رینڈم ٹکر جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقہ کار پر بحث
مصنف:FMZ~Lydia, تخلیق: 2024-12-02 11:26:13, تازہ کاری: 2024-12-02 21:39:39
پیش لفظ
ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم کا بیک ٹیسٹنگ سسٹم ایک بیک ٹیسٹنگ سسٹم ہے جو مستقل طور پر تکرار ، اپ ڈیٹ اور اپ گریڈ ہوتا ہے۔ یہ ابتدائی بنیادی بیک ٹیسٹنگ فنکشن سے آہستہ آہستہ افعال شامل کرتا ہے اور کارکردگی کو بہتر بناتا ہے۔ پلیٹ فارم کی ترقی کے ساتھ ، بیک ٹیسٹنگ سسٹم کو بہتر اور اپ گریڈ کیا جائے گا۔ آج ہم بیک ٹیسٹنگ سسٹم پر مبنی ایک موضوع پر تبادلہ خیال کریں گے:
طلب
مقداری تجارت کے میدان میں ، حکمت عملیوں کی ترقی اور اصلاح کو حقیقی مارکیٹ کے اعداد و شمار کی تصدیق سے الگ نہیں کیا جاسکتا ہے۔ تاہم ، اصل ایپلی کیشنز میں ، مارکیٹ کے پیچیدہ اور بدلتے ہوئے ماحول کی وجہ سے ، بیک ٹسٹنگ کے لئے تاریخی اعداد و شمار پر انحصار کرنا ناکافی ہوسکتا ہے ، جیسے مارکیٹ کے انتہائی حالات یا خصوصی منظرناموں کی کوریج کا فقدان۔ لہذا ، ایک موثر بے ترتیب مارکیٹ جنریٹر ڈیزائن کرنا مقداری حکمت عملی تیار کرنے والوں کے لئے ایک موثر آلہ بن گیا ہے۔
جب ہمیں حکمت عملی کو کسی خاص تبادلے یا کرنسی پر تاریخی اعداد و شمار کا سراغ لگانے کی ضرورت ہوتی ہے تو ، ہم بیک ٹیسٹنگ کے لئے ایف ایم زیڈ پلیٹ فارم کے سرکاری ڈیٹا سورس کا استعمال کرسکتے ہیں۔ بعض اوقات ہم یہ بھی دیکھنا چاہتے ہیں کہ حکمت عملی مکمل طور پر
بے ترتیب ٹکر ڈیٹا کا استعمال کرنے کی اہمیت یہ ہے:
-
- حکمت عملیوں کی مضبوطی کا اندازہ کریں بے ترتیب ٹکر جنریٹر مختلف ممکنہ مارکیٹ کے منظرنامے تشکیل دے سکتا ہے ، بشمول انتہائی اتار چڑھاؤ ، کم اتار چڑھاؤ ، رجحان سازی والے بازار اور اتار چڑھاؤ والے بازار۔ ان نقلی ماحول میں ٹیسٹنگ کی حکمت عملی اس بات کا اندازہ کرنے میں مدد دے سکتی ہے کہ آیا ان کی کارکردگی مختلف مارکیٹ کے حالات میں مستحکم ہے۔ مثال کے طور پر:
کیا حکمت عملی رجحان اور اتار چڑھاؤ کی تبدیلی کے مطابق ہو سکتی ہے؟ کیا یہ حکمت عملی انتہائی مارکیٹ کے حالات میں بڑے نقصان کا باعث بنے گی؟
-
- حکمت عملی میں ممکنہ کمزوریوں کی شناخت کریں کچھ غیر معمولی مارکیٹ کے حالات (جیسے فرضی بلیک سوان واقعات) کا نقالی کرکے ، حکمت عملی میں ممکنہ کمزوریوں کا پتہ لگایا جاسکتا ہے اور ان کو بہتر بنایا جاسکتا ہے۔ مثال کے طور پر:
کیا یہ حکمت عملی ایک مخصوص مارکیٹ کی ساخت پر بہت زیادہ انحصار کرتی ہے؟ کیا پیرامیٹرز کو زیادہ فٹ کرنے کا خطرہ ہے؟
-
- حکمت عملی کے پیرامیٹرز کو بہتر بنانا تصادفی طور پر تیار کردہ ڈیٹا حکمت عملی کے پیرامیٹر کی اصلاح کے لئے مکمل طور پر تاریخی اعداد و شمار پر انحصار کیے بغیر ، زیادہ متنوع ٹیسٹنگ ماحول فراہم کرتا ہے۔ اس سے آپ کو حکمت عملی کی پیرامیٹر رینج کو زیادہ جامع طور پر تلاش کرنے کی اجازت ملتی ہے اور تاریخی اعداد و شمار میں مخصوص مارکیٹ کے نمونوں تک محدود ہونے سے بچنے کی اجازت ملتی ہے۔
-
- تاریخی اعداد و شمار میں خلا کو پُر کرنا کچھ مارکیٹوں میں (جیسے ابھرتے ہوئے بازاروں یا چھوٹی کرنسی ٹریڈنگ مارکیٹوں) ، تاریخی اعداد و شمار تمام ممکنہ مارکیٹ کے حالات کو ڈھکنے کے لئے کافی نہیں ہوسکتے ہیں۔ بے ترتیب ٹکر جنریٹر زیادہ جامع ٹیسٹنگ کرنے میں مدد کے ل a ایک بڑی مقدار میں اضافی اعداد و شمار فراہم کرسکتا ہے۔
-
- تیز رفتار تکراراتی ترقی ریپڈ ٹیسٹنگ کے لئے بے ترتیب اعداد و شمار کا استعمال حقیقی وقت کی مارکیٹ ٹکر حالات یا وقت طلب ڈیٹا کی صفائی اور تنظیم پر انحصار کیے بغیر حکمت عملی کی ترقی کی تکرار کو تیز کرسکتا ہے۔
تاہم ، حکمت عملی کا عقلی انداز میں بھی جائزہ لینا ضروری ہے۔ تصادفی طور پر تیار کردہ ٹکر ڈیٹا کے ل please ، براہ کرم نوٹ کریں:
-
- اگرچہ بے ترتیب مارکیٹ جنریٹر مفید ہیں، ان کی اہمیت پیدا کردہ اعداد و شمار کے معیار اور ہدف منظر نامے کے ڈیزائن پر منحصر ہے:
-
- پیداوار کی منطق کو حقیقی مارکیٹ کے قریب ہونے کی ضرورت ہے۔ اگر تصادفی طور پر تیار کردہ مارکیٹ حقیقت سے مکمل طور پر رابطہ سے باہر ہے تو ، ٹیسٹ کے نتائج میں ریفرنس ویلیو کی کمی ہوسکتی ہے۔ مثال کے طور پر ، جنریٹر کو اصل مارکیٹ کے شماریاتی خصوصیات (جیسے اتار چڑھاؤ کی تقسیم ، رجحان تناسب) کی بنیاد پر ڈیزائن کیا جاسکتا ہے۔
-
- یہ حقیقی ڈیٹا ٹیسٹنگ کو مکمل طور پر تبدیل نہیں کرسکتا: بے ترتیب ڈیٹا صرف حکمت عملیوں کی ترقی اور اصلاح کی تکمیل کرسکتا ہے۔ حتمی حکمت عملی کو ابھی بھی حقیقی مارکیٹ کے اعداد و شمار میں اس کی تاثیر کی تصدیق کی ضرورت ہے۔
اتنا کہہ کر ، ہم کچھ ڈیٹا کو کیسے
ڈیزائن کے خیالات
یہ مضمون بحث کے لئے ایک نقطہ اغاز فراہم کرنے کے لئے ڈیزائن کیا گیا ہے اور نسبتا simple آسان بے ترتیب ٹکر جنریشن حساب فراہم کرتا ہے۔ در حقیقت ، متعدد تخروپن الگورتھم ، ڈیٹا ماڈل اور دیگر ٹیکنالوجیز ہیں جن کو لاگو کیا جاسکتا ہے۔ بحث کی محدود جگہ کی وجہ سے ، ہم پیچیدہ ڈیٹا تخروپن کے طریقوں کا استعمال نہیں کریں گے۔
پلیٹ فارم بیک ٹیسٹنگ سسٹم کے کسٹم ڈیٹا سورس فنکشن کو ملا کر، ہم نے پائتھون میں ایک پروگرام لکھا۔
-
- K لائن کے اعداد و شمار کا ایک سیٹ تصادفی طور پر تیار کریں اور انہیں مستقل ریکارڈنگ کے لئے CSV فائل میں لکھیں ، تاکہ تیار کردہ ڈیٹا کو محفوظ کیا جاسکے۔
-
- پھر بیک ٹسٹنگ سسٹم کے لیے ڈیٹا سورس سپورٹ فراہم کرنے کے لیے ایک سروس بنائیں۔
-
- چارٹ میں پیدا کردہ K لائن ڈیٹا دکھائیں.
کچھ نسل کے معیارات اور K لائن کے اعداد و شمار کے فائل اسٹوریج کے لئے مندرجہ ذیل پیرامیٹر کنٹرولز کی وضاحت کی جاسکتی ہے:
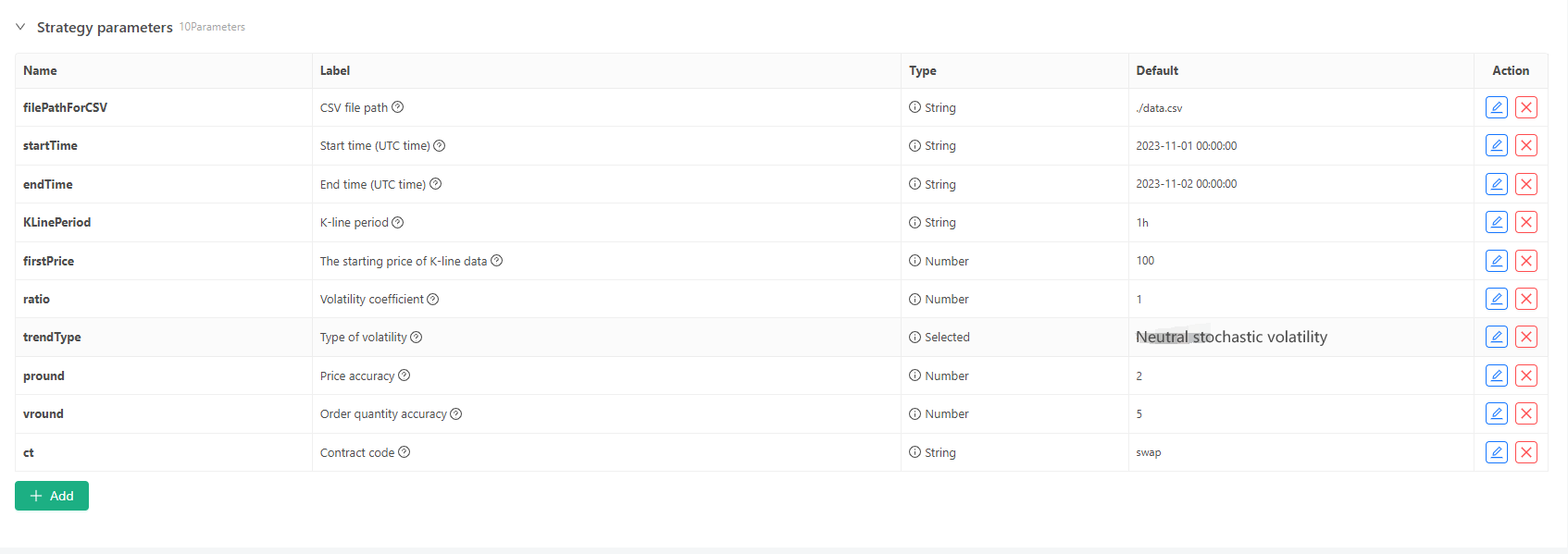
-
اعداد و شمار کی پیداوار کا بے ترتیب موڈ K لائن کے اعداد و شمار کی اتار چڑھاؤ کی قسم کی نقالی کے لئے ، مثبت اور منفی بے ترتیب نمبروں کے امکان کا استعمال کرتے ہوئے ایک سادہ ڈیزائن بنایا جاتا ہے۔ جب تیار کردہ اعداد و شمار بہت زیادہ نہیں ہوتے ہیں تو ، یہ مطلوبہ مارکیٹ پیٹرن کی عکاسی نہیں کرسکتا ہے۔ اگر کوئی بہتر طریقہ موجود ہے تو ، کوڈ کے اس حصے کو تبدیل کیا جاسکتا ہے۔ اس سادہ ڈیزائن کی بنیاد پر ، بے ترتیب تعداد کی نسل کی حد کو ایڈجسٹ کرنا اور کوڈ میں کچھ گتانک پیدا کردہ ڈیٹا اثر کو متاثر کرسکتے ہیں۔
-
ڈیٹا کی تصدیق پیدا کردہ K- لائن کے اعداد و شمار کو عقلانیت کے لئے بھی جانچنے کی ضرورت ہے ، یہ چیک کرنے کے لئے کہ آیا اعلی افتتاحی اور کم اختتامی قیمتیں تعریف کی خلاف ورزی کرتی ہیں ، اور K- لائن کے اعداد و شمار کی تسلسل کی جانچ کرنا ہے۔
بیک ٹیسٹنگ سسٹم رینڈم ٹکر جنریٹر
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
بیک ٹسٹنگ سسٹم میں پریکٹس
- مندرجہ بالا حکمت عملی مثال بنائیں، پیرامیٹرز کو ترتیب دیں، اور اسے چلائیں.
- لائیو ٹریڈنگ (اسٹریٹیجی مثال) کو سرور پر تعینات ڈوکر پر چلانے کی ضرورت ہے ، اسے عوامی نیٹ ورک آئی پی کی ضرورت ہے ، تاکہ بیک ٹیسٹنگ سسٹم اس تک رسائی حاصل کرسکے اور ڈیٹا حاصل کرسکے۔
- بات چیت کے بٹن پر کلک کریں، اور حکمت عملی خود کار طریقے سے بے ترتیب ٹکر ڈیٹا پیدا کرنے کے لئے شروع ہو جائے گا.
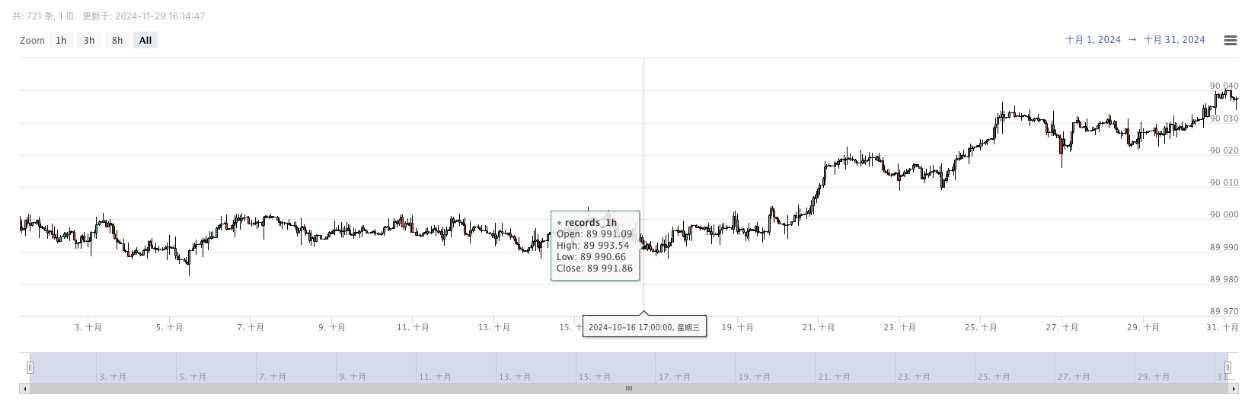
- پیدا کردہ اعداد و شمار کو آسانی سے مشاہدے کے لئے چارٹ پر دکھایا جائے گا، اور اعداد و شمار کو مقامی data.csv فائل میں ریکارڈ کیا جائے گا.
- اب ہم ان بے ترتیب پیدا اعداد و شمار کا استعمال کر سکتے ہیں اور بیک ٹیسٹنگ کے لئے کسی بھی حکمت عملی کا استعمال کر سکتے ہیں:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
مندرجہ بالا معلومات کے مطابق، تشکیل اور ایڈجسٹ.http://xxx.xxx.xxx.xxx:9090سرور کا آئی پی ایڈریس اور بے ترتیب ٹکر جنریشن کی حکمت عملی کی کھلی بندرگاہ ہے۔
یہ اپنی مرضی کے مطابق ڈیٹا ماخذ ہے ، جو پلیٹ فارم API دستاویز کے کسٹم ڈیٹا ماخذ سیکشن میں پایا جاسکتا ہے۔
- بیک ٹیسٹ سسٹم کے اعداد و شمار کے ذریعہ قائم کرنے کے بعد، ہم بے ترتیب مارکیٹ کے اعداد و شمار کی جانچ کر سکتے ہیں:
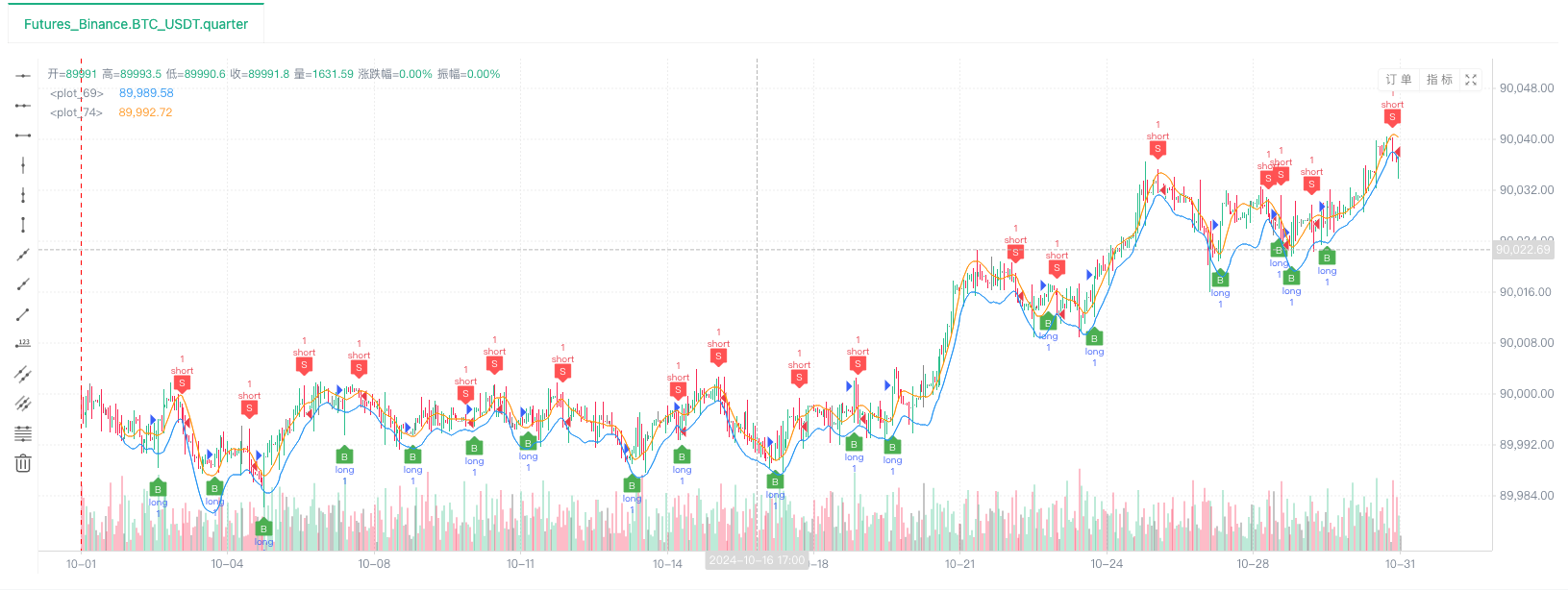
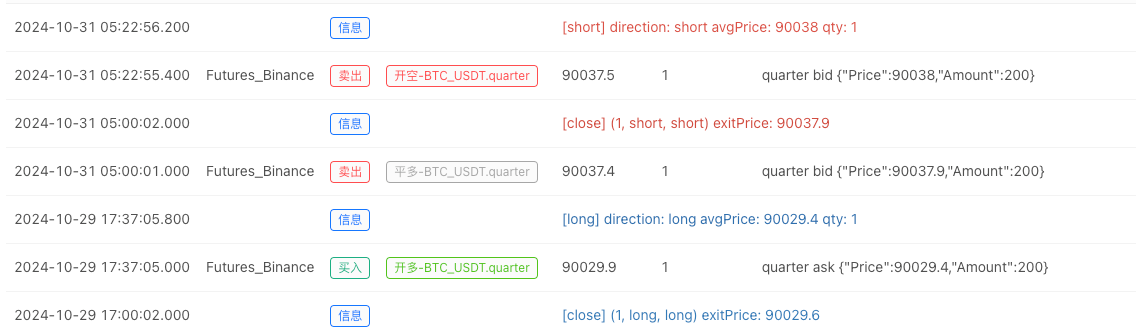
اس وقت ، بیک ٹیسٹ سسٹم کو ہمارے
- اوہ ، ہاں ، میں اس کا ذکر کرنا بھول گیا تھا۔ بے ترتیب ٹکر جنریٹر کا یہ پائیتھون پروگرام لائیو ٹریڈنگ کی تخلیق کی وجہ پیدا شدہ K لائن ڈیٹا کی نمائش ، آپریشن اور نمائش میں سہولت فراہم کرنا ہے۔ اصل درخواست میں ، آپ آزاد پائیتھون اسکرپٹ لکھ سکتے ہیں ، لہذا آپ کو لائیو ٹریڈنگ چلانے کی ضرورت نہیں ہے۔
حکمت عملی کا ماخذ کوڈ:بیک ٹیسٹنگ سسٹم رینڈم ٹکر جنریٹر
آپ کی حمایت اور پڑھنے کے لئے شکریہ.
- ڈی ای ایکس ایکسچینج کی کوانٹیٹیشن پریکٹس ((1) -- dYdX v4 استعمال کرنے کا رہنما
- ڈیجیٹل کرنسیوں میں لیڈ لیگ سوٹ کا تعارف (3)
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (2)
- ڈیجیٹل کرنسیوں میں لیڈ لیگ سوٹ کا تعارف ((2)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر بحث: حکمت عملی میں بلٹ ان ایچ ٹی پی سروس کے ساتھ سگنل وصول کرنے کے لئے ایک مکمل حل
- ایف ایم زیڈ پلیٹ فارم کے بیرونی سگنل وصول کرنے کا جائزہ: حکمت عملی بلٹ میں HTTP سروس سگنل وصول کرنے کا مکمل نظام
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (1)
- ڈیجیٹل کرنسی میں لیڈ لیگ سوٹ کا تعارف ((1)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر تبادلہ خیال: توسیع شدہ اے پی آئی بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- ایف ایم زیڈ پلیٹ فارم کے لئے بیرونی سگنل وصول کرنے کا جائزہ: توسیع API بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- بے ترتیب مارکیٹ جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقوں کا جائزہ
- ایف ایم زیڈ کوانٹ کی نئی خصوصیت: آسانی سے ایچ ٹی ٹی پی سروسز بنانے کے لئے _Serve فنکشن کا استعمال کریں
- ایجاد کاروں کی طرف سے نئی خصوصیات کو مقدار میں بڑھانا: _Serve فنکشن کا استعمال کرتے ہوئے آسانی سے HTTP سروسز بنائیں
- FMZ کوانٹ ٹریڈنگ پلیٹ فارم کسٹم پروٹوکول رسائی گائیڈ
- ایف ایم زیڈ فنڈنگ ریٹ حصول اور نگرانی کی حکمت عملی
- ایف ایم زیڈ فنڈز کی شرح کے حصول اور نگرانی کی حکمت عملی
- ایک حکمت عملی ٹیمپلیٹ آپ WebSocket مارکیٹ ہموار استعمال کرنے کی اجازت دیتا ہے
- ایک حکمت عملی ٹیمپلیٹ آپ کو ویب ساکٹ کے شعبے کو بغیر کسی رکاوٹ کے استعمال کرنے کی اجازت دیتا ہے
- ایجاد کنندہ کوالٹی ٹرانزیکشن پلیٹ فارم کے لئے جنرل پروٹوکول تک رسائی کی رہنمائی
- ایف ایم زیڈ اپ گریڈ کے بعد فوری طور پر ایک یونیورسل ملٹی کرنسی ٹریڈنگ کی حکمت عملی کی تعمیر کیسے کریں