Aplicación de la tecnología de aprendizaje automático en el comercio
 3
3072
3
3072

Esta publicación se inspiró en mis observaciones de algunas advertencias y trampas comunes después de intentar aplicar técnicas de aprendizaje automático a problemas comerciales durante mi investigación de datos en la plataforma Inventor Quant.
Si no ha leído mi artículo anterior, le recomendamos que lea mi guía anterior sobre el entorno de investigación de datos automatizado establecido en la plataforma cuantitativa Inventor y el enfoque sistemático para desarrollar estrategias comerciales antes de este artículo.
Las direcciones están aquí: https://www.fmz.com/digest-topic/4187 y https://www.fmz.com/digest-topic/4169.
Sobre el establecimiento del entorno de investigación
Este tutorial está diseñado para entusiastas, ingenieros y científicos de datos de todos los niveles. Ya sea que sea un experto en la industria o un novato en programación, las únicas habilidades que necesita son una comprensión básica del lenguaje de programación Python y un conocimiento suficiente de las operaciones de línea de comandos. (Es suficiente la capacidad de plantear un proyecto de ciencia de datos)
- Instalación de Inventor Quant Hoster y configuración de Anaconda
Además de proporcionar fuentes de datos de alta calidad de los principales intercambios convencionales, la plataforma cuantitativa Inventor FMZ.COM también proporciona un amplio conjunto de interfaces API para ayudarnos a realizar transacciones automatizadas después de completar el análisis de datos. Este conjunto de interfaces incluye herramientas prácticas como la consulta de información de cuentas, la consulta de precios altos, de apertura, bajos y de cierre, el volumen de operaciones, varios indicadores de análisis técnico comúnmente utilizados de varios intercambios principales, etc., especialmente para conectarse a los principales intercambios principales en tiempo real. Procesos comerciales. La interfaz API pública proporciona un soporte técnico potente.
Todas las características mencionadas anteriormente están encapsuladas en un sistema similar a Docker. Todo lo que tenemos que hacer es comprar o alquilar nuestro propio servicio de computación en la nube y luego implementar el sistema Docker.
En el nombre oficial de Inventor Quantitative Platform, este sistema Docker se denomina sistema host.
Para obtener más información sobre cómo implementar hosts y robots, consulte mi artículo anterior: https://www.fmz.com/bbs-topic/4140
Los lectores que quieran comprar su propio servidor de implementación de computación en la nube pueden consultar este artículo: https://www.fmz.com/bbs-topic/2848
Después de implementar con éxito el servicio de computación en la nube y el sistema host, instalaremos la herramienta Python más poderosa: Anaconda
Para lograr todos los entornos de programa relevantes necesarios para este artículo (bibliotecas dependientes, gestión de versiones, etc.), la forma más sencilla es utilizar Anaconda. Es un ecosistema de ciencia de datos Python empaquetado y un administrador de dependencias.
Dado que estamos instalando Anaconda en un servicio en la nube, le recomendamos que instale el sistema Linux más la versión de línea de comandos de Anaconda en el servidor en la nube.
Para conocer el método de instalación de Anaconda, consulte la guía oficial de Anaconda: https://www.anaconda.com/distribution/
Si eres un programador Python experimentado y no sientes la necesidad de usar Anaconda, no hay problema. Asumiré que no necesitas ayuda para instalar las dependencias necesarias y puedes omitir esta sección.
Desarrollar una estrategia comercial
El resultado final de una estrategia comercial debe responder las siguientes preguntas:
Dirección: Determinar si un activo es barato, caro o tiene un valor justo.
Condiciones de apertura: Si el precio del activo es barato o caro, debes posicionarte en largo o en corto.
Cerrar operación: si el precio del activo es justo y tenemos una posición en ese activo (compra o venta previa), ¿debería cerrar la posición?
Rango de precios: El precio (o rango) en el que se abre la operación.
Cantidad: La cantidad de fondos negociados (por ejemplo, la cantidad de moneda digital o la cantidad de lotes de futuros de materias primas)
El aprendizaje automático se puede utilizar para responder cada una de estas preguntas, pero en el resto de este artículo nos centraremos en responder la primera pregunta, que es la dirección del comercio.
Enfoque estratégico
Hay dos tipos de enfoques para desarrollar estrategias: uno se basa en modelos y el otro se basa en minería de datos. Estos dos son enfoques básicamente opuestos.
En la construcción de estrategias basadas en modelos, comenzamos con un modelo de ineficiencias del mercado, construimos expresiones matemáticas (por ejemplo, precios, retornos) y probamos su efectividad durante períodos de tiempo más largos. El modelo suele ser una versión simplificada de un modelo complejo real, y es necesario verificar su importancia y estabilidad a largo plazo. Las estrategias habituales de seguimiento de tendencias, reversión a la media y arbitraje entran en esta categoría.
Por otro lado, primero buscamos patrones de precios y tratamos de utilizar algoritmos en métodos de minería de datos. Lo que causa estos patrones no es importante, ya que lo único seguro es que seguirán repitiéndose en el futuro. Este es un método de análisis ciego y necesitamos una inspección rigurosa para identificar los patrones reales de los patrones aleatorios. “Prueba y error”, “Patrones de gráficos de barras” y “Regresión de masa de características” pertenecen a esta categoría.
Es evidente que el aprendizaje automático se presta fácilmente a los métodos de minería de datos. Veamos cómo se puede utilizar el aprendizaje automático para crear señales comerciales a través de la minería de datos.
Los ejemplos de código utilizan la herramienta de backtesting y la interfaz API de comercio automatizado basada en la plataforma cuantitativa Inventor. Después de implementar el hoster e instalar Anaconda en la sección anterior, solo necesitas instalar la biblioteca de análisis de ciencia de datos que necesitamos y el famoso modelo de aprendizaje automático scikit-learn. No entraremos en detalles sobre esta parte.
pip install -U scikit-learn
Uso del aprendizaje automático para crear señales de estrategia comercial
- Minería de datos
Antes de comenzar, un problema de aprendizaje automático estándar se ve así:
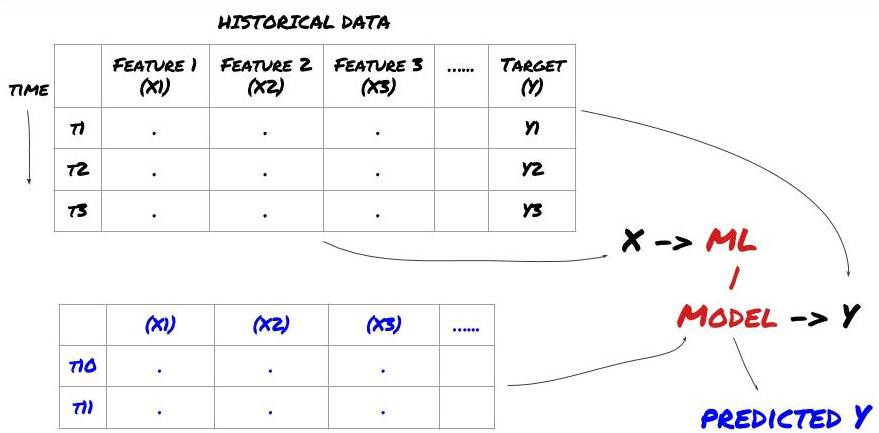
Marco de problemas de aprendizaje automático
Las características que vamos a crear deben tener cierto poder predictivo (X), queremos predecir la variable objetivo (Y) y usar los datos históricos para entrenar un modelo ML que pueda predecir Y lo más cerca posible del valor real. Finalmente, utilizamos este modelo para hacer predicciones sobre nuevos datos donde Y es desconocido. Esto nos lleva al primer paso:
Paso 1: Configura tu problema
- ¿Qué quieres predecir? ¿Qué es un buen pronóstico? ¿Cómo evalúas los resultados de la predicción?
Es decir, en nuestro marco anterior, ¿qué es Y?
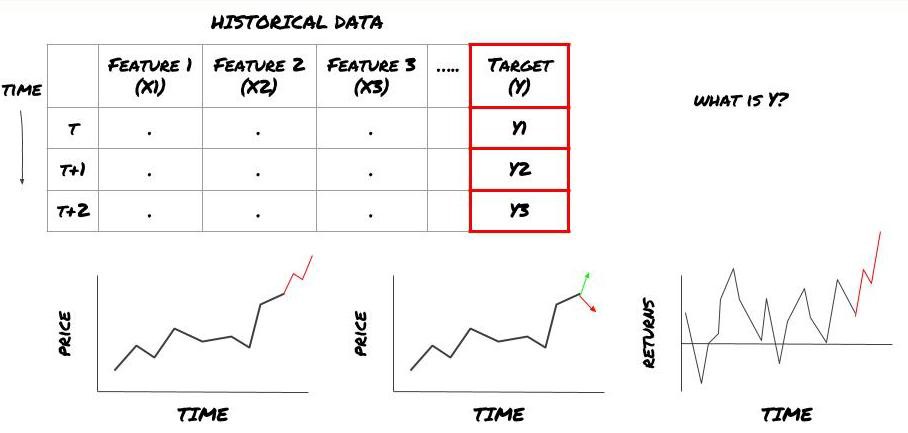
¿Qué quieres predecir?
¿Quiere predecir precios futuros, retornos/Pnl futuros, señales de compra/venta, optimizar las asignaciones de cartera e intentar ejecutar operaciones de manera eficiente, etc.?
Supongamos que estamos tratando de predecir el precio en la siguiente marca de tiempo. En este caso, Y(t) = Precio(t+1). Ahora podemos completar nuestro marco con datos históricos.
Tenga en cuenta que Y(t) solo se conoce en el backtest, pero cuando usamos nuestro modelo no sabremos el precio en el momento t (t+1). Utilizamos nuestro modelo para hacer una predicción Y(predicho, t) y la comparamos con el valor real solo en el tiempo t+1. Esto significa que no puedes usar Y como una característica en un modelo predictivo.
Una vez que conocemos nuestro objetivo Y, también podemos decidir cómo evaluar nuestras predicciones. Esto es importante para distinguir los diferentes modelos que probaremos con nuestros datos. Dependiendo del problema que estemos resolviendo, elegimos una métrica para medir la eficiencia de nuestro modelo. Por ejemplo, si estamos prediciendo precios, podemos utilizar el error cuadrático medio como métrica. Algunos indicadores de uso común (promedio móvil, MACD y puntuación de varianza, etc.) se han codificado previamente en la caja de herramientas de Inventor Quant y puede llamar a estos indicadores globalmente a través de la interfaz API.
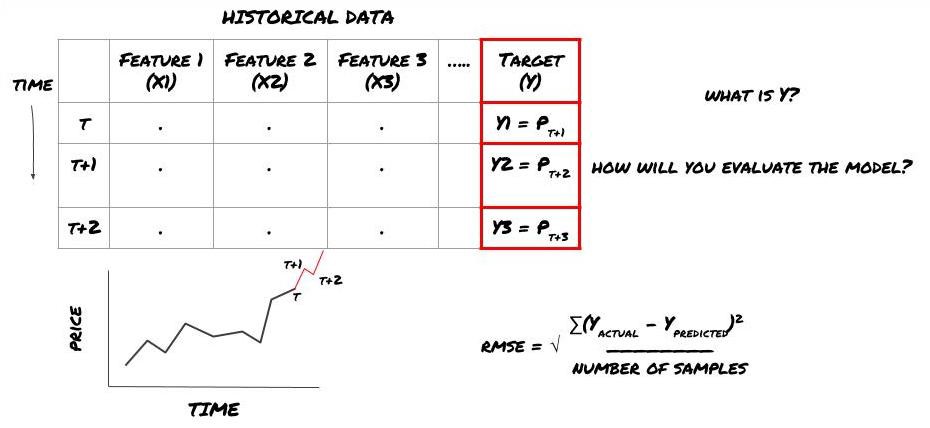
Marco de aprendizaje automático para predecir precios futuros
Para demostrarlo, crearemos un modelo de pronóstico para predecir el valor base futuro esperado de un objetivo de inversión hipotético, donde:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Dado que se trata de un problema de regresión, evaluaremos el modelo en RMSE (error cuadrático medio). También utilizaremos el Pnl Total como criterio de evaluación.
Nota: Para obtener conocimientos matemáticos relevantes sobre RMSE, consulte el contenido relevante de la Enciclopedia Baidu.
- Nuestro objetivo: crear un modelo que haga que los valores predichos sean lo más cercanos a Y como sea posible.
Paso 2: Recopilar datos confiables
Recopilar y limpiar datos que puedan ayudarle a resolver el problema en cuestión
¿Qué datos necesitas considerar para tener poder predictivo para la variable objetivo Y? Si estamos prediciendo precios, podemos utilizar datos de precios objetivo, datos de volumen comercial objetivo, datos similares para objetivos relacionados, indicadores generales del mercado como niveles de índice objetivo, precios de otros activos relacionados, etc.
Necesitará configurar permisos de acceso a estos datos y asegurarse de que sean precisos y resolver los datos faltantes (un problema muy común). Asegúrese también de que sus datos sean imparciales y representen adecuadamente todas las condiciones del mercado (por ejemplo, la misma cantidad de escenarios de ganancias y pérdidas) para evitar sesgos en su modelo. Es posible que también sea necesario limpiar los datos de dividendos, divisiones de cartera, continuaciones, etc.
Si utiliza la plataforma cuantitativa Inventor (FMZ.COM), podemos acceder a datos globales gratuitos de Google, Yahoo, NSE y Quandl; datos detallados de futuros de materias primas nacionales como CTP e Yisheng; Binance, OKEX, Huobi y BitMex La plataforma cuantitativa Inventor también limpia previamente y filtra estos datos, como las divisiones de objetivos de inversión y los datos detallados del mercado, y los presenta a los desarrolladores de estrategias en un formato que es fácil de entender para los trabajadores cuantitativos.
Para facilitar este artículo, utilizamos los siguientes datos como objetivo de inversión virtual ‘MQK’. También utilizamos una herramienta cuantitativa muy conveniente llamada Caja de herramientas de Auquan. Para obtener más información, consulte: https://github.com/Auquan / caja de herramientas auquan-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Con el código anterior, Auquan’s Toolbox ha descargado y cargado los datos en el diccionario del marco de datos. Ahora necesitamos preparar los datos en el formato que prefiramos. La función ds.getBookDataByFeature() devuelve un diccionario de marcos de datos, un marco de datos por característica. Creamos un nuevo marco de datos para acciones con todas las funcionalidades.
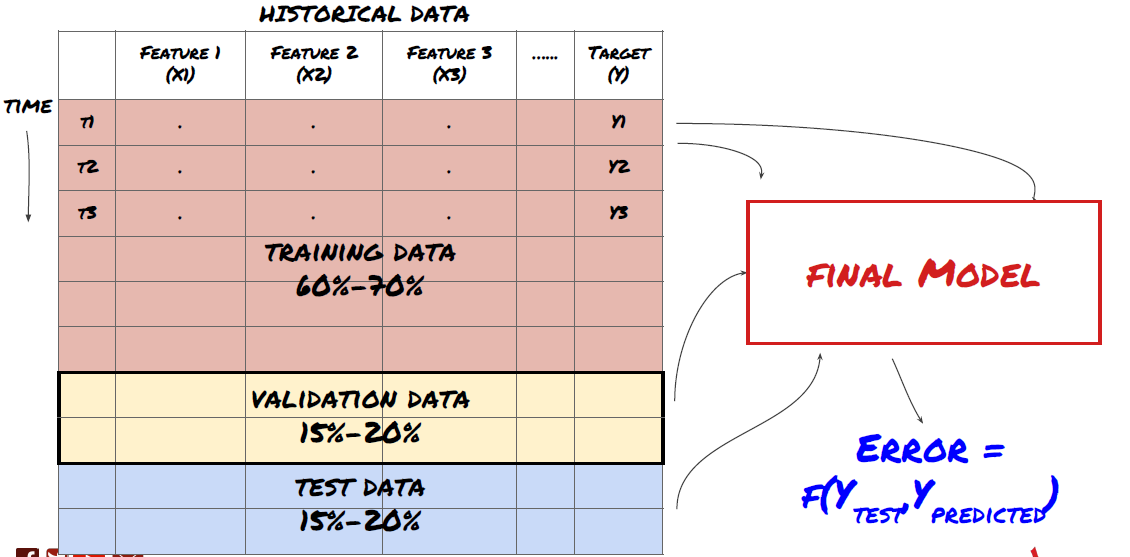
Paso 3: Dividir los datos
- Cree conjuntos de entrenamiento a partir de datos, valide de forma cruzada y pruebe estos conjuntos
¡Éste es un paso muy importante! Antes de continuar, debemos dividir los datos en un conjunto de datos de entrenamiento, para entrenar el modelo, y un conjunto de datos de prueba, para evaluar el rendimiento del modelo. La división recomendada es: 60-70% del conjunto de entrenamiento y 30-40% del conjunto de prueba.
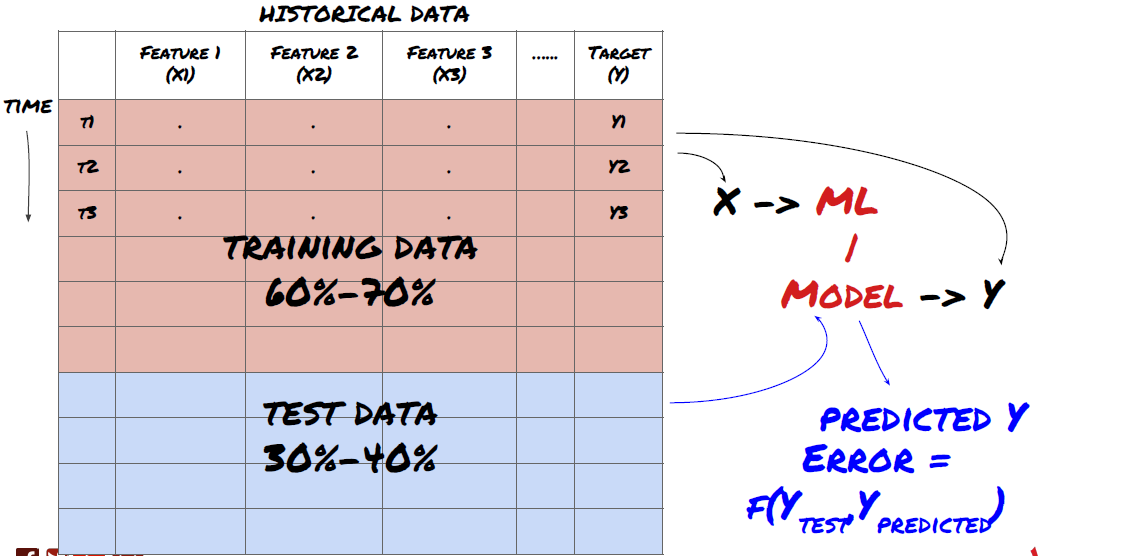
Dividir los datos en conjuntos de entrenamiento y prueba
Dado que los datos de entrenamiento se utilizan para evaluar los parámetros del modelo, es posible que su modelo se sobreajuste a estos datos de entrenamiento y estos datos pueden inducir a error en el rendimiento del modelo. Si no conserva datos de prueba separados y utiliza todos los datos para el entrenamiento, no sabrá qué tan bien o qué tan mal funcionará su modelo con datos nuevos e invisibles. Esta es una de las principales razones por las que los modelos ML entrenados fallan con datos en vivo: las personas se entrenan con todos los datos disponibles y se entusiasman con las métricas de los datos de entrenamiento, pero el modelo no puede hacer predicciones significativas con datos en vivo con los que no fue entrenado. .
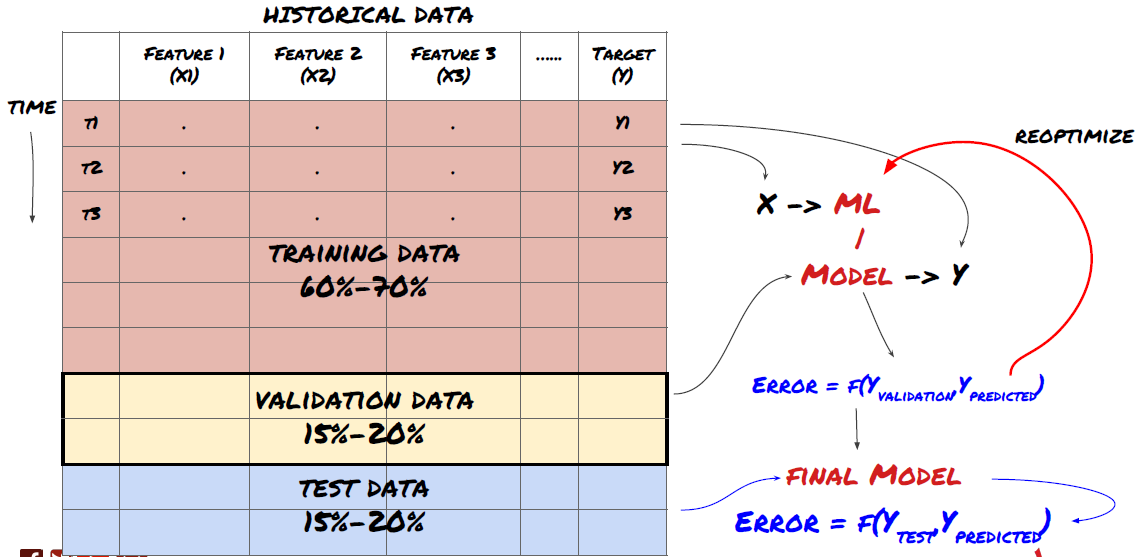
Dividir los datos en conjuntos de entrenamiento, validación y prueba.
Este enfoque plantea problemas. Si entrenamos repetidamente con datos de entrenamiento, evaluamos el rendimiento con datos de prueba y optimizamos nuestro modelo hasta que estemos satisfechos con el rendimiento, incluimos implícitamente los datos de prueba como parte de los datos de entrenamiento. En última instancia, nuestro modelo puede funcionar bien en este conjunto de datos de entrenamiento y prueba, pero no hay garantía de que pueda predecir bien nuevos datos.
Para abordar este problema, podemos crear un conjunto de datos de validación separado. Ahora puede entrenar con los datos, evaluar el rendimiento con los datos de validación, optimizar hasta estar satisfecho con el rendimiento y, finalmente, probar con los datos de prueba. De esta manera, los datos de prueba no se contaminarán y no utilizaremos ninguna información de los datos de prueba para mejorar nuestro modelo.
Recuerde, una vez que haya verificado el rendimiento en los datos de prueba, no regrese e intente optimizar aún más el modelo. Si descubre que su modelo no da buenos resultados, deséchelo por completo y comience de nuevo. La división sugerida podría ser 60% de datos de entrenamiento, 20% de datos de validación y 20% de datos de prueba.
Para nuestro problema, tenemos tres conjuntos de datos disponibles y utilizaremos uno como conjunto de entrenamiento, el segundo como conjunto de validación y el tercero como conjunto de prueba.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
A cada uno de estos, añadimos la variable objetivo Y, definida como la media de los siguientes cinco valores base.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Paso 4: Ingeniería de características
Analice el comportamiento de los datos y cree funciones con poder predictivo
Ahora comienza la construcción propiamente dicha del proyecto. La regla de oro de la selección de características es que el poder predictivo proviene principalmente de las características, no del modelo. Descubrirás que la elección de las características tiene un impacto mucho mayor en el rendimiento que la elección del modelo. Algunas notas sobre la selección de funciones:
No seleccione arbitrariamente un conjunto grande de características sin explorar su relación con la variable objetivo.
Una relación escasa o nula con la variable objetivo puede provocar un sobreajuste
Las características que elija pueden estar altamente correlacionadas entre sí, en cuyo caso una menor cantidad de características también puede explicar el objetivo.
Normalmente creo algunas características que tienen sentido intuitivo y observo cómo se correlaciona la variable de destino con estas características, así como también cómo se correlacionan entre sí para decidir cuáles usar.
También puede intentar clasificar las características candidatas según el coeficiente de información máximo (MIC), realizar un análisis de componentes principales (PCA) y otros métodos.
Transformación/normalización de características:
Los modelos ML tienden a funcionar bien con la normalización. Sin embargo, la normalización es complicada cuando se trabaja con datos de series de tiempo porque se desconoce el rango futuro de datos. Es posible que sus datos estén fuera del rango normalizado, lo que provoca que el modelo sea incorrecto. Pero aún puedes intentar forzar cierto grado de estacionariedad:
Escalamiento: dividir las características por desviación estándar o rango intercuartil
Centrado: Restar el promedio histórico del valor actual
Normalización: Dos períodos de retrospección de lo anterior (x - media) / desviación estándar
Normalización convencional: normaliza los datos en un rango de -1 a +1 y vuelve a centrarlos dentro del período de retrospección (x-min)/(max-min)
Tenga en cuenta que, dado que utilizamos la media móvil histórica, la desviación estándar, el valor máximo o mínimo durante el período retrospectivo, el valor normalizado de la característica representará diferentes valores reales en diferentes momentos. Por ejemplo, si el valor actual de una característica es 5 y el promedio móvil de 30 períodos es 4,5, se convertirá a 0,5 después del centrado. Posteriormente, si el promedio móvil de 30 períodos se convierte en 3, el valor 3,5 se convertirá en 0,5. Esta podría ser la razón por la que el modelo está equivocado. Por lo tanto, la regularización es complicada y hay que averiguar qué mejora realmente el rendimiento del modelo (si es que mejora algo).
Para la primera iteración de nuestro problema, creamos una gran cantidad de características utilizando los parámetros de mezcla. Más adelante intentaremos ver si podemos reducir el número de funciones.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Paso 5: Selección del modelo
Elija el modelo estadístico/ML apropiado para el problema elegido
La elección del modelo depende de cómo se formule el problema. ¿Está resolviendo un problema de aprendizaje supervisado (cada punto X en la matriz de características se asigna a una variable objetivo Y) o no supervisado (no se proporciona ninguna asignación y el modelo intenta aprender patrones desconocidos)? ¿Está resolviendo una regresión (prediciendo el precio real en un momento futuro) o un problema de clasificación (prediciendo solo la dirección (aumento/disminución) del precio en un momento futuro)?

Aprendizaje supervisado o no supervisado

Regresión o clasificación
Algunos algoritmos comunes de aprendizaje supervisado pueden ayudarle a comenzar:
Regresión lineal (parámetros, regresión)
Regresión logística (parámetros, clasificación)
Algoritmo de K-vecinos más cercanos (KNN) (basado en instancias, regresión)
SVM, SVR (parámetros, clasificación y regresión)
Árbol de decisión
Bosque de decisiones
Recomiendo comenzar con un modelo simple, como la regresión lineal o logística, y construir modelos más complejos a partir de allí según sea necesario. También se recomienda leer las matemáticas detrás del modelo en lugar de usarlo ciegamente como una caja negra.
Paso 6: Entrenamiento, validación y optimización (repetir los pasos 4-6)
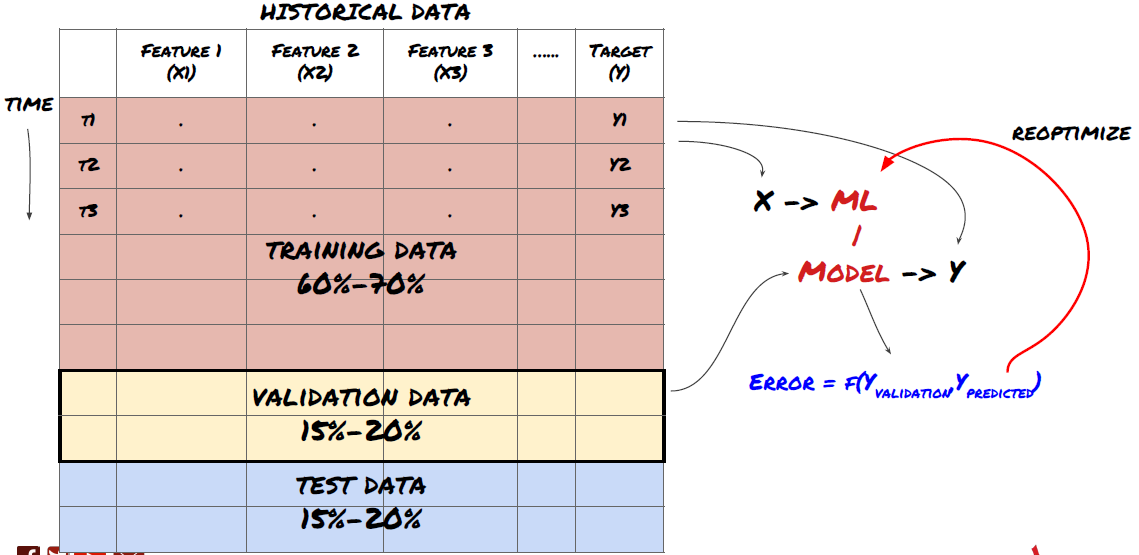
Entrene y optimice su modelo utilizando los conjuntos de datos de entrenamiento y validación
Ahora estás listo para construir finalmente tu modelo. En esta etapa, en realidad solo estás iterando sobre el modelo y los parámetros del modelo. Entrene su modelo con los datos de entrenamiento, mida su rendimiento con los datos de validación, luego regrese, optimice, vuelva a entrenar y evalúe. Si no está satisfecho con el rendimiento de un modelo, intente utilizar un modelo diferente. Pasarás por esta fase varias veces hasta que finalmente tengas un modelo con el que estés satisfecho.
Sólo cuando tengas un modelo que te guste, procede al siguiente paso.
Para nuestro problema de demostración, comencemos con una regresión lineal simple.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
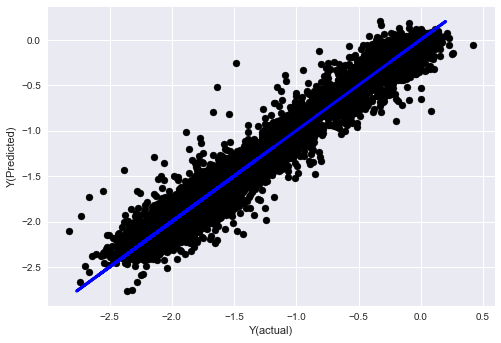
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
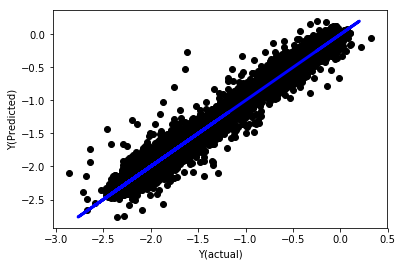
Regresión lineal sin normalización
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Mira los coeficientes del modelo. Realmente no podemos compararlos ni decir cuáles son importantes porque todos caen en escalas diferentes. Intentemos normalizarlos para ponerlos en la misma escala y también imponer cierta estacionariedad.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
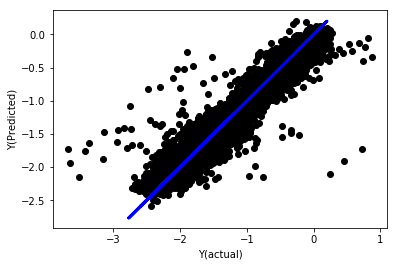
Regresión lineal normalizada
Mean squared error: 0.05
Variance score: 0.90
Este modelo no es una mejora respecto al anterior, pero tampoco es peor. Ahora podemos comparar los coeficientes y ver cuáles son realmente significativos.
Veamos los coeficientes
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
El resultado es:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Podemos ver claramente que algunas características tienen coeficientes más altos en comparación con otras características y es probable que tengan un mayor poder predictivo.
Veamos la correlación entre diferentes características.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
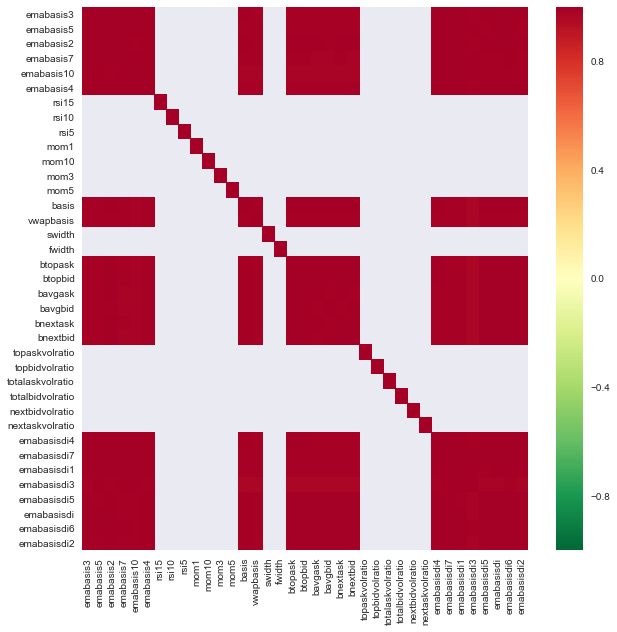
Correlación entre características
Las áreas de color rojo oscuro indican variables altamente correlacionadas. Vamos a crear/modificar algunas características nuevamente e intentar mejorar nuestro modelo.
Por ejemplo, puedo descartar fácilmente características como emabasisdi7, que son simplemente combinaciones lineales de otras características.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
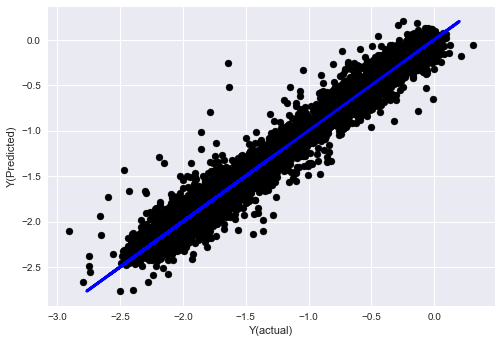
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Mira, no hay ningún cambio en el rendimiento de nuestro modelo, solo necesitamos algunas características para explicar nuestra variable objetivo. Le sugiero que pruebe más de las funciones anteriores, pruebe nuevas combinaciones, etc. para ver qué puede mejorar nuestro modelo.
También podemos probar modelos más complejos para ver si los cambios en el modelo pueden mejorar el rendimiento.
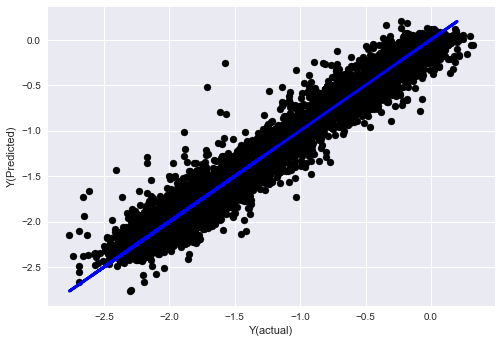
- Algoritmo de los K vecinos más cercanos (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
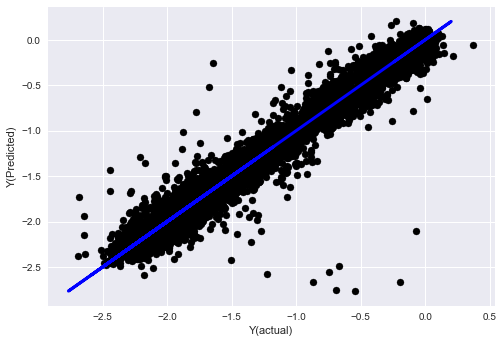
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Árbol de decisión
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Paso 7: Realizar una prueba retrospectiva de los datos de prueba
Verificar el rendimiento en datos de muestra reales
Rendimiento de las pruebas retrospectivas en el conjunto de datos de prueba (sin modificar)
Este es un momento crítico. Comenzamos desde el último paso ejecutando nuestro modelo optimizado final en los datos de prueba que dejamos de lado al principio y que no hemos tocado hasta ahora.
Esto le proporciona expectativas realistas de cómo funcionará su modelo con datos nuevos e invisibles cuando comience a operar en vivo. Por lo tanto, es necesario asegurarse de tener un conjunto de datos limpio que no haya sido utilizado para entrenar o validar el modelo.
Si no le gustan los resultados del backtesting en sus datos de prueba, deseche el modelo y comience de nuevo. ¡Nunca regrese y vuelva a optimizar su modelo, esto provocará un sobreajuste! (También se recomienda crear un nuevo conjunto de datos de prueba, ya que este conjunto de datos ahora está contaminado; al descartar el modelo, implícitamente ya sabemos algo sobre el conjunto de datos).
Aquí seguiremos utilizando la Caja de herramientas de Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
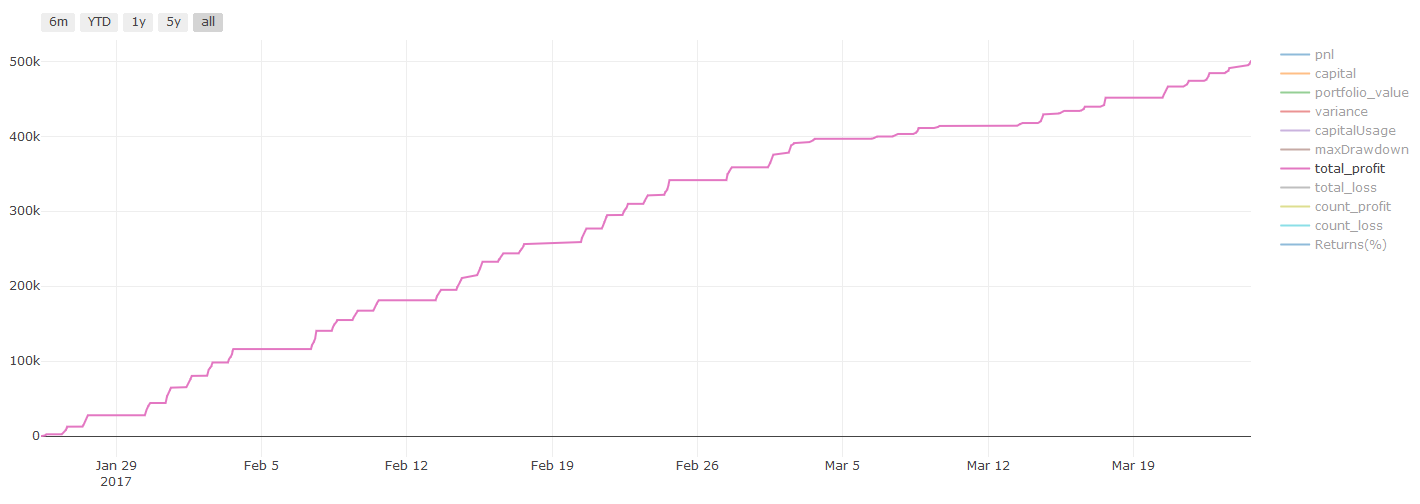
Resultados de backtest, Pnl se calcula en dólares estadounidenses (Pnl no incluye costos de transacción y otras tarifas)
Paso 8: Otras formas de mejorar el modelo
Validación continua, aprendizaje conjunto, bagging y boosting
Además de recopilar más datos, crear mejores funciones o probar más modelos, aquí hay algunas cosas que puedes intentar mejorar.
1. Verificación continua
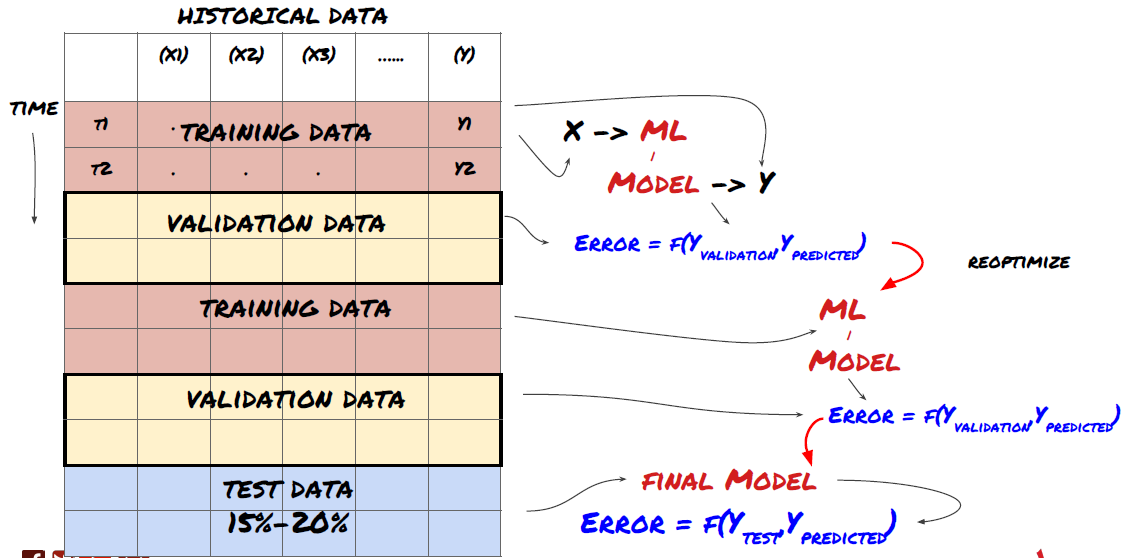
Validación continua
Las condiciones del mercado rara vez permanecen constantes. Digamos que tienes un año de datos y usas datos de enero a agosto para entrenar y datos de septiembre a diciembre para probar tu modelo; podrías terminar entrenando para un conjunto muy específico de condiciones de mercado. Tal vez no hubo volatilidad en el mercado durante la primera mitad del año y algunas noticias extremas provocaron que el mercado subiera bruscamente en septiembre. Su modelo no podrá aprender este patrón y le proporcionará resultados de predicción basura.
Tal vez sea mejor intentar avanzar con la validación: la capacitación en enero-febrero, la validación en marzo, la recapacitación en abril-mayo, la validación en junio, y así sucesivamente.
2. Aprendizaje en conjunto
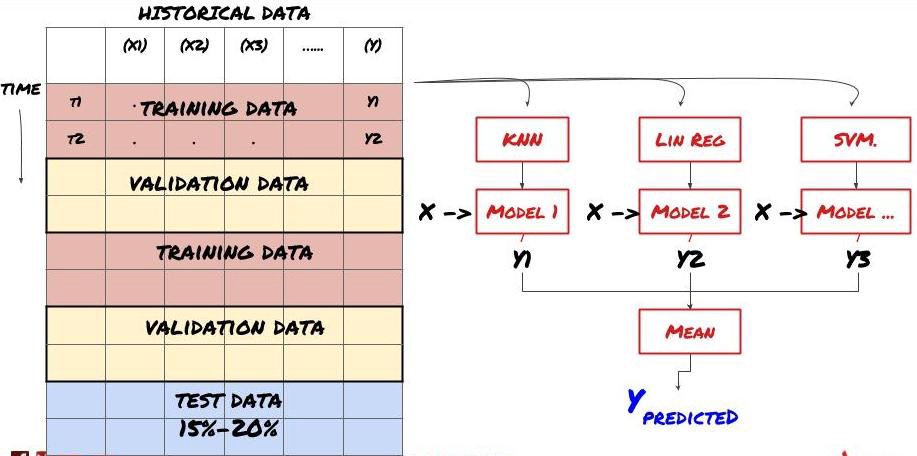
Aprendizaje en conjunto
Algunos modelos pueden funcionar bien para predecir ciertos escenarios, pero pueden sobreajustarse significativamente para predecir otros escenarios o en ciertas situaciones. Una forma de reducir el error y el sobreajuste es utilizar un conjunto de modelos diferentes. Su predicción será el promedio de las predicciones realizadas por muchos modelos, y los errores de los diferentes modelos pueden compensarse o reducirse. Algunos métodos de conjunto comunes son Bagging y Boosting.
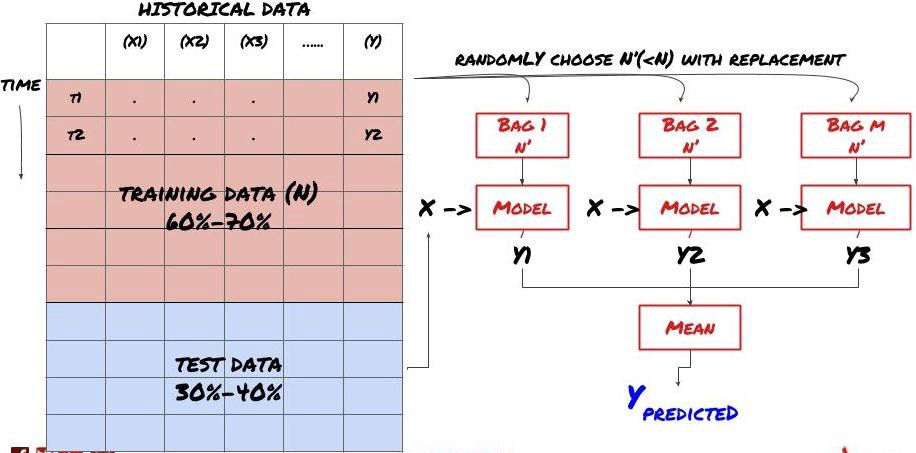
Bagging
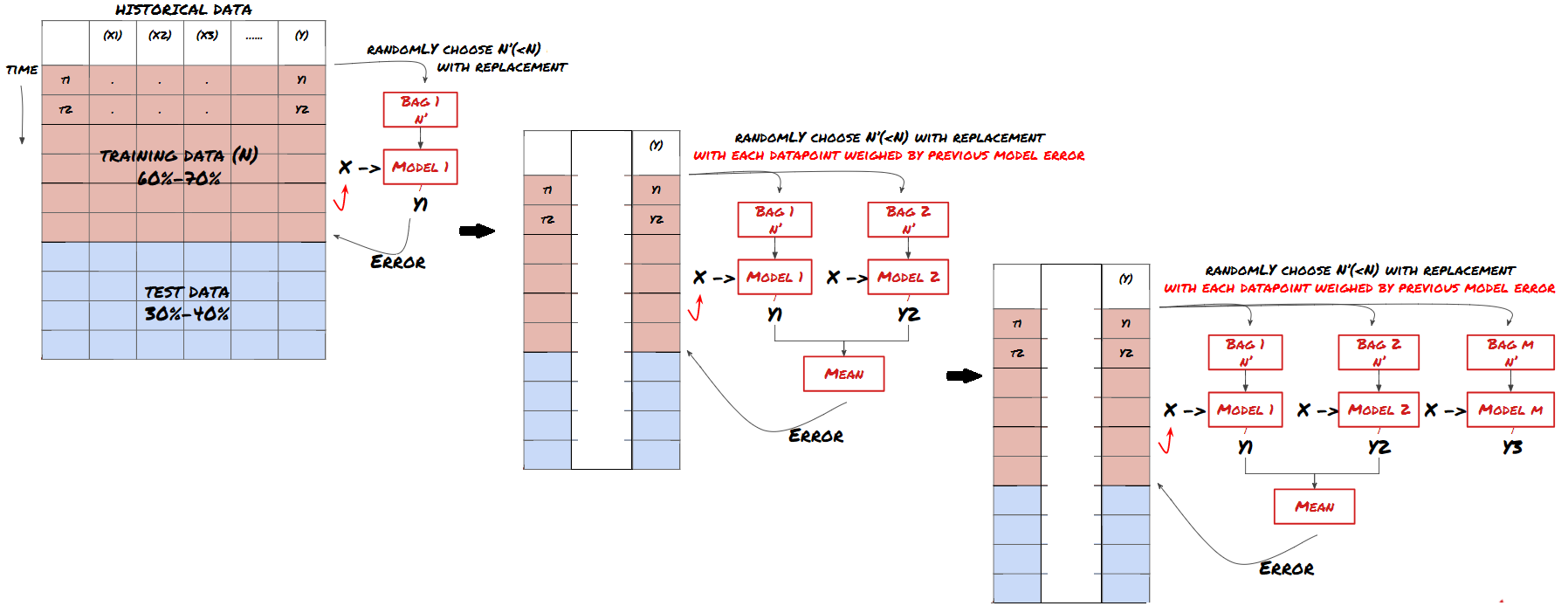
Boosting
Por el bien de la brevedad, omitiré estos métodos, pero puedes encontrar más información sobre ellos en línea.
Probemos un método de conjunto para nuestro problema.
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Hemos acumulado una gran cantidad de conocimientos e información hasta el momento. Repasemos rápidamente:
Resuelve tu problema
Recopilación de datos fiables y limpieza de datos
Dividir los datos en conjuntos de entrenamiento, validación y prueba.
Crear funciones y analizar su comportamiento.
Elija el modelo de entrenamiento adecuado en función del comportamiento
Utilice los datos de entrenamiento para entrenar su modelo y hacer predicciones
Verifique el rendimiento en el conjunto de validación y vuelva a optimizarlo
Validar el rendimiento final en el conjunto de pruebas
Muy emocionante, ¿verdad? Pero esto no ha terminado todavía. Ahora solo tienes un modelo de predicción fiable. ¿Recuerdas lo que realmente queríamos en nuestra estrategia? Así que todavía no necesitas:
Desarrollar señales basadas en modelos predictivos para identificar direcciones comerciales
Desarrollar una estrategia específica para identificar posiciones de apertura y cierre.
Sistema de ejecución para identificar posiciones y precios
Todo lo anterior requiere el uso de Inventor Quantitative Platform (FMZ.COM). En Inventor Quantitative Platform, hay una interfaz API altamente encapsulada y completa, así como funciones de órdenes y transacciones que se pueden llamar globalmente, por lo que no es necesario Para conectarlos y agregarlos uno por uno, las interfaces API de diferentes exchanges, en Strategy Square de Inventor Quantitative Platform, existen muchas estrategias alternativas maduras y completas. Con el método de aprendizaje automático de este artículo, su estrategia específica será más poderosa. La Plaza de Estrategia se encuentra en: https://www.fmz.com/square
Una nota importante sobre los costos de transacción:Su modelo le dirá cuándo tomar una posición larga o corta en su activo elegido. Sin embargo, no tiene en cuenta tarifas, costos de transacción, volumen disponible, stop loss, etc. Los costos de transacción a menudo pueden convertir una operación rentable en una pérdida. Por ejemplo, un activo cuyo precio se espera que aumente en \(0,05 es una compra, pero si tiene que pagar \)0,10 para realizar esta operación, terminará con una pérdida neta de $0,05. Nuestro impresionante gráfico de ganancias anterior en realidad se ve así después de tener en cuenta las comisiones del corredor, las tarifas de cambio y los diferenciales:
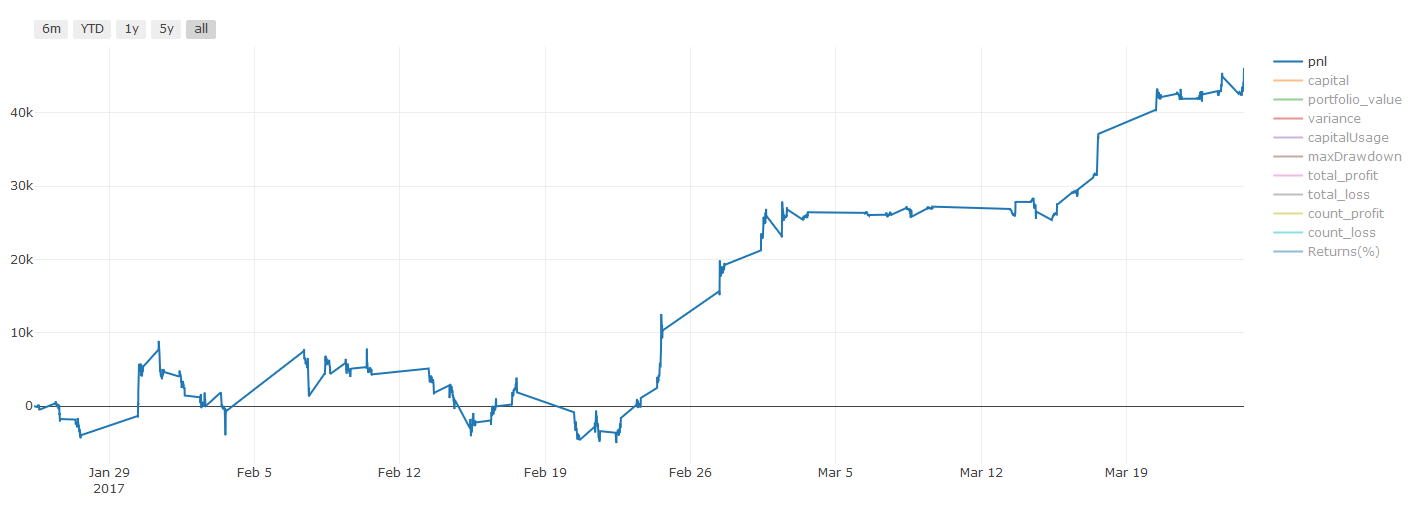
Resultados de la prueba retrospectiva después de las tarifas de transacción y los diferenciales, Pnl en USD
¡Las tarifas de transacción y los spreads representan más del 90% de nuestro PNL! Discutiremos estos temas en detalle en artículos posteriores.
Por último, veamos algunos errores comunes.
Qué hacer y qué no hacer
¡Evita el sobreajuste con todas tus fuerzas!
No vuelva a entrenar después de cada punto de datos: este es un error común que las personas cometen en el desarrollo de aprendizaje automático. Si su modelo necesita volver a entrenarse después de cada punto de datos, entonces probablemente no sea un modelo muy bueno. Es decir, es necesario volver a entrenarlo periódicamente, con la frecuencia que sea necesaria (por ejemplo, al final de cada semana si se realizan pronósticos intradiarios).
Evite los sesgos, especialmente el sesgo de anticipación: esta es otra razón por la que los modelos no funcionan. Asegúrese de no utilizar ninguna información del futuro. La mayoría de las veces, esto significa no utilizar la variable de destino Y como una característica en su modelo. Puedes usarlo durante las pruebas retrospectivas, pero no estará disponible cuando realmente ejecutes tu modelo, lo que lo hará inútil.
Tenga cuidado con el sesgo de minería de datos: dado que estamos tratando de realizar una serie de modelos en nuestros datos para determinar si encajan, si no hay una razón particular para ello, asegúrese de ejecutar pruebas rigurosas para separar los patrones aleatorios de los patrones reales que podrían ocurrir. . Por ejemplo, un patrón de tendencia ascendente se explica bien mediante una regresión lineal, pero es probable que sea una pequeña parte de un recorrido aleatorio más grande.
Evite el sobreajuste
Esto es tan importante que creo que es necesario mencionarlo nuevamente.
El sobreajuste es la trampa más peligrosa en las estrategias comerciales
Un algoritmo complejo puede funcionar muy bien en pruebas retrospectivas, pero fallar estrepitosamente con datos nuevos que no se han visto. El algoritmo no revela ninguna tendencia en los datos y no tiene un poder predictivo real. Se adapta muy bien a los datos que ve.
Mantenga su sistema lo más simple posible. Si descubre que necesita muchas características complejas para explicar sus datos, es posible que esté sobreajustándolos.
Divida los datos disponibles en datos de entrenamiento y de prueba, y verifique siempre el rendimiento en datos de muestra reales antes de usar el modelo para operaciones en vivo.