Machines à vecteurs de support dans le cerveau
 0
1749
0
1749
Machines à vecteurs de support dans le cerveau
Le support vectoriel (SVM) est un classificateur important de l’apprentissage automatique, qui utilise des transformations non linéaires pour projeter des caractéristiques de basse dimension en haute dimension, permettant d’effectuer des tâches de classification plus complexes. Le SWM semble utiliser un tour de passe-passe mathématique, mais il se trouve qu’il correspond à la mécanique du codage du cerveau. Titre de l’article: L’importance de la sélectivité mixte dans les tâches cognitives complexes (par Omri Barak et al.)
- #### SVM
D’où cette connexion étonnante? Parlons d’abord de la nature du codage neuronal: les animaux reçoivent un signal et agissent en fonction de celui-ci, l’un est de convertir le signal externe en signal électrique neuronal, l’autre est de convertir le signal électrique neuronal en signal de décision, le premier processus est appelé codage, le second processus est appelé décodage. Le véritable but du codage neuronal est de le décoder pour ensuite prendre une décision.
Alors, voyons comment le codage neuronal se passe. Tout d’abord, un neurone peut être considéré comme un circuit RC qui ajuste la résistance et la capacité en fonction de la tension externe. Quand le signal externe est suffisamment grand, il est conduit, sinon il est fermé, et un signal est représenté par la fréquence d’émission pendant un certain temps.
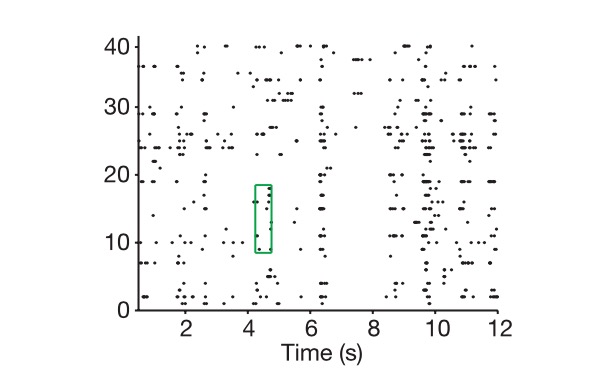
Le diagramme montre comment nous extraions le code neuronal de la cellule et de l’organisme.
Bien sûr, il y a une différence entre les dimensions réelles d’un vecteur n-dimensionnel et celles d’un code neuronal. Comment définir la dimension réelle d’un code neuronal? D’abord, nous entrons dans cet espace n-dimensionnel marqué par un vecteur n-dimensionnel, puis nous donnons toutes les combinaisons possibles de tâches, comme vous montrer un millier d’images, supposons que ces images représentent le monde entier, marquer chaque fois que nous obtenons un code neuronal comme un point dans cet espace, et enfin nous utilisons la pensée de l’algèbre vectorielle pour voir la dimension de ce millier de points qui constituent le sous-espace, c’est-à-dire la dimension réelle de la représentation neuronale.
En plus de la dimension réelle du code, nous avons un autre concept qui est la dimension réelle du signal externe, qui est le signal externe exprimé par un réseau de neurones, bien sûr, vous devez répéter tous les détails du signal externe c’est un problème infini, mais notre base de classification et de décision est toujours la caractéristique clé, un processus de réduction, c’est aussi l’idée de l’ACP. Ici, nous pouvons considérer les variables clés de la tâche réelle comme la dimension réelle de la tâche, par exemple, si vous voulez contrôler le mouvement d’un bras, vous avez généralement besoin de contrôler l’angle de rotation de l’articulation, si vous le faites comme un problème de dynamique solide, la dimension ne sera probablement pas supérieure à 10, nous l’appelons K.
Alors les scientifiques se posent une question fondamentale: pourquoi résoudre ce problème avec des dimensions de code et des nombres de neurones bien plus grands que les vrais problèmes ?
Et la neuroscience computationnelle et l’apprentissage automatique ensemble nous disent que les caractéristiques de haute dimension d’une représentation neuronale sont la base de ses capacités d’apprentissage supérieures. Plus la dimension de l’encodage est élevée, plus la capacité d’apprentissage est élevée.
Notez que le codage neuronal dont il est question ici se réfère principalement au codage neuronal des centres neuronaux supérieurs, tels que le cortex préfrontal (PFC) dont il est question dans le texte, car les lois de codage des centres neuronaux inférieurs ne sont pas très impliquées dans la classification et la prise de décision.
Les zones cérébrales supérieures représentées par le PFC
Tout d’abord, nous supposons que nous n’arriverons pas à traiter un problème de classification non linéaire en utilisant un classificateur linéaire lorsque notre dimension de codage est égale à celle d’une variable clé dans une tâche réelle (en supposant que vous vouliez séparer un melon d’un melon, vous ne pourriez pas le séparer d’un melon d’un melon avec une frontière linéaire), ce qui est un problème typique que nous avons du mal à résoudre en apprentissage en profondeur et sans SVM dans l’apprentissage automatique.
SVM (avec support vectoriel):
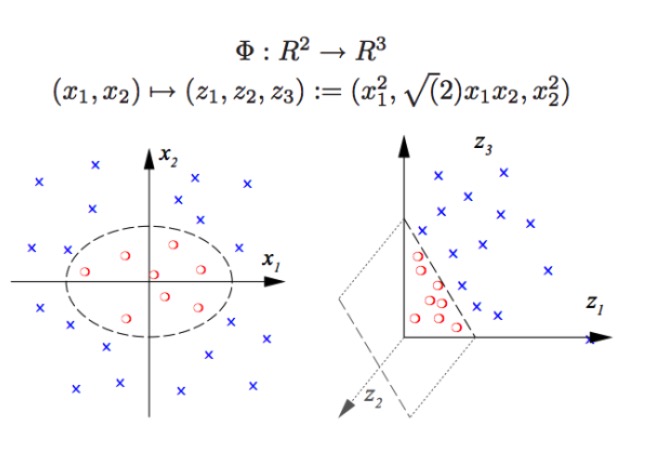
Le SVM peut effectuer des classifications non linéaires, par exemple séparer les points rouges et les points bleus dans le graphique, avec une frontière linéaire, nous ne pouvons pas séparer les points rouges et les points bleus (figure de gauche), donc la méthode utilisée par le SVM est l’élévation de la dimension. La simple augmentation du nombre de variables n’est pas possible, par exemple, la cartographie de (x1, x2) vers (x1, x2, x1 + x2) Le système est en fait un espace linéaire en deux dimensions (le fait de dessiner un graphique est que les points rouges et les points bleus sont sur un même plan), en utilisant uniquement des fonctions non linéaires (x1 ^ 2, x1)*x2, x2^2) on a une transition substantielle de la basse dimension vers la haute dimension, et vous jetez un point bleu dans l’air, et vous dessinez un plan dans l’air, et vous séparez le point bleu du point rouge, comme dans l’image de droite.
En fait, c’est exactement ce que font les réseaux neuronaux réels. Les types de classification qu’un classificateur linéaire comme celui-ci peut effectuer ont été considérablement augmentés, ce qui signifie que nous avons une capacité de reconnaissance de modèles beaucoup plus forte qu’auparavant.
Alors, comment obtenir une haute dimension de codage neuronal ? Un nombre plus élevé de neurones optiques n’est pas utile. Parce qu’en apprenant l’algèbre linéaire, nous savons que si nous avons un nombre énorme de neurones N, et que le décharge de chaque neurone n’est lié que de manière linéaire à K de caractéristiques clés, alors la dimension que nous avons finalement représentée n’est que la dimension du problème lui-même, vos N neurones n’ont pas d’importance (… les neurones en surnombre sont une combinaison linéaire de K de neurones).
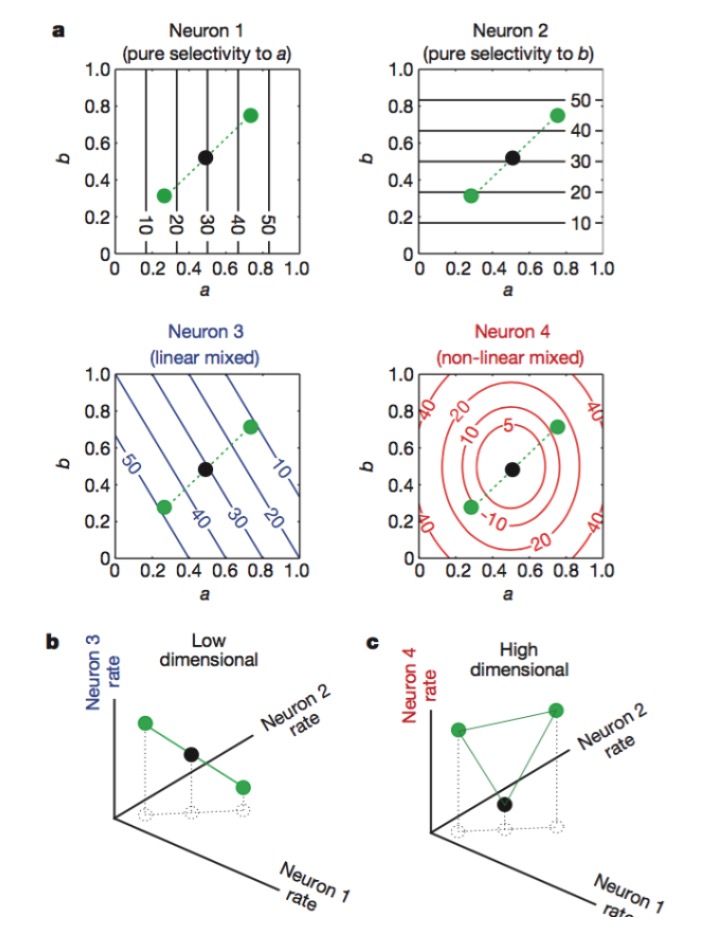
Figure: Les neurones 1 et 2 sont sensibles uniquement aux caractéristiques a et b, 3 aux caractéristiques a et b, et 4 aux caractéristiques non-linéaires. Finalement, seules les combinaisons de neurones 1, 2 et 4 augmentent la dimension de l’encodage neuronal (figure ci-dessous).
La fonction de chaque neurone est assez spécifique, par exemple les rods et les cones de la rétine sont chargés de recevoir les photons, puis la cellule Gangelion continue à coder, chaque neurone est comme un sentinelle spécialement formé. Dans les régions supérieures du cerveau, cette distinction claire est difficile à voir, et nous découvrons qu’une même neurone peut être sensible à une variété de caractéristiques, et que cette sensibilité n’est pas linéaire.
Chaque détail de la nature contient un sous-jacent, beaucoup de redondance et de codage mixte, ce qui semble être une pratique peu professionnelle, un signal apparemment chaotique, qui aboutit à une meilleure capacité de calcul. Avec ce principe, nous pouvons facilement gérer certaines tâches comme:
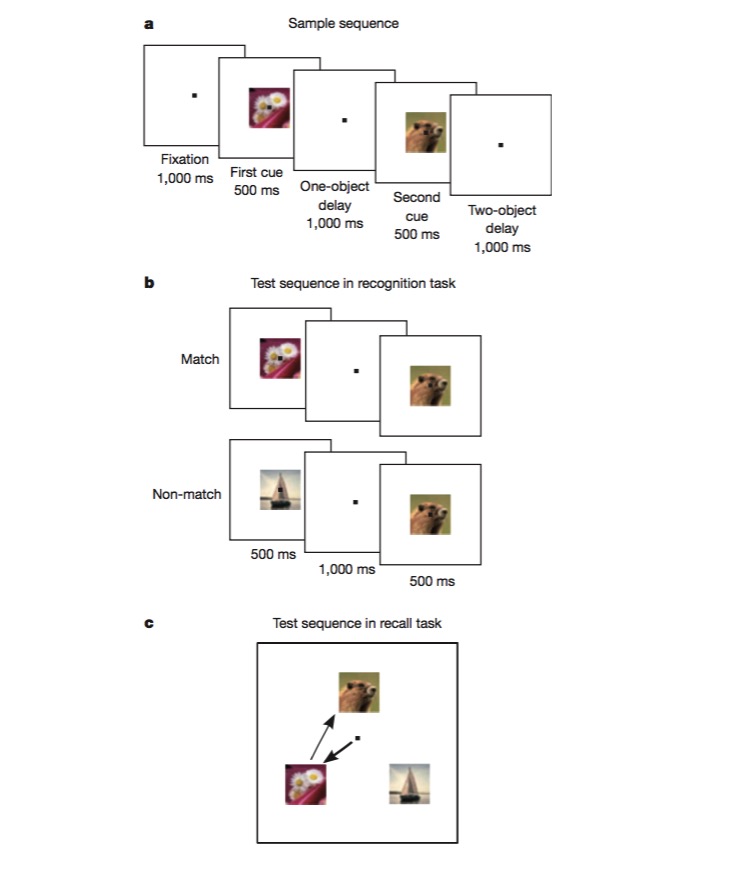
Dans cette tâche, le singe est d’abord entraîné à distinguer si une image est identique à la précédente (reconnaissance), puis à juger de l’ordre dans lequel deux images différentes apparaissent (rappel). Pour accomplir une telle tâche, le singe doit être capable de coder les différents aspects de la tâche, tels que le type de tâche (rappel ou reconnaissance), le type d’image, etc., et c’est l’expérience idéale pour tester l’existence d’un mécanisme de codage non linéaire mixte.
En lisant cet article, nous comprenons que la conception d’un réseau neuronal peut considérablement améliorer la reconnaissance de modèles en introduisant des unités non-linéaires, et que la SVM l’utilise pour résoudre le problème de la classification non-linéaire.
Nous étudions les fonctions des zones du cerveau, d’abord en utilisant des méthodes d’apprentissage automatique pour traiter les données, par exemple en trouvant les dimensions clés du problème avec l’A.C.P., puis en utilisant des modèles d’apprentissage automatique pour reconnaître la pensée pour comprendre le codage et le décodage des neurones. Finalement, si nous recevons de nouvelles inspirations, nous pouvons améliorer la méthode d’apprentissage automatique.
Une fois que vous aurez terminé, vous pourrez vous rendre à l’aéroport.