Исследование методов тестирования стратегии на основе генератора случайных рынков
Автор:Изобретатели количественного измерения - мечты, Создано: 2024-11-29 16:35:44, Обновлено: 2024-12-02 09:12:43[TOC]

Преамбула
Изобретатели квантовой торговой платформы имеют систему обратной проверки, которая постоянно обновляется и обновляется, постепенно увеличивая функциональность и оптимизируя производительность. По мере развития платформы система обратной проверки будет постоянно оптимизироваться. Сегодня мы рассмотрим тему, основанную на системе обратной проверки: "Стратегическое тестирование на основе случайного рынка".
Потребность
В области количественной торговли разработка и оптимизация стратегии неотделимы от проверки реальных рыночных данных. Однако в практическом применении, из-за сложности и многообразия рыночной среды, может быть недостаточное использование исторических данных для повторного анализа, например, отсутствие охвата крайних рынков или особых сценариев. Поэтому разработка эффективного генератора случайного движения является эффективным инструментом для разработчиков количественной стратегии.
Когда нам нужно, чтобы стратегия отслеживала исторические данные на какой-либо бирже или валюте, мы можем использовать официальные источники данных на платформе FMZ для повторной проверки. Иногда мы хотим увидеть, как стратегия будет выглядеть на совершенно незнакомом рынке.
Использование случайных данных о рынке означает:
-
- Оценка эффективности стратегии Генераторы случайных рынков могут создавать различные возможные рыночные сценарии, включая экстремальные, низкие, тенденционные и волатильные рынки. Испытание стратегии в этих аналогичных условиях может помочь оценить ее стабильность в различных рыночных условиях.
Может ли стратегия адаптироваться к трендам и колебаниям? Как вы думаете, может ли стратегия привести к значительным потерям на экстремальных рынках?
-
- Идентификация потенциальных недостатков стратегии Моделируя некоторые необычные рыночные ситуации (например, предполагаемые события черного цыпленка), можно обнаружить потенциальные слабости стратегии и улучшить их.
Может ли стратегия чрезмерно зависеть от определенной структуры рынка? Существует ли риск того, что параметры будут перенастроены?
-
- Оптимизация параметров стратегии Данные, генерируемые случайным образом, обеспечивают более разнообразную тестовую среду для настройки параметров стратегии без необходимости полностью полагаться на исторические данные. Это позволяет найти более полный диапазон параметров стратегии, избегая ограничения конкретными рыночными моделями в исторических данных.
-
- Недостаток исторических данных В некоторых рынках (например, в развивающихся или небольших валютных рынках) исторических данных может быть недостаточно, чтобы охватить все возможные рыночные условия. Генераторы случайных рынков могут предоставить большое количество дополнительных данных, которые помогут провести более полное тестирование.
-
- Быстрая иерархия Быстрое тестирование с помощью рандомизированных данных позволяет ускорить ипотеку разработки стратегии без необходимости полагаться на реальные рыночные рынки или трудоемкую очистку и уборку данных.
Однако также необходима рациональная стратегия оценки, и для случайных данных о рынке следует иметь в виду следующее:
- 1, Хотя генерирование случайных транзакций полезно, их значение зависит от качества генерируемых данных и дизайна целевых сценариев:
- 2) генерирующая логика должна быть близкой к реальному рынку: если произвольно генерируемые рынки полностью отрываются от реальности, результаты тестирования могут не иметь базовых значений. Например, генератор может быть разработан в сочетании с фактическими статистическими характеристиками рынка (например, распределение волатильности, соотношение тенденций).
- 3) Не может полностью заменить тестирование реальных данных: случайные данные могут только дополнять разработку и оптимизацию стратегии, и в конечном итоге стратегия все еще должна быть проверена на реальных данных рынка.
Как мы можем легко, быстро и легко создавать информацию, которая будет использоваться в системе обратной связи?
Идеи дизайна
Эта статья предназначена для того, чтобы дать более простые методы вычисления, но в действительности существует множество различных методов, таких как алгоритмы и модели данных, которые могут быть использованы без использования особенно сложных методов моделирования данных.
В сочетании с возможностью настройки источников данных в системе рецензирования платформы, мы написали программу на языке Python.
- 1, произвольно создать набор K-линий данных, записанных в CSV-файл, чтобы сохранить данные.
- 2, затем создать сервис для поддержки источников данных системы обратной связи.
- 3 ∞ Получаемые данные K-линий отображаются на графике.
Для некоторых стандартов генерации K-линейных данных, файлового хранения и т. д. можно определить следующие параметровые управления:
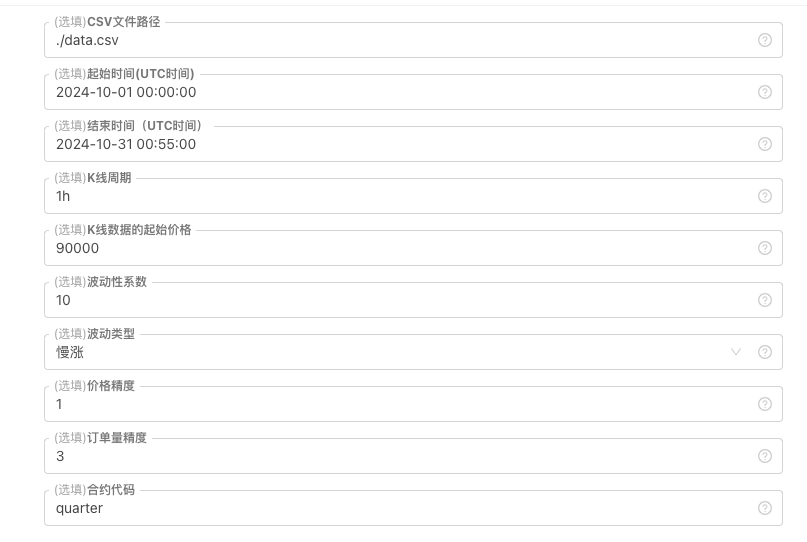
-
Схема произвольного генерирования данных Для типа колебаний аналоговых данных K-линий простое использование случайных чисел с отрицательными вероятностными значениями может не отражать нужную модель поведения, когда генерируемых данных мало. Если есть лучший способ, то эту часть кода можно заменить. Основываясь на такой простой конструкции, корректировка диапазона генерирования случайных чисел в коде и некоторых коэффициентов может повлиять на эффект генерируемых данных.
-
Проверка данных Для генерируемых данных K-линии также требуется проверка рациональности, чтобы проверить, не противоречит ли цена за высокую или низкую цену определению, чтобы проверить преемственность данных K-линии и т. д.
Система отслеживания генерирует случайные действия
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Практика в системе рецензирования
1, создать примеры вышеперечисленных стратегий, настроить параметры и запустить. 2, Диск (политический пример) должен работать на хостере, развернутом на сервере, поскольку для получения данных требуется наличие общедоступного IP-адреса, доступ к которому может быть получен системой обратной связи. Нажмите на кнопку "Интеракция", и стратегия автоматически начнет генерировать данные о случайных рынках.

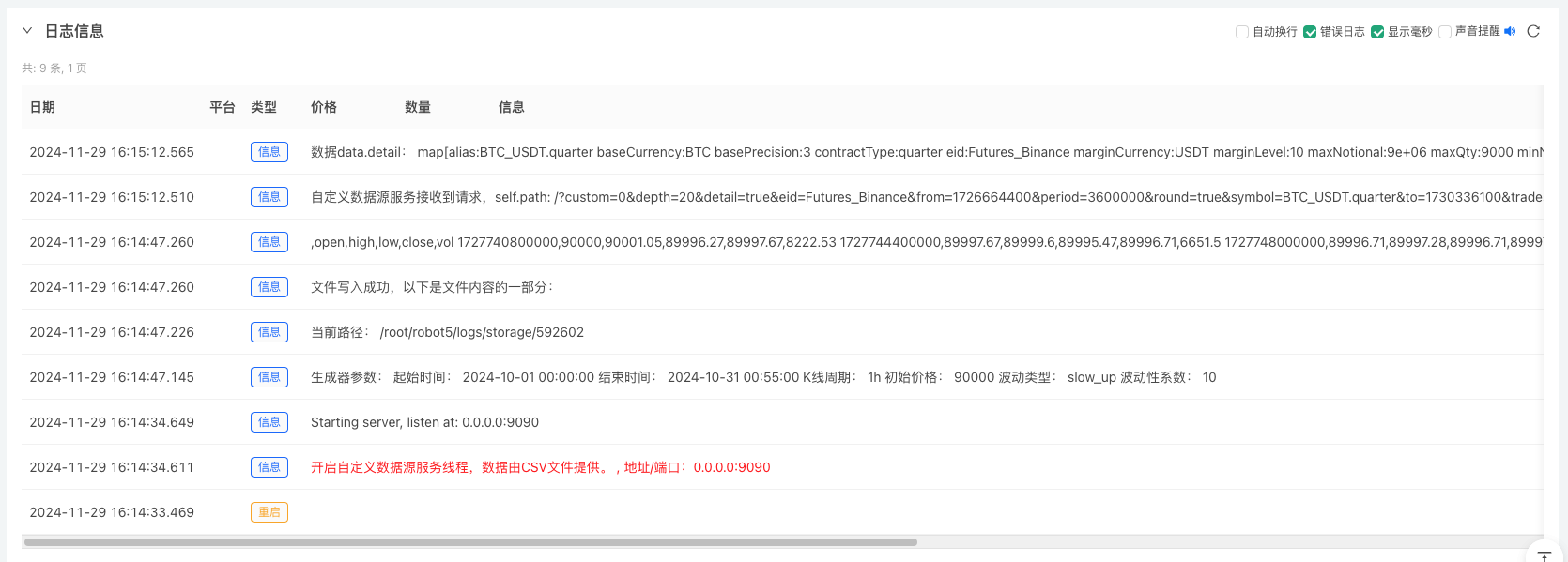
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
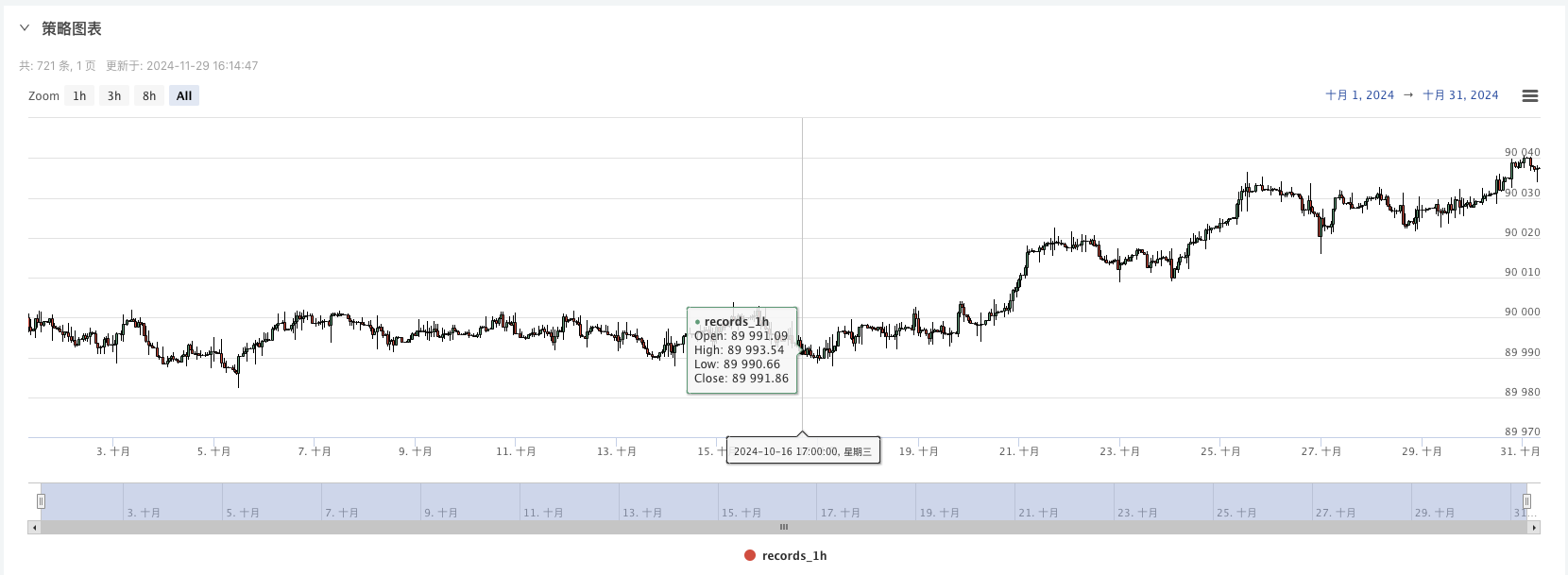
И мы можем использовать эти случайные данные, и мы можем использовать эту стратегию для повторного анализа.
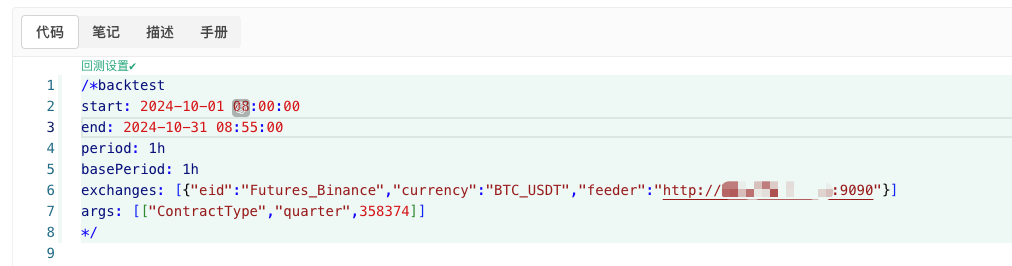
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
В соответствии с этой информацией, конфигурация должна быть изменена.http://xxx.xxx.xxx.xxx:9090Это IP-адрес сервера и открытый порт, на котором произвольно генерируется политика диска.
Это и есть настраиваемый источник данных, который можно узнать в разделе настраиваемых источников данных в документации API платформы.
6, с помощью системы обратной проверки можно проверить случайные данные.
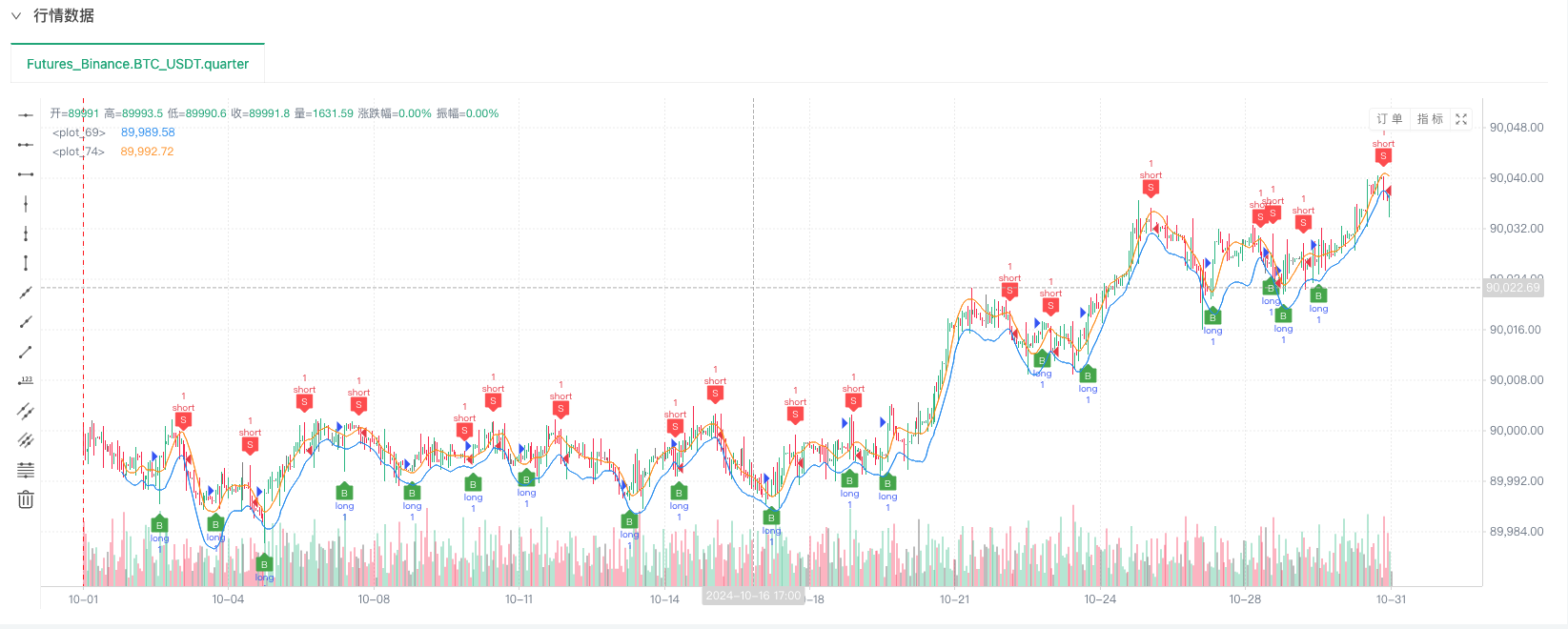
На данный момент система обратной проверки проводится с использованием аналогичных данных, которые мы создали для обратной проверки. Согласно данным, представленным на графике рынка, на момент обратной проверки, данные сравниваются с данными, представленными на графике рынка, созданном на реальной основе, время: 16 октября 2024 года в 17:00, данные одинаковые.
О, да, я почти забыл! Python-программа с произвольным генератором действий создает реальный диск для демонстрации, обработки и отображения генерируемых K-линий данных.
Источник стратегии:Система отслеживания генерирует случайные действия
Спасибо за поддержку и чтение.
- Презентация о своде Lead-Lag в цифровой валюте (3)
- Введение в арбитраж с задержкой свинца в криптовалюте (2)
- Презентация о своде Lead-Lag в цифровой валюте (2)
- Обсуждение по внешнему приему сигналов платформы FMZ: полное решение для приема сигналов с встроенным сервисом Http в стратегии
- Обзор приема внешних сигналов на платформе FMZ: стратегию полного решения приема сигналов встроенного сервиса HTTP
- Введение в арбитраж с задержкой свинца в криптовалюте (1)
- Введение Lead-Lag в цифровой валюте (1)
- Дискуссия по внешнему приему сигнала платформы FMZ: расширенный API VS стратегия встроенного HTTP-сервиса
- Обзор FMZ-платформы для получения внешних сигналов: расширение API против стратегии встроенного HTTP-сервиса
- Обсуждение метода тестирования стратегии на основе генератора случайных тикеров
- Новая функция FMZ Quant: Используйте функцию _Serve для простого создания HTTP-сервисов
- Изобретатели количественно увеличили новые возможности: легко создать HTTP-сервисы с помощью функции _Serve
- FMZ Quant Trading Platform Руководство по доступу к пользовательскому протоколу
- Стратегия приобретения и мониторинга ставки финансирования FMZ
- Стратегия получения и мониторинга FMZ
- Шаблон стратегии позволяет беспрепятственно использовать WebSocket Market
- Схема политики, которая позволяет беспрепятственно использовать веб-сокет
- Инвесторы по количественной торговле
- Как построить универсальную стратегию многовалютной торговли быстро после обновления FMZ
- Как быстрее построить универсальную стратегию многовалютных сделок после модернизации FMZ