Métodos de teste de estratégias baseados em geradores de mercado aleatórios
Autora:Inventor quantificado - sonho pequeno, Criado: 2024-11-29 16:35:44, Atualizado: 2024-12-02 09:12:43[TOC]

Prefácio
O sistema de retrospecção do inventor da plataforma de negociação quantitativa é um sistema de retrospecção que é constantemente atualizado e atualizado, aumentando gradualmente as funções e otimizando o desempenho. Como o sistema de retrospecção continua a ser otimizado com o desenvolvimento da plataforma, hoje vamos explorar um tópico baseado no sistema de retrospecção: "Testes estratégicos baseados em mercados aleatórios".
Necessidades
No campo da negociação quantitativa, o desenvolvimento de estratégias e a verificação da otimização são inseparáveis dos dados reais do mercado. No entanto, nas aplicações práticas, pode haver insuficiência para a retrospecção com base em dados históricos, como a falta de cobertura de mercados extremos ou cenários especiais, devido à complexidade do ambiente do mercado. Portanto, o design de um gerador de transações aleatórias eficiente é um instrumento eficaz para os desenvolvedores de estratégias de quantificação.
Quando precisamos que a estratégia seja rastreada para dados históricos de um mercado, de uma moeda, podemos usar a fonte oficial de dados da plataforma FMZ para testá-la. Às vezes, também queremos ver como a estratégia se comporta em um mercado totalmente estranho, quando podemos criar dados para testar a estratégia.
O uso de dados de mercado aleatórios significa:
-
- Avaliação da robustez da estratégia O gerador de mercado aleatório pode criar uma variedade de cenários de mercado possíveis, incluindo os mercados de extrema volatilidade, baixa volatilidade, tendência e turbulência. Testar estratégias nesses ambientes analógicos pode ajudar a avaliar se elas serão estáveis em diferentes condições de mercado. Por exemplo:
A estratégia pode ser adaptada às tendências e às mudanças de choque? A estratégia pode ser muito prejudicial em um mercado extremista?
-
- Identificar as potenciais fraquezas da estratégia A estratégia pode ser identificada e melhorada através da simulação de algumas situações de mercado anormais (por exemplo, um evento de cisne negro hipotético).
A estratégia depende excessivamente de uma estrutura de mercado? Há algum risco de que os parâmetros sejam demasiado ajustados?
-
- Optimização de parâmetros estratégicos Os dados gerados aleatoriamente oferecem um ambiente de teste mais diversificado para ajustar os parâmetros da estratégia, sem depender exclusivamente de dados históricos. Isso permite encontrar uma gama mais abrangente de parâmetros da estratégia, evitando ser limitado a padrões de mercado específicos nos dados históricos.
-
- Insuficiência de dados históricos Em alguns mercados (por exemplo, mercados emergentes ou mercados de negociação de pequenas moedas), os dados históricos podem não ser suficientes para cobrir todas as condições possíveis do mercado. O gerador de mercado aleatório pode fornecer uma grande quantidade de dados complementares para ajudar a realizar testes mais abrangentes.
-
- Desenvolvimento iterativo rápido Testes rápidos com dados aleatórios podem acelerar o ritmo de desenvolvimento de estratégias, sem depender de mercados em tempo real ou de limpeza e classificação de dados demorados.
Mas também é preciso uma estratégia de avaliação racional, e para dados de mercado gerados aleatoriamente, cuidado:
- 1, Embora os geradores de transações aleatórias sejam úteis, seu significado depende da qualidade dos dados gerados e do design do cenário alvo:
- 2, a lógica de geração deve ser próxima do mercado real: os resultados dos testes podem não ter valor de referência se o mercado gerado aleatoriamente estiver completamente fora da realidade. Por exemplo, pode-se combinar características estatísticas do mercado real (como distribuição de volatilidade, proporção de tendência) para projetar um gerador.
- O teste de dados reais não é uma substituição completa: dados aleatórios só complementam o desenvolvimento e otimização de estratégias, e as estratégias finais ainda precisam ser validadas em dados reais de mercado.
Como é que podemos criar dados de forma conveniente, rápida e fácil de usar, para que os sistemas de rastreamento possam usar?
Ideias de Design
Este artigo foi concebido para dar um cálculo de geração de mercado aleatório relativamente simples, mas há uma grande variedade de algoritmos de simulação, modelos de dados e outras técnicas que podem ser aplicadas, já que a discussão é limitada.
Combinando com o recurso de fontes de dados personalizadas do sistema de retorno da plataforma, nós escrevemos um programa em Python.
- 1, gerar aleatoriamente um conjunto de dados de linha K para gravar registros de persistência de arquivos CSV, para que os dados gerados possam ser salvos.
- 2, e então criar um serviço para fornecer suporte de fontes de dados para o sistema de rastreamento.
- 3, mostrar os dados da linha K gerados no gráfico.
Para alguns padrões de geração de dados de linha K, armazenamento de arquivos, etc., o controle de parâmetros pode ser definido como:
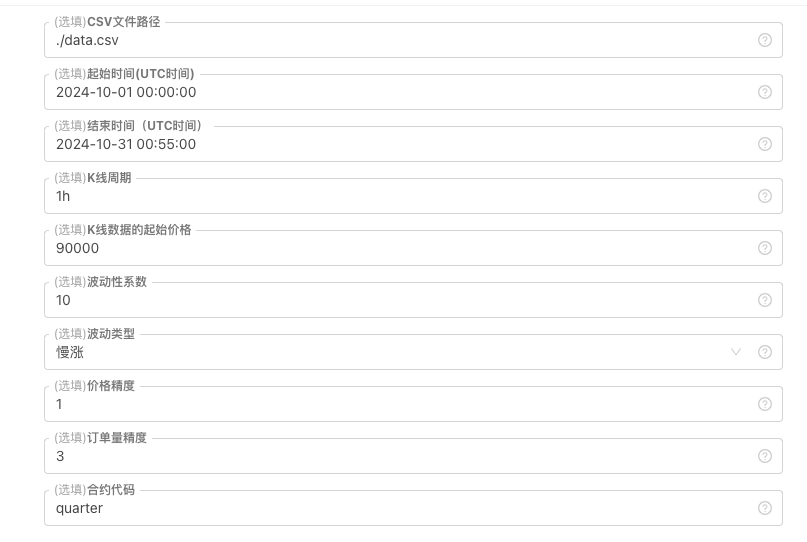
-
Padrão de geração aleatória de dados Para os tipos de flutuação de dados analógicos de linha K, apenas o simples uso de um número aleatório de probabilidades positivas negativas para um design simples pode não refletir o padrão de comportamento desejado quando não há muitos dados gerados. Se houver um método melhor, essa parte do código pode ser substituída. Com base nesse design simples, ajustar a gama de geração de números aleatórios no código e alguns coeficientes pode afetar o efeito dos dados gerados.
-
Verificação de dados O teste de racionalidade também é necessário para os dados da linha K gerados, para verificar se os preços altos e baixos não estão de acordo com a definição, para verificar a continuidade dos dados da linha K, etc.
Gerador de transações aleatórias do sistema de detecção
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Práticas em sistemas de retestamento
1, criar instâncias de políticas acima, configurar parâmetros e executar. 2, Disco físico (instância de política) precisa ser executado em um servidor de hospedagem, pois é necessário ter um IP público para que o sistema de retrospecção possa acessá-lo para obter dados. A estratégia começa automaticamente a gerar dados de transações aleatórias.

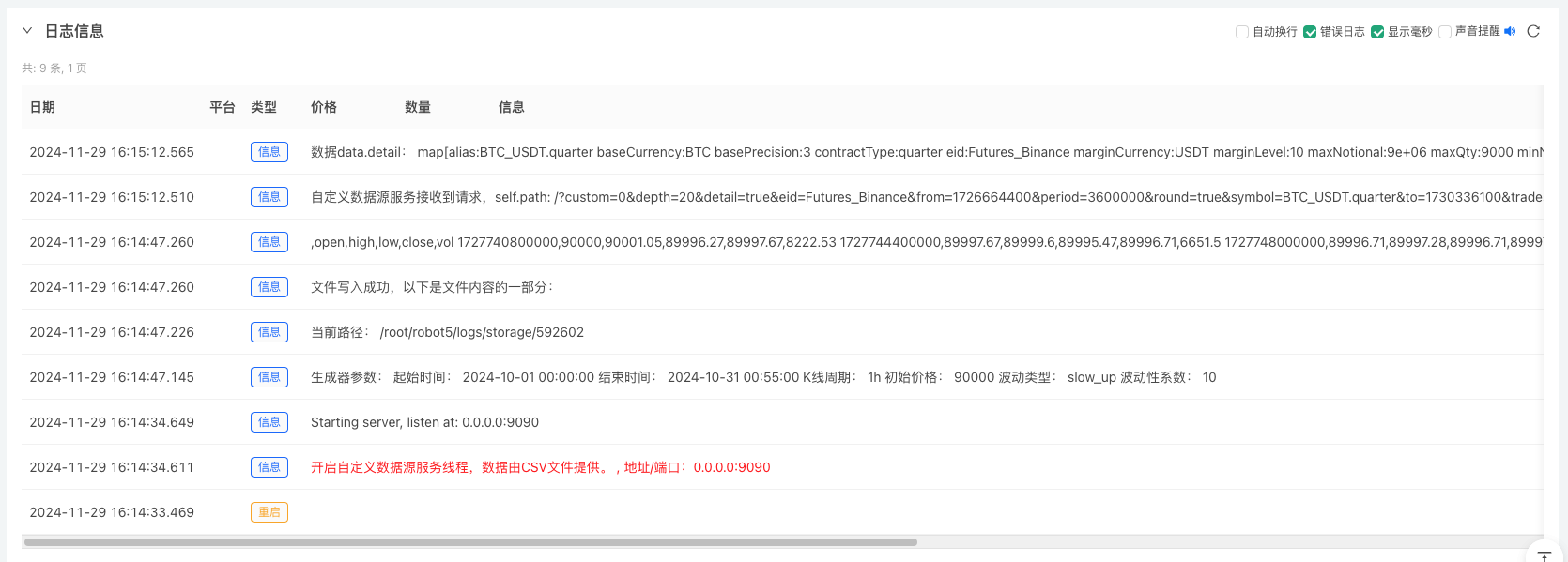
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
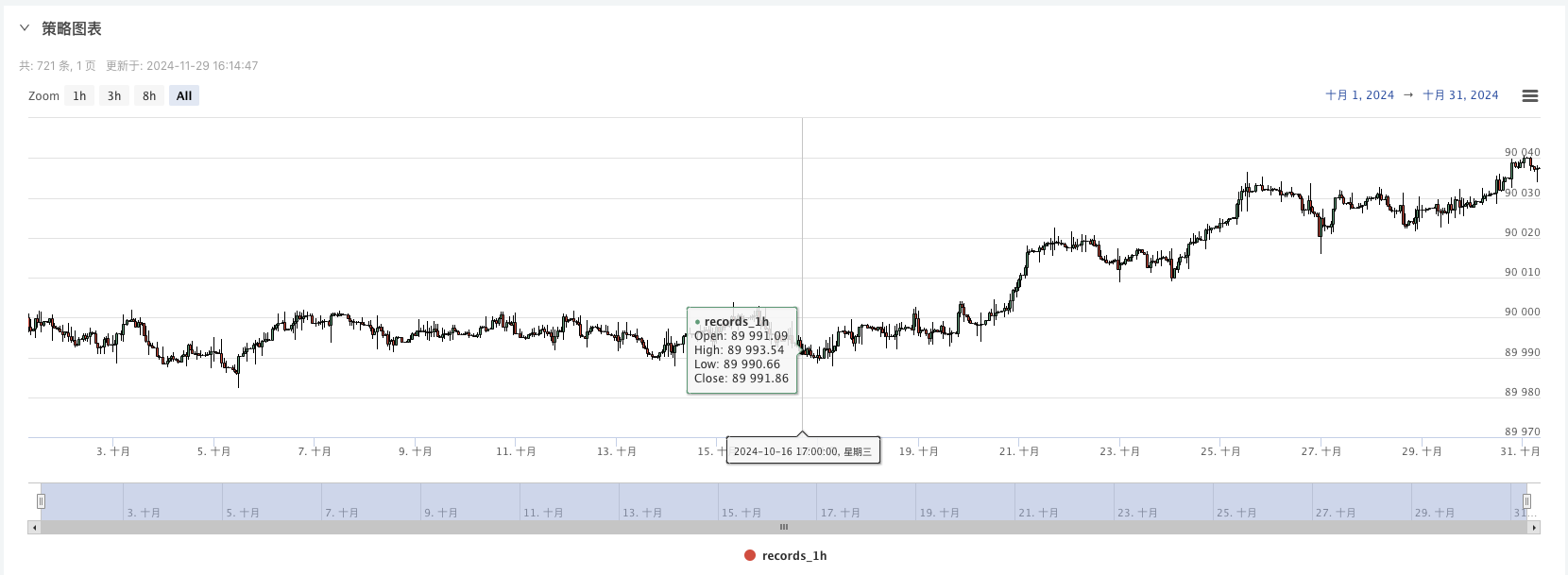
Agora, podemos usar os dados gerados aleatoriamente para fazer um teste de volta com uma estratégia.
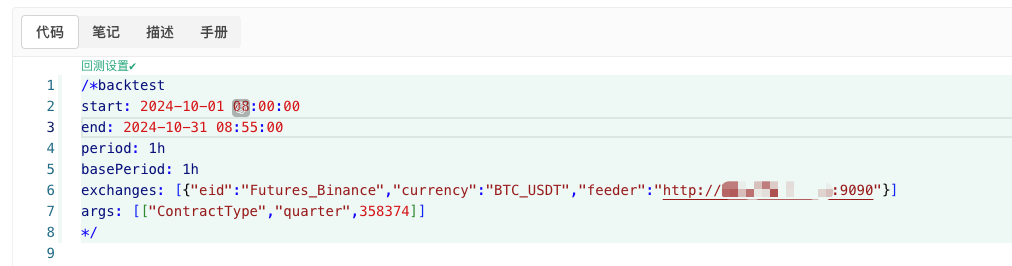
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
A configuração é ajustada de acordo com as informações acima.http://xxx.xxx.xxx.xxx:9090É o endereço IP do servidor e a porta aberta para o disco real de gerenciamento de políticas de transações aleatórias.
Esta é a fonte de dados personalizada, que pode ser consultada na seção de fontes de dados personalizadas na documentação da API da plataforma.
6o, o sistema de retrospecção pode testar dados aleatórios com uma boa fonte de dados.
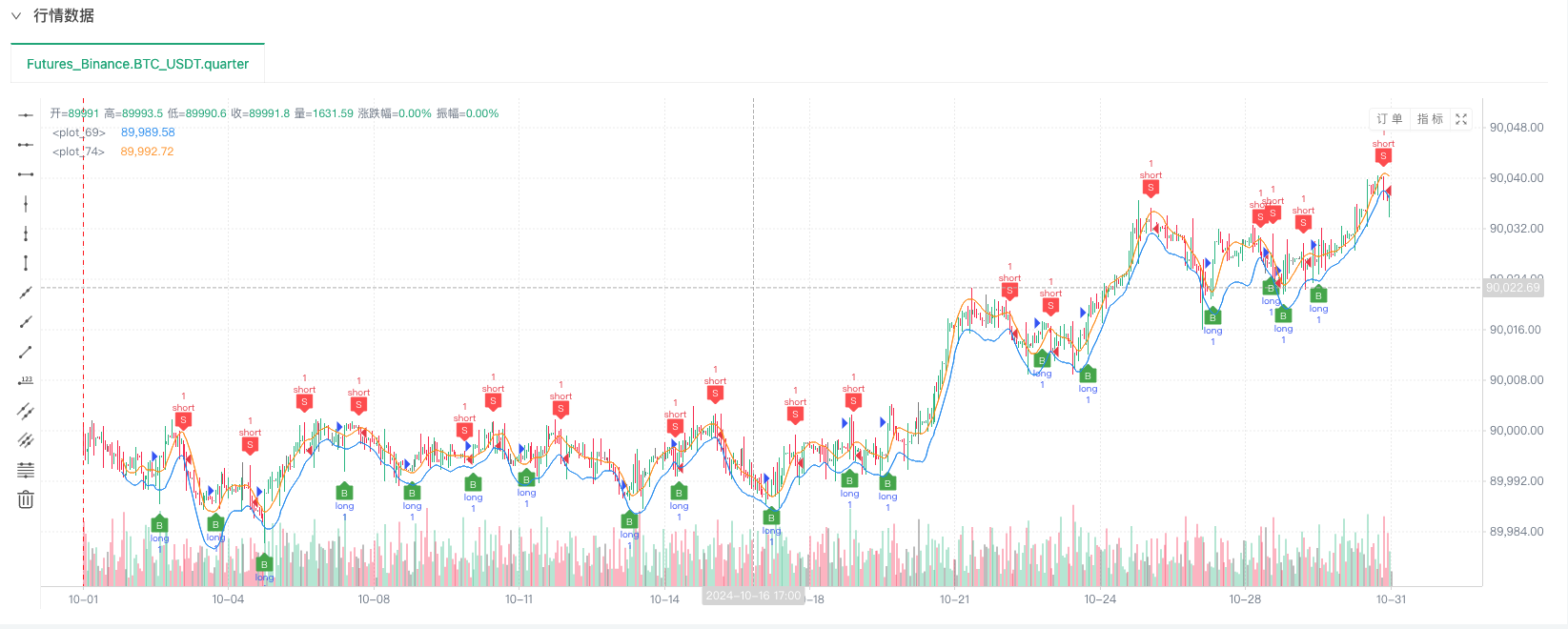
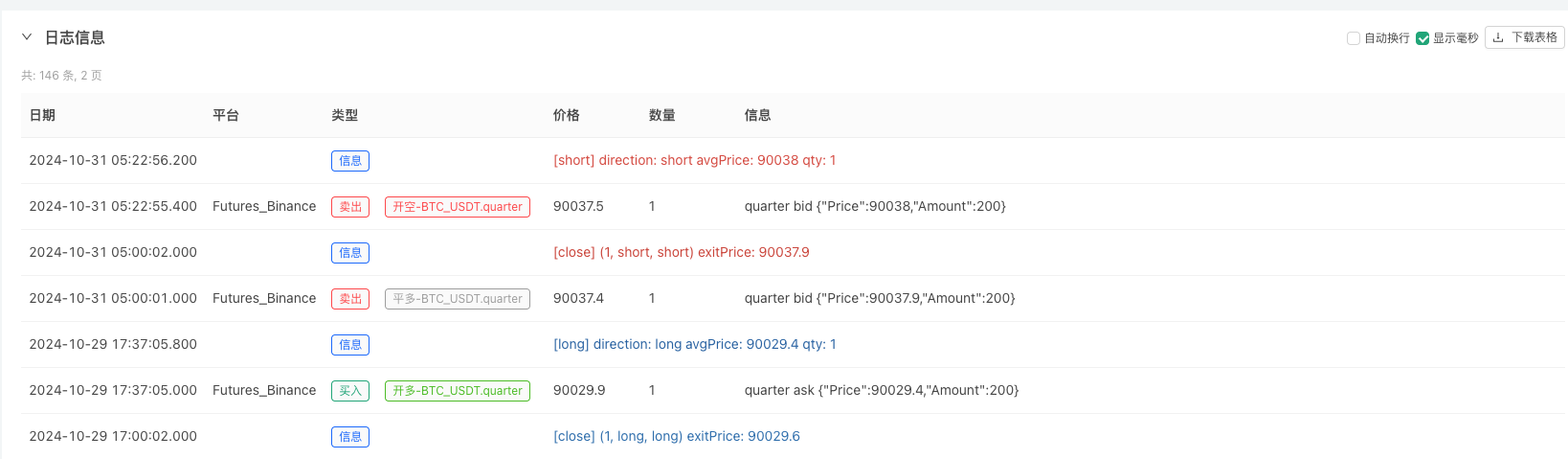
Neste momento, o sistema de retrospecção é testado com dados analógicos de nossa construção de um retrovisor. Com base nos dados do gráfico do mercado no momento do retrospecção, em comparação com os dados do gráfico do mercado gerado aleatoriamente em disco real, o tempo: 16 de outubro de 2024 às 17h00, os dados são os mesmos.
O programa Python para gerador de transações aleatórias cria um disco real para facilitar a demonstração, a operação e a exibição dos dados de linha K gerados.
O código da estratégia:Gerador de transações aleatórias do sistema de detecção
Obrigado pelo apoio e pela leitura.
- Introdução ao conjunto de Lead-Lag na moeda digital (3)
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Introdução ao suporte de Lead-Lag na moeda digital
- Discussão sobre a recepção de sinais externos da plataforma FMZ: API estendida VS estratégia Serviço HTTP integrado
- Exploração da recepção de sinais externos da plataforma FMZ: API de extensão vs estratégia de serviços HTTP embutidos
- Discussão sobre o método de teste de estratégia baseado no gerador de tickers aleatórios
- Novo recurso do FMZ Quant: Use a função _Serve para criar serviços HTTP facilmente
- Inventores quantificam novas funcionalidades: criar serviços HTTP facilmente com a função _Serve
- FMZ Quant Trading Platform Guia de acesso ao protocolo personalizado
- Estratégia de aquisição e acompanhamento da taxa de financiamento da FMZ
- Estratégias de captação e monitoramento de taxas de financiamento da FMZ
- Um modelo de estratégia permite que você use o WebSocket Market sem problemas
- Um modelo de estratégia para usar o WebSocket sem problemas
- Guia de acesso ao Protocolo Geral para Inventores de Plataformas de Negociação Quantificadas
- Como construir uma estratégia de negociação multi-moeda universal rapidamente após a atualização da FMZ
- Como construir rapidamente uma estratégia de negociação multicurrency geral após a atualização do FMZ