Redes neurais e negociação quantitativa de moeda digital série (2) - Aprendizagem e treinamento intensivos estratégia de negociação Bitcoin
Autora:FMZ~Lydia, Criado: 2023-01-12 16:49:09, Atualizado: 2024-12-19 21:09:28
Redes neurais e negociação quantitativa de moeda digital série (2) - Aprendizagem e treinamento intensivos estratégia de negociação Bitcoin
1. Introdução
No último artigo, introduzimos o uso da rede LSTM para prever o preço do Bitcoin:https://www.fmz.com/bbs-topic/9879Como mencionado no artigo, é apenas um pequeno projeto de treinamento para se familiarizar com RNN e pytorch. Este artigo introduzirá o uso de aprendizagem intensiva para treinar as estratégias de negociação diretamente. O modelo de aprendizagem intensiva é o OpenAI open source PPO, e o ambiente refere-se ao estilo de ginásio. O PPO, ou otimização de política próxima, é uma melhoria de otimização do Gradiente de Política. o gym também foi lançado pela OpenAI. Ele pode interagir com a rede de estratégia e feedback o status e recompensas do ambiente atual. É como a prática de aprendizado intensivo. Ele usa o modelo PPO do LSTM para fazer instruções, como comprar, vender ou não operar diretamente de acordo com as informações do mercado do Bitcoin. O feedback é dado pelo ambiente de backtest. Através de treinamento, o modelo é otimizado continuamente para alcançar a meta de lucro estratégico. A leitura deste artigo requer uma certa base de aprendizagem intensiva em Python, pytorch e DRL. Mas não importa se você não pode. É fácil de aprender e começar com o código dado neste artigo.www.fmz.comBem-vindo ao grupo QQ: 863946592 para comunicação.
2. Referências de dados e de aprendizagem
Dados de preço do Bitcoin provenientes da plataforma de negociação FMZ Quant:https://www.quantinfo.com/Tools/View/4.html- Não. Um artigo usando DRL+gym para treinar estratégias de negociação:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4- Não. Alguns exemplos de como começar com pytorch:https://github.com/yunjey/pytorch-tutorial- Não. Este artigo irá implementar pelo modelo LSTM-PPO diretamente:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py- Não. Artigos sobre PPO:https://zhuanlan.zhihu.com/p/38185553- Não. Mais artigos sobre DRL:https://www.zhihu.com/people/flood-sung/posts- Não. Sobre o ginásio, este artigo não requer instalação, mas é muito comum na aprendizagem intensiva:https://gym.openai.com/.
3. LSTM-PPO
Para uma explicação aprofundada do PPO, você pode aprender com os materiais de referência anteriores. Aqui está apenas uma introdução simples aos conceitos. A última edição da rede LSTM apenas previu o preço. Como comprar e vender com base no preço previsto terá que ser realizado separadamente. É natural pensar que a saída direta da ação de negociação será mais direta. Este é o caso do Gradiente de Política, que pode dar a probabilidade de várias ações de acordo com a informação do ambiente de entrada s. A perda de LSTM é a diferença entre o preço previsto e o preço real, enquanto a perda de PG é - log § * Q, onde p é a probabilidade de uma ação de saída, e Q é o valor da ação (como pontuação de recompensa intuitiva). A explicação é que se o valor de uma ação for maior, a rede deve ser uma chave para reduzir a perda. Embora o PPO seja mais complexo, o seu princípio é muito mais similar.
O código fonte do LSTM-PPO é apresentado abaixo, que pode ser entendido em combinação com os dados anteriores:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Ambiente de backtesting do Bitcoin
Seguindo o formato do ginásio, há um método de inicialização de reinicialização. Step insere a ação e o resultado retornado é (próximo status, renda da ação, se terminar, informações adicionais). Todo o ambiente de backtest também é de 60 linhas. Você pode modificar versões mais complexas por si mesmo. O código específico é:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Vários detalhes dignos de nota
- Porque é que a conta inicial tem moeda?
A fórmula para calcular o retorno do ambiente de backtest é: retorno atual = valor da conta corrente - valor atual da conta inicial. Isso significa que se o preço do Bitcoin diminui e a estratégia faz uma operação de venda de moedas, mesmo que o valor total da conta diminua, a estratégia deve realmente ser recompensada. Se o backtest levar muito tempo, a conta inicial pode ter pouco impacto, mas terá um grande impacto no início. O cálculo do retorno relativo garante que cada operação correta obtenha uma recompensa positiva.
- Por que o mercado foi amostrado durante a formação?
A quantidade total de dados é de mais de 10.000 K-linhas. Se você executar um loop no total toda vez, levará muito tempo, e a estratégia enfrenta a mesma situação toda vez, pode ser mais fácil de overfit.
- E se não houver moeda ou dinheiro?
Esta situação não é considerada no ambiente de backtest. Se a moeda foi vendida ou a quantidade mínima de negociação não pode ser alcançada, então a operação de venda é equivalente à não operação na verdade. Se o preço diminui, de acordo com o método de cálculo do retorno relativo, ele ainda é baseado no retorno estratégico positivo. O impacto desta situação é que quando a estratégia julga que o mercado está diminuindo e a moeda restante da conta não pode ser vendida, é impossível distinguir a ação de venda da ação não operativa, mas não tem impacto no julgamento da própria estratégia no mercado.
- Por que devo devolver as informações da conta como status?
O modelo PPO tem uma rede de valor para avaliar o valor do status atual. Obviamente, se a estratégia julgar que o preço aumentará, todo o status terá valor positivo apenas quando a conta corrente detém Bitcoin e vice-versa. Portanto, as informações da conta são uma base importante para o julgamento da rede de valor.
- Quando voltará a não operar?
Quando a estratégia julga que os retornos trazidos pela transação não podem cobrir a taxa de manipulação, ela deve voltar a não operação. Embora a descrição anterior use estratégias repetidamente para julgar a tendência de preços, é apenas para a conveniência de compreensão. Na verdade, este modelo PPO não prevê o mercado, mas apenas produz a probabilidade de três ações.
6. Aquisição e formação de dados
Como no artigo anterior, o método e o formato de aquisição de dados são os seguintes: linha K do período de uma hora do par de negociação BTC_USD da Bitfinex Exchange de 7 de maio de 2018 a 27 de junho de 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Devido ao uso da rede LSTM, o tempo de treinamento é muito longo. Mudei para uma versão GPU, que é cerca de três vezes mais rápida.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Resultados e análise da formação
Depois de uma longa espera:

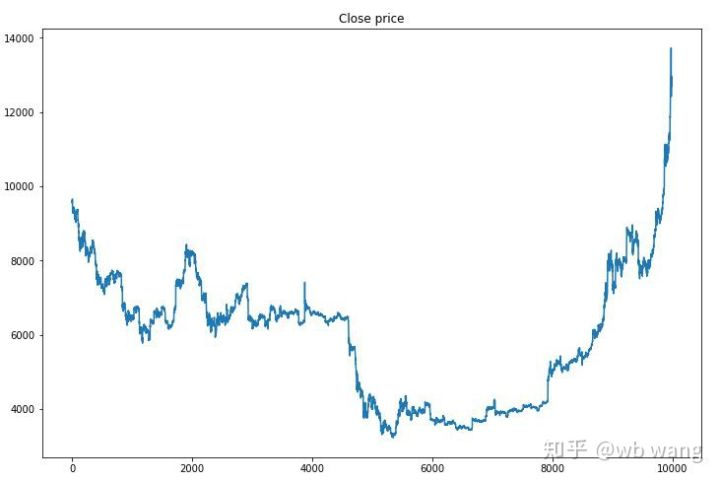
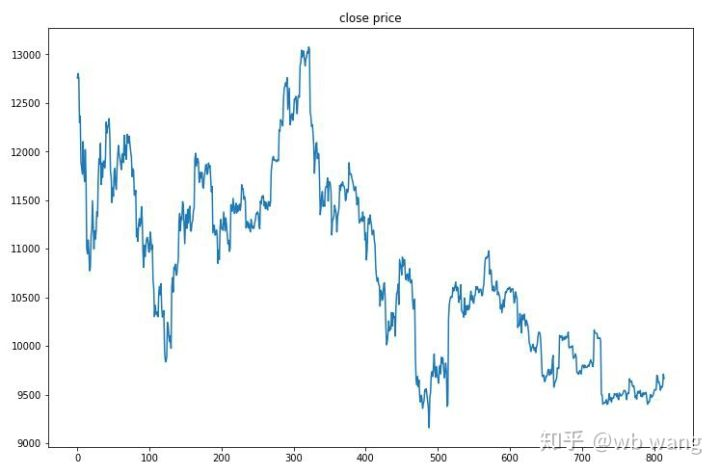
Em primeiro lugar, olhem para o mercado dos dados de formação: em geral, a primeira metade é um declínio de longa duração e a segunda metade é uma forte recuperação.
No início do treinamento, há muitas operações de compra, e basicamente não há uma rodada lucrativa.
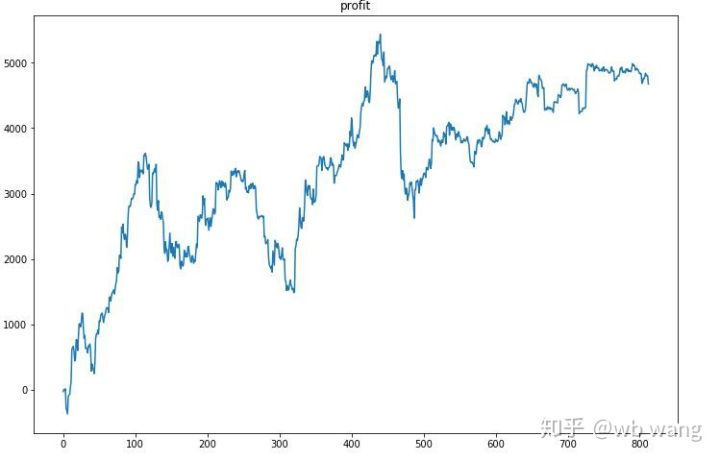
Limpa o lucro de cada rodada, e o resultado é o seguinte:
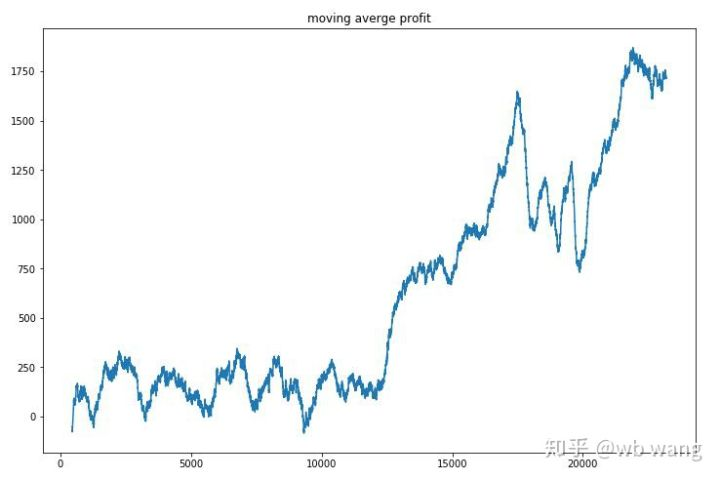
A estratégia rapidamente se livrou da situação de que o retorno inicial era negativo, mas a flutuação era grande.
Após o treinamento final, deixe o modelo executar todos os dados novamente para ver como ele funciona. Durante o período, registre o valor total de mercado da conta, o número de Bitcoins mantidos, a proporção do valor do Bitcoin e os retornos totais. Primeiro é o valor total de mercado, e os retornos totais são semelhantes a ele, eles não serão postados:
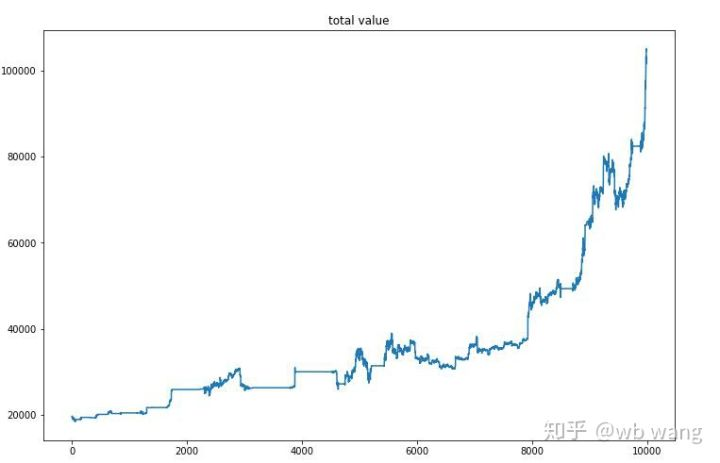
O valor total de mercado aumentou lentamente no início do mercado de baixa, e manteve-se com o aumento no mercado de alta posterior, mas ainda houve perdas periódicas.
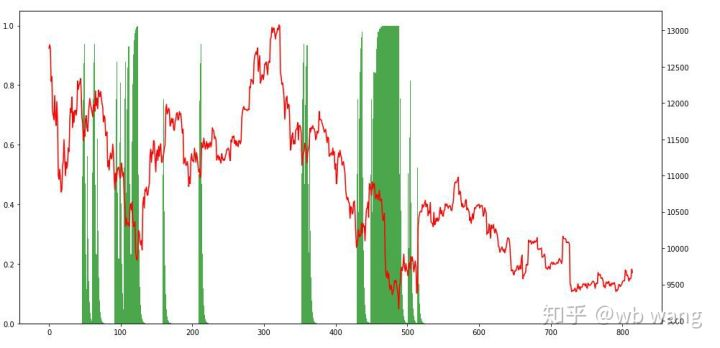
Por fim, dê uma olhada na proporção de posições. O eixo esquerdo do gráfico é a proporção de posições e o eixo direito é o mercado. Pode-se julgar preliminarmente que o modelo está sobreajustado. A frequência de posições é baixa no início do mercado de baixa e alta na parte inferior do mercado.
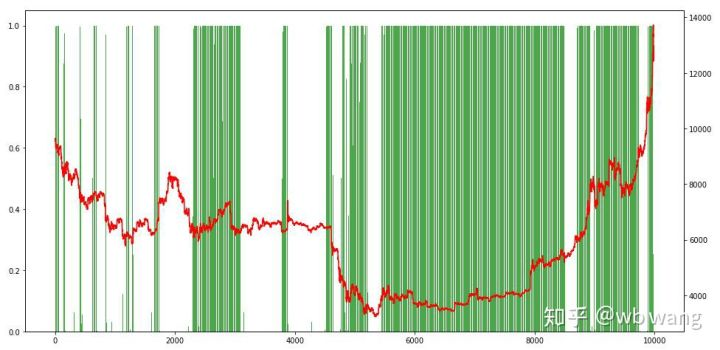
8. Análise dos dados do ensaio
O mercado de uma hora do Bitcoin de 27 de junho de 2019 até agora foi obtido a partir dos dados do teste. Pode-se ver no gráfico que o preço caiu de US $ 13.000 para mais de US $ 9.000, o que é um grande teste para o modelo.
Em primeiro lugar, o retorno relativo final realizou assim, mas não houve perda.
Olhando para a situação da posição, podemos adivinhar que o modelo tende a comprar após uma queda acentuada e vender após uma recuperação.
9. Resumo
Neste artigo, um robô de negociação automática Bitcoin é treinado com a ajuda de PPO, um método de aprendizado intensivo profundo, e algumas conclusões são obtidas. Devido ao tempo limitado, ainda há alguns aspectos a serem melhorados no modelo. Bem-vindo à discussão. A maior lição é que para o método de padronização de dados, não use escalagem e outros métodos, caso contrário, o modelo vai lembrar rapidamente a relação entre preço e mercado, e cair em sobreajuste. A taxa de mudança padronizada é os dados relativos, o que dificulta o modelo lembrar a relação com o mercado, e é forçado a encontrar a relação entre a taxa de mudança e o aumento e diminuição.
Introdução a artigos anteriores: Uma estratégia de alta frequência que eu revelei que já foi muito rentável:https://www.fmz.com/bbs-topic/9886.
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Introdução ao suporte de Lead-Lag na moeda digital
- Discussão sobre a recepção de sinais externos da plataforma FMZ: API estendida VS estratégia Serviço HTTP integrado
- Exploração da recepção de sinais externos da plataforma FMZ: API de extensão vs estratégia de serviços HTTP embutidos
- Discussão sobre o método de teste de estratégia baseado no gerador de tickers aleatórios
- Métodos de teste de estratégias baseados em geradores de mercado aleatórios
- Novo recurso do FMZ Quant: Use a função _Serve para criar serviços HTTP facilmente
- Três modelos potenciais de negociação quantitativa
- Sistema de negociação intradiário de ponto pivô
- 6 estratégias e práticas simples para iniciantes em negociação quantitativa de moeda digital
- Quadro estratégico do intervalo verdadeiro médio
- Prática e aplicação da estratégia do termostato na plataforma FMZ Quant
- Estratégia de negociação baseada na teoria da caixa, apoiando futuros de commodities e moeda digital
- Estratégia quantitativa de negociação baseada no preço
- Estratégia quantitativa de negociação utilizando um índice ponderado pelo volume de negociação
- Implementação e aplicação da estratégia de negociação PBX na plataforma de negociação FMZ Quant
- Compartilhamento tardio: Bitcoin robô de alta frequência com 5% de retornos diários em 2014
- Redes Neurais e Currency Digital Quantitative Trading Series (1) - LSTM Prevê o preço do Bitcoin
- Aplicação da estratégia combinada do índice de força relativa da SMA e do índice de força relativa do RSI
- Desenvolvimento da estratégia CTA e da biblioteca de classes padrão da plataforma FMZ Quant
- Estratégia de negociação quantitativa com análise de dinâmica de preços em Python
- Implementar uma estratégia de negociação quantitativa de moeda digital de duplo impulso em Python
- A melhor maneira de instalar e atualizar para Linux docker
- Realização de estratégias equitativas equilibradas de posições longas-cortas com um alinhamento ordenado
- Análise de dados de séries temporais e backtesting de dados de tiques
- Análise Quantitativa do Mercado de Moeda Digital
- Negociação em pares baseada em tecnologia baseada em dados