Crear un robot de comercio de Bitcoin que no pierda dinero
El autor:La bondad, Creado: 2019-06-27 10:58:40, Actualizado: 2023-10-30 20:30:00
Vamos a usar el aprendizaje reforzado de la IA para hacer un robot de comercio de moneda digital.
En este artículo, vamos a crear y aplicar un algoritmo de aprendizaje reforzado para aprender cómo hacer un robot de negociación de Bitcoin. En este tutorial, vamos a usar el gim de OpenAI y el robot PPO de la base de datos estable-baselines, que es una rama de la base de datos de OpenAI.
Muchas gracias a OpenAI y DeepMind por el software de código abierto que han proporcionado a los investigadores de aprendizaje profundo en los últimos años. Si aún no has visto los increíbles logros que han logrado con tecnologías como AlphaGo, OpenAI Five y AlphaStar, es posible que hayas vivido fuera del aislamiento el año pasado, pero deberías ir a verlas.
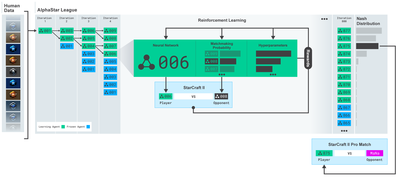
Formación de AlphaStarhttps://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Si bien no vamos a crear nada impresionante, el comercio de bitcoins por parte de robots en las transacciones diarias sigue siendo una tarea difícil.
Lo que se obtiene demasiado fácilmente no tiene valor alguno.
Por lo tanto, no solo debemos aprender a negociar por nosotros mismos... sino también dejar que los robots negocien por nosotros.
El plan

1.为我们的机器人创建gym环境以供其进行机器学习
2.渲染一个简单而优雅的可视化环境
3.训练我们的机器人,使其学习一个可获利的交易策略
Si aún no estás familiarizado con cómo crear entornos de gimnasia desde cero, o cómo visualizarlos con una simple representación. Antes de continuar, no dudes en googlear un artículo como este. Estas dos acciones no son difíciles incluso para un programador de primer nivel.
Entra
在本教程中,我们将使用Zielak生成的Kaggle数据集。如果您想下载源代码,我的Github仓库中会提供,同时也有.csv数据文件。好的,让我们开始吧。
Primero, importemos todas las bibliotecas necesarias. Asegúrate de instalar con pip cualquier biblioteca que te falte.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
A continuación, vamos a crear nuestra clase para el entorno. Necesitamos transmitir un parámetro de datos de pandas, así como un inicial_balance opcional y un lookback_window_size, que indicará el número de pasos de tiempo pasados observados por el robot en cada paso. Vamos a establecer la comisión por cada transacción como 0.075%, es decir, el tipo de cambio actual de Bitmex, y vamos a establecer el parámetro de la serie como falso por defecto, lo que significa que, por defecto, nuestro parámetro de datos se recorrerá en fragmentos aleatorios.
También llamamos a los datos dropna (()) y reset_index (()) y primero eliminamos las líneas con el valor NaN y luego reinsertamos el índice de los puntos, ya que hemos eliminado los datos.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Nuestro action_space aquí se representa como un grupo de 3 opciones (comprar, vender o mantener) y otro grupo de 10 cantidades (1/10, 2/10, 3/10, etc.). Cuando se selecciona la acción de comprar, se usa el buy amount * self.balance worth of BTC. Para la acción de vender, se usa el sell amount * self.btc_held value of BTC. Por supuesto, la acción de mantener ignora la cantidad y no hace nada.
Nuestro observation_space está definido como un conjunto de puntos flotantes continuos entre 0 y 1, y tiene la forma de ((10, lookback_window_size + 1)); + 1 para calcular la longitud del tiempo actual. Para cada longitud de tiempo en la ventana, observaremos el valor de OHCLV. Nuestro valor neto es igual a la cantidad de BTC comprados o vendidos, y el total de dólares que gastamos o recibimos en estos BTC.
A continuación, necesitamos escribir un método de reset para iniciar el entorno.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Aquí usamos self._reset_session y self._next_observation, que aún no hemos definido.
Las conversaciones
我们环境的一个重要部分是交易会话的概念。如果我们将这个机器人部署到市场外,我们可能永远不会一次运行它超过几个月。出于这个原因,我们将限制self.df中连续帧数的数量,也就是我们的机器人连续一次能看到的帧数。
En nuestro método_reset_session, primero restablecemos el current_step a 0; luego, establecemos el steps_left como un número aleatorio entre 1 y MAX_TRADING_SESSION, parte que definiremos en la parte superior del programa.
MAX_TRADING_SESSION = 100000 # ~2个月
A continuación, si queremos recorrer el número de bits continuamente, debemos establecerlo para recorrer todo el número de bits, de lo contrario, configuraremos frame_start como un punto aleatorio en el self.df y crearemos un nuevo número de bits de datos llamado active_df, que es solo un trozo de self.df y que proviene de frame_start a frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Un efecto secundario importante de recorrer los bits de datos en trozos aleatorios es que nuestros robots tendrán más datos únicos para usarlos en entrenamientos largos. Por ejemplo, si solo recorremos los bits de datos en serie (es decir, en la secuencia de 0 a len (df)) entonces tendremos solo los únicos puntos de datos con la misma cantidad de bits de datos. Nuestro espacio de observación puede incluso tener solo un número de estados discretos en cada paso de tiempo.
Sin embargo, al recorrer al azar los fragmentos del conjunto de datos, podemos crear un conjunto de resultados de transacciones más significativos para cada paso de tiempo en el conjunto de datos inicial, es decir, una combinación de comportamientos de transacciones y comportamientos de precios vistos anteriormente para producir conjuntos de datos más únicos. Déjenme explicar con un ejemplo.
Cuando el paso de tiempo después de restablecer el entorno de la serie es de 10, nuestro robot siempre se ejecutará simultáneamente en el conjunto de datos, y después de cada paso de tiempo hay tres opciones: comprar, vender o mantener. Para cada una de estas tres opciones se requiere otra opción: 10%, 20%,... o 100% de potencia específica. Esto significa que nuestro robot puede encontrarse con uno de los 10 estados de 103 veces, un total de 1030 situaciones.
Ahora volvemos a nuestro entorno de corte aleatorio. Cuando el paso de tiempo es 10, nuestro robot puede estar en cualquier paso de tiempo len (df) dentro del número de bits de datos. Suponiendo que se haga la misma elección después de cada paso de tiempo, significa que el robot puede experimentar un estado único en 30 segundos de cualquier paso de tiempo len (df) en los mismos 10 pasos de tiempo.
Aunque esto puede causar bastante ruido en los grandes conjuntos de datos, creo que debería permitir que los robots aprendan más de nuestra cantidad limitada de datos. Todavía vamos a recorrer nuestros datos de prueba en forma seria para obtener datos frescos y que parecen estar en estado de cero en tiempo real, con la esperanza de obtener una comprensión más precisa de la eficacia de los algoritmos.
Observado a través de ojos robóticos
La observación de un entorno visual eficaz es a menudo útil para entender el tipo de funciones que nuestro robot va a utilizar. Por ejemplo, aquí está la visualización de un espacio observable que se utiliza para la representación de OpenCV.

Observaciones del entorno de visualización de OpenCV
Cada línea en la imagen representa una línea en nuestro observation_space. Las primeras 4 líneas de frecuencia similar en rojo representan datos OHCL, y los puntos naranja y amarillo justo debajo representan transacciones completas. Las barras de color azul oscilante en la parte inferior representan las netas del robot, y las barras más ligeras en la parte inferior representan transacciones del robot.
Si observas con atención, incluso puedes hacer un diagrama por ti mismo. Debajo de la barra de volumen de transacción hay una interfaz similar a Morse que muestra el historial de transacciones. Parece que nuestro robot debería ser capaz de aprender lo suficiente de los datos de nuestro observation_space, así que sigamos adelante.
- Es importante ampliar solo los datos observados hasta ahora por el robot para evitar el desvío transversal.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
La acción
Ya hemos establecido nuestro espacio de observación, ahora es el momento de escribir nuestra función de la escalera y tomar las acciones previstas por el robot. Cada vez que tengamos el self.steps_left == 0 de la hora de negociación actual, venderemos el BTC que tenemos y llamaremos a_reset_session ((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((())))))))))))))))
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Tomar acciones de transacción es tan simple como obtener el precio actual, determinar las acciones que se necesitan realizar, y el número de compras o ventas.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
最后,在同一方法中,我们会将交易附加到self.trades并更新我们的净值和账户历史。
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Nuestros robots ahora pueden iniciar nuevos entornos, completarlos gradualmente y tomar acciones que afecten el entorno.
Vea nuestras operaciones robóticas
Nuestro método de renderización puede ser tan simple como llamar a print ((self.net_worth), pero no es lo suficientemente divertido. En su lugar, vamos a dibujar un simple diagrama que contiene un gráfico separado de los volúmenes de transacción y nuestro valor neto.
我们将从我上一篇文章中获取StockTradingGraph.py中的代码,并重新设计它以适应比特币环境。你可以从我的Github中获取代码。
El primer cambio que vamos a hacer es actualizar el self.df [
from datetime import datetime
Primero, importamos el datetime, y luego usamos el método utcfromtimestamp para obtener las cadenas UTC de cada horario y strftime, formándolas en: Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Finalmente, cambiamos el self.df a self.df para que coincida con nuestro conjunto de datos y estamos listos para hacerlo. Volviendo a nuestro Bitcoin TradingEnv, ahora podemos escribir métodos de renderización para mostrar los gráficos.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
¡Oh! ahora podemos ver a nuestros robots intercambiar bitcoins.

Visualizar las transacciones de nuestros robots con Matplotlib
Las etiquetas de fantasía verde representan las compras de BTC, las etiquetas de fantasía rojas representan las ventas. La etiqueta blanca en la esquina superior derecha es el valor neto actual del robot, y la etiqueta inferior derecha es el precio actual de Bitcoin. Simple y elegante. Ahora, es hora de entrenar a nuestro robot y ver cuánto dinero podemos ganar.
Tiempo de entrenamiento
Una de las críticas que recibí en un artículo anterior fue la falta de verificación cruzada, que no dividía los datos en conjuntos de entrenamiento y conjuntos de prueba. El objetivo de hacerlo era probar la precisión del modelo final sobre nuevos datos que nunca antes se habían visto. Aunque no era el enfoque de ese artículo, sí era muy importante.
Por ejemplo, una forma común de verificación cruzada se llama verificación k-fold, en la que usted divide los datos en k grupos iguales, uno por separado como grupo de prueba y el resto como grupo de entrenamiento. Sin embargo, los datos de la secuencia de tiempo son altamente dependientes del tiempo, lo que significa que los datos posteriores dependen altamente de los anteriores.
Cuando se aplica a datos de secuencias de tiempo, el mismo defecto se aplica a la mayoría de las otras estrategias de verificación cruzada. Por lo tanto, solo necesitamos usar una parte del conjunto de bits de datos completos como un conjunto de entrenamiento que comienza con el número de bits hasta algún índice arbitrario, y usar el resto de datos como un conjunto de pruebas.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
A continuación, ya que nuestro entorno está configurado para procesar solo el número de bits de datos individuales, vamos a crear dos entornos, uno para entrenar datos y otro para probar datos.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
现在,训练我们的模型就像使用我们的环境创建机器人并调用model.learn一样简单。
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Aquí, usamos tablas de tensión, por lo que podemos visualizar fácilmente nuestro flujo de tensión y ver algunos indicadores cuantitativos sobre nuestros robots. Por ejemplo, aquí hay una tabla de recompensas con descuento para muchos robots que han avanzado más de 200,000 pasos de tiempo:
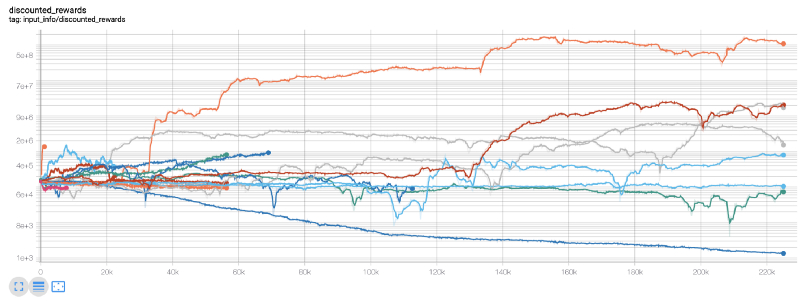
¡Oh, parece que nuestro robot es muy rentable! ¡Incluso nuestros mejores robots pueden lograr 1000 veces el equilibrio en el proceso de 200.000 pasos, con un promedio restante de al menos 30 veces!
En ese momento, me di cuenta de que había un error en el entorno... y después de corregirlo, este es el nuevo mapa de recompensas:
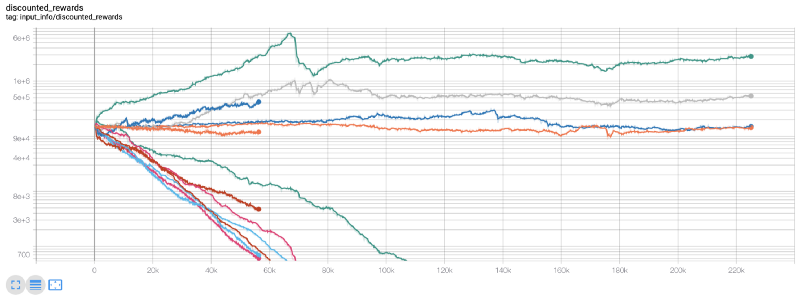
Como puedes ver, algunos de nuestros robots funcionan bien y otros se quiebran por sí solos. Sin embargo, los robots que funcionan bien pueden alcanzar hasta 10 veces o incluso 60 veces el saldo inicial. Tengo que admitir que todos los robots rentables son entrenados y probados sin comisiones, por lo que no es práctico que nuestros robots ganen dinero real.
Vamos a probar nuestros robots en un entorno de prueba (usando nuevos datos que nunca antes han visto) y ver cómo se comportan.
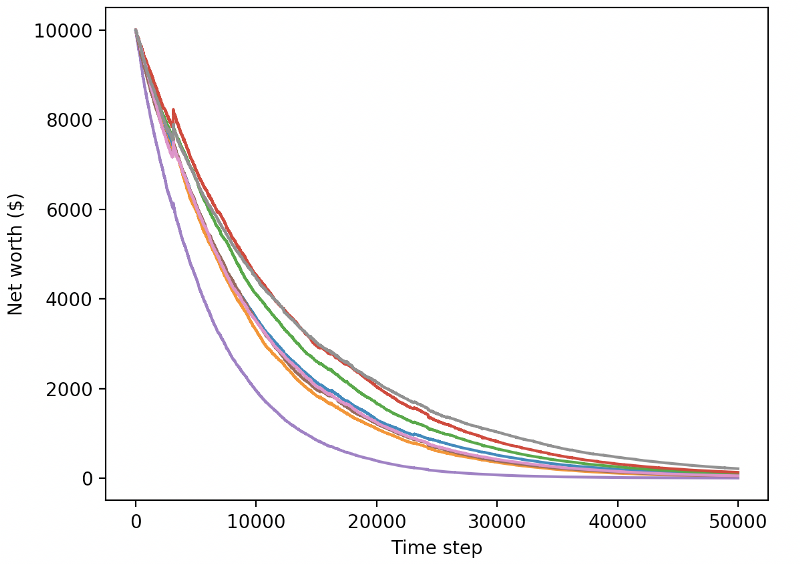
Nuestros robots entrenados en el comercio de nuevos datos de pruebas se estropean.
Obviamente, todavía tenemos mucho trabajo por hacer. Podemos mejorar enormemente nuestro rendimiento en este conjunto de datos simplemente cambiando el modelo para usar A2C de base estable, en lugar del actual robot PPO2. Finalmente, según las sugerencias de Sean O'Gorman, podemos actualizar ligeramente nuestra función de recompensas para que podamos aumentar la recompensa en el valor neto, en lugar de solo alcanzar un valor neto alto y quedarse allí.
reward = self.net_worth - prev_net_worth
Estos dos cambios por sí solos pueden mejorar enormemente el rendimiento de los conjuntos de datos de prueba, y como verás a continuación, finalmente podemos obtener ventajas de nuevos datos que no existen en los conjuntos de entrenamiento.
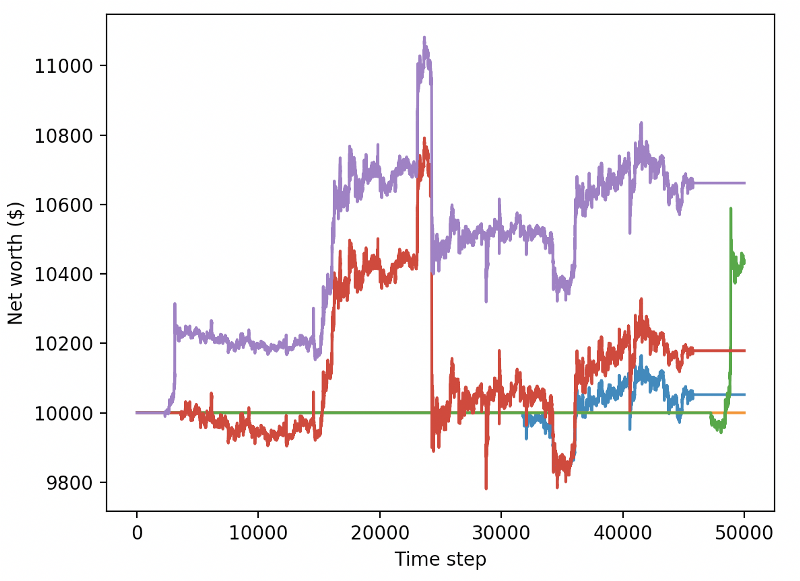
Pero podemos hacerlo mejor. Para mejorar estos resultados, necesitamos optimizar nuestros hiperparámetros y entrenar a nuestros robots por más tiempo.
Hasta ahora, este artículo es un poco largo y todavía tenemos muchos detalles que considerar, por lo que tenemos la intención de descansar aquí. En el siguiente artículo, usaremos la optimización de Bayes para asignar los mejores superparámetros para nuestro espacio de problemas y prepararnos para entrenar / probar con CUDA en la GPU.
Las conclusiones
En este artículo, comenzamos a crear un robot de comercio de Bitcoin rentable desde cero usando el aprendizaje reforzado.
1.使用OpenAI的gym从零开始创建比特币交易环境。
2.使用Matplotlib构建该环境的可视化。
3.使用简单的交叉验证对我们的机器人进行训练和测试。
4.略微调整我们的机器人以实现盈利
Aunque nuestros robots de negociación no han sido tan rentables como esperábamos, estamos avanzando en la dirección correcta. La próxima vez, vamos a asegurarnos de que nuestros robots siempre puedan vencer a los mercados y veremos cómo nuestros robots de negociación procesan los datos en tiempo real.
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Explorar métodos de prueba de estrategias basados en generadores de mercado aleatorios
- Nueva característica de FMZ Quant: Utilice la función _Serve para crear servicios HTTP fácilmente
- Sistema de negociación de divisas automático y software de negociación cuantitativa basado en el inventor de KAMA
- La plataforma de cuantificación de los inventores de FMZ
- Una simple demostración de la operación de la barra de la media móvil. (My language version)
- El edificio de la industria revela transacciones de algoritmos: los inventores cuantifican las plataformas como estrategias de mercado
- Cálculo y aplicación de los indicadores DMI
- Una estrategia de negociación intradía que utiliza la regresión de la media entre SPY e IWM
- Aplicación de los indicadores tecnológicos de Aroon en las transacciones cuantitativas
- Implementar políticas de cuantificación con JavaScript para ejecutar simultáneamente la función Go de envase de galón
- 19 expertos comparten sus consejos para las transacciones de moneda digital
- Las aplicaciones de los demonios de Shannon en la moneda digital
- Desarrollo de estrategias de CTA para obtener ganancias absolutas desde la cuantificación de transacciones hasta la gestión de activos
- 9 reglas de trading que ayudaron a un trader a pasar de $1,000 a $46,000 en menos de un año
- Introducción a las transacciones cuantificadas por los inventores - desde lo básico hasta la vida real
- 5.5 Optimización de la estrategia de negociación
- 5.4 ¿Por qué necesitamos un ensayo fuera de la muestra?
- 5.3 Cómo leer el informe de desempeño de la estrategia de pruebas de retroceso
- 5.2 Cómo hacer backtesting de operaciones cuantitativas
- 5.1 El significado y la trampa del backtesting
- 4.6 Cómo implementar estrategias en lenguaje C++
- 4.5 Lenguaje C++ Inicio rápido