Ứng dụng công nghệ học máy trong giao dịch
Tác giả:FMZ~Lydia, Tạo: 2022-12-30 10:53:07, Cập nhật: 2023-09-20 09:30:09
Ứng dụng công nghệ học máy trong giao dịch
Cảm hứng cho bài viết này xuất phát từ quan sát của tôi về một số cảnh báo và cạm bẫy phổ biến sau khi cố gắng áp dụng công nghệ học máy cho các vấn đề giao dịch trong quá trình nghiên cứu dữ liệu trên nền tảng FMZ Quant.
Nếu bạn chưa đọc các bài viết trước đây của tôi, chúng tôi đề nghị bạn đọc hướng dẫn môi trường nghiên cứu dữ liệu tự động và phương pháp có hệ thống để xây dựng các chiến lược giao dịch mà tôi đã thiết lập trên nền tảng FMZ Quant trước bài viết này.
Hai địa chỉ bài viết này ở đây:https://www.fmz.com/digest-topic/9862vàhttps://www.fmz.com/digest-topic/9863.
Về việc thiết lập môi trường nghiên cứu
Bài hướng dẫn này dành cho những người đam mê, kỹ sư và các nhà khoa học dữ liệu ở tất cả các cấp độ kỹ năng. Cho dù bạn là một nhà lãnh đạo ngành công nghiệp hoặc một người mới lập trình, những kỹ năng duy nhất bạn cần là một sự hiểu biết cơ bản về ngôn ngữ lập trình Python và kiến thức đầy đủ về các hoạt động dòng lệnh (có thể thiết lập một dự án khoa học dữ liệu là đủ).
- Cài đặt FMZ Quant docker và thiết lập Anaconda
Nền tảng FMZ QuantFMZ.COMKhông chỉ cung cấp các nguồn dữ liệu chất lượng cao cho các sàn giao dịch chính, mà còn cung cấp một bộ giao diện API phong phú để giúp chúng tôi thực hiện giao dịch tự động sau khi hoàn thành phân tích dữ liệu. Bộ giao diện này bao gồm các công cụ thực tế, chẳng hạn như truy vấn thông tin tài khoản, truy vấn giá cao, mở, thấp, nhận, khối lượng giao dịch và các chỉ số phân tích kỹ thuật thường sử dụng khác nhau của các sàn giao dịch chính.
Tất cả các tính năng được đề cập ở trên được đóng gói trong một hệ thống giống như Docker. Những gì chúng ta cần làm là mua hoặc thuê dịch vụ điện toán đám mây của riêng chúng tôi và triển khai hệ thống Docker.
Trong tên chính thức của nền tảng FMZ Quant, hệ thống Docker được gọi là hệ thống Docker.
Vui lòng tham khảo bài viết trước của tôi về cách triển khai một docker và robot:https://www.fmz.com/bbs-topic/9864.
Người đọc muốn mua máy chủ điện toán đám mây của riêng mình để triển khai các dockers có thể tham khảo bài viết này:https://www.fmz.com/digest-topic/5711.
Sau khi triển khai thành công máy chủ điện toán đám mây và hệ thống docker, tiếp theo chúng tôi sẽ cài đặt hiện tại lớn nhất hiện vật của Python: Anaconda
Để thực hiện tất cả các môi trường chương trình có liên quan (thư viện phụ thuộc, quản lý phiên bản, v.v.) được yêu cầu trong bài viết này, cách đơn giản nhất là sử dụng Anaconda.
Vì chúng tôi cài đặt Anaconda trên dịch vụ đám mây, chúng tôi khuyên rằng máy chủ đám mây cài đặt hệ thống Linux cộng với phiên bản dòng lệnh của Anaconda.
Đối với phương pháp cài đặt của Anaconda, vui lòng tham khảo hướng dẫn chính thức của Anaconda:https://www.anaconda.com/distribution/.
Nếu bạn là một lập trình viên Python có kinh nghiệm và nếu bạn cảm thấy rằng bạn không cần phải sử dụng Anaconda, thì không có vấn đề gì cả. Tôi sẽ giả định rằng bạn không cần sự giúp đỡ khi cài đặt môi trường phụ thuộc cần thiết. Bạn có thể bỏ qua phần này trực tiếp.
Xây dựng chiến lược giao dịch
Kết quả cuối cùng của chiến lược giao dịch nên trả lời các câu hỏi sau:
-
Định hướng: Xác định xem tài sản có giá rẻ, đắt tiền hoặc giá trị hợp lý hay không.
-
Điều kiện mở vị trí: Nếu tài sản rẻ hoặc đắt tiền, bạn nên mua dài hoặc mua ngắn.
-
Giao dịch vị trí đóng cửa: nếu tài sản có giá hợp lý và chúng tôi có một vị trí trong tài sản (mua hoặc bán trước đó), bạn nên đóng cửa vị trí?
-
Phạm vi giá: giá (hoặc phạm vi) mà vị trí được mở.
-
Số lượng: số lượng tiền được giao dịch (ví dụ, số tiền kỹ thuật số hoặc số lượng lô hợp đồng tương lai hàng hóa).
Học máy có thể được sử dụng để trả lời từng câu hỏi này, nhưng cho phần còn lại của bài viết này, chúng tôi sẽ tập trung vào câu hỏi đầu tiên, đó là hướng của thương mại.
Cách tiếp cận chiến lược
Có hai loại cách tiếp cận để xây dựng chiến lược: một là dựa trên mô hình; khác dựa trên khai thác dữ liệu.
Trong xây dựng chiến lược dựa trên mô hình, chúng ta bắt đầu từ mô hình không hiệu quả thị trường, xây dựng các biểu thức toán học (như giá và lợi nhuận) và kiểm tra hiệu quả của chúng trong một khoảng thời gian dài. Mô hình này thường là một phiên bản đơn giản của một mô hình phức tạp thực sự, và tầm quan trọng và sự ổn định dài hạn của nó cần được xác minh.
Mặt khác, chúng ta tìm kiếm các mẫu giá đầu tiên và cố gắng sử dụng các thuật toán trong các phương pháp khai thác dữ liệu. Lý do cho các mẫu này không quan trọng, bởi vì chỉ có các mẫu được xác định sẽ tiếp tục lặp lại trong tương lai. Đây là một phương pháp phân tích mù, và chúng ta cần kiểm tra nghiêm ngặt để xác định các mẫu thực từ các mẫu ngẫu nhiên.
Rõ ràng, máy học rất dễ áp dụng cho các phương pháp khai thác dữ liệu.
Ví dụ mã sử dụng một công cụ backtesting dựa trên nền tảng FMZ Quant và giao dịch tự động giao diện API. Sau khi triển khai docker và cài đặt Anaconda trong phần trên, bạn chỉ cần cài đặt thư viện phân tích khoa học dữ liệu chúng tôi cần và mô hình học máy nổi tiếng scikit-learn. Chúng tôi sẽ không đi qua phần này một lần nữa.
pip install -U scikit-learn
Sử dụng máy học để tạo ra các tín hiệu chiến lược giao dịch
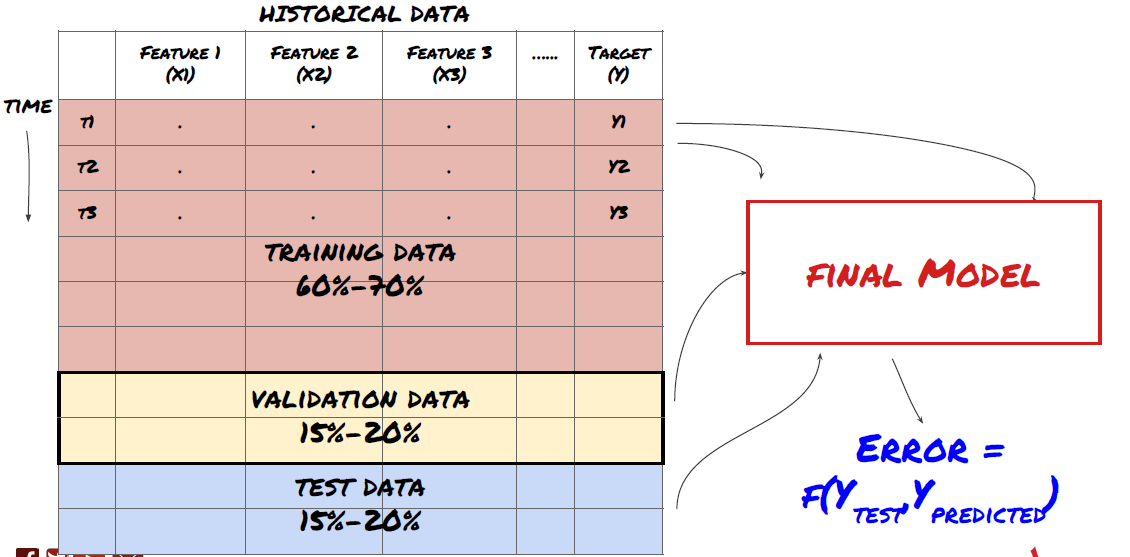
- Data mining. Trước khi bắt đầu, một hệ thống vấn đề máy học tiêu chuẩn được hiển thị trong hình sau:
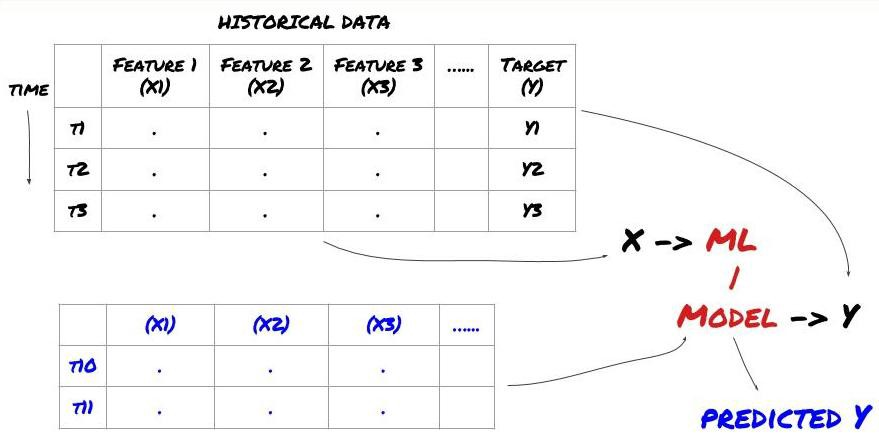
Hệ thống vấn đề học máy
Các tính năng chúng ta sẽ tạo ra phải có một số khả năng dự đoán (X). Chúng ta muốn dự đoán biến mục tiêu (Y) và sử dụng dữ liệu lịch sử để đào tạo mô hình ML có thể dự đoán Y càng gần với giá trị thực càng tốt. Cuối cùng, chúng ta sử dụng mô hình này để dự đoán trên dữ liệu mới mà Y là không rõ. Điều này đưa chúng ta đến bước đầu tiên:
Bước 1: Đặt câu hỏi
- Bạn muốn dự đoán gì? Một dự đoán tốt là gì? Bạn đánh giá kết quả dự đoán như thế nào?
Đó là, trong khuôn khổ của chúng tôi ở trên, những gì là Y?
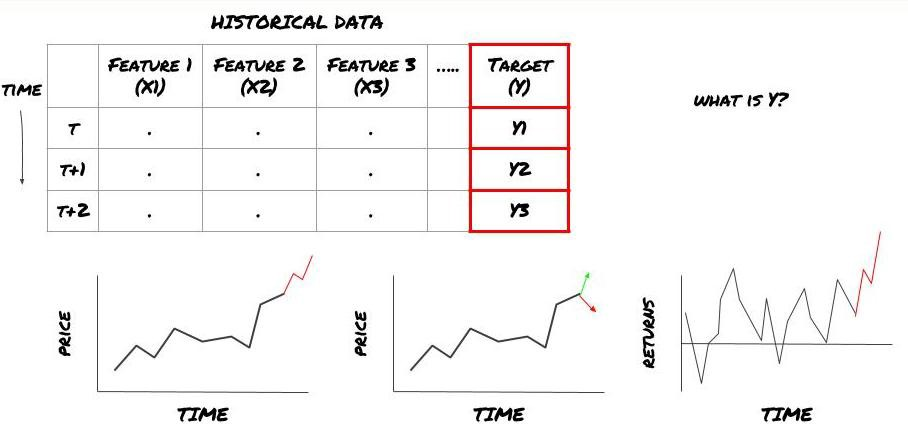
Ông muốn dự đoán gì?
Bạn có muốn dự đoán giá trong tương lai, lợi nhuận trong tương lai / Pnl, tín hiệu mua / bán, tối ưu hóa phân bổ danh mục đầu tư và cố gắng thực hiện giao dịch hiệu quả?
Giả sử chúng ta cố gắng dự đoán giá vào thời điểm tiếp theo. trong trường hợp này, Y (t) = giá (t + 1). bây giờ chúng ta có thể sử dụng dữ liệu lịch sử để hoàn thành khung của chúng tôi.
Lưu ý rằng Y (t) chỉ được biết trong backtest, nhưng khi chúng ta sử dụng mô hình của chúng ta, chúng ta sẽ không biết giá (t + 1) của thời gian t. Chúng ta sử dụng mô hình của chúng ta để dự đoán Y (được dự đoán, t) và so sánh nó với giá trị thực tế chỉ tại thời điểm t + 1. Điều này có nghĩa là bạn không thể sử dụng Y như một tính năng trong mô hình dự đoán.
Một khi chúng ta biết mục tiêu Y, chúng ta cũng có thể quyết định cách đánh giá dự đoán của mình. Điều này rất quan trọng để phân biệt giữa các mô hình khác nhau của dữ liệu mà chúng ta sẽ thử. Chọn một chỉ số để đo hiệu quả của mô hình của chúng ta theo vấn đề mà chúng ta đang giải quyết. Ví dụ, nếu chúng ta dự đoán giá, chúng ta có thể sử dụng lỗi hình vuông gốc như một chỉ số. Một số chỉ số thường được sử dụng (EMA, MACD, điểm chênh lệch, v.v.) đã được mã hóa trước trong hộp công cụ FMZ Quant. Bạn có thể gọi các chỉ số này toàn cầu thông qua giao diện API.
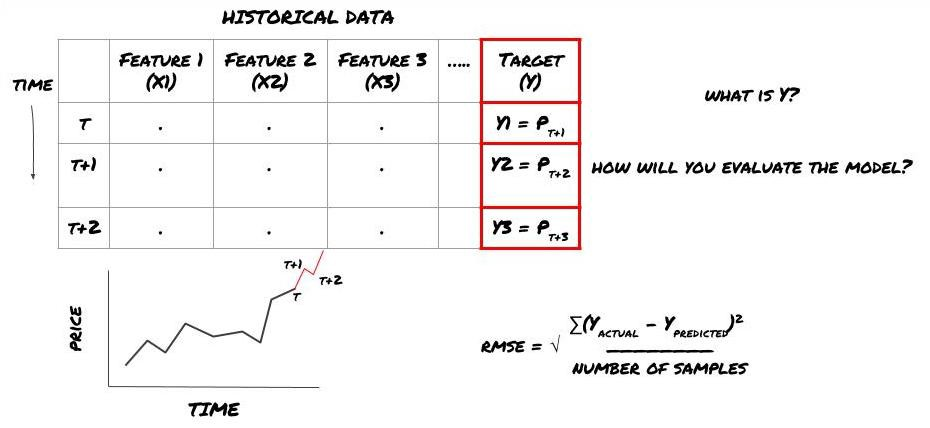
Khung ML để dự đoán giá trong tương lai
Đối với mục đích chứng minh, chúng tôi sẽ tạo ra một mô hình dự đoán để dự đoán giá trị chuẩn dự kiến trong tương lai của một đối tượng đầu tư giả định, trong đó:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Vì đây là một vấn đề hồi quy, chúng ta sẽ đánh giá mô hình trên RMSE (sự sai số bậc hai gốc trung bình).
Lưu ý: Vui lòng tham khảo Bách khoa toàn thư Baidu để biết kiến thức toán học liên quan đến RMSE.
- Mục tiêu của chúng tôi: tạo ra một mô hình để làm cho giá trị dự đoán càng gần Y càng tốt.
Bước 2: Thu thập dữ liệu đáng tin cậy
Thu thập và xóa dữ liệu có thể giúp bạn giải quyết vấn đề.
Những dữ liệu nào bạn cần xem xét để có thể dự đoán biến mục tiêu Y? Nếu chúng tôi dự đoán giá, bạn có thể sử dụng dữ liệu giá của đối tượng đầu tư, dữ liệu số lượng giao dịch của đối tượng đầu tư, dữ liệu tương tự của đối tượng đầu tư liên quan, chỉ số của đối tượng đầu tư và các chỉ số thị trường tổng thể khác, và giá của các tài sản liên quan khác.
Bạn cần thiết lập quyền truy cập dữ liệu cho các dữ liệu này và đảm bảo rằng dữ liệu của bạn chính xác, và giải quyết dữ liệu bị mất (một vấn đề rất phổ biến). Đồng thời, hãy đảm bảo rằng dữ liệu của bạn không thiên vị và đại diện đầy đủ cho tất cả các điều kiện thị trường (ví dụ, cùng một số kịch bản lợi nhuận và lỗ) để tránh thiên vị trong mô hình. Bạn cũng có thể cần phải làm sạch dữ liệu để có được cổ tức, mục tiêu đầu tư chia, tiếp tục, v.v.
Nếu bạn sử dụng nền tảng FMZ Quant (FMZ. COM), chúng tôi có thể truy cập dữ liệu toàn cầu miễn phí từ Google, Yahoo, NSE và Quandl; Dữ liệu sâu về tương lai hàng hóa trong nước như CTP và Esunny; Dữ liệu từ các sàn giao dịch tiền kỹ thuật số chính như Binance, OKX, Huobi và BitMex. Nền tảng FMZ Quant cũng lọc và lọc các dữ liệu này, chẳng hạn như phân chia các mục tiêu đầu tư và dữ liệu thị trường chuyên sâu, và trình bày chúng cho các nhà phát triển chiến lược trong một định dạng dễ hiểu cho các học viên định lượng.
Để tạo điều kiện cho bài viết này, chúng tôi sẽ sử dụng các dữ liệu sau đây như
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Với mã trên, Auquan
Bước 3: Phân chia dữ liệu
- Tạo tập tập huấn, xác minh chéo và kiểm tra các tập dữ liệu này từ dữ liệu.
Đây là một bước rất quan trọng!Trước khi tiếp tục, chúng ta nên chia dữ liệu thành tập dữ liệu đào tạo để đào tạo mô hình của bạn; tập dữ liệu thử nghiệm để đánh giá hiệu suất mô hình.
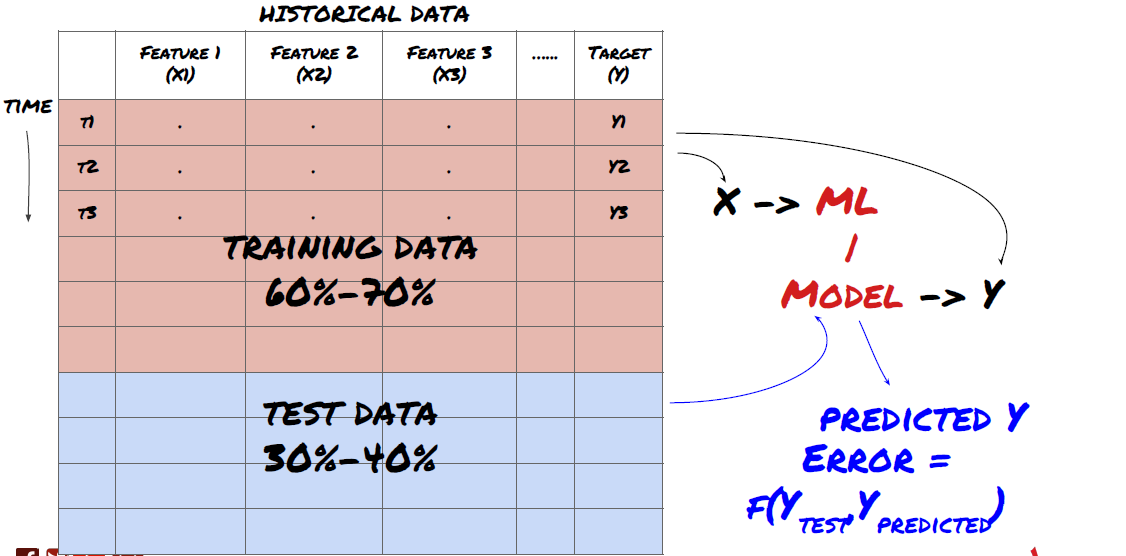
Phân dữ liệu thành tập huấn và tập thử nghiệm
Vì dữ liệu đào tạo được sử dụng để đánh giá các thông số mô hình, mô hình của bạn có thể quá phù hợp với các dữ liệu đào tạo này và dữ liệu đào tạo có thể gây hiểu lầm về hiệu suất mô hình. Nếu bạn không giữ bất kỳ dữ liệu thử nghiệm cá nhân nào và sử dụng tất cả dữ liệu để đào tạo, bạn sẽ không biết mô hình của bạn hoạt động tốt hay xấu như thế nào trên các dữ liệu vô hình mới. Đây là một trong những lý do chính cho sự thất bại của mô hình ML được đào tạo trong dữ liệu thời gian thực: mọi người đào tạo tất cả dữ liệu có sẵn và rất phấn khích bởi các chỉ số dữ liệu đào tạo, nhưng mô hình không thể đưa ra bất kỳ dự đoán có ý nghĩa nào về dữ liệu thời gian thực không được đào tạo.
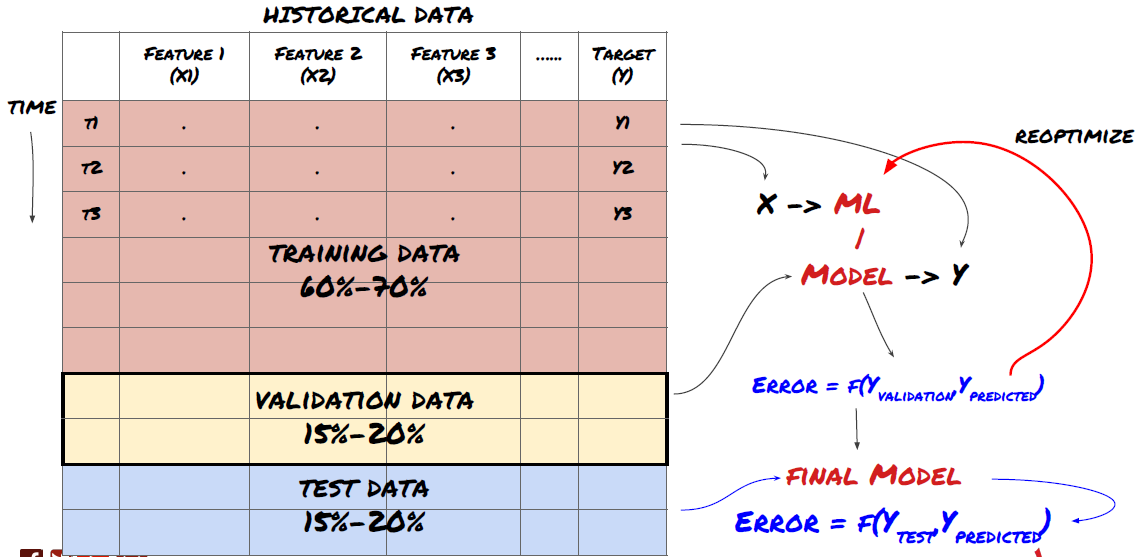
Phân dữ liệu thành bộ đào tạo, bộ xác minh và bộ thử nghiệm
Có những vấn đề với phương pháp này. Nếu chúng ta đào tạo dữ liệu đào tạo nhiều lần, đánh giá hiệu suất của dữ liệu thử nghiệm và tối ưu hóa mô hình của chúng ta cho đến khi chúng ta hài lòng với hiệu suất, chúng ta đưa dữ liệu thử nghiệm như một phần của dữ liệu đào tạo ngụ ý. Cuối cùng, mô hình của chúng ta có thể hoạt động tốt trên bộ dữ liệu đào tạo và thử nghiệm này, nhưng nó không thể đảm bảo rằng nó có thể dự đoán dữ liệu mới tốt.
Để giải quyết vấn đề này, chúng ta có thể tạo ra một bộ dữ liệu xác thực riêng biệt. Bây giờ, bạn có thể đào tạo dữ liệu, đánh giá hiệu suất của dữ liệu xác thực, tối ưu hóa cho đến khi bạn hài lòng với hiệu suất, và cuối cùng kiểm tra dữ liệu thử nghiệm. Bằng cách này, dữ liệu thử nghiệm sẽ không bị ô nhiễm, và chúng tôi sẽ không sử dụng bất kỳ thông tin nào trong dữ liệu thử nghiệm để cải thiện mô hình của chúng tôi.
Hãy nhớ rằng, một khi bạn đã kiểm tra hiệu suất của dữ liệu thử nghiệm của mình, đừng quay lại và cố gắng tối ưu hóa mô hình của bạn hơn nữa. Nếu bạn thấy rằng mô hình của bạn không mang lại kết quả tốt, hãy loại bỏ mô hình hoàn toàn và bắt đầu lại.
Đối với câu hỏi của chúng tôi, chúng tôi có ba bộ dữ liệu có sẵn. Chúng tôi sẽ sử dụng một bộ như tập huấn, bộ thứ hai như bộ xác minh, và bộ thứ ba như bộ thử nghiệm của chúng tôi.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Đối với mỗi số này, chúng ta thêm biến mục tiêu Y, được định nghĩa là trung bình của năm giá trị cơ bản tiếp theo.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Bước 4: Kỹ thuật tính năng
Phân tích hành vi dữ liệu và tạo các tính năng dự đoán
Bây giờ việc xây dựng dự án thực sự đã bắt đầu. Quy tắc vàng của việc lựa chọn tính năng là khả năng dự đoán chủ yếu đến từ các tính năng, chứ không phải từ các mô hình. Bạn sẽ thấy rằng việc lựa chọn các tính năng có tác động lớn hơn nhiều đến hiệu suất so với việc lựa chọn các mô hình. Một số cân nhắc cho việc lựa chọn tính năng:
-
Không chọn một tập hợp lớn các tính năng ngẫu nhiên mà không khám phá mối quan hệ với biến mục tiêu.
-
Sự tương quan ít hoặc không có gì với biến mục tiêu có thể dẫn đến quá phù hợp.
-
Các tính năng bạn chọn có thể có liên quan cao với nhau, trong trường hợp đó một số ít tính năng cũng có thể giải thích mục tiêu.
-
Tôi thường tạo ra một số tính năng trực quan, kiểm tra mối tương quan giữa biến mục tiêu và các tính năng này, và mối tương quan giữa chúng để quyết định sử dụng nào.
-
Bạn cũng có thể thử thực hiện phân tích thành phần chính (PCA) và các phương pháp khác để sắp xếp các tính năng ứng cử viên theo hệ số thông tin tối đa (MIC).
Chuyển đổi đặc điểm / bình thường hóa:
Các mô hình ML có xu hướng hoạt động tốt về mặt bình thường hóa. Tuy nhiên, bình thường hóa rất khó khi xử lý dữ liệu chuỗi thời gian, bởi vì phạm vi dữ liệu trong tương lai không được biết. Dữ liệu của bạn có thể nằm ngoài phạm vi bình thường hóa, dẫn đến lỗi mô hình. Nhưng bạn vẫn có thể cố gắng buộc một mức độ ổn định:
-
Scaling: chia các tính năng theo độ lệch chuẩn hoặc phạm vi phân đoạn.
-
Trung tâm: trừ giá trị trung bình lịch sử từ giá trị hiện tại.
-
Bình thường hóa: hai giai đoạn ngược lại của điều trên (x - trung bình) / stdev.
-
Bình thường hóa thường xuyên: chuẩn hóa dữ liệu trong phạm vi từ - 1 đến +1 và xác định lại trung tâm trong khoảng thời gian theo dõi ngược (x-min) / ((max min).
Lưu ý rằng vì chúng ta sử dụng giá trị trung bình liên tục lịch sử, độ lệch chuẩn, giá trị tối đa hoặc tối thiểu vượt quá thời gian truy cập lại, giá trị chuẩn hóa bình thường của tính năng sẽ đại diện cho các giá trị thực tế khác nhau tại các thời điểm khác nhau. Ví dụ, nếu giá trị hiện tại của tính năng là 5 và giá trị trung bình trong 30 thời gian liên tiếp là 4,5, nó sẽ được chuyển đổi thành 0,5 sau khi tập trung. Sau đó, nếu giá trị trung bình của 30 thời gian liên tiếp trở thành 3, giá trị 3,5 sẽ trở thành 0,5. Đây có thể là nguyên nhân của mô hình sai. Do đó, bình thường hóa là khó khăn, và bạn phải tìm ra điều gì cải thiện hiệu suất của mô hình (nếu thực sự có).
Đối với lần lặp đầu tiên trong vấn đề của chúng tôi, chúng tôi đã tạo ra một số lượng lớn các tính năng bằng cách sử dụng các tham số hỗn hợp.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Bước 5: Chọn mô hình
Chọn mô hình thống kê/ML phù hợp theo các câu hỏi đã chọn
Sự lựa chọn mô hình phụ thuộc vào cách thức hình thành vấn đề. Bạn đang giải quyết theo giám sát (mỗi điểm X trong ma trận tính năng được gán cho biến mục tiêu Y) hoặc học không giám sát (không có bản đồ nhất định, mô hình cố gắng học một mô hình không rõ)? Bạn đang làm việc với hồi quy (làm dự đoán giá thực tế trong thời gian tương lai) hoặc phân loại (chỉ dự đoán hướng giá trong thời gian tương lai (tăng / giảm))?

Học tập theo dõi hoặc không theo dõi

Chuyển hướng hoặc phân loại
Một số thuật toán học tập được giám sát phổ biến có thể giúp bạn bắt đầu:
-
Phục hồi tuyến tính (các tham số, hồi quy)
-
Phục hồi hậu cần (thời điểm, phân loại)
-
thuật toán K-Nearest Neighbor (KNN) (dựa trên trường hợp, hồi quy)
-
SVM, SVR (các thông số, phân loại và hồi quy)
-
Cây quyết định
-
Rừng quyết định
Tôi đề nghị bắt đầu với một mô hình đơn giản, chẳng hạn như hồi quy tuyến tính hoặc hậu cần, và xây dựng các mô hình phức tạp hơn từ đó khi cần thiết.
Bước 6: Đào tạo, xác minh và tối ưu hóa (lặp lại các bước 4-6)
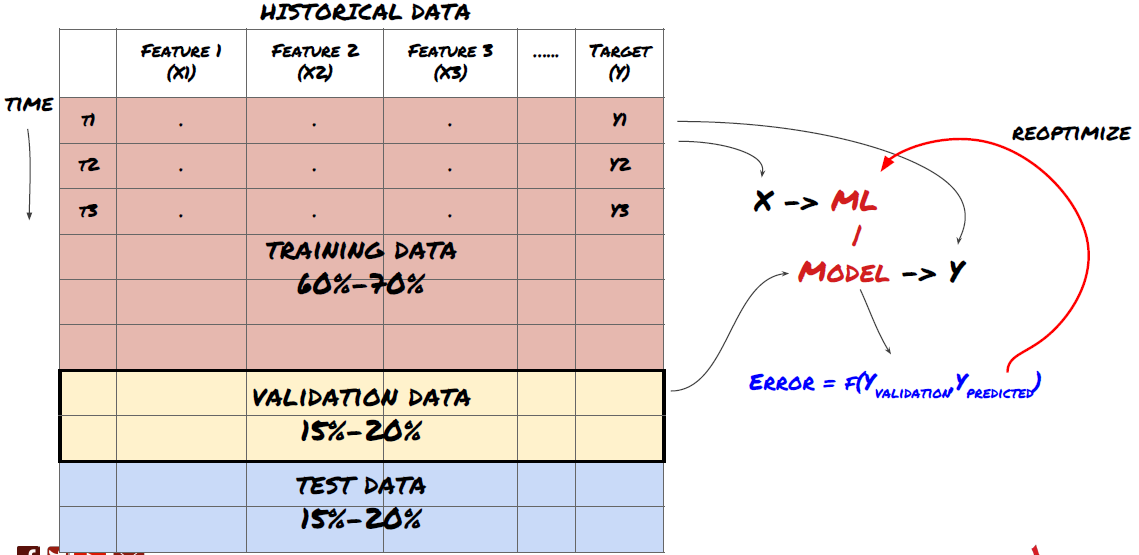
Sử dụng tập dữ liệu đào tạo và xác minh để đào tạo và tối ưu hóa mô hình của bạn
Bây giờ bạn đã sẵn sàng để cuối cùng xây dựng mô hình. Ở giai đoạn này, bạn thực sự chỉ cần lặp lại mô hình và các tham số mô hình. Đào tạo mô hình của bạn trên dữ liệu đào tạo, đo hiệu suất của nó trên dữ liệu xác minh, và sau đó trả về, tối ưu hóa, đào tạo lại và đánh giá nó. Nếu bạn không hài lòng với hiệu suất của mô hình, vui lòng thử mô hình khác. Bạn chu kỳ qua giai đoạn này nhiều lần cho đến khi cuối cùng bạn có một mô hình mà bạn hài lòng.
Chỉ khi bạn có mô hình yêu thích của bạn, sau đó chuyển sang bước tiếp theo.
Đối với vấn đề chứng minh của chúng tôi, hãy bắt đầu với một sự hồi quy tuyến tính đơn giản:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
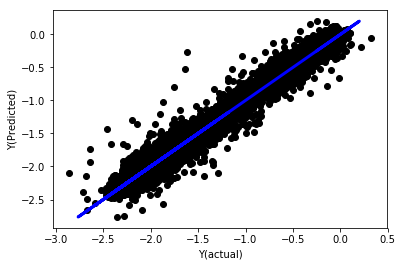
Phục hồi tuyến tính không bình thường hóa
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Hãy nhìn vào hệ số mô hình. chúng ta không thể thực sự so sánh chúng hoặc nói cái nào quan trọng, bởi vì chúng đều thuộc về các thang điểm khác nhau. hãy thử bình thường hóa để làm cho chúng phù hợp với cùng một tỷ lệ và cũng thực thi một số tính mượt mà.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
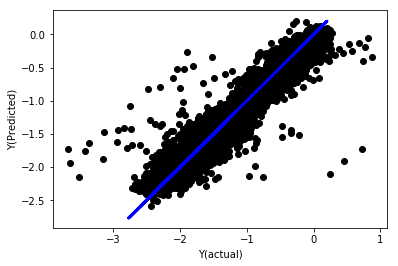
Phục hồi tuyến tính với bình thường hóa
Mean squared error: 0.05
Variance score: 0.90
Mô hình này không cải thiện mô hình trước, nhưng nó không tệ hơn. Bây giờ chúng ta có thể so sánh các hệ số để xem những gì thực sự quan trọng.
Hãy xem các hệ số:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Kết quả là:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Chúng ta có thể thấy rõ rằng một số tính năng có hệ số cao hơn những tính năng khác, và chúng có thể có khả năng dự đoán mạnh hơn.
Hãy xem mối tương quan giữa các đặc điểm khác nhau.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
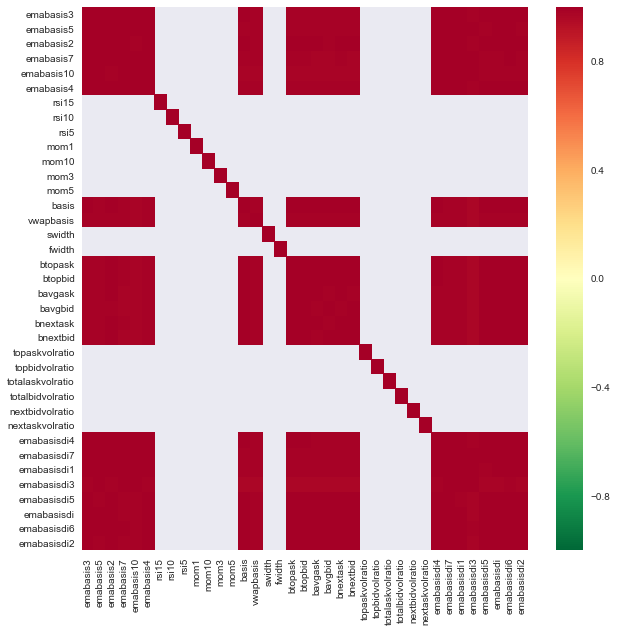
Sự tương quan giữa các đặc điểm
Các vùng màu đỏ đậm đại diện cho các biến có tương quan cao.
Ví dụ, tôi có thể loại bỏ các tính năng như emabasisdi7 dễ dàng, mà chỉ là sự kết hợp tuyến tính của các tính năng khác.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
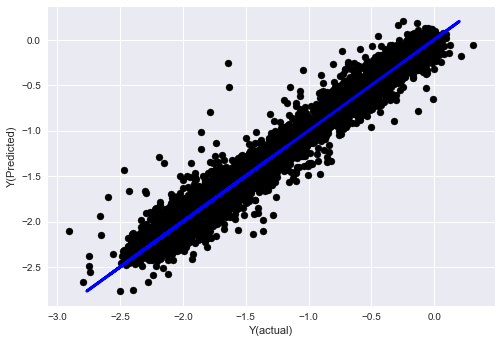
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Xem, hiệu suất của mô hình của chúng tôi không thay đổi. chúng tôi chỉ cần một số đặc điểm để giải thích các biến mục tiêu của chúng tôi. tôi đề nghị bạn thử nhiều tính năng trên, thử các kết hợp mới, vv, để xem những gì có thể cải thiện mô hình của chúng tôi.
Chúng ta cũng có thể thử các mô hình phức tạp hơn để xem liệu thay đổi mô hình có thể cải thiện hiệu suất hay không.
- thuật toán K-Nearest Neighbor (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Cây quyết định
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
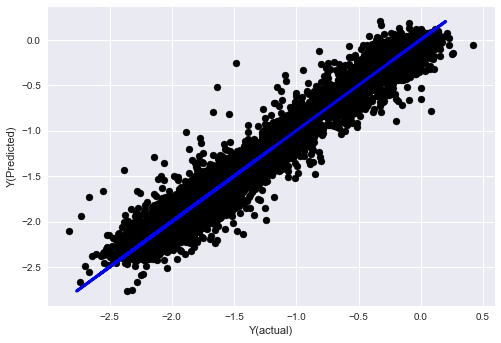
Bước 7: Kiểm tra lại dữ liệu thử nghiệm
Kiểm tra hiệu suất của dữ liệu mẫu thực tế
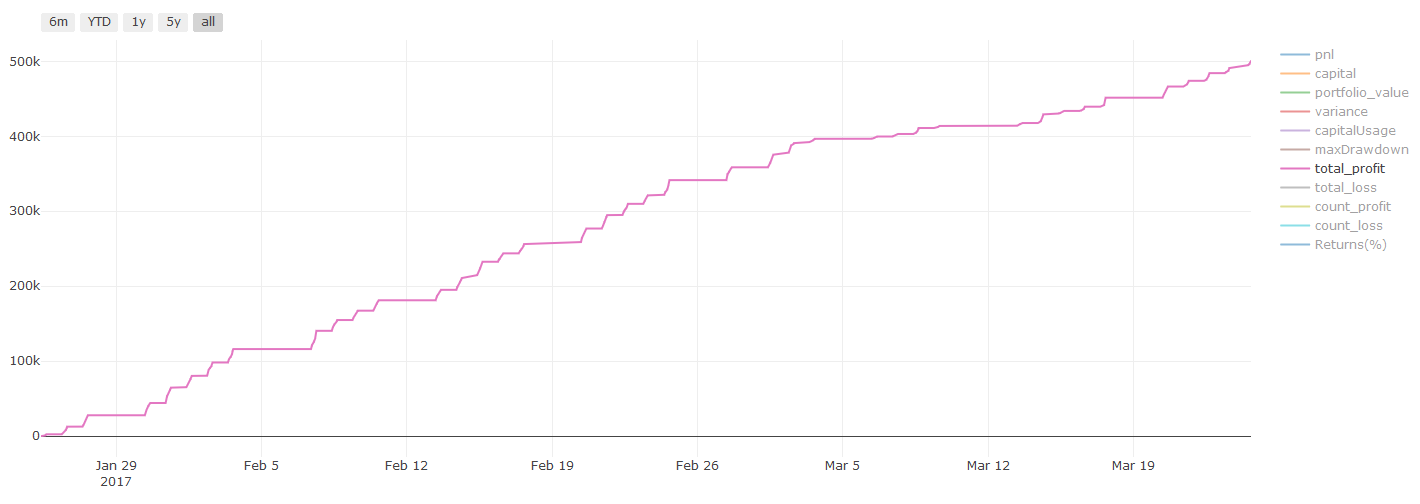
Hiệu suất kiểm tra ngược trên các bộ dữ liệu thử nghiệm (không bị ảnh hưởng)
Đây là một thời điểm quan trọng. Chúng tôi chạy mô hình tối ưu hóa cuối cùng của chúng tôi từ bước cuối cùng của dữ liệu thử nghiệm, chúng tôi đặt nó sang một bên ở đầu và chúng tôi đã không chạm vào dữ liệu cho đến nay.
Điều này cung cấp cho bạn một kỳ vọng thực tế về cách mô hình của bạn sẽ thực hiện trên dữ liệu mới và chưa thấy khi bạn bắt đầu giao dịch thời gian thực.
Nếu bạn không thích kết quả backtest của dữ liệu thử nghiệm, vui lòng loại bỏ mô hình và bắt đầu lại. Đừng bao giờ quay lại hoặc tối ưu hóa lại mô hình của bạn, điều này sẽ dẫn đến quá phù hợp! (Còn được khuyến cáo tạo một bộ dữ liệu thử nghiệm mới, bởi vì bộ dữ liệu này bây giờ bị ô nhiễm; khi loại bỏ mô hình, chúng tôi đã biết nội dung của bộ dữ liệu ngụ ý).
Ở đây chúng ta vẫn sẽ sử dụng Toolbox của Auquan:
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
Kết quả kiểm tra ngược, Pnl được tính bằng USD (Pnl không bao gồm chi phí giao dịch và phí khác)
Bước 8: Các phương pháp khác để cải thiện mô hình
Kiểm tra Rolling, Set Learning, Bagging và Boosting
Ngoài việc thu thập nhiều dữ liệu hơn, tạo ra các tính năng tốt hơn hoặc thử nhiều mô hình hơn, có một vài điểm khác bạn có thể cố gắng cải thiện.
1. Kiểm tra lăn
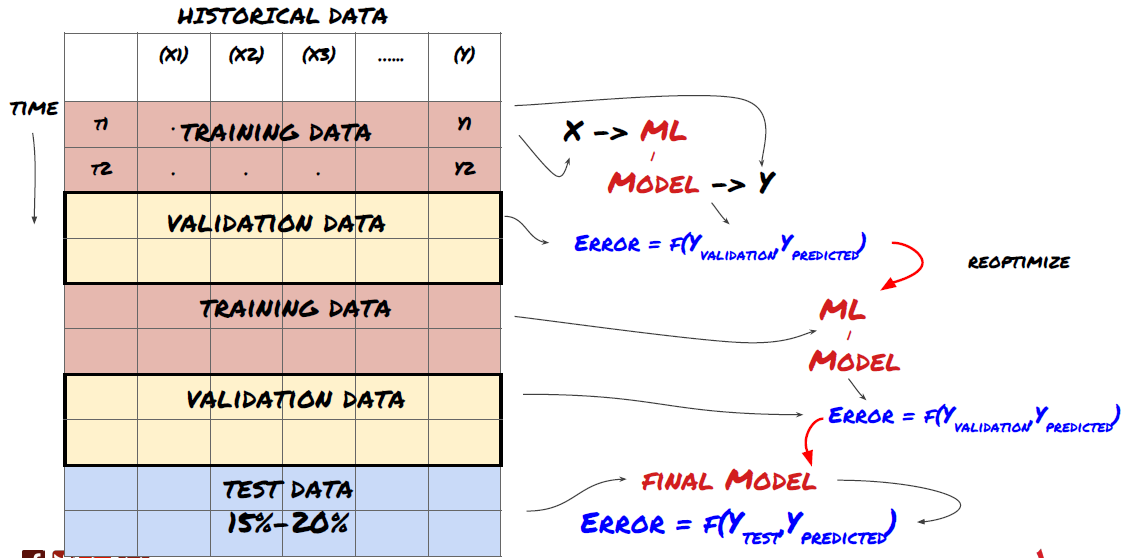
Kiểm tra lăn
Điều kiện thị trường hiếm khi giữ nguyên. Giả sử bạn có dữ liệu một năm, và bạn sử dụng dữ liệu từ tháng 1 đến tháng 8 để đào tạo, và sử dụng dữ liệu từ tháng 9 đến tháng 12 để kiểm tra mô hình của bạn. Bạn có thể đào tạo cho một tập hợp các điều kiện thị trường rất cụ thể cuối cùng. Có lẽ không có biến động thị trường trong nửa đầu năm, và một số tin tức cực đoan dẫn đến sự gia tăng mạnh mẽ của thị trường vào tháng 9. Mô hình của bạn sẽ không thể học mô hình này, và nó sẽ mang lại cho bạn kết quả dự đoán rác.
Có thể tốt hơn là thử kiểm tra lăn lăn phía trước, chẳng hạn như đào tạo từ tháng 1 đến tháng 2, kiểm tra vào tháng 3, đào tạo lại từ tháng 4 đến tháng 5, kiểm tra vào tháng 6, v.v.
2. Học tập tập thể
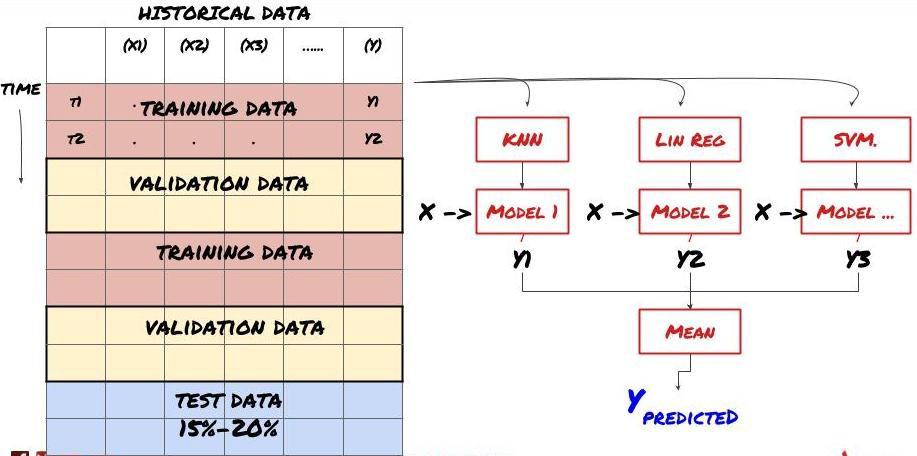
Học tập tập
Một số mô hình có thể rất hiệu quả trong việc dự đoán một số kịch bản nhất định, trong khi các mô hình có thể cực kỳ quá phù hợp trong việc dự đoán các kịch bản khác hoặc trong một số hoàn cảnh nhất định. Một cách để giảm lỗi và quá phù hợp là sử dụng một tập hợp các mô hình khác nhau. Dự đoán của bạn sẽ là trung bình của các dự đoán được thực hiện bởi nhiều mô hình, và các lỗi của các mô hình khác nhau có thể được bù đắp hoặc giảm. Một số phương pháp tập hợp phổ biến là Bagging và Boosting.
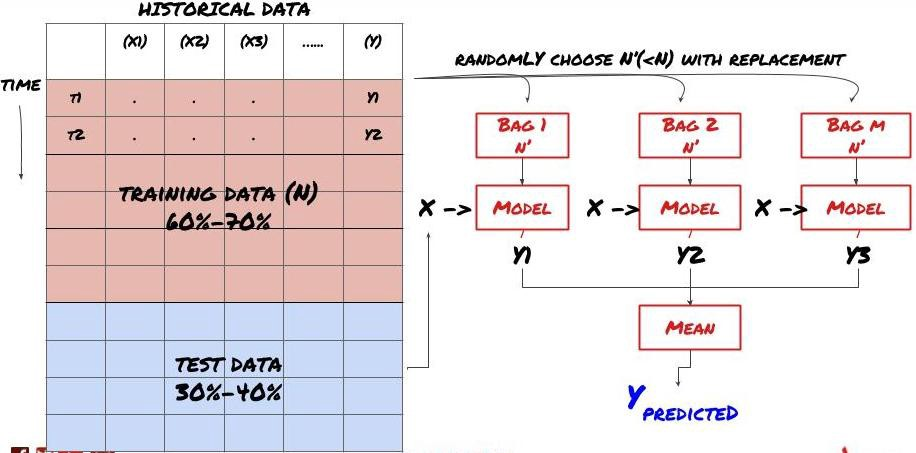
Bổn
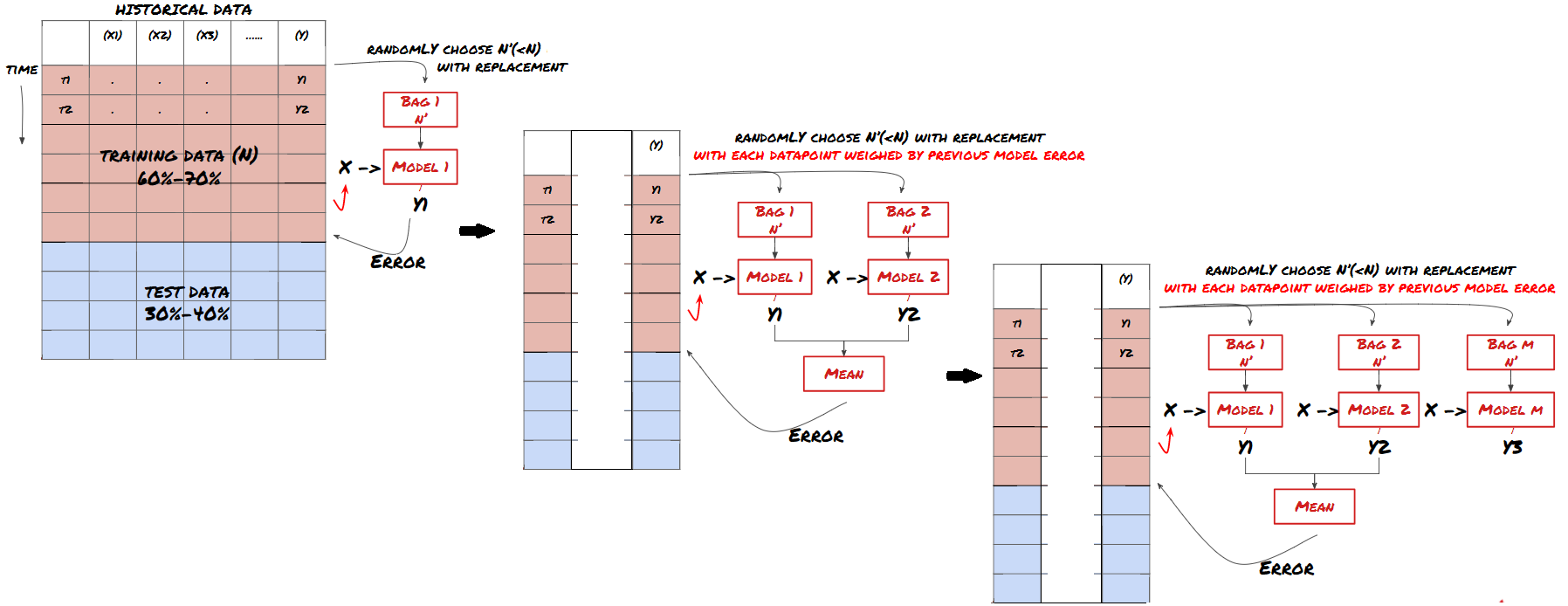
Tăng cường
Vì sự ngắn gọn, tôi sẽ bỏ qua các phương pháp này, nhưng bạn có thể tìm thêm thông tin trực tuyến.
Hãy thử một phương pháp tập hợp cho vấn đề của chúng ta:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Cho đến nay, chúng ta đã tích lũy được rất nhiều kiến thức và thông tin.
-
Hãy giải quyết vấn đề của mình.
-
Thu thập dữ liệu đáng tin cậy và dọn dẹp dữ liệu;
-
Phân dữ liệu thành các tập huấn, xác minh và thử nghiệm;
-
Tạo các tính năng và phân tích hành vi của chúng;
-
Chọn mô hình đào tạo phù hợp theo hành vi;
-
Sử dụng dữ liệu đào tạo để đào tạo mô hình của bạn và đưa ra dự đoán;
-
Kiểm tra hiệu suất trên bộ xác minh và tối ưu hóa lại;
-
Xác minh hiệu suất cuối cùng của bộ thử nghiệm.
Bạn có nhớ những gì chúng tôi thực sự muốn trong chiến lược của chúng tôi? vì vậy bạn không cần phải:
-
Phát triển các tín hiệu dựa trên các mô hình dự đoán để xác định hướng giao dịch;
-
Phát triển các chiến lược cụ thể để xác định các vị trí mở và đóng;
-
Thực hiện hệ thống để xác định vị trí và giá.
Các công ty trên sẽ sử dụng nền tảng FMZ Quant (FMZ.COMTrên nền tảng FMZ Quant, có các giao diện API hoàn hảo và được đóng gói cao, cũng như các chức năng đặt hàng và giao dịch có thể được gọi trên toàn cầu. Bạn không cần phải kết nối và thêm các giao diện API của các sàn giao dịch khác nhau từng cái một. Trong quảng trường Chiến lược của nền tảng FMZ Quant, có nhiều chiến lược thay thế trưởng thành và hoàn hảo phù hợp với phương pháp học máy trong bài viết này, nó sẽ làm cho chiến lược cụ thể của bạn mạnh mẽ hơn. Quảng trường chiến lược nằm ở:https://www.fmz.com/square.
** Lưu ý quan trọng về chi phí giao dịch: ** Mô hình của bạn sẽ cho bạn biết khi nào tài sản đã chọn sẽ đi dài hoặc đi ngắn. Tuy nhiên, nó không xem xét phí / chi phí giao dịch / số lượng giao dịch có sẵn / dừng lỗ, v.v. Chi phí giao dịch thường biến các giao dịch có lợi nhuận thành lỗ. Ví dụ, một tài sản với giá tăng dự kiến là 0,05 đô la là mua, nhưng nếu bạn phải trả 0,10 đô la cho giao dịch này, cuối cùng bạn sẽ nhận được lỗ ròng 0,05 đô la. Sau khi bạn tính đến hoa hồng, phí trao đổi và điểm chênh lệch của nhà môi giới, biểu đồ lợi nhuận tuyệt vời ở trên trông như thế này:
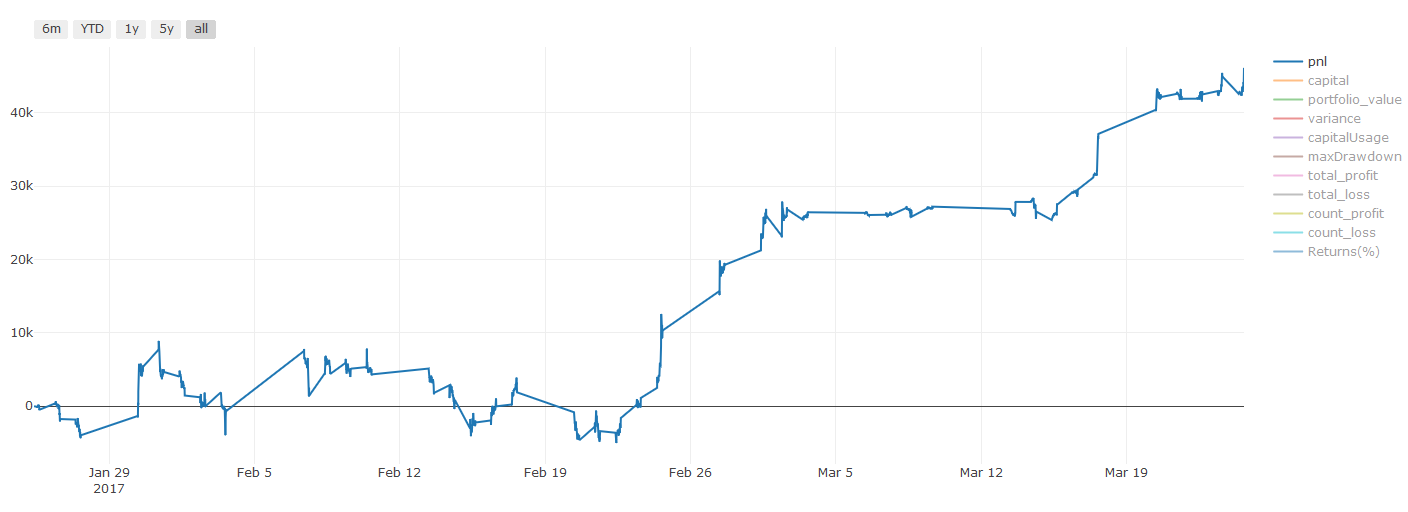
Kết quả backtest sau phí giao dịch và điểm khác biệt, Pnl là USD.
Phí giao dịch và chênh lệch giá chiếm hơn 90% PNL của chúng tôi! Chúng tôi sẽ thảo luận chi tiết về chúng trong một bài viết tiếp theo.
Cuối cùng, hãy xem xét một số cạm bẫy phổ biến.
Phải làm gì và không nên làm gì
-
Tránh quá sức với tất cả sức mạnh của bạn!
-
Đừng đào tạo lại sau mỗi điểm dữ liệu: đây là một sai lầm phổ biến mà mọi người mắc phải trong phát triển máy học. Nếu mô hình của bạn cần được đào tạo lại sau mỗi điểm dữ liệu, nó có thể không phải là một mô hình rất tốt. nghĩa là nó cần được đào tạo lại thường xuyên và chỉ cần được đào tạo với tần suất hợp lý (ví dụ, nếu dự đoán trong ngày được thực hiện, nó cần được đào tạo lại vào cuối mỗi tuần).
-
Tránh thiên vị, đặc biệt là thiên vị nhìn về phía trước: Đây là một lý do khác khiến mô hình không hoạt động và đảm bảo rằng bạn không sử dụng bất kỳ thông tin tương lai nào. Trong hầu hết các trường hợp, điều này có nghĩa là biến mục tiêu Y không được sử dụng như một tính năng trong mô hình. Bạn có thể sử dụng nó trong quá trình backtesting, nhưng nó sẽ không có sẵn khi bạn thực sự chạy mô hình, khiến mô hình của bạn không thể sử dụng được.
-
Hãy cẩn thận với sự thiên vị khai thác dữ liệu: Vì chúng tôi đang cố gắng thực hiện một loạt các mô hình trên dữ liệu của chúng tôi để xác định xem nó có phù hợp hay không, nếu không có lý do đặc biệt, vui lòng đảm bảo rằng bạn chạy các bài kiểm tra nghiêm ngặt để tách chế độ ngẫu nhiên khỏi chế độ thực tế có thể xảy ra. Ví dụ, hồi quy tuyến tính giải thích mô hình xu hướng tăng lên tốt, nhưng nó có khả năng trở thành một phần nhỏ của các luân chuyển ngẫu nhiên lớn hơn!
Tránh quá phù hợp
Điều này rất quan trọng. Tôi nghĩ rằng cần phải nhắc lại.
-
Việc quá phù hợp là cái bẫy nguy hiểm nhất trong các chiến lược giao dịch;
-
Một thuật toán phức tạp có thể hoạt động rất tốt trong backtest, nhưng nó thất bại thảm khốc trên dữ liệu vô hình mới. thuật toán này không thực sự tiết lộ bất kỳ xu hướng nào của dữ liệu, cũng không có khả năng dự đoán thực sự. Nó rất phù hợp với dữ liệu mà nó nhìn thấy;
-
Giữ hệ thống của bạn đơn giản nhất có thể. Nếu bạn thấy rằng bạn cần rất nhiều chức năng phức tạp để giải thích dữ liệu, bạn có thể overfit;
-
Phân chia dữ liệu có sẵn của bạn thành dữ liệu đào tạo và thử nghiệm và luôn kiểm tra hiệu suất của dữ liệu mẫu thực trước khi sử dụng mô hình cho các giao dịch thời gian thực.
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (2)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (2)
- Thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: Một giải pháp hoàn chỉnh để tiếp nhận tín hiệu với dịch vụ Http tích hợp trong chiến lược
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: Chiến lược xây dựng dịch vụ HTTP để nhận tín hiệu
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (1)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (1)
- Cuộc thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: API mở rộng VS Chiến lược Dịch vụ HTTP tích hợp
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: API mở rộng vs chiến lược dịch vụ HTTP tích hợp
- Cuộc thảo luận về phương pháp thử nghiệm chiến lược dựa trên Random Ticker Generator
- Khám phá phương pháp thử nghiệm chiến lược dựa trên trình tạo thị trường ngẫu nhiên
- Tính năng mới của FMZ Quant: Sử dụng chức năng _Serve để tạo dịch vụ HTTP dễ dàng
- Mạng thần kinh và chuỗi giao dịch định lượng tiền kỹ thuật số (1) - LSTM dự đoán giá Bitcoin
- Áp dụng chiến lược kết hợp của chỉ số sức mạnh tương đối SMA và RSI
- Phát triển chiến lược CTA và thư viện lớp học tiêu chuẩn của nền tảng FMZ Quant
- Chiến lược giao dịch định lượng với phân tích động lực giá trong Python
- Thực hiện một chiến lược giao dịch định lượng tiền kỹ thuật số tăng gấp đôi trong Python
- Cách tốt nhất để cài đặt và nâng cấp cho Linux docker
- Đạt được các chiến lược vốn chủ sở hữu cân bằng với sự điều chỉnh có trật tự
- Phân tích dữ liệu chuỗi thời gian và kiểm tra lại dữ liệu tick
- Phân tích định lượng thị trường tiền kỹ thuật số
- Giao dịch cặp dựa trên công nghệ dữ liệu
- Sử dụng môi trường nghiên cứu để phân tích các chi tiết của việc bảo hiểm hình tam giác và tác động của phí xử lý đối với chênh lệch giá có thể bảo hiểm
- Cải cách API tương lai Deribit để thích nghi với giao dịch tùy chọn định lượng
- Các công cụ tốt hơn làm cho công việc tốt hơn - học cách sử dụng môi trường nghiên cứu để phân tích các nguyên tắc giao dịch
- Các chiến lược phòng ngừa rủi ro giữa các loại tiền tệ trong giao dịch định lượng các tài sản blockchain
- Mua hướng dẫn chiến lược tiền kỹ thuật số của FMex trên FMZ Quant
- Dạy bạn viết các chiến lược -- cấy ghép một chiến lược MyLanguage (Tiến bộ)
- Dạy bạn viết chiến lược -- cấy ghép một chiến lược MyLanguage
- Dạy bạn thêm hỗ trợ đa biểu đồ cho chiến lược
- Dạy bạn viết một hàm tổng hợp K-line trong phiên bản Python
- Phân tích chiến lược kênh Donchian trong môi trường nghiên cứu