Mengkaji kaedah ujian strategi berdasarkan penjana pasaran rawak
Penulis:Pencipta Kuantiti - Impian Kecil, Dicipta pada: 2024-11-29 16:35:44, Dikemas kini pada: 2024-12-02 09:12:43[TOC]

Pengantar
Pembuat platform dagangan kuantitatif mempunyai sistem penyesuaian yang terus-menerus diperbaharui dan ditingkatkan, dari fungsi penyesuaian asas awal, untuk meningkatkan fungsi dan mengoptimumkan prestasi. Dengan perkembangan platform, sistem penyesuaian akan terus dioptimumkan, hari ini kita akan membincangkan topik berdasarkan sistem penyesuaian: "Pengujian strategi berdasarkan pasaran rawak".
Keperluan
Dalam bidang perdagangan kuantitatif, pengembangan strategi dan pengesanan optimasi tidak dapat dipisahkan dari data pasaran sebenar. Walau bagaimanapun, dalam aplikasi praktikal, kerana persekitaran pasaran yang kompleks dan berubah-ubah, mungkin terdapat kekurangan untuk mengulang semula berdasarkan data sejarah, seperti kekurangan liputan untuk pasaran yang melampau atau senario khas. Oleh itu, reka bentuk penjana pasaran rawak yang cekap menjadi alat yang berkesan untuk pemaju strategi kuantitatif.
Apabila kita memerlukan strategi untuk mengulangi data sejarah di bursa atau mata wang tertentu, kita boleh menggunakan sumber data rasmi di platform FMZ untuk menguji semula. Kadang-kadang kita juga ingin melihat bagaimana strategi itu berfungsi jika di pasaran yang sama sekali tidak dikenali, ketika ini kita boleh membuat beberapa data untuk menguji strategi.
Penggunaan data pasaran rawak bermaksud:
-
- Mengkaji kehebatan strategi Penjana pasaran rawak boleh mencipta pelbagai senario pasaran yang mungkin berlaku, termasuk pasaran yang sangat berfluktuasi, rendah berfluktuasi, pasaran trend, dan pasaran yang bergolak. Menguji strategi dalam persekitaran analog ini dapat membantu menilai sama ada ia akan stabil dalam keadaan pasaran yang berbeza. Contohnya:
Adakah strategi boleh menyesuaikan diri dengan trend dan perubahan kejatuhan? Adakah strategi akan menyebabkan kerugian besar dalam pasaran yang melampau?
-
- Mengenali kelemahan strategi yang berpotensi Dengan mensimulasikan beberapa keadaan pasaran yang luar biasa (seperti peristiwa Black Swan yang diandaikan), kelemahan berpotensi strategi dapat dijumpai dan diperbaiki; contohnya:
Adakah strategi akan terlalu bergantung kepada struktur pasaran? Adakah terdapat risiko parameter terlalu sesuai?
-
- Mengoptimumkan parameter strategi Data yang dihasilkan secara rawak menyediakan persekitaran ujian yang lebih pelbagai untuk penyesuaian parameter strategi, yang tidak perlu bergantung sepenuhnya pada data sejarah. Ini membolehkan untuk mencari jangkauan parameter strategi yang lebih menyeluruh, mengelakkan daripada terhad kepada model pasaran tertentu dalam data sejarah.
-
- Tidak mencukupi untuk mengisi data sejarah Dalam beberapa pasaran (seperti pasaran baru muncul atau pasaran dagangan mata wang kecil), data sejarah mungkin tidak mencukupi untuk merangkumi semua keadaan pasaran yang mungkin. Penjana pasaran rawak boleh menyediakan banyak data tambahan untuk membantu ujian yang lebih menyeluruh.
-
- Pembangunan Iterasi Cepat Dengan menggunakan data rawak untuk ujian cepat, ia dapat mempercepatkan kadar iterasi pembangunan strategi tanpa bergantung pada pasaran masa nyata atau pembersihan dan penyusunan data yang memakan masa.
Tetapi ia juga memerlukan strategi penilaian yang rasional, dan untuk data pasaran yang dihasilkan secara rawak, perhatikan:
- 1. Walaupun penjana pasaran rawak berguna, pentingnya bergantung kepada kualiti data yang dihasilkan dan reka bentuk senario sasaran:
- 2. Logik penjanaan perlu mendekati pasaran sebenar: jika pasaran yang dijana secara rawak benar-benar lepas dari realiti, keputusan ujian mungkin tidak mempunyai nilai rujukan. Sebagai contoh, penjana boleh digabungkan dengan ciri statistik pasaran sebenar (seperti pembahagian kadar turun naik, peratusan trend) untuk merancang penjana.
- 3. Tidak boleh menggantikan sepenuhnya ujian data sebenar: data rawak hanya dapat melengkapi pembangunan dan pengoptimuman strategi, dan strategi akhir masih perlu disahkan berkesan dalam data pasaran sebenar.
Oleh itu, bagaimana kita boleh membuat data yang mudah, cepat dan mudah digunakan untuk membuat data yang mudah digunakan oleh sistem pengukuran semula?
Idea Reka Bentuk
Artikel ini direka untuk memberikan perhitungan penjanaan acak yang lebih mudah, tetapi terdapat pelbagai teknik analog, seperti algoritma dan model data yang boleh digunakan, kerana perbincangan ini terhad.
Kami menulis satu program dalam bahasa Python yang menggunakan fungsi sumber data tersuai dengan sistem penyesuaian platform.
- 1, secara rawak menjana satu set data K-line yang ditulis ke dalam rekod persistensi fail CSV, supaya data yang dihasilkan dapat disimpan sebagai rekod.
- 2. Kemudian, buat perkhidmatan untuk menyokong sumber data untuk sistem pengesanan semula.
- 3. Mempunyai data K-line yang dihasilkan dalam grafik.
Untuk beberapa standard penjanaan data K-line, penyimpanan fail, dan lain-lain, kawalan parameter berikut boleh ditakrifkan:
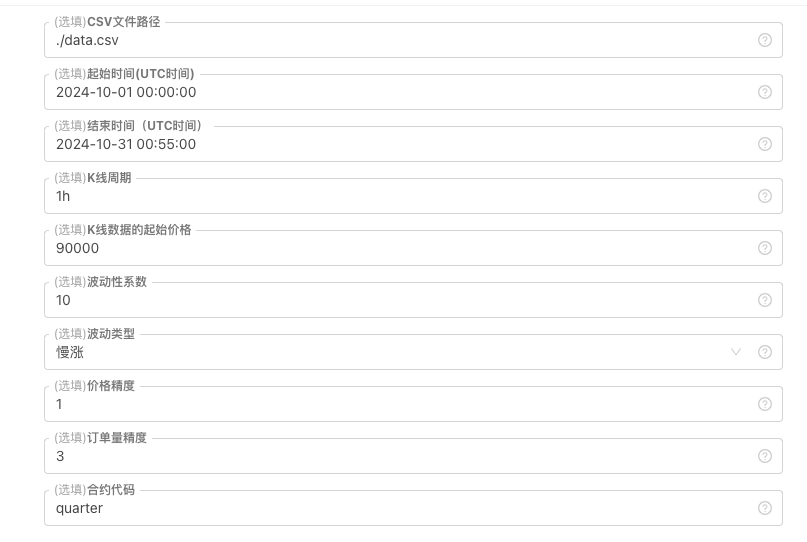
-
Bentuk penjanaan data secara rawak Untuk jenis turun naik data analog K-line, hanya menggunakan nombor rawak yang mudah digunakan untuk membuat reka bentuk yang mudah yang berbeza dengan kebarangkalian positif negatif, yang mungkin tidak mencerminkan corak yang diperlukan apabila data yang dihasilkan tidak banyak. Jika ada kaedah yang lebih baik, bahagian kod ini boleh digantikan. Berdasarkan reka bentuk yang mudah ini, penyesuaian dalam jumlah bilangan rawak dalam kod dan beberapa faktor boleh mempengaruhi kesan data yang dihasilkan.
-
Periksa data Untuk data K-line yang dihasilkan juga memerlukan pemeriksaan kelayakan, memeriksa sama ada harga tinggi atau rendah melanggar definisi, memeriksa kesinambungan data K-line, dan lain-lain.
Penjana Pergerakan Rawak Sistem Pemindaian
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Praktik dalam sistem pengesanan semula
1. Buat contoh dasar di atas, sesuaikan parameter, dan jalankan. 2, cakera sebenar (contoh dasar) perlu dijalankan pada hoster yang digunakan pada pelayan, kerana ia memerlukan IP rangkaian awam yang boleh diakses oleh sistem pengesanan semula untuk mendapatkan data. 3. Klik butang interaksi, dan strategi akan secara automatik memulakan penjanaan data pasaran rawak.

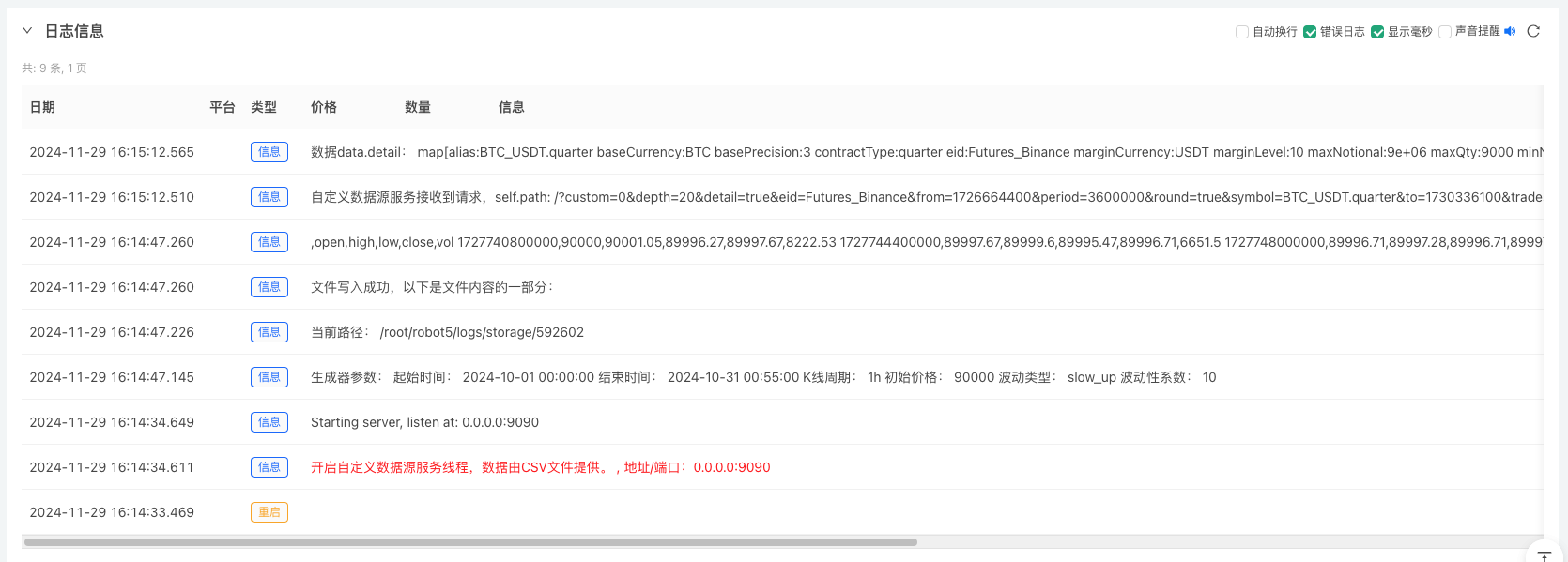
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
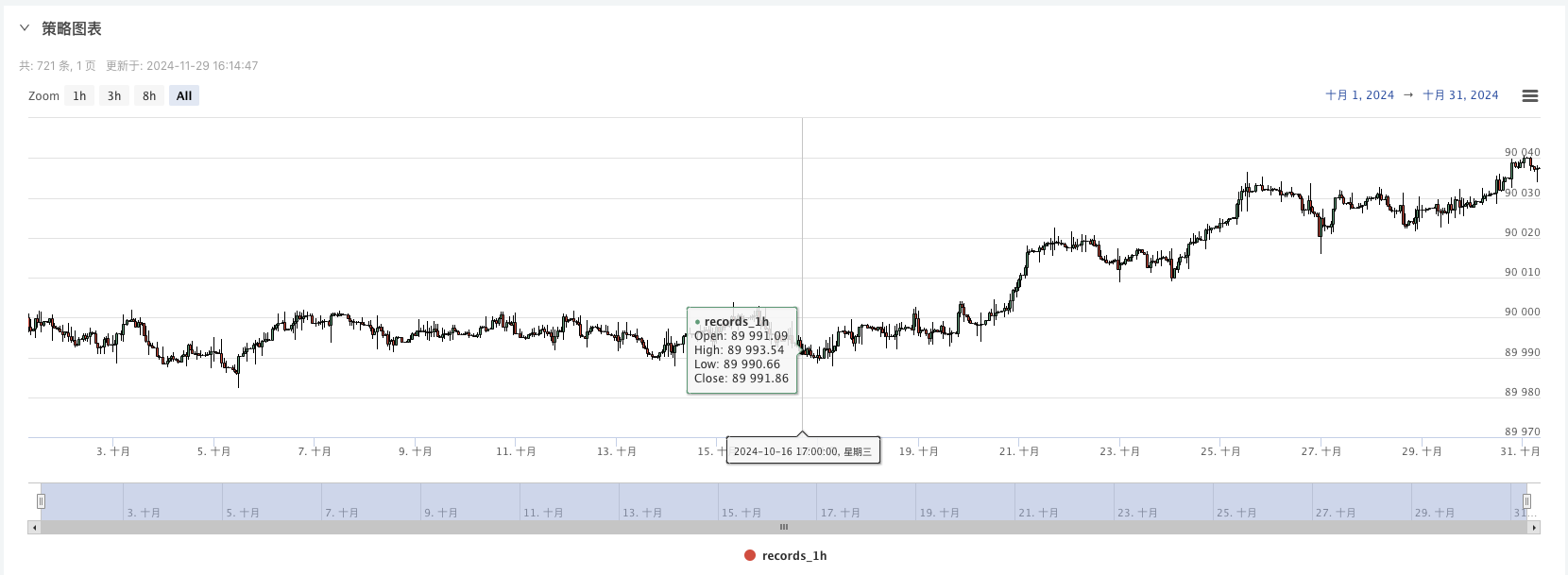
Jadi kita boleh menggunakan data yang dihasilkan secara rawak ini untuk mengulang semula dengan menggunakan satu strategi.
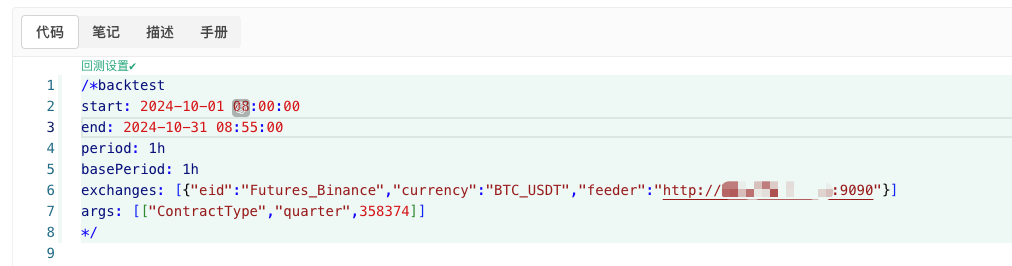
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Di bawah ini adalah beberapa maklumat yang boleh digunakan untuk membuat penyesuaian.http://xxx.xxx.xxx.xxx:9090Ia adalah alamat IP pelayan dan port yang dibuka pada cakera nyata yang secara rawak menghasilkan dasar.
Ini adalah sumber data tersuai, dan anda boleh mencari bahagian sumber data tersuai dalam dokumentasi API platform.
6. Sistem pengesanan semula dengan sumber data yang baik boleh menguji data pasaran rawak.
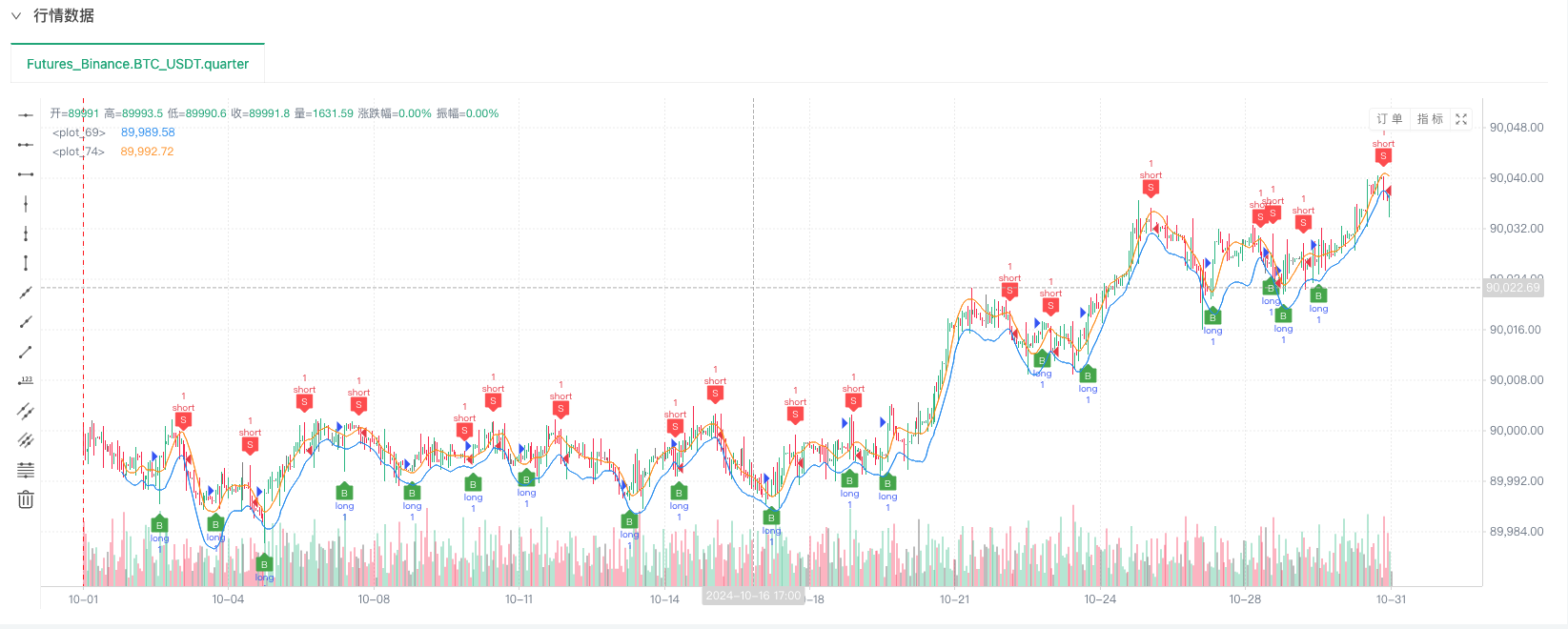
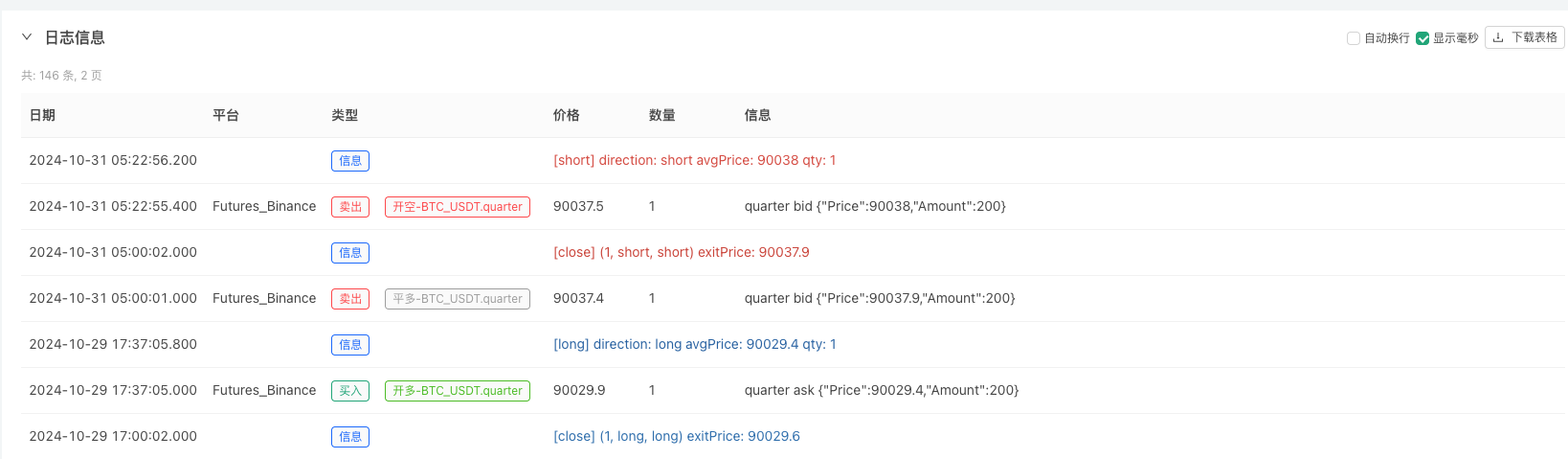
Pada masa ini, sistem pengesanan semula adalah untuk menguji data analog yang dibuat oleh kami. Berdasarkan data dalam carta pasaran pada masa pengesanan semula, berbanding data dalam carta pasaran yang dihasilkan secara rawak, masa: 16 Oktober 2024 pukul 17.00, data adalah sama.
7. Oh ya, hampir lupa! Program python ini untuk penjana keadaan rawak mencipta cakera maya untuk memudahkan demonstrasi, pengendalian, memaparkan data K-line yang dihasilkan.
Kod sumber strategi:Penjana Pergerakan Rawak Sistem Pemindaian
Terima kasih atas sokongan dan bacaan anda.
- Pengenalan suite Lead-Lag dalam mata wang digital (3)
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (2)
- Pendahuluan mengenai Lead-Lag dalam mata wang digital (2)
- Perbincangan mengenai Penerimaan Isyarat Luaran Platform FMZ: Penyelesaian Lengkap untuk Menerima Isyarat dengan Perkhidmatan Http Terbina dalam Strategi
- Penyelidikan penerimaan isyarat luaran platform FMZ: strategi penyelesaian lengkap untuk penerimaan isyarat perkhidmatan HTTP terbina dalam
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (1)
- Perkenalkan led-lag suite dalam mata wang digital ((1)
- Perbincangan mengenai penerimaan isyarat luaran Platform FMZ: API Terpanjang VS Strategi Perkhidmatan HTTP Terbina dalam
- Penyelidikan penerimaan isyarat luaran platform FMZ: API yang diperluaskan vs strategi perkhidmatan HTTP terbina dalam
- Perbincangan mengenai Kaedah Ujian Strategi Berdasarkan Random Ticker Generator
- Ciri baru FMZ Quant: Gunakan fungsi _Serve untuk membuat perkhidmatan HTTP dengan mudah
- Pencipta mengutip ciri baru: mudah membuat perkhidmatan HTTP menggunakan fungsi _Serve
- FMZ Quant Trading Platform Panduan Akses Protokol Sesuai
- Strategi Pemerolehan dan Pemantauan Kadar Pembiayaan FMZ
- FMZ Rate Pengambilan dan Pemantauan Strategi
- Templat Strategi membolehkan anda menggunakan WebSocket Market dengan lancar
- Satu templat dasar yang membolehkan anda menggunakan sektor WebSocket dengan lancar
- Pencipta Panduan Akses Platform Perdagangan Kuantitatif
- Cara Membina Strategi Dagangan Multi-Mata Wang Universal dengan Cepat Selepas Peningkatan FMZ
- Bagaimana untuk membina strategi perdagangan multi-mata wang yang universal dengan cepat selepas peningkatan FMZ