Application de la technologie d'apprentissage automatique dans le trading
 3
3072
3
3072

Cet article a été inspiré par mes observations de certains avertissements et pièges courants après avoir essayé d’appliquer des techniques d’apprentissage automatique à des problèmes de trading lors de mes recherches de données sur la plateforme Inventor Quant.
Si vous n’avez pas lu mon article précédent, nous vous recommandons de lire mon guide précédent sur l’environnement de recherche de données automatisé établi sur la plateforme quantitative Inventor et l’approche systématique du développement de stratégies de trading avant cet article.
Les adresses sont ici : https://www.fmz.com/digest-topic/4187 et https://www.fmz.com/digest-topic/4169.
À propos de la création d’un environnement de recherche
Ce didacticiel est conçu pour les passionnés, les ingénieurs et les data scientists de tous niveaux. Que vous soyez un expert du secteur ou un novice en programmation, les seules compétences dont vous avez besoin sont une compréhension de base du langage de programmation Python et une connaissance suffisante des opérations en ligne de commande. (La capacité à mettre en place un projet de science des données est suffisante)
- Installation d’Inventor Quant Hoster et configuration d’Anaconda
En plus de fournir des sources de données de haute qualité provenant des principales bourses grand public, la plateforme quantitative Inventor FMZ.COM fournit également un riche ensemble d’interfaces API pour nous aider à effectuer des transactions automatisées après avoir terminé l’analyse des données. Cet ensemble d’interfaces comprend des outils pratiques tels que l’interrogation des informations de compte, l’interrogation des prix les plus élevés, d’ouverture, les plus bas et les prix de clôture, le volume des transactions, divers indicateurs d’analyse technique couramment utilisés de diverses bourses traditionnelles, etc., en particulier pour se connecter aux principales bourses traditionnelles en temps réel. processus de trading. L’interface API publique fournit un support technique puissant.
Toutes les fonctionnalités mentionnées ci-dessus sont encapsulées dans un système similaire à Docker. Il suffit d’acheter ou de louer notre propre service de cloud computing, puis de déployer le système Docker.
Dans le nom officiel de la plateforme quantitative Inventor, ce système Docker est appelé système hôte.
Pour plus d’informations sur la manière de déployer des hôtes et des robots, veuillez vous référer à mon article précédent : https://www.fmz.com/bbs-topic/4140
Les lecteurs qui souhaitent acheter leur propre hébergeur de déploiement de serveur de cloud computing peuvent se référer à cet article : https://www.fmz.com/bbs-topic/2848
Après avoir déployé avec succès le service de cloud computing et le système hôte, nous installerons l’outil Python le plus puissant : Anaconda
Afin d’obtenir tous les environnements de programme pertinents requis pour cet article (bibliothèques dépendantes, gestion des versions, etc.), le moyen le plus simple est d’utiliser Anaconda. Il s’agit d’un écosystème de science des données Python packagé et d’un gestionnaire de dépendances.
Étant donné que nous installons Anaconda sur un service cloud, nous vous recommandons d’installer le système Linux ainsi que la version en ligne de commande d’Anaconda sur le serveur cloud.
Pour la méthode d’installation d’Anaconda, veuillez vous référer au guide officiel d’Anaconda : https://www.anaconda.com/distribution/
Si vous êtes un programmeur Python expérimenté et que vous ne ressentez pas le besoin d’utiliser Anaconda, c’est tout à fait normal. Je suppose que vous n’avez pas besoin d’aide pour installer les dépendances requises et que vous pouvez ignorer cette section.
Développer une stratégie de trading
Le résultat final d’une stratégie de trading doit répondre aux questions suivantes :
Direction : Déterminer si un actif est bon marché, cher ou équitablement valorisé.
Conditions d’ouverture : Si le prix de l’actif est bon marché ou cher, vous devez être long ou short.
Clôture de la transaction : si le prix de l’actif est juste et que nous avons une position sur cet actif (achat ou vente précédent), devez-vous clôturer la position ?
Fourchette de prix : Le prix (ou la fourchette) auquel la transaction est ouverte
Quantité : Le montant des fonds échangés (par exemple, le montant de la monnaie numérique ou le nombre de lots de contrats à terme sur matières premières)
L’apprentissage automatique peut être utilisé pour répondre à chacune de ces questions, mais pour le reste de cet article, nous nous concentrerons sur la réponse à la première question, qui est la direction du commerce.
Approche stratégique
Il existe deux types d’approches pour élaborer des stratégies : l’une est basée sur un modèle et l’autre est basée sur l’exploration de données. Ces deux approches sont fondamentalement opposées.
Dans la construction de stratégies basées sur des modèles, nous commençons par un modèle d’inefficacités du marché, construisons des expressions mathématiques (par exemple, prix, rendements) et testons leur efficacité sur des périodes plus longues. Le modèle est généralement une version simplifiée d’un modèle complexe réel, et sa signification et sa stabilité à long terme doivent être vérifiées. Les stratégies habituelles de suivi de tendance, de retour à la moyenne et d’arbitrage entrent dans cette catégorie.
D’autre part, nous recherchons d’abord des modèles de prix et essayons d’utiliser des algorithmes dans des méthodes d’exploration de données. La cause de ces modèles n’est pas importante, il est simplement certain que ces modèles continueront à se répéter à l’avenir. Il s’agit d’une méthode d’analyse à l’aveugle et nous avons besoin d’une inspection rigoureuse pour identifier les modèles réels parmi les modèles aléatoires. « Essais et erreurs », « Modèles de graphiques à barres » et « Régression de masse des fonctionnalités » appartiennent à cette catégorie.
De toute évidence, l’apprentissage automatique se prête facilement aux méthodes d’exploration de données. Voyons comment l’apprentissage automatique peut être utilisé pour créer des signaux de trading grâce à l’exploration de données.
Les exemples de code utilisent l’outil de backtesting et l’interface API de trading automatisée basée sur la plateforme quantitative Inventor. Après avoir déployé l’hébergeur et installé Anaconda dans la section ci-dessus, il ne vous reste plus qu’à installer la bibliothèque d’analyse de science des données dont nous avons besoin et le célèbre modèle d’apprentissage automatique scikit-learn. Nous n’entrerons pas dans les détails de cette partie.
pip install -U scikit-learn
Utiliser l’apprentissage automatique pour créer des signaux de stratégie de trading
- Exploration de données
Avant de commencer, un problème d’apprentissage automatique standard ressemble à ceci :
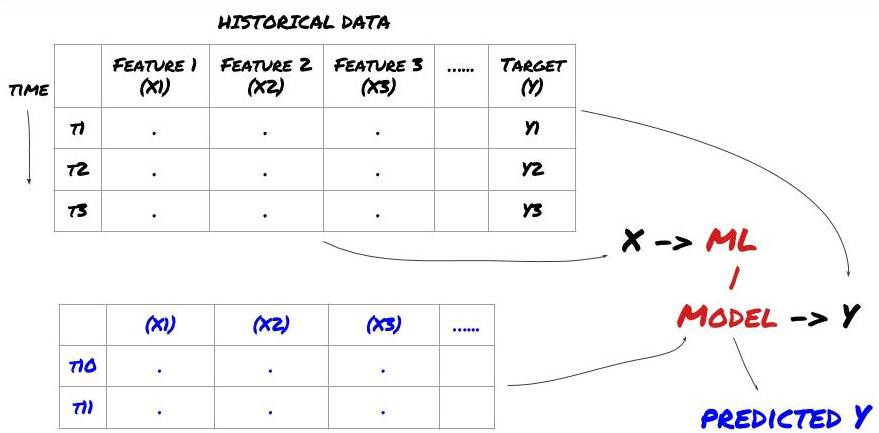
Cadre de problèmes d’apprentissage automatique
Les fonctionnalités que nous allons créer doivent avoir un certain pouvoir prédictif (X), nous voulons prédire la variable cible (Y) et utiliser les données historiques pour former un modèle ML capable de prédire Y aussi près que possible de la valeur réelle. Enfin, nous utilisons ce modèle pour faire des prédictions sur de nouvelles données où Y est inconnu. Cela nous amène à la première étape :
Étape 1 : Configurez votre problème
- Que voulez-vous prédire ? Qu’est-ce qu’une bonne prévision ? Comment évaluez-vous les résultats de la prédiction ?
Autrement dit, dans notre cadre ci-dessus, qu’est-ce que Y ?
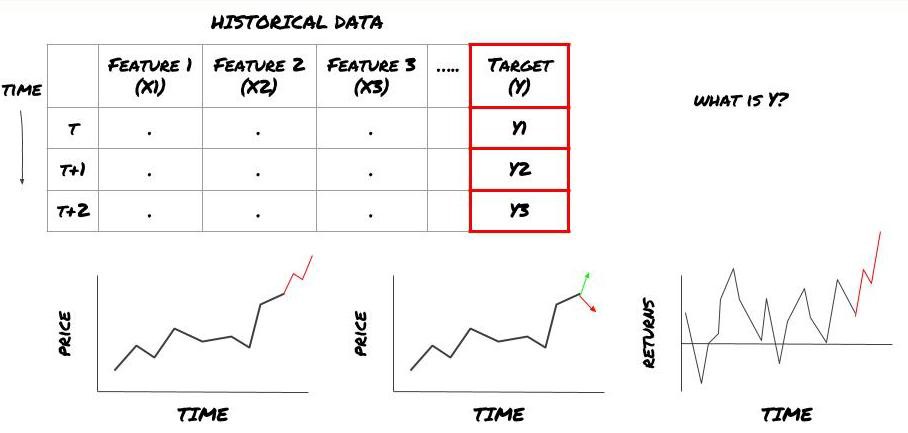
Que voulez-vous prédire ?
Voulez-vous prédire les prix futurs, les rendements futurs/Pnl, les signaux d’achat/vente, optimiser les allocations de portefeuille et essayer d’exécuter des transactions efficacement, etc. ?
Supposons que nous essayions de prédire le prix au prochain horodatage. Dans ce cas, Y(t) = Prix(t+1). Nous pouvons maintenant compléter notre cadre avec des données historiques
Notez que Y(t) n’est connu que dans le backtest, mais lorsque nous utilisons notre modèle, nous ne connaîtrons pas le prix à l’instant t (t+1). Nous utilisons notre modèle pour faire une prédiction Y(prédite, t) et la comparons à la valeur réelle uniquement à l’instant t+1. Cela signifie que vous ne pouvez pas utiliser Y comme fonctionnalité dans un modèle prédictif.
Une fois que nous connaissons notre cible Y, nous pouvons également décider comment évaluer nos prédictions. Ceci est important pour distinguer les différents modèles que nous allons essayer sur nos données. En fonction du problème que nous résolvons, choisissons une métrique pour mesurer l’efficacité de notre modèle. Par exemple, si nous prédisons les prix, nous pouvons utiliser l’erreur quadratique moyenne comme mesure. Certains indicateurs couramment utilisés (moyenne mobile, MACD et score de variance, etc.) ont été précodés dans la boîte à outils Inventor Quant, et vous pouvez appeler ces indicateurs globalement via l’interface API.
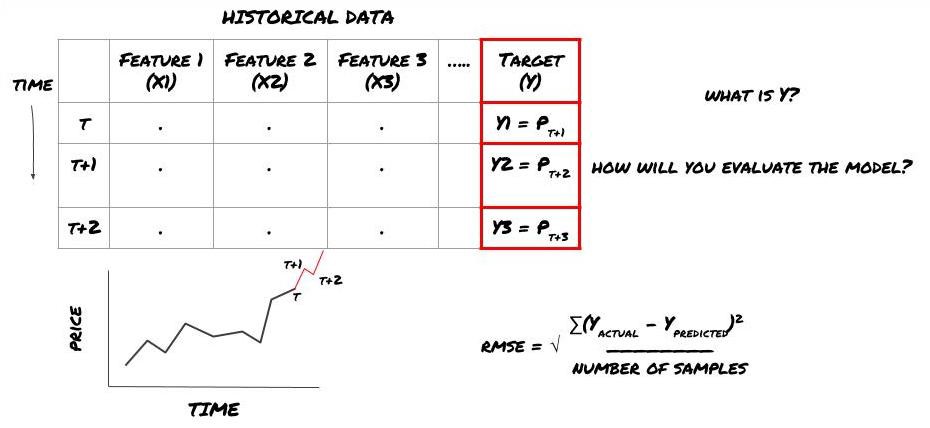
Cadre ML pour prédire les prix futurs
Pour démontrer cela, nous allons créer un modèle de prévision pour prédire la valeur de base future attendue d’une cible d’investissement hypothétique, où :
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Puisqu’il s’agit d’un problème de régression, nous évaluerons le modèle sur la RMSE (Root Mean Squared Error). Nous utiliserons également le Pnl total comme critère d’évaluation
Remarque : pour des connaissances mathématiques pertinentes sur le RMSE, veuillez vous référer au contenu pertinent de l’encyclopédie Baidu
- Notre objectif : créer un modèle qui rend les valeurs prédites aussi proches que possible de Y.
Étape 2 : Collecter des données fiables
Collectez et nettoyez les données qui peuvent vous aider à résoudre le problème en question
Quelles données devez-vous prendre en compte pour avoir un pouvoir prédictif pour la variable cible Y ? Si nous prédisons les prix, vous pouvez utiliser des données de prix cible, des données de volume de transactions cible, des données similaires pour des cibles connexes, des indicateurs de marché globaux tels que les niveaux d’indice cible, les prix d’autres actifs connexes, etc.
Vous devrez configurer des autorisations d’accès aux données pour ces données et vous assurer que vos données sont exactes et résoudre les données manquantes (un problème très courant). Assurez-vous également que vos données sont impartiales et représentent adéquatement toutes les conditions du marché (par exemple, le même nombre de scénarios de gain/perte) pour éviter tout biais dans votre modèle. Vous devrez peut-être également nettoyer les données relatives aux dividendes, aux répartitions de portefeuille, aux continuations, etc.
Si vous utilisez la plateforme quantitative Inventor (FMZ.COM), nous pouvons accéder gratuitement aux données mondiales de Google, Yahoo, NSE et Quandl ; aux données détaillées des contrats à terme sur matières premières nationales tels que CTP et Yisheng ; Binance, OKEX, Huobi et BitMex La plateforme quantitative Inventor pré-nettoie et filtre également ces données, telles que les répartitions des objectifs d’investissement et les données de marché approfondies, et les présente aux développeurs de stratégies dans un format facile à comprendre pour les travailleurs quantitatifs.
Pour la commodité de cet article, nous utilisons les données suivantes comme objectif d’investissement virtuel « MQK ». Nous utilisons également un outil quantitatif très pratique appelé Auquan’s Toolbox. Pour plus d’informations, veuillez consulter : https://github.com/Auquan / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Avec le code ci-dessus, la boîte à outils d’Auquan a téléchargé et chargé les données dans le dictionnaire de trame de données. Nous devons maintenant préparer les données dans un format que nous préférons. La fonction ds.getBookDataByFeature() renvoie un dictionnaire de trames de données, une trame de données par fonctionnalité. Nous créons un nouveau cadre de données pour les actions avec toutes les fonctionnalités.
Étape 3 : Diviser les données
- Créez des ensembles de formation à partir de données, validez et testez ces ensembles
C’est une étape très importante ! Avant de continuer, nous devons diviser les données en un ensemble de données d’entraînement, pour entraîner votre modèle, et un ensemble de données de test, pour évaluer les performances du modèle. La répartition recommandée est la suivante : 60 à 70 % de l’ensemble d’entraînement et 30 à 40 % de l’ensemble de test
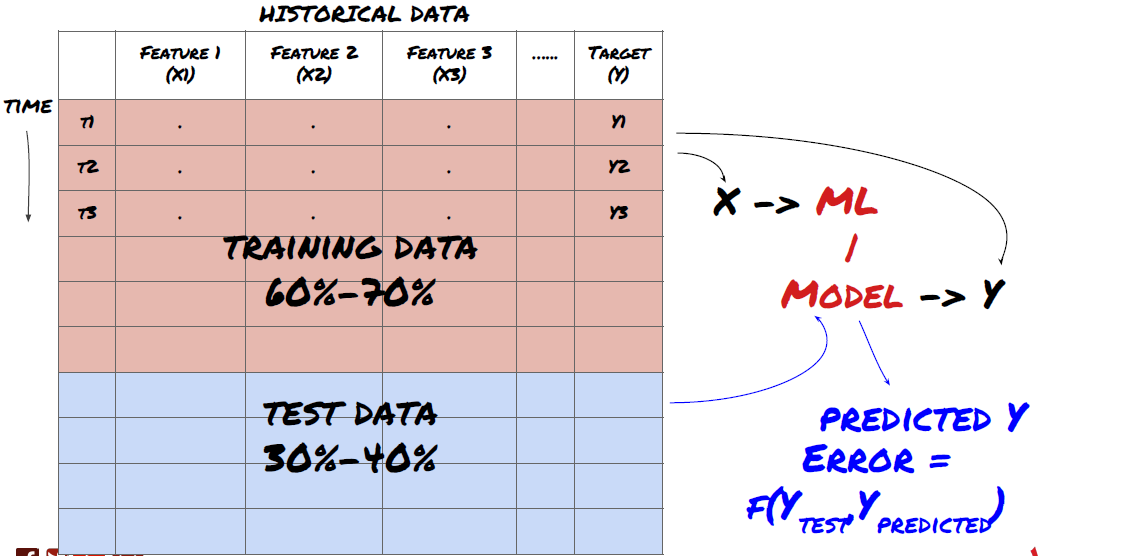
Diviser les données en ensembles d’entraînement et de test
Étant donné que les données d’entraînement sont utilisées pour évaluer les paramètres du modèle, votre modèle peut être surajusté à ces données d’entraînement et ces dernières peuvent induire en erreur les performances du modèle. Si vous ne conservez pas de données de test distinctes et que vous utilisez toutes les données pour la formation, vous ne saurez pas dans quelle mesure votre modèle fonctionnera bien ou mal sur des données nouvelles et invisibles. C’est l’une des principales raisons pour lesquelles les modèles ML formés échouent sur les données en direct : les utilisateurs s’entraînent sur toutes les données disponibles et sont enthousiasmés par les mesures des données d’entraînement, mais le modèle ne parvient pas à faire de prédictions significatives sur les données en direct sur lesquelles il n’a pas été formé. .
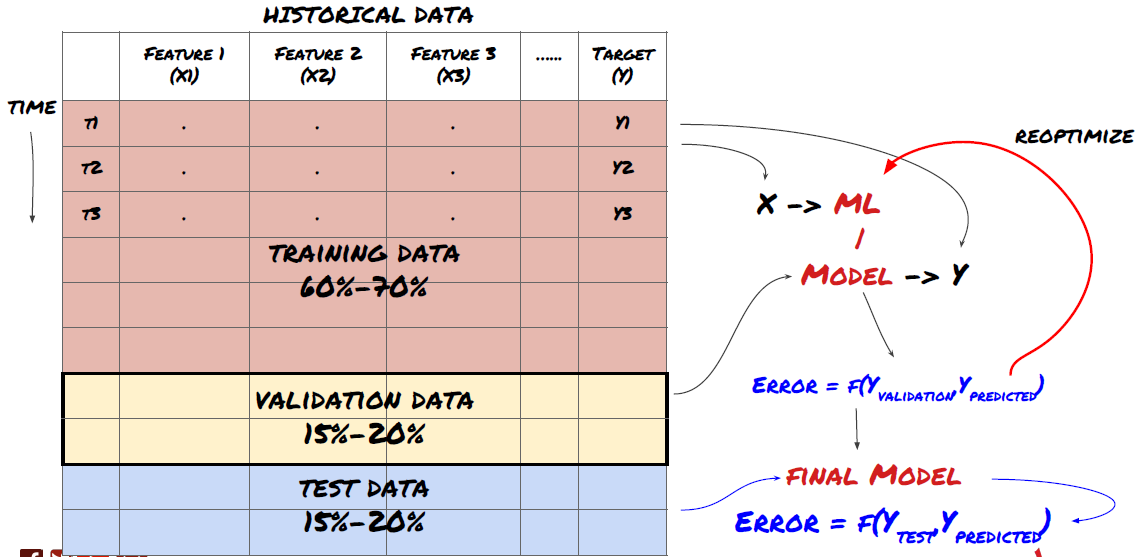
Divisez les données en ensembles d’entraînement, de validation et de test
Cette approche présente des problèmes. Si nous nous entraînons de manière répétée sur des données d’entraînement, évaluons les performances sur des données de test et optimisons notre modèle jusqu’à ce que nous soyons satisfaits des performances, nous incluons implicitement les données de test dans le cadre des données d’entraînement. En fin de compte, notre modèle peut bien fonctionner sur cet ensemble de données d’entraînement et de test, mais rien ne garantit qu’il sera capable de bien prédire de nouvelles données.
Pour résoudre ce problème, nous pouvons créer un ensemble de données de validation distinct. Vous pouvez désormais vous entraîner sur les données, évaluer les performances sur les données de validation, optimiser jusqu’à ce que vous soyez satisfait des performances et enfin tester sur les données de test. De cette façon, les données de test ne seront pas contaminées et nous n’utiliserons aucune information des données de test pour améliorer notre modèle.
N’oubliez pas qu’une fois que vous avez vérifié les performances des données de test, ne revenez pas en arrière et n’essayez pas d’optimiser davantage le modèle. Si vous constatez que votre modèle ne donne pas de bons résultats, jetez-le entièrement et recommencez. La répartition suggérée pourrait être de 60 % de données de formation, 20 % de données de validation et 20 % de données de test.
Pour notre problème, nous avons trois ensembles de données disponibles et nous en utiliserons un comme ensemble d’entraînement, le deuxième comme ensemble de validation et le troisième comme ensemble de test.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
À chacune d’entre elles, nous ajoutons la variable cible Y, définie comme la moyenne des cinq valeurs de base suivantes
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Étape 4 : Ingénierie des fonctionnalités
Analysez le comportement des données et créez des fonctionnalités avec un pouvoir prédictif
Maintenant, la construction proprement dite du projet commence. La règle d’or de la sélection des fonctionnalités est que le pouvoir prédictif provient principalement des fonctionnalités, et non du modèle. Vous constaterez que le choix des fonctionnalités a un impact beaucoup plus important sur les performances que le choix du modèle. Quelques notes sur la sélection des fonctionnalités :
Ne sélectionnez pas arbitrairement un grand ensemble de fonctionnalités sans explorer leur relation avec la variable cible.
Une relation faible ou inexistante avec la variable cible peut conduire à un surajustement
Les fonctionnalités que vous choisissez peuvent être fortement corrélées les unes aux autres, auquel cas un plus petit nombre de fonctionnalités peut également expliquer la cible
Je crée généralement des fonctionnalités qui ont un sens intuitif et j’examine comment la variable cible est corrélée avec ces fonctionnalités, ainsi que comment elles sont corrélées entre elles pour décider lesquelles utiliser.
Vous pouvez également essayer de classer les fonctionnalités candidates en fonction du coefficient d’information maximal (MIC), d’effectuer une analyse en composantes principales (ACP) et d’autres méthodes.
Transformation/normalisation des fonctionnalités :
Les modèles ML ont tendance à bien fonctionner avec la normalisation. Cependant, la normalisation est délicate lorsqu’il s’agit de données de séries chronologiques, car la plage future des données est inconnue. Vos données peuvent être en dehors de la plage normalisée, ce qui peut entraîner une erreur dans le modèle. Mais vous pouvez toujours essayer de forcer un certain degré de stationnarité :
Mise à l’échelle : diviser les caractéristiques par écart type ou intervalle interquartile
Centrage : Soustraire la moyenne historique de la valeur actuelle
Normalisation : Deux périodes de rétrospection de ce qui précède (x - moyenne) / écart-type
Normalisation conventionnelle : normaliser les données dans une plage de -1 à +1 et recentrer dans la période de rétrospection (x-min)/(max-min)
Notez que puisque nous utilisons la moyenne mobile historique, l’écart type, la valeur maximale ou minimale sur la période rétrospective, la valeur normalisée de la fonctionnalité représentera différentes valeurs réelles à différents moments. Par exemple, si la valeur actuelle d’une fonction est de 5 et que la moyenne mobile sur 30 périodes est de 4,5, elle sera convertie en 0,5 après centrage. Plus tard, si la moyenne mobile sur 30 périodes devient 3, la valeur 3,5 deviendra 0,5. Cela pourrait être la raison pour laquelle le modèle est erroné. La régularisation est donc délicate et vous devez déterminer ce qui améliore réellement les performances du modèle (le cas échéant).
Pour la première itération de notre problème, nous avons créé un grand nombre de fonctionnalités en utilisant les paramètres de mixage. Plus tard, nous essaierons de voir si nous pouvons réduire le nombre de fonctionnalités
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Étape 5 : Sélection du modèle
Choisissez le modèle statistique/ML approprié au problème choisi
Le choix du modèle dépend de la manière dont le problème est formulé. Résolvez-vous un problème d’apprentissage supervisé (chaque point X de la matrice de caractéristiques est mappé à une variable cible Y) ou non supervisé (aucun mappage n’est donné et le modèle essaie d’apprendre des modèles inconnus) ? Résolvez-vous un problème de régression (prédire le prix réel à un moment futur) ou un problème de classification (prédire uniquement la direction (augmentation/diminution) du prix à un moment futur).

Apprentissage supervisé ou non supervisé

Régression ou classification
Certains algorithmes d’apprentissage supervisé courants peuvent vous aider à démarrer :
LinearRegression(paramètres, régression)
Régression logistique (paramètres, classification)
Algorithme des K plus proches voisins (KNN) (basé sur les instances, régression)
SVM, SVR (paramètres, classification et régression)
Arbre de décision
Forêt de décision
Je recommande de commencer par un modèle simple, tel qu’une régression linéaire ou logistique, et de créer des modèles plus complexes à partir de là si nécessaire. Il est également recommandé de lire les mathématiques derrière le modèle plutôt que de l’utiliser aveuglément comme une boîte noire.
Étape 6 : Formation, validation et optimisation (répétez les étapes 4 à 6)
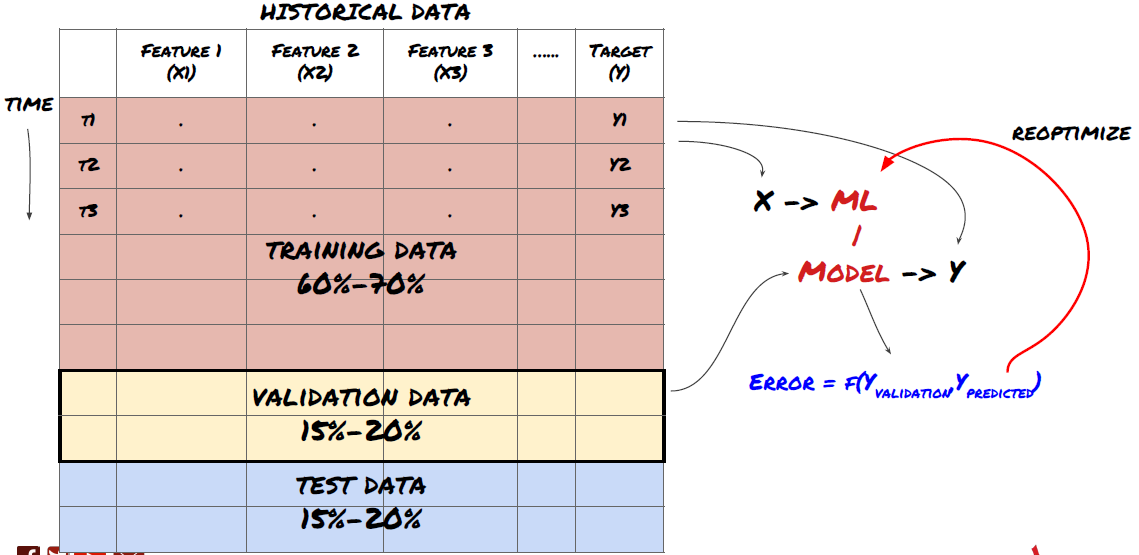
Entraînez et optimisez votre modèle à l’aide des ensembles de données d’entraînement et de validation
Vous êtes maintenant prêt à enfin construire votre modèle. À ce stade, vous ne faites qu’itérer sur le modèle et les paramètres du modèle. Entraînez votre modèle sur les données d’entraînement, mesurez ses performances sur les données de validation, puis revenez en arrière, optimisez, recyclez et évaluez. Si vous n’êtes pas satisfait des performances d’un modèle, essayez d’utiliser un autre modèle. Vous parcourez cette phase plusieurs fois jusqu’à ce que vous obteniez enfin un modèle qui vous convient.
Une fois que vous avez un modèle qui vous plaît, passez à l’étape suivante.
Pour notre problème de démonstration, commençons par une régression linéaire simple
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
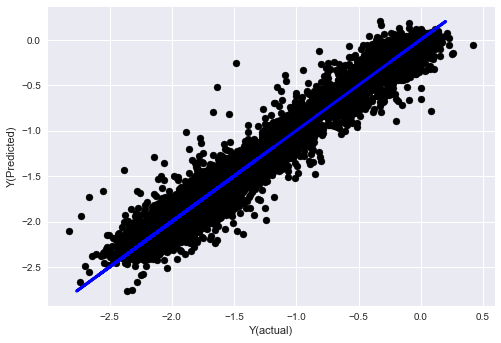
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
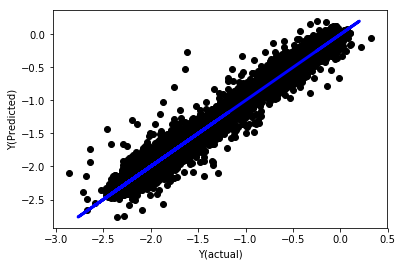
Régression linéaire sans normalisation
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Regardez les coefficients du modèle. Nous ne pouvons pas vraiment les comparer ou dire lesquels sont importants car ils se situent tous à des échelles différentes. Essayons de normaliser pour les amener à la même échelle et également renforcer une certaine stationnarité.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
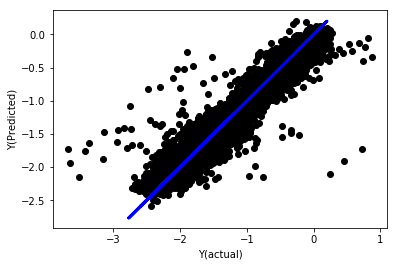
Régression linéaire normalisée
Mean squared error: 0.05
Variance score: 0.90
Ce modèle n’est pas une amélioration par rapport au précédent, mais il n’est pas pire non plus. Nous pouvons maintenant comparer les coefficients et voir lesquels sont réellement significatifs.
Regardons les coefficients
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Le résultat est :
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Nous pouvons clairement voir que certaines fonctionnalités ont des coefficients plus élevés par rapport à d’autres fonctionnalités et sont susceptibles d’avoir un pouvoir prédictif plus fort.
Regardons la corrélation entre différentes fonctionnalités.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
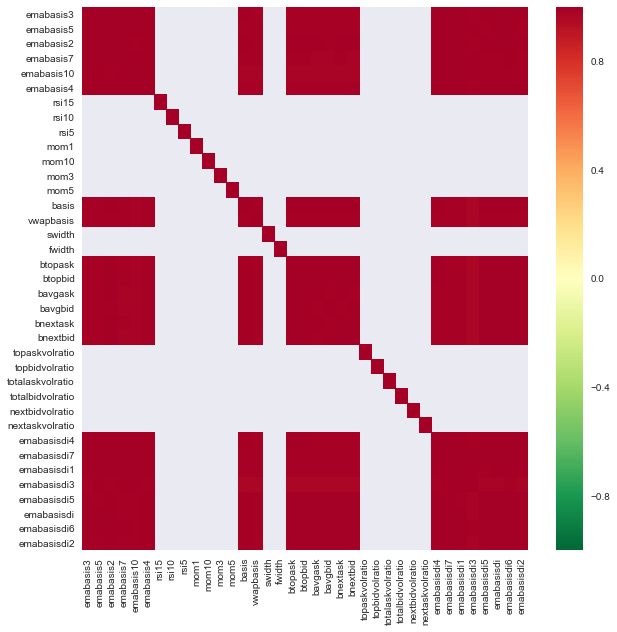
Corrélation entre les caractéristiques
Les zones rouge foncé indiquent des variables fortement corrélées. Créons/modifions à nouveau certaines fonctionnalités et essayons d’améliorer notre modèle.
Par exemple, je peux facilement ignorer des fonctionnalités comme emabasisdi7 qui ne sont que des combinaisons linéaires d’autres fonctionnalités.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
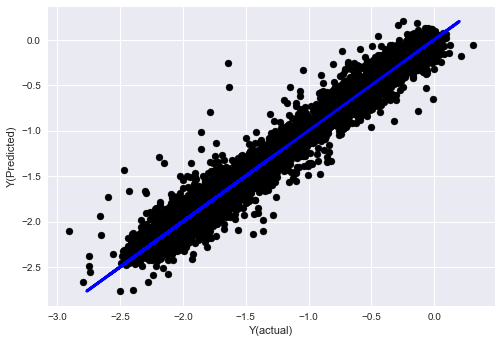
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Vous voyez, il n’y a aucun changement dans les performances de notre modèle, nous avons juste besoin de quelques fonctionnalités pour expliquer notre variable cible. Je vous suggère d’essayer davantage de fonctionnalités ci-dessus, d’essayer de nouvelles combinaisons, etc. pour voir ce qui peut améliorer notre modèle.
Nous pouvons également essayer des modèles plus complexes pour voir si des modifications apportées au modèle peuvent améliorer les performances.
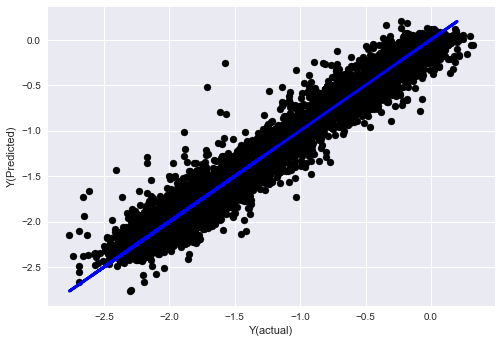
- Algorithme des K plus proches voisins (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
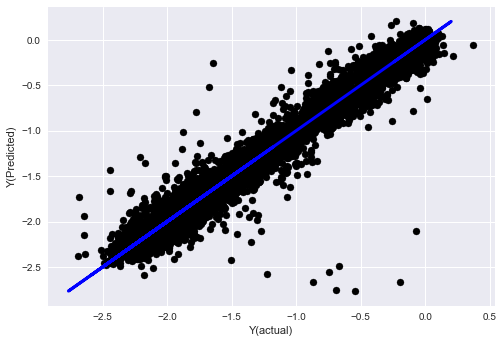
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Arbre de décision
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Étape 7 : Effectuer un backtest des données de test
Vérifier les performances sur des données d’échantillon réelles
Performances du backtest sur l’ensemble de données de test (intactes)
C’est un moment critique. Nous commençons par la dernière étape en exécutant notre modèle optimisé final sur les données de test que nous avons mises de côté au début et que nous n’avons pas encore touchées.
Cela vous fournit des attentes réalistes sur les performances de votre modèle sur des données nouvelles et inédites lorsque vous commencerez à trader en direct. Il est donc nécessaire de s’assurer que vous disposez d’un ensemble de données propre qui n’a pas été utilisé pour former ou valider le modèle.
Si vous n’aimez pas les résultats du backtest sur vos données de test, jetez le modèle et recommencez. Ne revenez jamais en arrière et ne réoptimisez jamais votre modèle, cela conduira à un surajustement ! (Il est également recommandé de créer un nouvel ensemble de données de test, car cet ensemble de données est désormais contaminé ; lorsque nous abandonnons le modèle, nous savons déjà implicitement quelque chose sur l’ensemble de données).
Ici, nous utiliserons toujours la boîte à outils d’Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
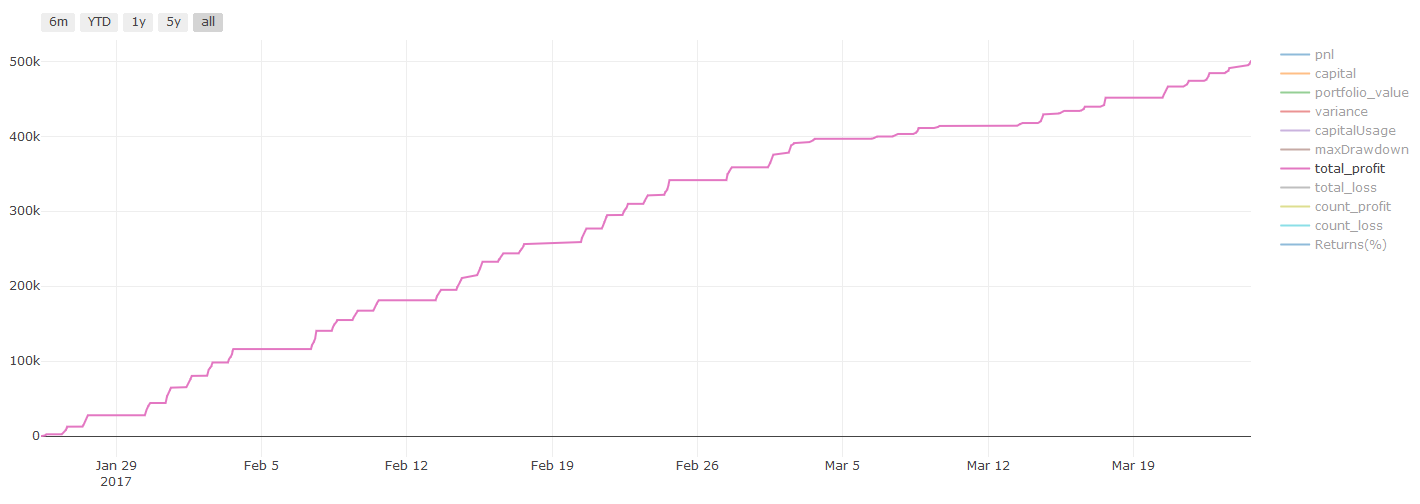
Résultats des backtests, le Pnl est calculé en dollars américains (le Pnl n’inclut pas les frais de transaction et autres frais)
Étape 8 : Autres moyens d’améliorer le modèle
Validation continue, apprentissage d’ensemble, bagging et boosting
Outre la collecte de plus de données, la création de meilleures fonctionnalités ou l’essai de plus de modèles, voici quelques éléments que vous pouvez essayer d’améliorer.
1. Vérification continue
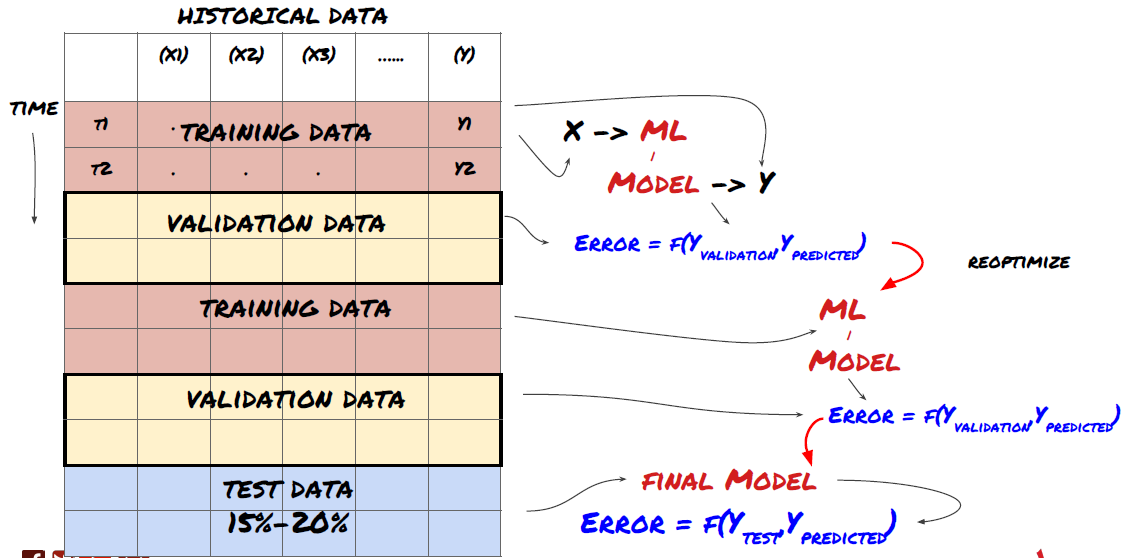
Validation continue
Les conditions du marché restent rarement constantes. Disons que vous disposez de données sur une année et que vous utilisez les données de janvier à août pour l’entraînement, et les données de septembre à décembre pour tester votre modèle. Vous pourriez vous retrouver à vous entraîner pour un ensemble très spécifique de conditions de marché. Il se peut qu’il n’y ait pas eu de volatilité sur le marché au premier semestre de l’année et que des nouvelles extrêmes aient provoqué une forte hausse du marché en septembre. Votre modèle ne sera pas en mesure d’apprendre ce modèle et vous donnera des résultats de prédiction médiocres.
Il serait peut-être préférable d’essayer de faire avancer la validation, en formant en janvier-février, en validant en mars, en recyclant en avril-mai, en validant en juin, et ainsi de suite.
2. Apprentissage d’ensemble
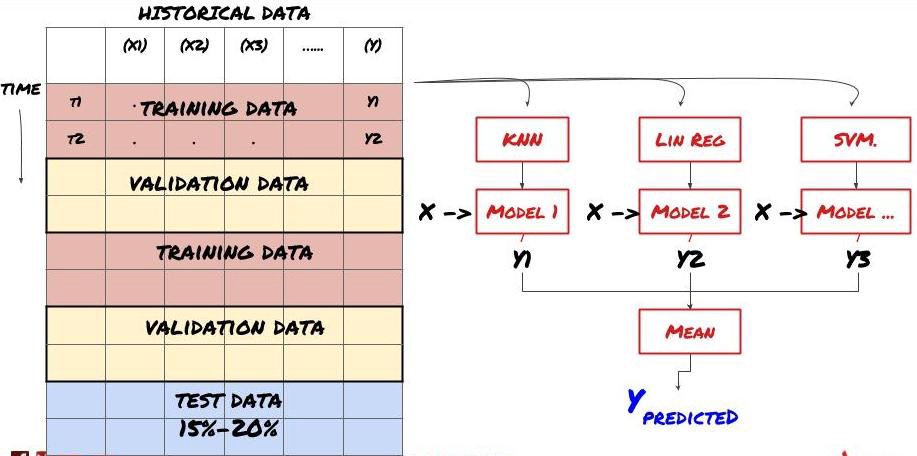
Apprentissage d’ensemble
Certains modèles peuvent bien fonctionner pour prédire certains scénarios, mais peuvent être considérablement surajustés pour prédire d’autres scénarios ou dans certaines situations. Une façon de réduire les erreurs et le surajustement est d’utiliser un ensemble de modèles différents. Votre prédiction sera la moyenne des prédictions faites par de nombreux modèles, et les erreurs des différents modèles peuvent être compensées ou réduites. Certaines méthodes d’ensemble courantes sont le Bagging et le Boosting.
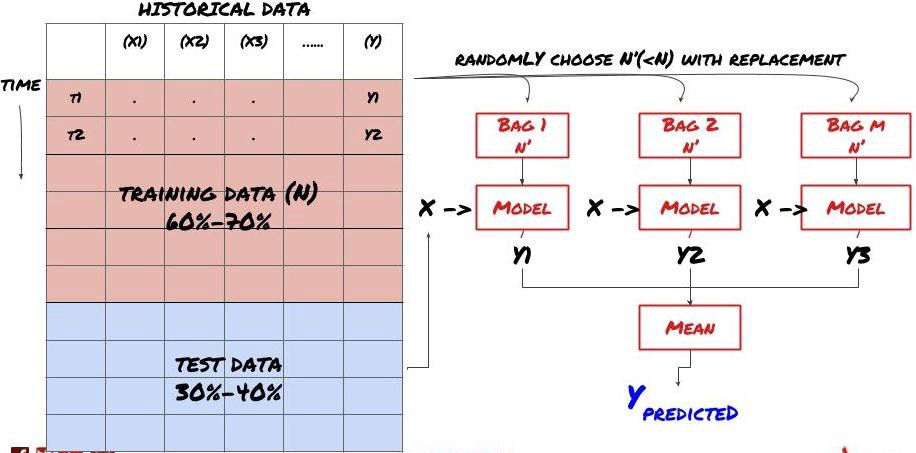
Bagging
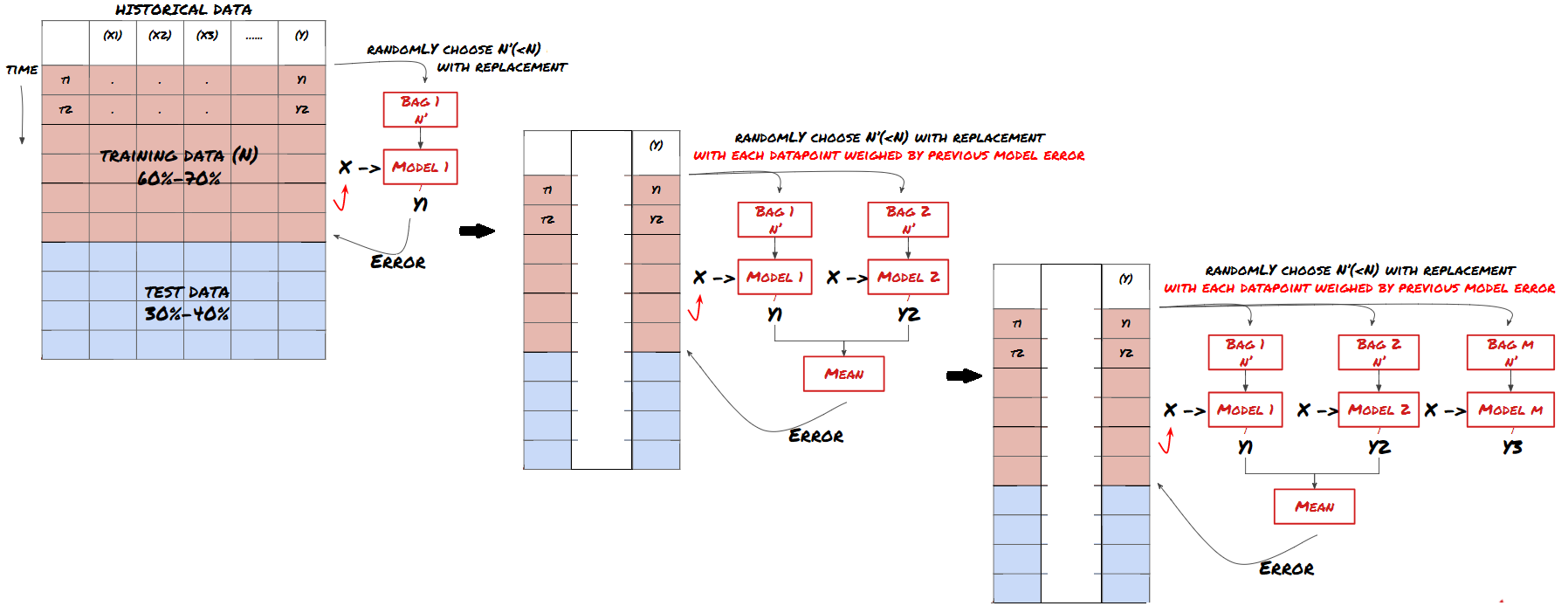
Boosting
Par souci de concision, je vais ignorer ces méthodes, mais vous pouvez trouver plus d’informations à leur sujet en ligne.
Essayons une méthode d’ensemble pour notre problème
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Nous avons accumulé beaucoup de connaissances et d’informations jusqu’à présent. Passons rapidement en revue :
Résolvez votre problème
Collecter des données fiables et nettoyer les données
Divisez les données en ensembles d’entraînement, de validation et de test
Créer des fonctionnalités et analyser leur comportement
Choisissez le modèle de formation approprié en fonction du comportement
Utilisez les données de formation pour entraîner votre modèle et faire des prédictions
Vérifiez les performances sur l’ensemble de validation et réoptimisez
Vérifier les performances finales sur l’ensemble de test
Plutôt excitant, non ? Mais ce n’est pas encore fini. Vous disposez désormais d’un modèle de prédiction fiable. Vous souvenez-vous de ce que nous voulions vraiment dans notre stratégie ? Vous n’avez donc pas encore besoin de :
Développer des signaux prédictifs basés sur des modèles pour identifier les directions de trading
Développer des stratégies spécifiques pour identifier les positions d’ouverture et de fermeture
Système d’exécution pour identifier les positions et les prix
Tout ce qui précède nécessite l’utilisation de la plateforme quantitative Inventor (FMZ.COM). Dans la plateforme quantitative Inventor, il existe une interface API hautement encapsulée et complète, ainsi que des fonctions de commande et de transaction appelables à l’échelle mondiale, vous n’avez donc pas besoin pour les connecter et les ajouter une par une. Interfaces API de différents échanges, dans le Strategy Square de la plateforme quantitative Inventor, il existe de nombreuses stratégies alternatives matures et complètes. Avec la méthode d’apprentissage automatique de cet article, votre stratégie spécifique sera plus puissante . La place stratégique est située à : https://www.fmz.com/square
Remarque importante sur les coûts de transaction:Votre modèle vous indiquera quand investir à la hausse ou à la baisse sur l’actif que vous avez choisi. Cependant, il ne prend pas en compte les frais/coûts de transaction/volume disponible/stop loss, etc. Les coûts de transaction peuvent souvent transformer une transaction rentable en une perte. Par exemple, un actif dont le prix devrait augmenter de 0,05 \( est un achat, mais si vous devez payer 0,10 \) pour effectuer cette transaction, vous vous retrouverez avec une perte nette de 0,05 $. Notre superbe graphique de bénéfices ci-dessus ressemble en fait à ceci après avoir pris en compte les commissions des courtiers, les frais de change et les spreads :
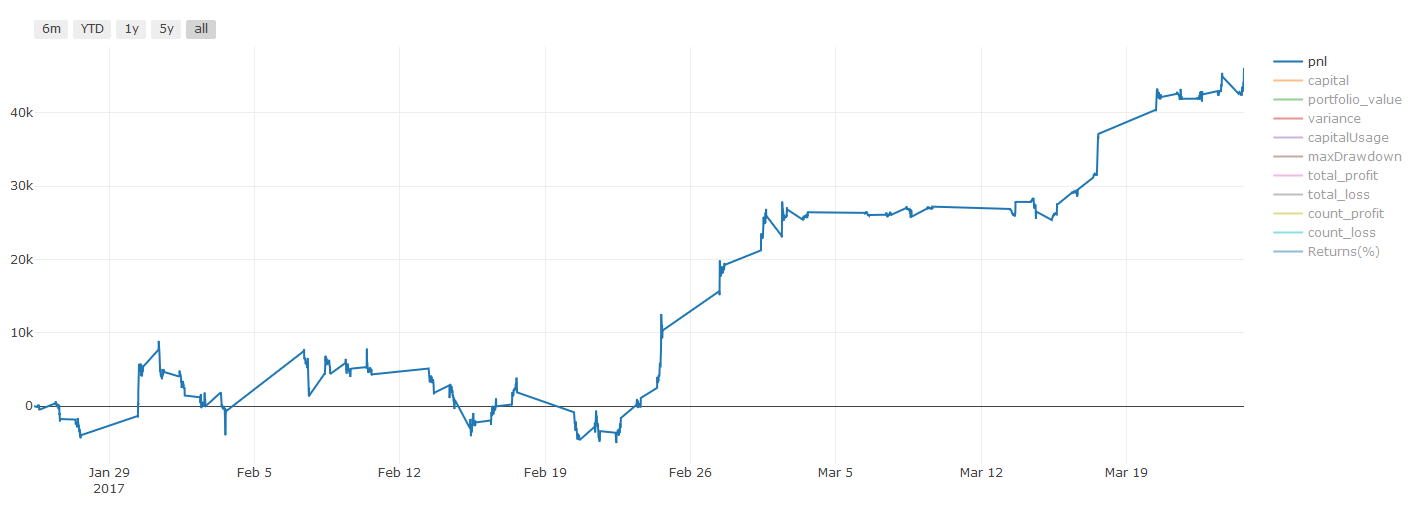
Résultats des backtests après frais de transaction et spreads, Pnl est en USD
Les frais de transaction et les spreads représentent plus de 90 % de notre Pnl ! Nous en discuterons en détail dans les articles suivants.
Enfin, examinons quelques pièges courants.
À faire et à ne pas faire
Évitez le surapprentissage par tous les moyens !
Ne réentraînez pas après chaque point de données : c’est une erreur courante que les gens font dans le développement de l’apprentissage automatique. Si votre modèle doit être réentraîné après chaque point de données, il ne s’agit probablement pas d’un très bon modèle. Autrement dit, il doit être réentraîné périodiquement, aussi souvent que cela est logique (par exemple, à la fin de chaque semaine si vous effectuez des prévisions intrajournalières).
Évitez les biais, en particulier les biais d’anticipation : c’est une autre raison pour laquelle les modèles ne fonctionnent pas. Assurez-vous de ne pas utiliser d’informations provenant du futur. La plupart du temps, cela signifie ne pas utiliser la variable cible Y comme fonctionnalité dans votre modèle. Vous pouvez l’utiliser pendant les backtests, mais il ne sera pas disponible lors de l’exécution réelle de votre modèle, ce qui rendra votre modèle inutile.
Attention aux biais d’exploration de données : puisque nous essayons d’effectuer une série de modélisations sur nos données pour déterminer si elles correspondent, s’il n’y a pas de raison particulière à cela, assurez-vous d’exécuter des tests rigoureux pour séparer les modèles aléatoires des modèles réels qui pourraient se produire. . Par exemple, une tendance à la hausse s’explique bien par une régression linéaire, mais il s’agit probablement d’une petite partie d’une marche aléatoire plus vaste !
Éviter le surapprentissage
C’est tellement important que je pense qu’il faut le mentionner à nouveau.
Le surapprentissage est le piège le plus dangereux des stratégies de trading
Un algorithme complexe peut être extrêmement performant dans le cadre de backtesting, mais échouer lamentablement sur de nouvelles données non analysées. L’algorithme ne révèle pas réellement de tendances dans les données et n’a pas de véritable pouvoir prédictif. Il est très bien adapté aux données qu’il voit
Gardez votre système aussi simple que possible. Si vous avez besoin de nombreuses fonctionnalités complexes pour expliquer vos données, vous êtes peut-être en surapprentissage.
Divisez vos données disponibles en données de formation et de test, et vérifiez toujours les performances sur des échantillons de données réels avant d’utiliser le modèle pour le trading en direct.