Penggunaan Teknologi Pembelajaran Mesin dalam Perdagangan
Penulis:FMZ~Lydia, Dicipta: 2022-12-30 10:53:07, Dikemas kini: 2023-09-20 09:30:09
Penggunaan Teknologi Pembelajaran Mesin dalam Perdagangan
Inspirasi untuk artikel ini datang daripada pemerhatian saya tentang beberapa amaran dan perangkap biasa selepas cuba menggunakan teknologi pembelajaran mesin untuk masalah transaksi semasa penyelidikan data di platform FMZ Quant.
Jika anda belum membaca artikel saya sebelumnya, kami mencadangkan anda membaca panduan persekitaran penyelidikan data automatik dan kaedah sistematik untuk merumuskan strategi perdagangan yang saya tetapkan di platform FMZ Quant sebelum artikel ini.
Alamat dua artikel ini adalah di sini:https://www.fmz.com/digest-topic/9862danhttps://www.fmz.com/digest-topic/9863.
Mengenai penubuhan persekitaran penyelidikan
Tutorial ini ditujukan untuk peminat, jurutera dan saintis data pada semua tahap kemahiran. Sama ada anda seorang pemimpin industri atau pemula pengaturcaraan, satu-satunya kemahiran yang anda perlukan adalah pemahaman asas bahasa pengaturcaraan Python dan pengetahuan yang mencukupi mengenai operasi baris arahan (mampu menubuhkan projek sains data sudah cukup).
- Memasang FMZ Quant docker dan menyediakan Anaconda
Platform FMZ QuantFMZ.COMbukan sahaja menyediakan sumber data berkualiti tinggi untuk pertukaran arus perdana utama, tetapi juga menyediakan satu set antara muka API yang kaya untuk membantu kami menjalankan transaksi automatik selepas menyelesaikan analisis data. Set antara muka ini termasuk alat praktikal, seperti menanyakan maklumat akaun, menanyakan harga yang tinggi, terbuka, rendah, penerimaan, jumlah dagangan, dan pelbagai penunjuk analisis teknikal yang biasa digunakan dari pelbagai pertukaran arus perdana. Khususnya, ia menyediakan sokongan teknikal yang kuat untuk antara muka API awam yang menghubungkan pertukaran arus perdana utama dalam proses dagangan sebenar.
Semua ciri yang disebutkan di atas dikemas dalam sistem seperti Docker. Apa yang perlu kita lakukan adalah membeli atau menyewa perkhidmatan pengkomputeran awan kita sendiri dan menggunakan sistem Docker.
Dalam nama rasmi platform FMZ Quant, sistem Docker dipanggil sistem Docker.
Sila rujuk artikel saya sebelum ini mengenai cara menggunakan docker dan robot:https://www.fmz.com/bbs-topic/9864.
Pembaca yang ingin membeli pelayan pengkomputeran awan mereka sendiri untuk menggunakan pelabuhan boleh merujuk artikel ini:https://www.fmz.com/digest-topic/5711.
Selepas menyebarkan pelayan pengkomputeran awan dan sistem docker dengan berjaya, seterusnya kita akan memasang artifak terbesar sekarang Python: Anaconda
Untuk merealisasikan semua persekitaran program yang relevan (bibliotek ketergantungan, pengurusan versi, dan lain-lain) yang diperlukan dalam artikel ini, cara yang paling mudah adalah menggunakan Anaconda.
Oleh kerana kami memasang Anaconda pada perkhidmatan awan, kami mengesyorkan bahawa pelayan awan memasang sistem Linux ditambah versi baris arahan Anaconda.
Untuk kaedah pemasangan Anaconda, sila rujuk panduan rasmi Anaconda:https://www.anaconda.com/distribution/.
Jika anda seorang pengaturcara Python yang berpengalaman dan jika anda merasakan bahawa anda tidak perlu menggunakan Anaconda, ia tidak ada masalah sama sekali. Saya akan menganggap bahawa anda tidak memerlukan bantuan semasa memasang persekitaran bergantung yang diperlukan. Anda boleh melangkau bahagian ini secara langsung.
Membangunkan strategi perdagangan
Hasil akhir strategi perdagangan harus menjawab soalan-soalan berikut:
-
Arahan: Tentukan sama ada aset itu murah, mahal atau nilai wajar.
-
Syarat pembukaan kedudukan: Jika aset itu murah atau mahal, anda harus pergi panjang atau pergi pendek.
-
Perdagangan kedudukan penutupan: jika aset mempunyai harga yang munasabah dan kita mempunyai kedudukan dalam aset (beli atau jual sebelumnya), adakah anda harus menutup kedudukan?
-
Julat harga: harga (atau julat) di mana kedudukan dibuka.
-
Jumlah: kuantiti wang yang didagangkan (contohnya, jumlah mata wang digital atau jumlah lot niaga hadapan komoditi).
Pembelajaran mesin boleh digunakan untuk menjawab setiap soalan ini, tetapi untuk selebihnya artikel ini, kita akan memberi tumpuan kepada soalan pertama, iaitu arah perdagangan.
Pendekatan strategik
Terdapat dua jenis pendekatan untuk membina strategi: satu adalah berdasarkan model; yang lain adalah berdasarkan perlombongan data.
Dalam pembinaan strategi berasaskan model, kita bermula dari model ketidakcekapan pasaran, membina ungkapan matematik (seperti harga dan keuntungan) dan menguji keberkesanannya dalam jangka masa yang lama. Model ini biasanya merupakan versi yang dipermudahkan dari model kompleks sebenar, dan kepentingan jangka panjang dan kestabilan perlu disahkan.
Sebaliknya, kita mencari corak harga terlebih dahulu dan cuba menggunakan algoritma dalam kaedah perlombongan data. Alasan corak ini tidak penting, kerana hanya corak yang dikenal pasti akan terus berulang pada masa akan datang. Ini adalah kaedah analisis buta, dan kita perlu memeriksa dengan ketat untuk mengenal pasti corak sebenar dari corak rawak.
Jelas, pembelajaran mesin sangat mudah digunakan untuk kaedah perlombongan data. mari kita lihat bagaimana menggunakan pembelajaran mesin untuk membuat isyarat transaksi melalui perlombongan data.
Contoh kod menggunakan alat backtesting berdasarkan platform FMZ Quant dan antara muka API transaksi automatik. Selepas menggunakan docker dan memasang Anaconda dalam bahagian di atas, anda hanya perlu memasang perpustakaan analisis sains data yang kita perlukan dan model pembelajaran mesin terkenal scikit-learn. Kami tidak akan pergi ke bahagian ini lagi.
pip install -U scikit-learn
Gunakan pembelajaran mesin untuk membuat isyarat strategi perdagangan
- Data perlombongan Sebelum kita mula, sistem masalah pembelajaran mesin standard ditunjukkan dalam gambar berikut:
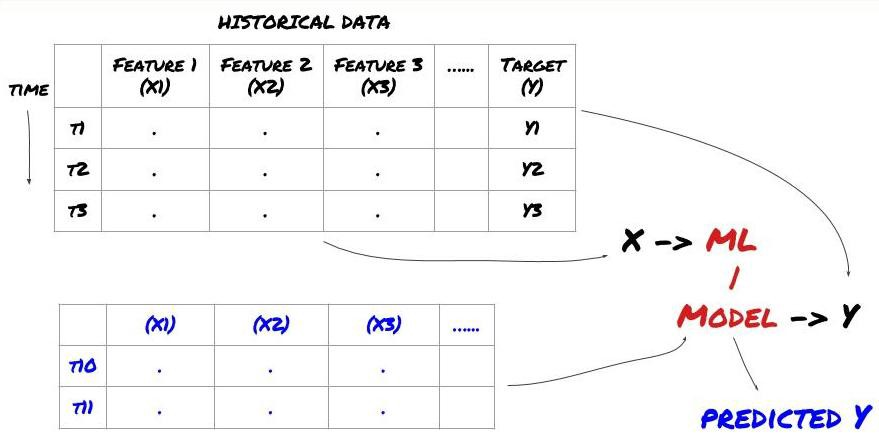
Sistem masalah pembelajaran mesin
Fitur yang akan kita cipta mesti mempunyai kemampuan ramalan (X). Kita mahu meramalkan pembolehubah sasaran (Y) dan menggunakan data sejarah untuk melatih model ML yang dapat meramalkan Y sedekat mungkin dengan nilai sebenar. Akhirnya, kita menggunakan model ini untuk membuat ramalan pada data baru di mana Y tidak diketahui. Ini membawa kita ke langkah pertama:
Langkah 1: Sediakan soalan anda
- Apa yang anda mahu meramalkan? Apakah ramalan yang baik? Bagaimana anda menilai hasil ramalan?
Maksudnya, dalam rangka kerja di atas, apa Y?
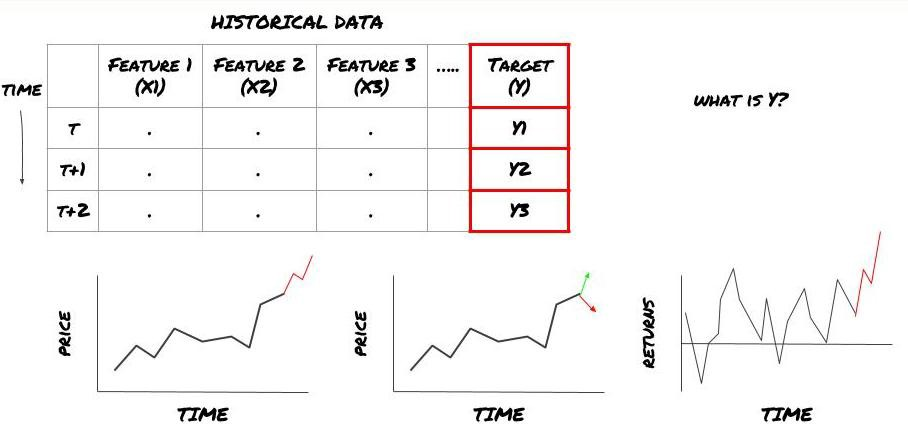
Apa yang anda mahu meramalkan?
Adakah anda ingin meramalkan harga masa depan, pulangan masa depan / Pnl, isyarat beli / jual, mengoptimumkan peruntukan portfolio dan cuba melaksanakan transaksi dengan cekap?
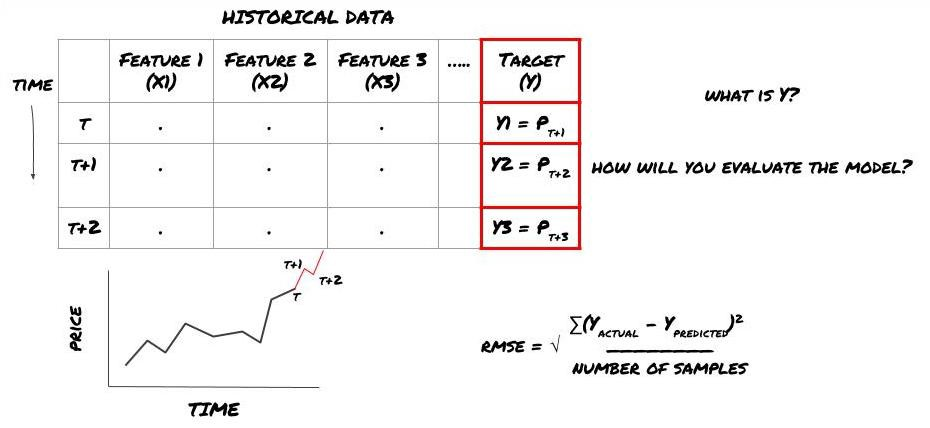
Katakan kita cuba meramalkan harga pada stempel masa seterusnya. dalam kes ini, Y (t) = harga (t + 1). sekarang kita boleh menggunakan data sejarah untuk melengkapkan rangka kerja kita.
Perhatikan bahawa Y (t) hanya diketahui dalam backtest, tetapi apabila kita menggunakan model kita, kita tidak akan tahu harga (t + 1) masa t. Kita menggunakan model kita untuk meramalkan Y (diprediksi, t) dan membandingkannya dengan nilai sebenar hanya pada masa t + 1. Ini bermakna bahawa anda tidak boleh menggunakan Y sebagai ciri dalam model ramalan.
Apabila kita tahu sasaran Y, kita juga boleh memutuskan bagaimana untuk menilai ramalan kita. Ini adalah penting untuk membezakan antara model yang berbeza data yang akan kita cuba. Pilih satu penunjuk untuk mengukur kecekapan model kita mengikut masalah yang kita selesaikan. Sebagai contoh, jika kita meramalkan harga, kita boleh menggunakan root mean square error sebagai penunjuk. Beberapa penunjuk yang biasa digunakan (EMA, MACD, skor varians, dan lain-lain) telah pra dikodkan dalam kotak alat FMZ Quant. Anda boleh memanggil penunjuk ini secara global melalui antara muka API.
Rangka kerja ML untuk meramalkan harga masa depan
Untuk tujuan demonstrasi, kami akan membuat model ramalan untuk meramalkan nilai penanda aras (basis) masa depan yang dijangkakan bagi objek pelaburan hipotetik, di mana:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Oleh kerana ini adalah masalah regresi, kita akan menilai model pada RMSE (kesalahan kuadrat akar rata-rata).
Nota: Sila rujuk Ensiklopedia Baidu untuk pengetahuan matematik yang berkaitan dengan RMSE.
- Matlamat kami: untuk mencipta model untuk membuat nilai yang diramalkan sedekat mungkin dengan Y.
Langkah 2: Kumpulkan data yang boleh dipercayai
Kumpulkan dan jelaskan data yang boleh membantu anda menyelesaikan masalah di tangan.
Data apa yang perlu anda pertimbangkan yang boleh meramalkan pembolehubah sasaran Y? Jika kita meramalkan harga, anda boleh menggunakan data harga objek pelaburan, data kuantiti perdagangan objek pelaburan, data serupa objek pelaburan yang berkaitan, tahap indeks objek pelaburan dan penunjuk pasaran keseluruhan yang lain, dan harga aset lain yang berkaitan.
Anda perlu menetapkan kebenaran akses data untuk data ini dan memastikan bahawa data anda adalah tepat, dan menyelesaikan data yang hilang (masalah yang sangat biasa). Pada masa yang sama, pastikan bahawa data anda tidak memihak dan mewakili sepenuhnya semua keadaan pasaran (contohnya, jumlah senario keuntungan dan kerugian yang sama) untuk mengelakkan bias dalam model.
Jika anda menggunakan platform FMZ Quant (FMZ. COM), kita boleh mengakses data global percuma dari Google, Yahoo, NSE dan Quandl; Data kedalaman niaga hadapan komoditi domestik seperti CTP dan Esunny; Data dari bursa mata wang digital arus perdana seperti Binance, OKX, Huobi dan BitMex. Platform FMZ Quant juga membersihkan dan menapis data ini, seperti pembahagian sasaran pelaburan dan data pasaran yang mendalam, dan membentangkannya kepada pemaju strategi dalam format yang mudah difahami oleh pengamal kuantitatif.
Untuk memudahkan demonstrasi artikel ini, kami menggunakan data berikut sebagai
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Dengan kod di atas, Auquan
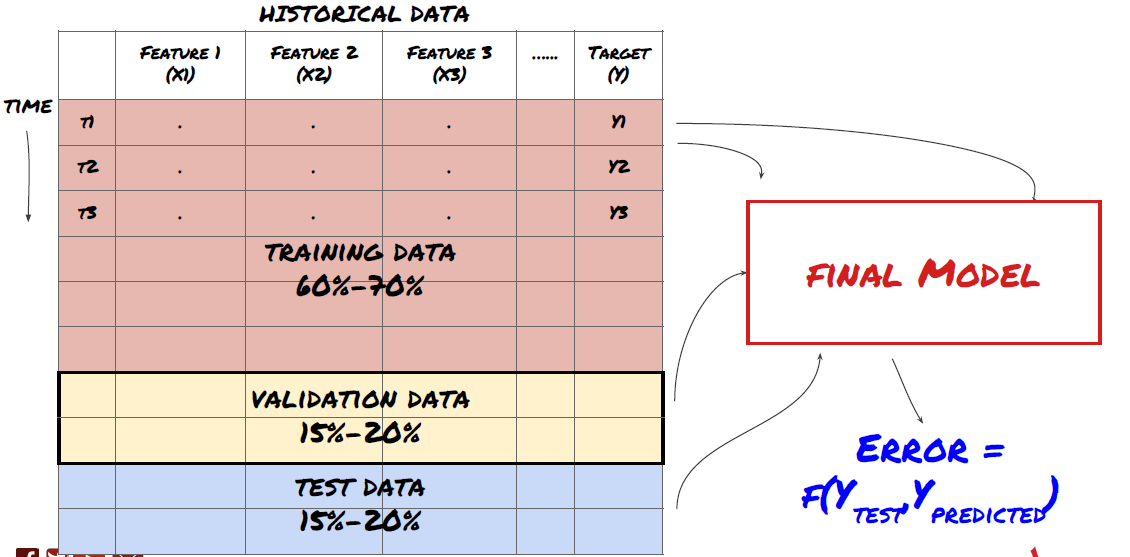
Langkah 3: Pembagian data
- Buat set latihan, salib pengesahan dan menguji set data ini dari data.
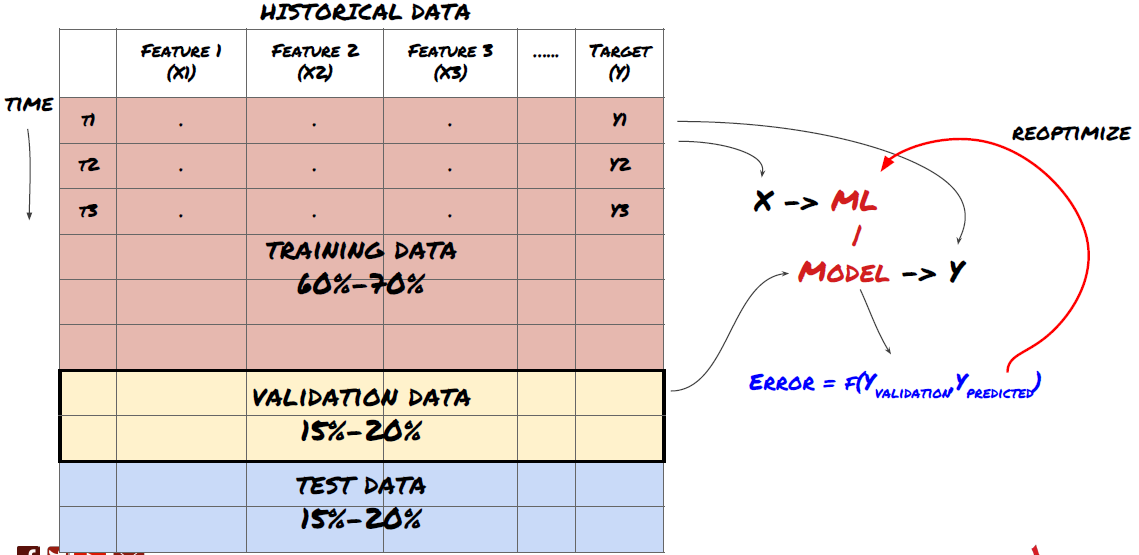
Ini adalah langkah yang sangat penting!Sebelum kita meneruskan, kita harus membahagikan data ke dalam set data latihan untuk melatih model anda; set data ujian untuk menilai prestasi model.
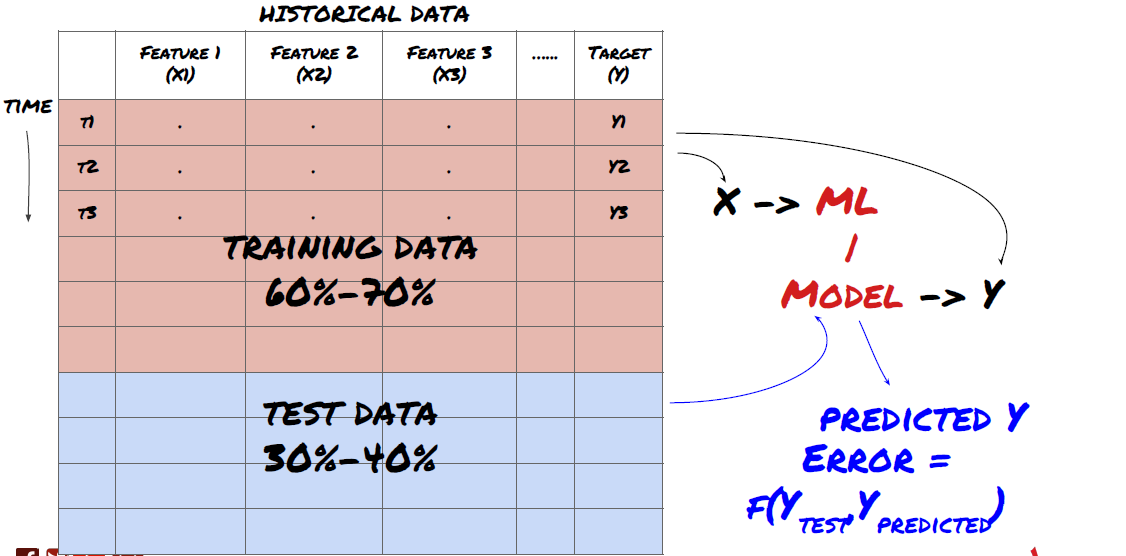
Pembagian data ke dalam set latihan dan set ujian
Oleh kerana data latihan digunakan untuk menilai parameter model, model anda mungkin terlalu sesuai dengan data latihan ini, dan data latihan mungkin menyesatkan prestasi model. Jika anda tidak menyimpan data ujian individu dan menggunakan semua data untuk latihan, anda tidak akan tahu seberapa baik atau buruk model anda melakukan pada data yang tidak kelihatan baru. Ini adalah salah satu sebab utama kegagalan model ML yang dilatih dalam data masa nyata: orang melatih semua data yang ada dan teruja dengan penunjuk data latihan, tetapi model tidak dapat membuat ramalan yang bermakna pada data masa nyata yang tidak dilatih.
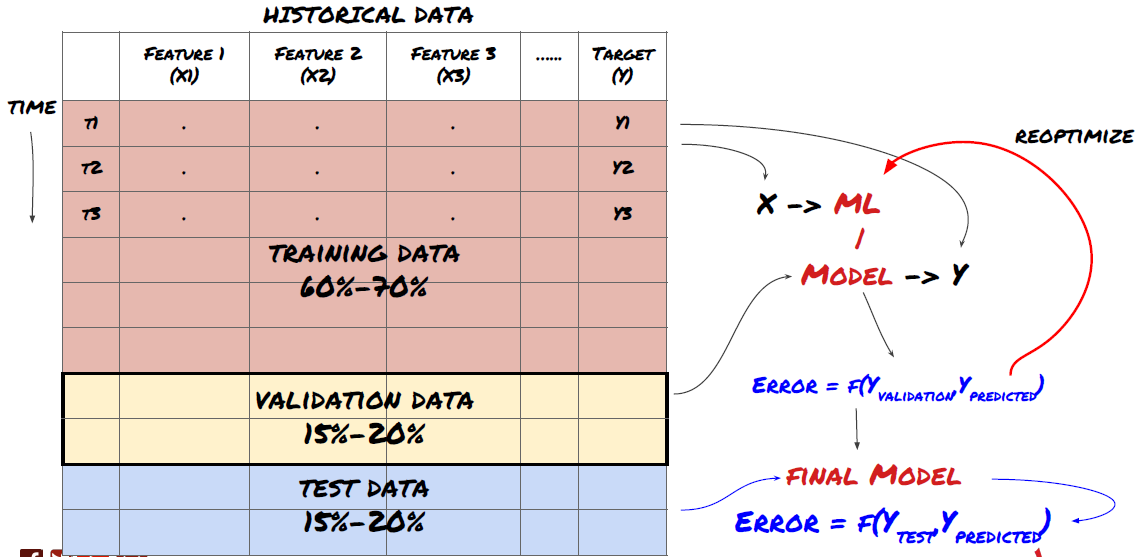
Pembagian data ke dalam set latihan, set pengesahan dan set ujian
Terdapat masalah dengan kaedah ini. Jika kita melatih data latihan berulang kali, menilai prestasi data ujian dan mengoptimumkan model kita sehingga kita berpuas hati dengan prestasi, kita mengambil data ujian sebagai sebahagian daripada data latihan secara tersirat. Pada akhirnya, model kita mungkin berfungsi dengan baik pada set data latihan dan ujian ini, tetapi ia tidak dapat menjamin bahawa ia dapat meramalkan data baru dengan baik.
Untuk menyelesaikan masalah ini, kita boleh membuat satu set data pengesahan yang berasingan. Sekarang, anda boleh melatih data, menilai prestasi data pengesahan, mengoptimumkan sehingga anda berpuas hati dengan prestasi, dan akhirnya menguji data ujian. Dengan cara ini, data ujian tidak akan tercemar, dan kita tidak akan menggunakan apa-apa maklumat dalam data ujian untuk meningkatkan model kita.
Ingat, setelah anda memeriksa prestasi data ujian anda, jangan kembali dan cuba mengoptimumkan model anda lebih lanjut. Jika anda mendapati bahawa model anda tidak memberikan hasil yang baik, membuang model sepenuhnya dan mulakan semula. Disarankan bahawa 60% data latihan, 20% data pengesahan dan 20% data ujian boleh dibahagikan.
Untuk soalan kami, kami mempunyai tiga set data yang tersedia. kami akan menggunakan satu sebagai set latihan, yang kedua sebagai set pengesahan, dan yang ketiga sebagai set ujian kami.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Untuk setiap daripada ini, kita menambah pembolehubah sasaran Y, yang ditakrifkan sebagai purata lima nilai asas seterusnya.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Langkah 4: Kejuruteraan Ciri
Menganalisis tingkah laku data dan mencipta ciri ramalan
Sekarang pembinaan projek sebenar telah bermula. Peraturan emas pemilihan ciri adalah bahawa keupayaan ramalan terutamanya berasal dari ciri, bukan dari model. Anda akan mendapati bahawa pemilihan ciri mempunyai kesan yang jauh lebih besar terhadap prestasi daripada pemilihan model. Beberapa pertimbangan untuk pemilihan ciri:
-
Jangan memilih satu set besar ciri secara rawak tanpa meneroka hubungan dengan pembolehubah sasaran.
-
Sedikit atau tidak ada hubungan dengan pembolehubah sasaran boleh membawa kepada overfit.
-
Ciri-ciri yang anda pilih mungkin sangat berkaitan antara satu sama lain, dalam hal ini sebilangan kecil ciri juga boleh menjelaskan sasaran.
-
Saya biasanya membuat beberapa ciri intuitif, memeriksa hubungan antara pembolehubah sasaran dan ciri-ciri ini, dan hubungan antara mereka untuk memutuskan mana yang akan digunakan.
-
Anda juga boleh cuba melakukan analisis komponen utama (PCA) dan kaedah lain untuk menyusun ciri calon mengikut pekali maklumat maksimum (MIC).
Transformasi ciri/normalisasi:
Model ML cenderung berfungsi dengan baik dari segi normalisasi. Walau bagaimanapun, normalisasi sukar apabila berurusan dengan data siri masa, kerana julat data masa depan tidak diketahui. Data anda mungkin berada di luar julat normalisasi, yang membawa kepada ralat model. Tetapi anda masih boleh cuba memaksa beberapa tahap kestabilan:
-
Pengukuran: membahagikan ciri-ciri dengan penyimpangan standard atau julat kuartil.
-
Pusatkan: tolak nilai purata sejarah dari nilai semasa.
-
Normalisasi: dua tempoh retrospektif di atas (x - purata) / stdev.
-
Normalisasi tetap: standardkan data ke dalam julat - 1 hingga +1 dan tentukan semula pusat dalam tempoh mundur (x-min) / ((max min).
Perhatikan bahawa kerana kita menggunakan nilai purata berterusan bersejarah, penyimpangan piawai, nilai maksimum atau minimum di luar tempoh tindak balik, nilai standardisasi normalized ciri akan mewakili nilai sebenar yang berbeza pada masa yang berlainan. Sebagai contoh, jika nilai semasa ciri adalah 5 dan nilai purata untuk 30 tempoh berturut-turut adalah 4.5, ia akan ditukar kepada 0.5 selepas pusat. Selepas itu, jika nilai purata 30 tempoh berturut-turut menjadi 3, nilai 3.5 akan menjadi 0.5. Ini mungkin penyebab model yang salah. Oleh itu, normalisasi rumit, dan anda mesti memikirkan apa yang meningkatkan prestasi model (jika benar-benar ada).
Untuk pengulangan pertama dalam masalah kami, kami mencipta sebilangan besar ciri dengan menggunakan parameter campuran. kemudian kita akan cuba untuk melihat jika kita boleh mengurangkan bilangan ciri.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Langkah 5: Pilihan Model
Pilih model statistik/ML yang sesuai mengikut soalan yang dipilih
Pemilihan model bergantung kepada bagaimana masalah terbentuk. Adakah anda menyelesaikan pengawasan (setiap titik X dalam matriks ciri dipetakan ke pembolehubah sasaran Y) atau pembelajaran tanpa pengawasan (tanpa pemetaan tertentu, model cuba mempelajari corak yang tidak diketahui)? Adakah anda berurusan dengan regresi (memprediksi harga sebenar dalam masa akan datang) atau pengelasan (hanya meramalkan arah harga dalam masa akan datang (peningkatan / penurunan))?

Pembelajaran yang dipantau atau tidak dipantau

Kemunduran atau klasifikasi
Beberapa algoritma pembelajaran pengawasan biasa boleh membantu anda memulakan:
-
Regresi linear (parameter, regresi)
-
Regresi logistik (parameter, klasifikasi)
-
Algoritma K-Nearest Neighbor (KNN) (berasaskan kes, regresi)
-
SVM, SVR (parameter, klasifikasi dan regresi)
-
Pokok keputusan
-
Hutan keputusan
Saya cadangkan bermula dengan model yang mudah, seperti regresi linear atau logistik, dan membina model yang lebih kompleks dari sana seperti yang diperlukan.
Langkah 6: Latihan, pengesahan dan pengoptimuman (ulang langkah 4-6)
Gunakan latihan dan set data pengesahan untuk melatih dan mengoptimumkan model anda
Sekarang anda sudah bersedia untuk akhirnya membina model. Pada peringkat ini, anda benar-benar hanya mengulangi model dan parameter model. Latih model anda pada data latihan, mengukur prestasi pada data pengesahan, dan kemudian kembali, mengoptimumkan, melatih semula dan menilai. Jika anda tidak berpuas hati dengan prestasi model, sila cuba model lain. Anda berputar melalui fasa ini berkali-kali sehingga akhirnya anda mempunyai model yang anda berpuas hati.
Hanya apabila anda mempunyai model kegemaran anda, kemudian beralih ke langkah seterusnya.
Untuk masalah demonstrasi kita, mari kita mulakan dengan regresi linear yang mudah:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
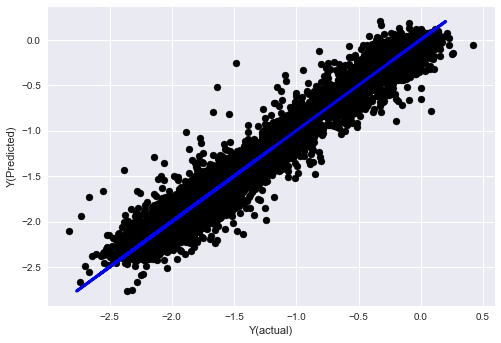
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
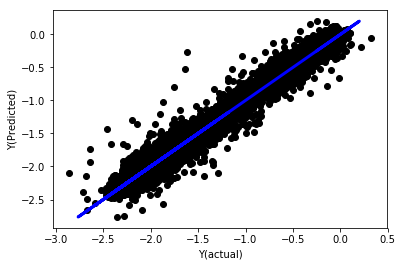
Regresi linear tanpa normalisasi
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Lihatlah pada pekali model. kita tidak boleh membandingkannya atau mengatakan mana yang penting, kerana mereka semua adalah skala yang berbeza. mari kita cuba normalisasi untuk membuat mereka sesuai dengan nisbah yang sama dan juga menguatkuasakan beberapa kelancaran.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
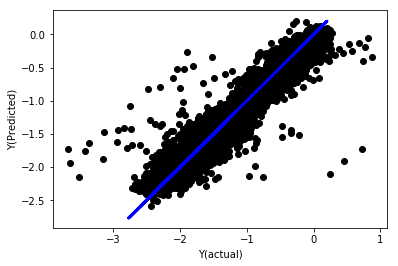
Regresi linear dengan normalisasi
Mean squared error: 0.05
Variance score: 0.90
Model ini tidak meningkatkan model sebelumnya, tetapi ia tidak lebih teruk. sekarang kita boleh membandingkan pekali untuk melihat mana yang sebenarnya penting.
Mari kita lihat pada pekali:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Hasilnya ialah:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Kita dapat melihat dengan jelas bahawa beberapa ciri mempunyai pekali yang lebih tinggi daripada yang lain, dan mereka mungkin mempunyai keupayaan ramalan yang lebih kuat.
Mari kita lihat hubungan antara ciri-ciri yang berbeza.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
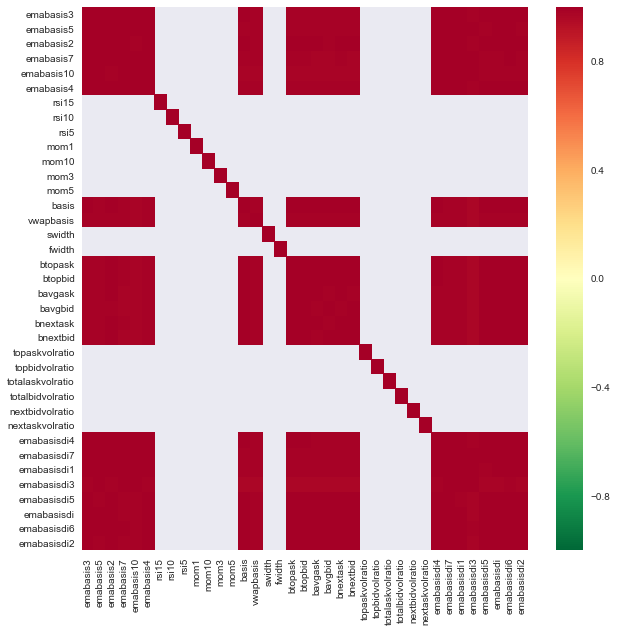
Hubungan antara ciri-ciri
Kawasan merah gelap mewakili pembolehubah yang sangat berkaitan. Mari kita mencipta / mengubah suai beberapa ciri lagi dan cuba memperbaiki model kita.
Sebagai contoh, saya boleh membuang ciri-ciri seperti emabasisdi7 dengan mudah, yang hanya kombinasi linear ciri-ciri lain.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
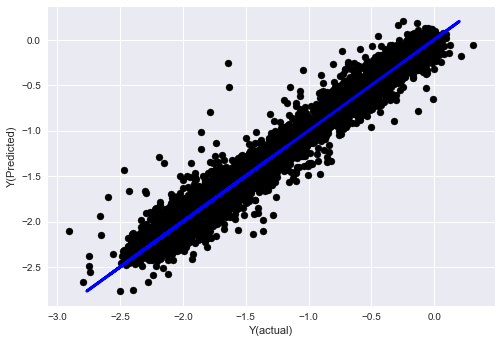
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Lihat, prestasi model kami tidak berubah. kami hanya memerlukan beberapa ciri untuk menjelaskan pembolehubah sasaran kami. saya cadangkan anda mencuba lebih banyak ciri di atas, cuba kombinasi baru, dan sebagainya, untuk melihat apa yang boleh meningkatkan model kami.
Kita juga boleh mencuba model yang lebih kompleks untuk melihat sama ada perubahan dalam model boleh meningkatkan prestasi.
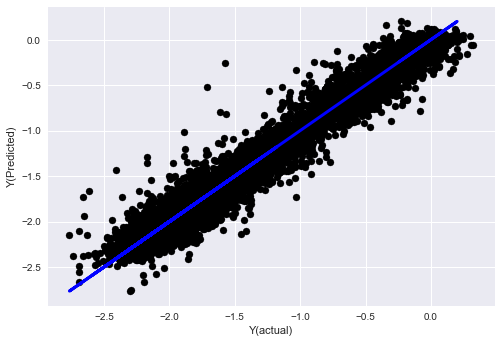
- Algoritma jiran terdekat K (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
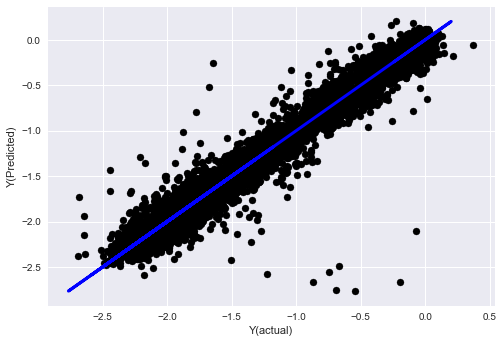
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Pokok keputusan
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Langkah 7: Uji semula data ujian
Periksa prestasi data sampel sebenar
Prestasi pengujian balik pada set data ujian (tidak disentuh)
Ini adalah masa yang kritikal. kita menjalankan model pengoptimuman akhir kita dari langkah terakhir data ujian, kita mengetepikan pada permulaan dan kita tidak menyentuh data setakat ini.
Ini memberi anda jangkaan yang realistik tentang bagaimana model anda akan dijalankan pada data baru dan tidak dilihat apabila anda memulakan perdagangan masa nyata. Oleh itu, adalah perlu untuk memastikan bahawa anda mempunyai set data yang bersih yang tidak digunakan untuk melatih atau mengesahkan model.
Jika anda tidak suka hasil backtest data ujian, sila buang model dan mulakan semula. Jangan kembali atau mengoptimumkan semula model anda, yang akan membawa kepada overfit! (Ia juga disyorkan untuk membuat set data ujian baru, kerana set data ini kini tercemar; apabila membuang model, kita sudah tahu kandungan set data secara tersirat).
Di sini kita masih akan menggunakan Alat Alat Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
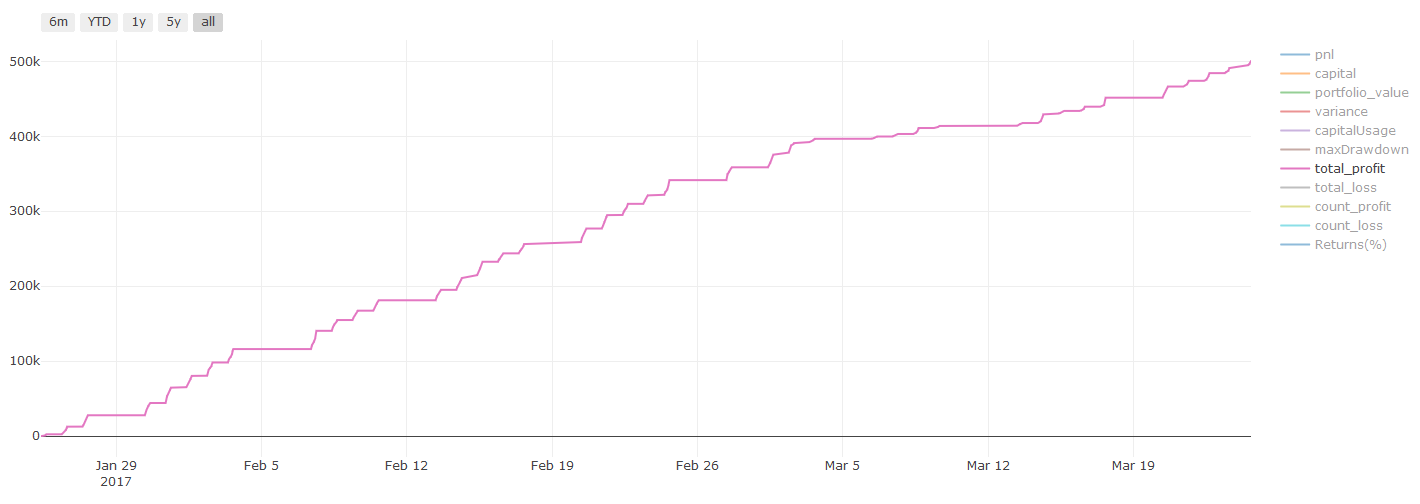
Hasil pengujian balik, Pnl dikira dalam USD (Pnl tidak termasuk dalam kos transaksi dan yuran lain)
Langkah 8: Kaedah lain untuk meningkatkan model
Pemantauan Rolling, pembelajaran set, Bagging dan Boosting
Selain mengumpul lebih banyak data, mencipta ciri yang lebih baik atau mencuba lebih banyak model, terdapat beberapa perkara lagi yang boleh anda cuba untuk meningkatkan.
1. Pemeriksaan Rolling
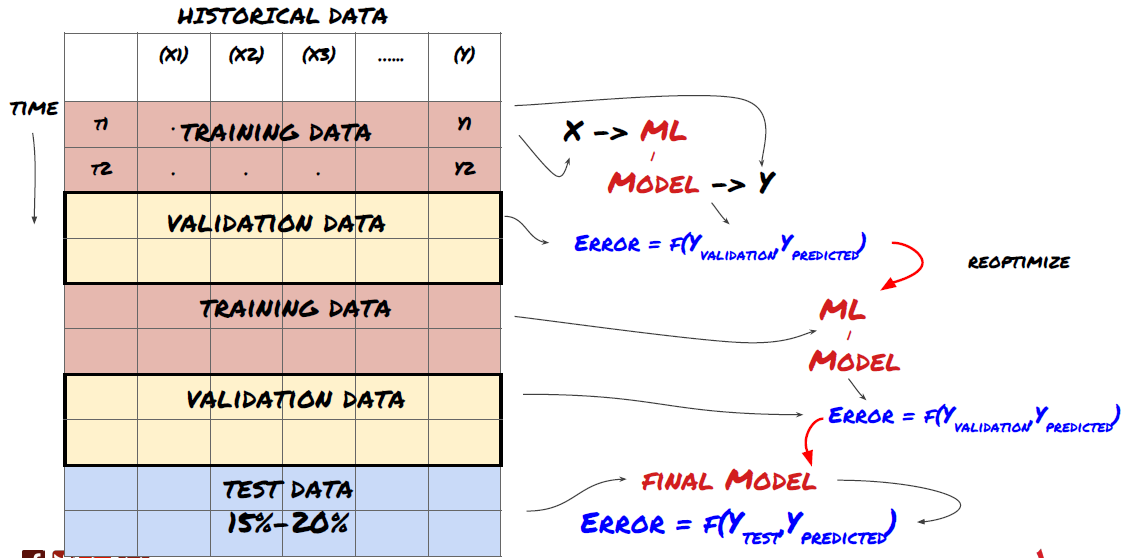
Pengesahan Rolling
Kondisi pasaran jarang kekal sama. Misalkan anda mempunyai data setahun, dan anda menggunakan data dari Januari hingga Ogos untuk latihan, dan menggunakan data dari September hingga Disember untuk menguji model anda. Anda mungkin berlatih untuk satu set keadaan pasaran yang sangat spesifik akhirnya. Mungkin tidak ada turun naik pasaran pada separuh pertama tahun, dan beberapa berita melampau membawa kepada kenaikan tajam di pasaran pada bulan September. Model anda tidak akan dapat mempelajari model ini, dan ia akan membawa anda hasil ramalan sampah.
Mungkin lebih baik untuk mencuba pengesahan bergolak ke hadapan, seperti latihan dari Januari hingga Februari, pengesahan pada bulan Mac, latihan semula dari April hingga Mei, pengesahan pada bulan Jun, dll.
2. Pembelajaran set
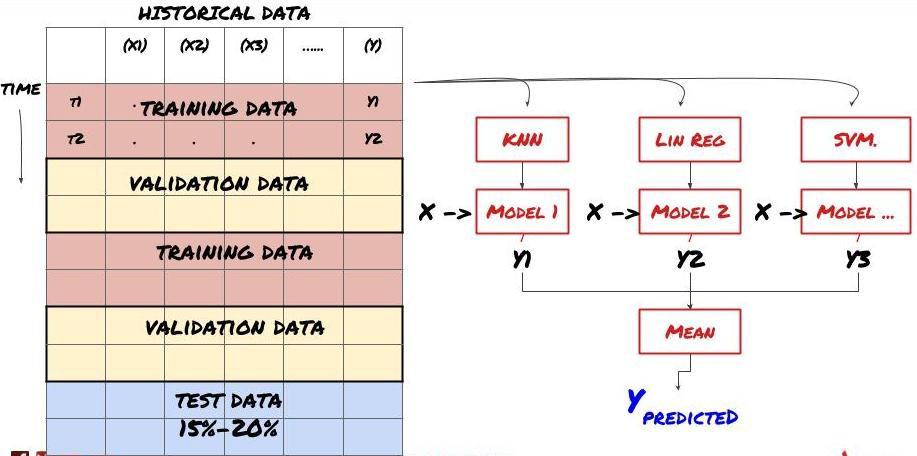
Pembelajaran Set
Beberapa model mungkin sangat berkesan dalam meramalkan senario tertentu, sementara model mungkin sangat terlalu sesuai dalam meramalkan senario lain atau dalam keadaan tertentu. Salah satu cara untuk mengurangkan kesilapan dan terlalu sesuai adalah dengan menggunakan satu set model yang berbeza. Ramalan anda akan menjadi purata ramalan yang dibuat oleh banyak model, dan kesilapan model yang berbeza mungkin diimbangi atau dikurangkan. Beberapa kaedah set biasa adalah Bagging dan Boosting.
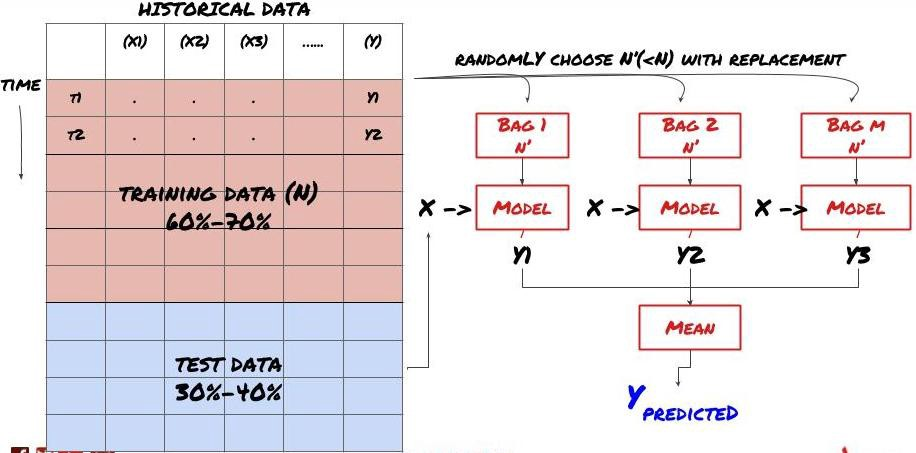
Pengemas
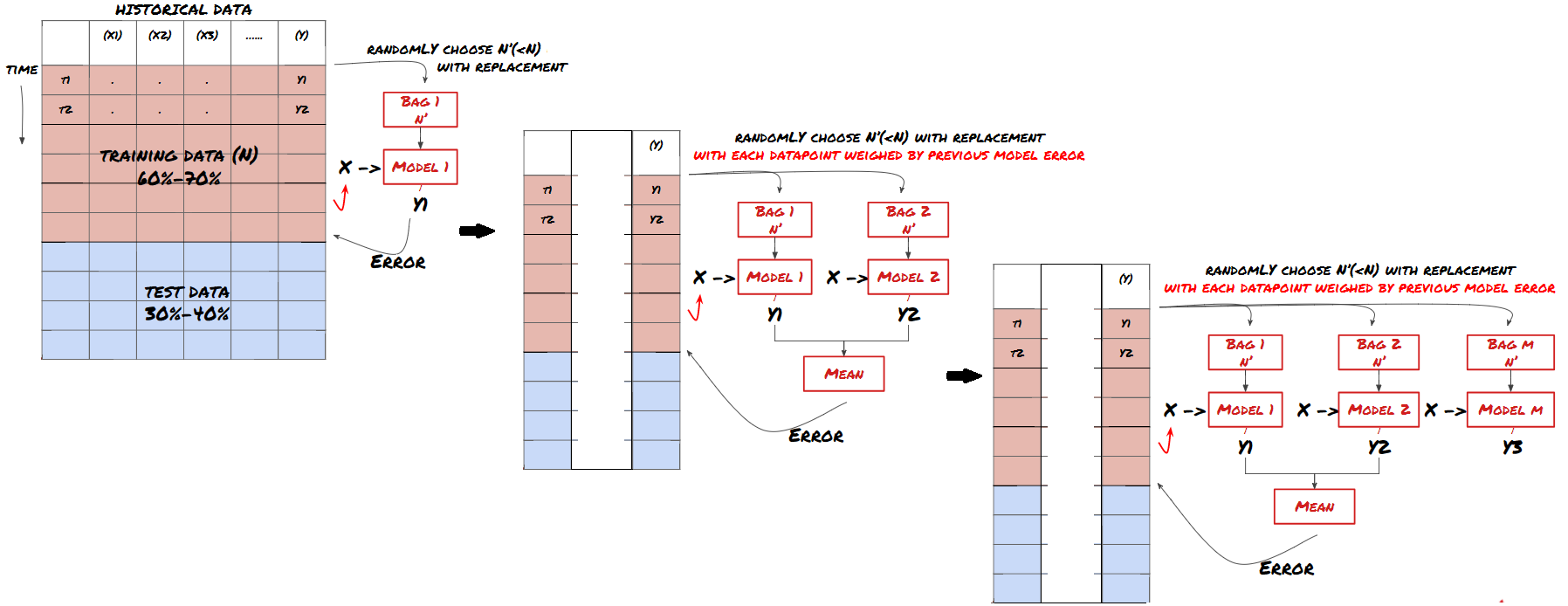
Meningkatkan
Untuk tujuan ringkas, saya akan melangkau kaedah ini, tetapi anda boleh mencari maklumat lanjut dalam talian.
Mari kita cuba kaedah set untuk masalah kita:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Setakat ini, kita telah mengumpulkan banyak pengetahuan dan maklumat.
-
Menyelesaikan masalah anda;
-
Mengumpul data yang boleh dipercayai dan membersihkan data;
-
Pembagian data kepada set latihan, pengesahan dan ujian;
-
Mencipta ciri dan menganalisis tingkah laku mereka;
-
Pilih model latihan yang sesuai mengikut tingkah laku;
-
Gunakan data latihan untuk melatih model anda dan membuat ramalan;
-
Memeriksa prestasi pada set pengesahan dan mengoptimumkan semula;
-
Memastikan prestasi akhir set ujian.
Adakah itu tidak masuk ke kepala anda? Tetapi ia tidak berakhir lagi. anda hanya mempunyai model ramalan yang boleh dipercayai. ingat apa yang kita benar-benar mahu dalam strategi kita? jadi anda tidak perlu:
-
Membangunkan isyarat berdasarkan model ramalan untuk mengenal pasti arah perdagangan;
-
Membangunkan strategi khusus untuk mengenal pasti kedudukan terbuka dan ditutup;
-
Melaksanakan sistem untuk mengenal pasti kedudukan dan harga.
Di atas akan menggunakan platform FMZ Quant (FMZ.COMPada platform FMZ Quant, terdapat antara muka API yang sangat terkapas dan sempurna, serta fungsi pesanan dan perdagangan yang boleh dipanggil secara global. Anda tidak perlu menyambung dan menambah antara muka API pertukaran yang berbeza satu demi satu. Di kotak Strategi platform FMZ Quant, terdapat banyak strategi alternatif yang matang dan sempurna yang sesuai dengan kaedah pembelajaran mesin dalam artikel ini, ia akan menjadikan strategi khusus anda lebih berkuasa.https://www.fmz.com/square.
** Nota penting mengenai kos transaksi: ** Model anda akan memberitahu anda apabila aset yang dipilih akan pergi panjang atau pergi pendek. Walau bagaimanapun, ia tidak mempertimbangkan yuran / kos transaksi / kuantiti perdagangan yang tersedia / stop loss, dll. Kos transaksi biasanya mengubah transaksi yang menguntungkan menjadi kerugian. Sebagai contoh, aset dengan kenaikan harga yang dijangka $ 0.05 adalah membeli, tetapi jika anda perlu membayar $ 0.10 untuk transaksi ini, anda akan mendapat kerugian bersih $ 0.05 akhirnya. Selepas anda mengambil kira komisen broker, yuran pertukaran dan perbezaan mata, carta keuntungan besar kami di atas kelihatan seperti ini:
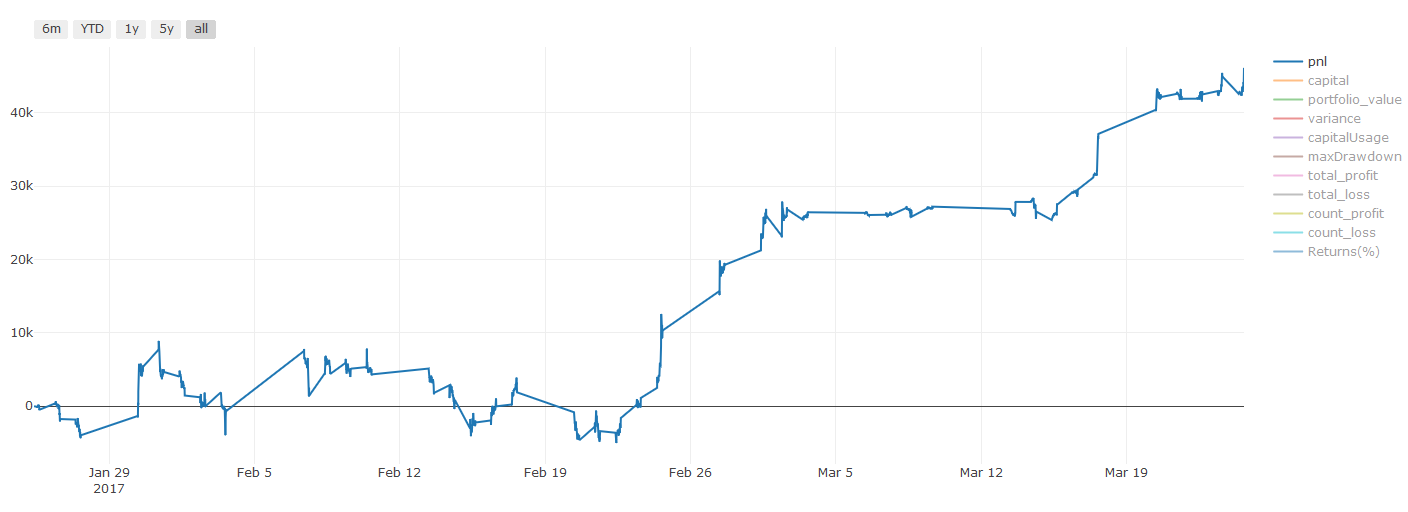
Hasil backtest selepas yuran dagangan dan perbezaan mata, Pnl adalah USD.
Bayaran urus niaga dan perbezaan harga menyumbang lebih 90% daripada PNL kami! Kami akan membincangkannya secara terperinci dalam artikel seterusnya.
Akhirnya, mari kita lihat beberapa perangkap biasa.
Apa yang perlu dilakukan dan apa yang tidak boleh dilakukan
-
Elakkan terlalu sesuai dengan semua kekuatan anda!
-
Jangan melatih semula selepas setiap titik data: ini adalah kesilapan biasa yang dilakukan orang dalam pembangunan pembelajaran mesin. Jika model anda perlu dilatih semula selepas setiap titik data, ia mungkin bukan model yang sangat baik. Maksudnya, ia perlu dilatih semula secara berkala, dan hanya perlu dilatih pada kekerapan yang munasabah (contohnya, jika ramalan dalam hari dibuat, ia perlu dilatih semula pada akhir setiap minggu).
-
Elakkan bias, terutamanya bias yang melihat ke hadapan: Ini adalah sebab lain mengapa model tidak berfungsi, dan pastikan anda tidak menggunakan maklumat masa depan. Dalam kebanyakan kes, ini bermakna pembolehubah sasaran Y tidak digunakan sebagai ciri dalam model. Anda boleh menggunakannya semasa backtesting, tetapi ia tidak akan tersedia apabila anda menjalankan model sebenarnya, yang akan membuat model anda tidak dapat digunakan.
-
Berhati-hati dengan bias perlombongan data: Oleh kerana kami cuba menjalankan satu siri pemodelan pada data kami untuk menentukan sama ada ia sesuai, jika tidak ada sebab khusus, sila pastikan anda menjalankan ujian yang ketat untuk memisahkan mod rawak dari mod sebenar yang mungkin berlaku.
Elakkan pemasangan berlebihan
Ini sangat penting. Saya rasa perlu menyebutnya lagi.
-
Overfitting adalah perangkap yang paling berbahaya dalam strategi perdagangan;
-
Algoritma yang kompleks mungkin berfungsi dengan baik dalam backtest, tetapi ia gagal dengan teruk pada data yang tidak kelihatan baru. Algoritma ini tidak benar-benar mendedahkan sebarang trend data, juga tidak mempunyai keupayaan ramalan sebenar. Ia sangat sesuai untuk data yang dilihat;
-
Pastikan sistem anda semudah mungkin. Jika anda mendapati bahawa anda memerlukan banyak fungsi yang kompleks untuk menafsirkan data, anda mungkin overfit;
-
Bahagikan data yang ada kepada data latihan dan ujian, dan sentiasa mengesahkan prestasi data sampel sebenar sebelum menggunakan model untuk transaksi masa nyata.
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (2)
- Pendahuluan mengenai Lead-Lag dalam mata wang digital (2)
- Perbincangan mengenai Penerimaan Isyarat Luaran Platform FMZ: Penyelesaian Lengkap untuk Menerima Isyarat dengan Perkhidmatan Http Terbina dalam Strategi
- Penyelidikan penerimaan isyarat luaran platform FMZ: strategi penyelesaian lengkap untuk penerimaan isyarat perkhidmatan HTTP terbina dalam
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (1)
- Perkenalkan led-lag suite dalam mata wang digital ((1)
- Perbincangan mengenai penerimaan isyarat luaran Platform FMZ: API Terpanjang VS Strategi Perkhidmatan HTTP Terbina dalam
- Penyelidikan penerimaan isyarat luaran platform FMZ: API yang diperluaskan vs strategi perkhidmatan HTTP terbina dalam
- Perbincangan mengenai Kaedah Ujian Strategi Berdasarkan Random Ticker Generator
- Mengkaji kaedah ujian strategi berdasarkan penjana pasaran rawak
- Ciri baru FMZ Quant: Gunakan fungsi _Serve untuk membuat perkhidmatan HTTP dengan mudah
- Rangkaian Perdagangan Kuantitatif Rangkaian Rangkaian Rangkaian Neural dan Mata Wang Digital (1) - LSTM Meramalkan Harga Bitcoin
- Penggunaan strategi gabungan indeks kekuatan relatif SMA dan RSI
- Pembangunan strategi CTA dan perpustakaan kelas standard platform FMZ Quant
- Strategi perdagangan kuantitatif dengan analisis momentum harga dalam Python
- Melaksanakan Strategi Dagangan Kuantitatif Mata Wang Digital Dual Thrust di Python
- Cara terbaik untuk memasang dan menaik taraf untuk Linux docker
- Mencapai strategi ekuiti yang seimbang dengan penyelarasan yang teratur
- Analisis Data Siri Masa dan Ujian Balik Data Tick
- Analisis Kuantitatif Pasaran Mata Wang Digital
- Perdagangan berpasangan berasaskan teknologi data
- Menggunakan persekitaran penyelidikan untuk menganalisis butiran lindung nilai segitiga dan kesan yuran pengendalian pada perbezaan harga lindung nilai
- Reformasi API niaga hadapan Deribit untuk menyesuaikan diri dengan perdagangan kuantitatif opsyen
- Alat yang lebih baik membuat kerja yang baik - belajar menggunakan persekitaran penyelidikan untuk menganalisis prinsip perdagangan
- Strategi lindung nilai silang mata wang dalam perdagangan kuantitatif aset blockchain
- Dapatkan panduan strategi mata wang digital FMex di FMZ Quant
- Mengajar anda untuk menulis strategi - pemindahan strategi MyLanguage (Advanced)
- Mengajar anda untuk menulis strategi - menanam strategi MyLanguage
- Mengajar anda untuk menambah sokongan pelbagai carta kepada strategi
- Mengajar anda untuk menulis fungsi sintesis K-garis dalam versi Python
- Analisis Strategi Saluran Donchian dalam persekitaran penyelidikan