ট্রেডিং এ মেশিন লার্নিং প্রযুক্তির প্রয়োগ
 3
3072
3
3072

এই নিবন্ধটি উদ্ভাবক কোয়ান্ট প্ল্যাটফর্মে আমার ডেটা গবেষণার সময় ট্রেডিং সমস্যাগুলির জন্য মেশিন লার্নিং কৌশল প্রয়োগ করার চেষ্টা করার পরে কিছু সাধারণ সতর্কতা এবং ত্রুটি সম্পর্কে আমার পর্যবেক্ষণ দ্বারা অনুপ্রাণিত হয়েছিল।
আপনি যদি আমার আগের নিবন্ধগুলি না পড়ে থাকেন তবে আমরা সুপারিশ করব যে আপনি এই নিবন্ধের আগে একটি স্বয়ংক্রিয় ডেটা গবেষণা পরিবেশ এবং উদ্ভাবক পরিমাণগত প্ল্যাটফর্মে ট্রেডিং কৌশল বিকাশের জন্য একটি পদ্ধতিগত পদ্ধতির জন্য আমার পূর্ববর্তী নির্দেশিকাটি পড়ুন।
ঠিকানাগুলি এখানে: https://www.fmz.com/digest-topic/4187 এবং https://www.fmz.com/digest-topic/4169 এই দুটি নিবন্ধ।
গবেষণা পরিবেশ স্থাপন সম্পর্কে
এই টিউটোরিয়ালটি সমস্ত দক্ষতার স্তরের উত্সাহী, প্রকৌশলী এবং ডেটা বিজ্ঞানীদের দ্বারা ব্যবহার করার জন্য ডিজাইন করা হয়েছে, আপনি একজন শিল্প বিশেষজ্ঞ বা একজন প্রোগ্রামিং নবাগত, আপনার প্রয়োজন একমাত্র দক্ষতা হল পাইথন প্রোগ্রামিং ভাষার একটি প্রাথমিক বোঝা এবং কমান্ড লাইনের পর্যাপ্ত জ্ঞান। অপারেশন (যতদিন আপনি একটি ডেটা বিজ্ঞান প্রকল্প সেট আপ করতে পারেন)
- উদ্ভাবক কোয়ান্ট হোস্ট ইনস্টল করুন এবং অ্যানাকোন্ডা সেট আপ করুন
প্রধান মূলধারার এক্সচেঞ্জগুলি থেকে উচ্চ-মানের ডেটা উত্স সরবরাহ করার পাশাপাশি, FMZ.COM, উদ্ভাবকের পরিমাণগত প্ল্যাটফর্ম, ডেটা বিশ্লেষণ সম্পূর্ণ করার পরে আমাদের স্বয়ংক্রিয় ট্রেডিং পরিচালনা করতে সহায়তা করার জন্য API ইন্টারফেসের একটি সমৃদ্ধ সেট সরবরাহ করে। ইন্টারফেসের এই সেটটিতে ব্যবহারিক টুল রয়েছে যেমন অ্যাকাউন্টের তথ্য অনুসন্ধান করা, উচ্চ, খোলার, কম, বন্ধের মূল্য, ট্রেডিং ভলিউম, বিভিন্ন মূলধারার এক্সচেঞ্জের বিভিন্ন সাধারণ প্রযুক্তিগত বিশ্লেষণের সূচক, বিশেষ করে যারা প্রকৃত ট্রেডিংয়ের সময় প্রধান মূলধারার এক্সচেঞ্জের সাথে সংযোগ করেন তাদের জন্য। প্রক্রিয়া পাবলিক API ইন্টারফেস শক্তিশালী প্রযুক্তিগত সহায়তা প্রদান করে।
উপরে উল্লিখিত সমস্ত বৈশিষ্ট্যগুলি ডকারের মতো একটি সিস্টেমে এনক্যাপসুলেট করা হয়েছে আমাদের যা করতে হবে তা হল আমাদের নিজস্ব ক্লাউড কম্পিউটিং পরিষেবা ক্রয় করা এবং তারপরে ডকার সিস্টেম স্থাপন করা।
উদ্ভাবক কোয়ান্টিফিকেশন প্ল্যাটফর্মের অফিসিয়াল নামে, এই ডকার সিস্টেমটিকে হোস্ট সিস্টেম বলা হয়।
কিভাবে হোস্ট এবং রোবট স্থাপন করতে হয়, অনুগ্রহ করে আমার আগের নিবন্ধটি পড়ুন: https://www.fmz.com/bbs-topic/4140
যে পাঠকরা তাদের নিজস্ব ক্লাউড কম্পিউটিং সার্ভার স্থাপনার হোস্টার কিনতে চান তারা এই নিবন্ধটি উল্লেখ করতে পারেন: https://www.fmz.com/bbs-topic/2848
ক্লাউড কম্পিউটিং পরিষেবা এবং হোস্ট সিস্টেম সফলভাবে স্থাপন করার পরে, পরবর্তী, আমাদের পাইথনের বৃহত্তম শিল্পকর্মটি ইনস্টল করতে হবে: অ্যানাকোন্ডা
এই নিবন্ধটির জন্য প্রয়োজনীয় সমস্ত প্রাসঙ্গিক প্রোগ্রামিং পরিবেশ বাস্তবায়নের জন্য (নির্ভরতা লাইব্রেরি, সংস্করণ ব্যবস্থাপনা, ইত্যাদি), সবচেয়ে সহজ উপায় হল Anaconda ব্যবহার করা। এটি একটি প্যাকেজড পাইথন ডেটা সায়েন্স ইকোসিস্টেম এবং নির্ভরতা লাইব্রেরি ম্যানেজার।
যেহেতু আমরা ক্লাউড সার্ভিসে অ্যানাকোন্ডা ইনস্টল করছি, তাই আমরা সুপারিশ করছি যে ক্লাউড সার্ভারটি Linux সিস্টেম এবং Anaconda-এর কমান্ড লাইন সংস্করণ ইনস্টল করে।
অ্যানাকোন্ডার ইনস্টলেশন পদ্ধতির জন্য, অনুগ্রহ করে অ্যানাকোন্ডার অফিসিয়াল গাইডটি দেখুন: https://www.anaconda.com/distribution/
আপনি যদি একজন অভিজ্ঞ পাইথন প্রোগ্রামার হন এবং মনে করেন না যে আপনার অ্যানাকোন্ডা ব্যবহার করার দরকার আছে, তাহলে কোন সমস্যা নেই। আমি অনুমান করতে যাচ্ছি যে প্রয়োজনীয় নির্ভরতা ইনস্টল করার জন্য আপনার সাহায্যের প্রয়োজন নেই এবং আপনি এই বিভাগটি এড়িয়ে যেতে পারেন।
একটি ট্রেডিং কৌশল বিকাশ করুন
একটি ট্রেডিং কৌশলের চূড়ান্ত ফলাফলে নিম্নলিখিত প্রশ্নের উত্তর দেওয়া উচিত:
দিকনির্দেশ: একটি সম্পদ সস্তা, ব্যয়বহুল বা মোটামুটি মূল্যবান কিনা তা নির্ধারণ করুন।
একটি অবস্থান খোলার শর্ত: সম্পদ সস্তা বা ব্যয়বহুল হলে, আপনি দীর্ঘ বা ছোট যেতে হবে.
ক্লোজিং ট্রেড: যদি সম্পদের মূল্য যুক্তিসঙ্গত হয় এবং আমাদের সম্পদে একটি অবস্থান থাকে (আগের ক্রয় বা বিক্রয়), তাহলে আপনি কি অবস্থানটি বন্ধ করবেন?
মূল্য সীমা: মূল্য (বা পরিসর) যেটিতে একটি ট্রেড খুলতে হবে
পরিমাণ: ট্রেডিং ফান্ডের পরিমাণ (যেমন ডিজিটাল মুদ্রার পরিমাণ বা কমোডিটি ফিউচার লটের সংখ্যা)
উপরের প্রতিটি প্রশ্নের উত্তর দেওয়ার জন্য মেশিন লার্নিং ব্যবহার করা যেতে পারে, তবে এই নিবন্ধের বাকি অংশের জন্য আমরা প্রথম প্রশ্নের উত্তরে ফোকাস করব, বাণিজ্য নির্দেশনা।
কৌশলগত পদ্ধতি
কৌশল তৈরির জন্য দুটি ধরণের পদ্ধতি রয়েছে, একটি মডেল-ভিত্তিক; অন্যটি ডেটা মাইনিংয়ের উপর ভিত্তি করে। দুটি মূলত বিপরীত পন্থা।
মডেল-ভিত্তিক কৌশল নির্মাণে, আমরা বাজারের অদক্ষতার একটি মডেল দিয়ে শুরু করি, গাণিতিক রাশি (যেমন, দাম, রিটার্ন) তৈরি করি এবং দীর্ঘ সময় ধরে তাদের কার্যকারিতা পরীক্ষা করি। মডেলটি সাধারণত একটি বাস্তব জটিল মডেলের সরলীকৃত সংস্করণ, এবং দীর্ঘমেয়াদে এর তাৎপর্য এবং স্থায়িত্ব যাচাই করা প্রয়োজন। স্বাভাবিক প্রবণতা অনুসরণ, গড় প্রত্যাবর্তন এবং সালিসি কৌশলগুলি এই বিভাগে পড়ে।
অন্যদিকে, আমরা প্রথমে দামের নিদর্শন খুঁজি এবং ডেটা মাইনিং পদ্ধতিতে অ্যালগরিদম ব্যবহার করার চেষ্টা করি। এই নিদর্শনগুলি কী কারণে ঘটেছে তা বিবেচ্য নয়, কারণ শুধুমাত্র নির্দিষ্ট নিদর্শনগুলি ভবিষ্যতে নিজেদের পুনরাবৃত্তি করতে থাকবে৷ এটি একটি অন্ধ বিশ্লেষণ পদ্ধতি এবং এলোমেলো নিদর্শন থেকে বাস্তব নিদর্শন সনাক্ত করতে আমাদের কঠোর পরিদর্শন প্রয়োজন। “ট্রায়াল এবং এরর মেথড”, “কে-লাইন চার্ট প্যাটার্ন” এবং “ফিচার ভর রিগ্রেশন” এই বিভাগের অন্তর্গত।
স্পষ্টতই, মেশিন লার্নিং ডেটা মাইনিং পদ্ধতিতে সহজেই কাজ করে। আসুন দেখি কিভাবে মেশিন লার্নিং ব্যবহার করে ডেটা মাইনিং এর মাধ্যমে ট্রেডিং সিগন্যাল তৈরি করা যায়।
কোড উদাহরণ ব্যাকটেস্টিং টুল এবং উদ্ভাবক পরিমাণগত প্ল্যাটফর্মের উপর ভিত্তি করে স্বয়ংক্রিয় ট্রেডিং API ইন্টারফেস ব্যবহার করে। হোস্ট স্থাপন এবং উপরোক্ত অংশে Anaconda ইনস্টল করার পরে, আপনাকে শুধুমাত্র আমাদের প্রয়োজনীয় ডেটা সায়েন্স অ্যানালাইসিস লাইব্রেরি এবং বিখ্যাত মেশিন লার্নিং মডেল scikit-learn ইনস্টল করতে হবে।
pip install -U scikit-learn
মেশিন লার্নিং ব্যবহার করে ট্রেডিং কৌশল সংকেত তৈরি করুন
- ডেটা মাইনিং
আমরা শুরু করার আগে, একটি স্ট্যান্ডার্ড মেশিন লার্নিং সমস্যা সিস্টেম নীচে দেখানো হয়েছে:
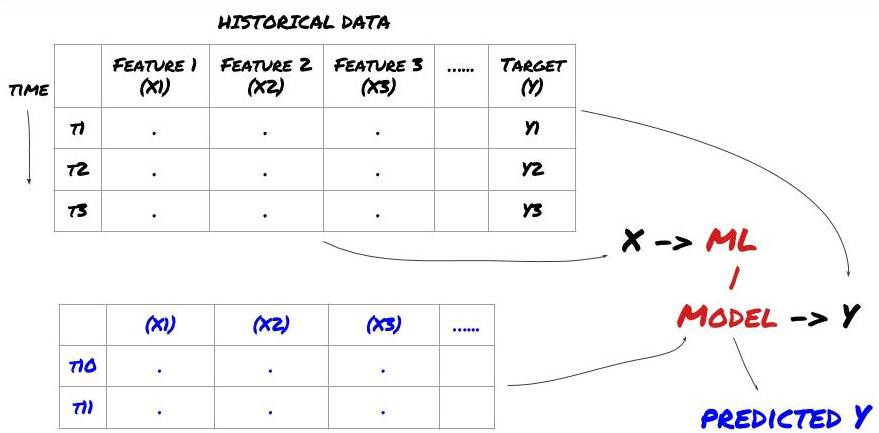
মেশিন লার্নিং সমস্যা সিস্টেম
আমরা যে বৈশিষ্ট্যগুলি তৈরি করতে যাচ্ছি তাতে অবশ্যই কিছু ভবিষ্যদ্বাণীমূলক শক্তি (X) থাকতে হবে যা আমরা লক্ষ্য ভেরিয়েবল (Y) ভবিষ্যদ্বাণী করতে চাই এবং একটি ML মডেলকে প্রশিক্ষিত করতে ঐতিহাসিক ডেটা ব্যবহার করতে চাই যা যথাসম্ভব প্রকৃত মানের কাছাকাছি Y-এর পূর্বাভাস দিতে পারে৷ অবশেষে, আমরা এই মডেলটি ব্যবহার করি নতুন ডেটার উপর ভবিষ্যদ্বাণী করতে যেখানে Y অজানা। এটি আমাদের প্রথম ধাপে নিয়ে আসে:
ধাপ 1: আপনার প্রশ্ন সেট আপ করুন
- আপনি কি ভবিষ্যদ্বাণী করতে চান? একটি ভাল ভবিষ্যদ্বাণী কি? আপনি কিভাবে পূর্বাভাস ফলাফল রেট হবে?
যে, আমাদের উপরের কাঠামোতে, Y কি?
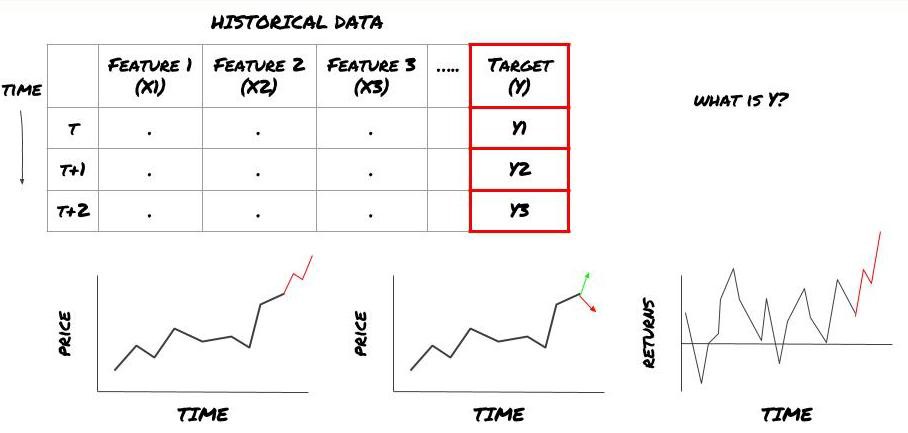
তুমি কী ভবিষ্যদ্বাণী করতে চাও?
আপনি কি ভবিষ্যতের দাম, ভবিষ্যতের রিটার্ন/পিএনএল, ক্রয়/বিক্রয় সংকেত, পোর্টফোলিও বরাদ্দ অপ্টিমাইজ করতে এবং দক্ষতার সাথে ট্রেড সম্পাদন করার চেষ্টা করতে চান?
ধরা যাক আমরা পরের টাইমস্ট্যাম্পে মূল্য অনুমান করার চেষ্টা করছি। এই ক্ষেত্রে, Y(t) = মূল্য(t+1)। এখন আমরা ঐতিহাসিক তথ্য দিয়ে আমাদের কাঠামো সম্পূর্ণ করতে পারি
মনে রাখবেন যে Y(t) শুধুমাত্র ব্যাকটেস্টে পরিচিত, কিন্তু যখন আমরা আমাদের মডেল ব্যবহার করি তখন আমরা t (t+1) সময়ে মূল্য জানব না। আমরা আমাদের মডেলটি ব্যবহার করি ভবিষ্যদ্বাণী করতে Y(ভবিষ্যদ্বাণী করা,t) এবং এটিকে শুধুমাত্র t+1 সময়ে প্রকৃত মানের সাথে তুলনা করি। এর মানে আপনি একটি ভবিষ্যদ্বাণীমূলক মডেলের বৈশিষ্ট্য হিসাবে Y ব্যবহার করতে পারবেন না।
একবার আমরা লক্ষ্য Y জেনে গেলে, আমরা আমাদের ভবিষ্যদ্বাণীগুলি কীভাবে মূল্যায়ন করব তাও সিদ্ধান্ত নিতে পারি। আমরা ডেটাতে চেষ্টা করব বিভিন্ন মডেলের মধ্যে পার্থক্য করার জন্য এটি গুরুত্বপূর্ণ। আমরা যে সমস্যার সমাধান করছি তার উপর নির্ভর করে, আমাদের মডেলের দক্ষতা পরিমাপের জন্য একটি মেট্রিক বেছে নিন। উদাহরণস্বরূপ, যদি আমরা দামের পূর্বাভাস দিই, আমরা একটি সূচক হিসাবে রুট গড় বর্গাকার ত্রুটি ব্যবহার করতে পারি। কিছু সাধারণভাবে ব্যবহৃত সূচক (মুভিং এভারেজ, MACD, ভ্যারিয়েন্স স্কোর, ইত্যাদি) উদ্ভাবকের পরিমাণগত টুলবক্সে প্রিকোড করা হয়েছে এবং আপনি API ইন্টারফেসের মাধ্যমে বিশ্বব্যাপী এই সূচকগুলিকে কল করতে পারেন।
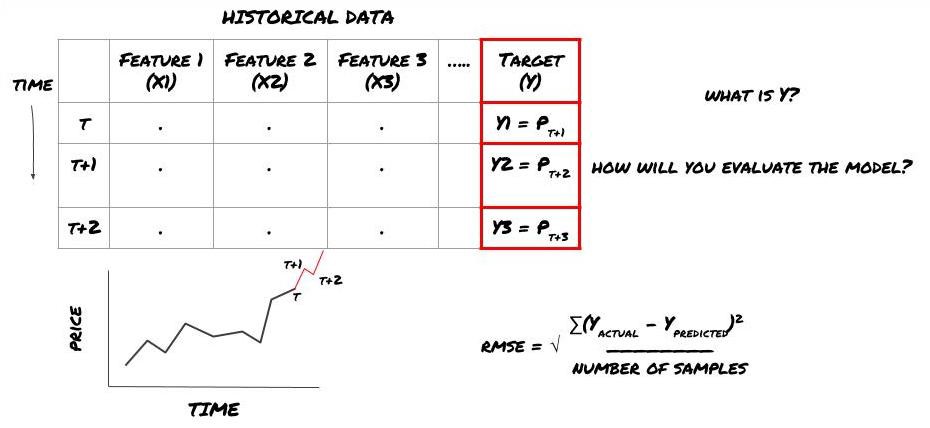
ভবিষ্যতের দামের পূর্বাভাস দেওয়ার জন্য ML কাঠামো
প্রদর্শন করার জন্য, আমরা একটি অনুমানমূলক বিনিয়োগের ভবিষ্যত প্রত্যাশিত ভিত্তিরেখা মান ভবিষ্যদ্বাণী করার জন্য একটি ভবিষ্যদ্বাণীমূলক মডেল তৈরি করব, যেখানে:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
যেহেতু এটি একটি রিগ্রেশন সমস্যা, আমরা RMSE তে মডেলটি মূল্যায়ন করব (রুট মানে বর্গ ত্রুটি)। আমরা মূল্যায়নের মানদণ্ড হিসাবে মোট Pnl ব্যবহার করব
দ্রষ্টব্য: RMSE সম্পর্কে প্রাসঙ্গিক গাণিতিক জ্ঞানের জন্য, অনুগ্রহ করে Baidu এনসাইক্লোপিডিয়ার প্রাসঙ্গিক বিষয়বস্তু পড়ুন
- আমাদের লক্ষ্য: এমন একটি মডেল তৈরি করুন যা Y যতটা সম্ভব কাছাকাছি ভবিষ্যদ্বাণী করে।
ধাপ ২: নির্ভরযোগ্য তথ্য সংগ্রহ করুন
তথ্য সংগ্রহ এবং পরিষ্কার করুন যা আপনাকে হাতের সমস্যা সমাধানে সহায়তা করে
টার্গেট ভেরিয়েবল Y-এর জন্য ভবিষ্যদ্বাণীমূলক শক্তি পাওয়ার জন্য আপনাকে কোন ডেটা বিবেচনা করতে হবে? আমরা যদি দামের পূর্বাভাস দিই, তাহলে আপনি বিনিয়োগ লক্ষ্যমাত্রার মূল্য ডেটা, বিনিয়োগ লক্ষ্যমাত্রার লেনদেনের পরিমাণ ডেটা, সম্পর্কিত বিনিয়োগ লক্ষ্যমাত্রার অনুরূপ ডেটা, বিনিয়োগ লক্ষ্য সূচকের স্তর এবং অন্যান্য সামগ্রিক বাজার সূচক, অন্যান্য সম্পর্কিত সম্পদের দাম ইত্যাদি ব্যবহার করতে পারেন।
আপনাকে এই ডেটার জন্য ডেটা অ্যাক্সেসের অনুমতি সেট আপ করতে হবে, আপনার ডেটা সঠিক কিনা তা নিশ্চিত করুন এবং হারিয়ে যাওয়া ডেটা (খুব সাধারণ সমস্যা) সমাধান করতে হবে। এছাড়াও নিশ্চিত করুন যে আপনার ডেটা নিরপেক্ষ এবং পর্যাপ্তভাবে সমস্ত বাজারের অবস্থার প্রতিনিধিত্ব করে (যেমন, একই সংখ্যক লাভ এবং ক্ষতির পরিস্থিতি) মডেলে পক্ষপাত এড়াতে। লভ্যাংশ, বিনিয়োগ লক্ষ্য বিভাজন, ধারাবাহিকতা ইত্যাদি পেতে আপনাকে ডেটা পরিষ্কার করতে হতে পারে।
আপনি যদি ইনভেনটর কোয়ান্ট প্ল্যাটফর্ম (FMZ.COM) ব্যবহার করেন, তাহলে আমরা Google, Yahoo, NSE এবং Quandl-এর কাছ থেকে CTP এবং Yisheng, Binance, OKEX, Huobi এবং বিটমেক্স এবং মূলধারার ডিজিটাল কারেন্সি এক্সচেঞ্জের অন্যান্য ডেটা ইনভেনটর কোয়ান্টিটেটিভ প্ল্যাটফর্ম এই ডেটাগুলিকে প্রাক-পরিষ্কার করে এবং ফিল্টার করে, যেমন বিনিয়োগ লক্ষ্য বিভাজন এবং গভীরতাপূর্ণ বাজারের ডেটা, এবং কৌশল বিকাশকারীদের কাছে একটি ফর্ম্যাটে উপস্থাপন করে যা পরিমাণগত কর্মীদের জন্য সহজ। বুঝতে
এই নিবন্ধটির প্রদর্শনের সুবিধার্থে, আমরা ভার্চুয়াল বিনিয়োগ লক্ষ্য ‘MQK’ হিসাবে ব্যবহার করি আমরা আরও তথ্যের জন্য, অনুগ্রহ করে দেখুন: https://github.com নামে একটি খুব সুবিধাজনক পরিমাণগত টুল /Auquan/ auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
উপরের কোডের সাথে, Auquan’s Toolbox ডাটা ফ্রেম ডিকশনারিতে ডাটা ডাউনলোড করে লোড করেছে। আমাদের এখন আমাদের পছন্দের ফরম্যাটে ডেটা প্রস্তুত করতে হবে। ফাংশন ds.getBookDataByFeature() ডেটা ফ্রেমের একটি অভিধান প্রদান করে, প্রতি বৈশিষ্ট্যে একটি ডেটা ফ্রেম। আমরা সমস্ত বৈশিষ্ট্য সহ স্টকগুলির জন্য একটি নতুন ডেটাফ্রেম তৈরি করি৷
ধাপ 3: ডেটা বিভক্ত করুন
- ডেটা থেকে প্রশিক্ষণ সেট তৈরি করুন, এই ডেটা সেটগুলি ক্রস-ভ্যালিডেট করুন এবং পরীক্ষা করুন
এটি একটি খুব গুরুত্বপূর্ণ পদক্ষেপ! আমরা এগিয়ে যাওয়ার আগে, আমাদের ডেটাগুলিকে একটি প্রশিক্ষণ ডেটাসেটে ভাগ করা উচিত, আপনার মডেলকে প্রশিক্ষণ দেওয়ার জন্য, এবং একটি পরীক্ষামূলক ডেটাসেটে, মডেলের কর্মক্ষমতা মূল্যায়ন করার জন্য। প্রস্তাবিত ভাগ হল: ৬০-৭০% প্রশিক্ষণ সেট এবং ৩০-৪০% পরীক্ষার সেট
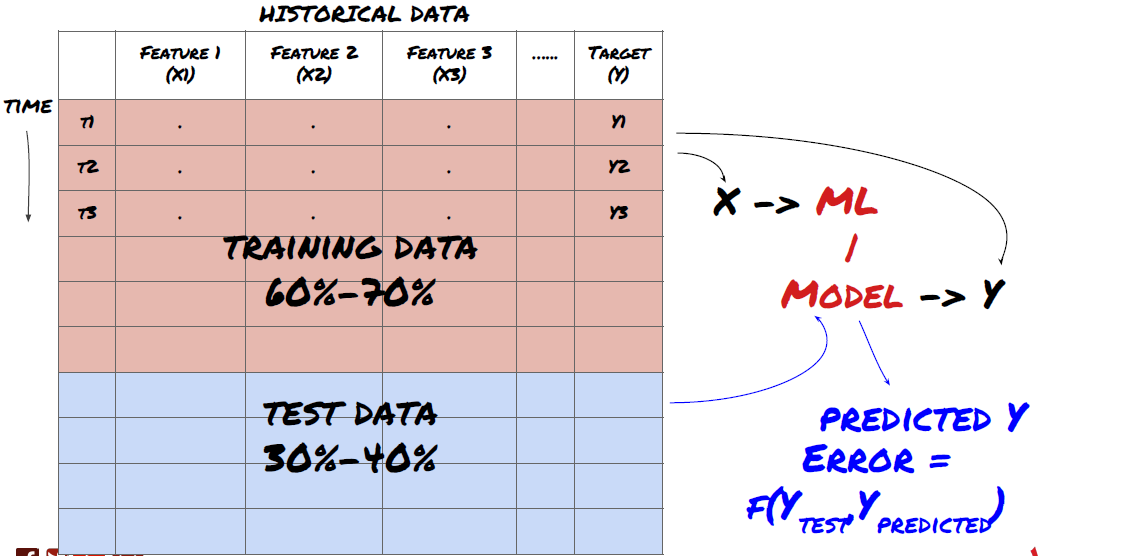
প্রশিক্ষণ এবং পরীক্ষার সেটে ডেটা বিভক্ত করুন
যেহেতু ট্রেনিং ডেটা মডেল প্যারামিটারগুলি মূল্যায়ন করতে ব্যবহৃত হয়, আপনার মডেল এই প্রশিক্ষণ ডেটার সাথে ওভারফিট হতে পারে এবং প্রশিক্ষণের ডেটা মডেলের কার্যকারিতাকে বিভ্রান্ত করতে পারে। আপনি যদি কোনও পৃথক পরীক্ষার ডেটা না রাখেন এবং প্রশিক্ষণের জন্য সমস্ত ডেটা ব্যবহার করেন তবে আপনি জানতে পারবেন না যে আপনার মডেলটি নতুন অদেখা ডেটাতে কতটা ভাল বা খারাপভাবে পারফর্ম করে। প্রশিক্ষিত এমএল মডেলগুলি রিয়েল-টাইম ডেটাতে ব্যর্থ হওয়ার এটি একটি প্রধান কারণ: লোকেরা উপলব্ধ সমস্ত ডেটার উপর প্রশিক্ষণ নেয় এবং প্রশিক্ষণ ডেটা মেট্রিক্স সম্পর্কে উত্তেজিত হয়, কিন্তু মডেলটি রিয়েল-টাইম ডেটাতে কোনও অর্থপূর্ণ ভবিষ্যদ্বাণী করতে পারে না যে এটি প্রশিক্ষিত ছিল না। অন
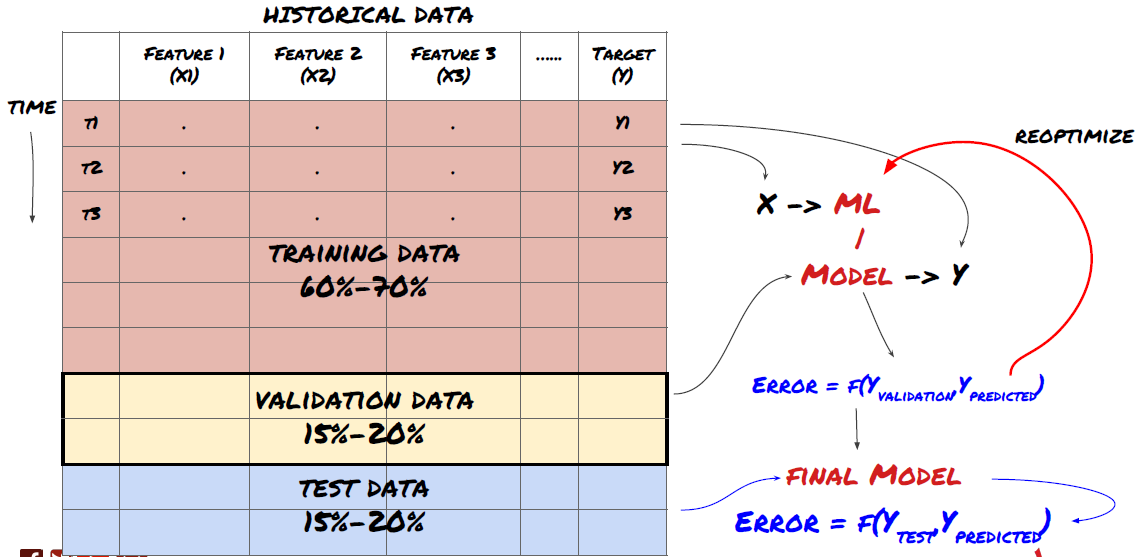
প্রশিক্ষণ সেট, বৈধতা সেট এবং পরীক্ষা সেটে ডেটা বিভক্ত করুন
এই পদ্ধতির সঙ্গে সমস্যা আছে. যদি আমরা বারবার প্রশিক্ষণের ডেটার উপর প্রশিক্ষণ নিই, পরীক্ষার ডেটাতে কর্মক্ষমতা মূল্যায়ন করি এবং কর্মক্ষমতা নিয়ে সন্তুষ্ট না হওয়া পর্যন্ত আমাদের মডেলটি অপ্টিমাইজ করি, আমরা প্রশিক্ষণের ডেটার অংশ হিসাবে পরীক্ষার ডেটা অন্তর্ভুক্ত করি। পরিশেষে, আমাদের মডেল প্রশিক্ষণ এবং পরীক্ষার ডেটার এই সেটে ভাল পারফর্ম করতে পারে, তবে এটি যে নতুন ডেটা ভালভাবে ভবিষ্যদ্বাণী করবে তার কোনও গ্যারান্টি নেই।
এই সমস্যা সমাধানের জন্য, আমরা একটি পৃথক বৈধতা ডেটাসেট তৈরি করতে পারি। এখন, আপনি ডেটার উপর প্রশিক্ষণ নিতে পারেন, বৈধতা ডেটাতে কর্মক্ষমতা মূল্যায়ন করতে পারেন, পারফরম্যান্সে সন্তুষ্ট না হওয়া পর্যন্ত অপ্টিমাইজ করতে পারেন এবং অবশেষে পরীক্ষার ডেটা পরীক্ষা করতে পারেন। এইভাবে, পরীক্ষার ডেটা দূষিত হয় না এবং আমরা আমাদের মডেল উন্নত করতে পরীক্ষার ডেটা থেকে কোনো তথ্য ব্যবহার করি না।
মনে রাখবেন, একবার আপনি পরীক্ষার ডেটাতে পারফরম্যান্স চেক করার পরে, ফিরে যান না এবং মডেলটিকে আরও অপ্টিমাইজ করার চেষ্টা করুন৷ আপনি যদি দেখেন যে আপনার মডেলটি ভাল ফলাফল দিচ্ছে না, তাহলে মডেলটিকে সম্পূর্ণ বাদ দিন এবং আবার শুরু করুন। প্রস্তাবিত বিভাজন হতে পারে 60% প্রশিক্ষণ ডেটা, 20% বৈধতা ডেটা এবং 20% পরীক্ষার ডেটা।
আমাদের সমস্যার জন্য, আমাদের কাছে তিনটি ডেটাসেট উপলব্ধ রয়েছে, আমরা একটিকে প্রশিক্ষণ সেট হিসাবে ব্যবহার করব, দ্বিতীয়টি বৈধতা সেট হিসাবে এবং তৃতীয়টি আমাদের পরীক্ষার সেট হিসাবে।
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
এর প্রতিটিতে, আমরা টার্গেট ভেরিয়েবল Y যোগ করি, যা পরবর্তী পাঁচটি ভিত্তি মানের গড় হিসাবে সংজ্ঞায়িত করা হয়
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
ধাপ 4: ফিচার ইঞ্জিনিয়ারিং
ডেটার আচরণ বিশ্লেষণ করুন এবং ভবিষ্যদ্বাণীমূলক ক্ষমতা সহ বৈশিষ্ট্য তৈরি করুন
এখন প্রকল্পের প্রকৃত নির্মাণ কাজ শুরু হচ্ছে। বৈশিষ্ট্য নির্বাচনের সুবর্ণ নিয়ম হল ভবিষ্যদ্বাণী করার ক্ষমতা মূলত বৈশিষ্ট্য থেকে আসে, মডেল থেকে নয়। আপনি দেখতে পাবেন যে মডেল পছন্দের তুলনায় বৈশিষ্ট্যের পছন্দ কর্মক্ষমতার উপর অনেক বেশি প্রভাব ফেলে। বৈশিষ্ট্য নির্বাচন সম্পর্কে কিছু নোট:
লক্ষ্য ভেরিয়েবলের সাথে সম্পর্ক অন্বেষণ না করে এলোমেলোভাবে বৈশিষ্ট্যগুলির একটি বড় সেট নির্বাচন করবেন না
টার্গেট ভেরিয়েবলের সাথে সামান্য বা কোন সম্পর্ক অতিরিক্ত ফিটিং হতে পারে
আপনার বেছে নেওয়া বৈশিষ্ট্যগুলি একে অপরের সাথে অত্যন্ত সম্পর্কযুক্ত হতে পারে, এই ক্ষেত্রে একটি ছোট সংখ্যক বৈশিষ্ট্য লক্ষ্য ব্যাখ্যা করতে পারে
আমি সাধারণত কয়েকটি বৈশিষ্ট্য তৈরি করি যা স্বজ্ঞাত অর্থে তৈরি করে, লক্ষ্য ভেরিয়েবলটি কীভাবে এই বৈশিষ্ট্যগুলির সাথে সম্পর্কযুক্ত তা দেখুন এবং কোনটি ব্যবহার করবেন তা নির্ধারণ করতে তাদের মধ্যে পারস্পরিক সম্পর্ক।
আপনি সর্বোচ্চ তথ্য সহগ (MIC), প্রিন্সিপাল কম্পোনেন্ট অ্যানালাইসিস (PCA) এবং অন্যান্য পদ্ধতির উপর ভিত্তি করে র্যাঙ্কিং প্রার্থী বৈশিষ্ট্যগুলিও চেষ্টা করতে পারেন
বৈশিষ্ট্য রূপান্তর/স্বাভাবিককরণ:
এমএল মডেলগুলি স্বাভাবিককরণের সাথে ভাল পারফর্ম করার প্রবণতা রাখে। যাইহোক, টাইম সিরিজ ডেটা নিয়ে কাজ করার সময় স্বাভাবিককরণ কঠিন কারণ ডেটার ভবিষ্যত পরিসর অজানা। আপনার ডেটা স্বাভাবিক সীমার বাইরে পড়তে পারে, যার ফলে মডেল ত্রুটি হতে পারে। কিন্তু আপনি এখনও কিছু স্থিরতা জোর করার চেষ্টা করতে পারেন:
স্কেলিং: বৈশিষ্ট্যগুলিকে স্ট্যান্ডার্ড বিচ্যুতি বা ইন্টারকোয়ার্টাইল রেঞ্জ দ্বারা ভাগ করুন
কেন্দ্র: বর্তমান মান থেকে ঐতিহাসিক গড় বিয়োগ করুন
স্বাভাবিককরণ: উপরে (x - গড়)/stdev-এর জন্য দুটি লুকব্যাক পিরিয়ড
প্রচলিত স্বাভাবিকীকরণ: লুকব্যাক পিরিয়ড (x-মিনিট)/(সর্বোচ্চ মিনিট) এর মধ্যে -1 থেকে +1 পরিসরে ডেটাকে স্বাভাবিক করুন এবং পুনরায় কেন্দ্রীভূত করুন
উল্লেখ্য যে, যেহেতু আমরা লুকব্যাক পিরিয়ডে ঐতিহাসিক ক্রমাগত গড়, মানক বিচ্যুতি, সর্বোচ্চ বা সর্বনিম্ন ব্যবহার করি, তাই বৈশিষ্ট্যগুলির স্বাভাবিক মানগুলি বিভিন্ন সময়ে বিভিন্ন প্রকৃত মানকে উপস্থাপন করবে। উদাহরণস্বরূপ, যদি একটি বৈশিষ্ট্যের বর্তমান মান 5 হয় এবং চলমান 30-পিরিয়ড গড় 4.5 হয়, তাহলে কেন্দ্র করার পরে এটি 0.5-এ রূপান্তরিত হবে। এরপরে, যদি একটানা 30 পিরিয়ডের জন্য গড় 3 হয়ে যায়, তাহলে মান 3.5 হবে 0.5। এটি মডেলের ত্রুটির কারণ হতে পারে তাই, স্বাভাবিকীকরণ কঠিন এবং আপনাকে বুঝতে হবে যে মডেলটির কার্যকারিতা কি আসলে উন্নত করে (যদি কিছু থাকে)।
আমাদের সমস্যার প্রথম পুনরাবৃত্তির জন্য, আমরা ব্লেন্ডিং প্যারামিটার ব্যবহার করে প্রচুর সংখ্যক বৈশিষ্ট্য তৈরি করেছি। পরে আমরা ফিচারের সংখ্যা কমাতে পারি কিনা তা দেখার চেষ্টা করব
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
ধাপ 5: মডেল নির্বাচন
নির্বাচিত সমস্যার উপর ভিত্তি করে উপযুক্ত পরিসংখ্যান/এমএল মডেল নির্বাচন করুন
মডেলের পছন্দ কীভাবে সমস্যাটি তৈরি করা হয়েছে তার উপর নির্ভর করে। আপনি কি একটি তত্ত্বাবধানে (ফিচার ম্যাট্রিক্সের প্রতিটি পয়েন্ট X একটি টার্গেট ভেরিয়েবল Y-তে ম্যাপ করে) বা একটি অতত্ত্বাবধানহীন শিক্ষার সমস্যা (কোনও ম্যাপিং দেওয়া নেই, মডেলটি অজানা নিদর্শনগুলি শেখার চেষ্টা করে) সমাধান করছেন? আপনি কি একটি রিগ্রেশন (ভবিষ্যত সময়ে প্রকৃত মূল্য ভবিষ্যদ্বাণী) বা একটি শ্রেণীবিভাগ সমস্যা সমাধান করছেন (ভবিষ্যত সময়ে শুধুমাত্র মূল্যের দিকনির্দেশ (বৃদ্ধি/হ্রাস) ভবিষ্যদ্বাণী করুন)।

তত্ত্বাবধানে বা তত্ত্বাবধানহীন শিক্ষা

রিগ্রেশন বা শ্রেণীবিভাগ
কিছু সাধারণ তত্ত্বাবধানে শেখার অ্যালগরিদম আপনাকে শুরু করতে পারে:
লিনিয়ার রিগ্রেশন (প্যারামিটার, রিগ্রেশন)
লজিস্টিক রিগ্রেশন (পরামিতি, শ্রেণীবিভাগ)
K নিকটতম প্রতিবেশী (KNN) অ্যালগরিদম (উদাহরণ-ভিত্তিক, রিগ্রেশন)
SVM, SVR (প্যারামেট্রিক, শ্রেণীবিভাগ এবং রিগ্রেশন)
সিদ্ধান্ত গাছ
ডিসিশন ফরেস্ট
আমি একটি সাধারণ মডেল দিয়ে শুরু করার পরামর্শ দিই, যেমন লিনিয়ার বা লজিস্টিক রিগ্রেশন এবং সেখান থেকে প্রয়োজন অনুসারে আরও জটিল মডেল তৈরি করুন৷ এটিও সুপারিশ করা হয় যে আপনি মডেলটির পিছনের গণিতটি অন্ধভাবে একটি কালো বাক্স হিসাবে ব্যবহার না করে পড়েন৷
ধাপ ষষ্ঠ: প্রশিক্ষণ, বৈধতা এবং অপ্টিমাইজেশান (ধাপ 4-6 পুনরাবৃত্তি করুন)
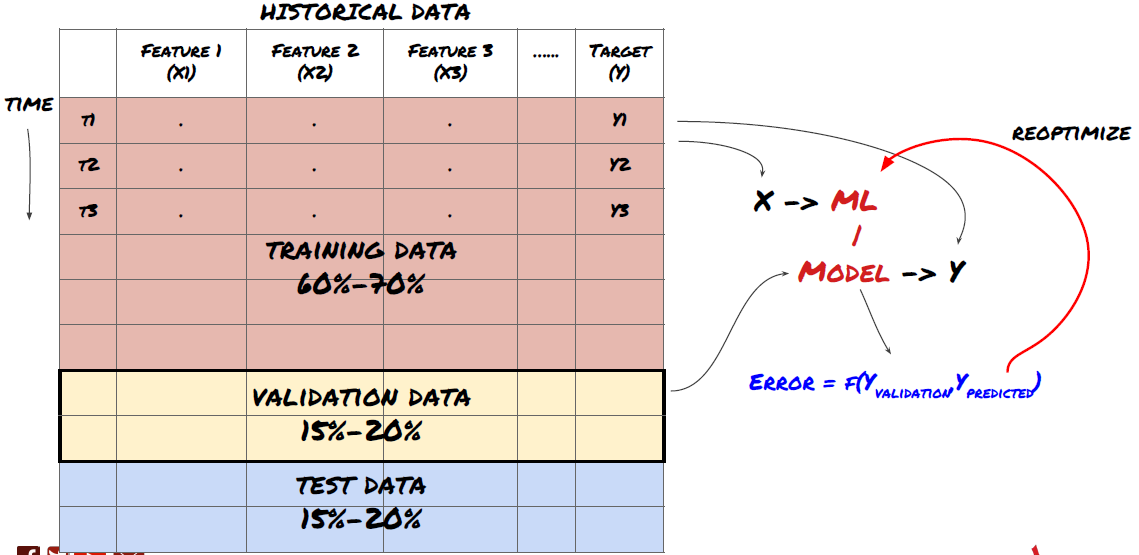
প্রশিক্ষণ এবং বৈধতা ডেটাসেট ব্যবহার করে আপনার মডেলকে প্রশিক্ষণ দিন এবং অপ্টিমাইজ করুন
এখন, আপনি অবশেষে মডেল তৈরি করতে প্রস্তুত. এই পর্যায়ে, আপনি সত্যিই মডেল এবং মডেল পরামিতিগুলির উপর পুনরাবৃত্তি করছেন। প্রশিক্ষণ ডেটাতে আপনার মডেলকে প্রশিক্ষণ দিন, বৈধতা ডেটাতে এর কার্যকারিতা পরিমাপ করুন এবং তারপরে ফিরে যান, অপ্টিমাইজ করুন, পুনরায় প্রশিক্ষণ দিন এবং মূল্যায়ন করুন। আপনি যদি একটি মডেলের পারফরম্যান্সে সন্তুষ্ট না হন তবে একটি ভিন্ন মডেল চেষ্টা করুন। আপনি এই পর্যায়ে একাধিকবার সাইকেল চালান যতক্ষণ না আপনি শেষ পর্যন্ত এমন একটি মডেল পাবেন যার সাথে আপনি খুশি হন।
শুধুমাত্র একবার আপনার পছন্দের একটি মডেল আছে তারপর পরবর্তী ধাপে এগিয়ে যান।
আমাদের প্রদর্শনের সমস্যার জন্য, আসুন একটি সাধারণ লিনিয়ার রিগ্রেশন দিয়ে শুরু করি
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
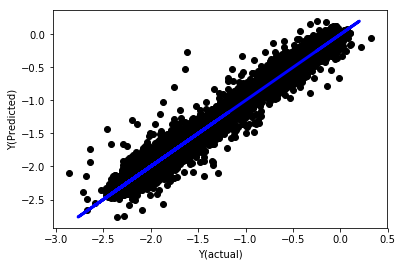
স্বাভাবিককরণ ছাড়াই রৈখিক রিগ্রেশন
”` (‘Coefficients: \n’, array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07