Drei Bilder zum Verständnis des maschinellen Lernens: Grundkonzepte, fünf große Schulen und neun gängige Algorithmen
 0
2382
0
2382
Drei Bilder zum Verständnis des maschinellen Lernens: Grundkonzepte, fünf große Schulen und neun gängige Algorithmen
- #### 1. Übersicht über maschinelles Lernen

Was ist maschinelles Lernen?
Maschinen lernen, indem sie große Datenmengen analysieren. Zum Beispiel müssen sie nicht programmiert werden, um Katzen oder Gesichter zu erkennen. Sie können trainiert werden, indem sie Bilder verwenden, um bestimmte Ziele zu summieren und zu erkennen.
Die Beziehung zwischen maschinellem Lernen und künstlicher Intelligenz
Maschinelles Lernen ist eine Kategorie von Forschungen und Algorithmen, die darauf ausgerichtet sind, nach Mustern in Daten zu suchen und diese zu nutzen, um Vorhersagen zu treffen. Maschinelles Lernen ist ein Teil des Bereichs der künstlichen Intelligenz und vernetzt sich mit der Erkenntnisfindung und dem Data Mining.
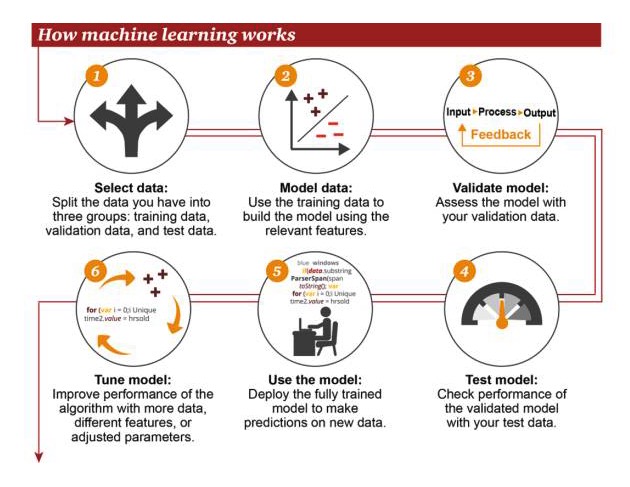
Wie funktioniert maschinelles Lernen
1 Daten auswählen: Teilen Sie Ihre Daten in drei Gruppen ein: Trainingsdaten, Verifizierungsdaten und Testdaten 2 Modelldaten: Gebrauch von Trainingsdaten zum Erstellen von Modellen mit relevanten Merkmalen 3 Validation Modell: Verwenden Sie Ihre Validationsdaten, um Ihr Modell zu erreichen 4 Testmodelle: Verwenden Sie Ihre Testdaten, um die Performance von verifizierten Modellen zu überprüfen
- Modellverwendung: Vorhersagen mit vollständig ausgebildeten Modellen über neue Daten 6 Modell der Optimierung: Die Algorithmen werden mit mehr Daten, unterschiedlichen Merkmalen oder angepassten Parametern verbessert
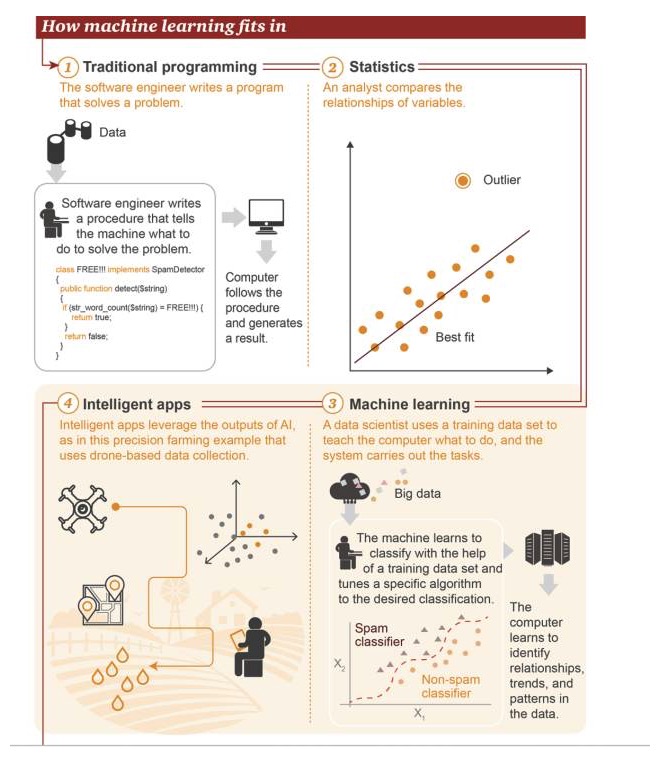
Die Position von Maschinelles Lernen
- Traditionelle Programmierung: Software-Ingenieure schreiben Programme, um Probleme zu lösen. Zuerst gibt es einige Daten→ Um ein Problem zu lösen, schreiben Software-Ingenieure einen Prozess, um der Maschine zu sagen, was sie tun soll→ Der Computer folgt diesem Prozess und liefert dann ein Ergebnis 2 Statistik: Analysten vergleichen die Beziehungen zwischen Variablen 3 Maschinelles Lernen: Die Datenwissenschaftler nutzen den Trainingsdatensatz, um dem Computer beizubringen, was er tun soll, und das System führt diese Aufgabe aus. Zuerst gibt es Big Data→ Die Maschine lernt, den Trainingsdatensatz zu verwenden, um zu klassifizieren und bestimmte Algorithmen zu modulieren, um die Zielklassifizierung zu erreichen→ Der Computer lernt, Beziehungen, Trends und Muster in den Daten zu erkennen 4 Intelligente Anwendungen: Intelligente Anwendungen Die Ergebnisse der Anwendung von KI, dargestellt in einer Anwendungsbeispiel für Präzisionslandwirtschaft, basieren auf Daten, die von Drohnen gesammelt werden

Praktische Anwendungen von Machine Learning
Hier sind einige Beispiele, wie Sie Machine Learning anwenden können.
Schnelle dreidimensionale Kartierung und Modellierung: Um eine Eisenbahnbrücke zu bauen, wenden die Datenwissenschaftler und Fachexperten von PwC maschinelles Lernen auf die von den Drohnen gesammelten Daten an. Diese Kombination ermöglicht eine präzise Überwachung und schnelle Rückmeldung zum Erfolg der Arbeit.
Erweiterte Analyse zur Verringerung des Risikos: Um interne Transaktionen zu erkennen, kombiniert PwC maschinelles Lernen mit anderen Analysetechnologien, um ein umfassenderes Benutzerprofil zu entwickeln und ein tieferes Verständnis für komplexe, verdächtige Verhaltensweisen zu erhalten.
Best-Performing-Ziel: PwC nutzt maschinelles Lernen und andere Analysemethoden, um das Potenzial verschiedener Pferde auf dem Melbourne Cup-Rennplatz zu bewerten.
- #### 2. Die Entwicklung von Machine Learning

Die verschiedenen “Stämme” der KI-Forscher haben sich über Jahrzehnte hinweg um die Vorherrschaft gegeneinander gestritten. Ist es jetzt an der Zeit, dass sich diese Stämme vereinigen?
Die fünf größten
1 Symbolismus: Die Verwendung von Symbolen, Regeln und Logik, um Wissen zu symbolisieren und logische Argumentation durchzuführen. Die beliebtesten Algorithmen sind: Regeln und Entscheidungsbäume 2 Bayesian: Die Wahrscheinlichkeit, dass ein Ereignis eintritt, um daraus Wahrscheinlichkeiten zu schließen, bevorzugte Algorithmen: naive Bayes oder Markov 3 Linkage: Dynamische Identifizierung und Induktion von Modellen mit Probabilitätsmatrizen und Gewichtsneuronen, bevorzugte Algorithmen: Neural Networks 4 Evolutionismus: Veränderungen erzeugen und dann die besten für bestimmte Zwecke gewinnen, bevorzugte Algorithmen sind: genetische Algorithmen 5 Analogizer: Optimierung der Funktion unter Einschränkungen ((Gehen Sie so hoch wie möglich, aber verlassen Sie nicht die Straße)) Die beliebteste Algorithmus: Unterstützung der Vektormaschine
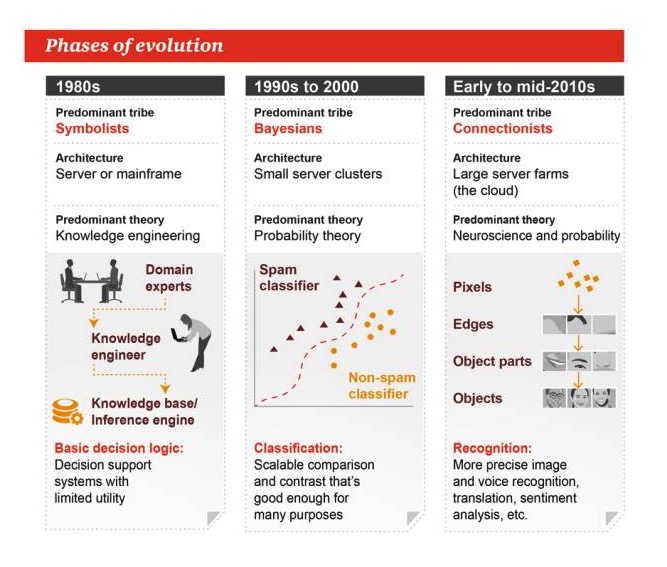
Entwicklungsstadien
1980er Jahre
Haupttypen: Symbolismus Architektur: Server oder Großmaschine Vorherrschende Theorie: Wissenstechnik Grundlegende Entscheidungslogik: Entscheidungsunterstützungssysteme mit begrenzter Praxis
1990 bis 2000
Hauptgenre: Bayes Architektur: kleine Servercluster Die vorherrschende Theorie: Wahrscheinlichkeitstheorie Klassifizierung: erweiterbarer Vergleich oder Vergleich, gut genug für viele Aufgaben
Anfang bis Mitte der 2010er Jahre
Hauptgenre: Bündnismus Architektur: eine große Serverfarm Die vorherrschenden Theorien: Neurowissenschaften und Wahrscheinlichkeit Identifizierung: Genauere Bild- und Tonerkennung, Übersetzung, Emotionalanalyse und mehr
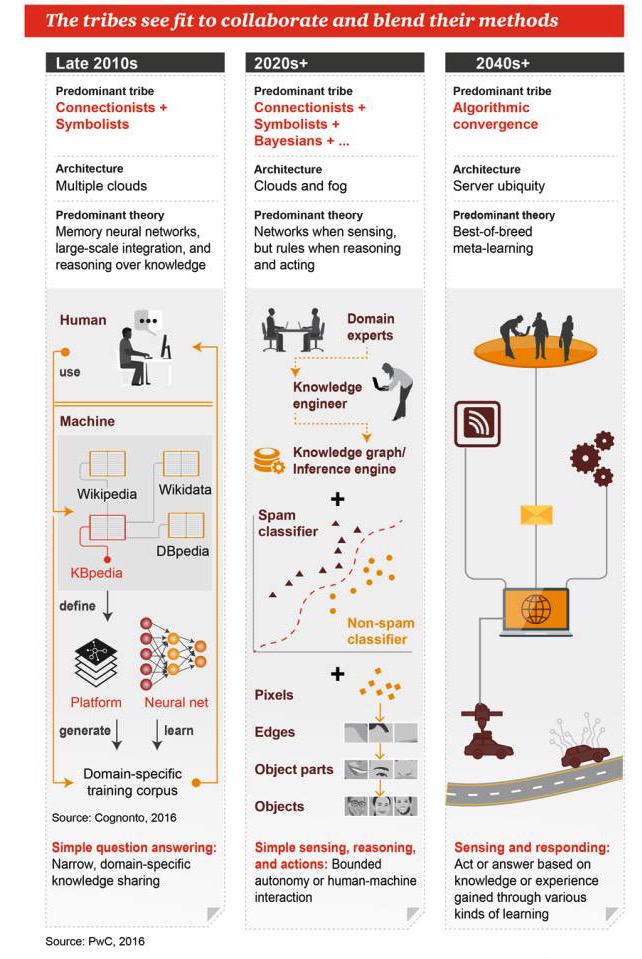
Diese Gruppen hoffen, zusammenzuarbeiten und ihre Methoden zu verschmelzen.
Ende der 2010er Jahre
Hauptgenre: Bündnismus + Symbolismus Architektur: viele Wolken Haupttheorien: Gedächtnis-Neuralnetzwerke, Massenintegration und wissensbasierte Argumentation Einfache Fragestellungen und Antworten: Wissensverteilung in einem begrenzten, spezifischen Bereich
2020er Jahre+
Die wichtigsten Genres sind: Bündnismus + Symbolismus + Bayesianismus + … Architektur: Cloud und Nebel Die vorherrschende Theorie: Netzwerke für Wahrnehmung, Regeln für Logik und Arbeit Einfache Wahrnehmung, Argumentation und Handlung: begrenzte Automatisierung oder Mensch-Maschine-Interaktion
2040er Jahre+
Haupttypen: Algorithmus-Fusion Architektur: Allgegenwärtige Server Die vorherrschende Theorie: Meta-Lernen in der optimalen Kombination Wahrnehmung und Reaktion: Handeln oder Antworten geben, basierend auf Wissen oder Erfahrungen, die durch verschiedene Lernmethoden gewonnen wurden
- #### 3. Algorithmen für maschinelles Lernen

Welche Algorithmen sollten Sie verwenden? Das hängt stark von der Art und Menge der verfügbaren Daten und Ihren Trainingszielen in jedem bestimmten Anwendungsfall ab. Verwenden Sie nicht die komplexesten Algorithmen, es sei denn, die Ergebnisse sind die Kosten und Ressourcen wert. Hier sind einige der am häufigsten verwendeten Algorithmen, sortiert nach der einfachen Verwendung.
Entscheidungsbaum: Eine typische Entscheidungsbaumanalyse verwendet bei der Schritt-für-Schritt-Antwortung Schichtungsvariablen oder Entscheidungs-Noten, z. B. um einen bestimmten Benutzer in Kredit- oder Nicht-Kredit zu klassifizieren.
Stärken: Fähigkeit, eine Reihe von Merkmalen, Eigenschaften und Eigenschaften von Personen, Orten und Dingen zu beurteilen Szenarienbeispiele: Regelbasierte Kredit-Bewertungen, Prognosen über die Ergebnisse von Pferden
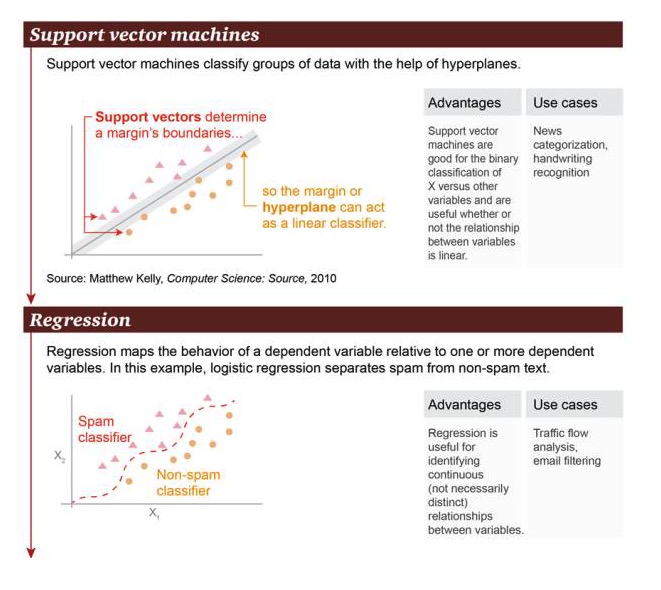
Support Vector Machine: basierend auf der Hyperplane kann die Support Vector Machine die Datensätze klassifizieren.
Vorteile: Unterstützung von Vektormaschinen, die in der Lage sind, binäre Klassifikationen zwischen Variablen X und anderen Variablen durchzuführen, unabhängig davon, ob die Beziehung linear ist oder nicht Es gibt viele Beispiele für diese Art von Szenarien: Nachrichtenklassifizierung, Handschrifterkennung.
Regression: Regression kann die Zustandsbeziehung zwischen einer Faktorvariablen und einer oder mehreren Faktorvariablen darstellen. In diesem Beispiel wird zwischen Spam und Nicht-Spam unterschieden.
Vorteile: Regression kann verwendet werden, um eine kontinuierliche Beziehung zwischen Variablen zu erkennen, auch wenn diese Beziehung nicht sehr offensichtlich ist Szenarien: Verkehrsanalyse, E-Mail-Filterung
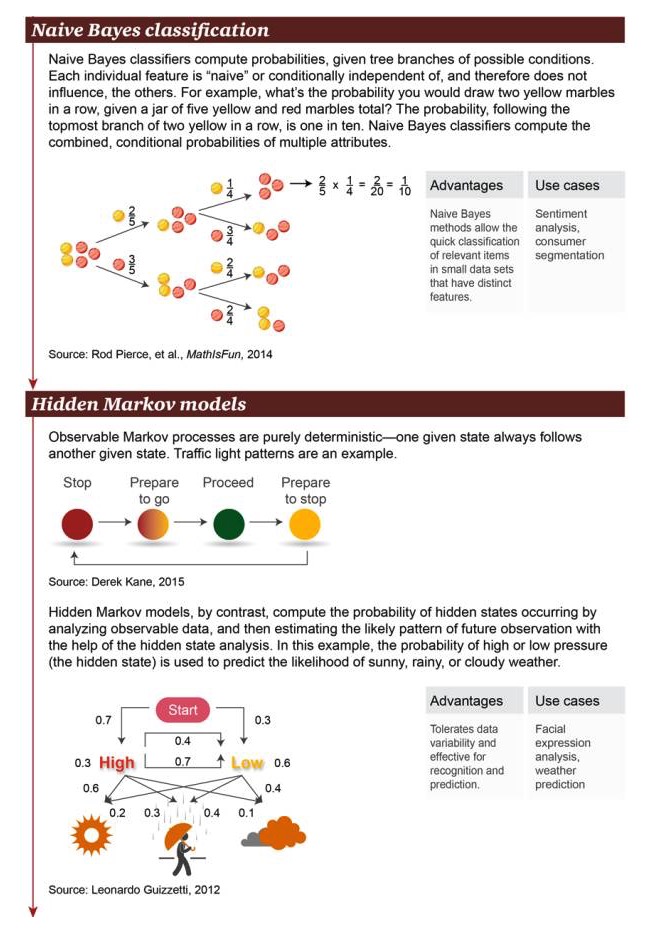
Naive Bayes-Klassifikation: Die Naive Bayes-Klassifikation berechnet die Ausgliederungswahrscheinlichkeit für mögliche Bedingungen. Jede einzelne Eigenschaft ist “naiv” oder bedingungsunabhängig, so dass sie keine anderen Objekte beeinflusst.
Vorteile: Einfache Bayesian-Methode für schnelle Klassifizierung von relevanten Objekten mit signifikanten Merkmalen in kleinen Datensätzen Szenarien wie Emotionsanalyse und Verbraucherklassifizierung
Das Hidden-Markov-Modell: Ein Markov-Prozess, bei dem es sich um absolute Sicherheit handelt, dass ein gegebener Zustand häufig mit einem anderen einhergeht. Ein Beispiel dafür ist ein Verkehrssignal. Im Gegensatz dazu berechnet das Hidden-Markov-Modell das Auftreten von versteckten Zuständen durch die Analyse sichtbarer Daten.
Vorteile: Erlaubt die Variabilität der Daten, eignet sich für Erkennung und Vorhersage Szenenbeispiele: Analyse von Gesichtsausdrücken, Wettervorhersage
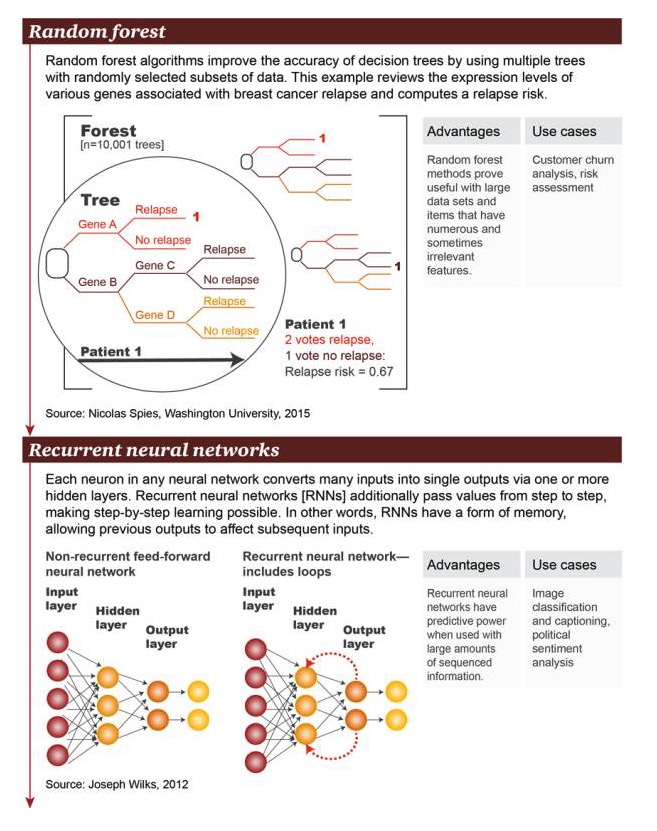
Random Forest: Die Random Forest-Algorithmen verbessern die Genauigkeit der Entscheidungsträume, indem sie mehrere Bäume mit mehreren, zufällig ausgewählten Datensubsätzen verwenden. Dieses Beispiel untersucht eine Vielzahl von Genen, die mit Brustkrebs-Rezidiv verbunden sind, auf der Ebene der Genexpression und berechnet das Risiko für ein erneutes Auftreten.
Vorteile: Die Random Forest-Methode hat sich als nützlich für große Datensätze und für Elemente mit einer großen Anzahl und manchmal unabhängigen Merkmalen erwiesen Szenarienbeispiel: Nutzerströmeanalyse, Risikobewertung
Recurrent Neural Network (RNN): In einem beliebigen neuronalen Netzwerk überträgt jede Nervenzelle viele Eingänge in eine einzelne Ausgabe über eine oder mehrere versteckte Schichten. Recurrent Neural Networks (RNNs) übertragen Werte weiter, Schicht für Schicht, so dass Lernprozesse möglich sind. In anderen Worten, RNNs haben eine Art von Speicher, der es erlaubt, dass frühere Eingänge die späteren Eingänge beeinflussen.
Vorteile: Die Vorhersagefähigkeit eines Kreislaufneuronalen Netzes in der Gegenwart einer großen Menge an organisierter Information Szenenbeispiele: Klassifizierung von Bildern mit Untertiteln, Analyse politischer Emotionen

Langes Kurzzeitgedächtnis (LSTM) und ein geschlossenes Recurrent Unit Nerual Network (GRU): Die frühen RNN-Formen sind verschwendet. Obwohl diese frühen Recurrent Unit Nerual Networks nur eine geringe Menge an frühen Informationen speichern konnten, verfügen die neueren RNNs über eine bessere Kontrolle des Gedächtnisses, was die Bewahrung früherer Werte erlaubt oder die Übersetzung dieser Werte, wenn eine Reihe von Schritten notwendig ist, was die endgültige Degradation der “Abnahme” oder der Übertragung von Werten in einer Reihe von Schritten verhindert.
Vorteile: Langzeit- und Kurzzeitgedächtnis-Netzwerke und Gate-Control-Neuralnetze haben die gleichen Vorteile wie andere Kreislauf-Netzwerke, werden jedoch häufiger verwendet, da sie bessere Speicherkapazitäten haben. Szenenbeispiele: natürliche Sprachverarbeitung, Übersetzung
Convolutional Neural Networks: Convolution ist die Verschmelzung von Gewichten aus nachfolgenden Schichten, die zur Markierung der Ausgabe verwendet werden können.
Vorteile: Convoluted Neural Networks sind sehr nützlich, wenn es sehr große Datensätze, eine große Anzahl von Merkmalen und komplexe Klassifizierungsaufgaben gibt Szenenbeispiele: Bilderkennung, Textübertragung, Sprachausgabe, Drogenentdeckung
- #### Das ist eine sehr schwierige Aufgabe.
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Übertragung von Big Data Land