مشین لرننگ کی تین بڑی اقسام کے 6 بڑے الگورتھم کے فوائد اور نقصانات
مصنف:ایجاد کاروں کی مقدار - خواب, تخلیق: 2017-10-30 12:01:59, تازہ کاری: 2017-11-08 13:55:03مشین لرننگ کی تین بڑی اقسام کے 6 بڑے الگورتھم کے فوائد اور نقصانات
مشین لرننگ میں ، مقصد یا تو پیش گوئی ہے (پروڈکشن) یا کلیسٹرنگ (کلسٹرنگ) ؛ اس مضمون میں پیش گوئی پر توجہ دی گئی ہے۔ پیش گوئی ان پٹ متغیرات کے ایک سیٹ سے آؤٹ پٹ متغیرات کی قدر کا اندازہ لگانے کا عمل ہے۔ مثال کے طور پر ، متعلقہ گھر کی خصوصیات کے ایک سیٹ کو حاصل کرنے کے بعد ، ہم اس کی فروخت کی قیمت کا اندازہ لگا سکتے ہیں۔ پیش گوئی کے مسائل کو دو بڑی اقسام میں تقسیم کیا جاسکتا ہے۔ اس کے بعد ، آئیے مشین لرننگ میں سب سے زیادہ نمایاں اور عام طور پر استعمال ہونے والے الگورتھم پر نگاہ ڈالیں۔ ہم ان کو تین اقسام میں تقسیم کرتے ہیں: لکیری ماڈل ، درخت پر مبنی ماڈل ، اور اعصابی نیٹ ورکس ، اور عام طور پر استعمال ہونے والے 6 پر توجہ دیتے ہیں:
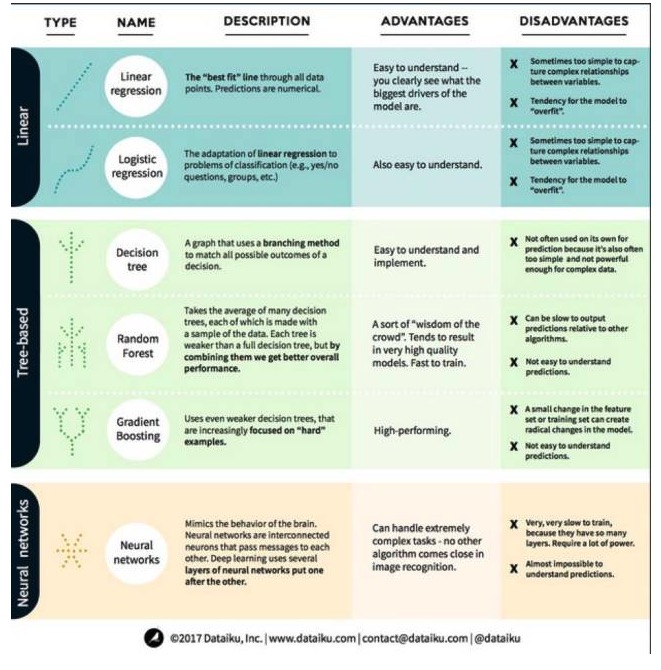
ایک ، لکیری ماڈل الگورتھم: لکیری ماڈل سادہ فارمولوں کا استعمال کرتے ہوئے ، ڈیٹا پوائنٹس کے ایک سیٹ کے ذریعے بہترین فٹ ہونے والی لائنوں کو ڈھونڈتا ہے۔ یہ طریقہ 200 سال سے زیادہ کا ہے اور اعدادوشمار اور مشین لرننگ دونوں شعبوں میں وسیع پیمانے پر استعمال ہوتا ہے۔ اس کی سادگی کی وجہ سے ، یہ اعدادوشمار کے لئے مفید ہے۔ آپ جس متغیر کی پیش گوئی کرنا چاہتے ہیں اسے متغیر کے مساوات کے طور پر پیش کیا جاتا ہے جسے آپ پہلے ہی جانتے ہیں (خود متغیر) ، لہذا پیش گوئی کرنا صرف ایک متغیر کو داخل کرنا ہے اور پھر مساوات کے جوابات کا حساب لگانا ہے۔
- ### #1. لکیری رجعت
لکیری رجعت ، یا زیادہ درست طور پر ، فاریکس ٹریڈنگ کے بہترین اختیارات کیا ہیں؟ کا سب سے معیاری فارم ہے۔ لکیری رجعت رجعت کے مسائل کے ل the ، لکیری رجعت سب سے آسان لکیری ماڈل ہے۔ اس کا نقصان یہ ہے کہ ماڈل آسانی سے اوور فٹ ہوجاتا ہے ، یعنی ، ماڈل مکمل طور پر تربیت یافتہ اعداد و شمار کے مطابق ہوجاتا ہے ، اس کی قیمت پر نئے اعداد و شمار میں توسیع کرنے کی صلاحیت پر۔ لہذا ، مشین سیکھنے میں لکیری رجعت (اور منطقی رجعت جس کے بارے میں ہم بعد میں بات کریں گے) عام طور پر موڈل کیپشن ہے ، جس کا مطلب ہے کہ ماڈل کو اوور فٹ ہونے سے روکنے کے لئے کچھ سزا ہے۔
لکیری ماڈلز کا ایک اور نقصان یہ ہے کہ چونکہ وہ بہت آسان ہیں ، لہذا جب ان پٹ متغیرات آزاد نہیں ہوتے ہیں تو وہ زیادہ پیچیدہ طرز عمل کی پیش گوئی کرنے میں آسان نہیں ہوتے ہیں۔
- #### #2. منطقی رجعت
منطقی رجعت درجہ بندی کے مسئلے کے لئے لکیری رجعت کی موافقت ہے۔ منطقی رجعت کے نقصانات لکیری رجعت کی طرح ہیں۔ منطقی افعال درجہ بندی کے مسئلے کے لئے بہت اچھے ہیں کیونکہ اس نے تھریڈ ویلیو اثر متعارف کرایا ہے۔
دوسرا، درخت ماڈل الگورتھم
- ########################################################################################################################################################
فیصلے کا درخت ہر ممکنہ نتائج کی ایک تصویر ہے جس میں فیصلے کو دکھایا گیا ہے۔ مثال کے طور پر، آپ نے سلاد کا حکم دینے کا فیصلہ کیا ہے، آپ کا پہلا فیصلہ ممکنہ طور پر خام کیلے کی قسم ہے، اس کے بعد آم اور پھر سلاد کی قسم. ہم ایک فیصلے کے درخت میں تمام ممکنہ نتائج ظاہر کر سکتے ہیں.
فیصلے کے درخت کو تربیت دینے کے لیے ہمیں ٹریننگ ڈیٹاسیٹ کا استعمال کرنے کی ضرورت ہوتی ہے اور یہ معلوم کرنا پڑتا ہے کہ مقصد کے لیے کون سی صفت سب سے زیادہ مفید ہے۔ مثال کے طور پر، دھوکہ دہی کے پتہ لگانے کے استعمال کی مثال میں، ہم یہ تلاش کر سکتے ہیں کہ ملک دھوکہ دہی کے خطرے کی پیشن گوئی کرنے میں سب سے زیادہ اثر انداز ہوتا ہے۔ پہلی صفت کے ساتھ شاخ بندی کرنے کے بعد، ہمیں دو ذیلی سیٹ ملتی ہیں، جو کہ سب سے زیادہ درست اندازہ لگانے کے قابل ہوتی ہیں اگر ہم صرف پہلی صفت کو جانتے ہوں۔ پھر ہم دوسری اچھی صفت کا پتہ لگاتے ہیں جو ان دونوں ذیلی سیٹوں کے ساتھ شاخ بندی کی جا سکتی ہے، دوبارہ تقسیم کرتے ہیں، اور اسی طرح بار بار استعمال کرتے ہیں، جب تک کہ کافی تعداد میں صفتیں موجود نہ ہوں تاکہ مقصد کی ضروریات پوری کی جا سکیں۔
- ###############################################################################################################################################################################################################################################################
بے ترتیب جنگل بہت سے فیصلے کے درختوں کا اوسط ہے، جن میں سے ہر ایک فیصلے کے درخت کو بے ترتیب اعداد و شمار کے نمونے کے ساتھ تربیت دی جاتی ہے۔ بے ترتیب جنگل میں ہر ایک درخت ایک مکمل فیصلے کے درخت سے کمزور ہے، لیکن تمام درختوں کو ایک ساتھ ڈالنے سے، ہم تنوع کے فوائد کی وجہ سے بہتر مجموعی کارکردگی حاصل کرسکتے ہیں۔
بے ترتیب جنگل آج مشین سیکھنے میں ایک بہت ہی مقبول الگورتھم ہے۔ بے ترتیب جنگل کی تربیت کرنا آسان ہے ، اور اس کی کارکردگی کافی اچھی ہے۔ اس کا نقصان یہ ہے کہ بے ترتیب جنگل کی پیداوار کی پیش گوئی دوسرے الگورتھم کے مقابلے میں سست ہوسکتی ہے ، لہذا جب تیز پیش گوئی کی ضرورت ہو تو ، بے ترتیب جنگل کا انتخاب نہیں کیا جاسکتا ہے۔
- ##### 3، گرڈینٹ اپ
گریڈینٹ بوسٹنگ ، جیسے بے ترتیب جنگلات ، کمزور اور کمزور فیصلہ سازی کے درختوں پر مشتمل ہے۔ گریڈینٹ بوسٹنگ کا سب سے بڑا فرق یہ ہے کہ گریڈینٹ بوسٹنگ میں ، درختوں کو ایک ایک کرکے تربیت دی جاتی ہے۔ ہر پچھلے درخت کو بنیادی طور پر سامنے والے درختوں کے ذریعہ غلط اعداد و شمار کی نشاندہی کرنے کی تربیت دی جاتی ہے۔ اس سے گریڈینٹ بوسٹنگ میں آسانی سے پیش گوئی کرنے والے حالات پر زیادہ توجہ دی جاتی ہے ، اور کم مشکل حالات پر زیادہ توجہ دی جاتی ہے۔
گرڈ اپ ٹریننگ بھی تیز ہے اور بہت اچھی کارکردگی کا مظاہرہ کرتی ہے۔ تاہم ، ٹریننگ ڈیٹاسیٹ میں چھوٹی چھوٹی تبدیلیاں ماڈل میں بنیادی تبدیلیاں لا سکتی ہیں ، لہذا اس کے نتیجے میں ممکنہ طور پر سب سے زیادہ قابل عمل نتائج نہیں مل سکتے ہیں۔
تیسرا ، نیورل نیٹ ورکس الگورتھم: نیورل نیٹ ورکس ایک حیاتیاتی رجحان ہے جس میں دماغ میں ایک دوسرے کے ساتھ معلومات کا تبادلہ کرنے والے مربوط نیورون ہوتے ہیں۔ یہ خیال اب مشین لرننگ کے شعبے میں بھی لاگو کیا گیا ہے ، جسے اے این این کہا جاتا ہے۔ گہری تعلیم ایک دوسرے کے اوپر پرتوں پر مشتمل نیورل نیٹ ورکس ہے۔ این این ایک ایسے ماڈل کا ایک سلسلہ ہے جو سیکھنے کے ذریعے انسانی دماغ کی طرح علمی صلاحیتوں کو حاصل کرتا ہے۔ نیورل نیٹ ورکس بہت پیچیدہ کاموں کو سنبھالنے میں اچھی کارکردگی کا مظاہرہ کرتے ہیں ، جیسے تصویر کی شناخت۔ لیکن ، جیسے انسانی دماغ ، ٹریننگ ماڈل بہت وقت لگتا ہے اور بہت زیادہ توانائی کی ضرورت ہوتی ہے۔
بگ ڈیٹا پلیٹ فارم سے نقل کیا گیا
- کیا انوینٹرز کیوٹیفیکیشن ہوبی اور اوکیکس کے ساتھ سکے کی تجارت اور یو ایس ڈی ٹی کی تجارت کی حمایت کرتا ہے؟
- ایک عوامی ادائیگی کا فنکشن جو ڈیجیٹل کرنسی ٹریڈنگ لائبریری میں ضم ہے
- کس طرح ایک حکمت عملی کے لیے زیادہ سے زیادہ فنڈنگ کی گنجائش کا حساب لگایا جائے؟ اس حکمت عملی کے لیے زیادہ سے زیادہ فنڈنگ کی گنجائش کا حساب کیسے لگایا جائے؟
- شینن کے شیطان
- یہ پیچیدہ ٹیکنالوجی نہیں ہے، یہ صرف انسانی دماغ ہے!
- Bitfinex کے انٹرفیس تک رسائی سست ہے، کیا آپ کے پاس سرور کی جگہ کے بارے میں کوئی مشورہ ہے؟
- Bitfinex ایک غلطی کے ساتھ چل رہا ہے، مدد کے لئے تجزیہ، شکریہ!
- براہ کرم بتائیں کہ API کو کال کرتے وقت حاصل کردہ ڈیٹا کس وقت کے نقطہ پر مبنی ہے؟
- اس کے علاوہ ، آپ کو اس کے بارے میں مزید جاننے کی ضرورت ہے۔
- بٹ فائنکس کے ٹریڈنگ جوڑے میں صرف چار اقسام کیوں ہیں؟ BCH_USD، BTC_USD، ETH_USD، LTC_USD
- ایک ماہ میں 5000 یوآن کی رقم کمانے کے لئے ، ایک معاہدے کے لئے زیادہ بی ٹی سی ، ایک ماہ میں 1229 اوکیکس خالی کریں!
- آخری مشاہدہ کا طریقہ کار
- بگ درج کریں: پالیسی بنانے کے دوران بغیر ڈیفالٹ پیرامیٹرز کے تعامل کے بٹن کو محفوظ کرنے میں ناکامی
- براہ کرم، کیا ریویو سسٹم دیگر کرنسیوں کو منتخب نہیں کر سکتا؟
- براہ کرم خریداری کی منصوبہ بندی کے صفحے کا ترجمہ کریں
- بٹ فائن ایکس میں تین مارکیٹیں ہیں، روبوٹ کو کس طرح منتخب کرنا ہے؟ شکریہ
- متحرک نقطہ نظر کے تحت اختیارات مشترکہ طور پر جیتتے ہیں
- bitfinex دوبارہ جانچ اور تصدیق کرنسی یونٹ متفق نہیں ہے
- کیا آپ کو لگتا ہے کہ اس طرح کی کارروائیوں سے آپ کی زندگی میں تبدیلی آئے گی؟
- BitHumb کو اکاؤنٹ کی معلومات میں خرابی