Análise completa de vantagens e desvantagens de três grandes categorias de algoritmos de aprendizagem de máquina
Autora:Inventor quantificado - sonho pequeno, Criado: 2017-10-30 12:01:59, Atualizado: 2017-11-08 13:55:03Análise completa de vantagens e desvantagens de três grandes categorias de algoritmos de aprendizagem de máquina
No aprendizado de máquina, o objetivo é a previsão ou o agrupamento. O foco deste artigo é a previsão. A previsão é o processo de estimar o valor das variáveis de saída a partir de um conjunto de variáveis de entrada. Por exemplo, se obtermos um conjunto de características de uma casa, podemos prever seu preço de venda. Os problemas de previsão podem ser divididos em duas grandes categorias: Com isso em mente, vamos ver agora os algoritmos mais comuns e destacados em aprendizagem de máquina. Dividimos esses algoritmos em três categorias: modelos lineares, modelos baseados em árvores e redes neurais.
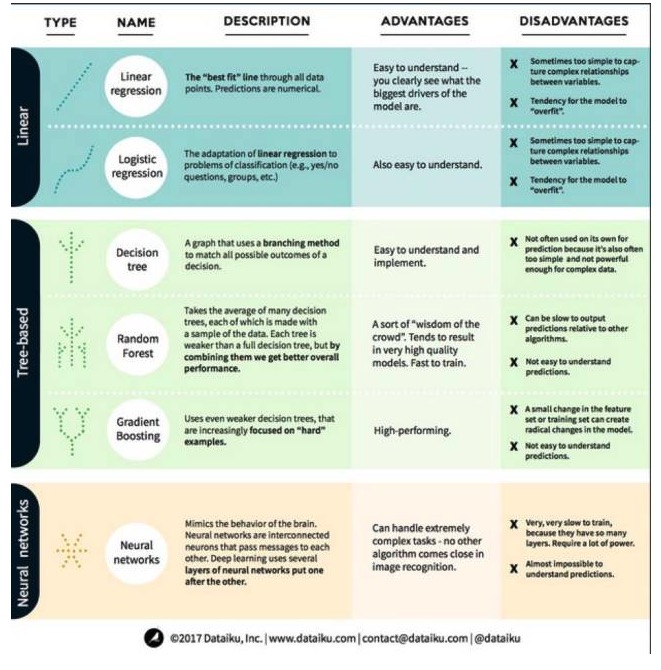
Um algoritmo de modelo linear: um modelo linear usa uma fórmula simples para encontrar a linha que melhor se encaixa em um conjunto de pontos de dados. Este método, que remonta a mais de 200 anos, é amplamente utilizado em estatística e aprendizado de máquina. Por sua simplicidade, é útil para estatística. A variável que você deseja prever é representada como uma equação de uma variável que você já conhece.
-
1.线性回归
A regressão linear, ou mais precisamente, a regressão linear do quadrado mínimo, é a forma mais padrão de um modelo linear. Para problemas de regressão, a regressão linear é o modelo linear mais simples. Sua desvantagem é que o modelo é facilmente super-adaptável, ou seja, o modelo se adapta perfeitamente aos dados treinados, à custa da capacidade de se difundir para novos dados. Portanto, a regressão linear no aprendizado de máquina (e a regressão lógica que falaremos em seguida) geralmente é super-adaptável, o que significa que o modelo tem uma certa punição para evitar o super-ajuste.
Outra desvantagem dos modelos lineares é que, como são muito simples, não são fáceis de prever comportamentos mais complexos quando as variáveis de entrada não são independentes.
-
2.逻辑回归
A regressão lógica é a adaptação da regressão linear ao problema de classificação. A desvantagem da regressão lógica é a mesma que a regressão linear. A função lógica é muito boa para o problema de classificação, pois introduz efeitos de limite.
Segundo, algoritmos de modelos de árvores
-
1a árvore de decisão
A árvore de decisão é uma ilustração de cada resultado possível da decisão usando o método de ramificação. Por exemplo, você decide encomendar uma salada e sua primeira decisão pode ser a variedade de lentilhas cruas, depois os ingredientes e depois a variedade de salada. Podemos representar todos os resultados possíveis em uma árvore de decisão.
Para treinar árvores de decisão, precisamos usar o conjunto de dados de treinamento e descobrir qual atributo é mais útil para o objetivo. Por exemplo, nos casos de detecção de fraudes, podemos descobrir que o atributo que mais afeta a previsão do risco de fraudes é o país. Depois de ramificar a primeira propriedade, obtemos dois subconjuntos, que são mais acertados se soubermos apenas a primeira propriedade. Em seguida, descobrimos o segundo atributo que é o melhor para ramificar esses dois subconjuntos, dividimos novamente e assim por diante, até que um número suficiente de atributos atenda às necessidades do objetivo.
-
2 - Florestas aleatórias
A floresta aleatória é a média de muitas árvores de decisão, em que cada árvore de decisão é treinada com uma amostra aleatória de dados. Cada árvore na floresta aleatória é mais fraca do que uma árvore de decisão completa, mas colocando todas as árvores juntas, podemos obter um melhor desempenho geral devido às vantagens da diversidade.
A floresta aleatória é um algoritmo muito popular na aprendizagem de máquinas hoje. A floresta aleatória é fácil de treinar e tem um desempenho bastante bom. Sua desvantagem é que, em relação a outros algoritmos, a floresta aleatória pode ser lenta em produzir previsões, por isso, quando uma previsão rápida é necessária, a floresta aleatória pode não ser escolhida.
-
3o, elevação de gradiente
A maior diferença entre o gradient boosting e o random forest é que, no gradient boosting, as árvores são treinadas uma a uma. Cada árvore posterior é treinada principalmente pela árvore da frente para identificar dados errados. Isso torna o gradient boosting mais focado em situações mais fáceis de prever e mais focado em situações menos difíceis.
O treinamento de elevação de gradiente também é rápido e tem um bom desempenho. No entanto, pequenas mudanças no conjunto de dados de treinamento podem causar mudanças fundamentais no modelo e, portanto, o resultado que ele produz pode não ser o mais viável.
Três, algoritmos de redes neurais: redes neurais são um fenômeno biológico composto por neurônios interligados no cérebro que trocam informações uns com os outros. A ideia é agora aplicada ao campo do aprendizado de máquina, chamado ANN. O aprendizado profundo é uma rede neural de várias camadas sobrepostas. A ANN é uma série de modelos que obtêm capacidades cognitivas semelhantes às do cérebro humano através da aprendizagem.
Traduzido do Big Data Plateau
- Os inventores quantificam o suporte ao comércio de moedas como o huobi e o OKEX e ao USDT?
- Publicar uma função de retorno integrada ao catálogo de transações de moeda digital
- Como calcular o potencial máximo de financiamento de uma estratégia usando dados de retrospectiva de ganhos, flutuações, etc. de uma estratégia quantificada?
- O Demónio de Shannon.
- O que é complexo não é a tecnologia, é a mente humana!
- O acesso à interface do bitfinex é lento, quais são as recomendações para a colocação do servidor?
- Bitfinex está a correr mal, por favor, ajudem-me a analisá-lo, obrigado!
- Por favor, baseie-se em que ponto de tempo os dados obtidos pela API foram chamados?
- O Bitcoin é uma moeda digital, mas não é uma moeda virtual, é uma moeda virtual.
- Por que há apenas quatro pares de negociação no bitfinex: BCH_USD, BTC_USD, ETH_USD e LTC_USD?
- O Bitcoin é o Bitcoin mais vendido do mundo, e o Bitcoin é o Bitcoin mais vendido do mundo.
- Mecanismo de observação final
- Comentário de Bug: O botão de interação sem o valor padrão de parâmetros na criação da política falhou em salvar
- Por favor, o sistema de retrospecção não pode selecionar outras moedas?
- Por favor traduza a página do plano de compra
- O Bitfinex tem três mercados, como fazer com que o robô escolha?
- Opções ganham-se com a perspectiva dinâmica
- Bitfinex retrospectiva e verificação de moedas não coincidem
- Como é que se vê a eficácia da ruptura e da forca de ouro?
- Bithumb recebeu informações de conta erradas