Преимущества и недостатки шести алгоритмов машинного обучения
Автор:Изобретатели количественного измерения - мечты, Создано: 2017-10-30 12:01:59, Обновлено: 2017-11-08 13:55:03Преимущества и недостатки шести алгоритмов машинного обучения
В машинном обучении целью является либо предсказание, либо кластеризация. Основное внимание в данной статье сосредоточено на прогнозировании. Прогнозирование - это процесс предсказания значения выходной переменной из набора входных переменных. Например, получив набор характеристик, относящихся к дому, мы можем предсказать его цену продажи. С учетом этого, давайте посмотрим на наиболее популярные и часто используемые алгоритмы в машинном обучении. Мы разделили их на три категории: линейные модели, модели на основе деревьев и нейронные сети.
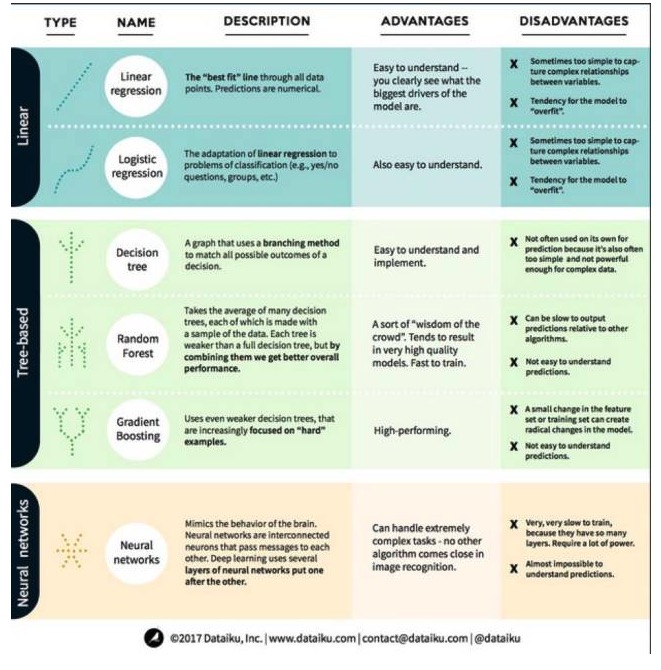
Линейные модели используют простые формулы, чтобы найти строку, которая лучше всего подходит для параметров, через набор точек данных. Этот метод датируется более чем 200 годами и широко используется в области статистики и машинного обучения. Он полезен для статистики из-за своей простоты.
- #### 1. Линейная регрессия
Линейная регрессия, или, точнее, рефракционная регрессия с минимальным двукратным возвратом, является наиболее стандартной формой линейной модели. Для регрессионных проблем линейная регрессия является наиболее простой линейной моделью. Недостатком является то, что модель легко перенастраивается, то есть модель полностью адаптируется к обученным данным, в ущерб способности распространяться на новые данные. Таким образом, линейная регрессия в машинном обучении (и логическая регрессия, о которой мы поговорим далее) обычно является рефракционной, что означает, что модель имеет определенное наказание, чтобы предотвратить перенастраивание.
Еще один недостаток линейных моделей заключается в том, что, поскольку они очень просты, они не могут предсказывать более сложное поведение, когда входные переменные не являются независимыми.
- #### 2. Логическая регрессия
Логическая регрессия - это адаптация линейной регрессии к классификационным проблемам. Логическая регрессия имеет те же недостатки, что и линейная регрессия. Логические функции очень хороши для классификационных проблем, поскольку они вводят эффект порога.
Второй - алгоритм деревянной модели.
- ###############################################################################################################################################################################################################################################################
Дерево решения представляет собой изображение каждого возможного результата решения с использованием разветвления. Например, вы решили заказать салат, и ваше первое решение может быть разновидностью сырых овощей, затем соусов, а затем разновидностью салатных овощей. Мы можем представить все возможные результаты в дереве решения.
Для обучения дерева мы должны использовать тренировочный набор данных и выяснить, какое свойство является наиболее полезным для цели. Например, в случае использования для обнаружения мошенничества мы можем обнаружить, что наиболее влияющее на прогнозирование риска мошенничества свойство - страна. После разделения на первое свойство мы получаем два подмножества, которые наиболее точно предсказуются, если мы знаем только первое свойство. Затем мы выясняем, какое второе лучшее свойство можно разделить на эти два подмножества, используем разделение снова, и так далее, пока не будет достаточное количество свойств, чтобы удовлетворить потребности цели.
- ##### 2#########################################################################################################################################################################################################################################################
Случайный лес - это средний из многих решений деревьев, каждое из которых тренируется с помощью случайных образцов данных. Каждое дерево в случайном лесу слабее, чем целостное решение дерева, но если собрать все деревья вместе, мы можем получить лучшую общую производительность из-за преимуществ разнообразия.
Random Forests - очень популярный алгоритм в современном машинном обучении. Random Forests легко обучаются и работают довольно хорошо. Его недостаток заключается в том, что Random Forests могут быть медленными по сравнению с другими алгоритмами, поэтому они могут не выбирать Random Forests, когда требуется быстрое предсказание.
- #### 3, подъем
Градиент-бустинг, как и случайный лес, состоит из слаборазвитых деревьев решения. Основное отличие от случайного леса заключается в том, что деревья тренируются один за другим. Каждое последующее дерево обучается в основном тому, что дерево впереди распознает неправильные данные.
Тренировка повышения градиента также быстрая и хорошо работает. Однако небольшие изменения в тренировочном наборе данных могут привести к фундаментальным изменениям в модели, поэтому результаты, которые она дает, могут быть не самыми практичными.
Третье, алгоритм нейронной сети: нейронная сеть - это биологическое явление, в котором нейроны в головном мозге взаимодействуют друг с другом, обмениваясь информацией. Эта идея теперь применяется к области машинного обучения, и называется ANN (искусственная нейронная сеть). Глубокое обучение - это сложные нейронные сети, которые накладываются друг на друга.
Переведено с сайта Big Data Plateau
- Изобретатели количественно поддерживают криптовалютные сделки на Huobi и OKEX, а также USDT?
- Публичная функция сбора, интегрированная в библиотеку цифровых валют
- Как вычислить максимальный потенциал финансирования стратегии с помощью количественных данных о возврате, волатильности и т.д.?
- Демон Шеннон
- Сложнее не технология, а человеческий разум! Трейдинговые способности должны соответствовать системе.
- Как вы думаете, где можно разместить сервер, если интерфейс Bitfinex медленный?
- Bitfinex работает неправильно, помогите проанализировать, спасибо
- На какой точке времени были получены данные при вызове API при повторном поиске?
- Попросите код для биткоина.
- Почему на Bitfinex есть только четыре пары для торговли: BCH_USD, BTC_USD, ETH_USD и LTC_USD?
- Популярные игровые автоматы, в том числе и в Китае, выставляют на продажу новые игровые автоматы, которые будут продаваться в разных странах.
- Механизм последнего наблюдения
- Сообщение о ошибке: Не удалось сохранить интерактивную кнопку без параметров по умолчанию при создании политики
- Не могли бы вы выбрать другие валюты?
- Пожалуйста, переведите страницу плана покупки.
- У bitfinex есть три рынка, как заставить робота выбирать?
- Возможности в динамической перспективе выигрывают вместе
- Bitfinex переоценивает и проверяет валютные единицы не совпадают
- Как вы относитесь к эффективности отступничества и золотой вилки?
- Bithumb получил ошибочную информацию об аккаунте