Phân loại Bayesian dựa trên thuật toán KNN
 0
1912
0
1912
Phân loại Bayesian dựa trên thuật toán KNN
Cơ sở lý thuyết cho việc thiết kế bộ phân loại để đưa ra quyết định phân loại Lý thuyết quyết định của Béyès:
So sánh P(ωi 173x) ⋅ trong đóωi là loại i, x là một dữ liệu được quan sát và cần phân loại, P(ωi 173x) biểu thị xác suất của dữ liệu này thuộc loại i trong trường hợp có vector đặc trưng của dữ liệu này, cũng là xác suất sau xét. Theo công thức của Bayes, nó có thể được thể hiện như sau:
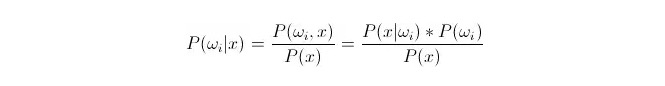
Trong số đó, P ((xfin_Latnfin_Latnfin_Latnfin_Latnfin_Latn Jossa i) được gọi là likelihood hoặc likelihood; P ((ωi) được gọi là prior probability, bởi vì nó không liên quan đến thử nghiệm và có thể được biết trước khi thử nghiệm.
Khi phân loại, cho một x, chọn loại mà xác suất hậu nghiệm P ((ωiⴰⵙx) lớn nhất. Trong mỗi loại so sánh, khi P ((ωiⴰⵙx) nhỏ, thì ωi là biến số, và x là cố định; vì vậy bạn có thể loại bỏ P ((x) mà không xem xét.
Vì vậy, cuối cùng nó sẽ là P (x) của x < x < i.*Câu hỏi P ((ωi)) Xác suất tiên đoán P ((ωi) là tốt, chỉ cần tập trung vào thống kê tỷ lệ dữ liệu xuất hiện trong mỗi phân loại.
Vì x là dữ liệu của tập trung thử nghiệm, không thể lấy trực tiếp từ tập trung huấn luyện. Vì vậy, chúng ta cần tìm ra quy luật phân bố của tập trung huấn luyện, và sau đó chúng ta có thể có được P (x của tập trung).
Sau đây là một phần giới thiệu về thuật toán k-nearest neighbor (KNN).
Chúng ta sẽ sử dụng dữ liệu x1, x2…xn trong tập luyện (mỗi dữ liệu đều có chiều m) để phân bố các dữ liệu này theo loạiωi. Đặt x là bất kỳ điểm nào trong không gian chiều m, làm thế nào để tính P ((x củaωi)?
Chúng ta biết rằng khi số lượng dữ liệu đủ lớn, ta có thể sử dụng tỷ lệ xấp xỉ xác suất. Sử dụng nguyên tắc này, trong vòng quanh điểm x, tìm ra k điểm mẫu gần nhất từ điểm x, trong đó có một số thuộc loại i. Tính toán khối lượng V của siêu cầu nhỏ nhất bao quanh điểm mẫu k này; và tìm ra số Ni trong tất cả các dữ liệu mẫu thuộc loại ωi:
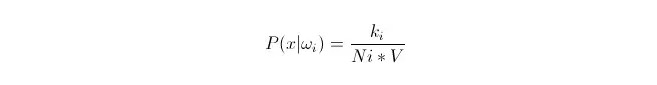
Bạn có thể thấy rằng chúng ta đã tính ra mật độ xác suất điều kiện lớp ở điểm x.
P (ωi) là gì? Theo phương pháp trên, P (ωi) = Ni/N 。 trong đó N là tổng số mẫu 。 Ngoài ra, P (x) = k/N*V), trong đó k là số lượng tất cả các điểm lấy mẫu bao quanh siêu cầu này; N là tổng số mẫu. Vậy thì P (ωi Arduinox) có thể được tính: đưa vào công thức, dễ dàng có được:
P(ωi|x)=ki/k
Để giải thích thêm, trong một siêu cầu có kích thước V, bao quanh k mẫu, trong đó có ki thuộc loại i. Như vậy, bao quanh loại mẫu nào nhiều nhất, chúng ta sẽ xác định x ở đây nên thuộc loại nào. Đây là bộ phân loại được thiết kế bằng thuật toán k gần gũi.