자인에 달려 있습니다:
- 2, 생성 논리는 실제 시장에 가깝게 만들어져야 한다: 무작위로 생성된 시장이 현실에서 완전히 벗어난 경우, 테스트 결과는 참조 가치가 부족할 수 있다. 예를 들어, 실제 시장의 통계적 특징 (예를 들어, 변동률 분포, 트렌드 비율) 을 결합하여 생성자를 설계할 수 있다.
- 3., 실제 데이터 테스트를 완전히 대체할 수 없다: 무작위 데이터는 전략의 개발과 최적화를 보완할 뿐이며, 최종 전략은 여전히 실제 시장 데이터에 대한 유효성을 검증해야 한다.
이렇게 많은 것을 말하면서, 우리는 어떻게 데이터를 조작할 수 있을까요? 어떻게 쉽고 빠르게, 쉽게 데이터를 조작할 수 있을까요?
디자인 아이디어
이 논문은 비교적 간단한 무작위 시장 생성 계산을 제공하기 위해 기획되어 있으며, 실제로는 다양한 모의 알고리즘, 데이터 모델 등의 기술이 적용될 수 있으며, 논의의 범위가 제한되어 있기 때문에 특히 복잡한 데이터 모의 방법을 사용하지 않습니다.
플랫폼 검색 시스템의 사용자 정의 데이터 소스 기능과 함께, 우리는 파이썬 언어로 프로그램을 작성했습니다.
- 1, 무작위로 K 라인 데이터 집합을 CSV 파일의 영구 기록으로 작성하여 생성된 데이터를 기록할 수 있도록 합니다.
- 2, 그 다음 검색 시스템에 데이터 소스를 지원하는 서비스를 생성합니다.
- 3, 생성된 K선 데이터를 그래프에 표시합니다.
일부 K선 데이터 생성 기준, 파일 저장 등에 대해서는 다음과 같은 매개 변수 컨트롤을 정의할 수 있다.
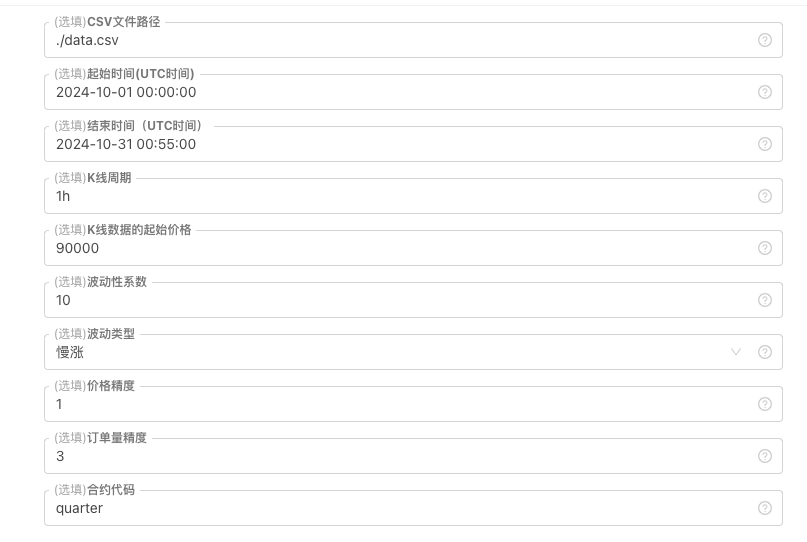
-
데이터의 무작위 생성 패턴 K선 데이터를 모방하는 변동형의 경우, 단순히 무작위 수를 양적 음의 확률로 다르게 사용하는 간단한 설계에 불과하며, 생성된 데이터가 많지 않을 때 필요한 동작 패턴을 반영하지 않을 수 있다. 더 나은 방법이 있다면, 이 부분 코드를 대체할 수 있다. 이 간단한 설계에 기초하여, 코드 내의 무작위 숫자 생성 범위와 일부 계수들을 조정하면 생성된 데이터 효과에 영향을 줄 수 있다.
-
데이터 검사 생성된 K-선 데이터에 대해서도 합리성 검사가 필요하며, 높은 가격과 낮은 가격의 정의를 위반하는지 확인하고, K-선 데이터의 연속성을 검사합니다.
재검토 시스템 무작위 거래 생성기
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
재검토 시스템에서의 연습
1, 위의 정책의 예를 만들고, 파라미터를 구성하고, 실행하십시오. 2, 디스크 ((정책 예제) 는 서버에 배포된 호스트에서 실행되어야하며, 공개 IP가 필요하기 때문에 검색 시스템이 액세스 할 수 있기 때문에 데이터를 얻을 수 있습니다. 세 번째, 인터랙션 버튼을 클릭하면 전략이 자동으로 무작위 시장 데이터를 생성합니다.

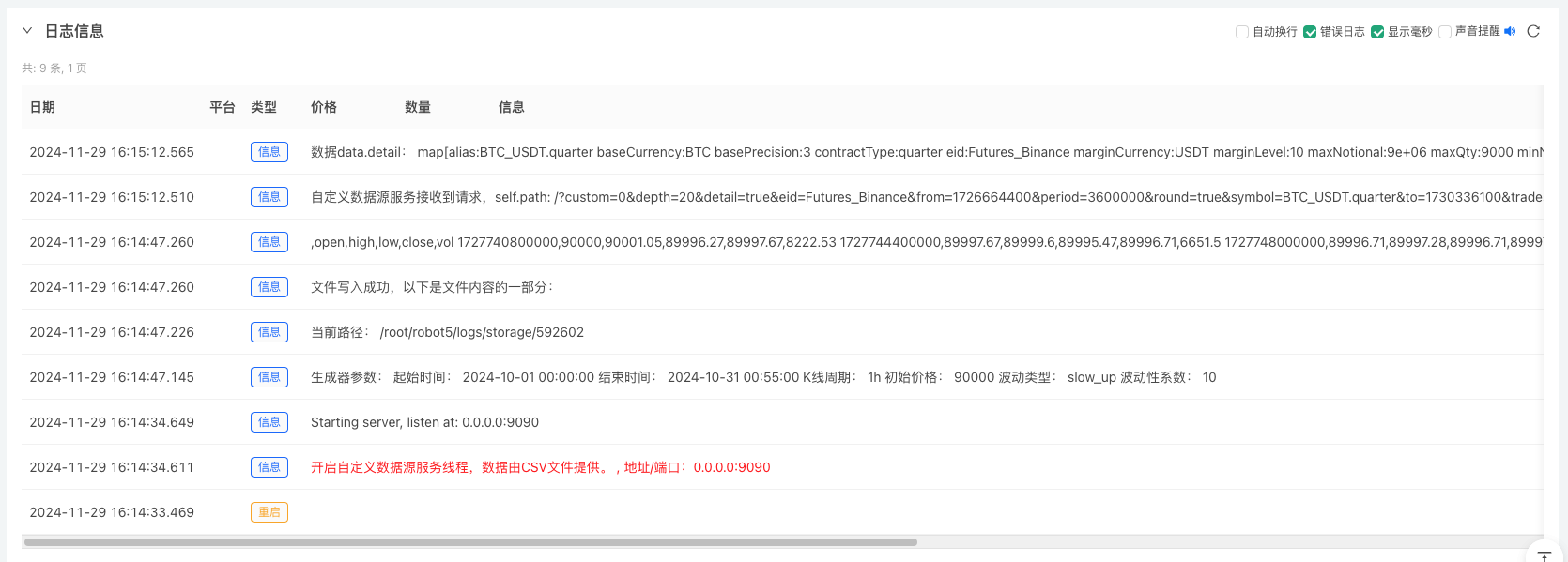
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
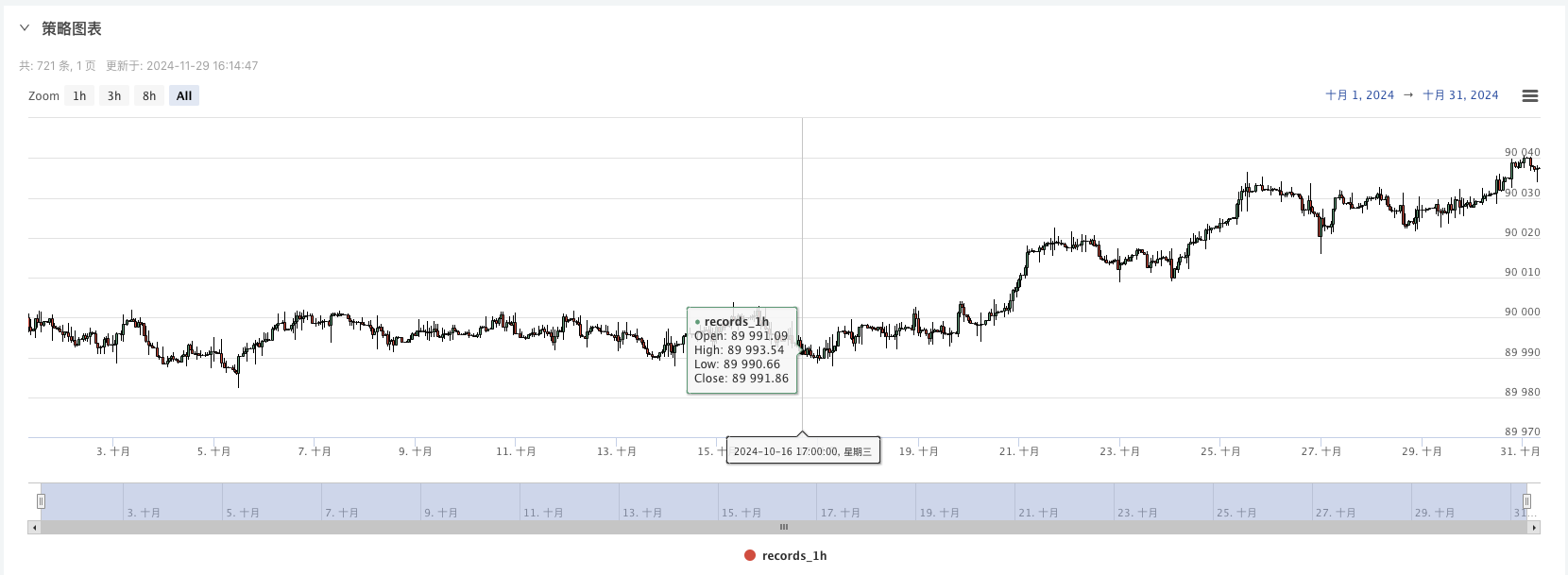
5. 이제 우리는 무작위로 생성된 데이터를 사용할 수 있습니다.
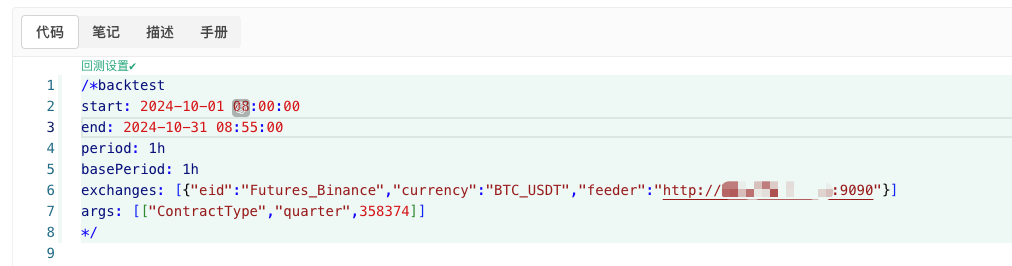
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
위 정보에 따라 구성, 개조.http://xxx.xxx.xxx.xxx:9090임의로 생성된 정책 디스크의 서버 IP 주소와 열린 포트이다.
이것은 사용자 지정 데이터 소스입니다. 플랫폼 API 문서의 사용자 지정 데이터 소스 섹션을 참조하십시오.
6. 리코딩 시스템을 설정하면 무작위 시장 데이터를 테스트 할 수 있습니다.
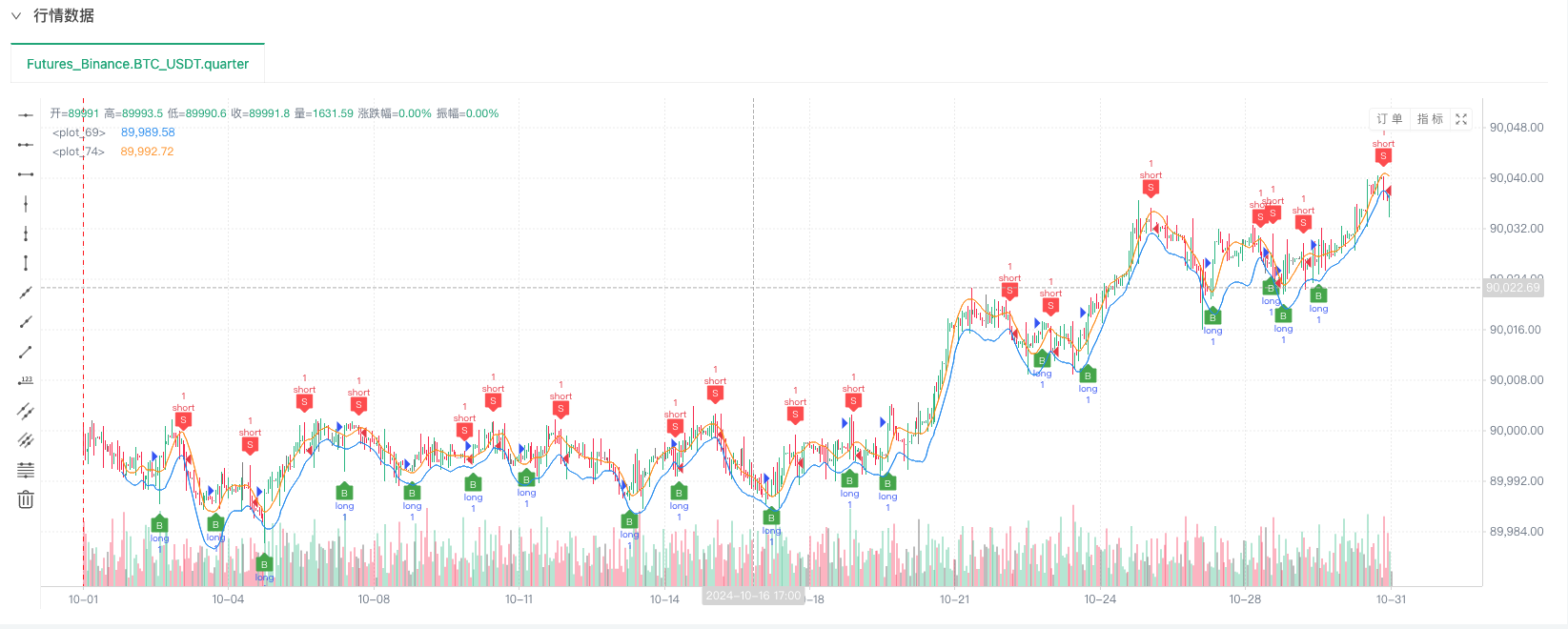
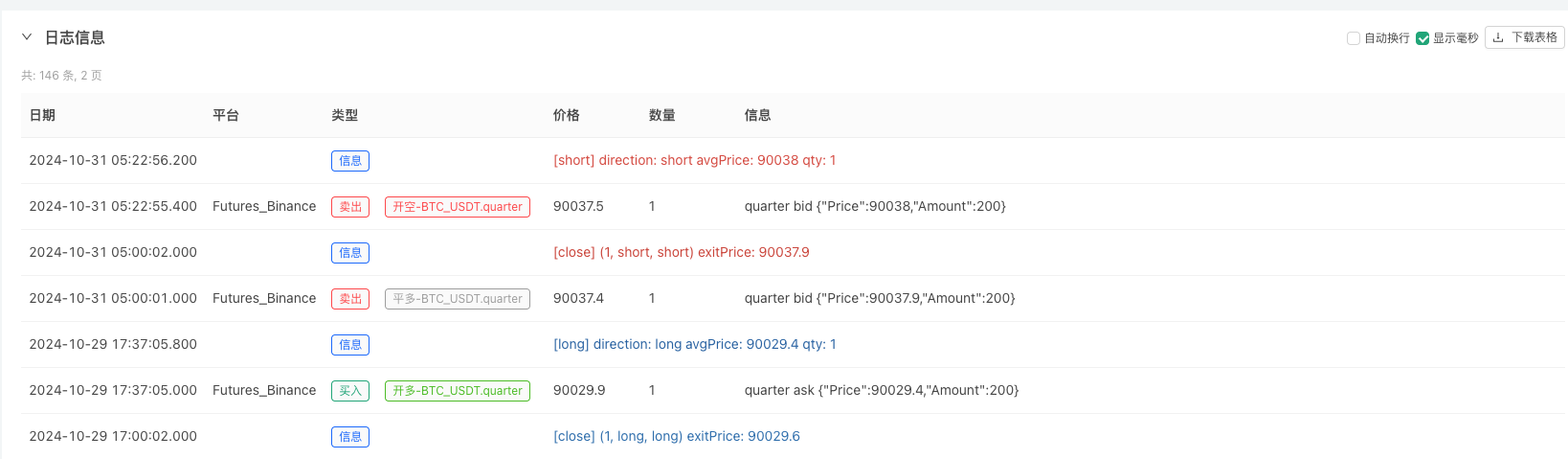
이 때 재검토 시스템은 우리의
7, 오, 맞습니다, 거의 잊어 버렸어요! 이 무작위 행렬 생성기의 파이썬 프로그램이 실제 디스크를 만드는 이유는 생성된 K 라인 데이터를 설명, 조작, 표시하는 데 편리하기 위해서입니다. 실제 응용 프로그램에서는 독립적인 파이썬 스크립트를 완전히 쓸 수 있습니다.
이 전략의 소스 코드는:재검토 시스템 무작위 거래 생성기
이 글은 많은 사람들에게 알려졌습니다.
- 디지털 화폐의 리드-래그 스위트 소개 (3)
- 암호화폐의 리드-래그 중재에 대한 소개 (2)
- 디지털 화폐의 리드-래그 스위트 소개 (2)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 전략 내 내장 Http 서비스와 함께 신호 수신에 대한 완전한 솔루션
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 전략 내장 HTTP 서비스 신호 수신의 전체 방안
- 암호화폐의 리드-래그 중재에 대한 소개 (1)
- 디지털 화폐의 리드-래그 스위트 소개 (1)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 확장 API VS 전략 내장 HTTP 서비스
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 확장 API vs 전략 내장 HTTP 서비스
- 무작위 틱커 생성기에 기반한 전략 테스트 방법 논의
- FMZ Quant의 새로운 기능: _Serve 기능을 사용하여 HTTP 서비스를 쉽게 만들 수 있습니다
- 발명가들의 새로운 기능: _Serve 기능을 사용하여 쉽게 HTTP 서비스를 만들 수 있습니다.
- FMZ 양자 거래 플랫폼 사용자 지정 프로토콜 액세스 가이드
- FMZ 펀딩 비율 획득 및 모니터링 전략
- FMZ 자금률 확보 및 모니터링 전략 전략
- 전략 템플릿은 웹소켓 마켓을 원활하게 사용할 수 있습니다
- 웹소켓을 원활하게 사용할 수 있는 정책 템플릿
- 발명가 양적 거래 플랫폼 일반 프로토콜 접근 지침
- FMZ 업그레이드 후 어떻게 하면 유니버설 멀티 화폐 거래 전략을 빠르게 구축 할 수 있습니까?
- FMZ 업그레이드 후 어떻게 더 빠르게 통용형 다화 거래 전략을 구축할 수 있습니까?