Reguläre Ausdrücke systematisch lernen (I): Die Grundlagen
 2
2780
2
2780
Reguläre Ausdrücke systematisch lernen (I): Die Grundlagen
Was ist ein regulärer Ausdruck? Regelmäßige Ausdrücke sind bestimmte Zeichen, die im Voraus definiert sind, und Kombinationen dieser bestimmten Zeichen, die eine Reihe von Regeln für die Ausdrucksweise einer Filterlogik für Strings bilden.
- Regelmäßige Ausdrücke dienen folgenden Zwecken:
给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
可以通过正则表达式,从字符串中获取我们想要的特定部分。
Um das Lernen zu erleichtern, empfehle ich Regextor, eine Software zur Überprüfung von regulären Ausdrücken, die ich in meinem Artikel beschrieben habe, in dem ich einige gute Software für Mac empfehle.
Die Regeln für die Regularisierung von Ausdrücken beginnen hier:
- #### Passend zu normalen Textcharakteren
Reguläre Ausdrücke können nur gewöhnlichen Text enthalten, der genau diesem Text entspricht. Zum Beispiel:
Die korrekte Formulierung lautet:song
Der Titel des Films wurde von der japanischen Film- und TV-Schauspielerin Xiao Songge veröffentlicht.
Ergebnisse nach dem Treffen: xiaosongge,xiaoSongge
Regular expressions sind standardmäßig groß- und kleingeschrieben, so dass song nicht mit “Song” übereinstimmt. Die meisten Regular Expressionen bieten jedoch eine Option, die kleine und große Buchstaben nicht zu unterscheiden.
- #### Wunschchchcharaktere passen
. wird verwendet, um ein beliebiges Zeichen zu kombinieren, z. B.:
Formel: c.t
Der Titel des Videos lautet: Cat cet caaat dog
Das Ergebnis:cat cet caaat dog
Analyse: c.t passt zu einem String, der mit “c” beginnt und mit “t” endet, mit einem beliebigen Zeichen in der Mitte.
Gleichermaßen kann mit mehreren aufeinanderfolgenden, beliebigen Zeichen verglichen werden:
Regelmäßige Ausdrücke: c..t
Der Text lautet: cat cet cat dog
Das Ergebnis: cat cet caat dog
- #### Besondere Zeichen passen
. enthält eine spezielle Bedeutung in einem regulären Ausdruck und ist ein spezielles Zeichen. .\ ist auch ein spezielles Zeichen und kann als Übersetzung für spezielle Zeichen fungieren. Wenn Sie ein echtes “ . ” -Zeichen anpassen möchten, müssen Sie vor . hinzufügen und \ für die Übersetzung des Zeichens verwenden..Das Zeichen “ . ” steht für das wahre .
Regelmäßiger Ausdruck: c.t
Der Titel des Videos lautet: Cat c.t dog
Ergebnisse nach dem Treffen: catc.t dog
Hinweis: Da \ auch ein Sonderzeichen ist, müssen zwei Rückschrägstriche verwendet werden, um ein echtes \ zu erhalten.\:
Regelmäßiger Ausdruck: c\t
Der Text lautet: cat c\t dog
Ergebnisse nach dem Treffen: catc\t dog
- #### Charakter-Sammlung verwendet
Ich kann ein beliebiges Zeichen anpassen, aber was ist, wenn ich mehrere bestimmte Zeichen anpassen möchte?[und [Metacharakter。]
Regelmäßiger Ausdruck: c[ab]t
Der Titel der Serie lautet: Cat cbt cet
Das Ergebnis:cat cbt cet
Analyse:[ab] passt zu “a” oder “b”.[ab]t passt zu “cat” und “cbt”, aber nicht zu “cet”.
- #### Benutzung von Zeichengruppen
In dem Beispiel oben, wenn ich Cet anpassen möchte, dann gibt es[Wenn ich eine beliebige kleine Schrift anpassen möchte, dann kann ich Dutzende von Buchstaben darin schreiben. Das ist gut, aber es ist zu lang.[a-z]:
Regelmäßiger Ausdruck: c[a-z]t
Der Text wird mit cat cbt czt c2t verglichen.
Das Ergebnis:cat cbt czt c2t
Analyse: c[a-z]t bedeutet einen beliebigen Buchstaben der Buchstaben “a” - “z”, der mit “c” beginnt und mit “t” endet.
Es gibt auch ähnliche Abstände:
[0-9] und[0123456789] hat die gleiche Funktion. Passt alle Zahlen zusammen. [A-F] passt zu den Großbuchstaben A bis F. [A-Z] passt zu allen Großbuchstaben von A bis Z. [a-z] passt zu allen kleinen Buchstaben von a bis z. [A-z] passt alle Zeichen von ASCII A bis ASCII z, nicht nur alle Buchstaben, sondern auch alle Buchstaben von A bis z in einer ASCII-Tabelle, wie[Und so weiter. [A-Za-z0-9] Passt zu allen kleinen Buchstaben und Zahlen.
- #### Nicht-Charakter-Set-Übereinstimmung
Eine Zeichenmenge wird in der Regel verwendet, um eine Gruppe von Zeichen zu bestimmen, die übereinstimmen müssen. Manchmal möchten Sie jedoch eine Gruppe von Zeichen ausschließen, die Sie nicht übereinstimmen möchten. Dies kann durch die Negation der Zeichenmenge erreicht werden.
Regelmäßiger Ausdruck: c[^a-z]t
Der Text muss noch abgeglichen werden: cat cbt czt c2t cAt
Nach dem Treffen: cat cbt czt c2t cAt
Analyse: Das ist das Gegenteil des vorherigen Beispiels.[a-z] passt zu allen kleinen Buchstaben, während [^a-z] passt zu allen nicht kleingeschriebenen Buchstaben.
Beobachten Sie, dass der ^-Zeichen alle Zeichen in der Zeichenmenge annulliert.
- #### Primärzeichen
Die Meta-Zeichen haben eine besondere Bedeutung in regulären Ausdrücken, wie wir bereits einige Meta-Zeichen erwähnt haben.[Die Zeichen können ihre Bedeutung nicht direkt ausdrücken, z. B. nicht direkt verwendet werden.[Ich bin ein guter Spieler”.[“Das ist eine sehr schwierige Aufgabe.
Alle Meta-Zeichen können mit einer Rückschreibung vorangestellt werden, so dass sie sich selbst anpassen, anstatt ihrer besonderen Bedeutung.[Ich werde dich treffen”.[ “:
Regelmäßige Ausdrücke: a[b
Der Text ist noch zu vergleichen: a[b ab a[[b
Das Ergebnis:a[b ab a[[b
Hinweis: \ wird als Metallzeichen verwendet, was bedeutet, dass \ auch ein Metallzeichen ist. Es kann also verwendet werden, wenn es notwendig ist, das wahre “\” zu vergleichen.\:
Regelmäßige Ausdrücke: a\b
Der Text ist noch zu vergleichen: a\b a\b a[[b
Ergebnis nach dem Treffen: a\b a\b a[[b
- #### Leerzeichen
Manchmal müssen Sie die Leerzeichen, die im Text nicht gedruckt werden können, aufeinander abstimmen. Zum Beispiel möchten Sie alle Tab-Zeichen oder alle Umschreibzeichen finden. Sie können die speziellen Meta-Zeichen in der folgenden Tabelle verwenden:
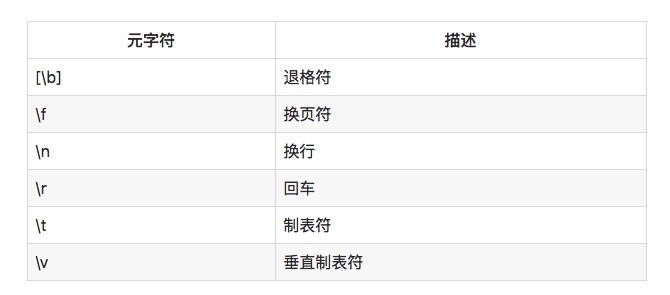
Zum Beispiel wird \r\n mit einer Rückfahrt-Wechselkombination übereinstimmen, die in Windows eine Datei-Wechsel darstellt. In Linux und Unix-Systemen wird nur \n verwendet.
- #### Zu einem bestimmten Charaktertyp passen
Es gibt einige spezielle Metacharaktere, die verwendet werden können, um die üblichen Charakter-Sätze zu vergleichen. Diese Metacharaktere werden als Match-Character-Klassen bezeichnet. Sie werden es sehr bequem finden, sie zu verwenden.
Zahlen oder Nicht-Zahlen Das ist eine sehr schwierige Aufgabe.[0-9] kann mit allen Zahlen übereinstimmen. Wenn Sie keine Zahlen übereinstimmen wollen, können Sie[In der folgenden Tabelle finden Sie eine Liste der numerischen und nicht-numerischen Klassentitel:

Regelle Ausdrücke: c\dt
Der Text wird mit cat c2t czt c9t verglichen.
Ergebnisse nach dem Treffen: catc2t czt c9t
Regelle Ausdrücke: c\Dt
Der Text wird mit cat c2t czt c9t verglichen.
Das Ergebnis:cat c2t czt c9t
Alphabetische und Nicht-Alphabetische Zeichen
Ein weiteres häufig verwendete Metakarakter ist \w und \W:
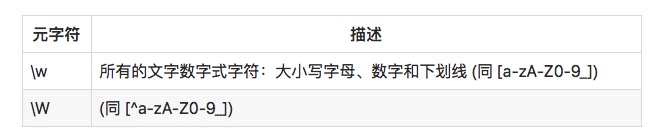
Regelmäßige Ausdrücke: c\wt
Der Text muss noch abgeglichen werden: cat c2t czt c-t c\t
Das Ergebnis:cat c2t c-t c\t
Regelle Ausdrücke: c\Wt
Der Text, der noch zu vergleichen ist, ist: cat c2t c-t c\t
Ergebnis nach dem Treffen: cat c2tc-t c\t
Abgleich von Leerzeichen und Nichtleerzeichen
Die letzte Matching-Klasse, die wir finden werden, ist die leere:

Regelle Ausdrücke: c\st
Der Text muss noch abgeglichen werden: cat c t c2t c\t
Ergebnisse nach dem Treffen: catc t c2t c\t
Regelle Ausdrücke: c\St
Der Text muss noch abgeglichen werden: cat c t c2t c\t
Das Ergebnis:cat c t c2t c\t
- #### Eine oder mehrere Zeichen passen
Der +-Zeichenzeichen steht für die Übereinstimmung eines oder mehrerer Zeichen. Zum Beispiel wird a mit “a” übereinstimmen, während a+ mit einem oder mehreren “a” übereinstimmt.
Formel: cat
Der Text wurde von der BBC veröffentlicht und wurde von der BBC veröffentlicht.
Ergebnisse nach dem Treffen: ctcat caat caaat
Regelmäßige Ausdrucksweise: ca+t
Der Text wurde von der BBC veröffentlicht und wurde von der BBC veröffentlicht.
Ergebnisse nach dem Treffen: ctcat caat caaat
Wenn man + in einem Zeichenkatalog verwendet, muss das +-Zeichen außerhalb des Zeichenkatalogs stehen:
Regelmäßiger Ausdruck: c[0-9]+t
Es gibt keine Überschrift.
Ergebnisse nach dem Treffen: ctc0t cat c123t
Analyse: c[0-9]+t bedeutet eine Zeichenfolge, die mit “c” beginnt, mit “t” endet und in der Mitte eine oder mehrere Ziffern hat.
Natürlich.[0-9+] ist auch eine rechtmäßige Regellexpression, aber sie stellt eine Zeichenmenge dar, die die Zeichen “0” - “9” und “+” enthält.
Im Allgemeinen werden Metacharaktere wie . und + als wörtliche Bedeutungen verwendet, wenn sie für Zeichengruppen verwendet werden, so dass keine Übersetzung notwendig ist.[0-9+] und[0-9+Die Funktion ist dieselbe.
Hinweis: + ist ein Metakarakter, der mit “+” übereinstimmt.+。
- #### 0 oder mehr Zeichen
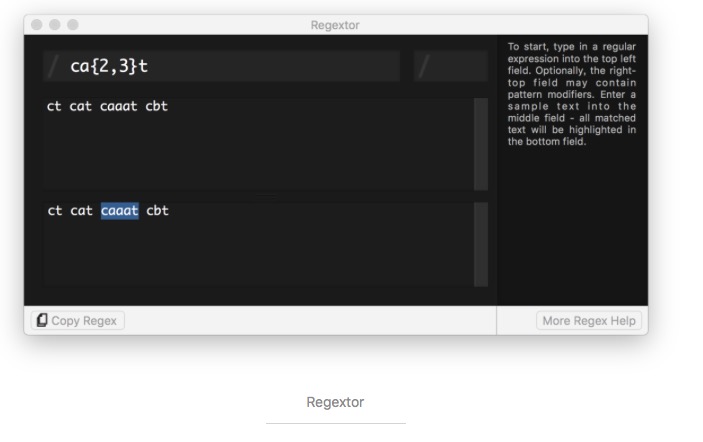
Wenn Sie mit 0 oder mehr Zeichen übereinstimmen möchten, können Sie das hier verwenden.*Elemente und Zeichen
Formel: ca*t
Der Titel des Films ist:
Das Ergebnis:ct cat caat cbt
Beachten:Die Symbole sind Metacharaktere. Um mit “” übereinstimmen zu können, ist eine Übersetzung erforderlich.*。
- #### 0 oder 1 Zeichen.
? passt zu Nullen oder zu einem Zeichen. Daher ist ? sehr gut geeignet, um zu einem beliebigen Zeichen im Text zu passen.
Formaler Ausdruck: ca?t
Der Titel des Films ist:
Das Ergebnis:ct cat caat cbt
Hinweis: ? ist ein Metallzeichen. Um mit “?” zu übereinstimmen, muss eine Übersetzung vorgenommen werden.?。
- #### Benutzung der Anzahl der Matches
Reguläre Ausdrücke erlauben es, die Anzahl der Übereinstimmungen anzugeben. Die Anzahl der Übereinstimmungen kann zwischen { } und { Hinweis: { und } sind auch Stammzeichen, die bei der Verwendung der wörtlichen Bedeutung übersetzt werden müssen.
Genaue Übereinstimmung Um zu bestimmen, wie oft es angezeigt werden soll, können Sie eine Zahl zwischen { und } eingeben. Zum Beispiel wird { 3 } mit dem Zeichen oder der Gruppe übereinstimmen, die 3 Mal zuvor erscheint:
Formel: ca{3}t
Der Text wurde von der US-Studie “C.T. Cat” veröffentlicht.
Ergebnisse nach dem Treffen: ct catcaaat cbt
Mindeste Anzahl der Treffer
Wir können auch nur die Mindestwerte angeben, die übereinstimmen. Zum Beispiel {2,} bedeutet, dass 2 oder mehr Mal übereinstimmen:
Regelmäßige Ausdrücke: ca{1,}t
Der Text wurde von der US-Studie “C.T. Cat” veröffentlicht.
Ergebnisse nach dem Treffen: ctcat caaat cbt
Dimensionsabgleich
Wir können auch die Mindest- und Maximalwerte verwenden, um die Anzahl der Matches zu bestimmen. Zum Beispiel bedeutet {2,3} mindestens 2 und höchstens 3 Matches.
Regelmäßige Ausdrucksweise: ca{2,3}t
Der Text wurde von der US-Studie “C.T. Cat” veröffentlicht.
Ergebnisse nach dem Treffen: ct catcaaat cbt
Also? Und die Funktion von {0,1} ist die gleiche wie die Funktion von {1,}.
- #### Nicht gierige Übereinstimmung
Hier sind einige Beispiele:
Regelmäßiger Ausdruck: s.*g Der Titel des Films ist “Aus dem Schatten der Nacht” und der Titel ist “Aus dem Schatten der Nacht”. Nach dem Spiel: xiao song xiao song Analyse von s.*g passt nicht wie erwartet zwei “Songs” an, sondern alle Texte zwischen dem ersten “s” und dem letzten “g”.
Das liegt daran,*Und + sind gierige Übereinstimmungen. Das heißt, dass regelmäßige Ausdrücke immer nach der größten Übereinstimmung suchen, nicht nach der geringsten, was absichtlich ist.
Aber wenn du keine gierigen Übereinstimmungen möchtest, dann benutze die nicht-gierigen Übereinstimmungen dieser Quantifikatoren. Die nicht-gierigen Quantifikatoren werden hinter dem Quantifikator hinzugefügt:

*Ja?Das ist eine nicht-gierige Version, also kann man sie verwenden.? um das oben genannte Beispiel zu ändern:
Regelmäßiger Ausdruck: s.?g
Der Titel des Films ist “Aus dem Schatten der Nacht” und der Titel ist “Aus dem Schatten der Nacht”.
Die Ergebnisse des Matches: xiaosong xiao song
Analyse: Sie können s sehen.?g hat zwei “Songs” gefunden.
- #### Definieren Sie die Stringgrenze
Die Meta-Zeichen, die die Grenze einer String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-String-
^ Wie folgt:
Formel: ^xiao
Der Text wurde von Xiaoosong veröffentlicht.
Das Ergebnis:xiaosong
Der Titel des Films ist “Axiaosong”. Das Ergebnis: axiaosong Analyse: ^xiao passt zu Zeichenfolgen, die mit “xiao” beginnen.
$ wird wie folgt verwendet:
Die offizielle Ausdrucksform ist song$.
Der Text wurde von Xiaoosong veröffentlicht.
Ergebnisse nach dem Treffen: xiaosong
Der Text wird von Xiaosonga geschrieben. Das Ergebnis: Xiaosonga Analyse: song$ passt zu den Zeichenfolgen, die mit “song” enden.
Gemeinsam:
Regelmäßige Formel: ^[0-9a-zA-Z]{4,}$
Der Text ist noch zu vergleichen: a1b234ABC
Das Ergebnis:a1b234ABC
- a1b23 = 4ABC Das Ergebnis nach dem Treffen: + a1b23 = 4ABC Analyse:[0-9a-zA-Z]{4,}$ ist eine Zeichenfolge, die aus Ziffern oder Buchstaben besteht und die Ziffern größer sind als die vier Ziffern.
Hinweis: ^ wenn es am Anfang der Menge ist, bedeutet es Negativ; wenn es außerhalb der Menge ist, wird die Anfangsposition der Zeichenfolge angezeigt.[^0-9] und ^[Unterschied zwischen 0-9]
- #### Verwenden Sie mehrere Zeilen
Aber ((?m) kann in mehrere Zeilen eingesetzt werden. In mehreren Zeilen wird die Regellexpressions-Engine den Wechselzeichen als Trennzeichen für die Zeichenkette verwenden. ^ entspricht dem Beginn des Textes oder dem Beginn einer Zeile, während $ dem Ende des Textes oder dem Ende einer Zeile entspricht.
Das ist eine Änderung des vorherigen Beispiels:
Regelmäßige Ausdrücke:[0-9a-zA-Z]{4,}$
Der Text ist noch zu vergleichen: a1b234ABC +a1b23=4ABC ABC123456
Das Ergebnis:a1b234ABC
+a1b23=4ABC
ABC123456
Analyse:[0-9a-zA-Z]{4,}$ wird zu einer Zeichenfolge mit Zahlen oder Buchstaben gematcht, die größer ist als die vierstellige Zahl.
Anmerkung: Wenn mehrere Zeilen verwendet werden, muss ((?m) am Anfang eines Regular-Ausdrucks stehen. (?m) wird in den meisten Regular-Expression-Implementierungen nicht unterstützt. Einige Regular-Expression-Implementierungen unterstützen auch den Beginn von \A-Matching-Strings und das Ende von \Z-Matching-Strings. Wenn sie unterstützt werden, sind diese Metacharaktere die gleichen Funktionen wie ^, $.
Der erste Artikel behandelt die Grundlagen, der nächste soll die systematische Erlernung der regulären Ausdrücke ((ii) beschreiben: Progressive Artikel ().
Übertragung aus dem Kurzbuch iOS_小松哥