取引における機械学習技術の応用
作者: リン・ハーン優しさ更新日:2023年10月19日 21:02:44 更新日:2020年10月19日 21:02:44 更新日:2020年10月19日 21:02:44 更新日:2020年10月19日 21:02:44 更新日:2020年10月19日 21:02:44 更新日:2020年10月19日 21:02:44 更新日:2020年10月19日 21:02:44
この記事のインスピレーションは,発明者による量化プラットフォームのデータ研究中に,機械学習技術を取引問題に適用しようとしたときに,ある一般的な警告や罠を観察した結果です.
もし私の前の記事をまだ読んでないなら,この記事より前に,私の発明者定量化プラットフォームで構築された自動化データ研究環境のガイドと取引戦略を策定するための体系的な方法について読むことをお勧めします.
住所はこちら:https://www.fmz.com/digest-topic/4187そしてhttps://www.fmz.com/digest-topic/4169 这两篇文章.
研究環境の構築について
このチュートリアルは,あらゆるレベルのスキルを持つアマチュア,エンジニア,データサイエンティストのために設計されています.あなたが業界大手でも,プログラミングの初心者でも,必要なのは Python プログラミング言語の基本的な知識とコマンドライン操作の十分な知識です. (データサイエンスのプロジェクトを設定するには).
- インストーラー 発明者 量化管理者 アナコンダの設定
发明者量化平台FMZ.COM除了提供优质的各大主流交易所的数据源,还提供一套丰富的API接口以帮助我们在完成数据的分析后进行自动化交易。这套接口包括查询账户信息,查询各个主流交易所的高,开,低,收价格,成交量,各种常用技术分析指标等实用工具,特别是对于实际交易过程中连接各大主流交易所的公共API接口,提供了强大的技术支持。
これらの機能はすべてDockerのようなシステムに組み込まれています. クラウドサービスを購入したり,レンタルしたりして,Dockerを導入するだけです.
発明者による量化プラットフォームの公式名称では,このDockerシステムはホストシステムと呼ばれています.
管理者やロボットの配備については,私の前の記事を参照してください.https://www.fmz.com/bbs-topic/4140
クラウドサーバーの展開管理者を購入したい人は,この記事を参照してください:https://www.fmz.com/bbs-topic/2848
Pythonの最大級の神社である Anaconda をインストールします. これは,Python の最大級の神社である Anaconda をインストールします.
本文に必要なすべての関連するプログラム環境 (依存庫,バージョン管理など) を実現するには,最も簡単な方法はAnacondaです.これはパッケージ化されたPythonデータサイエンスのエコシステムであり,依存庫管理者です.
Anacondaは,クラウド上のサービスにインストールされているため,Linuxシステムに Anacondaのコマンドラインバージョンをクラウドサーバーにインストールすることをお勧めします.
アナコンダのインストール方法については,Anacondaの公式ガイドを参照してください.https://www.anaconda.com/distribution/
経験豊富なPythonプログラマーで,Anacondaを使用する必要がないと感じている場合,それはまったく問題ありません. 必要な依存環境をインストールする際に助けを必要としていないと仮定すると,このセクションを直接スキップできます.
取引戦略を策定する
取引戦略の最終的な出力は,以下の質問に答えなければならない.
方向性:資産が安価,高価,または価値の公平かどうかを決定する.
开仓条件:如果资产价格便宜或者昂贵,你应该做多或者做空.
平衡取引:資産の価格が合理的で,当社がその資産に所持している場合 (前回の購入または売却) は平衡すべきか
価格範囲:開設取引を行う価格 (または範囲)
量:取引資金の量 (デジタル通貨の数や商品先物手数など)
機械学習は上記の質問のそれぞれに答えることができますが,この記事の残りの部分では,最初の質問,つまり取引の方向性,に焦点を当てます.
戦略的方法
戦略構築には,モデルベースの方法と,データベースの挖掘の2つのタイプがあります. これらは基本的に対照的な方法です.
モデルベースの戦略構築では,市場低効率モデルから始め,数学式 (例えば価格,利益) を構築し,より長い時間周期でその有効性をテストする.このモデルは通常,より複雑なモデルの簡略化されたバージョンであり,その長期周期の意味と安定性を検証する必要がある.通常,傾向が続くため,均等値帰還と利息戦略はこのカテゴリーに属します.
一方,私たちはまず価格パターンを探して,データ挖掘方法でアルゴリズムを使用しようとします. これらのパターンの原因は重要ではなく,特定のパターンだけが将来的に繰り返されるからです. これは盲目分析方法であり,ランダムなパターンから真のパターンを識別するために厳格に検査する必要があります.
明らかに,機械学習はデータマイニング方法に簡単に適用できます. では,機械学習を使用してデータマイニングで取引信号を作成する方法を見てみましょう.
コード例は,発明者による量化プラットフォームに基づく復習ツールと自動取引APIインターフェースを使用します.上記セクションでホストを展開し,Anacondaをインストールした後,必要なデータ科学分析庫と有名な機械学習モデルscikit-learnをインストールするだけです.このセクションの内容については,これ以上述べません.
pip install -U scikit-learn
機械学習を使って取引戦略信号を作成する
- データ採掘
機械学習の標準的な問題システムは,
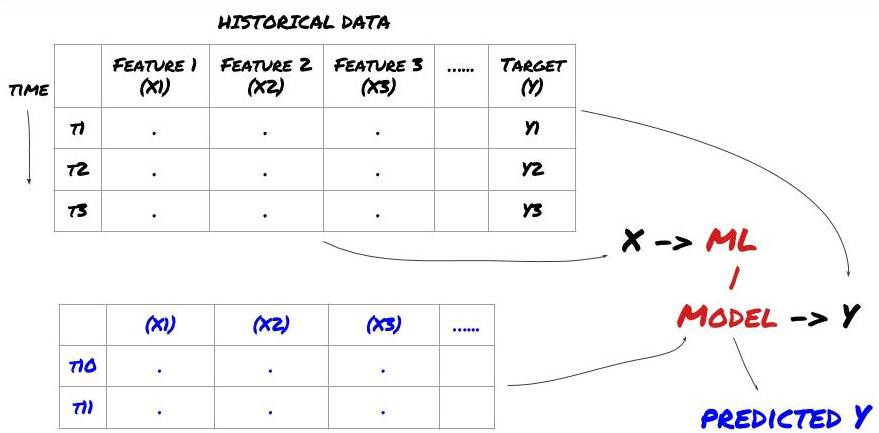
機械学習の問題システム
私たちが作成する特性は,何らかの予測能力を持つ必要があります (x),我々は目標変数 (y) を予測したい,そして歴史データを使用して,実際の値にできるだけ近いYを予測できるMLモデルを訓練します. 最後に,このモデルを使用して,未知のYに対する新しいデータを予測します. これはステップ1に導きます:
"つ目のステップは 問題を設定する"
- 予想したいことは何ですか? 良い予測とは何か? 予想結果をどう評価しますか?
このフレームワークでは,yは何ですか?
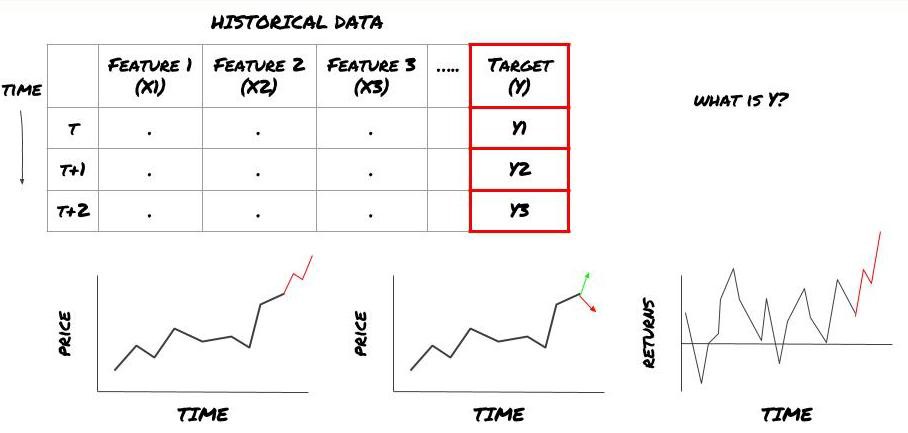
予想したいことは何ですか?
将来の価格,将来のリターン/Pnl,買い/売るシグナル,ポートフォリオの配分を最適化し,取引の効率的な実行を試みたいですか?
次の時間軸で価格を予測しようとします. この場合,Y (t) =価格 (t + 1) です.
注意 Y (t) は回帰でのみ知られていますが,我々のモデルを使うとき,我々は時間 t の価格 (t + 1) を知りません.我々は我々のモデルを使って予測 Y (t) を予測し,それを時間 t + 1 でのみ実際の値と比較します.これは,あなたが Y を予測モデルの特性として使用できないことを意味します.
目標Yが分かれば,予測の評価方法も決定できる.これは,我々が試すデータの異なるモデルを区別するのに非常に重要です.我々が解決している問題に応じて,モデル効率を測定する指標を選択します.例えば,価格を予測する場合は,均等根差を指標として使用できます.一般的な指標 (平均線,MACD,差分数など) のいくつかは,発明者の定量化ツールキットにプリコードされており,APIインターフェイスでグローバルに呼び出すことができます.
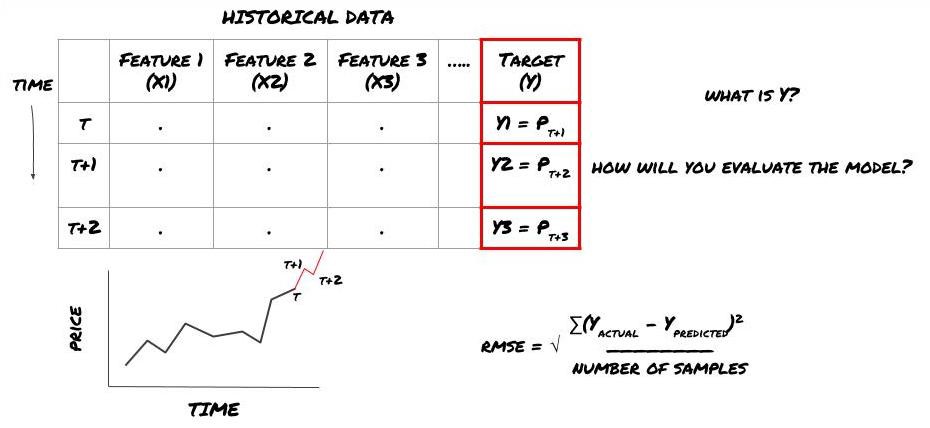
将来の価格を予測するためのMLフレームワーク
演示のために,予測モデルを作成し,仮定された投資指標の将来の期待基準 (basis) の値を予測します.
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
この回帰問題であるため,RMSE (均等根誤差) でモデルを評価します.また,評価基準としてTotal Pnlを使用します.
注:RMSEに関する数学知識については,百科事典の関連記事を参照してください.
- 我们的目标:创建一个模型,使预测值尽可能接近Y.
2つ目のステップ:信頼できるデータ収集
データを収集し,整理することで,問題解決に役立ちます.
目標変数Yについて,どのようなデータが予測可能かを考える必要があります.価格を予測する場合は,投資指数の価格データ,投資指数の取引量データ,関連投資指数の類似データ,投資指数の指数の平衡度,他の関連資産の価格などを使用できます.
このデータに対してデータアクセス権限を設定し,あなたのデータが正確で間違いないことを確認し,失われたデータ ("非常に一般的な問題") を解決する必要があります.同時に,あなたのデータが偏見なく,すべての市場条件を十分に代表していることを確認します (例えば,同じ数の損失と利益のシナリオ) モデルに偏差が生じないようにします.また,あなたが分散,投資指数の分割,連続等を得るためにデータをクリアする必要があるかもしれません.
FMZ.COMを利用している場合は,Google,Yahoo,NSE,Quandlからの無料のグローバルデータ,CTPやEasyJetなどの国内商品フューチャーに関する深層データ,Binance,OKEX,Huobi,BitMexなどの主流デジタル通貨取引所のデータにアクセスできます.また,InventorQuantification Platformは,投資指数の分割や深層行情データなどのデータを事前にクリアし,フィルタリングし,定量化作業者が容易に理解できる形式で戦略開発者に提示します.
この文のデモを簡単にするために,次のデータを仮想投資指標の
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
上記のコードで,Auquan
ステップ3:データを分割する
- データからトレーニングセットを作成し,それをクロス検証し,テストします.
海外のメディアは,この事件について,進める前に,データをトレーニングデータセットに分割してモデルを訓練し,テストデータセットをモデル性能を評価する. 60~70%のトレーニングデータセットと 30-40%のテストデータセットに分割することをお勧めします.
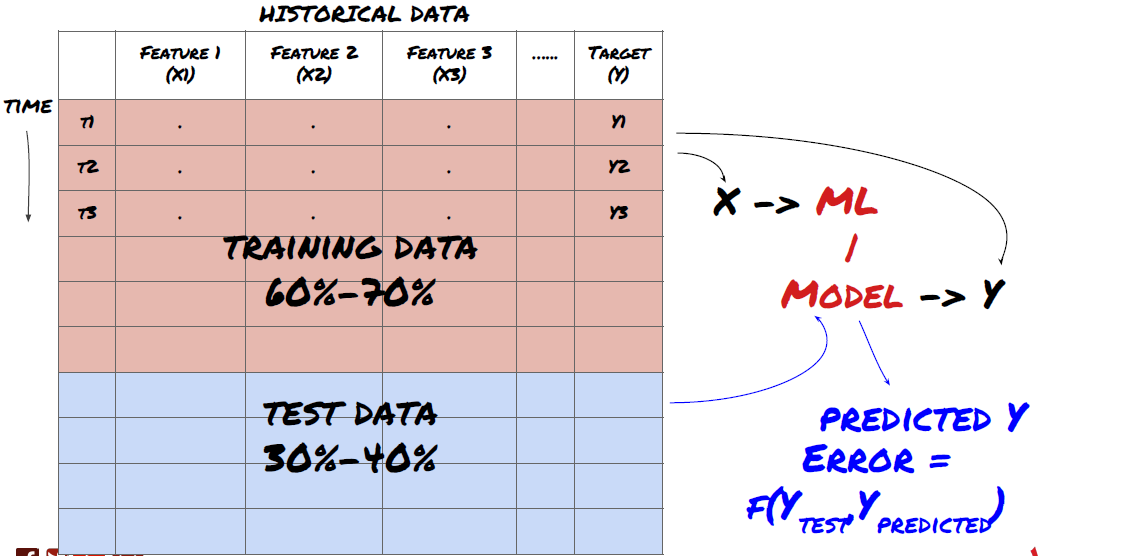
データをトレーニングセットとテストセットに分割します
訓練データはモデルのパラメータを評価するために使用されるため,あなたのモデルはこれらの訓練データに過剰に適合し,訓練データはモデルの性能を誤導する可能性があります. あなたが個々のテストデータを持っておらず,すべてのデータを訓練するために使用しなければ,あなたのモデルは新しい目に見えないデータに対してどの程度良いか悪いかを知らないでしょう. これは,訓練されたMLモデルはリアルタイムデータで失敗する主な理由の一つです. 人々は利用可能なすべてのデータを訓練し,訓練されたデータ指標に興奮しますが,モデルは未訓練のリアルタイムデータに対して意味のある予測を行うことができません.
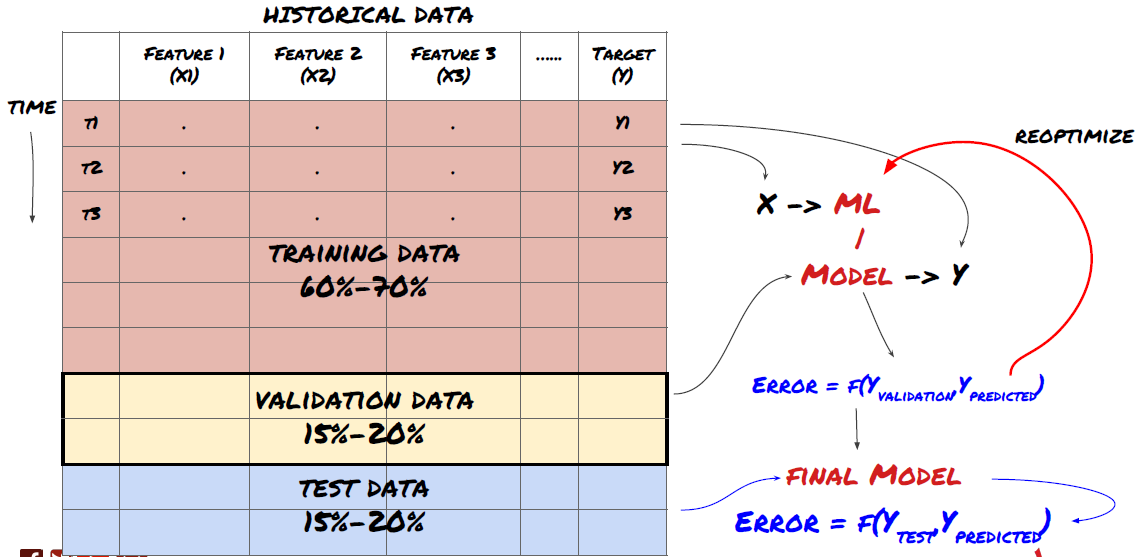
データをトレーニングセット,検証セット,テストセットに分けます
この方法には問題がある.もし私たちがトレーニングデータに繰り返しトレーニングし,テストデータの性能を評価し,パフォーマンスに満足するまでモデルを最適化するならば,テストデータを訓練データの一部として含んでいる.最終的には,私たちのモデルはこのトレーニングとテストデータセットにうまく機能するかもしれませんが,新しいデータをうまく予測する保証はありません.
この問題を解決するために,私たちは別の検証データセットを作成できます. 現在,あなたはデータを訓練し,検証データの性能を評価し,性能に満足するまで最適化し,最後にテストデータをテストすることができます. これにより,テストデータは汚染されることはありません.
テストデータの性能を検証した後に,モデルをさらに最適化しようと考えることを忘れないでください. モデルがうまく機能していないことを発見した場合,モデルを完全に捨て,再起動してください. 60%のトレーニングデータ,20%の検証データ,20%のテストデータに分割することが推奨されています.
テストセットとして使用します. テストセットとして使用します. テストセットとして使用します.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
目標変数Yを加えると,次の5つのベース値の平均値になります.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
ステップ4 特徴工学
データの行動を分析し,予測可能な特性を作成する
真の工学が構築されるようになった. 特徴選択の黄金律は,予測能力がモデルではなく特徴から得られるということです. 特徴選択がモデル選択よりもはるかに性能に影響を与えることがわかります. 特徴選択の注意点:
目標変数との関係性をまだ探していない限り, 随意に多くの特性を選択しないでください.
目標変数とほとんど関係していない場合,過度に適合することがあります.
選択した特徴は互いに高度に関連している可能性があり,この場合,少数特性が目標を説明することもできます.
目標変数とそれらの特性の関連性,そしてそれらの間の関連性を見て,どの特性を使うかを決定します.
また,最大情報系数 (MIC) による候補特性の順序付け,主成分分析 (PCA) や他の方法も試すことができます.
特徴転換/規范化:
MLモデルは標準化に関してよく機能する.しかし,タイムシーケンスデータを処理するとき,標準化は難しい.将来のデータ範囲は不明である.あなたのデータは標準化範囲を超え,モデルエラーを引き起こす可能性があります.しかし,あなたはまだ一定の平坦性を強制しようとすることができます:
スケール:標準差または四桁の範囲で特徴を区切る
住所:現在の値から歴史的な平均を引く
統一:上記 ((x - mean) /stdev の2つの回帰期
常規アトラクション: 回帰期 ((x-min) / ((max-min)) でデータを-1から+1の範囲に標準化し,中心を再定義する
注目すべきは,過去連続平均値,標準偏差,最大値,最小値を回帰期を超えて使用しているため,特性の統一標準値が異なる時点での異なる実際の値を表す.例えば,特性の現在の値が5である場合,連続30サイクル平均値が4.5である場合,中間値が0.5に変換される.その後,連続30サイクル平均値が3になった場合,値は3.5に変換される.これはモデルエラーの原因となる可能性があります.したがって,規范化は難しいので,実際にモデルのパフォーマンスを改善したものを (もしあるならば) 解明する必要があります.
複合参数を使って多くの特性を作成しました.後で,特性の数を減らすことができるか試してみます.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
ステップ5:モデルを選択する
選択された問題に基づいて適切な統計/MLモデルを選択する
モデルの選択は,問題の構成方法によって決まる.あなたは監視 (特性のマトリックス内の各点Xが目標変数Yにマッピングされる) を解決しているか,監視なしの学習 (マッピングが与えられず,モデルは未知のパターンを学習しようとしている) を解決しているか?あなたは回帰 (将来の実際の価格を予測する) を解決しているか,分類の問題 (将来の価格の方向を予測するのみ) を解決しているか (増加/減少) を解決しているか.

監督または無監督の学習

回帰 or 分類
監視学習アルゴリズムは,以下のように簡単に説明できます.
線形回帰 (参数,回帰)
ロジスティック回帰 (パラメータ,分類)
K近隣 (KNN) アルゴリズム (例に基づく回帰)
SVM,SVR (参数,分類,回帰)
意思決定の木
意思決定の森
私は,線形または論理回帰のような単純なモデルから始め,必要に応じてより複雑なモデルをそこから構築することをお勧めします.また,盲目的にブラックボックスとして使用するのではなく,モデルの背後にある数学を読むことをお勧めします.
ステップ6:訓練,検証,最適化 (ステップ4〜6を繰り返す)
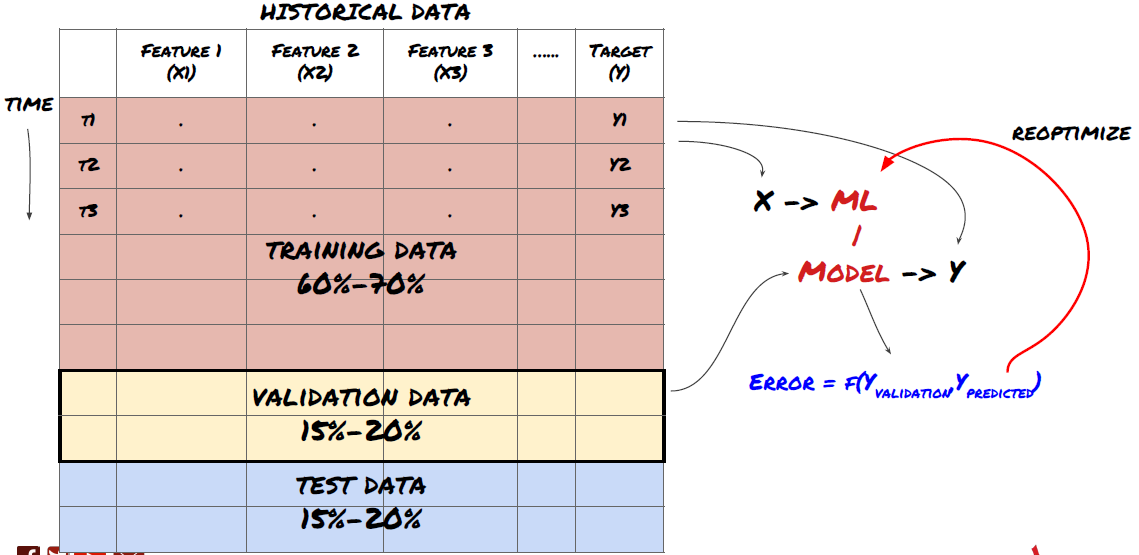
訓練と検証データセットを使って モデルを訓練し最適化します
この段階では,あなたは本当にモデルとモデルのパラメータを繰り返すだけです. 訓練データでモデルを訓練し,検証データでそのパフォーマンスを測定し,それから戻り,最適化,再訓練,評価します. モデルのパフォーマンスに満足していない場合は,他のモデルを試してみてください.
モデルが気に入ったら,次のステップに移ります.
簡単な線形回帰から始めましょう.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
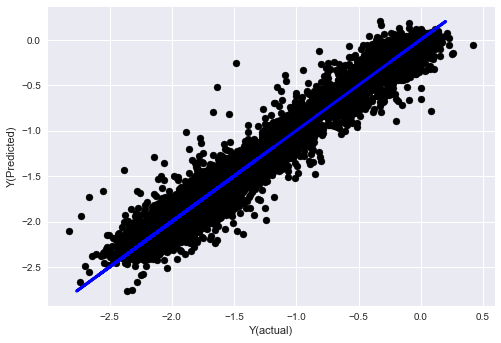
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
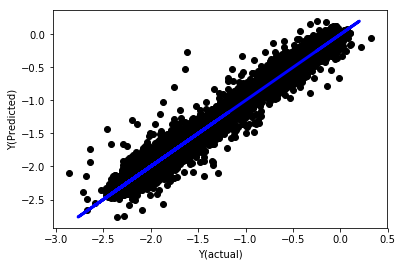
統一されていない線形回帰
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
モデル系数を見てください. どれも異なるスケールに属しているので,それらを本当に比較したり,どれが重要かと言うことはできません. 均等な比例に合わせて,平衡を強制するために,それらを統一してみましょう.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
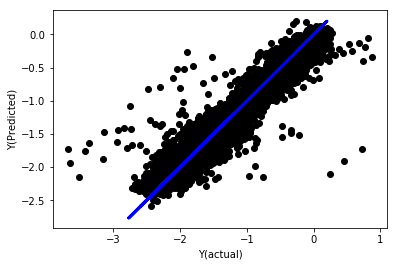
統合の線形回帰
Mean squared error: 0.05
Variance score: 0.90
このモデルは以前のモデルを改良したわけではないが,さらに悪化したわけではない.現在,実際に系数を比較して,実際に重要な系数がどれか見ることができる.
この2つの因数で,
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
答えはこうです.
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
ある特性が他の特性よりも高い系数を持ち,より強い予測力を持つ可能性があることがはっきりとわかります.
異なる特徴の関連性を見てみましょう.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
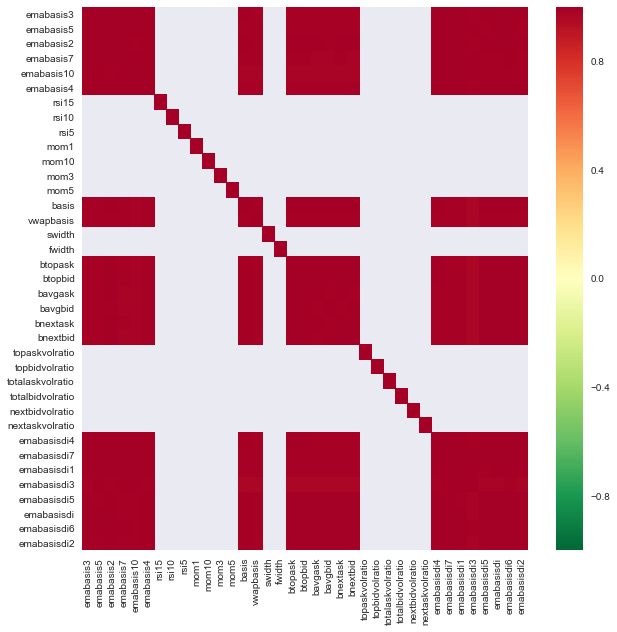
特徴の関連性
濃い赤色の領域は高度に関連している変数を表しています. また,いくつかの特性を作成/変更して,モデルを改良してみましょう.
例如,我可以轻松地丢弃像emabasisdi7这样的特征,这些特征只是其他特征的线性组合.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
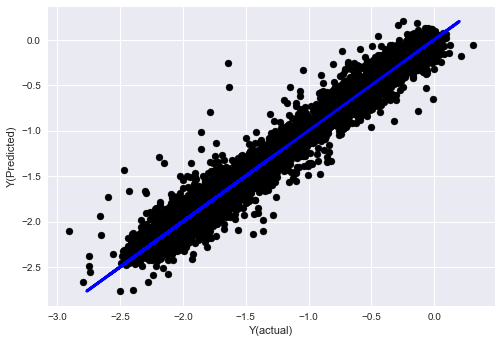
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
私たちのモデル性能は変わっていないので,目標変数を説明する特性がいくつか必要です. 上記の特性をさらに試してみて,新しい組み合わせを試してみて,モデルを改善できるものを見ることをお勧めします.
我们还可以尝试更复杂的模型,看看模型的变化是否可以提高性能.
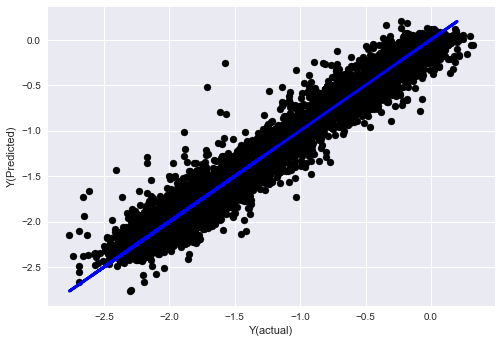
- K近隣 (KNN) アルゴリズム
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
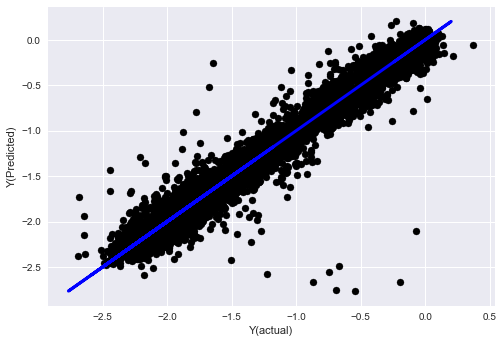
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- 意思決定の木
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
ステップ7 テストデータを再テストする
実際のサンプルデータの性能を検証する
(未触れた) テストデータセットにおける回測性能
テストデータの最後のステップから最終的な最適化モデルを実行し,最初からそれを脇に置いて,これまで触れていないデータから始めます.
これは,あなたがリアルタイムで取引を始めるとき,新しいデータと未知のデータに対して,あなたのモデルはどのように実行するかについての現実的な期待を与えます.したがって,訓練または検証モデルに使用されていないクリーンなデータセットを持っていることを確認することが重要です.
テストデータの復習結果が気に入らない場合は,モデルを捨てて再起動してください. モデルを再最適化するために戻らないでください,これは過剰な適合につながるでしょう! (また,新しいテストデータセットを作成することもお勧めします.このデータセットは,現在汚染されているため,モデルを捨てるときには,そのデータセットの内容が暗示的に知られています).
オークアン
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
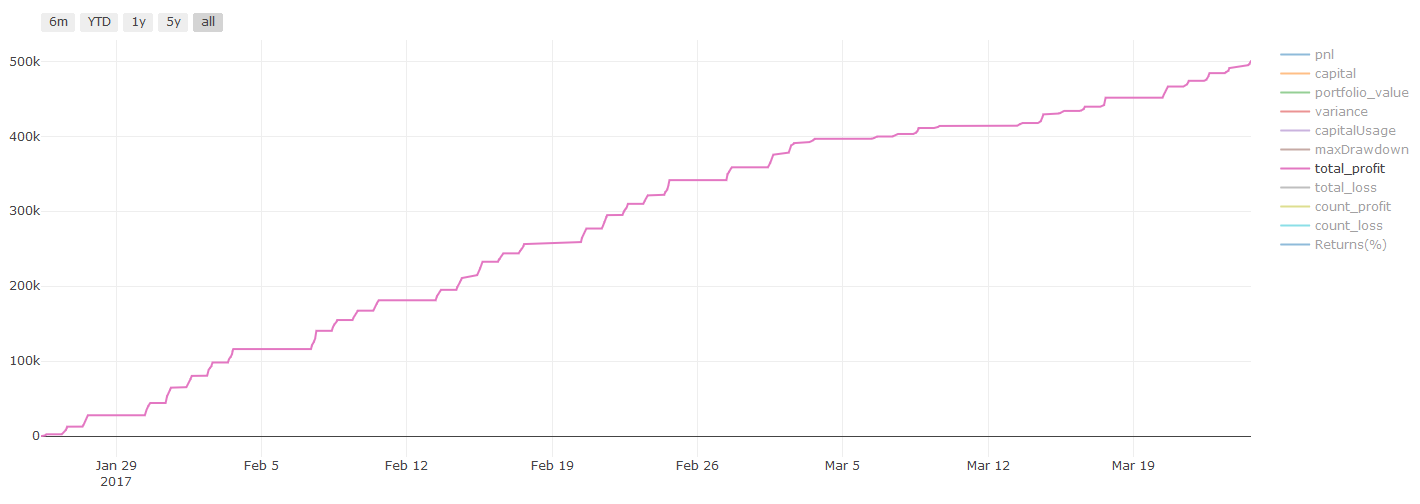
Pnl は,取引コストおよびその他の費用を考慮しない.
ステップ8 モデルを改良する他の方法
ロールチェック,集団学習,バッグ,ブーシング
より多くのデータを収集したり,より優れた機能を作成したり,より多くのモデルを試したりする以外に,改善を試みることができるいくつかの点があります.
1. ロール認証
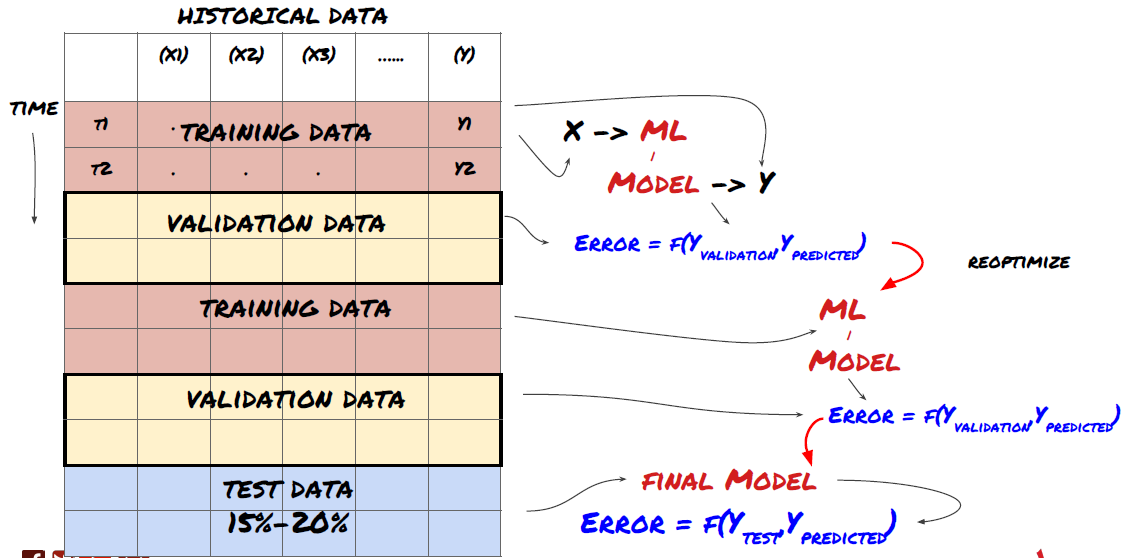
ローラー認証
市場情勢はほとんど変わらない. 例えば,1年分のデータを持っていて,1月から8月のデータを使って訓練し,9月から12月のデータを使ってモデルをテストすると,非常に具体的な市場情勢のセットに対して訓練をすることになりかねない.
先進的なロール検証を試みる方が良いかもしれません. 1月から2月の訓練,3月の検証,4月から5月の再訓練,6月の検証など.
2.集団学習
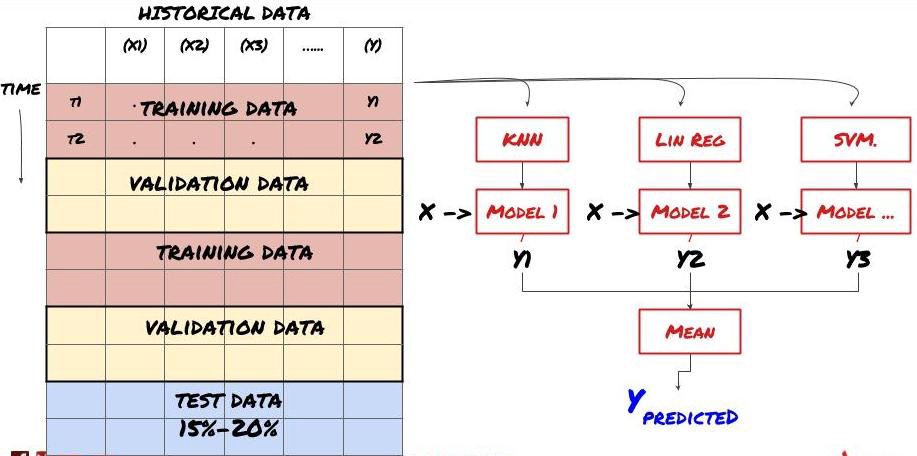
集団学習
あるモデルが特定のシナリオを予測する際にうまく機能する可能性があるが,他のシナリオを予測する際に,またはある状況においてモデルが極端に過剰に適合する可能性がある.誤差と過剰な適合を減らす方法の一つは,異なるモデルの集合を使用することである.あなたの予測は,多くのモデルが予測する平均値であり,異なるモデルの誤差が抵消または減少する可能性があります.一般的な集合方法のいくつかは,バッシングとブーシングである.
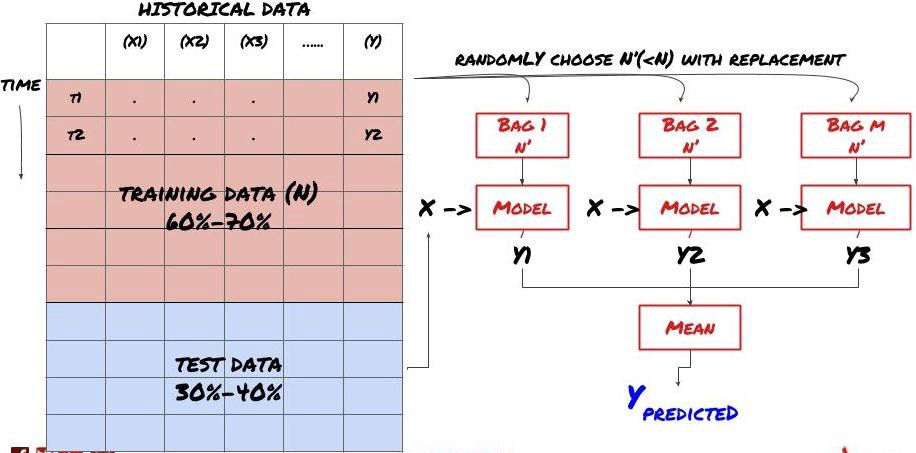
バッグ
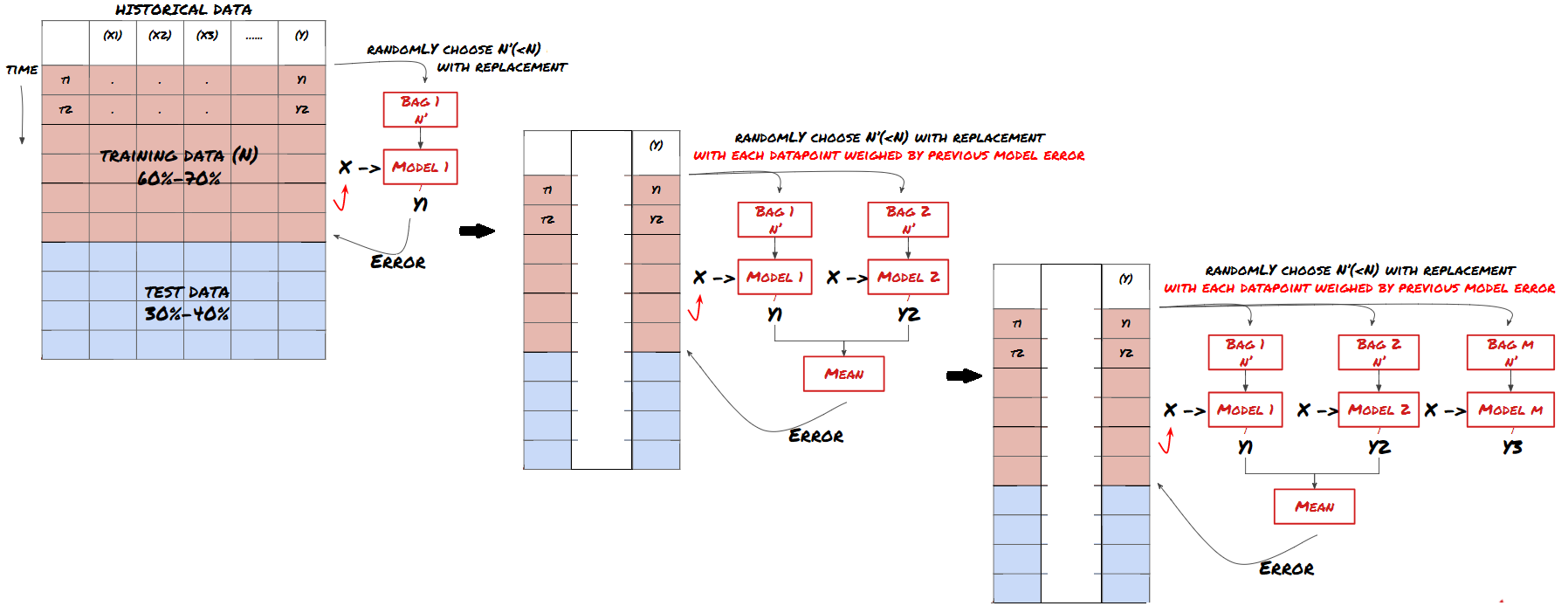
刺激する
簡単に説明するために,これらの方法を省略しますが,オンラインでもっと詳しく調べてください.
集合の方法を使ってみましょう.
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
この記事へのトラックバック一覧です: 海外の情報: 海外の情報: 海外の情報
問題を解決する
信頼性の高いデータ収集とデータ清掃
データをトレーニング,検証,テストセットに分割します
特徴を作り,その行動を分析する
行動に基づく適切なトレーニングモデル
訓練データを使ってモデルを訓練し 予測します
チェックセットのパフォーマンスをチェックし,再最適化します
テストセットの最終性能を検証する
信頼性の高い予測モデルしか持っていない.我々の戦略に本当に必要なことは覚えてますか? だからあなたはまだ必要ありません.
予測モデルに基づくシグナルを開発し,取引の方向性を識別する
取引先を特定するための具体的な戦略を開発
ポジションと価格を識別するための実行システム
FMZ.COMでは,高度なパッケージ化と完善されたAPIインターフェース,およびグローバルに呼び出すことができる下記の注文と取引関数,あなたが個別に結合し,異なる取引所を追加するAPIインターフェースを必要とせず,発明者定量化プラットフォームの戦略広場には,多くの成熟した完全なオプション戦略があります.https://www.fmz.com/square
取引コストに関する重要な説明:你的模型会告诉你所选资产何时是做多或做空。然而,它没有考虑费用/交易成本/可用交易量/止损等。交易成本通常会使有利可图的交易成为亏损。例如,预期价格上涨0.05美元的资产是买入,但如果你必须支付0.10美元进行此交易,你将最终获得净亏损$0.05。在你考虑经纪人佣金,交换费和点差后,我们上面看起来很棒的盈利图实际上是这样的:
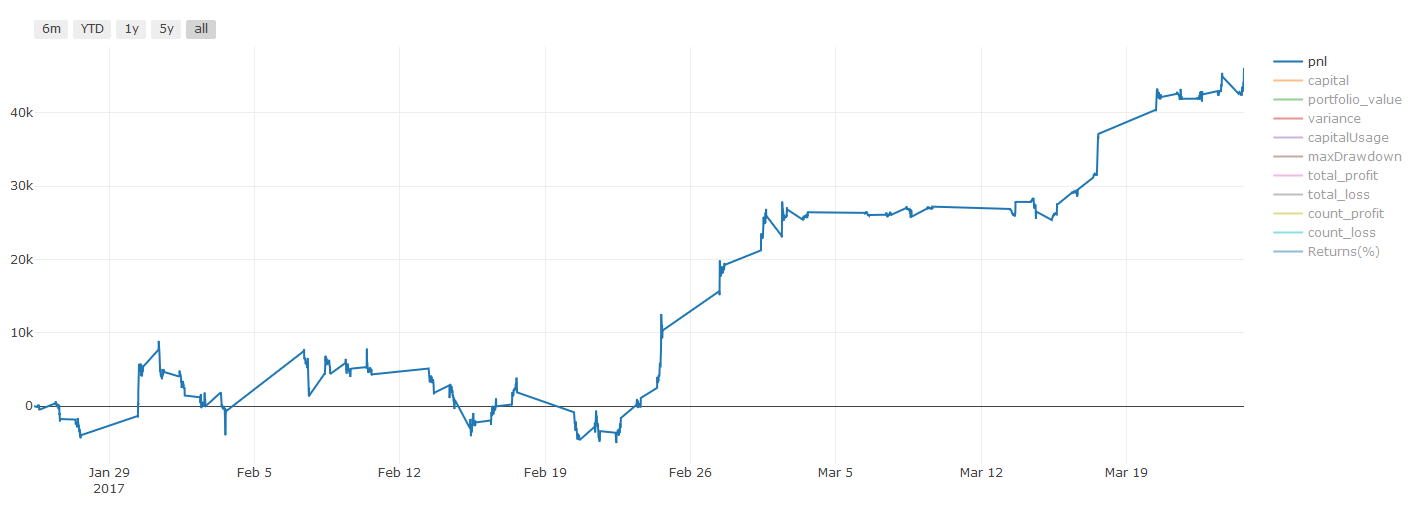
Pnl はドルで計算されます.
取引手数料と差額は,Pnlの90%以上を占めています.これについては,次の記事で詳しく説明します.
この記事の記事へのトラックバック一覧です.
何をするべきか,何をするべきか
超適合を尽力して避ける!
データポイントごとに再訓練しないでください:これは機械学習開発でよくある間違いです. あなたのモデルがデータポイントごとに再訓練する必要がある場合,それは非常に良いモデルではない可能性があります.つまり,定期的に再訓練が必要であり,合理的な頻度でしか訓練する必要はありません (例えば,日中の予測を行う場合,週末に再訓練します)
偏差,特に前向きの偏差を避ける:これはモデルが機能しないもう一つの理由であり,将来に関する情報を一切使っていないことを確認する.ほとんどの場合,これはモデル内の特徴として目標変数Yを使用しないことを意味します.レグロテスト中にそれを使用できますが,実際にモデルを実行するときに使用できないので,あなたのモデルが使えなくなります.
データ挖掘偏差注意:当社は,私たちのデータに対して一連のモデリングを試みているため,それが適しているかどうかを確認するために,特別な理由がない場合は,ランダムなパターンを実際に起こる可能性のあるパターンから分離するために厳格なテストを実行することを確認してください.例えば,線形回帰は上向きのパターンをよく説明し,それだけで大きなランダムな移動の一部になる可能性があります!
オーバーフィットメントを避ける
この記事へのトラックバック一覧です.
過剰な適合は取引戦略の最も危険な罠です
複雑なアルゴリズムは反復で非常にうまく機能するかもしれませんが,目に見えない新しいデータで失敗します.このアルゴリズムはデータにどんな傾向も明らかにせず,実際の予測能力も持っていません.それはそれに見たデータに非常に適しています.
データを解釈するために多くの複雑な機能が必要だと気づけば,あなたは過剰に適合している可能性があります.
利用可能なデータをトレーニングデータとテストデータに分割し,モデルを使ってリアルタイム取引をする前に,常に実際のサンプルデータの性能を検証します.
- DEX取引所の定量実践 (2) -- ハイパーリキッドユーザーガイド
- DEX取引所の量化実践 (2) -- Hyperliquidの使用ガイド
- DEX取引所の定量実践 (1) -- dYdX v4 ユーザーガイド
- 暗号通貨におけるリード・レイグ・アービトラージへの導入 (3)
- DEX取引所の量化実践 ((1)-- dYdX v4 ユーザーガイド
- デジタル通貨におけるリード-ラグ套路の紹介 (3)
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (2)
- デジタル通貨におけるリード-ラグ套路の紹介 (2)
- FMZプラットフォームの外部信号受信に関する議論: 戦略におけるHttpサービス内蔵の信号受信のための完全なソリューション
- FMZプラットフォームの外部信号受信に関する探求:戦略内蔵Httpサービス信号受信の完全な方案
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (1)
- ウェブソケットにシームレス接続する 古い戦略のインターフェースを教えます
- 多レベル 利得率戦略
- コモディティフューチャーとデジタル通貨取引所のAPIの違い
- 取引戦略におけるK線影部分の適用
- クリプト通貨の量的な取引戦略の交換構成
- 高頻度戦略バックテストのために開発された Tick レベルトランザクションマッチングメカニズム
- 取引戦略開発経験
- 定量取引におけるK線データ処理
- デジタル通貨量化取引戦略 取引所の配置詳細
- "OKEXの先物取引のヘッジ戦略のC++バージョン"で 硬い定量戦略を紹介します
- "C++版 OKEXの契約ヘッジ戦略"
- 秩序ある排列の多空の均衡権益戦略を実現
- データ駆動技術によるペア取引
- デジタル通貨市場を量的に分析する
- Pythonで Dual Thrust デジタル通貨の量化取引戦略を実装する
- プログラム化取引におけるK線データ処理の浅谈
- Pythonで価格動力分析を実現する量的な取引戦略
- タイムシーケンスデータ分析とTickデータ復習
- 取引戦略開発の体験談
- DMI指標の計算と適用
片足で知ることありがとうございました.
コングコン009素晴らしい記事,アイデア,そして初心者向けの要約
ラララデマキシア暴力を振るう!