نیورل نیٹ ورکس اور ڈیجیٹل کرنسی کوانٹیٹیٹو ٹریڈنگ سیریز (2) - انتہائی سیکھنے اور تربیت بٹکوئن ٹریڈنگ کی حکمت عملی
مصنف:FMZ~Lydia, تخلیق: 2023-01-12 16:49:09, تازہ کاری: 2024-12-19 21:09:28
نیورل نیٹ ورکس اور ڈیجیٹل کرنسی کوانٹیٹیٹو ٹریڈنگ سیریز (2) - انتہائی سیکھنے اور تربیت بٹکوئن ٹریڈنگ کی حکمت عملی
1. تعارف
پچھلے مضمون میں، ہم نے بٹ کوائن کی قیمت کی پیشن گوئی کرنے کے لئے ایل ایس ٹی ایم نیٹ ورک کے استعمال کا تعارف کرایا:https://www.fmz.com/bbs-topic/9879، جیسا کہ مضمون میں ذکر کیا گیا ہے ، یہ صرف آر این این اور پائی ٹورچ سے واقفیت حاصل کرنے کے لئے ایک چھوٹا سا تربیتی منصوبہ ہے۔ اس مضمون میں تجارتی حکمت عملیوں کو براہ راست تربیت دینے کے لئے انتہائی سیکھنے کے استعمال کا تعارف کرایا جائے گا۔ انتہائی سیکھنے کا ماڈل اوپن اے آئی اوپن سورس پی پی او ہے ، اور ماحول جم کے انداز سے مراد ہے۔ سمجھنے اور جانچ کی سہولت کے ل LS ، ایل ایس ٹی ایم کا پی پی او ماڈل اور بیک ٹیسٹنگ کے لئے جم کا ماحول تیار پیکجوں کے استعمال کے بغیر براہ راست لکھا جاتا ہے۔ پی پی او ، یا قریبی پالیسی کی اصلاح ، پالیسی گریڈیئنٹ کی اصلاح کی بہتری ہے۔ جم کو اوپن اے آئی نے بھی جاری کیا تھا۔ یہ حکمت عملی کے نیٹ ورک کے ساتھ بات چیت کرسکتا ہے اور موجودہ ماحول کی حیثیت اور انعامات کو فیڈ بیک کرسکتا ہے۔ یہ انتہائی سیکھنے کی مشق کی طرح ہے۔ یہ ایل ایس ٹی ایم کے پی پی او ماڈل کا استعمال براہ راست مارکیٹ کی معلومات کے مطابق ہدایات بنانے کے لئے کرتا ہے ، جیسے بٹ کوائن کی خریداری ، فروخت یا کوئی آپریشن نہیں۔ بیک ٹیسٹ ماحول کی طرف سے فیڈ بیک دیا جاتا ہے۔ تربیت کے ذریعے ، ماڈل کو اسٹریٹجک منافع کے مقصد کو حاصل کرنے کے لئے مستقل طور پر بہتر بنایا جاتا ہے۔ اس مضمون کو پڑھنے کے لئے پائیتھون ، پائیٹورچ اور ڈی آر ایل میں گہرائی سے گہری سیکھنے کی ایک خاص بنیاد کی ضرورت ہے۔ لیکن اس سے کوئی فرق نہیں پڑتا ہے اگر آپ نہیں کرسکتے ہیں۔ اس مضمون میں دیئے گئے کوڈ کے ساتھ سیکھنا اور شروع کرنا آسان ہے۔ یہ سبق ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم کے ذریعہ تیار کیا گیا ہے (www.fmz.com) ، QQ گروپ میں شامل ہونے کے لئے خوش آمدید: 863946592 مواصلات کے لئے.
اعداد و شمار اور سیکھنے کے حوالہ جات
بٹ کوائن کی قیمت کا ڈیٹا ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم سے حاصل کیا گیا ہے:https://www.quantinfo.com/Tools/View/4.html. تجارتی حکمت عملیوں کو تربیت دینے کے لئے ڈی آر ایل + جم کا استعمال کرتے ہوئے ایک مضمون:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4. پائیٹورچ کے ساتھ شروع کرنے کے لئے کچھ مثالیں:https://github.com/yunjey/pytorch-tutorial. یہ مضمون LSTM-PPO ماڈل کے ذریعے براہ راست لاگو کرے گا:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py. پی پی او کے بارے میں مضامین:https://zhuanlan.zhihu.com/p/38185553. ڈی آر ایل کے بارے میں مزید مضامین:https://www.zhihu.com/people/flood-sung/posts. جم کے بارے میں، اس مضمون میں تنصیب کی ضرورت نہیں ہے، لیکن یہ انتہائی سیکھنے میں بہت عام ہے:https://gym.openai.com/.
3۔ LSTM-PPO
پی پی او کی گہرائی سے وضاحت کے ل you ، آپ پچھلے حوالہ جات کے مواد سے سیکھ سکتے ہیں۔ یہاں صرف تصورات کا ایک سادہ تعارف ہے۔ ایل ایس ٹی ایم نیٹ ورک کے آخری شمارے میں صرف قیمت کی پیش گوئی کی گئی تھی۔ پیش گوئی کی قیمت کی بنیاد پر خرید و فروخت کا طریقہ الگ سے سمجھنا ہوگا۔ یہ سوچنا فطری ہے کہ تجارتی عمل کی براہ راست آؤٹ پٹ زیادہ براہ راست ہوگی۔ یہ پالیسی گریڈیئنٹ کا معاملہ ہے ، جو ان پٹ ماحولیاتی معلومات کے مطابق مختلف اقدامات کا امکان دے سکتا ہے۔ ایل ایس ٹی ایم کا نقصان متوقع قیمت اور اصل قیمت کے درمیان فرق ہے ، جبکہ پی جی کا نقصان - لاگ § * کیو ہے ، جہاں پی ایک آؤٹ پٹ کارروائی کا امکان ہے ، اور کیو کارروائی کی قدر ہے (جیسے انعام اسکور) ۔ وضاحت یہ ہے کہ اگر کسی کارروائی کی قیمت زیادہ ہے تو ، نیٹ ورک کو نقصان کو کم کرنے کے لئے ایک اہم عنصر ہونا چاہئے۔ اگرچہ پی پی او زیادہ پیچیدہ ہے ، اس کا اصول اس سے کہیں زیادہ ہے کہ ہر کارروائی کے آؤٹ پٹ ویلیو کو بہتر اندازہ لگانا اور اپ ڈیٹ
LSTM-PPO کا ماخذ کوڈ ذیل میں دیا گیا ہے، جسے پچھلے اعداد و شمار کے ساتھ مل کر سمجھا جا سکتا ہے:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. بٹ کوائن بیک ٹسٹنگ ماحول
جم کے فارمیٹ کے بعد ، ری سیٹ انیشیلائزیشن کا طریقہ موجود ہے۔ قدم عمل کو ان پٹ کرتا ہے ، اور واپسی کا نتیجہ یہ ہے (اگلی حیثیت ، عمل کی آمدنی ، ختم ہونے یا نہ ہونے کی ، اضافی معلومات) ۔ پورے بیک ٹیسٹ ماحول میں بھی 60 لائنیں ہیں۔ آپ خود ہی زیادہ پیچیدہ ورژن میں ترمیم کرسکتے ہیں۔ مخصوص کوڈ یہ ہے:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
۵. کئی قابل ذکر تفصیلات
- ابتدائی اکاؤنٹ میں کرنسی کیوں ہے؟
بیک ٹیسٹ ماحول کی واپسی کا حساب لگانے کا فارمولا یہ ہے: موجودہ واپسی = موجودہ اکاؤنٹ کی قیمت - ابتدائی اکاؤنٹ کی موجودہ قیمت۔ اس کا مطلب یہ ہے کہ اگر بٹ کوائن کی قیمت میں کمی واقع ہوتی ہے اور حکمت عملی سکوں کی فروخت کی کارروائی کرتی ہے تو ، یہاں تک کہ اگر کل اکاؤنٹ کی قیمت میں کمی واقع ہوتی ہے تو ، حکمت عملی کو اصل میں انعام دیا جانا چاہئے۔ اگر بیک ٹیسٹ میں زیادہ وقت لگتا ہے تو ، ابتدائی اکاؤنٹ کا کم اثر پڑ سکتا ہے ، لیکن اس کا آغاز میں بہت زیادہ اثر پڑے گا۔ نسبتا return واپسی کا حساب لگانے سے یہ یقینی بنتا ہے کہ ہر صحیح کارروائی سے مثبت انعام ملے گا۔
- تربیت کے دوران مارکیٹ کا نمونہ کیوں لیا گیا؟
اعداد و شمار کی کل مقدار 10،000 K لائنوں سے زیادہ ہے۔ اگر آپ ہر بار مکمل طور پر لوپ چلاتے ہیں تو ، اس میں بہت وقت لگے گا ، اور حکمت عملی کو ہر بار ایک ہی صورتحال کا سامنا کرنا پڑتا ہے ، تو زیادہ فٹ ہونا آسان ہوسکتا ہے۔ بیک ٹیسٹ کے طور پر ایک وقت میں 500 بار لینا۔ اگرچہ اب بھی زیادہ فٹ ہونا ممکن ہے ، حکمت عملی کو 10،000 سے زیادہ مختلف ممکنہ آغاز کا سامنا کرنا پڑتا ہے۔
- اگر کوئی کرنسی یا پیسہ نہ ہو تو کیا ہوگا؟
اس صورتحال کو بیک ٹسٹ ماحول میں نہیں سمجھا جاتا ہے۔ اگر کرنسی فروخت ہوچکی ہے یا کم سے کم تجارتی مقدار تک نہیں پہنچ سکتی ہے تو ، پھر فروخت کا عمل اصل میں غیر آپریشن کے برابر ہے۔ اگر قیمت کم ہوتی ہے تو ، نسبتا return واپسی کے حساب کتاب کے طریقہ کار کے مطابق ، یہ پھر بھی اسٹریٹجک مثبت واپسی پر مبنی ہے۔ اس صورتحال کا اثر یہ ہے کہ جب حکمت عملی کا فیصلہ ہوتا ہے کہ مارکیٹ کم ہو رہی ہے اور اکاؤنٹ کی باقی کرنسی فروخت نہیں کی جاسکتی ہے تو ، فروخت کی کارروائی کو غیر آپریٹنگ کارروائی سے ممتاز کرنا ناممکن ہے ، لیکن اس کا مارکیٹ پر حکمت عملی کے فیصلے پر کوئی اثر نہیں پڑتا ہے۔
- مجھے اکاؤنٹ کی معلومات کو حیثیت کے طور پر کیوں واپس کرنا چاہئے؟
پی پی او ماڈل میں موجودہ حیثیت کی قدر کا اندازہ کرنے کے لئے ایک ویلیو نیٹ ورک ہے۔ ظاہر ہے ، اگر حکمت عملی کا فیصلہ ہے کہ قیمت میں اضافہ ہوگا تو ، پوری حیثیت کی مثبت قدر صرف اس وقت ہوگی جب کرنٹ اکاؤنٹ میں بٹ کوائن موجود ہو ، اور اس کے برعکس۔ لہذا ، اکاؤنٹ کی معلومات ویلیو نیٹ ورک کی تشخیص کی ایک اہم بنیاد ہے۔ یہ نوٹ کیا گیا ہے کہ ماضی کی کارروائی کی معلومات کو حیثیت کے طور پر واپس نہیں کیا جاتا ہے۔ مجھے لگتا ہے کہ قدر کا فیصلہ کرنا بیکار ہے۔
- یہ کب غیر آپریشن میں واپس آ جائے گا؟
جب حکمت عملی کا فیصلہ ہوتا ہے کہ ٹرانزیکشن کے ذریعہ لائی گئی واپسی ہینڈلنگ فیس کو پورا نہیں کرسکتی ہے تو ، اسے غیر آپریشن میں واپس آنا چاہئے۔ اگرچہ پچھلی تفصیل قیمت کے رجحان کا فیصلہ کرنے کے لئے بار بار حکمت عملیوں کا استعمال کرتی ہے ، لیکن یہ صرف تفہیم کی سہولت کے لئے ہے۔ در حقیقت ، یہ پی پی او ماڈل مارکیٹ کی پیش گوئی نہیں کرتا ہے ، بلکہ صرف تین اقدامات کا امکان نکالتا ہے۔
ڈیٹا اکٹھا کرنا اور تربیت
جیسا کہ پچھلے مضمون میں ، ڈیٹا اکٹھا کرنے کا طریقہ اور شکل مندرجہ ذیل ہے۔ Bitfinex Exchange BTC_USD ٹریڈنگ جوڑی کی ایک گھنٹے کی مدت K لائن 7 مئی 2018 سے 27 جون 2019 تک:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
ایل ایس ٹی ایم نیٹ ورک کے استعمال کی وجہ سے ، تربیت کا وقت بہت لمبا ہے۔ میں نے جی پی یو ورژن میں تبدیل کیا ، جو تقریبا three تین گنا تیز ہے۔
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
تربیت کے نتائج اور تجزیہ
طویل انتظار کے بعد:

سب سے پہلے ، تربیت کے اعداد و شمار کی مارکیٹ پر ایک نظر ڈالیں۔ عام طور پر ، پہلی ششماہی ایک طویل عرصے سے کمی ہے ، اور دوسری ششماہی ایک مضبوط عروج ہے۔
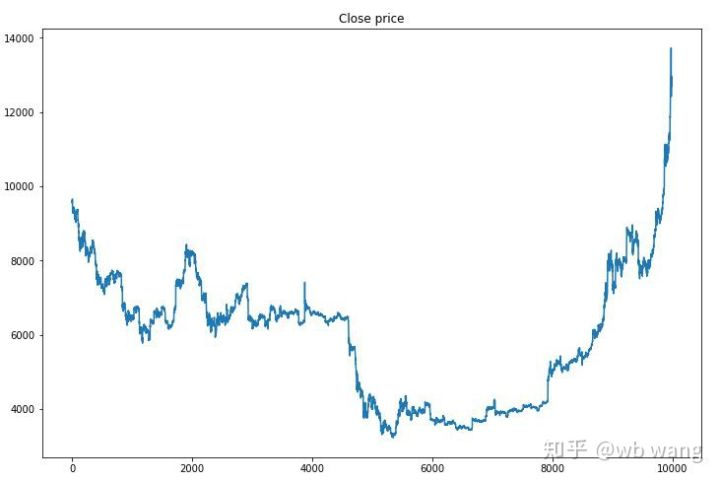
تربیت کے ابتدائی مرحلے میں بہت سارے خریداری کے عمل ہوتے ہیں ، اور بنیادی طور پر کوئی منافع بخش راؤنڈ نہیں ہوتا ہے۔ تربیت کے وسط تک ، خریداری کا عمل بتدریج کم ہو گیا ہے ، اور منافع کا امکان بھی بڑھ رہا ہے ، لیکن پھر بھی نقصان کا ایک بہت بڑا امکان ہے۔
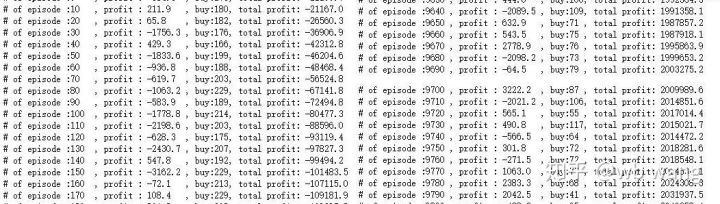
ہر راؤنڈ کے منافع کو ہموار کریں، اور نتیجہ مندرجہ ذیل ہے:
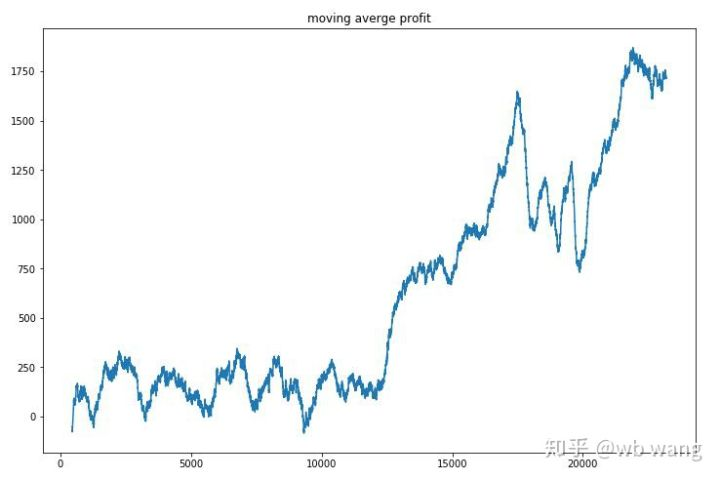
اس حکمت عملی نے تیزی سے اس صورتحال سے چھٹکارا پایا کہ ابتدائی واپسی منفی تھی ، لیکن اتار چڑھاؤ بہت زیادہ تھا۔ واپسی 10،000 راؤنڈ کے بعد تک تیزی سے نہیں بڑھی۔ عام طور پر ، ماڈل کی تربیت بہت مشکل تھی۔
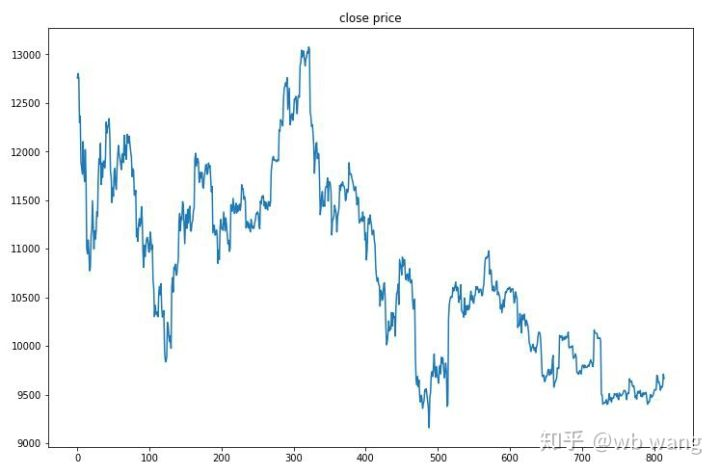
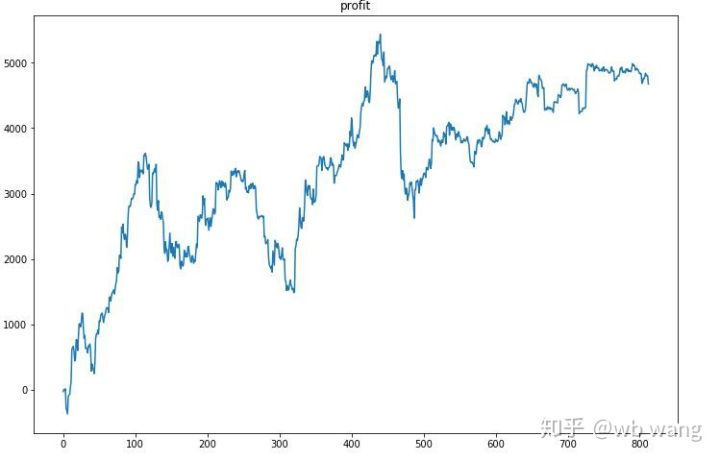
آخری تربیت کے بعد ، ماڈل کو تمام اعداد و شمار کو دوبارہ چلانے دیں تاکہ یہ معلوم ہو سکے کہ یہ کس طرح کام کرتا ہے۔ اس مدت کے دوران ، اکاؤنٹ کی کل مارکیٹ ویلیو ، بٹکوئن کی تعداد ، بٹکوئن ویلیو کا تناسب اور کل منافع کو ریکارڈ کریں۔ سب سے پہلے کل مارکیٹ ویلیو ہے، اور کل منافع اسی طرح ہے، وہ پوسٹ نہیں کیا جائے گا:
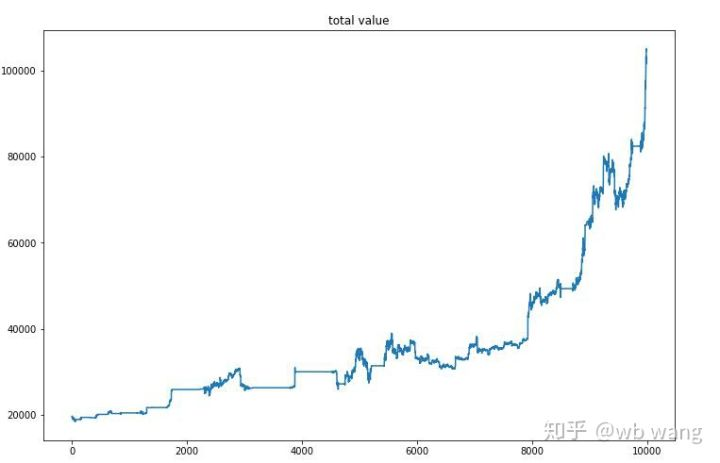
ابتدائی ریچھ مارکیٹ میں مجموعی مارکیٹ ویلیو میں آہستہ آہستہ اضافہ ہوا، اور بعد میں بیل مارکیٹ میں اضافے کے ساتھ ہی رہا، لیکن پھر بھی وقتا فوقتا نقصانات ہوئے۔
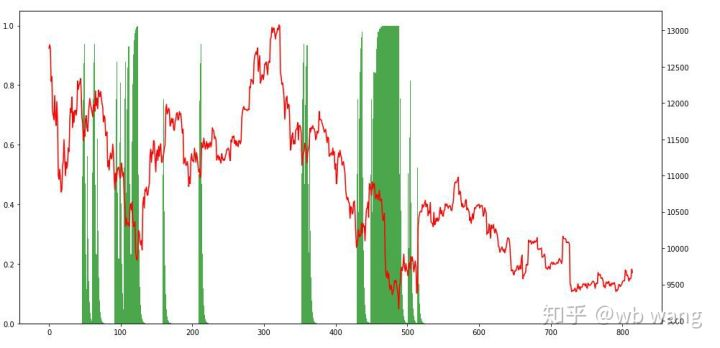
آخر میں ، پوزیشنوں کے تناسب پر ایک نظر ڈالیں۔ چارٹ کا بائیں محور پوزیشنوں کا تناسب ہے ، اور دائیں محور مارکیٹ ہے۔ یہ ابتدائی طور پر فیصلہ کیا جاسکتا ہے کہ ماڈل زیادہ فٹ ہے۔ پوزیشنوں کی تعدد ابتدائی ریچھ مارکیٹ میں کم ہے ، اور مارکیٹ کے نچلے حصے میں زیادہ ہے۔ یہ بھی دیکھا جاسکتا ہے کہ ماڈل نے طویل مدتی پوزیشنوں کو برقرار رکھنا نہیں سیکھا ہے اور ہمیشہ تیزی سے فروخت کرتا ہے۔
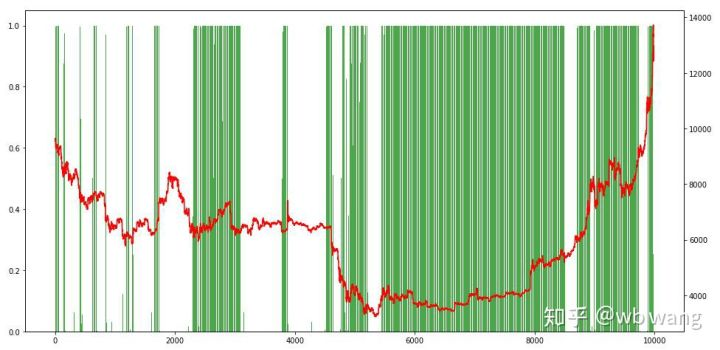
8. ٹیسٹ ڈیٹا کا تجزیہ
27 جون 2019 سے اب تک بٹ کوائن کی ایک گھنٹے کی مارکیٹ ٹیسٹ کے اعداد و شمار سے حاصل کی گئی تھی۔ چارٹ سے دیکھا جاسکتا ہے کہ قیمت 13،000 ڈالر سے گر کر 9،000 ڈالر سے زیادہ ہوگئی ہے ، جو ماڈل کے لئے ایک بہت بڑا ٹیسٹ ہے۔
سب سے پہلے، حتمی رشتہ دار واپسی نے ایسا ہی کیا، لیکن کوئی نقصان نہیں تھا.
پوزیشن کی صورتحال کو دیکھتے ہوئے ، ہم اندازہ لگا سکتے ہیں کہ ماڈل میں تیزی سے گرنے کے بعد خریدنے اور ری باؤنڈ کے بعد فروخت کرنے کا رجحان ہے۔ حالیہ عرصے میں بٹ کوائن کی مارکیٹ میں بہت کم اتار چڑھاؤ ہوا ہے ، اور ماڈل مختصر پوزیشن میں رہا ہے۔
9. خلاصہ
اس مقالے میں ، ایک بٹ کوائن خودکار ٹریڈنگ روبوٹ کو پی پی او کی مدد سے تربیت دی جاتی ہے ، جو ایک گہری گہرائی سے سیکھنے کا طریقہ ہے ، اور کچھ نتائج اخذ کیے جاتے ہیں۔ محدود وقت کی وجہ سے ، ماڈل میں ابھی بھی کچھ پہلوؤں میں بہتری لائی جاسکتی ہے۔ بحث کا خیرمقدم کرتے ہیں۔ سب سے بڑا سبق یہ ہے کہ ڈیٹا معیاری کاری کے طریقہ کار کے لئے ، اسکیلنگ اور دیگر طریقوں کا استعمال نہ کریں ، ورنہ ماڈل تیزی سے قیمت اور مارکیٹ کے مابین تعلقات کو یاد رکھے گا ، اور اوور فٹنگ میں گر جائے گا۔ معیاری شرح تبدیلی نسبتا data اعداد و شمار ہے ، جس سے ماڈل کے لئے مارکیٹ کے ساتھ تعلقات کو یاد رکھنا مشکل ہوجاتا ہے ، اور اسے شرح تبدیلی اور اضافے اور کمی کے مابین تعلق تلاش کرنے پر مجبور کیا جاتا ہے۔
پچھلے مضامین کا تعارف: ایک اعلی تعدد کی حکمت عملی میں نے انکشاف کیا کہ ایک بار بہت منافع بخش تھا:https://www.fmz.com/bbs-topic/9886.
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (2)
- ڈیجیٹل کرنسیوں میں لیڈ لیگ سوٹ کا تعارف ((2)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر بحث: حکمت عملی میں بلٹ ان ایچ ٹی پی سروس کے ساتھ سگنل وصول کرنے کے لئے ایک مکمل حل
- ایف ایم زیڈ پلیٹ فارم کے بیرونی سگنل وصول کرنے کا جائزہ: حکمت عملی بلٹ میں HTTP سروس سگنل وصول کرنے کا مکمل نظام
- کریپٹوکرنسی میں لیڈ لیگ اربیٹریج کا تعارف (1)
- ڈیجیٹل کرنسی میں لیڈ لیگ سوٹ کا تعارف ((1)
- ایف ایم زیڈ پلیٹ فارم کی بیرونی سگنل وصولی پر تبادلہ خیال: توسیع شدہ اے پی آئی بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- ایف ایم زیڈ پلیٹ فارم کے لئے بیرونی سگنل وصول کرنے کا جائزہ: توسیع API بمقابلہ حکمت عملی بلٹ ان HTTP سروس
- رینڈم ٹکر جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقہ کار پر بحث
- بے ترتیب مارکیٹ جنریٹر پر مبنی حکمت عملی ٹیسٹنگ کے طریقوں کا جائزہ
- ایف ایم زیڈ کوانٹ کی نئی خصوصیت: آسانی سے ایچ ٹی ٹی پی سروسز بنانے کے لئے _Serve فنکشن کا استعمال کریں
- مقداری تجارت میں تین ممکنہ ماڈل
- پییوٹ پوائنٹ انٹرا ڈے ٹریڈنگ سسٹم
- ڈیجیٹل کرنسی کی کوانٹیٹیو ٹریڈنگ میں ابتدائیوں کے لئے 6 آسان حکمت عملی اور طریق کار
- اوسط حقیقی رینج کا حکمت عملی فریم ورک
- ایف ایم زیڈ کوانٹ پلیٹ فارم پر ترموسٹیٹ کی حکمت عملی کا عمل اور اطلاق
- باکس تھیوری پر مبنی تجارتی حکمت عملی، خام مال کے مستقبل اور ڈیجیٹل کرنسی کی حمایت
- قیمت پر مبنی نسبتا طاقت مقداری تجارتی حکمت عملی
- تجارتی حجم کے وزن والے انڈیکس کا استعمال کرتے ہوئے تجارتی حکمت عملی
- ایف ایم زیڈ کوانٹ ٹریڈنگ پلیٹ فارم پر پی بی ایکس ٹریڈنگ حکمت عملی کا نفاذ اور اطلاق
- دیر سے شیئرنگ: بٹ کوائن ہائی فریکوئینسی روبوٹ جس میں 2014 میں روزانہ 5 فیصد واپسی ہوتی ہے
- نیورل نیٹ ورکس اور ڈیجیٹل کرنسی کی کوانٹیٹیٹو ٹریڈنگ سیریز (1) - LSTM Bitcoin قیمت کی پیش گوئی کرتا ہے
- ایس ایم اے اور آر ایس آئی رشتہ دار طاقت انڈیکس کی مجموعی حکمت عملی کا اطلاق
- سی ٹی اے کی حکمت عملی اور ایف ایم زیڈ کوانٹ پلیٹ فارم کی معیاری کلاس لائبریری کی ترقی
- پیتھون میں قیمت کی رفتار تجزیہ کے ساتھ مقداری تجارتی حکمت عملی
- پیتھون میں ڈبل تھرو ڈیجیٹل کرنسی کی کوانٹیٹیٹیو ٹریڈنگ کی حکمت عملی کو نافذ کریں
- لینکس ڈوکر کے لئے انسٹال اور اپ گریڈ کرنے کا بہترین طریقہ
- طویل مختصر پوزیشنوں کے لیے متوازن ایکویٹی حکمت عملیوں کو منظم طریقے سے سیدھ میں لانا
- ٹائم سیریز ڈیٹا تجزیہ اور ٹِک ڈیٹا بیک ٹیسٹنگ
- ڈیجیٹل کرنسی مارکیٹ کا مقداری تجزیہ
- ڈیٹا پر مبنی ٹیکنالوجی پر مبنی جوڑی ٹریڈنگ