신경망 및 디지털 통화 양적 거래 시리즈 (2) - 집중 학습 및 훈련 비트코인 거래 전략
저자:FMZ~리디아, 창작: 2023-01-12 16:49:09, 업데이트: 2024-12-19 21:09:28
신경망 및 디지털 통화 양적 거래 시리즈 (2) - 집중 학습 및 훈련 비트코인 거래 전략
1. 소개
지난 기사에서 우리는 비트코인의 가격을 예측하기 위해 LSTM 네트워크의 사용을 소개했습니다.https://www.fmz.com/bbs-topic/9879, 기사에서 언급했듯이, 그것은 RNN과 pytorch에 익숙해지는 작은 교육 프로젝트입니다. 이 기사에서는 거래 전략을 직접 훈련시키기 위해 집중 학습의 사용을 소개합니다. 집중 학습 모델은 OpenAI 오픈 소스 PPO이며 환경은 체육관의 스타일을 의미합니다. 이해와 테스트를 촉진하기 위해 LSTM의 PPO 모델과 백테스팅을위한 체육관 환경은 준비된 패키지를 사용하지 않고 직접 작성됩니다. PPO 또는 근접 정책 최적화 (Proximal Policy Optimization) 는 Policy Gradient의 최적화 개선 프로그램이다. gym는 OpenAI에서 출시했다. 전략 네트워크와 상호 작용하고 현재 환경의 상태와 보상을 피드백 할 수 있다. 집중 학습의 연습과 같다. 그것은 LSTM의 PPO 모델을 사용하여 비트코인의 시장 정보에 따라 직접 구매, 판매 또는 운영을 하지 않는 등의 지침을 만든다. 피드백은 백테스트 환경이 제공한다. 훈련을 통해 모델은 전략적 이익의 목표를 달성하기 위해 지속적으로 최적화된다. 이 기사를 읽는 것은 파이썬, 피토치 및 DRL에서 깊이있는 집중 학습의 기초가 필요합니다. 그러나 당신이 할 수 없더라도 중요하지 않습니다. 이 기사에 제공 된 코드로 배우기 쉽고 시작할 수 있습니다. 이 튜토리얼은 FMZ 퀀트 트레이딩 플랫폼 (www.fmz.comQQ 그룹에 오신 것을 환영합니다: 863946592 통신.
2. 데이터 및 학습 참조
FMZ 퀀트 트레이딩 플랫폼에서 얻은 비트코인 가격 데이터:https://www.quantinfo.com/Tools/View/4.html- 그래요 DRL+gym을 사용하여 거래 전략을 훈련하는 기사:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4- 그래요 피토치 (pytorch) 를 시작하는 몇 가지 예:https://github.com/yunjey/pytorch-tutorial- 그래요 이 문서는 LSTM-PPO 모델에 의해 직접 구현됩니다:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py- 그래요 PPO 에 관한 기사:https://zhuanlan.zhihu.com/p/38185553- 그래요 DRL에 관한 더 많은 기사:https://www.zhihu.com/people/flood-sung/posts- 그래요 체육관에 관한 이 기사에는 설치가 필요 없지만 집중학습에서는 매우 일반적입니다.https://gym.openai.com/.
3. LSTM-PPO
PPO에 대한 심층적인 설명은 이전 참조 자료에서 배울 수 있습니다. 여기 개념에 대한 간단한 소개입니다. LSTM 네트워크의 마지막 이슈는 가격만을 예측했습니다. 예측된 가격에 따라 구매 및 판매하는 방법은 별도로 실현되어야합니다. 거래 행동의 직접적인 출력이 더 직접적 일 것이라고 생각하는 것은 당연합니다. 이것은 입력 환경 정보 s에 따라 다양한 행동의 확률을 줄 수있는 정책 경사도의 경우입니다. LSTM의 손실은 예측된 가격과 실제 가격의 차이이며 PG의 손실은 - log § * Q이며, p는 출력 행동의 확률이며 Q는 행동의 값입니다.
LSTM-PPO의 소스 코드는 아래에서 제시되어 있으며, 이전 데이터와 결합하여 이해할 수 있습니다.
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. 비트코인 백테스팅 환경
체육관의 형식을 따라 리셋 초기화 방법이 있습니다. 단계 입력 액션, 반환 결과 (다음 상태, 액션 수입, 종료 여부, 추가 정보). 전체 백테스트 환경 또한 60 줄입니다. 더 복잡한 버전을 직접 수정 할 수 있습니다. 특정 코드는:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. 몇 가지 주목 할 만한 세부 사항
- 왜 초기 계좌에 화폐가 있나요?
백테스트 환경의 수익률을 계산하는 공식은: 현재 수익률 = 현재 계좌 가치 - 초기 계좌의 현재 가치입니다. 이것은 비트코인 가격이 감소하고 전략이 동전 판매 작업을 수행하는 경우 전체 계좌 가치가 감소하더라도 전략이 실제로 보상되어야한다는 것을 의미합니다. 백테스트가 오래 걸리면 초기 계정이 거의 영향을 미치지 않을 수 있지만 처음에는 큰 영향을 줄 것입니다. 상대적 수익률의 계산은 모든 올바른 작업이 긍정적 인 보상을 얻을 수 있음을 보장합니다.
- 왜 훈련 중에 시장 샘플링이 있었습니까?
데이터의 총 양은 10,000 K-라인 이상입니다. 매번 루프를 완전히 실행하면 시간이 오래 걸리고 전략이 매번 동일한 상황에 직면하면 과격이 더 쉬울 수 있습니다. 백테스트로 한 번에 500 바를 복용하십시오. 여전히 과격이 가능하지만 전략은 10,000 개 이상의 가능한 시작에 직면합니다.
- 돈이나 통화가 없다면요?
이러한 상황은 백테스트 환경에서 고려되지 않습니다. 통화가 매진되거나 최소 거래 양이 달성 될 수 없는 경우, 판매 작전은 실제로 작동하지 않는 것과 동등합니다. 상대 수익의 계산 방법에 따라 가격이 감소하면 여전히 전략적 긍정적 인 수익을 기반으로합니다. 이러한 상황의 영향은 전략이 시장이 감소하고 계정의 나머지 통화가 판매 될 수 없다고 판단하면 판매 행동을 작동하지 않는 행동과 구별하는 것이 불가능하지만 시장에서 전략 자체의 판단에 영향을 미치지 않습니다.
- 왜 계정 정보를 상태로 반환해야 할까요?
PPO 모델은 현재 상태의 가치를 평가하기 위해 가치 네트워크를 가지고 있습니다. 분명히, 전략이 가격이 증가할 것이라고 판단하면 전체 상태는 현재 계정이 비트코인을 보유 할 때만 긍정적 인 가치를 가지게 될 것이며, 그 반대의 경우입니다. 따라서 계정 정보는 가치 네트워크 판단의 중요한 기초입니다. 과거 행동 정보가 상태로 반환되지 않는다는 점에 유의하십시오. 가치를 판단하는 것은 쓸모가 없다고 생각합니다.
- 언제 다시 작동하지 않을까요?
전략은 거래로 인한 수익이 처리 수수료를 감당할 수 없다고 판단하면 운영하지 않는 상태로 돌아가야합니다. 이전 설명은 가격 추세를 판단하기 위해 전략을 반복적으로 사용하지만 이해의 편의를 위해입니다. 실제로이 PPO 모델은 시장을 예측하지 않고 세 가지 행동의 확률만을 출력합니다.
6. 데이터 수집 및 교육
이전 기사와 마찬가지로 데이터 획득 방법과 형식은 다음과 같습니다. Bitfinex 거래소 BTC_USD 거래 쌍의 1 시간 기간 K 라인 2018년 5월 7일부터 2019년 6월 27일까지:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
LSTM 네트워크 사용으로 인해 훈련 시간은 매우 길습니다. GPU 버전으로 변경했습니다. 약 3배 더 빠르죠.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. 교육 결과와 분석
오랜 기다림 끝에:

우선 교육 데이터 시장을 살펴보면 전반적으로 첫 반기는 장기적인 하락이고 두 번째 반기는 강한 회복입니다.
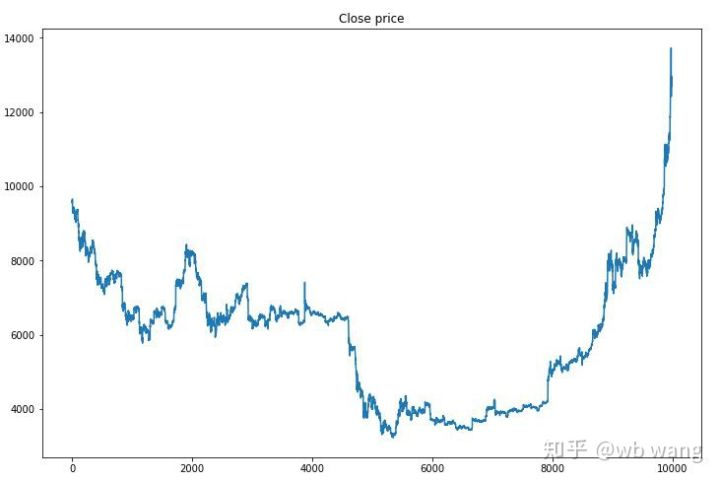
훈련 초기에는 많은 구매 거래가 있으며, 기본적으로 수익 라운드가 없습니다. 훈련 중간에 구매 거래가 점차 감소하고 수익 확률도 증가하지만 여전히 큰 손실 가능성이 있습니다.
각 라운드의 수익을 평형화하면, 결과는 다음과 같습니다.
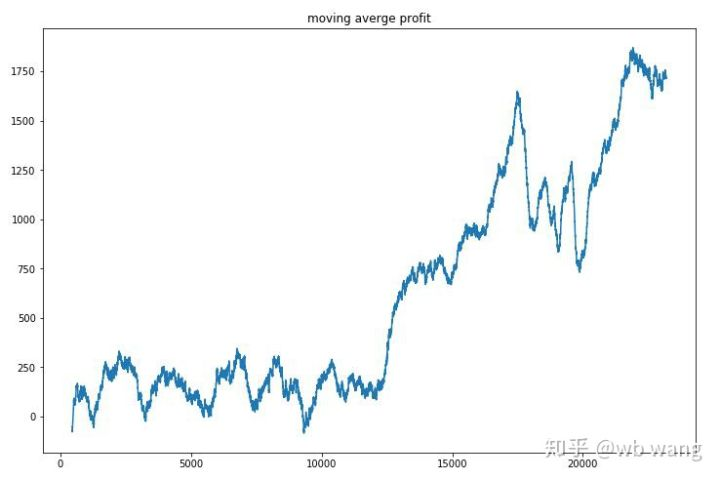
이 전략은 초기 수익이 부정적이라는 상황을 빠르게 제거했지만 변동은 크다. 수익은 10,000 라운드가 끝날 때까지 빠르게 증가하지 않았다. 일반적으로 모델 훈련은 매우 어려웠다.
최종 훈련 후, 모델이 모든 데이터를 다시 실행하여 어떻게 수행하는지 확인하십시오. 기간 동안, 계좌의 전체 시장 가치, 보유된 비트코인 수, 비트코인 가치의 비율 및 총 수익을 기록하십시오. 첫 번째는 전체 시장 가치입니다. 그리고 전체 수익은 그와 비슷합니다.
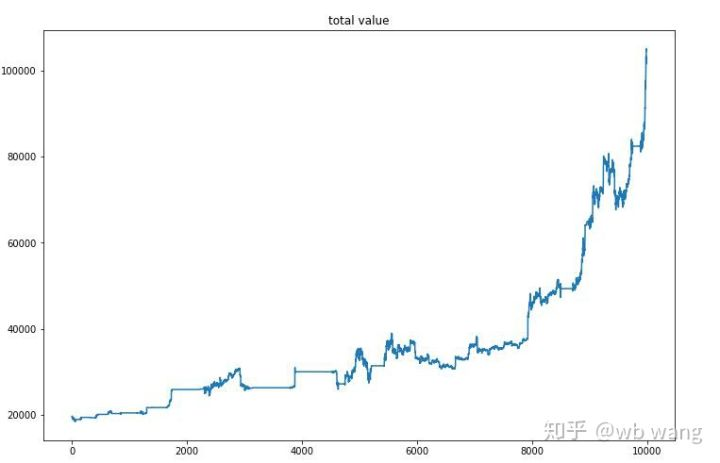
전체 시장 가치는 초기 곰 시장에서 서서히 증가했으며 후기 황소 시장의 증가와 함께 유지되었지만 여전히 주기적인 손실이있었습니다.
마지막으로, 포지션 비율을 살펴보십시오. 차트의 왼쪽 축은 포지션 비율이고 오른쪽 축은 시장입니다. 모델이 과도하게 적합하다는 것을 예비적으로 판단 할 수 있습니다. 초기 곰 시장에서 포지션 빈도는 낮고 시장 하단에 높습니다. 모델이 장기 포지션을 보유하는 것을 배우지 않았으며 항상 빠르게 판매한다는 것도 볼 수 있습니다.
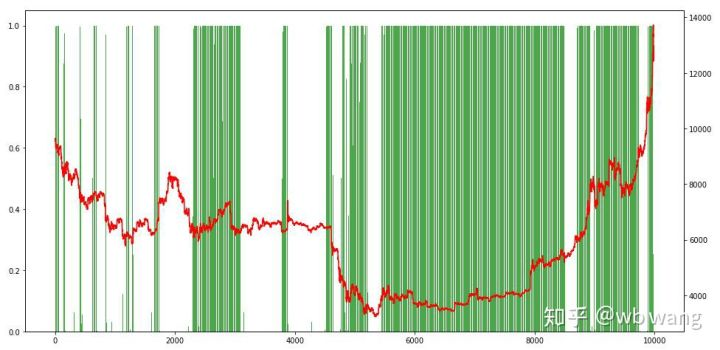
8. 테스트 데이터 분석
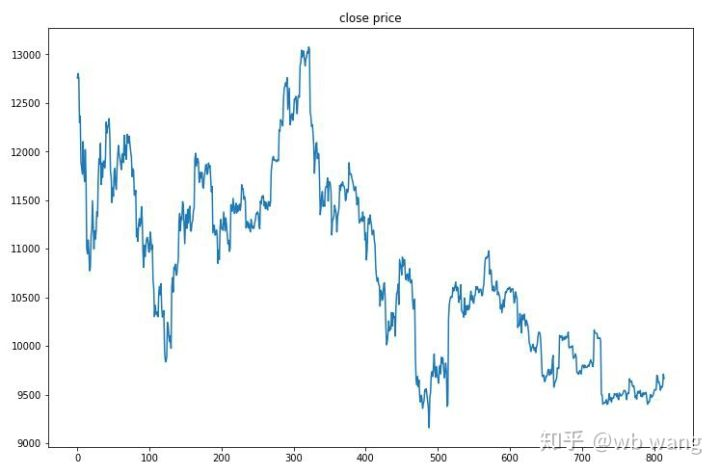
2019년 6월 27일부터 현재까지 1시간 동안의 비트코인 시장은 테스트 데이터에서 얻었습니다. 차트에서 가격이 13,000달러에서 9,000달러 이상으로 떨어졌다는 것을 볼 수 있습니다. 이는 모델에 대한 훌륭한 테스트입니다.
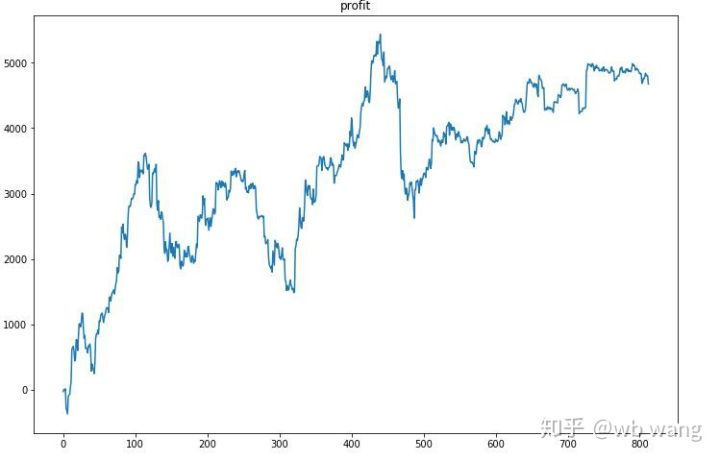
우선, 최종 상대적 환산은 이렇게 되지만 손실은 없었습니다.
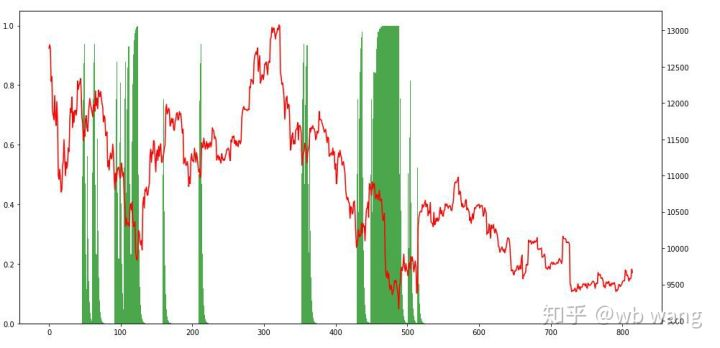
포지션 상황을 살펴보면 모델이 급격한 하락 후 구매하고 리바운드 후에 판매하는 경향이 있다고 추측 할 수 있습니다. 비트코인 시장은 최근 기간 동안 거의 변동하지 않았으며 모델은 짧은 위치에있었습니다.
9. 요약
이 논문에서는 비트코인 자동 거래 로봇이 심층 집중 학습 방법인 PPO의 도움으로 훈련되고 몇 가지 결론을 얻는다. 제한된 시간으로 인해 모델에는 여전히 개선해야 할 몇 가지 측면이 있다. 토론을 환영한다. 가장 큰 교훈은 데이터 표준화 방법의 경우 스케일링 및 기타 방법을 사용하지 않는 것이므로 모델은 가격과 시장 사이의 관계를 빠르게 기억하고 과도하게 부착 될 것입니다. 표준화 변화율은 상대적 데이터이며 모델이 시장과의 관계를 기억하는 것을 어렵게 만들고 변화율과 증가와 감소 사이의 관계를 찾을 수 밖에 없습니다.
이전 기사 소개: 제가 공개한 고주파 전략은 한때는 매우 수익성이 있었습니다.https://www.fmz.com/bbs-topic/9886.
- 암호화폐의 리드-래그 중재에 대한 소개 (2)
- 디지털 화폐의 리드-래그 스위트 소개 (2)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 전략 내 내장 Http 서비스와 함께 신호 수신에 대한 완전한 솔루션
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 전략 내장 HTTP 서비스 신호 수신의 전체 방안
- 암호화폐의 리드-래그 중재에 대한 소개 (1)
- 디지털 화폐의 리드-래그 스위트 소개 (1)
- FMZ 플랫폼의 외부 신호 수신에 대한 논의: 확장 API VS 전략 내장 HTTP 서비스
- FMZ 플랫폼 외부 신호 수신에 대한 탐구: 확장 API vs 전략 내장 HTTP 서비스
- 무작위 틱커 생성기에 기반한 전략 테스트 방법 논의
- 무작위 시장 생성기에 기반한 전략 테스트 방법을 탐구합니다.
- FMZ Quant의 새로운 기능: _Serve 기능을 사용하여 HTTP 서비스를 쉽게 만들 수 있습니다
- 양적 거래의 세 가지 잠재적 모델
- 중추점 내일 거래 시스템
- 디지털 화폐 양적 거래에 초보자를 위한 6 가지 간단한 전략과 방법
- 평균 실제 범위의 전략 틀
- FMZ 퀀트 플랫폼에서 온도계 전략의 실행 및 적용
- 상자 이론에 기반한 거래 전략, 상품 선물 및 디지털 화폐를 지원
- 상대적 힘 가격에 기반한 양적 거래 전략
- 거래량 가중된 인덱스를 이용한 양적 거래 전략
- FMZ 퀀트 트레이딩 플랫폼에서 PBX 거래 전략의 구현 및 적용
- 늦은 공유: 2014년 매일 5%의 수익을 내는 비트코인 고주파 로봇
- 신경망 및 디지털 통화 양적 거래 시리즈 (1) - LSTM 비트코인 가격을 예측합니다
- SMA와 RSI 상대 강도 지수의 조합 전략 적용
- CTA 전략의 개발과 FMZ 퀀트 플랫폼의 표준 클래스 라이브러리
- 파이썬에서 가격 모멘텀 분석과 함께 양적 거래 전략
- 파이썬에서 이중 추진 디지털 통화 양적 거래 전략을 구현합니다.
- 리눅스 도커를 설치하고 업그레이드하는 가장 좋은 방법
- 긴 짧은 포지션에 대한 균형 잡힌 주식 전략과 체계적인 조화를 달성
- 타임 시리즈 데이터 분석 및 틱 데이터 백테스팅
- 디지털 통화 시장의 정량 분석
- 데이터 기반 기술에 기반한 쌍 거래