Comparação dos 8 grandes algoritmos de aprendizagem de máquina
Autora:Inventor quantificado - sonho pequeno, Criado: 2016-12-05 10:42:02, Atualizado:Comparação dos 8 grandes algoritmos de aprendizagem de máquina
Este artigo analisa os cenários de adaptação dos seguintes algoritmos mais comuns e seus benefícios e desvantagens!
Há muitos algoritmos de aprendizagem de máquina, classificando, regressando, agrupando, recomendando, reconhecendo imagens, etc. Não é fácil encontrar um algoritmo adequado, então, em aplicações reais, geralmente experimentamos com o aprendizado inspirado.
Normalmente, nós começamos com algoritmos que todos aceitam, como o SVM, GBDT, Adaboost, e agora o aprendizado profundo é muito popular e as redes neurais também são uma boa opção.
Se você está preocupado com precisão, a melhor maneira é testar cada algoritmo individualmente através da validação cruzada, compará-los e ajustar os parâmetros para garantir que cada algoritmo obtenha o melhor e, finalmente, escolher o melhor.
Mas se você está apenas procurando por um algoritmo que seja bom o suficiente para resolver seu problema, ou aqui estão algumas dicas para você consultar, abaixo vamos analisar as vantagens e desvantagens de cada algoritmo, com base nas vantagens e desvantagens do algoritmo, é mais fácil escolher o que você quer.
- ## Desvios e desigualdades Em estatística, um modelo bom ou ruim é medido em termos de desvio e diferença, então vamos popularizar os desvios e diferenças:
Desvio: descreve a diferença entre o valor esperado (E
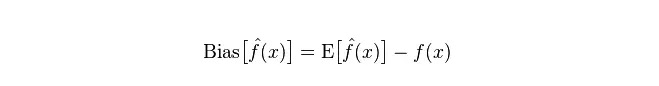
Divergência: descreve a amplitude de variação do valor de previsão P, o grau de separação, é a diferença do valor de previsão, ou seja, a distância do seu valor de expectativa E. Quanto maior a diferença, a distribuição dos dados é mais dispersa.
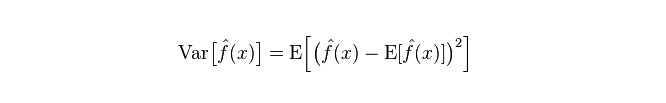
O erro real do modelo é a soma dos dois, conforme o gráfico abaixo:
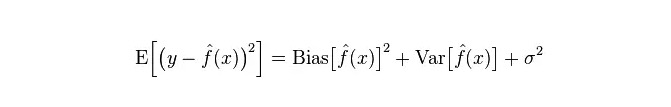
Se for um pequeno conjunto de treinamentos, um classificador de alto desvio/baixo desvio (por exemplo, o simples Bayes NB) tem uma vantagem maior do que um classificador de baixo desvio/baixo desvio (por exemplo, KNN) porque o último é super-ajustado.
Contudo, à medida que o conjunto de treinamentos cresce, o modelo é melhor capaz de fazer previsões sobre os dados originais, e o desvio diminui, quando os classificadores de baixo desvio/alto desvio começam a ganhar vantagem (por terem um menor erro de aproximação), quando os classificadores de alto desvio já não são suficientes para fornecer modelos precisos.
Claro, você também pode pensar que é uma diferença entre o modelo de geração (NB) e o modelo de determinação (KNN).
- ## Por que dizer que o simples Bayes é alto desvio e baixo desvio?
O seguinte foi divulgado:
Primeiro, suponha que você conheça a relação entre o conjunto de treinamento e o conjunto de testes. Simplificando, vamos aprender um modelo no conjunto de treinamento e, em seguida, usar o conjunto de testes.
Mas muitas vezes, podemos apenas assumir que os conjuntos de testes e os conjuntos de treinamento correspondem à mesma distribuição de dados, mas não obtemos dados reais de testes.
Como a amostra de treinamento é pequena (ou, pelo menos, insuficiente), o modelo obtido através do conjunto de treinamento não é sempre verdadeiramente correto. Mesmo com 100% de exatidão no conjunto de treinamento, não se pode dizer que ele representa uma distribuição de dados real.
Além disso, na prática, as amostras de treinamento também costumam ter um certo erro de ruído, de modo que, se se buscar muito a perfeição no conjunto de treinamento e usar um modelo muito complexo, o modelo pode usar os erros no conjunto de treinamento como características reais da distribuição de dados, resultando em estimativas erradas da distribuição de dados.
Assim, no conjunto de testes reais, o erro é um desastre ("este fenômeno é chamado de adequação"); mas também não se pode usar um modelo muito simples, caso contrário, o modelo não será suficiente para representar a distribuição de dados quando a distribuição de dados é mais complexa ("representa uma taxa de erro muito alta, mesmo no conjunto de treinamento, o fenômeno é de baixa adequação").
A superconfiguração indica que o modelo usado é mais complexo do que a distribuição real de dados, enquanto o modelo usado é mais simples do que a distribuição real de dados.
No contexto da aprendizagem estatística, quando se descreve a complexidade do modelo, há uma visão de que o erro = Bias + Variance. Aqui, o erro pode ser entendido como a taxa de erro de previsão do modelo, que é composta por duas partes, uma parte é o parte da estimativa imprecisa ("Bias") causada pela modelação muito simples, e a outra parte é o espaço maior de variação e incerteza ("Variance") causada pela modelação muito complexa.
Assim, é fácil analisar o simples Bayesian. O simples pressuposto de que os dados são independentes é um modelo muito simplificado. Assim, para um modelo simples como esse, a maioria das vezes o Bias é maior que o Variance, ou seja, há um desvio alto e um desvio baixo.
Na prática, para minimizar o erro, precisamos equilibrar a proporção de Bias e Variance na escolha do modelo, ou seja, equilibrar o over-fitting e o under-fitting.
A relação entre os desvios e diferenças e a complexidade do modelo é mais clara usando o gráfico abaixo:
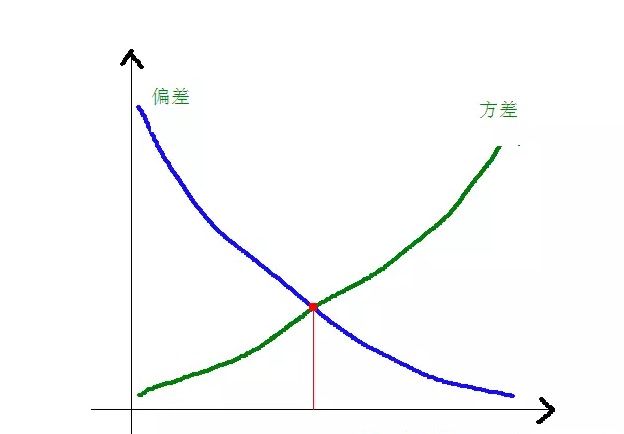
Quando a complexidade do modelo aumenta, os desvios diminuem gradualmente e os desvios aumentam gradualmente.
-
Avantagens e desvantagens de algoritmos comuns
- ### 1. Um inocente Bayes
O Bayesian simples pertence ao modelo de geração (sobre o modelo de geração e o modelo de determinação, principalmente sobre se eles exigem uma distribuição conjunta) e é muito simples, você apenas faz uma pilha de contagens.
Se o pressuposto de independência condicional (uma condição mais rigorosa) for estabelecido, o índice de convergência de um classificador Bayesian simples será mais rápido do que o de um modelo de classificação, como a regressão lógica, de modo que você só precisa de menos dados de treinamento. Mesmo que o pressuposto de independência condicional não seja estabelecido, o classificador NB ainda se apresenta muito bem na prática.
Sua principal desvantagem é que não pode aprender as interações entre características, que, em mRMR, são redundantes. Citando um exemplo mais clássico, por exemplo, embora você goste dos filmes de Brad Pitt e Tom Cruise, ele não pode aprender os filmes que você não gosta deles juntos.
Vantagens:
O modelo Bayesian simples é derivado da teoria matemática clássica, com uma base matemática sólida e uma eficiência de classificação estável. Performa bem com dados de pequena escala, pode lidar com tarefas multiclases individualmente e é adequado para treinamento incremental. O algoritmo é muito mais simples e é usado para classificar textos. Desvantagens:
A probabilidade anterior deve ser calculada. A taxa de erros nas decisões de classificação; A forma de expressão dos dados introduzidos é sensível.
- ### 2. Regresso lógico
Os modelos de determinação, onde há muitos métodos para normalizar os modelos (L0, L1, L2, etc.), e você não precisa se preocupar se suas características estão relacionadas, como acontece com o Bayesian simples.
Você também obtém uma boa explicação de probabilidade em comparação com árvores de decisão e máquinas SVM, e você pode até usar facilmente novos dados para atualizar o modelo (usando algoritmos de descida de gradiente on-line, gradient descent on-line).
Se você precisar de uma estrutura de probabilidade (por exemplo, para simplesmente ajustar o limite de classificação, indicar incertezas ou obter intervalos de confiança), ou se quiser integrar mais dados de treinamento rapidamente no modelo mais tarde, use-a.
Função sigmoide:
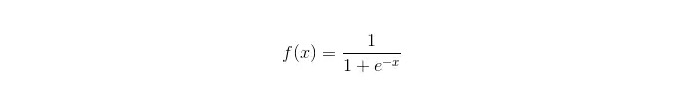
Vantagens: Realização de aplicações simples e amplas em questões industriais; O computador é muito pequeno quando classificado, rápido e com poucos recursos de armazenamento. A probabilidade de pontuação de uma amostra de observação conveniente; Para a regressão lógica, a conlinearidade múltipla não é um problema, que pode ser resolvido com a regularização L2; Desvantagens: Quando o espaço de características é grande, o desempenho da regressão lógica não é bom; Falta de ajuste e baixa precisão geral Não é capaz de lidar bem com um grande número de características ou variáveis de várias classes; Apenas pode lidar com problemas de duas categorias (o softmax derivado dessa base pode ser usado para múltiplas categorias) e deve ser linearmente divisível; Para características não-lineares, a conversão é necessária;
- ### 3. Regressão linear
A regressão linear é usada para regressão, ao contrário da regressão logística que é usada para classificação, cuja idéia básica é a otimização de funções de erro de forma mínima de duplicação com gradientes descrescentes.
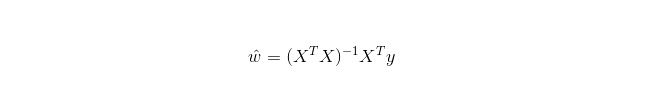
Em LWLR (Local weighted linear regression), a expressão de cálculo dos parâmetros é:
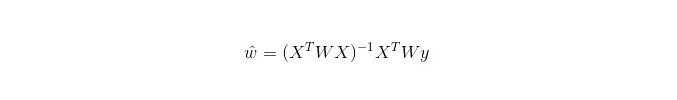
Assim, LWLR é um modelo não-paramétrico, uma vez que cada vez que um cálculo de regressão é feito, a amostra de treinamento é percorida pelo menos uma vez.
Vantagens: implementação simples, computação simples;
Desvantagens: Não é possível encaixar dados não-lineares.
- ### 4. Algoritmos de vizinhança mais recentes
O KNN é o algoritmo de vizinhança mais próxima, cujos principais processos são:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别;Como escolher um valor K ideal depende dos dados. Em geral, um valor K maior pode reduzir o impacto do ruído na classificação, mas pode tornar os limites entre as categorias mais obscuros.
Um melhor valor de K pode ser obtido por meio de várias técnicas inspiradas, como a verificação cruzada. Além disso, o ruído e a presença de vetores de características não correlacionadas reduzem a precisão do algoritmo próximo de K.
Os algoritmos de proximidade têm resultados de consistência mais fortes. À medida que os dados se aproximam do infinito, os algoritmos garantem que a taxa de erro não exceda duas vezes a taxa de erro dos algoritmos de Bayes. Para alguns valores bons de K, os algoritmos de proximidade garantem que a taxa de erro não exceda a taxa de erro teórico de Bayes.
Vantagens do algoritmo KNN
A teoria é madura, o pensamento é simples e pode ser usado para classificar e regressar. Pode ser usado para classificação não linear; A complexidade do tempo de treinamento é O ((n); Não há suposições sobre os dados, alta precisão e insensível aos outliers; Desvantagens
O número de computadores é grande. Problemas de desequilíbrio da amostra (isto é, algumas categorias têm um grande número de amostras, enquanto outras têm poucos); O Google Maps é uma ferramenta que permite que os usuários possam usar a sua própria memória.
- ### 5. Árvore de decisão
É fácil de explicar. Pode lidar com relações de interação entre características sem estresse e não é paramétrico, então você não precisa se preocupar com valores anormais ou se os dados são lineares (por exemplo, uma árvore de decisão pode facilmente lidar com a categoria A no final de uma dimensão x de uma característica, a categoria B no meio, e a categoria A aparece novamente no final da dimensão x de uma característica).
Uma das desvantagens é que não suporta o aprendizado on-line, então a árvore de decisão precisa ser completamente reconstruída quando a nova versão chega.
Outra desvantagem é a facilidade com que a adaptação ocorre, mas também é o ponto de entrada para métodos de integração como a floresta aleatória (RF) ou a elevação da árvore impulsionada.
Além disso, a floresta aleatória é frequentemente a vencedora de muitos problemas de classificação (geralmente um pouco melhor do que um vector de suporte), que é treinado rapidamente e pode ser ajustado, e você não precisa se preocupar em ajustar uma série de parâmetros como um vector de suporte, por isso tem sido popular no passado.
Uma coisa importante na árvore de decisão é escolher um atributo para ramificar, por isso é importante prestar atenção à fórmula de cálculo do ganho de informação e entender melhor isso.
A fórmula de cálculo para o filtro de informação é a seguinte:
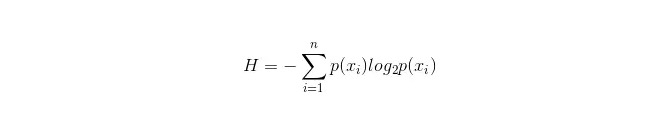
Nestes casos, n representa n categorias de classificação (por exemplo, se for um problema de 2 categorias, então n = 2) ; calcula as probabilidades p1 e p2 de que as duas categorias de amostras apareçam na amostra total, respectivamente, para calcular o volume de informação antes do ramificação da propriedade não selecionada.
Agora, selecione uma propriedade xixi para ramificar, e as regras de ramificação são: se xi = vxi = v, divida a amostra em um ramo da árvore; se não for igual, vá para outro ramo.
Obviamente, a amostra em ramificação provavelmente inclui duas categorias, calculadas respectivamente por H1 e H2 para os dois ramificados, e calculada a soma de informações após a ramificação H2 = p1 H1 + p2 H2, então o ganho de informações ΔH = H - H
. O princípio do ganho de informações é que todas as propriedades são testadas de lado e a propriedade que oferece o maior ganho é escolhida como propriedade da ramificação. Os benefícios da própria árvore de decisão
O cálculo é simples, fácil de entender e explicável; Uma amostra com propriedades inexistentes que seja mais adequada para tratamento; A partir de agora, a maioria dos usuários da rede social pode usar o aplicativo para fazer suas próprias perguntas. A partir daí, a pesquisa foi desenvolvida com o objetivo de obter resultados viáveis e eficazes em fontes de dados de grande porte em um período de tempo relativamente curto. Desvantagens
A floresta aleatória pode ser reduzida em grande parte; O que é que isso significa para o Brasil? Para os dados com uma variedade variável de amostras, no árvore de decisão, os resultados de ganhos de informação tendem a ser favoráveis a características com mais valores numéricos (a desvantagem ocorre sempre que os ganhos de informação são usados, como RF).
- ### 5.1 Adaptação
O Adaboost é um modelo de soma em que cada modelo é construído com base na taxa de erro do modelo anterior, com foco excessivo nas amostras com erros classificados e menos foco nas amostras com classificações corretas, para obter um modelo relativamente melhor após a repetição.
Vantagens
Adaboost é um classificador de alta precisão. Os subclassificadores podem ser construídos de várias maneiras. Os resultados calculados são compreensíveis quando usados classificadores simples, e a construção de classificadores fracos é extremamente simples. É simples, não precisa de filtragem de características. Não é fácil o overfitting. Sobre algoritmos combinados como o Random Forest e o GBDT, consulte este artigo: Machine Learning - Summary of Combination Algorithms
Desvantagem: mais sensível ao outlier
- ### 6. O SVM suporta vectores
A alta precisão fornece boas garantias teóricas para evitar a superfiguração, e funciona muito bem, mesmo que os dados sejam linearmente indivisíveis no espaço das características originais, desde que uma função nuclear apropriada seja dada.
É especialmente popular em problemas de classificação de texto em movimento em ultra-altas dimensões. Infelizmente, a memória é muito consumida e difícil de explicar, a execução e a configuração também são um pouco incômodas, mas o Random Forest apenas evita essas desvantagens e é mais prático.
Vantagens A partir daí, a tecnologia pode resolver problemas de alta dimensão, ou seja, grandes espaços de características. Capaz de lidar com interações de características não-lineares; Não é preciso depender de todos os dados. A população é muito grande e a população é pequena.
Desvantagens O estudo também mostrou que o número de amostras observadas não é muito elevado. Não há soluções universais para problemas não-lineares, e às vezes é difícil encontrar uma função nuclear adequada. A partir de agora, o número de usuários aumentará. A seleção de núcleos também é técnica (libsvm possui quatro funções nucleares: núcleo linear, núcleo polinômico, núcleo RBF e núcleo sigmoide):
Primeiro, se o número de amostras for menor do que o número de características, não é necessário escolher núcleos não-lineares, basta usar núcleos lineares.
Em segundo lugar, se o número de amostras for maior que o número de características, pode-se usar núcleos não-lineares para mapear a amostra em dimensões mais altas, geralmente com melhores resultados.
Terceiro, se o número de amostras e o número de características forem iguais, o caso pode ser usado com núcleos não-lineares, o mesmo princípio do segundo.
Para o primeiro caso, também é possível dimensionar os dados primeiro e usar núcleos não-lineares, que também é um método.
- ### 7. Vantagens e desvantagens de redes neurais artificiais
Os benefícios das redes neurais artificiais: A classificação é muito precisa. A partir de agora, a tecnologia será desenvolvida para fornecer soluções para o processo de processamento distribuído em paralelo, armazenamento distribuído e aprendizado. A robustez e a tolerância ao ruído dos nervos são fortes, o que permite aproximar-se adequadamente de relações não-lineares complexas. A função da memória de referência.
Os problemas das redes neurais artificiais: As redes neurais exigem uma grande quantidade de parâmetros, como a estrutura de topologia da rede, os valores iniciais de peso e de limite; Não é possível observar o processo de aprendizagem, os resultados de saída são difíceis de explicar e podem afetar a credibilidade e a aceitabilidade dos resultados; O tempo de aprendizagem é muito longo e pode até não atingir o objetivo.
- ### 8 K-Means agrupam
Anteriormente escrevi um artigo sobre o agrupamento de K-Means, link do blog: Algoritmos de aprendizagem de máquina - agrupamento de K-means.
Vantagens Os algoritmos são simples e fáceis de implementar; Para processar grandes conjuntos de dados, o algoritmo é relativamente escalável e eficiente, pois sua complexidade é de aproximadamente O ((nkt), onde n é o número de todos os objetos, k é o número de eixos e t é o número de vezes que o conjunto é iterado. O algoritmo tenta encontrar a divisão k que faz com que o erro do quadrado seja o menor valor da função. Os efeitos de agrupamento são melhores quando o núcleo é denso, esférico ou aglomerado, e a distinção entre núcleo e núcleo é clara.
Desvantagens Requisitos mais elevados para tipos de dados adequados para dados numéricos; Pode chegar a mínimos locais, mas é mais lento em dados de grande escala. O valor de K é mais difícil de escolher; Sensível aos valores centrais do pH do valor inicial, pode resultar em resultados de agrupamento diferentes para diferentes valores iniciais; Não é adequado para encontrar camadas com formas não convexas, ou camadas com grandes diferenças de tamanho. A pequena quantidade de dados sensíveis aos parâmetros de ruído e pontos isolados pode ter uma grande influência sobre a média.
Algoritmos de seleção de referências
O artigo que traduzi alguns artigos estrangeiros, em um deles, dá um simples truque de seleção de algoritmos:
A primeira opção é a regressão lógica, que se não funcionar bem, pode ser usada como referência para comparar seus resultados com outros algoritmos.
Em seguida, experimente uma árvore de decisão (uma floresta aleatória) para ver se pode melhorar significativamente o desempenho do seu modelo. Mesmo que você não o considere como o modelo final, você pode usar a floresta aleatória para remover as variáveis de ruído e fazer seleções de características.
Se o número de características e as amostras de observação forem particularmente grandes, o uso do SVM pode ser uma opção quando os recursos e o tempo forem suficientes.
Normalmente:
GBDT>=SVM>=RF>=Adaboost>=Other... Ah, agora o aprendizado profundo é muito popular, é usado em muitos campos, é baseado em redes neurais, eu também estou aprendendo, mas o conhecimento teórico não é muito sólido, não é profundo o suficiente para entender, por isso não o faço aqui. Algoritmos são importantes, mas bons dados são melhores do que bons algoritmos, e projetar boas características é muito útil. Se você tiver um conjunto de dados muito grande, o que quer que seja o algoritmo que você use pode não afetar muito o desempenho de classificação (assim, você pode fazer escolhas com base na velocidade e facilidade de uso).
-
Referências
- Filosofia de negociação em probabilidade
- Onde você precisa inserir o código de fundos
- GetRecords não está disponível no BTCTRADE.com
- O preço da opção é muito alto, mas você está perdendo dinheiro!
- Análise quantitativa da estratégia de acúmulo
- Aprendizagem de Máquina Engraçada: O Guia de Introdução Mais Breve
- A lei do comércio de urânio
- 7 algoritmos de classificação usados com frequência (estratégias de escrita usadas)
- A estratégia de negociação de alta frequência: triângulo de diferença
- 20 dicas para desenvolver o pensamento criativo
- Investimento para vencedores: segredos do pensamento anti-intuitivo
- Falar sobre os requisitos básicos de um sistema de negociação
- O indicador ATR é usado para medir a amplitude real da flutuação
- Há alguma consulta de código de erro robótico?
- A matemática do investimento é divertida!
- Matemática e jogos de azar
- Redenção do sistema equilátero
- Formulário de Kelly para o controle de posicionamento de arame
- A ideia de um velho pássaro de negociação de tendências, de um sistema de negociação quantitativa
- Recomendações de estratégias de alta frequência para o Bitcoin