Máy học 8 thuật toán lớn so sánh
Tác giả:Những nhà phát minh định lượng - những giấc mơ nhỏ, Tạo: 2016-12-05 10:42:02, Cập nhật:Máy học 8 thuật toán lớn so sánh
Bài viết này chủ yếu xem xét các kịch bản thích nghi và những ưu điểm và nhược điểm của một số thuật toán phổ biến sau!
Có quá nhiều thuật toán học máy, phân loại, hồi quy, phân loại, khuyến nghị, nhận dạng hình ảnh, v.v. và rất khó để tìm ra một thuật toán phù hợp, vì vậy trong các ứng dụng thực tế, chúng tôi thường thử nghiệm bằng cách học theo cách truyền cảm hứng.
Thông thường, chúng ta sẽ bắt đầu bằng cách chọn các thuật toán phổ biến như SVM, GBDT, Adaboost, và giờ đây, việc học sâu rất nóng bỏng và mạng thần kinh cũng là một lựa chọn tốt.
Nếu bạn quan tâm đến độ chính xác, cách tốt nhất là kiểm tra từng thuật toán một cách riêng biệt bằng cách kiểm chứng chéo, so sánh, và sau đó điều chỉnh các tham số để đảm bảo mỗi thuật toán đạt được tối ưu nhất, cuối cùng chọn một trong những tốt nhất.
Nhưng nếu bạn chỉ đang tìm kiếm một thuật toán đủ tốt để giải quyết vấn đề của bạn, hoặc đây là một số mẹo để tham khảo, dưới đây là phân tích các ưu điểm và nhược điểm của mỗi thuật toán, dựa trên ưu điểm và nhược điểm của thuật toán, chúng ta sẽ dễ dàng chọn nó.
- ## Biến và Phân biệt Trong thống kê, một mô hình tốt hay xấu được đo bằng cách lệch và chênh lệch, vì vậy chúng ta hãy phổ biến lệch và chênh lệch trước:
Biến lệch: mô tả khoảng cách giữa giá trị dự đoán (giá trị ước tính) được mong đợi E
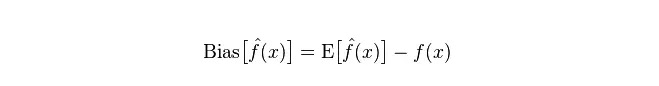
Phân số: mô tả phạm vi thay đổi của giá trị dự đoán P, mức độ phân tán, là chênh lệch của giá trị dự đoán, tức khoảng cách với giá trị dự kiến của nó E. Phân số càng lớn, phân bố dữ liệu càng phân tán.
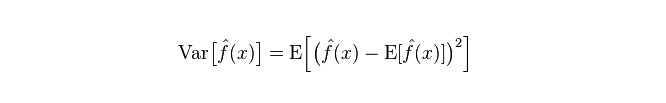
Sự sai lầm thực sự của mô hình là tổng của cả hai, như hình dưới:
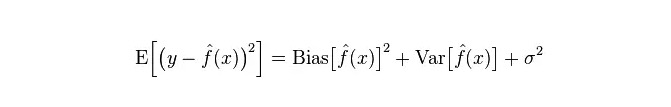
Nếu là một tập huấn nhỏ, một phân loại với độ lệch cao/mức độ lệch thấp (ví dụ, đơn giản Bayes NB) sẽ có lợi hơn so với một phân loại với độ lệch thấp/mức độ lệch cao (ví dụ, KNN) bởi vì sau này sẽ quá phù hợp.
Tuy nhiên, khi tập tập của bạn phát triển, các mô hình càng có khả năng dự đoán tốt hơn đối với dữ liệu gốc, độ lệch sẽ giảm, và các phân loại độ lệch thấp / độ lệch cao sẽ dần dần thể hiện lợi thế của mình (vì chúng có độ lệch gần thấp hơn), khi đó các phân loại độ lệch cao sẽ không đủ để cung cấp mô hình chính xác.
Tất nhiên, bạn cũng có thể nghĩ rằng đây là sự khác biệt giữa mô hình tạo (NB) và mô hình xác định (KNN).
- ## Tại sao người ta lại nói rằng Bayes đơn giản là người có độ lệch cao và thấp?
Những nội dung sau đây được công bố:
Đầu tiên, giả sử bạn biết mối quan hệ giữa tập huấn và tập thử. Nói một cách đơn giản, chúng ta sẽ học một mô hình trên tập huấn và sau đó lấy tập thử để sử dụng, kết quả tốt hay xấu được đo dựa trên tỷ lệ lỗi của tập thử.
Nhưng nhiều lần, chúng ta chỉ có thể giả định các tập thử nghiệm và tập huấn phù hợp với cùng một phân bố dữ liệu nhưng không có dữ liệu thử nghiệm thực sự. Tại sao chúng ta chỉ có thể đo lường tỷ lệ lỗi thử nghiệm bằng cách chỉ nhìn vào tỷ lệ lỗi đào tạo?
Bởi vì số lượng mẫu được đào tạo rất ít (hoặc ít nhất là không đủ), nên mô hình thu được thông qua tập huấn sẽ không bao giờ hoàn toàn chính xác.
Ngoài ra, trong thực tế, các mẫu được đào tạo thường có một số lỗi nhiễu, vì vậy nếu áp dụng một mô hình rất phức tạp để theo đuổi sự hoàn hảo trên tập huấn, nó sẽ khiến mô hình coi tất cả các lỗi trong tập huấn là các đặc điểm phân bố dữ liệu thực, do đó có ước tính phân bố dữ liệu sai.
Điều này làm cho sai lầm xảy ra trên các tập hợp thực sự (điều này được gọi là khớp). Nhưng cũng không thể sử dụng mô hình quá đơn giản, nếu không mô hình sẽ không đủ để vẽ phân bố dữ liệu khi phân bố dữ liệu tương đối phức tạp (có thể biểu hiện là tỷ lệ sai lầm cao ngay cả trên tập hợp huấn luyện, hiện tượng này kém khớp).
Mô hình quá phù hợp cho thấy mô hình được sử dụng phức tạp hơn so với phân bố dữ liệu thực, trong khi mô hình không phù hợp cho thấy mô hình được sử dụng đơn giản hơn so với phân bố dữ liệu thực.
Trong khuôn khổ học tập thống kê, người ta có quan điểm rằng khi vẽ phức tạp mô hình, Error = Bias + Variance. Error ở đây có thể được hiểu là tỷ lệ sai sót dự đoán của mô hình, được tạo thành từ hai phần, một phần là một phần dự đoán không chính xác do mô hình quá đơn giản và một phần là không gian thay đổi lớn hơn và sự không chắc chắn do mô hình quá phức tạp.
Vì vậy, nó dễ dàng phân tích Bayesian đơn giản. Nó đơn giản giả định rằng các dữ liệu không liên quan, và là một mô hình được đơn giản hóa nghiêm trọng. Vì vậy, đối với một mô hình đơn giản như vậy, hầu hết các trường hợp Bias phần lớn hơn phần biến thể, tức là chênh lệch cao và chênh lệch thấp.
Trong thực tế, để Error nhỏ nhất, chúng ta cần cân bằng tỷ lệ Bias và Variance khi lựa chọn mô hình, tức cân bằng over-fitting và under-fitting.
Mối quan hệ giữa độ lệch và chênh lệch với độ phức tạp của mô hình được minh họa rõ hơn bằng cách sử dụng biểu đồ sau:
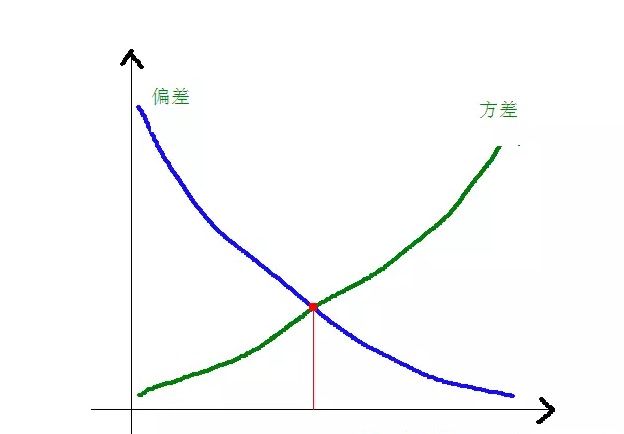
Khi sự phức tạp của mô hình tăng lên, độ lệch sẽ dần giảm, trong khi độ lệch sẽ dần lớn hơn.
-
Những ưu điểm và nhược điểm của các thuật toán phổ biến
- ### 1. Đơn giản Bayes
Bayes đơn giản thuộc về mô hình tạo ra (về mô hình tạo ra và mô hình xác định, chủ yếu là về việc liệu nó có yêu cầu phân bố hợp nhất hay không), rất đơn giản, bạn chỉ cần làm một đống tính toán.
Nếu đặt giả định độc lập có điều kiện (một điều kiện nghiêm ngặt hơn), tốc độ hội tụ của trình phân loại Bayesian đơn giản sẽ nhanh hơn so với việc xác định mô hình, chẳng hạn như hồi quy logic, vì vậy bạn chỉ cần ít dữ liệu đào tạo hơn. Ngay cả khi giả định độc lập có điều kiện NB không thành công, các trình phân loại NB vẫn hoạt động tốt trong thực tế.
Nhược điểm chính của nó là nó không thể học được sự tương tác giữa các tính năng, trong mRMR, R là tính năng không cần thiết. Ví dụ, nếu bạn thích phim của Brad Pitt và Tom Cruise, nó không thể học được những bộ phim mà bạn không thích khi họ đóng cùng nhau.
Lợi thế:
Mô hình Bayes đơn giản bắt nguồn từ lý thuyết toán học cổ điển, có nền tảng toán học vững chắc và hiệu quả phân loại ổn định. Hiệu suất tốt đối với dữ liệu quy mô nhỏ, có thể xử lý các nhiệm vụ đa lớp, phù hợp với đào tạo tăng. Không nhạy cảm với dữ liệu bị mất, các thuật toán tương đối đơn giản và thường được sử dụng để phân loại văn bản. Nhược điểm:
Có thể bạn sẽ thấy một số điều đáng chú ý. Có tỷ lệ sai lầm trong việc phân loại quyết định; Nhận dạng biểu thức của dữ liệu nhập rất nhạy cảm.
- ### 2. Logic Regression
Trong mô hình phân định, có rất nhiều phương pháp để chuẩn hóa mô hình (L0, L1, L2, vv), và bạn không phải lo lắng về tính liên quan của các đặc điểm của bạn như với Bayes đơn giản.
Bạn cũng sẽ có được một giải thích xác suất tốt hơn so với cây quyết định và máy SVM, bạn thậm chí có thể dễ dàng sử dụng dữ liệu mới để cập nhật mô hình (sử dụng thuật toán gradient descending online, gradient descent online).
Nếu bạn cần một cấu trúc xác suất (ví dụ, chỉ cần điều chỉnh ngưỡng phân loại, chỉ ra sự không chắc chắn, hoặc để có được khoảng tin cậy), hoặc bạn muốn tích hợp dữ liệu đào tạo nhanh hơn vào mô hình sau đó, hãy sử dụng nó.
Chức năng Sigmoid:
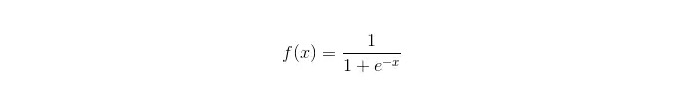
Lợi thế: Thực hiện một cách đơn giản, rộng rãi trong các vấn đề công nghiệp; Lượng tính toán rất nhỏ, tốc độ nhanh và nguồn lưu trữ thấp; Điểm số xác suất mẫu quan sát thuận tiện; Đối với hồi quy logic, đa côn tuyến tính không phải là vấn đề, nó có thể được giải quyết bằng cách kết hợp L2 định dạng; Nhược điểm: Khi không gian đặc điểm lớn, hiệu suất quay ngược logic không tốt; Dễ bị thiếu phù hợp, thông thường không chính xác Không thể xử lý tốt một số lượng lớn các đặc điểm hoặc biến thể đa loại; Chỉ có thể xử lý các vấn đề phân loại hai (softmax được tạo ra dựa trên đó có thể được sử dụng cho nhiều lớp) và phải phân loại tuyến tính; Các đặc điểm phi tuyến tính cần phải được chuyển đổi;
- ### 3. Chuyển hướng tuyến tính
Quá trình hồi quy tuyến tính được sử dụng để hồi quy, không giống như Logistic regression được sử dụng để phân loại, và ý tưởng cơ bản của nó là tối ưu hóa các hàm sai số dưới dạng lần hai nhỏ nhất bằng phương pháp giảm gradient, và tất nhiên cũng có thể tìm ra giải pháp cho các tham số trực tiếp bằng phương trình bình thường, kết quả là:
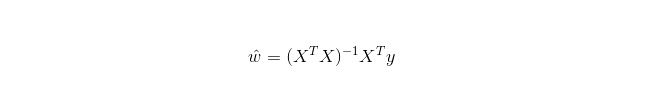
Trong LWLR, biểu thức tính toán cho các thông số là:
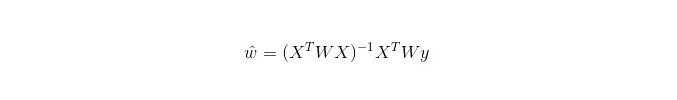
Do đó, LWLR khác với LR, LWLR là một mô hình phi tham số, vì mỗi lần tính toán hồi quy phải đi qua mẫu đào tạo ít nhất một lần.
Ưu điểm: Thực hiện đơn giản, tính toán đơn giản;
Nhược điểm: Không phù hợp với dữ liệu phi tuyến tính.
- ### 4. Giao thức hàng xóm gần đây
KNN là thuật toán lân cận gần nhất và các quy trình chính của nó là:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别;Cách chọn một giá trị K tối ưu phụ thuộc vào dữ liệu. Thông thường, một giá trị K lớn hơn trong phân loại sẽ giảm tác động của tiếng ồn. Nhưng sẽ làm mờ ranh giới giữa các loại.
Một giá trị K tốt hơn có thể được thu được thông qua các kỹ thuật thông minh khác nhau, ví dụ như xác minh chéo. Ngoài ra, sự hiện diện của các vector đặc trưng không liên quan và tiếng ồn làm giảm độ chính xác của các thuật toán K gần bên cạnh.
Các thuật toán cận vi có kết quả nhất quán mạnh hơn. Khi dữ liệu tiến đến vô hạn, thuật toán đảm bảo tỷ lệ lỗi không vượt quá hai lần tỷ lệ lỗi của thuật toán Bayes. Đối với một số giá trị K tốt, K cận vi đảm bảo tỷ lệ lỗi không vượt quá tỷ lệ lỗi lý thuyết Bayes.
Lợi thế của thuật toán KNN
Các nhà nghiên cứu đã nghiên cứu về các nguyên nhân gây ra sự biến đổi trong hệ thống phân loại và phân loại. Có thể được sử dụng để phân loại phi tuyến tính; Sự phức tạp thời gian đào tạo là O ((n); Không có giả định về dữ liệu, độ chính xác cao, không nhạy cảm với outlier; Nhược điểm
Một số người cho rằng: Vấn đề không cân bằng mẫu (tức là một số loại có nhiều mẫu và một số loại khác có ít); Có thể bạn có thể sử dụng một bộ nhớ lớn.
- ### 5. Cây quyết định
Dễ giải thích. Nó có thể xử lý các mối quan hệ tương tác giữa các tính năng mà không cần căng thẳng và không tham số, vì vậy bạn không cần phải lo lắng về các giá trị bất thường hoặc dữ liệu có thể phân loại tuyến tính (ví dụ, cây quyết định có thể dễ dàng xử lý thể loại A ở cuối một tính năng chiều x, thể loại B ở giữa, và sau đó thể loại A xuất hiện ở đầu của tính năng chiều x).
Một trong những nhược điểm của nó là nó không hỗ trợ học trực tuyến, vì vậy cây quyết định cần phải được xây dựng lại hoàn toàn sau khi mẫu mới đến.
Một nhược điểm khác là dễ dàng xảy ra sự phù hợp, nhưng đây cũng là điểm đến cho các phương pháp tích hợp như RF rừng ngẫu nhiên (hoặc nâng cao cây tăng cường).
Ngoài ra, rừng ngẫu nhiên thường là người chiến thắng trong nhiều vấn đề phân loại (thường là tốt hơn một chút so với máy hỗ trợ vector), nó được đào tạo nhanh chóng và có thể điều chỉnh, đồng thời bạn không phải lo lắng về việc điều chỉnh một loạt các tham số như máy hỗ trợ vector, vì vậy nó đã từng rất phổ biến trong quá khứ.
Một điểm quan trọng trong cây quyết định là chọn một thuộc tính để phân nhánh, vì vậy hãy chú ý đến công thức tính toán của sự gia tăng thông tin và hiểu nó một cách sâu sắc.
Các công thức tính toán của Information Particle là:
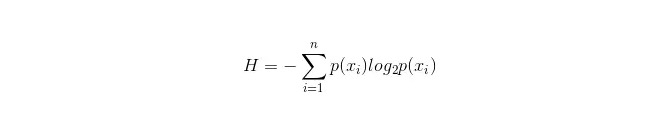
Trong đó n đại diện có n loại phân loại (ví dụ: giả sử là vấn đề loại 2, thì n = 2);; tính toán xác suất p1 và p2 của hai loại mẫu này trong mẫu tổng thể riêng biệt để tính ra các thông tin trước khi phân nhánh thuộc tính không được chọn.
Bây giờ chọn một thuộc tính xixi để phân nhánh, trong đó quy tắc phân nhánh là: nếu xi = vxi = v, phân mẫu vào một nhánh của cây; nếu không bằng nhau, vào nhánh khác.
Rõ ràng, mẫu trong nhánh có thể bao gồm 2 loại, tính toán các hàm H1 và H2 của hai hàm, tính toán tổng thông tin hàm H1 = p1 H1 + p2 H2 sau khi phân nhánh, thì thông tin tăng ΔH = H - H
. Theo nguyên tắc tăng thông tin, hãy kiểm tra tất cả các thuộc tính và chọn thuộc tính tạo ra sự gia tăng lớn nhất như thuộc tính phân nhánh này. Những lợi ích của cây quyết định
Tính toán đơn giản, dễ hiểu và dễ giải thích; Các mẫu có tính chất thiếu phù hợp để xử lý; Có thể xử lý các đặc điểm không liên quan; Có thể tạo ra kết quả khả thi và hiệu quả trên các nguồn dữ liệu lớn trong một thời gian tương đối ngắn. Nhược điểm
Có thể xảy ra quá phù hợp (một rừng ngẫu nhiên có thể giảm quá phù hợp một cách đáng kể); Các nhà nghiên cứu cho biết: Đối với những dữ liệu có số lượng mẫu khác nhau trong các loại dữ liệu, trong cây quyết định, kết quả của việc tăng thông tin có xu hướng đối với những đặc điểm có nhiều giá trị số hơn (như RF).
- ### 5.1 Khả năng thích nghi
Adaboost là một mô hình tổng hợp, mỗi mô hình được xây dựng dựa trên tỷ lệ lỗi của mô hình trước đó, tập trung quá nhiều vào các mẫu phân loại sai, và giảm tập trung vào các mẫu phân loại đúng, sau khi lặp đi lặp lại, bạn có thể nhận được một mô hình tương đối tốt hơn. Đây là một thuật toán tăng cường điển hình. Dưới đây là một tóm tắt về những ưu điểm và nhược điểm của nó.
Ưu điểm
Adaboost là một bộ phân loại có độ chính xác cao. Có thể sử dụng nhiều phương pháp khác nhau để xây dựng các bộ phân loại con, Adaboost cung cấp một framework. Khi sử dụng bộ phân loại đơn giản, kết quả tính toán có thể hiểu được, và cấu trúc của bộ phân loại yếu là cực kỳ đơn giản. Đơn giản, không cần lọc các tính năng. Không dễ bị quá phù hợp. Đối với các thuật toán kết hợp như Random Forest và GBDT, hãy tham khảo bài viết: Machine learning - Summary of combination algorithms
Nhược điểm: nhạy cảm hơn với outlier
- ### 6. SVM hỗ trợ máy vector
Độ chính xác cao, cung cấp một sự đảm bảo lý thuyết tốt để tránh quá phù hợp, và thậm chí nếu dữ liệu không thể phân chia tuyến tính trong không gian đặc điểm ban đầu, nó sẽ hoạt động tốt miễn là cho một hàm lõi phù hợp.
Nó đặc biệt phổ biến trong các vấn đề phân loại văn bản siêu chiều động. Thật không may là bộ nhớ rất tốn kém, khó giải thích, chạy và điều chỉnh cũng có một số phiền toái, trong khi rừng ngẫu nhiên chỉ tránh được những nhược điểm này, tương đối hữu ích.
Ưu điểm Các vấn đề có thể được giải quyết ở các chiều cao, đó là không gian đặc trưng lớn. Có khả năng xử lý sự tương tác của các đặc điểm phi tuyến tính; Không cần phải dựa vào toàn bộ dữ liệu. Có thể nâng cao khả năng phổ biến;
Nhược điểm Khi quan sát nhiều mẫu, hiệu quả không cao; Không có giải pháp chung cho các vấn đề phi tuyến tính, và đôi khi rất khó để tìm ra một hàm hạt nhân phù hợp. Những người bị mất dữ liệu: Ngoài ra còn có một sự lựa chọn kỹ thuật cho các hạt nhân (libsvm có bốn chức năng hạt nhân: hạt nhân tuyến tính, hạt nhân đa phân tử, RBF và hạt nhân sigmoid):
Thứ nhất, nếu số lượng mẫu nhỏ hơn số tính năng, thì không cần phải chọn hạt nhân phi tuyến tính, chỉ cần sử dụng hạt nhân tuyến tính.
Thứ hai, nếu số lượng mẫu lớn hơn số lượng đặc điểm, thì có thể sử dụng lõi phi tuyến để lập bản đồ mẫu ở kích thước cao hơn, thường có kết quả tốt hơn.
Thứ ba, nếu số lượng mẫu và số lượng đặc điểm bằng nhau, thì trường hợp này có thể sử dụng lõi phi tuyến tính, nguyên tắc tương tự như kiểu thứ hai.
Đối với trường hợp đầu tiên, bạn cũng có thể làm giảm kích thước dữ liệu trước và sử dụng lõi phi tuyến tính, đây cũng là một phương pháp.
- ### 7. Những ưu điểm và nhược điểm của mạng thần kinh nhân tạo
Những lợi ích của mạng thần kinh nhân tạo: Sự chính xác của phân loại; Có khả năng xử lý phân tán song song, lưu trữ phân tán và khả năng học tập mạnh mẽ. Có tính mạnh mẽ và khả năng chấp nhận lỗi đối với các dây thần kinh tiếng ồn, có khả năng gần gũi với các mối quan hệ phi tuyến tính phức tạp; Những người có chức năng nhớ liên kết.
Những nhược điểm của mạng thần kinh nhân tạo: Mạng thần kinh đòi hỏi một số lượng lớn các tham số, chẳng hạn như cấu trúc phân vùng mạng, trọng lượng và giá trị ban đầu của ngưỡng; Không thể quan sát được quá trình học tập giữa các kết quả đầu ra khó giải thích, ảnh hưởng đến độ tin cậy và độ chấp nhận của kết quả; Những người học tập có thể mất quá nhiều thời gian và thậm chí không đạt được mục đích của việc học.
- ### 8 K-Means nhóm
Một bài viết về K-Means đã được viết trước đây, liên kết: Máy học thuật K-Means.
Ưu điểm Các thuật toán đơn giản và dễ thực hiện; Đối với xử lý tập dữ liệu lớn, thuật toán này tương đối có thể mở rộng và hiệu quả vì độ phức tạp của nó là khoảng O ((nkt), trong đó n là số lượng tất cả các đối tượng, k là số lượng các con số và t là số lần lặp. Các thuật toán cố gắng tìm ra các phân vùng k có giá trị hàm sai số vuông nhỏ nhất. Các hiệu ứng phân nhóm tốt hơn khi các phân tử là dày đặc, hình cầu hoặc hình khối, và sự khác biệt rõ ràng giữa các phân tử và các phân tử.
Nhược điểm Các yêu cầu về loại dữ liệu cao hơn và phù hợp với dữ liệu số; Có thể kết hợp với các giá trị nhỏ nhất tại địa phương, kết hợp chậm hơn trên dữ liệu lớn Giá trị K khó chọn; Nhận thức về các giá trị trung tâm của các giá trị ban đầu, có thể dẫn đến kết quả phân loại khác nhau đối với các giá trị ban đầu khác nhau; Không phù hợp với việc phát hiện các con đường không có hình dạng vòm, hoặc các con đường có kích thước khác nhau. Một số lượng nhỏ dữ liệu có thể ảnh hưởng đáng kể đến giá trị trung bình.
Các thuật toán chọn tham chiếu
Một bài viết đã dịch một số bài viết nước ngoài trước đây, một bài viết đưa ra một mẹo đơn giản để lựa chọn thuật toán:
Nếu nó không hiệu quả, thì kết quả của nó có thể được sử dụng làm tiêu chuẩn để so sánh với các thuật toán khác.
Sau đó, thử cây quyết định (random forest) để xem liệu nó có thể cải thiện đáng kể hiệu suất mô hình của bạn không. Ngay cả khi cuối cùng bạn không coi nó là mô hình cuối cùng, bạn cũng có thể sử dụng Random Forest để loại bỏ các biến âm thanh, thực hiện lựa chọn tính năng.
Nếu số lượng đặc điểm và mẫu quan sát đặc biệt lớn, thì sử dụng SVM là một lựa chọn khi có đủ nguồn lực và thời gian (điều này là điều quan trọng).
Thông thường:
GBDT>=SVM>=RF>=Adaboost>=Other... , giờ đây, học sâu rất phổ biến, được sử dụng trong nhiều lĩnh vực, nó dựa trên mạng thần kinh, hiện tại tôi cũng đang học, chỉ là kiến thức lý thuyết không quá dày đặc, hiểu không đủ sâu, vì vậy tôi sẽ không giới thiệu ở đây. Các thuật toán quan trọng, nhưng dữ liệu tốt là tốt hơn các thuật toán tốt, và thiết kế các tính năng tốt là rất hữu ích. Nếu bạn có một bộ dữ liệu siêu lớn, bất kỳ thuật toán nào bạn sử dụng có thể không ảnh hưởng nhiều đến hiệu suất phân loại (bây giờ bạn có thể lựa chọn dựa trên tốc độ và dễ sử dụng).
-
Tài liệu tham khảo
- Triết lý giao dịch trong xác suất
- Đặt mã số tiền vào đâu
- BTCTRADE.com không thể truy cập GetRecords
- Trong khi đó, các nhà đầu tư khác cũng cho biết họ sẽ mua các quyền chọn khác.
- Phân tích định lượng chiến lược mua sắm
- Học máy thú vị: Hướng dẫn giới thiệu ngắn nhất
- Luật giao dịch nhôm
- 7 thuật toán sắp xếp thường được sử dụng.
- Chiến lược giao dịch tần số cao: Triangle leverage
- 20 mẹo để phát triển tư duy sáng tạo
- Đầu tư cho người chiến thắng: Bí quyết suy nghĩ chống trực giác
- Những yêu cầu cơ bản của hệ thống giao dịch
- Lượng biến động thực ATR sử dụng
- Có robot nào tìm kiếm mã lỗi không?
- Một số nhà đầu tư khác cũng đã làm điều này.
- Toán học và cờ bạc (1)
- Suy nghĩ lại về hệ thống đường thẳng
- Công thức Kelly về các thiết bị điều khiển vị trí
- Một con chim già đang tìm kiếm cách giao dịch xu hướng, định lượng hệ thống giao dịch
- Những ý tưởng chiến lược tần số cao của Bitcoin