Exploração preliminar da aplicação Python Crawler na plataforma FMZ -- rastreando o conteúdo do anúncio da Binance
Autora:FMZ~Lydia, Criado: 2022-12-16 14:32:19, Atualizado: 2024-12-04 21:42:15
Exploração preliminar da aplicação Python Crawler na plataforma FMZ Exploração do conteúdo do Anúncio da Binance
Recentemente, vi que não há informações relevantes sobre os rastreadores Python na comunidade e biblioteca, com base no espírito de desenvolvimento integral do QUANT, aprendi alguns conceitos e conhecimentos relacionados aos rastreadores simplesmente. Após algum entendimento, descobri que o
Demandas
Para aqueles que gostam de subscrever novas ações, eles sempre esperam obter as informações de moeda na casa de câmbio na primeira vez. É obviamente irrealista para as pessoas monitorarem o site da casa de câmbio o tempo todo.
Exploração preliminar
Um programa muito simples é usado para começar (um script de rastreador realmente poderoso é muito mais complexo, então leve seu tempo primeiro). A lógica do programa é muito simples. Ele permite que o programa acesse a página de anúncios da troca constantemente, analise o conteúdo HTML obtido e detecte se o conteúdo do rótulo específico é atualizado.
Código de execução
No entanto, considerando que os requisitos são muito simples, você pode escrever diretamente.
As seguintes bibliotecas Python devem ser utilizadas:
```Bs4```, which can be simply understood as a library used to parse HTML code on web pages.
Code:
Importação do BeautifulSoup Pedidos de importação
UrlBinanceAnnouncement =
def openUrl ((url):
headers = {
def main (():
PreNews_href =
Operação


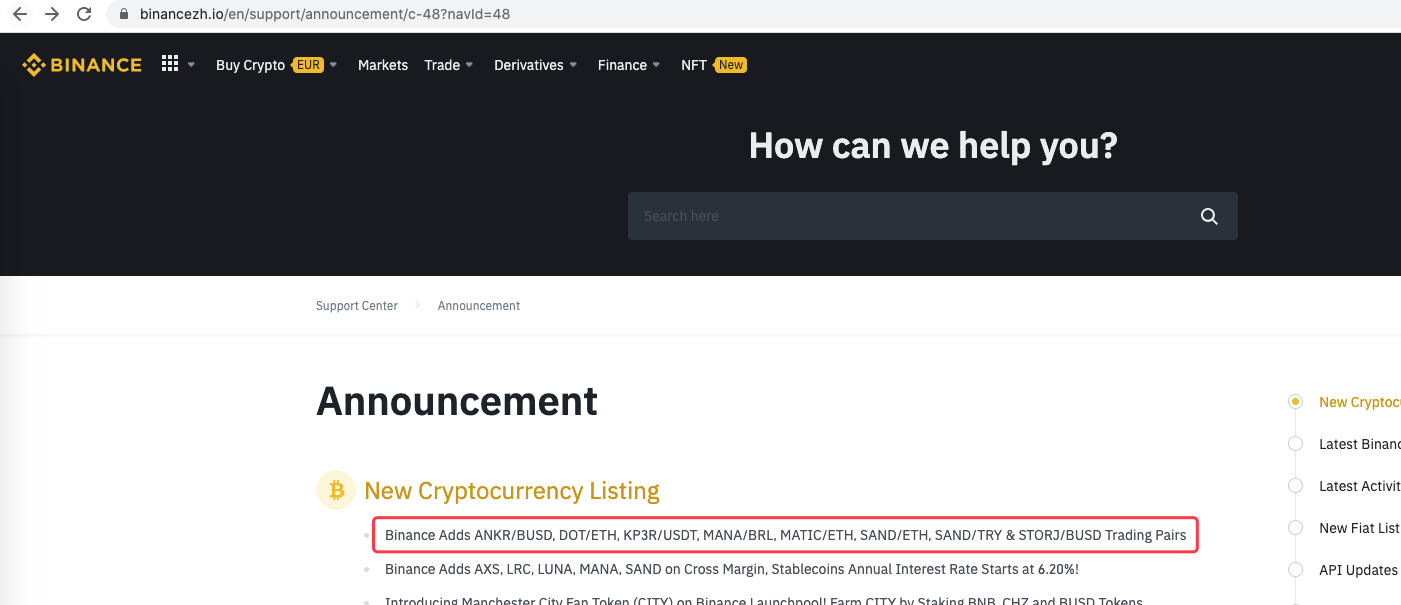
Pode ser estendido, por exemplo, quando um novo anúncio é detectado. Analisar a nova moeda no anúncio e colocar uma ordem automaticamente para subscrever novas ações.
- Prática quantitativa das bolsas DEX (2) -- Guia do utilizador do hiperlíquido
- Práticas de quantificação da DEX Exchange ((2) -- Guia de uso do Hyperliquid
- Prática quantitativa das bolsas DEX (1) -- dYdX v4 Guia do utilizador
- Introdução à arbitragem de lead-lag em criptomoedas (3)
- Práticas de quantificação da DEX exchange ((1) -- dYdX v4 Guia de uso
- Introdução ao conjunto de Lead-Lag na moeda digital (3)
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Estratégia para comprar os vencedores da versão Python
- FMZ Journey -- com estratégia de transição
- Ensinar a transformar uma estratégia Python de uma única espécie em uma estratégia multi-espécie
- Implementar um robô de negociação quantitativa início cronometrado ou parar gadget usando Python
- Oak ensina você a usar o JS para interagir com a API estendida FMZ
- Chame a interface Dingding para realizar mensagem de push do robô
- Estratégia de ordem pendente equilibrada (estratégia de ensino)
- Reflexões sobre a movimentação de ativos através de uma estratégia de cobertura contratual
- Muitos anos mais tarde, você vai descobrir que este artigo é o mais valioso em sua carreira de investimento - descubra de onde vêm os retornos e riscos
- Introdução recente da estratégia oficial de cobrança das FMZ
- Implementação do algoritmo de negociação Dual Thrust usando Mylanguage na plataforma FMZ Quant
- Introdução FAQ para negociação quantitativa de moeda digital
- Outro esquema de estratégia de execução de sinais TradingView
- Use a API estendida na plataforma de negociação FMZ Quant para realizar a negociação de sinais de alerta TradingView
- Módulo de visualização para construir estratégia de negociação - Explicação simples
- Módulo de visualização para construir estratégia de negociação - compreensão avançada
- Módulo de visualização para construir estratégia de negociação - Primeiro conhecimento
- A viagem de desvios de um programador experiente
- Estratégia de equilíbrio de plataforma única da versão Python
- Estratégia de arbitragem de período cruzado de moeda digital baseada na banda de Bollinger