돈을 잃지 않는 비트코인 거래 로봇을 만드는 것
저자:선함, 2019-06-27 10:58:40, 업데이트: 2024-12-24 20:16:45
인공지능의 강화학습을 사용하여 디지털 통화 거래 로봇을 만들자.
이 문서에서는, 우리는 Bitcoin 거래 로봇을 만드는 방법을 배우기 위해 강화 학습
지난 몇 년 동안 OpenAI와 DeepMind이 깊이 학습 연구자들에게 제공하는 오픈 소스 소프트웨어에 감사드립니다. 만약 그들이 AlphaGo, OpenAI Five, AlphaStar 같은 기술을 사용하여 놀라운 업적을 이루지 않았다면, 당신은 지난 1 년 동안 격리된 상태에서 살았을 수도 있지만, 당신은 그들을 보아야합니다.
알파스타 교육https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
우리는 놀라운 것을 만들지 않을 것이지만, 일상 거래에서 비트코인 로봇 거래는 여전히 쉬운 일이 아닙니다.
이 모든 것은 매우 간단하게 얻을 수 있는 가치가 없습니다.
그래서 우리는 자율적으로 거래하는 것을 배우는 것뿐만 아니라... 로봇이 우리를 대신해서 거래하도록 해야 합니다.
계획

1.为我们的机器人创建gym环境以供其进行机器学习
2.渲染一个简单而优雅的可视化环境
3.训练我们的机器人,使其学习一个可获利的交易策略
만약 당신이 운동장 환경을 처음부터 어떻게 만들지, 또는 그 환경을 어떻게 간단하게 표현할 수 있는지에 대해 익숙하지 않다면, 계속하기 전에 Google에 이런 기사를 찾아보시기 바랍니다. 이 두 가지 동작은 초보 프로그래머로서도 어렵지 않을 것입니다.
입구
在本教程中,我们将使用Zielak生成的Kaggle数据集。如果您想下载源代码,我的Github仓库中会提供,同时也有.csv数据文件。好的,让我们开始吧。
먼저, 필요한 모든 라이브러리를 가져오도록 하자. pip로 놓친 라이브러리를 설치하도록 하십시오.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
다음으로, 환경을 위해 우리의 클래스를 만들겠습니다. 우리는 pandas의 데이터
우리는 또한 데이터에 dropna () 와 reset_index () 를 호출하고 NaN값을 가진 줄을 먼저 삭제하고, 데이터를 삭제했기 때문에
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
우리의 action_space는 여기에 세 가지 옵션의 한 그룹 (구매, 판매 또는 보유) 과 다른 그룹 (10의 금액) 의 1/10로 나타납니다.2⁄10, 3/10 등등) ; 구매하는 동작을 선택할 때 우리는 구매 금액 * BTC의 self.balance worth of BTC;; 판매하는 동작을 위해 우리는 sell amount * BTC의 self.btc_held worth of BTC;; 물론, 보유하는 동작은 금액을 무시하고 아무것도하지 않습니다;;
우리의 observation_space는 0에서 1 사이의 연속적인 플로데이터 집합으로 정의되며, 모양은 ((10,lookback_window_size + 1);; + 1으로 현재 시간걸이를 계산합니다. 창에 있는 각 시간걸이를 위해 우리는 OHCLV 값을 관찰할 것입니다.
다음으로, 우리는 환경을 초기화하기 위해 재설정 방법을 작성해야 합니다.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
여기 우리는 self._reset_session와 self._next_observation을 사용했는데, 아직 정의하지 않았습니다. 먼저 정의해 보죠.
거래 회담
我们环境的一个重要部分是交易会话的概念。如果我们将这个机器人部署到市场外,我们可能永远不会一次运行它超过几个月。出于这个原因,我们将限制self.df中连续帧数的数量,也就是我们的机器人连续一次能看到的帧数。
우리의_reset_session 방법에서는 먼저 current_step를 0로 다시 설정합니다. 다음으로 우리는 steps_left을 1에서 MAX_TRADING_SESSION 사이의 무작위 숫자로 설정합니다. 이 부분은 프로그램의 꼭대기에 정의합니다.
MAX_TRADING_SESSION = 100000 # ~2个月
다음으로, 만약 우리가 연속적으로
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
무작위 조각에서 데이터 벡터를 탐색하는 중요한 부작용은 우리의 로봇이 긴 시간 동안 훈련할 때 사용할 수 있는 더 많은 고유한 데이터를 갖게 되는 것이다. 예를 들어, 우리가 데이터 벡터를 연속적으로 탐색하는 것 (즉 0에서 len까지의 순서) 을만 한다면, 우리는 데이터 벡터 중에서 단 하나의 데이터 포인트만큼만 많을 것이다. 우리의 관측 공간은 심지어 각 시간 단계에 대해 불분석한 수의 상태를만 채택할 수 있다.
그러나, 데이터 세트의 조각을 무작위로 탐색함으로써, 우리는 초기 데이터 세트의 각 시간대에 더 의미있는 거래 결과 집합을 만들 수 있습니다. 즉, 거래 행동과 이전에 본 가격 행동의 조합을 통해 더 독특한 데이터 세트를 만들 수 있습니다. 예를 하나 보여드리겠습니다.
재설계 순환 환경의 시간 단계가 10일 때, 우리의 로봇은 항상 데이터 세트 내에서 동시에 실행될 것이고, 각각의 시간 단계에 따라 세 가지 선택지가 있습니다: 구매, 판매, 또는 보유. 이 세 가지 선택의 각각에 대해 다른 선택이 필요합니다: 10%, 20%,..., 또는 100%의 구체적인 실행량. 이것은 우리의 로봇이 103의 10가지 중 어느 하나에 직면할 수 있음을 의미합니다. 총 1030개의 상황입니다.
이제 우리의 무작위 컷 환경으로 돌아갑니다. 시간 경로가 10일 때, 우리의 로봇은 데이터 칸 수 내의 모든 len (df) 시간 경로에 있을 수 있습니다. 각각의 시간 경로 후에 동일한 선택을 하는 것을 가정하면 로봇이 동일한 10 시간 경로에서 모든 len (df) 30차원 중 유일한 상태를 경험할 수 있다는 것을 의미합니다.
이것은 큰 데이터 세트에서 상당히 큰 소음을 일으킬 수 있지만, 저는 로봇이 우리의 제한된 데이터에서 더 많은 것을 배울 수 있도록 해야 한다고 믿습니다. 우리는 여전히 우리의 테스트 데이터를 순차적으로 탐색하여 최신의, 마치 실시간으로
로봇의 눈으로 관찰한 것
효과적인 시각적 환경을 관찰하는 것이 종종 도움이 되는데, 우리의 로봇이 사용하려는 기능의 유형을 이해하는 데 도움이 된다. 예를 들어, OpenCV 렌더링을 사용하여 관찰 가능한 공간의 시각화이다.

OpenCV 시각화 환경의 관측
그림의 각 줄은 우리의 관찰_스페이스의 한 줄을 나타냅니다. 앞 4 줄의 비슷한 주파수의 빨간 줄은 OHCL 데이터를 나타냅니다. 바로 아래의 오렌지색과 노란색 점들은 거래량을 나타냅니다. 아래의 휘발성 파란색 줄은 로봇의 순수이고 아래의 가벼운 줄은 로봇의 거래를 나타냅니다.
만약 당신이 자세히 관찰한다면, 당신은 심지어 직접
- 로봇이 지금까지 관찰한 데이터만을 확장하는 것이 중요하며, 이는 전진 편차를 방지하기 위한 것이다.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
행동하라
우리는 우리의 관측 공간을 구축했고, 이제 우리의 계단 함수를 작성하고 로봇이 예정한 행동을 취할 때입니다. 우리는 현재 거래 시간에 있는 self.steps_left == 0을 매각하고 BTC를 호출합니다.재설정session ((() ;; 그렇지 않으면, 우리는 현재 순으로 보상을 설정하고, 우리의 자금이 다 사용되면 True로 완료를 설정합니다.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
거래 행동을 취하는 것은 current_price를 얻는 것, 실행해야 할 동작과 구매 또는 판매의 수를 결정하는 것만큼 간단합니다. 우리의 환경을 테스트 할 수 있도록 빠르게_take_action를 작성해 봅시다.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
最后,在同一方法中,我们会将交易附加到self.trades并更新我们的净值和账户历史。
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
우리의 로봇은 이제 새로운 환경을 시작하고, 그 환경을 단계적으로 완성하고, 환경에 영향을 미치는 동작을 할 수 있습니다.
우리의 로봇 거래를 보세요.
우리의 렌더링 방법은 print (self.net_worth) 를 호출하는 것만큼 간단할 수 있지만 재미는 충분하지 않습니다. 대신, 우리는 거래량
我们将从我上一篇文章中获取StockTradingGraph.py中的代码,并重新设计它以适应比特币环境。你可以从我的Github中获取代码。
우리가 할 첫 번째 변화는 self.df [
from datetime import datetime
먼저, datetime 라이브러리를 가져오면, 우리는 utcfromtimestampmethod를 사용하여 각 시간대와 strftime에서 UTC 문자열을 가져와서:Y-m-d H:M 형식의 문자열로 형식을 만듭니다.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
마지막으로, 우리는 우리의 데이터 세트를 맞추기 위해 self.df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
오! 이제 우리는 우리의 로봇이 비트코인을 거래하는 것을 볼 수 있습니다.

우리의 로봇 거래를 Matplotlib로 시각화합니다.
초록색의 유령표는 BTC의 구매를, 빨간색의 유령표는 판매를 나타냅니다. 오른쪽 상단의 흰색표는 로봇의 현재 순액이고 오른쪽 하단의 표는 비트코인의 현재 가격입니다. 간단하고 우아합니다. 이제 로봇을 훈련시킬 때입니다. 얼마나 많은 돈을 벌 수 있는지 봅시다!
훈련시간
전 기사에서 받은 비판 중 하나는 데이터들을 트레이닝 세트와 테스트 세트로 나누지 않고 크로스 검증이 부족하다는 것입니다. 그렇게 하는 것은 이전에 볼 수 없었던 새로운 데이터에 대한 최종 모델의 정확성을 테스트하기 위한 것입니다. 이 글의 관심사는 아니지만, 정말 중요합니다. 우리는 시간 계열 데이터를 사용하기 때문에 크로스 검증에 있어서 선택의 여지가 많지 않습니다.
예를 들어, 일반적인 형태의 크로스 검증은 k-fold 검증이라고 하며, 이 검증에서는 데이터를 k 개의 동등한 그룹으로 분할하고, 각각 하나의 그룹을 개별적으로 테스트 그룹으로 사용하고, 나머지 데이터를 훈련 그룹으로 사용합니다. 그러나, 시간 계열 데이터가 매우 시간 의존적입니다. 이것은 후속 데이터가 이전 데이터에 매우 의존한다는 것을 의미합니다. 따라서 k-fold은 작동하지 않을 것입니다. 왜냐하면 우리의 로봇이 거래 전에 미래 데이터에서 배우기 때문에 불공평한 장점입니다.
시간 계열 데이터에 적용될 때, 동일한 결함은 대부분의 다른 교차 검증 전략에도 적용된다. 따라서 우리는 단지 전체 데이터의
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
다음으로, 우리의 환경은 단일 데이터
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
现在,训练我们的模型就像使用我们的环境创建机器人并调用model.learn一样简单。
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
여기에 우리는 팽창판을 사용해서 우리의 팽창 흐름 그래프를 쉽게 시각화하고 우리의 로봇에 대한 몇 가지 양적 지표를 볼 수 있습니다. 예를 들어, 아래는 많은 로봇이 200,000번 이상의 시간 걸음을 가진 할인된 보상 차트입니다.
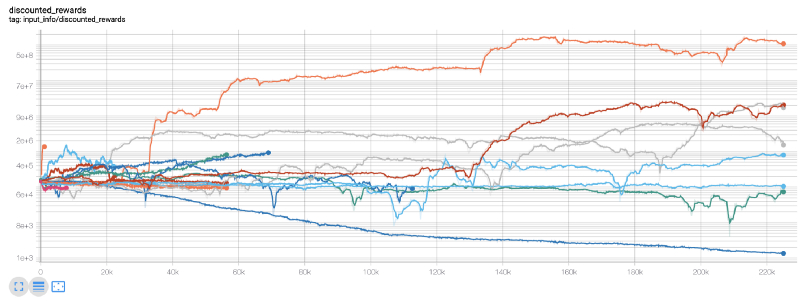
우리 최고의 로봇은 200,000단계 동안 1000배의 균형을 이룰 수 있고, 나머지 평균은 최소 30배나 증가합니다!
이 순간, 저는 환경의 오류가 있다는 것을 깨달았습니다. 그 오류를 수정한 후, 새로운 보상표가 있습니다.
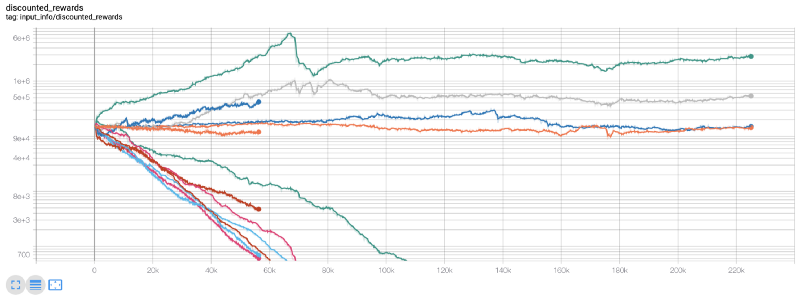
보시다시피, 우리 로봇들 중 일부는 잘하고 나머지는 스스로 파산합니다. 하지만, 좋은 로봇은 최대 10배, 심지어 60배까지 초기 잔액에 도달할 수 있습니다. 저는 모든 수익성 있는 로봇들이 수수료 없이 훈련되고 테스트를 받았다는 것을 인정해야 합니다. 그래서 우리의 로봇들이 진짜 돈을 벌 수 있는 것은 실용적이지 않습니다. 하지만 적어도 우리는 방향을 찾았습니다!
우리는 로봇을 테스트 환경에서 테스트해 보겠습니다. (그것들이 이전에 본 적이 없는 새로운 데이터를 사용해서) 그들이 어떻게 행동하는지 보자.
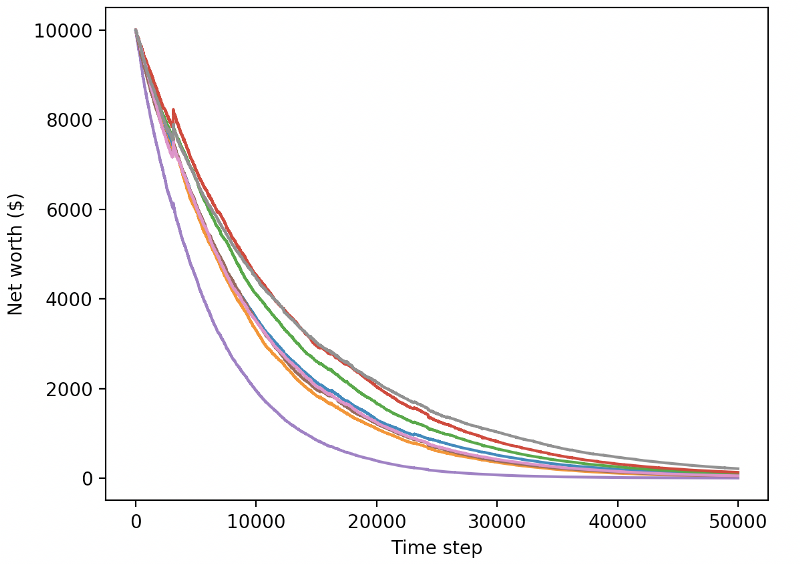
우리의 훈련된 로봇들은 새로운 테스트 데이터를 거래할 때 파산합니다.
분명히, 우리는 아직 많은 일을 해야 합니다. 우리는 단순히 모델로 전환하여 현재 PPO2 로봇 대신 안정적인 기본 라인 A2C를 사용함으로써 이 데이터 세트에 대한 우리의 성능을 크게 향상시킬 수 있습니다. 그리고 마지막으로, 션 오
reward = self.net_worth - prev_net_worth
이 두 가지 변화만으로도 테스트 데이터 세트의 성능을 크게 향상시킬 수 있으며, 아래에서 볼 수 있듯이, 우리는 마침내 훈련 세트에서 없는 새로운 데이터에서 이익을 얻을 수 있습니다.
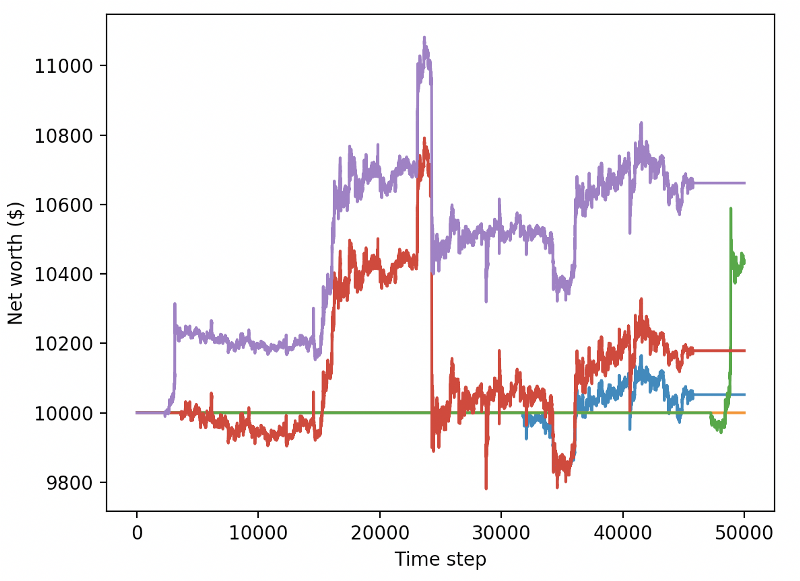
그러나 우리는 더 잘 할 수 있습니다. 이러한 결과를 개선하기 위해 우리는 우리의 초개 변수를 최적화하고 우리의 로봇을 더 오랫동안 훈련해야 합니다. GPU가 작동하고 총을 켜는 시간이 되었습니다!
이제까지 이 문서는 조금 길고, 우리가 고려해야 할 많은 세부 사항이 남아있기 때문에 우리는 여기서 잠시 휴식을 취할 계획입니다. 다음 기사에서는 우리는 베이어스 최적화를 사용하여 우리의 문제 공간에 최적의 초 파라미터를 구분하고 CUDA를 사용하여 GPU에서 훈련/테스트를 준비할 것입니다.
결론
이 글에서는 우리는 강화 학습을 사용하여 처음부터 수익성 있는 비트코인 거래 로봇을 만들기 시작했습니다. 우리는 다음과 같은 작업을 수행할 수 있습니다.
1.使用OpenAI的gym从零开始创建比特币交易环境。
2.使用Matplotlib构建该环境的可视化。
3.使用简单的交叉验证对我们的机器人进行训练和测试。
4.略微调整我们的机器人以实现盈利
우리의 거래 로봇은 우리가 기대했던 만큼 수익성이 높지는 않았지만, 우리는 올바른 방향으로 나아가고 있습니다. 다음 번에 우리는 우리의 로봇이 항상 시장을 이길 수 있도록 보장하고 우리의 거래 로봇이 실시간 데이터를 처리하는 방법을 보게 될 것입니다.
- DEX 거래소의 양적 관행 (2) -- 하이퍼 액성 사용자 가이드
- DEX 거래소 정량화 연습 ((2)-- Hyperliquid 사용 지침
- DEX 거래소의 양적 관행 (1) -- dYdX v4 사용자 안내
- 암호화폐의 리드-래그 중재에 대한 소개 (3)
- DEX 거래소 정량화 연습 ((1)-- dYdX v4 사용 설명서
- 디지털 화폐의 리드-래그 스위트 소개 (3)
- 암호화폐의 리드-래그 중재에 대한 소개 (2)
- 디지털 화폐의 리드-래그 스위트 소개 (2)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 전략 내 내장 Http 서비스와 함께 신호 수신에 대한 완전한 솔루션
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 전략 내장 HTTP 서비스 신호 수신의 전체 방안
- 암호화폐의 리드-래그 중재에 대한 소개 (1)
- 디지털 화폐 자율적 직선적 거래 시스템 및 KAMA 알고리즘 해독 팩 발명자 기반의 양적 거래 소프트웨어
- FMZ 발명자 양적 플랫폼 재검토 설명
의 이동평균 동작의 간단한 시범 (My Language Version) - 산업 대웅은 알고리즘 거래를 공개합니다: 발명가들의 시장 전략으로 정량화 플랫폼
- DMI 지표의 계산과 응용
- SPY와 IWM 사이의 평균 회귀를 사용하는 내일 거래 전략
- 아론 (Aroon) 기술 지표의 양적 거래에서의 사용
- 자바스크립트를 사용하여 양정책을 구현하여
포괄 Go 함수를 동시에 실행합니다 - 생존의 비결: 19명의 전문가들이 디지털 통화 거래에 대한 조언을 공유합니다
샤넌의 악마의 이 디지털 통화에 적용되는 방법 - 양적 거래에서 자산 관리에 대한 절대적인 이익의 CTA 전략 개발
- 9가지 거래 규칙은 거래자가 1년 이내에 1,000달러에서 46,000달러로 올리는 데 도움이 됩니다.
- 발명가들의 양적 거래에 대한 소개 - 기본부터 실제 전쟁까지
- 5.5 거래 전략 최적화
- 5.4 표본 이외의 테스트가 필요한 이유는
- 5.3 전략 백테스트 성과 보고서를 읽는 방법
- 5.2 수량적 거래 백테스팅을 어떻게 수행합니까?
- 5.1 백테스팅의 의미와 함정
- 4.6 C++ 언어에서 전략을 구현하는 방법
- 4.5 C++ 언어 빠른 시작