Обсуждение метода тестирования стратегии на основе генератора случайных тикеров
Автор:FMZ~Lydia, Создано: 2024-12-02 11:26:13, Обновлено: 2024-12-02 21:39:39
Преамбула
Система бэкстестинга FMZ Quant Trading Platform - это система бэкстестинга, которая постоянно итерация, обновление и обновление. Она добавляет функции и оптимизирует производительность постепенно от первоначальной базовой функции бэкстестинга. С развитием платформы, система бэкстестинга будет продолжать оптимизироваться и обновляться. Сегодня мы обсудим тему, основанную на системе бэкстестинга:
Спрос
В области количественной торговли разработка и оптимизация стратегий не могут быть отделены от проверки реальных рыночных данных. Однако в реальных приложениях из-за сложной и меняющейся рыночной среды может быть недостаточно полагаться на исторические данные для обратного тестирования, например, отсутствие охвата экстремальных рыночных условий или специальных сценариев. Поэтому разработка эффективного генератора случайного рынка стала эффективным инструментом для разработчиков количественной стратегии.
Когда нам нужно, чтобы стратегия отслеживала исторические данные на определенной бирже или валюте, мы можем использовать официальный источник данных платформы FMZ для обратного тестирования.
Значение использования данных случайного тикера заключается в следующем:
-
- Оценка надежности стратегий Генератор случайных тикеров может создавать различные возможные сценарии рынка, включая экстремальную волатильность, низкую волатильность, трендовые рынки и волатильные рынки.
Может ли стратегия адаптироваться к изменению тренда и волатильности? При экстремальных рыночных условиях стратегия понесет большие убытки?
-
- Выявление потенциальных недостатков в стратегии Симулируя некоторые ненормальные рыночные ситуации (например, гипотетические события черного лебедя), можно обнаружить и улучшить потенциальные слабости в стратегии.
Опирается ли стратегия слишком сильно на определенную структуру рынка? Существует ли риск перенастройки параметров?
-
- Оптимизация параметров стратегии Случайные данные обеспечивают более разнообразную среду тестирования для оптимизации параметров стратегии, не полагаясь полностью на исторические данные.
-
- Заполнение пробела в исторических данных На некоторых рынках (например, на развивающихся рынках или на рынках торговли небольшими валютами) исторических данных может быть недостаточно, чтобы охватить все возможные рыночные условия.
-
- Быстрая итеративная разработка Использование случайных данных для быстрого тестирования может ускорить итерацию разработки стратегии, не полагаясь на рыночные условия в режиме реального времени или на трудоемкую очистку и организацию данных.
Однако также необходимо рационально оценивать стратегию.
-
- Хотя случайные генераторы рынка полезны, их значимость зависит от качества полученных данных и дизайна целевого сценария:
-
- Логика генерации должна быть близка к реальному рынку: если случайный рынок полностью не соответствует действительности, результаты испытаний могут не иметь справочной ценности.
-
- Он не может полностью заменить тестирование реальных данных: случайные данные могут только дополнить разработку и оптимизацию стратегий.
Сказав так много, как мы можем "фабриковать" некоторые данные? Как мы можем "фабриковать" данные для системы обратного тестирования для удобного, быстрого и легкого использования?
Идеи дизайна
Эта статья предназначена для того, чтобы стать отправной точкой для обсуждения и предоставить относительно простой вычисление генерации случайных тикеров. На самом деле, существует множество алгоритмов моделирования, моделей данных и других технологий, которые могут быть применены. Из-за ограниченного пространства обсуждения мы не будем использовать сложные методы моделирования данных.
Объединив функцию источника данных платформы, мы написали программу на Python.
-
- Сгенерируйте набор данных K-линии случайным образом и запишите их в файл CSV для постоянной записи, чтобы генерируемые данные могли быть сохранены.
-
- Затем создать сервис для обеспечения поддержки источника данных для системы обратного тестирования.
-
- Отобразить полученные данные K-линии на диаграмме.
Для некоторых стандартов генерации и хранения файлов данных K-линии могут быть определены следующие параметры управления:
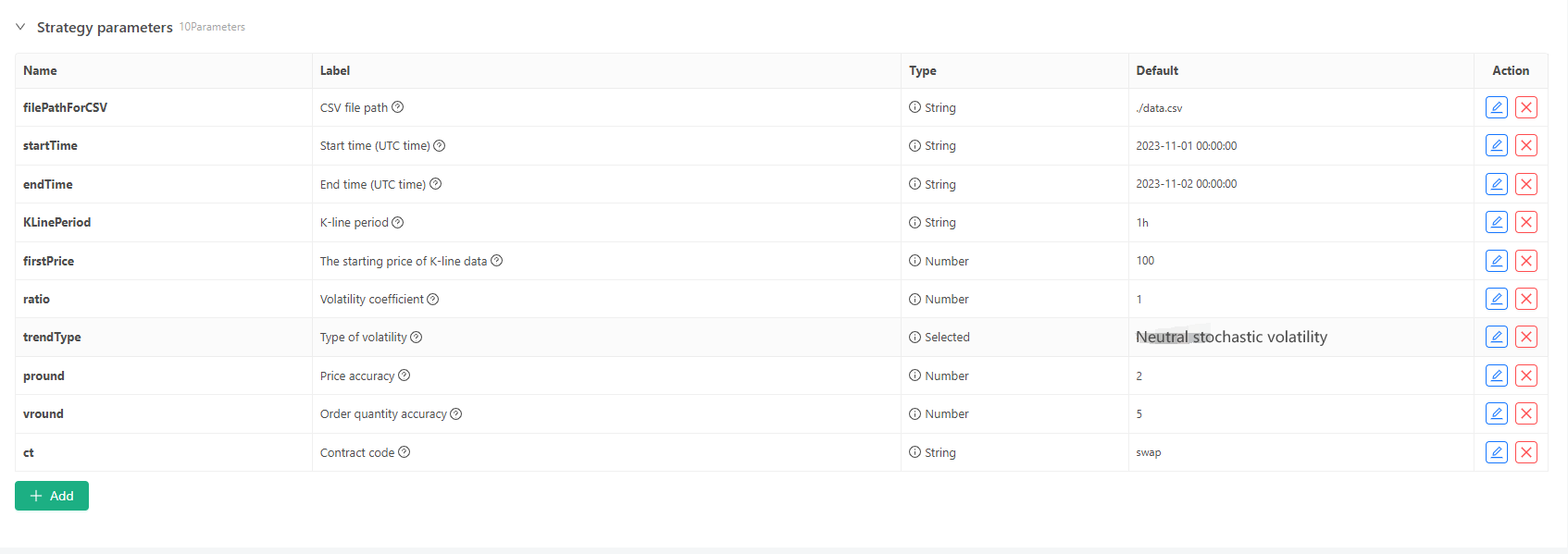
-
Режим создания случайных данных Для моделирования типа флуктуации данных K-линии простую конструкцию просто делают с использованием вероятности положительных и отрицательных случайных чисел. Основываясь на этой простой конструкции, корректировка диапазона генерации случайных чисел и некоторых коэффициентов в коде может повлиять на эффект генерируемых данных.
-
Проверка данных Созданные данные K-линии также должны быть проверены на рациональность, чтобы проверить, нарушают ли высокие цены открытия и низкие цены закрытия определение, и проверить непрерывность данных K-линии.
Система обратного тестирования генератор случайных тикеров
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Практика в системе обратного тестирования
- Создать вышеуказанный экземпляр стратегии, настроить параметры и запустить его.
- Торговля в режиме реального времени (инстанция стратегии) должна выполняться на докере, развернутом на сервере, ей нужен IP-адрес публичной сети, чтобы система бэкстестинга могла получить к ней доступ и получить данные.
- Нажмите кнопку взаимодействия, и стратегия начнет генерировать случайные данные автоматически.
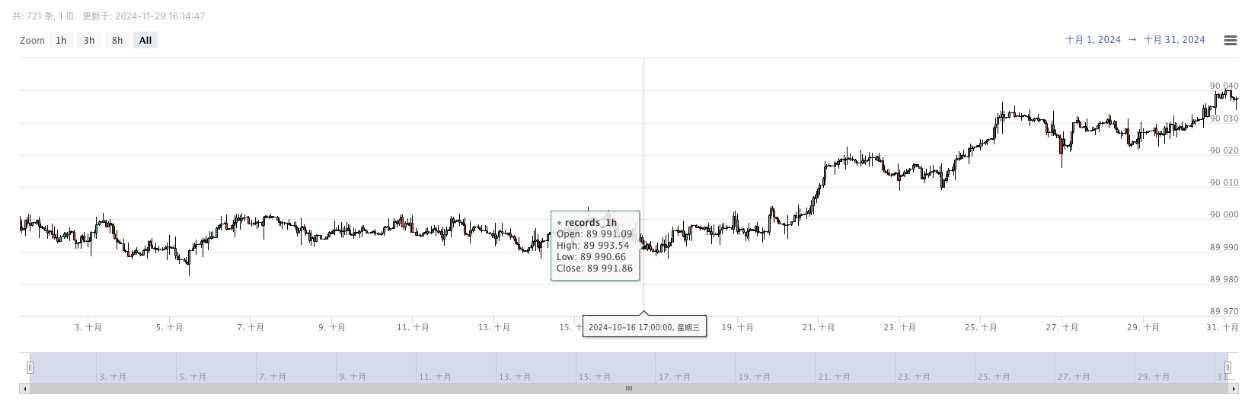
- Сгенерированные данные будут отображаться на графике для легкого наблюдения, а данные будут записаны в локальном файле data.csv.
- Теперь мы можем использовать эти случайные данные и использовать любую стратегию для обратного тестирования:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Согласно вышеуказанной информации, настроить и настроить.http://xxx.xxx.xxx.xxx:9090является IP-адресом сервера и открытым портом стратегии создания случайного тикера.
Это пользовательский источник данных, который можно найти в разделе пользовательский источник данных документа API платформы.
- После того, как система обратного теста настроит источник данных, мы можем проверить случайные данные рынка:
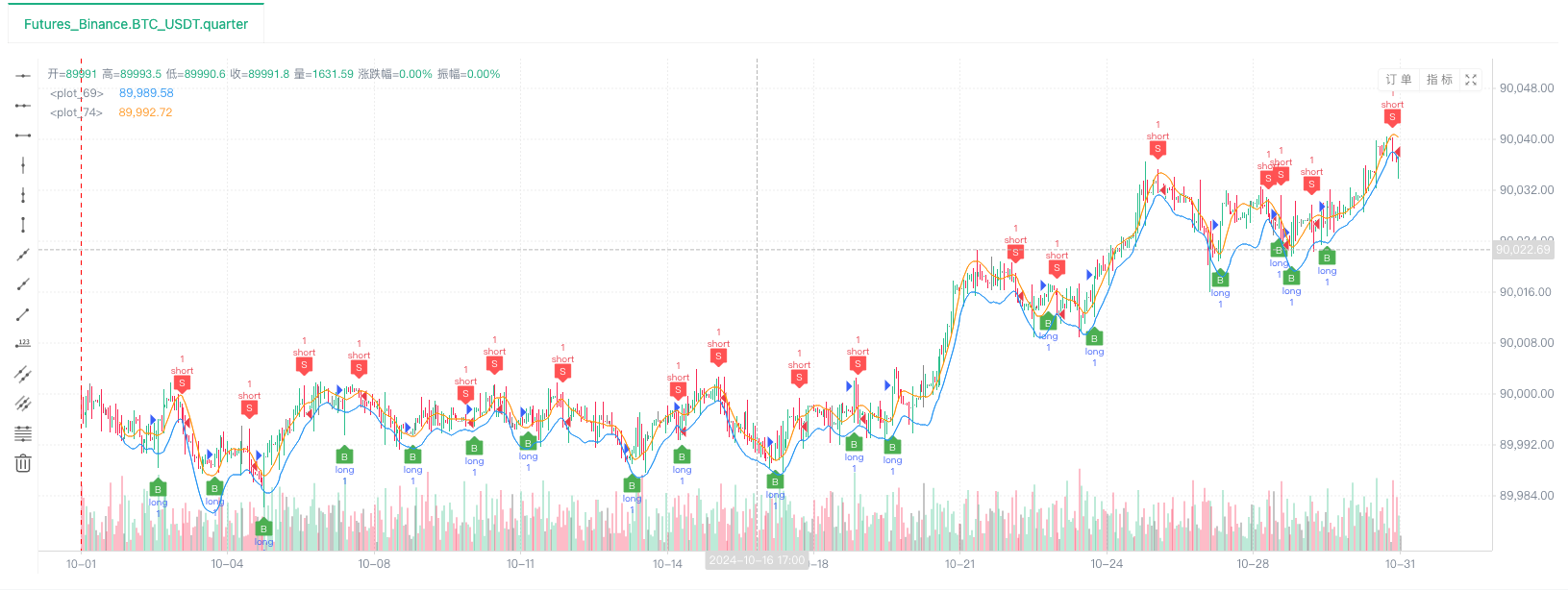
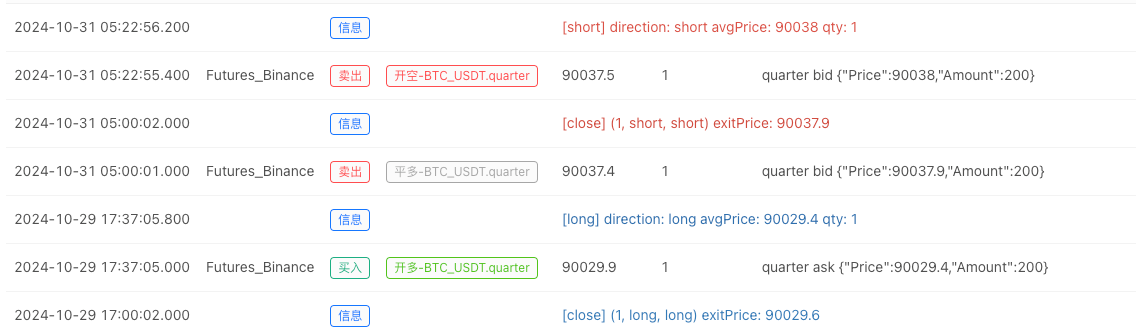
В это время система бэкстеста тестируется с помощью наших
- О, да, я чуть не забыл упомянуть! Причина, по которой эта программа Python создает живую торговлю, заключается в том, чтобы облегчить демонстрацию, работу и отображение генерируемых данных K-линии. В реальном применении вы можете написать независимый скрипт Python, поэтому вам не нужно запускать живую торговлю.
Источник стратегии:Система обратного тестирования генератор случайных тикеров
Спасибо за поддержку и чтение.
- DEX обмены количественные практики ((1) -- dYdX v4 Руководство пользователя
- Презентация о своде Lead-Lag в цифровой валюте (3)
- Введение в арбитраж с задержкой свинца в криптовалюте (2)
- Презентация о своде Lead-Lag в цифровой валюте (2)
- Обсуждение по внешнему приему сигналов платформы FMZ: полное решение для приема сигналов с встроенным сервисом Http в стратегии
- Обзор приема внешних сигналов на платформе FMZ: стратегию полного решения приема сигналов встроенного сервиса HTTP
- Введение в арбитраж с задержкой свинца в криптовалюте (1)
- Введение Lead-Lag в цифровой валюте (1)
- Дискуссия по внешнему приему сигнала платформы FMZ: расширенный API VS стратегия встроенного HTTP-сервиса
- Обзор FMZ-платформы для получения внешних сигналов: расширение API против стратегии встроенного HTTP-сервиса
- Исследование методов тестирования стратегии на основе генератора случайных рынков
- Новая функция FMZ Quant: Используйте функцию _Serve для простого создания HTTP-сервисов
- Изобретатели количественно увеличили новые возможности: легко создать HTTP-сервисы с помощью функции _Serve
- FMZ Quant Trading Platform Руководство по доступу к пользовательскому протоколу
- Стратегия приобретения и мониторинга ставки финансирования FMZ
- Стратегия получения и мониторинга FMZ
- Шаблон стратегии позволяет беспрепятственно использовать WebSocket Market
- Схема политики, которая позволяет беспрепятственно использовать веб-сокет
- Инвесторы по количественной торговле
- Как построить универсальную стратегию многовалютной торговли быстро после обновления FMZ