এসপিওয়াই এবং আইডব্লিউএম এর মধ্যে সমতুল্য প্রত্যাবর্তন ব্যবহার করে একটি দিনের ব্যবসায়ের কৌশল
লেখক:ভাল, তৈরিঃ 2019-07-01 11:47:08, আপডেটঃ 2023-10-26 20:07:32
এই প্রবন্ধে, আমরা একটি intraday ট্রেডিং কৌশল লিখব. এটি ক্লাসিক ট্রেডিং ধারণা ব্যবহার করবে, যা হল পেনড্রাইভ রিটার্ন ট্রেডিং জুটি পেনড্রাইভ। এই উদাহরণে, আমরা দুটি ট্রেডিং ওপেন ইন্ডেক্স ফান্ড (ইটিএফ), এসপিওয়াই এবং আইডব্লিউএম ব্যবহার করব, যা নিউ ইয়র্ক স্টক এক্সচেঞ্জে (এনওয়াইএসই) ট্রেড করে এবং মার্কিন স্টক এক্সচেঞ্জের সূচকগুলির প্রতিনিধিত্ব করার চেষ্টা করে, যথাক্রমে পেনড্রাইভ এসএন্ডপি 500 এবং পেনড্রাইভ রাসেল 2000"।
এই কৌশলটি একটি মুনাফা বিভাজন তৈরি করে, একাধিক ETF তৈরি করে এবং অন্যটি খালি করে। বহু-স্পেস রেসিওগুলি অনেক উপায়ে সংজ্ঞায়িত করা যেতে পারে, যেমন পরিসংখ্যানগত সমন্বয় সময় সিরিজের পদ্ধতি ব্যবহার করে। এই পরিস্থিতিতে, আমরা SPY এবং IWM এর মধ্যে হেজিং অনুপাত গণনা করব। এটি আমাদের SPY এবং IWM এর মধ্যে মুনাফা বিভাজন তৈরি করতে অনুমতি দেবে, যা z-score হিসাবে স্ট্যান্ডার্ড করা হয়েছে। যখন z-score একটি নির্দিষ্ট থ্রেডভ্যালু ছাড়িয়ে যায়, তখন একটি ট্রেডিং সিগন্যাল তৈরি হবে, কারণ আমরা বিশ্বাস করি যে মুনাফা বিভাজনটি গড় ফিরে আসবে।
এই কৌশলটির মূলনীতি হল যে এসপিওয়াই এবং আইডব্লিউএম উভয়ই প্রায় একই বাজারের পরিস্থিতির প্রতিনিধিত্ব করে, যা বড় এবং ছোট মার্কিন কোম্পানিগুলির একটি গোষ্ঠীর শেয়ারের মূল্যের পারফরম্যান্স। এটি অনুমান করা হয় যে যদি দামের পিক-ইন-ইউনিভার্স রিগ্রেশন পিক তত্ত্ব গ্রহণ করা হয় তবে এটি সর্বদা ফিরে আসে, কারণ পিক-ইভেন্ট পিকগুলি খুব অল্প সময়ের মধ্যে পৃথকভাবে এসএন্ডপি 500 এবং রাসেল 2000 কে প্রভাবিত করতে পারে, তবে তাদের মধ্যে মুনাফা পার্থক্য সর্বদা স্বাভাবিক গড়ের দিকে ফিরে আসে এবং দীর্ঘমেয়াদী মূল্য সিরিজগুলি সর্বদা সমন্বিত হয়।
কৌশল
এই কৌশলটি নিম্নলিখিত ধাপগুলি অনুসরণ করে কার্যকর করা হয়ঃ
ডেটা - এপ্রিল ২০০৭ থেকে ফেব্রুয়ারি ২০১৪ পর্যন্ত স্পাই এবং আইডব্লিউএম-এর ১ মিনিটের কে-স্ট্রিম গ্রাফ পাওয়া গেছে।
প্রসেসিং - ডেটা সঠিকভাবে সারিবদ্ধ করা এবং একে অপরের সাথে অনুপস্থিত k-স্ট্রিমগুলি মুছে ফেলা।
পার্থক্য - দুইটি ইটিএফের মধ্যে হেজিং অনুপাত একটি রোলিং লিনিয়ার রিগ্রেশন গণনা ব্যবহার করে। এটি একটি বি-১-কে থেকে বি-১-এ একটি ক্রসপয়েন্ট গণনা করে বি-১-কে ফিরে যাওয়ার জন্য ব্যবহৃত হয়।
জেড-স্কোর - স্ট্যান্ডার্ড ডিফারেন্সের মানটি স্বাভাবিক পদ্ধতিতে গণনা করা হয়। এর অর্থ হল, এটার গড় মান (নমুনা) কেটে এটার স্ট্যান্ডার্ড ডিফারেন্স (নমুনা) কে বিয়োগ করা হয়। এর কারণ হল, এই থ্রেডওয়াল প্যারামিটারটি আরও সহজেই বোঝা যায়, কারণ জেড-স্কোর একটি মাত্রাহীন পরিমাণ। আমি ইচ্ছাকৃতভাবে হিসাবের মধ্যে ফরোয়ার্ড ডিভেশন ভেরিফিকেশন যুক্ত করেছি, যাতে দেখানো যায় যে এটি কতটা সূক্ষ্ম হতে পারে। চেষ্টা করুন!
লেনদেন - যখন নেতিবাচক z-স্কোরের মান নির্ধারিত (বা অনুকূলিত) থ্রেডভ্যারের নিচে নেমে যায় তখন অতিরিক্ত সিগন্যাল তৈরি করা হয়, এবং বিপরীতভাবে, যখন z-স্কোরের নিখুঁত মান অতিরিক্ত থ্রেডভ্যারের নিচে নেমে যায় তখন স্থির সিগন্যাল তৈরি করা হয়। এই কৌশলটির জন্য, আমি (কিছুটা এলোমেলোভাবে) বেছে নিয়েছি Z-স্কোর = 2 খোলা থ্রেডভ্যারি হিসাবে এবং Z-স্কোর = 1 স্থির থ্রেডভ্যারি হিসাবে।
সম্ভবত কৌশলটি গভীরভাবে বোঝার সর্বোত্তম উপায় হ'ল বাস্তবে এটি বাস্তবায়ন করা। নীচের বিভাগে এই সমতুল্য প্রত্যাবর্তন কৌশলটি বাস্তবায়নের জন্য সম্পূর্ণ পাইথন কোড (একক ফাইল) বিস্তারিতভাবে বর্ণনা করা হয়েছে। আমি আপনাকে আরও ভালভাবে বুঝতে সহায়তা করার জন্য বিস্তারিত কোড মন্তব্য যুক্ত করেছি।
পাইথন বাস্তবায়ন
সমস্ত পাইথন/পান্ডা টিউটোরিয়ালের মতো, এটিকে এই টিউটোরিয়ালে বর্ণিত পাইথন পরিবেশ অনুসারে সেট আপ করতে হবে। সেটআপটি সম্পন্ন হওয়ার পরে, প্রথম কাজটি প্রয়োজনীয় পাইথন লাইব্রেরি আমদানি করা। এটি matplotlib এবং pandas ব্যবহারের জন্য প্রয়োজনীয়।
আমি যেসব সংস্করণ ব্যবহার করি তা হলঃ
পাইথন - ২.৭.৩ NumPy - 1.8.0 পান্ডা - 0.12.0 matplotlib - 1.1.0
আমরা এই লাইব্রেরীগুলি আমদানি করতে যাচ্ছিঃ
# mr_spy_iwm.py
import matplotlib.pyplot as plt
import numpy as np
import os, os.path
import pandas as pd
নিম্নলিখিত ফাংশনটি create_pairs_dataframe দুইটি সিএসভি ফাইলের মধ্যে দুইটি চিহ্নযুক্ত k-line আমদানি করে; আমাদের উদাহরণে, এটি SPY এবং IWM হবে; তারপর এটি একটি পৃথক প্যাটার্ন প্যাটার্ন তৈরি করে, যা দুটি মূল ফাইলের সূচক ব্যবহার করে প্যাটার্ন প্যাটার্ন করবে; তাদের টাইমফ্রেমগুলি মিসড লেনদেন এবং ত্রুটির কারণে আলাদা হতে পারে; এটি একটি ডাটা বিশ্লেষক যেমন প্যান্ডাস ব্যবহারের অন্যতম প্রধান সুবিধা; আমরা খুব দক্ষতার সাথে স্যাম্পল প্যাটার্ন কোডগুলি প্যাটার্ন করি।
# mr_spy_iwm.py
def create_pairs_dataframe(datadir, symbols):
"""Creates a pandas DataFrame containing the closing price
of a pair of symbols based on CSV files containing a datetime
stamp and OHLCV data."""
# Open the individual CSV files and read into pandas DataFrames
print "Importing CSV data..."
sym1 = pd.io.parsers.read_csv(os.path.join(datadir, '%s.csv' % symbols[0]),
header=0, index_col=0,
names=['datetime','open','high','low','close','volume','na'])
sym2 = pd.io.parsers.read_csv(os.path.join(datadir, '%s.csv' % symbols[1]),
header=0, index_col=0,
names=['datetime','open','high','low','close','volume','na'])
# Create a pandas DataFrame with the close prices of each symbol
# correctly aligned and dropping missing entries
print "Constructing dual matrix for %s and %s..." % symbols
pairs = pd.DataFrame(index=sym1.index)
pairs['%s_close' % symbols[0].lower()] = sym1['close']
pairs['%s_close' % symbols[1].lower()] = sym2['close']
pairs = pairs.dropna()
return pairs
পরবর্তী ধাপটি হল SPY এবং IWM এর মধ্যে রোলিং লিনিয়ার রিগ্রেশন করা। এই পরিস্থিতিতে, IWM হল পূর্বাভাস (
SPY-IWM এর লিনিয়ার রিগ্রেসন মডেলের বিটা কোয়ালিটি গণনা করার পর, এটি DataFrame জোড়ায় যোগ করা হয় এবং ফাঁকা লাইন মুছে ফেলা হয়। এটি প্রথম K-লাইন তৈরি করে, যা রিট্রাকশন দৈর্ঘ্যের ট্রিম পরিমাপের সমান। তারপর, আমরা দুটি ETF এর মুনাফা তৈরি করি, SPY এর ইউনিট এবং IWM এর -i ইউনিট। স্পষ্টতই, এটি বাস্তবিক নয়, কারণ আমরা একটি ছোট পরিমাণে IWM ব্যবহার করছি, যা বাস্তব বাস্তবায়নে অসম্ভব।
অবশেষে, আমরা মুনাফার গড়কে বিয়োগ করে মুনাফার গড়কে বিয়োগ করে এবং মানসম্মত মুনাফার মানদণ্ডে বিয়োগ করে মুনাফার গড়ের z-স্কোর তৈরি করি। এটা লক্ষ্য করা দরকার যে এখানে একটি বেশ সূক্ষ্ম প্রাকদর্শী দৃষ্টিভঙ্গি বিয়োগ রয়েছে। আমি এটি কোডটিতে ইচ্ছাকৃতভাবে রেখেছি কারণ আমি জোর দিতে চাই যে গবেষণায় এই ধরনের ভুল করা কতটা সহজ। পুরো মুনাফার সময়কালের সারিগুলির গড় এবং মানদণ্ডের বিয়োগ গণনা করা। যদি এটি সত্যিকারের historicalতিহাসিক নির্ভুলতা প্রতিফলিত করার জন্য হয় তবে এই তথ্যগুলি পাওয়া যাবে না, কারণ এটি ভবিষ্যতের তথ্যকে অবিকল্পিতভাবে ব্যবহার করে। অতএব, আমরা রোলিং গড় এবং devst মানগুলি ব্যবহার করে z-স্কোর গণনা করা উচিত।
# mr_spy_iwm.py
def calculate_spread_zscore(pairs, symbols, lookback=100):
"""Creates a hedge ratio between the two symbols by calculating
a rolling linear regression with a defined lookback period. This
is then used to create a z-score of the 'spread' between the two
symbols based on a linear combination of the two."""
# Use the pandas Ordinary Least Squares method to fit a rolling
# linear regression between the two closing price time series
print "Fitting the rolling Linear Regression..."
model = pd.ols(y=pairs['%s_close' % symbols[0].lower()],
x=pairs['%s_close' % symbols[1].lower()],
window=lookback)
# Construct the hedge ratio and eliminate the first
# lookback-length empty/NaN period
pairs['hedge_ratio'] = model.beta['x']
pairs = pairs.dropna()
# Create the spread and then a z-score of the spread
print "Creating the spread/zscore columns..."
pairs['spread'] = pairs['spy_close'] - pairs['hedge_ratio']*pairs['iwm_close']
pairs['zscore'] = (pairs['spread'] - np.mean(pairs['spread']))/np.std(pairs['spread'])
return pairs
create_long_short_market_signals-এ, ট্রেডিং সিগন্যাল তৈরি করা হয়। এগুলি z-স্কোরের মানের দ্বারা থ্রেশহোল্ডের চেয়ে বেশি গণনা করা হয়। যখন z-স্কোরের পরম মান অন্য (ছোট) থ্রেশহোল্ডের চেয়ে কম বা সমান হয়, তখন একটি স্থির সিগন্যাল দেওয়া হয়।
এটি বাস্তবায়নের জন্য, প্রতি কে-লাইন জন্য একটি ট্রেডিং কৌশল প্রতিষ্ঠা করা প্রয়োজন যা খোলা-হাউজিং বা স্থির-হাউজিং; দীর্ঘ_বাজার এবং সংক্ষিপ্ত_বাজার হ'ল দুটি সংজ্ঞায়িত ভেরিয়েবল যা বহু-শিরোনাম এবং শূন্য শিরোনামগুলি ট্র্যাক করতে ব্যবহৃত হয়; দুর্ভাগ্যক্রমে, ভেক্টর পদ্ধতির তুলনায় পুনরাবৃত্তিমূলকভাবে প্রোগ্রাম করা সহজ এবং তাই এটি ধীর গণনা করা হয়; যদিও 1 মিনিটের কে-লাইন চার্ট প্রতি সিএসভি ফাইলের জন্য প্রায় 700,000 ডেটা পয়েন্ট প্রয়োজন, তবে আমার পুরানো ডেস্কটপে এটি এখনও তুলনামূলকভাবে দ্রুত গণনা করে!
একটি পান্ডা ডেটাফ্রেম (এটি নিঃসন্দেহে একটি অস্বাভাবিক অপারেশন) পুনরাবৃত্তি করার জন্য, iterrows পদ্ধতি ব্যবহার করা প্রয়োজন, যা একটি পুনরাবৃত্তি জেনারেটর সরবরাহ করেঃ
# mr_spy_iwm.py
def create_long_short_market_signals(pairs, symbols,
z_entry_threshold=2.0,
z_exit_threshold=1.0):
"""Create the entry/exit signals based on the exceeding of
z_enter_threshold for entering a position and falling below
z_exit_threshold for exiting a position."""
# Calculate when to be long, short and when to exit
pairs['longs'] = (pairs['zscore'] <= -z_entry_threshold)*1.0
pairs['shorts'] = (pairs['zscore'] >= z_entry_threshold)*1.0
pairs['exits'] = (np.abs(pairs['zscore']) <= z_exit_threshold)*1.0
# These signals are needed because we need to propagate a
# position forward, i.e. we need to stay long if the zscore
# threshold is less than z_entry_threshold by still greater
# than z_exit_threshold, and vice versa for shorts.
pairs['long_market'] = 0.0
pairs['short_market'] = 0.0
# These variables track whether to be long or short while
# iterating through the bars
long_market = 0
short_market = 0
# Calculates when to actually be "in" the market, i.e. to have a
# long or short position, as well as when not to be.
# Since this is using iterrows to loop over a dataframe, it will
# be significantly less efficient than a vectorised operation,
# i.e. slow!
print "Calculating when to be in the market (long and short)..."
for i, b in enumerate(pairs.iterrows()):
# Calculate longs
if b[1]['longs'] == 1.0:
long_market = 1
# Calculate shorts
if b[1]['shorts'] == 1.0:
short_market = 1
# Calculate exists
if b[1]['exits'] == 1.0:
long_market = 0
short_market = 0
# This directly assigns a 1 or 0 to the long_market/short_market
# columns, such that the strategy knows when to actually stay in!
pairs.ix[i]['long_market'] = long_market
pairs.ix[i]['short_market'] = short_market
return pairs
এই পর্যায়ে, আমরা প্রকৃত বহু, ফাঁকা সংকেত অন্তর্ভুক্ত করার জন্য জোড়া আপডেট করেছি, যা আমাদের সিদ্ধান্ত নিতে সক্ষম করেছে যে আমাদের ট্রেডিং শুরু করা দরকার কিনা। এখন আমাদের একটি পোর্টফোলিও তৈরি করতে হবে যা অবস্থানের বাজার মূল্যকে ট্র্যাক করবে। প্রথম কাজটি হল একটি অবস্থান কলাম তৈরি করা যা বহু শিরোনাম এবং ফাঁকা সংকেতগুলিকে একত্রিত করে। এটিতে একটি কলামের উপাদান থাকবে যা থেকে ((1,0,-1), যেখানে 1 বহু শিরোনামকে নির্দেশ করে, যেখানে 0 কোনও অবস্থানকে নির্দেশ করে না ((প্লেইন হওয়া উচিত), এবং -1 ফাঁকা অবস্থানকে নির্দেশ করে। sym1 এবং sym2 কলামগুলি প্রতিটি k-রেখা শেষে SPY এবং IWM অবস্থানের বাজার মূল্যকে নির্দেশ করে।
একবার ইটিএফের বাজারমূল্য তৈরি হয়ে গেলে, আমরা সেগুলিকে একত্রিত করি এবং প্রতিটি k-স্ট্রিংয়ের শেষে মোট বাজারমূল্য উত্পাদন করি; তারপর এটিকে বস্তুর pct_change পদ্ধতির মাধ্যমে ফেরতের মান হিসাবে রূপান্তর করি; পরবর্তী কোড লাইনগুলি ভুল নিবন্ধগুলি (NaN এবং inf উপাদানগুলি) সরিয়ে দেয় এবং অবশেষে একটি সম্পূর্ণ স্বার্থ কার্ভ গণনা করে।
# mr_spy_iwm.py
def create_portfolio_returns(pairs, symbols):
"""Creates a portfolio pandas DataFrame which keeps track of
the account equity and ultimately generates an equity curve.
This can be used to generate drawdown and risk/reward ratios."""
# Convenience variables for symbols
sym1 = symbols[0].lower()
sym2 = symbols[1].lower()
# Construct the portfolio object with positions information
# Note that minuses to keep track of shorts!
print "Constructing a portfolio..."
portfolio = pd.DataFrame(index=pairs.index)
portfolio['positions'] = pairs['long_market'] - pairs['short_market']
portfolio[sym1] = -1.0 * pairs['%s_close' % sym1] * portfolio['positions']
portfolio[sym2] = pairs['%s_close' % sym2] * portfolio['positions']
portfolio['total'] = portfolio[sym1] + portfolio[sym2]
# Construct a percentage returns stream and eliminate all
# of the NaN and -inf/+inf cells
print "Constructing the equity curve..."
portfolio['returns'] = portfolio['total'].pct_change()
portfolio['returns'].fillna(0.0, inplace=True)
portfolio['returns'].replace([np.inf, -np.inf], 0.0, inplace=True)
portfolio['returns'].replace(-1.0, 0.0, inplace=True)
# Calculate the full equity curve
portfolio['returns'] = (portfolio['returns'] + 1.0).cumprod()
return portfolio
প্রধান ফাংশন এগুলিকে একত্রিত করে। ⇒ CSV ফাইলটি ডেটাডির পাথে অবস্থিত। ⇒ আপনার নির্দিষ্ট ডিরেক্টরিতে নির্দেশ করার জন্য নীচের কোডটি সংশোধন করতে ভুলবেন না।
কৌশলটি লুকব্যাক চক্রের প্রতি কতটা সংবেদনশীল তা নির্ধারণ করার জন্য, লুকব্যাকের কর্মক্ষমতা সূচকগুলির একটি সিরিজ গণনা করা প্রয়োজন। আমি পোর্টফোলিওর চূড়ান্ত মোট রিটার্নের শতাংশকে পারফরম্যান্স সূচক এবং লুকব্যাকের পরিসীমা হিসেবে বেছে নিয়েছি[50,200], যা 10 এর ইনক্রিমেন্ট। আপনি নীচের কোডে দেখতে পাচ্ছেন যে, পূর্ববর্তী ফাংশনটি এই পরিসরের মধ্যে for লুপে অন্তর্ভুক্ত রয়েছে, অন্যান্য থ্রেশহোল্ডগুলি অপরিবর্তিত রয়েছে। শেষ কাজটি হল matplotlib ব্যবহার করে লুকব্যাকগুলির তুলনায় রিটার্নগুলির একটি লাইন ফোল্ডার তৈরি করাঃ
# mr_spy_iwm.py
if __name__ == "__main__":
datadir = '/your/path/to/data/' # Change this to reflect your data path!
symbols = ('SPY', 'IWM')
lookbacks = range(50, 210, 10)
returns = []
# Adjust lookback period from 50 to 200 in increments
# of 10 in order to produce sensitivities
for lb in lookbacks:
print "Calculating lookback=%s..." % lb
pairs = create_pairs_dataframe(datadir, symbols)
pairs = calculate_spread_zscore(pairs, symbols, lookback=lb)
pairs = create_long_short_market_signals(pairs, symbols,
z_entry_threshold=2.0,
z_exit_threshold=1.0)
portfolio = create_portfolio_returns(pairs, symbols)
returns.append(portfolio.ix[-1]['returns'])
print "Plot the lookback-performance scatterchart..."
plt.plot(lookbacks, returns, '-o')
plt.show()
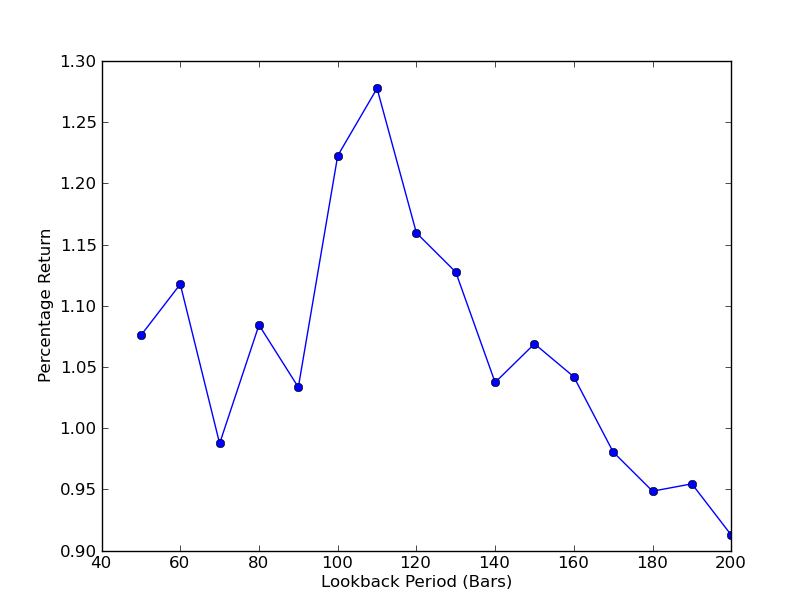
এখন আপনি lookbacks এবং returns এর একটি চার্ট দেখতে পারেন. মনে রাখবেন, lookback এর একটি সর্বাধিক ভলিউম ভলিউম আছে, যা 110 k-জোড়ের সমান। যদি আমরা lookbacks এবং returns এর মধ্যে কোন সম্পর্ক না দেখি, তাহলে এর কারণ হলঃ
SPY-IWM লিনিয়ার রিগ্রেশন হেজিং তুলনায় লুকব্যাক সময় সংবেদনশীলতা বিশ্লেষণ
উপরের দিকে ঝুঁকানো মুনাফা কার্ভ ছাড়া, যে কোনও রিটার্নিং নিবন্ধ অসম্পূর্ণ! সুতরাং, আপনি যদি সময়কালের সাথে সংযোজনমূলক মুনাফা রিটার্নের একটি কার্ভ আঁকতে চান তবে নিম্নলিখিত কোডটি ব্যবহার করতে পারেন। এটি লুকব্যাক পরামিতি গবেষণায় উত্পন্ন চূড়ান্ত পোর্টফোলিওটি আঁকবে। অতএব, আপনি যে চার্টটি দেখতে চান তার উপর ভিত্তি করে লুকব্যাক নির্বাচন করা প্রয়োজন। চার্টটি তুলনা করতে সহায়তা করার জন্য একই সময়ের এসপিওয়াইয়ের রিটার্নও আঁকেঃ
# mr_spy_iwm.py
# This is still within the main function
print "Plotting the performance charts..."
fig = plt.figure()
fig.patch.set_facecolor('white')
ax1 = fig.add_subplot(211, ylabel='%s growth (%%)' % symbols[0])
(pairs['%s_close' % symbols[0].lower()].pct_change()+1.0).cumprod().plot(ax=ax1, color='r', lw=2.)
ax2 = fig.add_subplot(212, ylabel='Portfolio value growth (%%)')
portfolio['returns'].plot(ax=ax2, lw=2.)
fig.show()
নিম্নলিখিত অধিকার-সুবিধার কার্ভ চার্টের লুকব্যাক সময়কাল ১০০ দিনঃ
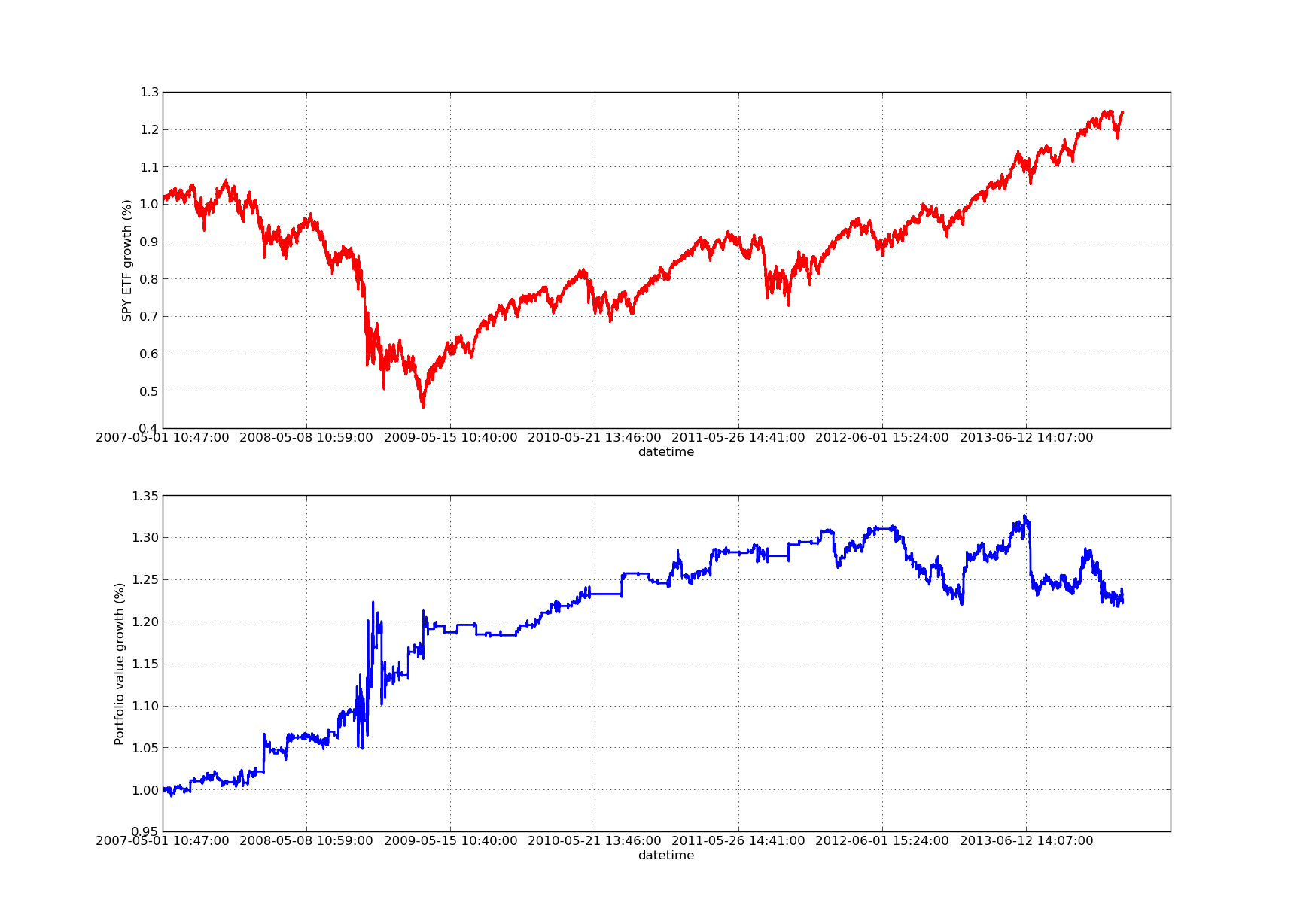
SPY-IWM লিনিয়ার রিগ্রেশন হেজিং তুলনায় লুকব্যাক সময় সংবেদনশীলতা বিশ্লেষণ
দয়া করে মনে রাখবেন যে আর্থিক সঙ্কটের সময় ২০০৯ সালে এসপিওয়াই-তে ব্যাপকভাবে হ্রাস ঘটেছে। এই কৌশলটি এই পর্যায়েও অশান্তিপূর্ণ অবস্থায় রয়েছে। এছাড়াও, মনে রাখবেন যে এই সময়ের মধ্যে এসপিওয়াই-র তীব্র প্রবণতার প্রকৃতি স্ট্যান্ডার্ড 500 সূচককে প্রতিফলিত করে।
দয়া করে মনে রাখবেন যে z-score এর সুবিধার হিসাব করার সময়, আমাদের এখনও ফরোয়ার্ড ডিভিশন ফরোয়ার্ড বিবেচনা করতে হবে। উপরন্তু, এই সমস্ত গণনাগুলি কোনও লেনদেনের ব্যয় ছাড়াই করা হয়েছে। একবার এই কারণগুলি বিবেচনা করা হলে, এই কৌশলটি অবশ্যই খারাপভাবে কাজ করবে। পদ্ধতির ফি এবং স্লিপ পয়েন্টগুলি বর্তমানে অনিশ্চিত। উপরন্তু, এই কৌশলটি ইটিএফের একটি ছোট সংখ্যক ইউনিটে লেনদেন করা হয়, যা খুব অবাস্তব।
পরবর্তী প্রবন্ধে, আমরা একটি আরও জটিল ইভেন্ট-ড্রাইভ ব্যাকটেস্টার তৈরি করব যা উপরের বিষয়গুলিকে বিবেচনা করবে, যাতে আমরা তহবিলের কার্ভ এবং পারফরম্যান্স সূচকগুলিতে আরও আত্মবিশ্বাসী হতে পারি।
- এফএমজেড কোয়ান্টের নতুন বৈশিষ্ট্যঃ সহজেই এইচটিটিপি সার্ভিস তৈরি করতে _সার্ভ ফাংশন ব্যবহার করুন
- উদ্ভাবক নতুন বৈশিষ্ট্য পরিমাণঃ _Serve ফাংশন ব্যবহার করে সহজেই HTTP পরিষেবা তৈরি করুন
- FMZ কোয়ান্ট ট্রেডিং প্ল্যাটফর্ম কাস্টম প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড তহবিলের হার অর্জন এবং পর্যবেক্ষণ কৌশল
- এফএমজেড তহবিলের হার প্রাপ্তি এবং পর্যবেক্ষণ কৌশল কৌশল
- একটি কৌশল টেমপ্লেট আপনাকে ওয়েবসকেট মার্কেটকে নির্বিঘ্নে ব্যবহার করতে দেয়
- একটি নীতিমালা টেমপ্লেট যা আপনাকে ওয়েবসকেট ক্ষেত্রের সাথে নির্বিঘ্নে ব্যবহার করতে দেয়
- ইনভেন্টর কোয়ালিফাইড ট্রেডিং প্ল্যাটফর্মের সাধারণ প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড আপগ্রেডের পরে কীভাবে দ্রুত একটি ইউনিভার্সাল মাল্টি-কারেন্সি ট্রেডিং কৌশল তৈরি করবেন
- এফএমজেড আপগ্রেডের পরে কীভাবে দ্রুত একটি সাধারণ বহু-মুদ্রা ট্রেডিং কৌশল তৈরি করা যায়
- ডিসিএ ট্রেডিংঃ একটি বহুল ব্যবহৃত পরিমাণগত কৌশল