Menghuraikan kelebihan dan kekurangan 3 kategori utama algoritma pembelajaran mesin
Penulis:Pencipta Kuantiti - Impian Kecil, Dicipta: 2017-10-30 12:01:59, Dikemas kini: 2017-11-08 13:55:03Menghuraikan kelebihan dan kekurangan 3 kategori utama algoritma pembelajaran mesin
Dalam pembelajaran mesin, matlamatnya adalah untuk meramalkan (prediction) atau mengelompokkan (clustering). Kajian ini memberi tumpuan kepada ramalan. Ramalan adalah proses untuk meramalkan nilai pembolehubah output dari satu set pembolehubah input. Sebagai contoh, dengan mendapatkan satu set ciri rumah yang berkaitan, kita boleh meramalkan harga jualannya. Dengan ini, mari kita lihat algoritma yang paling terkenal dan paling biasa digunakan dalam pembelajaran mesin. Kami telah membahagikan algoritma ini kepada tiga kategori: model linear, model berasaskan pokok, dan rangkaian saraf, dengan tumpuan kepada 6 algoritma yang paling biasa digunakan:
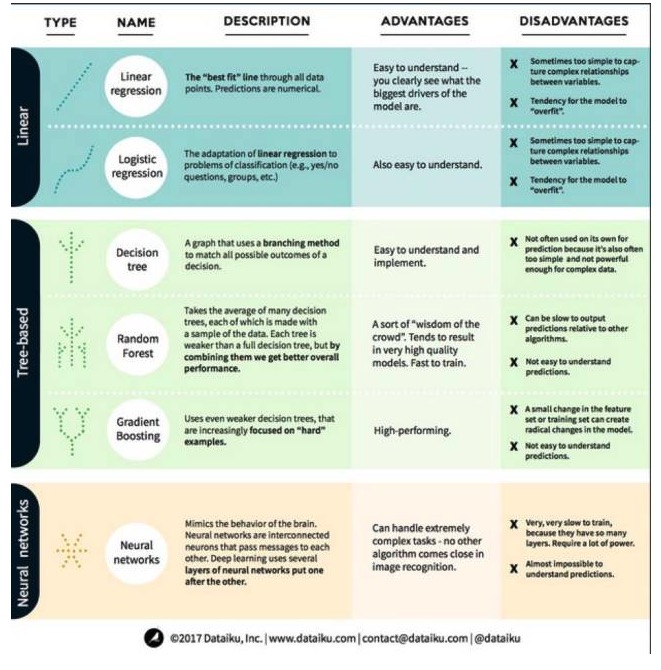
Satu, algoritma model linear: model linear menggunakan formula mudah untuk mencari baris yang paling sesuai dengan kerucut melalui satu set titik data. Kaedah ini bermula lebih dari 200 tahun yang lalu dan digunakan secara meluas dalam bidang statistik dan pembelajaran mesin. Oleh kerana kesederhanaannya, ia berguna untuk statistik. Variabel yang ingin anda ramalkan (sebab variabel) dinyatakan sebagai persamaan dari pembolehubah yang anda sudah tahu (sebab variabel), jadi ramalan hanya masalah memasukkan pembolehubah sendiri dan kemudian mengira jawapan untuk persamaan.
- #### 1. Regresi linear
Regresi linear, atau lebih tepatnya, regresi dua kali ganda terendah, adalah bentuk paling standard untuk model linear. Untuk masalah regresi, regresi linear adalah model linear yang paling mudah. Kelemahannya adalah model mudah disesuaikan, iaitu model sepenuhnya menyesuaikan diri dengan data yang telah dilatih, dengan mengorbankan keupayaan untuk menyebarkan ke data baru. Oleh itu, regresi linear dalam pembelajaran mesin (dan regresi logik yang akan kita bincangkan di bawah) biasanya adalah regresi linear, yang bermaksud bahawa model mempunyai hukuman tertentu untuk mencegah overfitting.
Kelemahan lain kepada model linear ialah kerana mereka sangat mudah, mereka tidak mudah meramalkan tingkah laku yang lebih kompleks apabila pembolehubah input tidak bebas.
- #### 2. Kembali logik
Regresi logik adalah penyesuaian regresi linear kepada masalah klasifikasi. Kelemahan regresi logik adalah sama dengan regresi linear. Fungsi logik sangat baik untuk masalah klasifikasi kerana ia memperkenalkan kesan ambang.
Kedua, algoritma model pokok
- ### ## 1, pokok keputusan
Pokok keputusan adalah gambaran setiap kemungkinan keputusan yang ditunjukkan menggunakan kaedah cabang. Sebagai contoh, anda memutuskan untuk memesan salad, keputusan pertama anda mungkin jenis lobak mentah, kemudian hidangan, dan kemudian jenis salad. Kita boleh menunjukkan semua kemungkinan keputusan dalam pokok keputusan.
Untuk melatih pokok keputusan, kita perlu menggunakan set data latihan dan mencari sifat yang paling berguna untuk sasaran. Sebagai contoh, dalam contoh penggunaan pengesanan penipuan, kita mungkin mendapati bahawa sifat yang paling berpengaruh terhadap ramalan risiko penipuan adalah negara. Setelah bercabang dengan sifat pertama, kita mendapat dua subset, yang merupakan ramalan yang paling tepat jika kita hanya tahu sifat pertama. Kemudian kita mencari sifat kedua yang terbaik yang boleh dibahagi kepada kedua subset ini, menggunakan pembahagian lagi, dan seterusnya sehingga cukup banyak sifat dapat memenuhi keperluan sasaran.
- ### ## 2 ## ## ## ## ## ## ### ### ### ### ### ### ### #### ####################################################################################################################################################################################################################
Hutan rawak adalah purata banyak pokok keputusan, di mana setiap pokok keputusan dilatih dengan sampel data rawak. Setiap pokok dalam hutan rawak lebih lemah daripada pokok keputusan yang lengkap, tetapi meletakkan semua pokok bersama, kita dapat memperoleh prestasi keseluruhan yang lebih baik kerana kelebihan kepelbagaian.
Hutan rawak adalah algoritma yang sangat popular dalam pembelajaran mesin hari ini. Hutan rawak mudah dilatih, dan menunjukkan prestasi yang agak baik. Kelemahannya adalah bahawa ramalan output hutan rawak mungkin lambat berbanding dengan algoritma lain, jadi mungkin tidak memilih hutan rawak apabila ramalan cepat diperlukan.
- #### 3, peningkatan ketinggian
Gradient Boosting, seperti hutan rawak, juga terdiri daripada pokok keputusan yang lemah. Perbezaan terbesar antara Gradient Boosting dan hutan rawak adalah bahawa dalam Gradient Boosting, pokok-pokok dilatih satu demi satu. Setiap pokok di belakang dilatih terutamanya oleh pokok di hadapan untuk mengenal pasti data yang salah.
Latihan untuk meningkatkan gradien juga cepat dan sangat baik. Walau bagaimanapun, perubahan kecil dalam set data latihan boleh menyebabkan perubahan mendasar pada model, jadi hasilnya mungkin tidak paling sesuai.
Algoritma rangkaian saraf: rangkaian saraf adalah fenomena biologi yang terdiri daripada neuron yang saling berkaitan dalam otak yang bertukar maklumat antara satu sama lain. Idea ini kini digunakan untuk bidang pembelajaran mesin, yang dikenali sebagai ANN. Pembelajaran mendalam adalah rangkaian saraf berlapis-lapis. ANN adalah satu set model yang memperoleh keupayaan kognitif yang serupa dengan otak manusia melalui pembelajaran.
Dibaharui dari Dataran Besar
- Adakah pencipta kuantitatif menyokong perdagangan mata wang kripto huobi dan OKEX dan perdagangan USDT?
- Memperkenalkan fungsi pembayaran yang disatukan ke dalam perpustakaan perdagangan mata wang digital
- Bagaimana anda boleh mengira jumlah maksimum wang yang boleh anda perolehi dari strategi yang diukur dengan data pulangan, turun naik, dan lain-lain?
- Shannon's Demon
- Yang rumit bukanlah teknologi, tetapi minda manusia! Kemahiran berdagang mestilah sesuai dengan sistem berdagang.
- Adakah anda mempunyai cadangan mengenai penempatan pelayan di Bitfinex?
- Bitfinex berjalan dengan salah, tolong analisis, terima kasih!
- Sila tanyakan pada titik masa mana data yang diambil semasa panggilan API diulang berdasarkan?
- Permintaan untuk kod Bitcoin.
- Mengapa hanya ada empat pasangan dagangan di bitfinex iaitu BCH_USD, BTC_USD, ETH_USD, dan LTC_USD?
- BUMN BUMN BUMN BUMN BUMN BUMN BUMN BUMN BUMN BUMN BUMN BUMN
- Peranti Pemantauan Akhir
- Bug yang dibuat: Tombol interaksi tanpa parameter lalai semasa membuat dasar gagal disimpan
- Bolehkah anda bertanya kepada saya, adakah sistem pengesanan tidak boleh memilih mata wang lain?
- Sila terjemahkan halaman rancangan beli
- Bitfinex mempunyai tiga pasaran, bagaimana untuk membuat bot memilih?
- Pilihan dalam perspektif dinamik menang bersama
- Bitfinex membetulkan dan mengesahkan unit mata wang yang berbeza
- Apa pendapat anda tentang keberkesanan penyangkalan dan garpu emas?
- Bithumb mendapat maklumat akaun yang salah