Применение технологии машинного обучения в торговле
Автор:FMZ~Lydia, Создано: 2022-12-30 10:53:07, Обновлено: 2023-09-20 09:30:09
Применение технологии машинного обучения в торговле
Вдохновение для этой статьи исходит из моего наблюдения за некоторыми распространенными предупреждениями и ловушками после попытки применить технологию машинного обучения к проблемам с транзакциями во время исследования данных на платформе FMZ Quant.
Если вы не читали мои предыдущие статьи, мы предлагаем вам прочитать руководство по автоматизированной среде исследования данных и систематический метод формулирования торговых стратегий, которые я установил на платформе FMZ Quant до этой статьи.
Адреса этих двух статей здесь:https://www.fmz.com/digest-topic/9862иhttps://www.fmz.com/digest-topic/9863.
О создании исследовательской среды
Этот учебник предназначен для энтузиастов, инженеров и ученых данных на всех уровнях квалификации. Независимо от того, являетесь ли вы лидером отрасли или новичком в программировании, единственные навыки, которые вам нужны, - это базовое понимание языка программирования Python и достаточные знания операций командной строки (достаточно иметь возможность настроить проект науки о данных).
- Установите FMZ Quant докер и настроите Anaconda
Платформа FMZ QuantFMZ.COMОн не только предоставляет высококачественные источники данных для основных основных бирж, но и предоставляет набор богатых интерфейсов API, которые помогают нам осуществлять автоматические транзакции после завершения анализа данных. Этот набор интерфейсов включает в себя практические инструменты, такие как запрос информации о счете, запрос высокой, открытой, низкой, цены получения, объема торговли и различных часто используемых технических показателей анализа различных основных бирж. В частности, он предоставляет сильную техническую поддержку для публичных интерфейсов API, соединяющих основные основные биржи в фактическом процессе торговли.
Все вышеупомянутые функции встроены в систему Docker. Что нам нужно сделать, это купить или арендовать наши собственные облачные вычислительные услуги и развернуть систему Docker.
В официальном названии платформы FMZ Quant система Docker называется системой Docker.
Пожалуйста, ознакомьтесь с моей предыдущей статьей о том, как развернуть докер и робота:https://www.fmz.com/bbs-topic/9864.
Читатели, которые хотят приобрести собственный сервер облачных вычислений для развертывания докеров, могут обратиться к этой статье:https://www.fmz.com/digest-topic/5711.
После успешного развертывания сервера облачных вычислений и системы докеров, следующим мы установим самый большой артефакт Python: Anaconda.
Чтобы реализовать все соответствующие программные среды (библиотеки зависимостей, управление версиями и т. д.), необходимые в этой статье, самый простой способ - использовать Anaconda.
Поскольку мы устанавливаем Anaconda на облачном сервисе, мы рекомендуем, чтобы облачный сервер устанавливал систему Linux плюс версию командной строки Anaconda.
Для установки Anaconda, пожалуйста, обратитесь к официальному руководству Anaconda:https://www.anaconda.com/distribution/.
Если вы опытный программист Python и если вы чувствуете, что вам не нужно использовать Anaconda, это вовсе не проблема. Я предположу, что вам не нужна помощь при установке необходимой зависимой среды. Вы можете пропустить этот раздел напрямую.
Разработать торговую стратегию
Окончательный результат торговой стратегии должен отвечать на следующие вопросы:
-
Направление: определить, является ли актив дешевым, дорогим или справедливой стоимостью.
-
Условия открытия позиции: если актив дешевый или дорогой, вы должны пойти длинным или коротким.
-
Закрытие позиции: если актив имеет разумную цену и у нас есть позиция в активе (предыдущая покупка или продажа), следует ли закрыть позицию?
-
Ценовой диапазон: цена (или диапазон), по которой была открыта позиция.
-
Количество: количество денежных средств, с которыми торгуется (например, количество цифровой валюты или количество лотов товарных фьючерсов).
Машинное обучение может быть использовано для ответа на каждый из этих вопросов, но в остальной части этой статьи мы сосредоточимся на первом вопросе, который является направлением торговли.
Стратегический подход
Существует два типа подходов к построению стратегий: один основан на модели; другой основан на майнинге данных.
В модели на основе стратегии строительства, мы начинаем с модели неэффективности рынка, строим математические выражения (такие как цена и прибыль) и проверяем их эффективность в течение длительного периода времени. Эта модель обычно является упрощенной версией реальной сложной модели, и ее долгосрочное значение и стабильность необходимо проверить.
С другой стороны, мы сначала ищем ценовые модели и пытаемся использовать алгоритмы в методах майнинга данных. Причины этих моделей не важны, потому что только идентифицированные модели будут продолжать повторяться в будущем. Это метод слепого анализа, и нам нужно строго проверять, чтобы определить реальные модели из случайных моделей.
Очевидно, что машинное обучение очень легко применить к методам майнинга данных. Давайте посмотрим, как использовать машинное обучение для создания сигналов транзакций посредством майнинга данных.
Пример кода использует инструмент обратного тестирования на основе платформы FMZ Quant и автоматизированный интерфейс API для транзакций. После развертывания докера и установки Anaconda в вышеуказанном разделе вам нужно только установить библиотеку анализа науки о данных, в которой мы нуждаемся, и известную модель машинного обучения scikit-learn.
pip install -U scikit-learn
Использование машинного обучения для создания сигналов торговой стратегии
- Добыча данных. Прежде чем мы начнем, стандартная система задач машинного обучения показана на следующем рисунке:
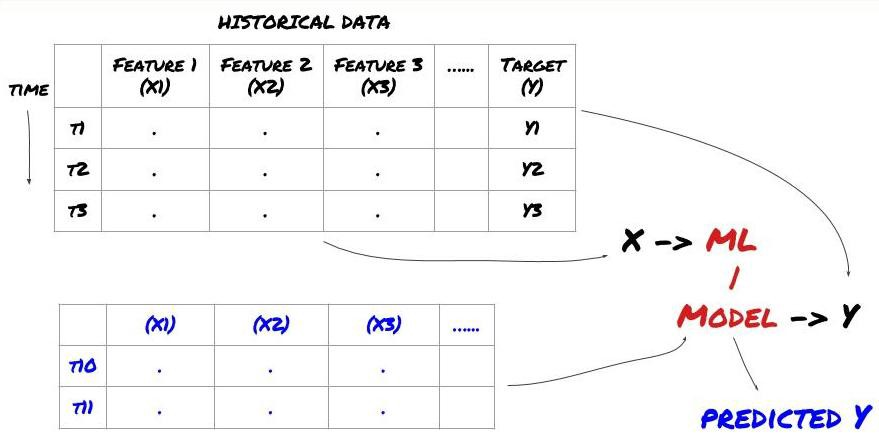
Система машинного обучения
Функция, которую мы собираемся создать, должна обладать некоторой способностью к предсказанию (X). Мы хотим предсказать целевую переменную (Y) и использовать исторические данные для обучения модели ML, которая может предсказать Y как можно ближе к фактическому значению. Наконец, мы используем эту модель для прогнозирования новых данных, где Y неизвестно. Это приводит нас к первому шагу:
Шаг 1: Задайте свой вопрос
- Что вы хотите предсказать? Что такое хорошее предсказание? Как вы оцениваете результаты предсказания?
То есть, в нашей структуре выше, что такое Y?
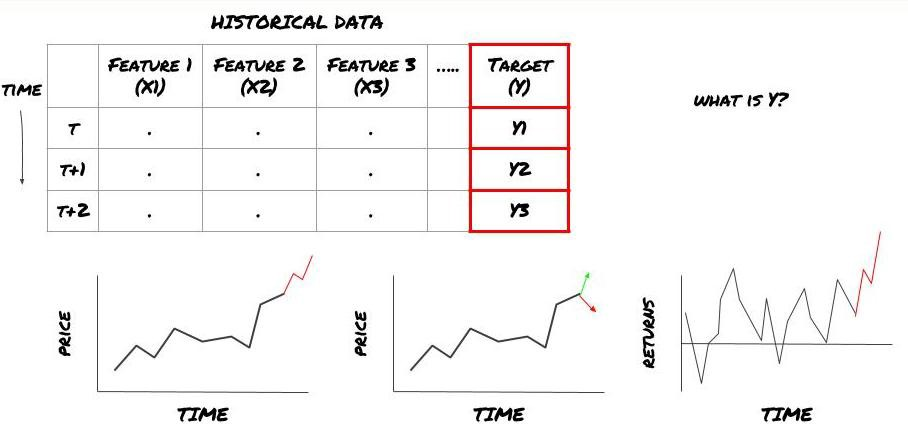
Что ты хочешь предсказать?
Хотите предсказать будущие цены, будущие доходы/Pnl, сигналы покупки/продажи, оптимизировать распределение портфеля и попытаться эффективно выполнять транзакции?
Предположим, что мы пытаемся спрогнозировать цены на следующую временную отметку.
Обратите внимание, что Y (t) известна только в обратном тесте, но когда мы используем нашу модель, мы не будем знать цену (t + 1) времени t. Мы используем нашу модель для прогнозирования Y (предсказанное, t) и сравниваем его с фактическим значением только во время t + 1. Это означает, что вы не можете использовать Y в качестве функции в модели прогнозирования.
После того, как мы узнаем цель Y, мы также можем решить, как оценить наши прогнозы. Это важно для различения между различными моделями данных, которые мы будем пробовать. Выберите индикатор для измерения эффективности нашей модели в соответствии с решенной нами проблемой. Например, если мы прогнозируем цены, мы можем использовать корневую среднюю квадратную ошибку в качестве индикатора. Некоторые часто используемые индикаторы (EMA, MACD, значение вариантности и т. Д.) были предварительно зашифрованы в инструментарии FMZ Quant. Вы можете вызвать эти индикаторы глобально через интерфейс API.
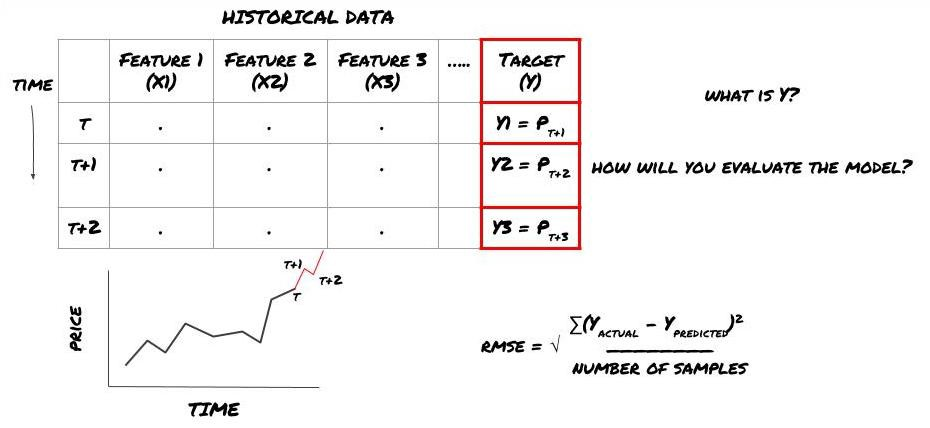
ML рамки прогнозирования будущих цен
В целях демонстрации мы создадим модель прогнозирования, чтобы предсказать ожидаемую будущую базовую стоимость гипотетического объекта инвестиций, где:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Поскольку это проблема регрессии, мы будем оценивать модель на RMSE (корень среднего квадрата ошибки).
Примечание: Пожалуйста, обратитесь к энциклопедии Baidu для соответствующих математических знаний RMSE.
- Наша цель: создать модель, чтобы сделать предсказанное значение как можно ближе к Y.
Шаг 2: Сбор достоверных данных
Соберите и очистите данные, которые могут помочь вам решить проблему.
Какие данные вам нужно учитывать, чтобы предсказать целевую переменную Y? Если мы предсказываем цену, вы можете использовать данные о цене объекта инвестиций, данные о количестве торговли объекта инвестиций, аналогичные данные о соответствующем объекте инвестиций, уровень индекса объекта инвестиций и другие общие рыночные показатели, а также цену других связанных активов.
Вы должны установить разрешения доступа к данным для этих данных и убедиться, что ваши данные точны, и решить потерянные данные (очень распространенная проблема). В то же время, убедитесь, что ваши данные беспристрастны и полностью представляют все рыночные условия (например, одинаковое количество сценариев прибыли и убытка), чтобы избежать предвзятости в модели.
Если вы используете платформу FMZ Quant (FMZ.COM), мы можем получить доступ к бесплатным глобальным данным от Google, Yahoo, NSE и Quandl; Глубокие данные отечественных товарных фьючерсов, таких как CTP и Esunny; Данные от основных цифровых валютных бирж, таких как Binance, OKX, Huobi и BitMex. Платформа FMZ Quant также предварительно очищает и фильтрует эти данные, такие как разделение инвестиционных целей и углубленные рыночные данные, и представляет их разработчикам стратегии в формате, который легко понять количественным практикам.
Для облегчения демонстрации этой статьи мы используем следующие данные в качестве
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
С помощью вышеперечисленного кода Auquan
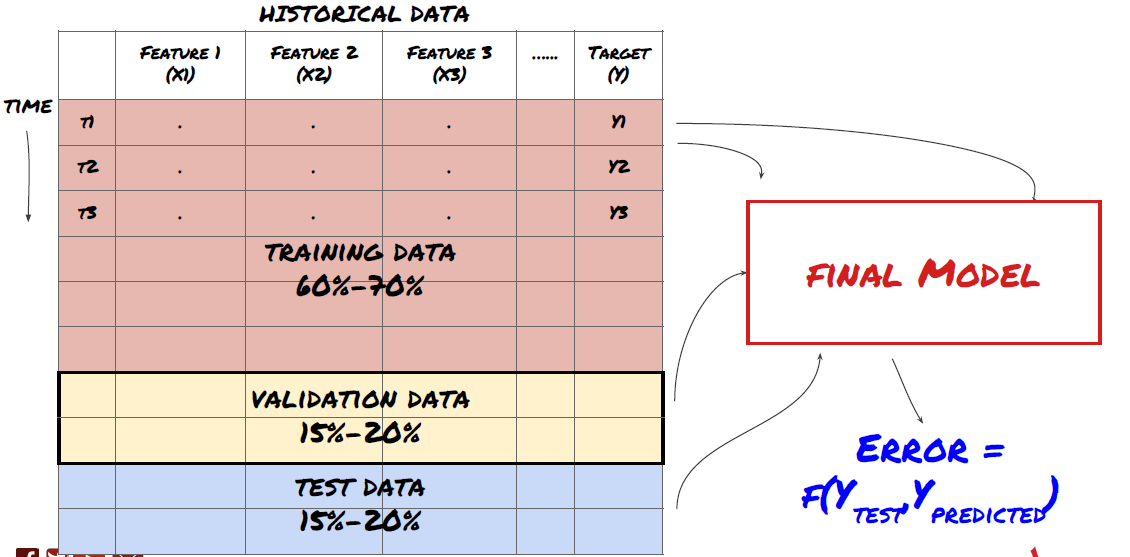
Шаг 3: Разделите данные
- Создать набор обучения, перекрестную проверку и тестировать эти наборы данных из данных.
Это очень важный шаг!Перед тем, как продолжить, мы должны разделить данные на наборы данных обучения для обучения вашей модели; наборы данных тестирования для оценки производительности модели.
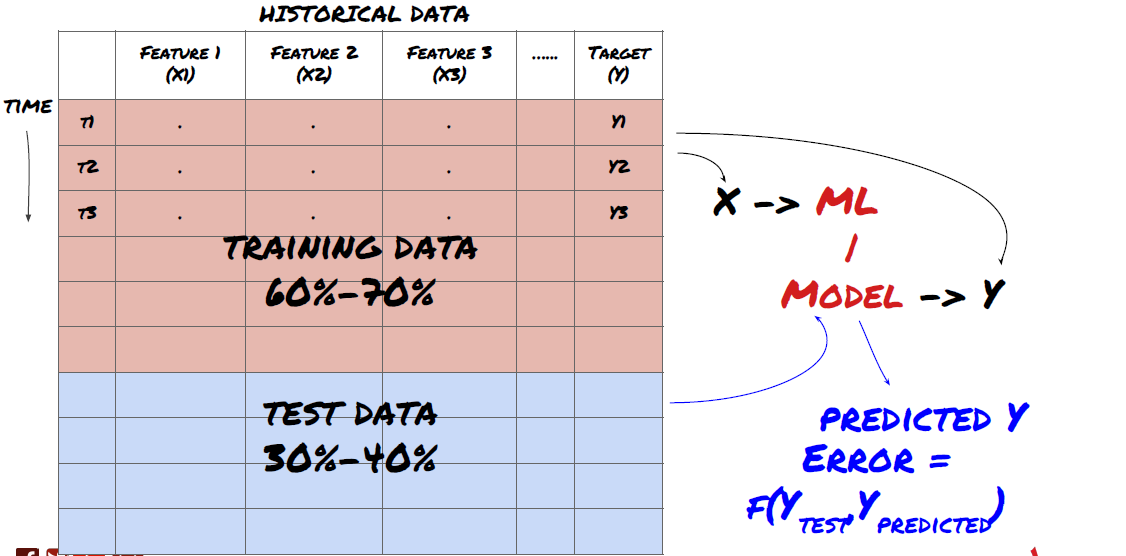
Разделить данные на наборы для обучения и наборы для испытаний
Поскольку данные обучения используются для оценки параметров модели, ваша модель может слишком сильно соответствовать этим данным обучения, и данные обучения могут вводить в заблуждение производительность модели. Если вы не сохраняете никаких отдельных тестовых данных и не используете все данные для обучения, вы не будете знать, насколько хорошо или плохо ваша модель работает на новых невидимых данных. Это одна из основных причин неудачи обученной модели ML в данных в режиме реального времени: люди тренируют все доступные данные и взволнованы индикаторами данных обучения, но модель не может делать никаких значимых предсказаний по необработанным данным в режиме реального времени.
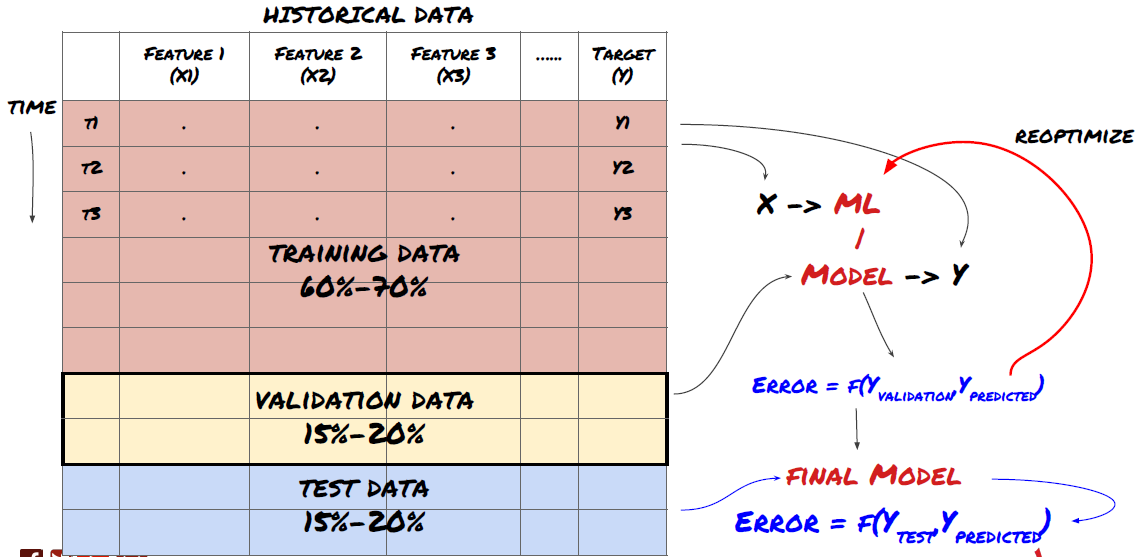
Разделить данные на набор обучения, набор проверки и набор испытаний
Есть проблемы с этим методом. Если мы неоднократно тренируем данные обучения, оцениваем производительность данных испытаний и оптимизируем нашу модель, пока не будем удовлетворены производительностью, мы принимаем данные испытаний как часть данных обучения подразумевающе. В конце концов, наша модель может хорошо работать на этом наборе данных обучения и испытаний, но она не может гарантировать, что она может хорошо предсказывать новые данные.
Чтобы решить эту проблему, мы можем создать отдельный набор данных проверки. Теперь вы можете обучать данные, оценивать производительность данных проверки, оптимизировать, пока не будете удовлетворены производительностью, и, наконец, протестировать данные теста. Таким образом, данные теста не будут загрязнены, и мы не будем использовать какую-либо информацию в данных теста для улучшения нашей модели.
Помните, как только вы проверили производительность ваших тестовых данных, не возвращайтесь и не пытайтесь оптимизировать свою модель. Если вы обнаружите, что ваша модель не дает хороших результатов, полностью отбросьте модель и начните сначала.
Для нашего вопроса у нас есть три доступных набора данных. мы будем использовать один как набор обучения, второй как набор проверки, и третий как наш тест набор.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Для каждого из них мы добавляем целевую переменную Y, которая определяется как среднее значение следующих пяти базовых значений.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Шаг 4: Инженерия характеристик
Анализировать поведение данных и создавать предсказательные функции
Теперь началось реальное строительство проекта. Золотое правило выбора функций заключается в том, что способность к прогнозированию в основном исходит от функций, а не от моделей. Вы обнаружите, что выбор функций оказывает гораздо большее влияние на производительность, чем выбор моделей.
-
Не выбирайте большой набор признаков случайным образом, не изучив взаимосвязь с целевой переменной.
-
Малое или никакое отношение к целевой переменной может привести к переподготовке.
-
Выбранные вами характеристики могут быть тесно связаны друг с другом, в этом случае небольшое количество характеристик также может объяснить цель.
-
Обычно я создаю некоторые интуитивные функции, проверяю корреляцию между целевой переменной и этими функциями, и корреляцию между ними, чтобы решить, какую из них использовать.
-
Вы также можете попробовать выполнять анализ основных компонентов (PCA) и другие методы сортировки кандидатов в соответствии с максимальным информационным коэффициентом (MIC).
Трансформация/нормализация характеристик:
Модели ML, как правило, хорошо работают с точки зрения нормализации. Однако нормализация затруднена при работе с данными временных рядов, потому что будущий диапазон данных неизвестен. Ваши данные могут находиться вне диапазона нормализации, что приводит к ошибкам модели. Но вы все равно можете попытаться вынудить некоторую степень стабильности:
-
Скалирование: деление признаков по стандартному отклонению или квартильному диапазону.
-
Центрирование: вычесть историческое среднее значение от текущего значения.
-
Нормализация: два ретроспективных периода вышеперечисленного (x - среднее значение) /stdev.
-
Регулярная нормализация: стандартизация данных в диапазоне от -1 до +1 и переопределение центра в течение периода обратного отслеживания (x-min) / ((max min).
Обратите внимание, что поскольку мы используем историческое непрерывное среднее значение, стандартное отклонение, максимальные или минимальные значения за пределами периода обратного отслеживания, нормализованное значение стандартизации характеристики будет представлять различные фактические значения в разное время. Например, если текущее значение характеристики составляет 5 и среднее значение за 30 последовательных периодов составляет 4,5, оно будет преобразовано в 0,5 после центрирования. После этого, если среднее значение 30 последовательных периодов становится 3, значение 3,5 станет 0,5. Это может быть причиной неправильной модели. Поэтому нормализация сложна, и вы должны выяснить, что улучшает производительность модели (если на самом деле есть).
Для первой итерации в нашей задаче мы создали большое количество функций с использованием смешанных параметров.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Шаг 5: Выбор модели
Выберите соответствующую статистическую/ML модель в соответствии с выбранными вопросами
Выбор модели зависит от того, как формируется проблема. Решаете ли вы под наблюдением (каждая точка X в матрице характеристик отображается в целевой переменной Y) или без наблюдения (без заданного отображения модель пытается выучить неизвестную модель)?

Обучение под надзором или без надзора

Регрессия или классификация
Некоторые распространенные алгоритмы обучения под наблюдением могут помочь вам начать:
-
Линейная регрессия (параметры, регрессия)
-
Логистическая регрессия (параметр, классификация)
-
Алгоритм K-ближайшего соседа (KNN) (на основе случаев, регрессия)
-
SVM, SVR (параметры, классификация и регрессия)
-
Дерево решений
-
Лес решений
Я предлагаю начать с простой модели, такой как линейная или логистическая регрессия, и построить более сложные модели оттуда по мере необходимости.
Шаг 6: Обучение, проверка и оптимизация (повторить шаги 4-6)
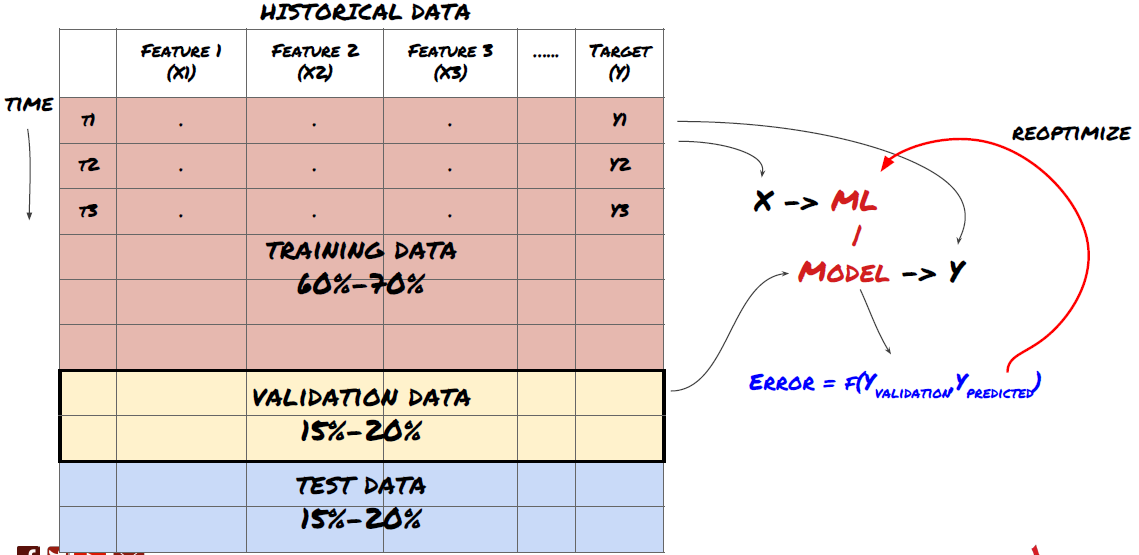
Используйте наборы данных обучения и проверки для обучения и оптимизации вашей модели
Теперь вы готовы наконец построить модель. На этом этапе вы просто повторяете модель и параметры модели. Обучите свою модель на данных обучения, измеряйте ее производительность на данных проверки, а затем возвращайте, оптимизируйте, переучите и оценивайте ее. Если вы не удовлетворены производительностью модели, попробуйте другую модель. Вы проходите через эту фазу много раз, пока, наконец, не получите модель, которой вы удовлетворены.
Только если у вас есть любимая модель, переходите к следующему шагу.
Для нашей задачи демонстрации, давайте начнем с простой линейной регрессии:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
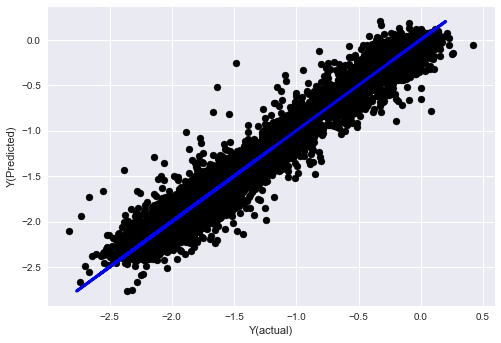
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
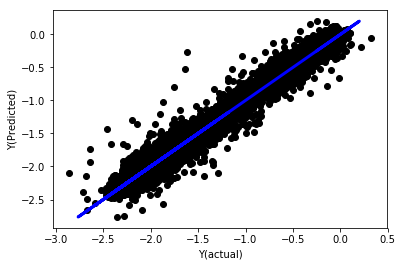
Линейная регрессия без нормализации
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Посмотрите на коэффициенты модели. мы не можем сравнить их или сказать, какой из них важен, потому что они все принадлежат к разным шкалам. давайте попробуем нормализацию, чтобы они соответствовали одной и той же пропорции и также обеспечить некоторую гладкость.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
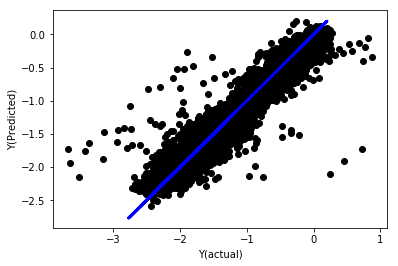
Линейная регрессия с нормализацией
Mean squared error: 0.05
Variance score: 0.90
Эта модель не улучшает предыдущую модель, но не хуже. Теперь мы можем сравнить коэффициенты, чтобы увидеть, какие из них действительно важны.
Давайте посмотрим на коэффициенты:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Результаты:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Мы можем ясно видеть, что некоторые особенности имеют более высокие коэффициенты, чем другие, и они могут иметь более сильную способность к предсказанию.
Давайте посмотрим на взаимосвязь между различными особенностями.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
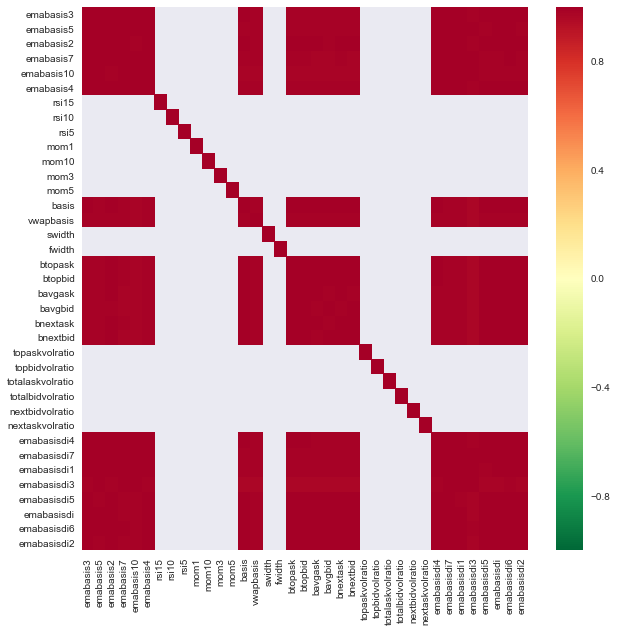
Соотношение между особенностями
Темно-красные области представляют собой сильно коррелирующие переменные. Давайте снова создадим/модифицируем некоторые функции и попытаемся улучшить нашу модель.
Например, я могу легко отказаться от таких функций, как emabasisdi7, которые являются только линейными комбинациями других функций.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
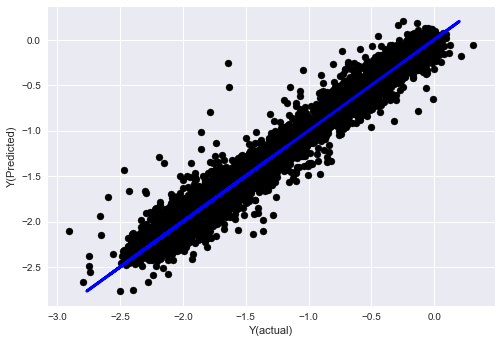
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Посмотрите, производительность нашей модели не изменилась. Нам нужны только некоторые характеристики, чтобы объяснить наши целевые переменные. Я предлагаю вам попробовать больше вышеперечисленных функций, попробовать новые комбинации и т.д., чтобы увидеть, что может улучшить нашу модель.
Мы также можем попробовать более сложные модели, чтобы увидеть, могут ли изменения в моделях улучшить производительность.
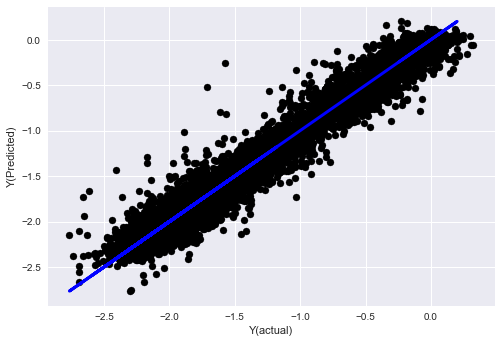
- Алгоритм K-ближайшего соседа (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
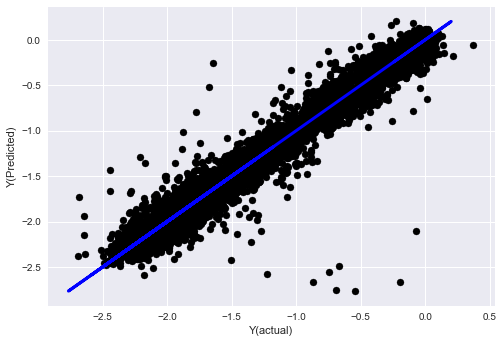
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Дерево решений
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Шаг 7: обратная проверка данных испытания
Проверка эффективности фактических данных выборки
Результаты обратных испытаний на (нетронутых) наборах данных испытаний
Это критический момент. Мы запускаем свою окончательную модель оптимизации с последнего шага тестовых данных, мы откладываем ее в сторону в начале и мы не трогали данные до сих пор.
Это дает вам реалистичные ожидания того, как ваша модель будет выполняться на новых и невидимых данных, когда вы начнете торговать в режиме реального времени.
Если вам не нравятся результаты обратного теста данных теста, пожалуйста, отбросьте модель и начните сначала. Никогда не возвращайтесь или не оптимизируйте свою модель, что приведет к переподключению! (Кроме того, рекомендуется создать новый набор данных теста, потому что этот набор данных теперь загрязнен; при отбросе модели мы уже знаем содержание набора данных подразумевающе).
Здесь мы будем использовать инструментарий Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
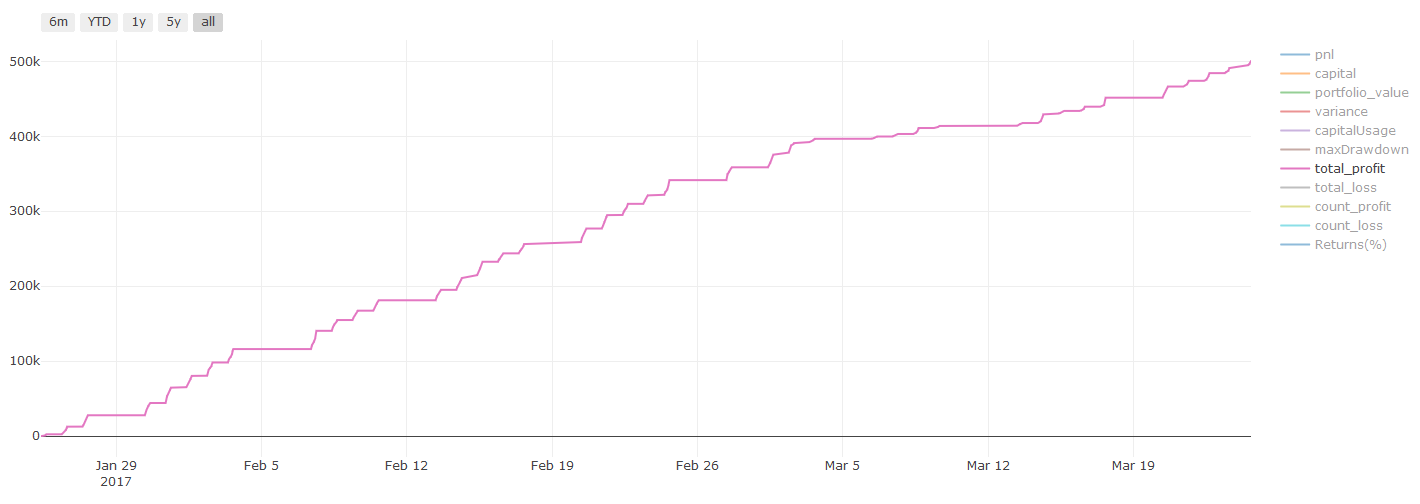
Результаты обратного тестирования, Pnl рассчитываются в долларах США (Pnl не включается в расходы на транзакции и другие сборы)
Шаг 8: Другие методы совершенствования модели
Проверка проката, обучение набору, упаковка и ускорение
В дополнение к сбору большего количества данных, созданию лучших функций или тестированию новых моделей, есть еще несколько моментов, которые вы можете попытаться улучшить.
1. Проверка проката
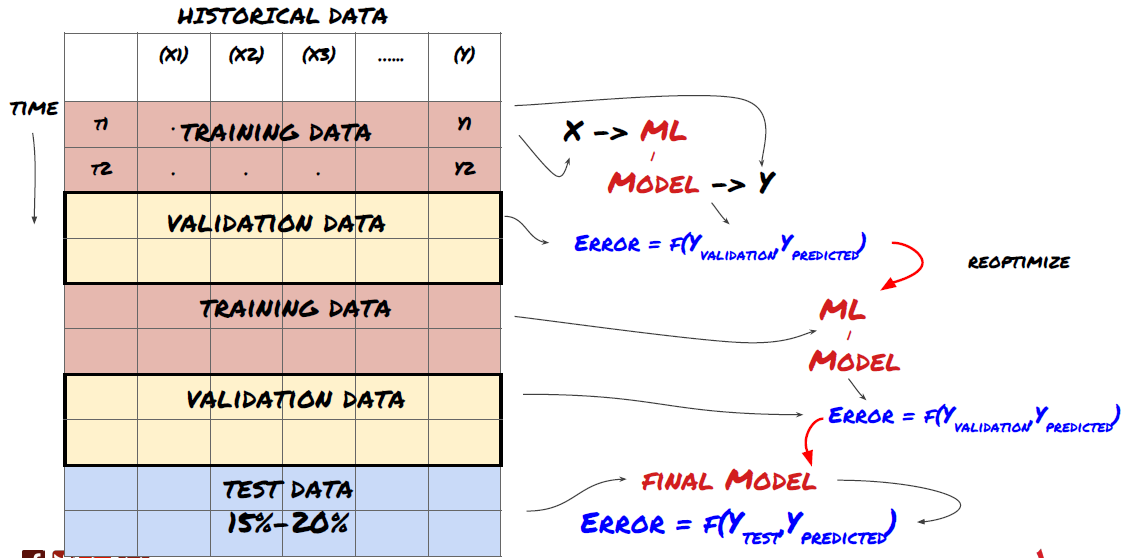
Проверка подвижного движения
Рыночные условия редко остаются прежними. Предположим, у вас есть данные за год, и вы используете данные с января по август для обучения, и используете данные с сентября по декабрь для тестирования своей модели. В конце концов вы можете тренироваться для очень конкретного набора рыночных условий. Может быть, в первой половине года не было колебаний рынка, и некоторые экстремальные новости привели к резкому росту рынка в сентябре. Ваша модель не сможет изучить эту модель, и она принесет вам результаты прогнозирования мусора.
Возможно, лучше попробовать прогрессивную проверку, такую как обучение с января по февраль, проверка в марте, переподготовка с апреля по май, проверка в июне и т.д.
2. Учебный процесс
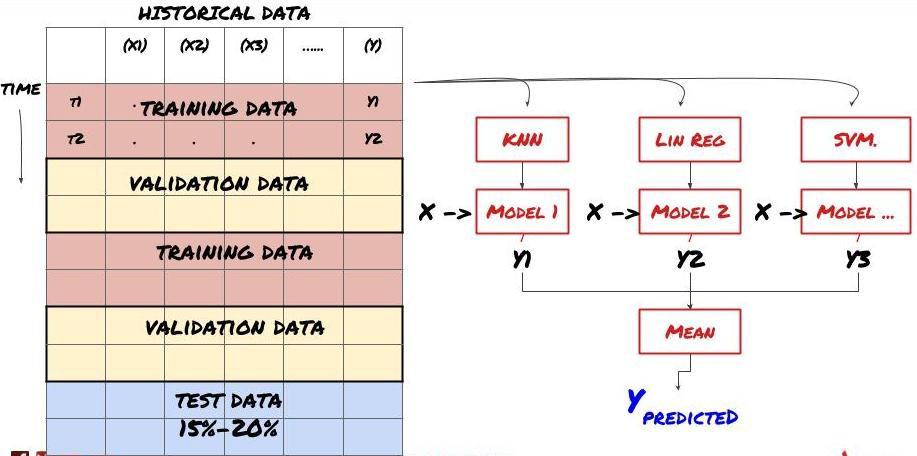
Обучение набора
Некоторые модели могут быть очень эффективными в прогнозировании определенных сценариев, в то время как модели могут быть чрезвычайно переподходящими в прогнозировании других сценариев или при определенных обстоятельствах. Один из способов уменьшить ошибки и переподготовку - использовать набор различных моделей.
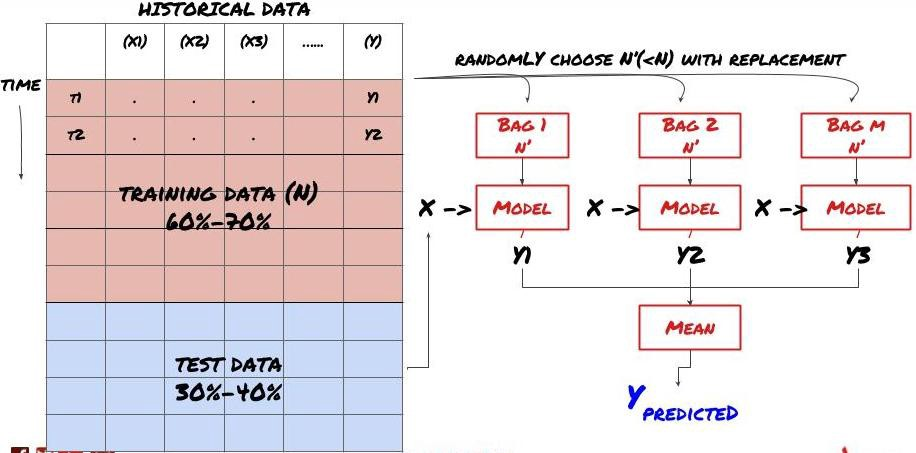
Запаковка
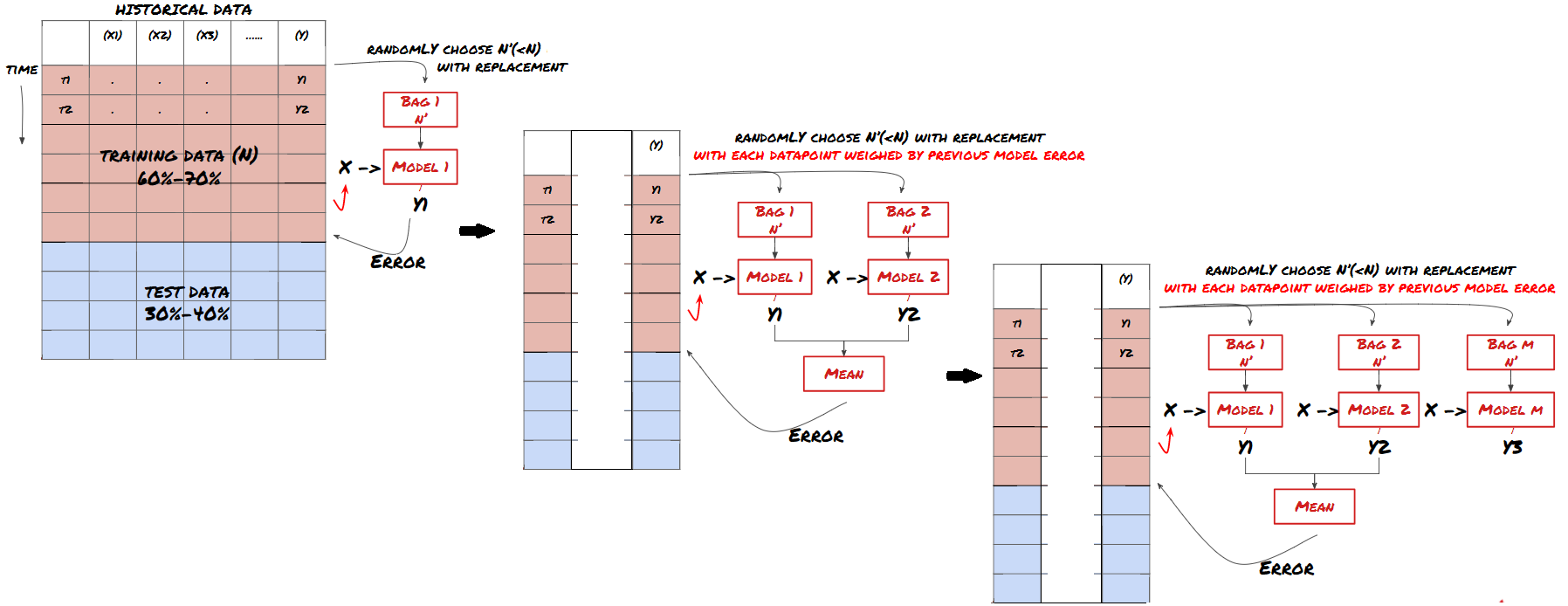
Повышение
Для краткости я не буду использовать эти методы, но вы можете найти больше информации в Интернете.
Давайте попробуем наборный метод для нашей задачи:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
До сих пор мы накопили много знаний и информации.
-
Реши свою проблему;
-
Сбор достоверных данных и очистка данных;
-
Разделение данных на наборы обучения, проверки и испытаний;
-
Создание особенностей и анализ их поведения;
-
Выбирать подходящую модель обучения в соответствии с поведением;
-
Используйте данные обучения для обучения вашей модели и прогнозирования;
-
Проверка эффективности набора проверки и повторная оптимизация;
-
Проверяется окончательная производительность испытательного комплекта.
Это не зашло вам в голову? Но это еще не конец. У вас есть только надежная модель прогнозирования. Помните, чего мы действительно хотели в нашей стратегии?
-
Разработка сигналов на основе прогнозных моделей для определения направлений торговли;
-
Разработка конкретных стратегий определения открытых и закрытых позиций;
-
Использование системы для определения позиций и цен.
Вышеупомянутые предприятия будут использовать платформу FMZ Quant (FMZ.COMНа платформе FMZ Quant существуют высококапсулированные и совершенные интерфейсы API, а также функции заказов и торговли, которые могут быть вызваны глобально. Вам не нужно подключать и добавлять интерфейсы API разных бирж один за другим. В квадрате стратегии платформы FMZ Quant есть много зрелых и совершенных альтернативных стратегий, которые соответствуют методу машинного обучения в этой статье, это сделает вашу конкретную стратегию более мощной. Квадрат стратегии расположен по адресу:https://www.fmz.com/square.
**Важное примечание по затратам на транзакции: ** Ваша модель сообщает вам, когда выбранный актив будет длинным или коротким. Однако она не учитывает сборы/стоимость транзакции/доступное количество торговли/стоп-потеря и т. д. Затраты на транзакции обычно превращают прибыльные транзакции в убытки. Например, актив с ожидаемым ростом цены в $0,05 является покупкой, но если вам придется заплатить $0,10 за эту транзакцию, вы в конечном итоге получите чистый убыток в размере $0,05. После учета комиссии брокера, валютной комиссии и разницы точек наш большой график прибыли выше выглядит так:
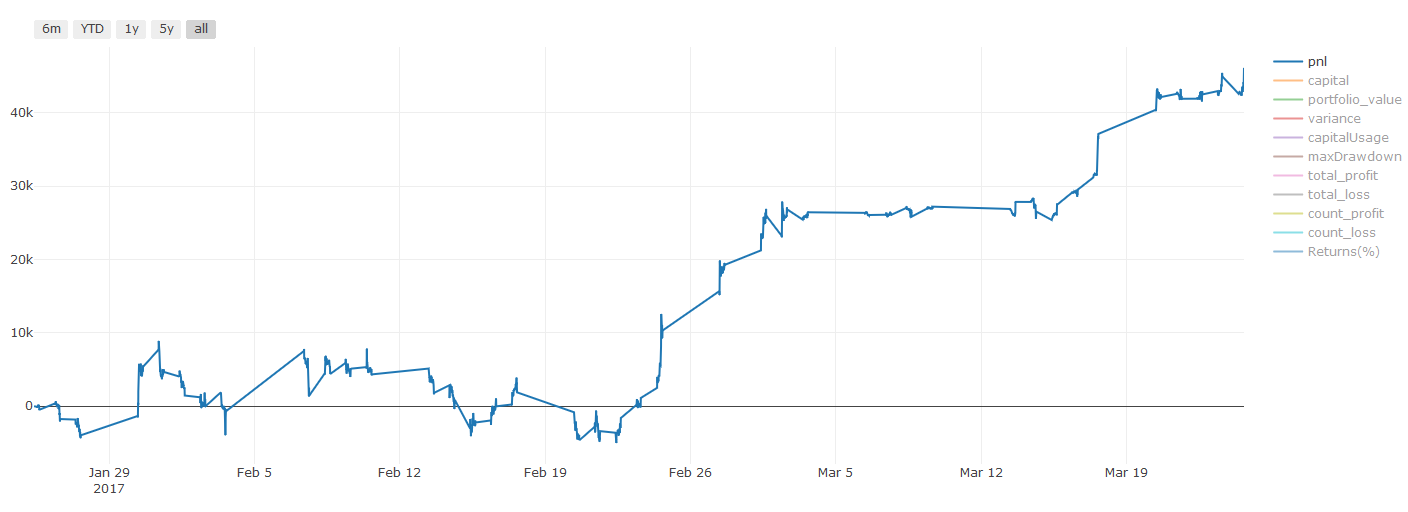
Результат обратного теста после сборов за торговлю и разницы в пунктах, Pnl, составляет USD.
Сборы за транзакции и ценовые различия составляют более 90% нашей ПНЛ!
Наконец, давайте посмотрим на некоторые распространенные ловушки.
Что делать и чего не делать
-
Избегайте чрезмерного приспособления всеми силами!
-
Не переобучайте после каждой точки данных: это распространенная ошибка, которую люди совершают при разработке машинного обучения. Если ваша модель должна быть переобучена после каждой точки данных, это может быть не очень хорошая модель. То есть, ее нужно переобучать регулярно и только с разумной частотой (например, если предсказание внутри дня, она должна быть переобучена в конце каждой недели).
-
Избегайте предвзятости, особенно предвзятости: это еще одна причина, по которой модель не работает, и убедитесь, что вы не используете какую-либо будущую информацию. В большинстве случаев это означает, что целевая переменная Y не используется в качестве функции в модели. Вы можете использовать ее во время обратного тестирования, но она не будет доступна, когда вы фактически запускаете модель, что сделает вашу модель непригодной для использования.
-
Будьте осторожны с предубеждениями в области майнинга данных: поскольку мы пытаемся провести серию моделей на наших данных, чтобы определить, является ли это целесообразным, если нет особой причины, пожалуйста, убедитесь, что вы выполняете строгие тесты, чтобы отделить случайный режим от фактического режима, который может возникнуть. Например, линейная регрессия хорошо объясняет тенденцию восходящего тренда, но она, вероятно, станет долей более крупных случайных странствий!
Избегайте чрезмерного приспособления
Это очень важно, и я думаю, что это необходимо повторить.
-
Слишком большие затраты - самая опасная ловушка в торговых стратегиях.
-
Сложный алгоритм может очень хорошо работать в бэкстесте, но он ужасно терпит неудачу на новых невидимых данных. Этот алгоритм на самом деле не показывает никаких тенденций данных, и у него нет реальной способности к прогнозированию. Он очень подходит для данных, которые он видит;
-
Если вы обнаружите, что вам нужно много сложных функций для интерпретации данных, вы можете переустановить;
-
Разделите имеющиеся данные на данные обучения и испытаний и всегда проверяйте эффективность реальных данных выборки перед использованием модели для транзакций в реальном времени.
- Введение в арбитраж с задержкой свинца в криптовалюте (2)
- Презентация о своде Lead-Lag в цифровой валюте (2)
- Обсуждение по внешнему приему сигналов платформы FMZ: полное решение для приема сигналов с встроенным сервисом Http в стратегии
- Обзор приема внешних сигналов на платформе FMZ: стратегию полного решения приема сигналов встроенного сервиса HTTP
- Введение в арбитраж с задержкой свинца в криптовалюте (1)
- Введение Lead-Lag в цифровой валюте (1)
- Дискуссия по внешнему приему сигнала платформы FMZ: расширенный API VS стратегия встроенного HTTP-сервиса
- Обзор FMZ-платформы для получения внешних сигналов: расширение API против стратегии встроенного HTTP-сервиса
- Обсуждение метода тестирования стратегии на основе генератора случайных тикеров
- Исследование методов тестирования стратегии на основе генератора случайных рынков
- Новая функция FMZ Quant: Используйте функцию _Serve для простого создания HTTP-сервисов
- Нейронные сети и цифровая валюта Количественная серия торговли (1) - LSTM предсказывает цену Биткоина
- Применение комбинированной стратегии индекса относительной прочности SMA и RSI
- Разработка стратегии CTA и стандартной библиотеки классов платформы FMZ Quant
- Количественная стратегия торговли с анализом динамики цен в Python
- Внедрить стратегию количественной торговли цифровой валютой с двойным толчком в Python
- Лучший способ установить и обновить Linux docker
- Достижение сбалансированной стратегии акций для длинных коротких позиций с упорядоченным согласованием
- Анализ данных по временным рядам и обратное тестирование данных по тикам
- Количественный анализ рынка цифровой валюты
- Торговля парами на основе технологии, основанной на данных
- Использовать исследовательскую среду для анализа деталей треугольного хеджирования и влияния комиссий за обработку на ценовую разницу хеджируемого
- Реформа фьючерсного API Deribit для адаптации к количественной торговле опционами
- Лучшие инструменты делают хорошую работу - научитесь использовать исследовательскую среду для анализа принципов торговли
- Стратегии хеджирования с использованием кросс-валюты при количественной торговле блокчейн-активами
- Приобрести руководство по стратегии цифровой валюты FMex на FMZ Quant
- Научить писать стратегии - трансплантировать стратегию MyLanguage (продвинутое)
- Научить писать стратегии - пересадить стратегию MyLanguage
- Научить вас добавить поддержку многографика к стратегии
- Научить вас писать функцию синтеза K-линии в версии Python
- Анализ стратегии Дончианского канала в исследовательской среде