트레이딩에 머신러닝 기술의 적용
 3
3072
3
3072

이 글은 Inventor Quant 플랫폼에서 데이터를 조사하는 동안 거래 문제에 머신 러닝 기법을 적용해 보고 몇 가지 흔한 경고와 함정을 관찰한 데서 영감을 받아 작성되었습니다.
이전 기사를 읽지 않으셨다면 이 기사보다 먼저 Inventor Quantitative Platform에 구축된 자동화된 데이터 연구 환경과 거래 전략 개발을 위한 체계적인 접근 방식에 대한 이전 가이드를 읽어보시기를 권장합니다.
주소는 다음과 같습니다: https://www.fmz.com/digest-topic/4187 및 https://www.fmz.com/digest-topic/4169.
연구환경 구축에 관하여
이 튜토리얼은 모든 기술 수준의 매니아, 엔지니어, 데이터 과학자를 위해 설계되었습니다. 업계 전문가이든 프로그래밍 초보자이든 필요한 기술은 Python 프로그래밍 언어에 대한 기본적인 이해와 명령줄 작업에 대한 충분한 지식뿐입니다. (데이터 과학 프로젝트를 설정할 수 있는 능력이면 충분합니다)
- Inventor Quant Hoster 설치 및 Anaconda 설정
Inventor Quantitative Platform FMZ.COM은 주요 거래소의 고품질 데이터 소스를 제공할 뿐만 아니라, 데이터 분석을 완료한 후 자동화된 거래를 수행하는 데 도움이 되는 풍부한 API 인터페이스 세트도 제공합니다. 이 인터페이스 세트에는 계정 정보 쿼리, 최고가, 시가, 최저가, 종가, 거래량, 다양한 주요 거래소의 일반적으로 사용되는 다양한 기술 분석 지표 쿼리 등과 같은 실용적인 도구가 포함되어 있으며, 특히 실제 주요 거래소에 연결하기 위한 것입니다. 거래 프로세스. 공개 API 인터페이스는 강력한 기술 지원을 제공합니다.
위에 언급된 모든 기능은 Docker와 유사한 시스템에 캡슐화되어 있습니다. 우리가 해야 할 일은 자체 클라우드 컴퓨팅 서비스를 구매하거나 임대하고 Docker 시스템을 배포하는 것뿐입니다.
Inventor Quantitative Platform의 공식 명칭에서는 이 Docker 시스템을 호스트 시스템이라고 합니다.
호스트와 로봇을 배치하는 방법에 대한 자세한 내용은 이전 기사를 참조하세요: https://www.fmz.com/bbs-topic/4140
자체 클라우드 컴퓨팅 서버 배포 호스트를 구매하려는 독자는 이 기사를 참조하세요: https://www.fmz.com/bbs-topic/2848
클라우드 컴퓨팅 서비스와 호스트 시스템을 성공적으로 배포한 후 가장 강력한 Python 도구인 Anaconda를 설치합니다.
이 문서에 필요한 모든 관련 프로그램 환경(종속 라이브러리, 버전 관리 등)을 구현하기 위한 가장 쉬운 방법은 Anaconda를 사용하는 것입니다. 이는 패키지된 Python 데이터 과학 생태계 및 종속성 관리자입니다.
클라우드 서비스에 Anaconda를 설치하므로 클라우드 서버에 Linux 시스템과 Anaconda 명령줄 버전을 설치하는 것이 좋습니다.
Anaconda 설치 방법은 Anaconda 공식 가이드를 참조하세요: https://www.anaconda.com/distribution/
만약 당신이 숙련된 Python 프로그래머이고 Anaconda를 사용할 필요성을 느끼지 못한다면, 전혀 괜찮습니다. 필요한 종속성을 설치하는 데 도움이 필요하지 않다고 가정하고 이 섹션을 건너뛸 수 있습니다.
거래 전략을 개발하다
거래 전략의 최종 결과는 다음 질문에 답해야 합니다.
지시사항: 자산이 저렴한지, 비싼지, 공정한 가치인지 판단합니다.
개시 조건: 자산 가격이 싸거나 비싸면 롱 포지션을 취하거나 숏 포지션을 취해야 합니다.
거래 종료: 자산 가격이 적정하고 해당 자산에 대한 포지션(이전 매수 또는 매도)이 있는 경우, 해당 포지션을 종료해야 할까요?
가격 범위: 거래가 시작되는 가격(또는 범위)
수량: 거래된 자금의 양(예: 디지털 화폐의 양 또는 상품 선물의 lot 수)
머신 러닝을 사용하면 이러한 각 질문에 답할 수 있지만, 이 글의 나머지 부분에서는 거래의 방향에 대한 첫 번째 질문에 대한 답에 초점을 맞추겠습니다.
전략적 접근 방식
전략 구축에는 두 가지 접근 방식이 있습니다. 하나는 모델 기반이고 다른 하나는 데이터 마이닝 기반입니다. 이 둘은 기본적으로 반대되는 접근 방식입니다.
모델 기반 전략 구축에서는 시장 비효율성 모델부터 시작하여 수학적 표현식(예: 가격, 수익)을 구성하고 장기간에 걸쳐 효과를 테스트합니다. 이 모델은 일반적으로 실제 복잡한 모델을 단순화한 버전이며, 장기적으로 볼 때 그 중요성과 안정성을 검증할 필요가 있습니다. 일반적인 추세 추종 전략, 평균 회귀 전략, 차익 거래 전략이 이 범주에 속합니다.
반면에 우리는 먼저 가격 패턴을 찾고 데이터 마이닝 방법에서 알고리즘을 사용하려고 노력합니다. 이러한 패턴이 무엇 때문에 나타나는지는 중요하지 않다. 단지 그 패턴이 미래에도 계속 반복될 것이라는 것만이 확실할 뿐이다. 이것은 맹검 분석 방법이며, 무작위 패턴에서 실제 패턴을 식별하기 위해 엄격한 검사가 필요합니다. “시행착오”, “막대 차트 패턴” 및 “특징 질량 회귀”가 이 범주에 속합니다.
분명히 머신 러닝은 데이터 마이닝 방법에 쉽게 적용됩니다. 데이터 마이닝을 통해 머신 러닝을 사용하여 거래 신호를 만드는 방법을 살펴보겠습니다.
코드 예제에서는 Inventor Quantitative Platform 기반의 백테스팅 도구와 자동화된 거래 API 인터페이스를 사용합니다. 위의 섹션에서 호스터를 배포하고 Anaconda를 설치한 후에는 필요한 데이터 과학 분석 라이브러리와 유명한 머신 러닝 모델인 scikit-learn만 설치하면 됩니다. 이 부분에 대한 자세한 내용은 다루지 않겠습니다.
pip install -U scikit-learn
머신러닝을 사용하여 거래 전략 신호 생성
- 데이터 마이닝
시작하기에 앞서, 표준 머신 러닝 문제는 다음과 같습니다.
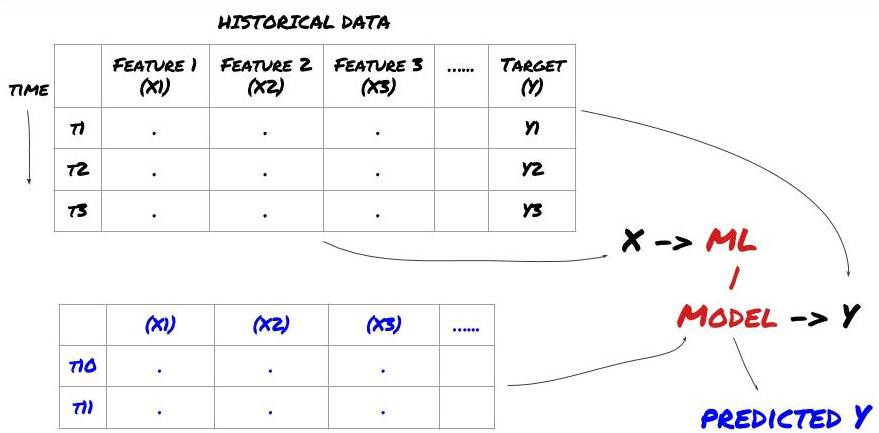
머신러닝 문제 프레임워크
우리가 만들려는 특징은 어느 정도 예측 능력(X)을 가져야 하고, 대상 변수(Y)를 예측하고, 과거 데이터를 사용하여 Y를 실제 값에 최대한 가깝게 예측할 수 있는 ML 모델을 훈련하려고 합니다. 마지막으로, 이 모델을 사용하여 Y가 알려지지 않은 새로운 데이터에 대한 예측을 내립니다. 이제 첫 번째 단계로 넘어가겠습니다.
1단계: 문제 설정
- 무엇을 예측하고 싶으신가요? 좋은 예측이란 무엇인가? 예측 결과를 어떻게 평가하시나요?
즉, 위의 프레임워크에서 Y는 무엇일까요?
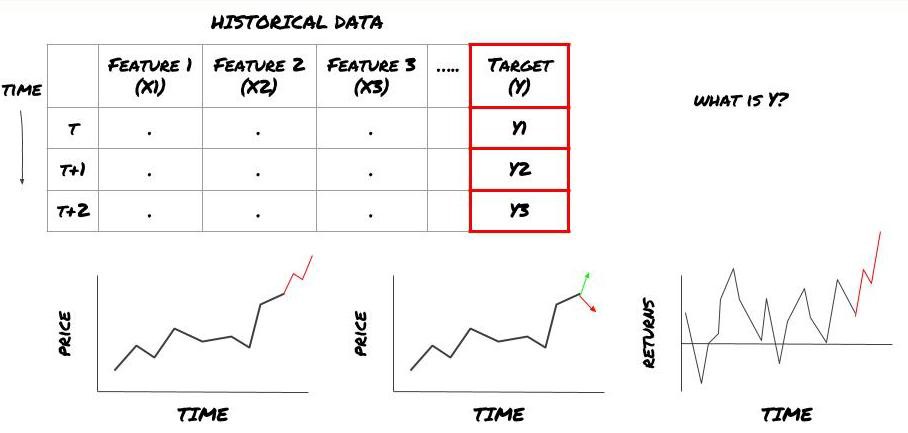
무엇을 예측하고 싶으신가요?
미래 가격, 미래 수익/손익, 매수/매도 신호를 예측하고, 포트폴리오 배분을 최적화하고 효율적으로 거래를 실행하고 싶으신가요?
다음 타임스탬프의 가격을 예측한다고 가정해보자. 이 경우 Y(t) = Price(t+1)입니다. 이제 우리는 과거 데이터로 프레임워크를 완성할 수 있습니다.
Y(t)는 백테스트에서만 알 수 있지만, 우리 모델을 사용하면 t(t+1) 시점의 가격은 알 수 없습니다. 우리는 모델을 사용하여 예측 Y(예측, t)를 수행하고 이를 시간 t+1에서만 실제 값과 비교합니다. 즉, 예측 모델에서 Y를 특징으로 사용할 수 없습니다.
목표 Y를 알게 되면 예측을 어떻게 평가할지 결정할 수도 있습니다. 이는 우리가 데이터에 시도할 다양한 모델을 구별하는 데 중요합니다. 우리가 해결하려는 문제에 따라 모델의 효율성을 측정하는 지표를 선택하세요. 예를 들어, 가격을 예측하는 경우 평균 제곱근 오차를 지표로 사용할 수 있습니다. 일반적으로 사용되는 일부 지표(이동 평균, MACD, 분산 점수 등)는 Inventor Quant 도구 상자에 미리 코딩되어 있으며, API 인터페이스를 통해 이러한 지표를 전역적으로 호출할 수 있습니다.
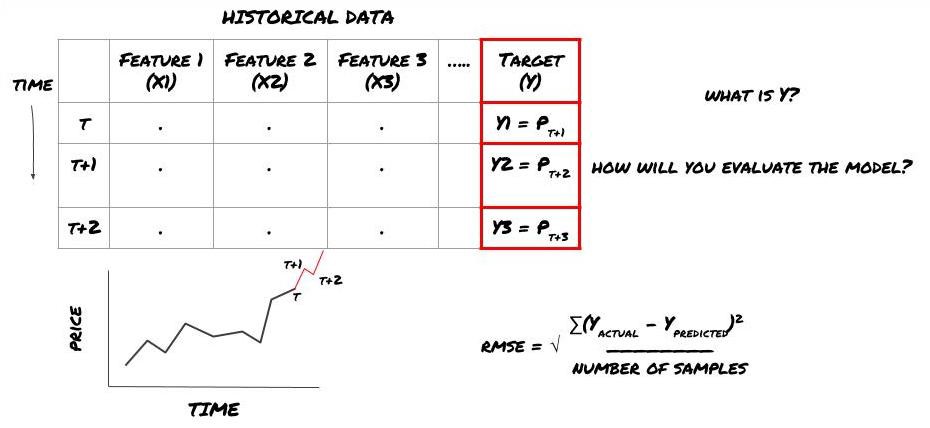
미래 가격 예측을 위한 ML 프레임워크
이를 증명하기 위해 가상 투자 대상의 미래 예상 기준 가치를 예측하는 예측 모델을 만들어 보겠습니다. 여기서:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
이것은 회귀 문제이므로 RMSE(Root Mean Squared Error)로 모델을 평가합니다. 또한 우리는 총 이익을 평가 기준으로 사용할 것입니다.
참고: RMSE에 대한 관련 수학적 지식은 Baidu 백과사전의 관련 내용을 참조하십시오.
- 우리의 목표는 예측된 값을 Y에 최대한 가깝게 만드는 모델을 만드는 것입니다.
2단계: 신뢰할 수 있는 데이터 수집
현재 문제를 해결하는 데 도움이 되는 데이터를 수집하고 정리하세요.
목표 변수 Y에 대한 예측 능력을 얻으려면 어떤 데이터를 고려해야 합니까? 가격을 예측하는 경우 목표 가격 데이터, 목표 거래량 데이터, 관련 목표에 대한 유사 데이터, 목표 지수 수준과 같은 전반적인 시장 지표, 다른 관련 자산의 가격 등을 활용할 수 있습니다.
이 데이터에 대한 데이터 액세스 권한을 설정하고, 데이터가 정확한지 확인하고 누락된 데이터(매우 일반적인 문제)를 해결해야 합니다. 또한 모델에 편향이 생기지 않도록 데이터가 편향되지 않고 모든 시장 상황을 적절히 나타내는지 확인하세요(예: 동일한 수의 승패 시나리오). 배당금, 포트폴리오 분할, 연속 등에 대한 데이터를 정리해야 할 수도 있습니다.
FMZ.COM(Inventor Quantitative Platform)을 이용하시는 경우, Google, Yahoo, NSE, Quandl 등의 글로벌 데이터를 무료로 이용하실 수 있으며, CTP, Yisheng 등의 국내 상품선물, Binance, OKEX, Huobi, BitMex 등의 심층데이터도 이용 가능합니다. Inventor Quantitative Platform은 또한 투자 대상 분할 및 심층적인 시장 데이터와 같은 이러한 데이터를 사전 정리하고 필터링하여 정량적 작업자가 이해하기 쉬운 형식으로 전략 개발자에게 제공합니다.
이 글의 편의를 위해, 우리는 다음 데이터를 가상 투자 대상 ‘MQK’로 사용합니다. 또한 Auquan’s Toolbox라는 매우 편리한 정량적 도구를 사용합니다. 자세한 내용은 다음을 참조하세요: https://github.com/Auquan / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
위 코드를 사용하면 Auquan의 도구 상자가 데이터를 다운로드하여 데이터 프레임 사전에 로드했습니다. 이제 우리가 선호하는 형식으로 데이터를 준비해야 합니다. ds.getBookDataByFeature() 함수는 피처당 하나의 데이터 프레임, 즉 데이터 프레임 사전을 반환합니다. 우리는 모든 기능을 갖춘 주식에 대한 새로운 데이터 프레임을 생성합니다.
3단계: 데이터 분할
- 데이터에서 훈련 세트를 생성하고 이러한 세트의 교차 검증 및 테스트
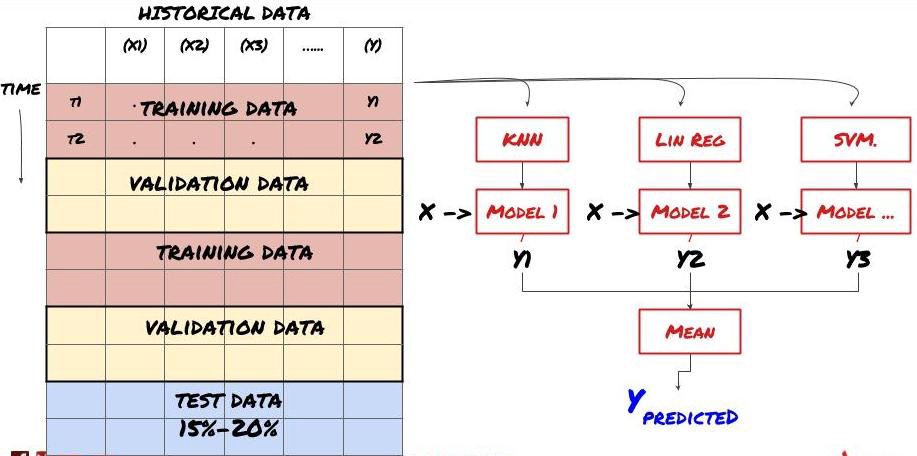
매우 중요한 단계예요! 계속하기 전에, 모델을 훈련하기 위한 훈련 데이터 세트와 모델 성능을 평가하기 위한 테스트 데이터 세트로 데이터를 분할해야 합니다. 권장 분할은 다음과 같습니다. 60-70% 훈련 세트, 30-40% 테스트 세트
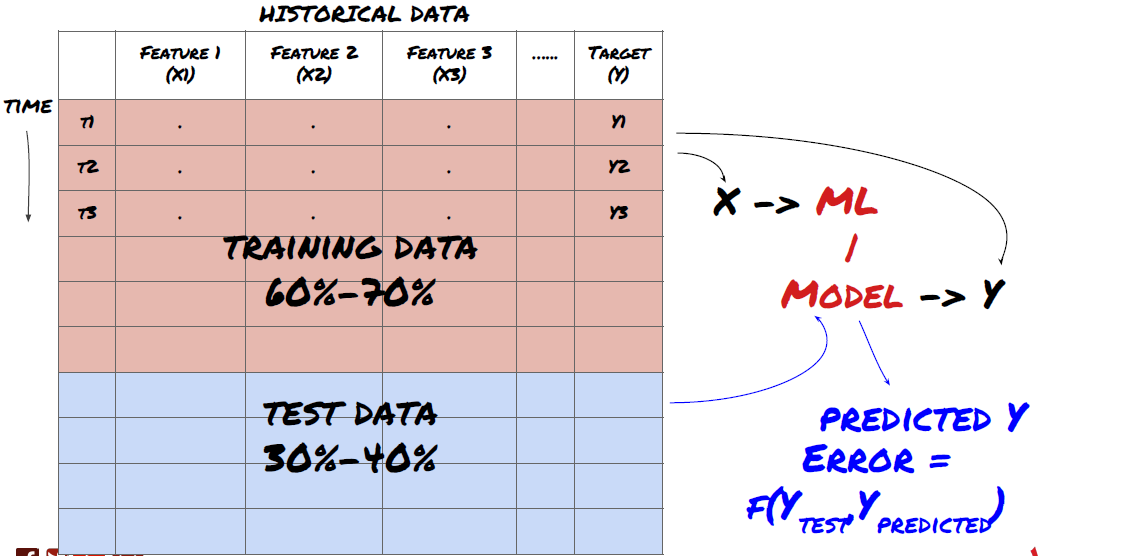
데이터를 훈련 세트와 테스트 세트로 분할
훈련 데이터는 모델 매개변수를 평가하는 데 사용되므로, 모델이 이 훈련 데이터에 과적합될 수 있으며, 훈련 데이터가 모델 성능을 왜곡할 수 있습니다. 별도의 테스트 데이터를 보관하지 않고 모든 데이터를 학습에 사용하면 모델이 새롭고 보이지 않는 데이터에서 얼마나 잘 수행될지 또는 얼마나 나쁜 성능을 보일지 알 수 없습니다. 이는 훈련된 ML 모델이 라이브 데이터에서 실패하는 주된 이유 중 하나입니다. 사람들은 사용 가능한 모든 데이터에서 훈련을 하고 훈련 데이터 지표에 흥분하지만, 모델은 훈련되지 않은 라이브 데이터에서 의미 있는 예측을 하지 못합니다. .
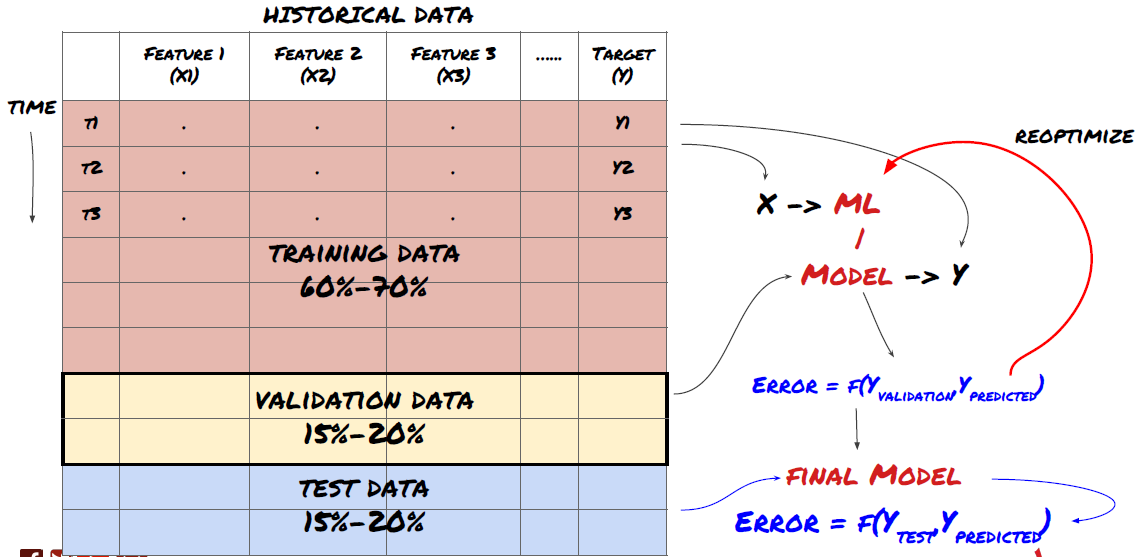
데이터를 훈련, 검증 및 테스트 세트로 분할합니다.
이런 접근 방식에는 문제가 있습니다. 우리가 훈련 데이터로 반복적으로 훈련하고, 테스트 데이터로 성능을 평가하고, 만족스러운 성능에 도달할 때까지 모델을 최적화하면, 우리는 암묵적으로 테스트 데이터를 훈련 데이터의 일부로 포함하게 됩니다. 궁극적으로, 우리 모델은 이러한 훈련 및 테스트 데이터 세트에서 좋은 성능을 보일 수 있지만, 새로운 데이터를 잘 예측할 수 있을 것이라는 보장은 없습니다.
이 문제를 해결하려면 별도의 검증 데이터 세트를 만들 수 있습니다. 이제 데이터를 학습하고, 검증 데이터에서 성능을 평가하고, 성능에 만족할 때까지 최적화하고, 마지막으로 테스트 데이터에서 테스트할 수 있습니다. 이렇게 하면 테스트 데이터가 오염되지 않고, 테스트 데이터의 정보를 사용하여 모델을 개선하지 않습니다.
테스트 데이터의 성능을 확인한 후에는 뒤로 돌아가 모델을 추가로 최적화하려고 하지 마세요. 모델이 좋은 결과를 제공하지 못한다면 모델을 완전히 삭제하고 다시 시작하세요. 제안된 분할은 60% 훈련 데이터, 20% 검증 데이터, 20% 테스트 데이터로 구성될 수 있습니다.
우리 문제에는 사용 가능한 세 가지 데이터 세트가 있으며, 하나를 훈련 세트로, 두 번째를 검증 세트로, 세 번째를 테스트 세트로 사용합니다.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
이들 각각에 다음 5개 기준 값의 평균으로 정의된 대상 변수 Y를 추가합니다.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
4단계: 기능 엔지니어링
데이터의 행동을 분석하고 예측 능력이 있는 기능을 만듭니다.
이제 프로젝트의 실제 건설이 시작됩니다. 특성 선택의 황금률은 예측 능력은 주로 모델이 아닌 특성에서 나온다는 것입니다. 모델 선택보다 기능 선택이 성능에 훨씬 더 큰 영향을 미친다는 것을 알게 될 것입니다. 기능 선택에 대한 몇 가지 참고 사항:
대상 변수와의 관계를 조사하지 않고 임의로 많은 기능 집합을 선택하지 마십시오.
대상 변수와의 관계가 거의 없거나 전혀 없으면 과적합이 발생할 수 있습니다.
선택한 기능은 서로 높은 상관관계를 가질 수 있으며 이 경우 더 적은 수의 기능만으로도 타겟을 설명할 수 있습니다.
저는 일반적으로 직관적으로 이해가 되는 몇 가지 기능을 만들고 대상 변수가 이러한 기능과 어떻게 연관되어 있는지, 또한 기능 간의 상관 관계를 살펴보아 어떤 기능을 사용할지 결정합니다.
또한, 최대 정보 계수(MIC)를 기준으로 후보 기능을 순위를 매기고, 주성분 분석(PCA)을 수행하고, 다른 방법을 시도할 수도 있습니다.
특징 변환/정규화:
ML 모델은 정규화를 통해 좋은 성능을 보이는 경향이 있습니다. 그러나 시계열 데이터를 다룰 때는 미래의 데이터 범위를 알 수 없기 때문에 정규화가 까다롭습니다. 데이터가 정규화된 범위를 벗어났을 수 있으며, 이로 인해 모델이 잘못되었을 수 있습니다. 하지만 여전히 어느 정도의 고정을 강제로 시도할 수 있습니다.
스케일링: 표준편차 또는 사분위 범위로 기능 분할
중앙화: 현재 값에서 과거 평균을 빼기
정규화: 위의 두 개의 룩백 기간(x - 평균) / stdev
기존 정규화: 데이터를 -1~+1 범위로 정규화하고 룩백 기간(x-min)/(max-min) 내에서 다시 중앙화합니다.
과거 이동 평균, 표준 편차, 과거 기간 동안의 최대값 또는 최소값을 사용하므로 특성의 정규화된 값은 다른 시간의 다른 실제 값을 나타냅니다. 예를 들어, 기능의 현재 값이 5이고 30기간 이동 평균이 4.5인 경우 중앙화 후 0.5로 변환됩니다. 나중에 30기간 이동평균이 3이 되면 3.5라는 값은 0.5가 됩니다. 이것이 모델이 틀린 이유일 수 있습니다. 따라서 정규화는 까다롭고 실제로 모델의 성능을 개선하는 것이 무엇인지(만약 있다면) 알아내야 합니다.
우리 문제의 첫 번째 반복에서 우리는 혼합 매개변수를 사용하여 많은 수의 기능을 생성했습니다. 나중에 기능 수를 줄일 수 있는지 시도해 보겠습니다.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
5단계: 모델 선택
선택한 문제에 적합한 통계/ML 모델을 선택하세요
모델의 선택은 문제가 어떻게 공식화되는지에 따라 달라집니다. 지도 학습 문제(특징 행렬의 각 점 X가 대상 변수 Y에 매핑됨)를 풀고 있습니까? 아니면 비지도 학습 문제(매핑이 주어지지 않고 모델은 알려지지 않은 패턴을 학습하려고 시도함)를 풀고 있습니까? 당신은 회귀 문제(미래의 실제 가격을 예측하는 문제)를 풀고 있습니까? 아니면 분류 문제(미래의 가격의 방향(증가/감소)만 예측하는 문제)를 풀고 있습니까?

지도 학습 또는 비지도 학습

회귀 또는 분류
몇 가지 일반적인 지도 학습 알고리즘을 사용하면 시작하는 데 도움이 될 수 있습니다.
LinearRegression(매개변수, 회귀)
로지스틱 회귀(매개변수, 분류)
K-최근접 이웃(KNN) 알고리즘(인스턴스 기반, 회귀)
SVM, SVR(매개변수, 분류 및 회귀)
의사결정 트리
결정 숲
선형 회귀나 로지스틱 회귀와 같은 간단한 모델부터 시작해서 필요에 따라 더 복잡한 모델을 구축하는 것이 좋습니다. 모델을 무작정 블랙박스로 여기기보다는, 모델의 기반이 되는 수학을 읽어보는 것이 좋습니다.
6단계: 훈련, 검증 및 최적화(4-6단계 반복)
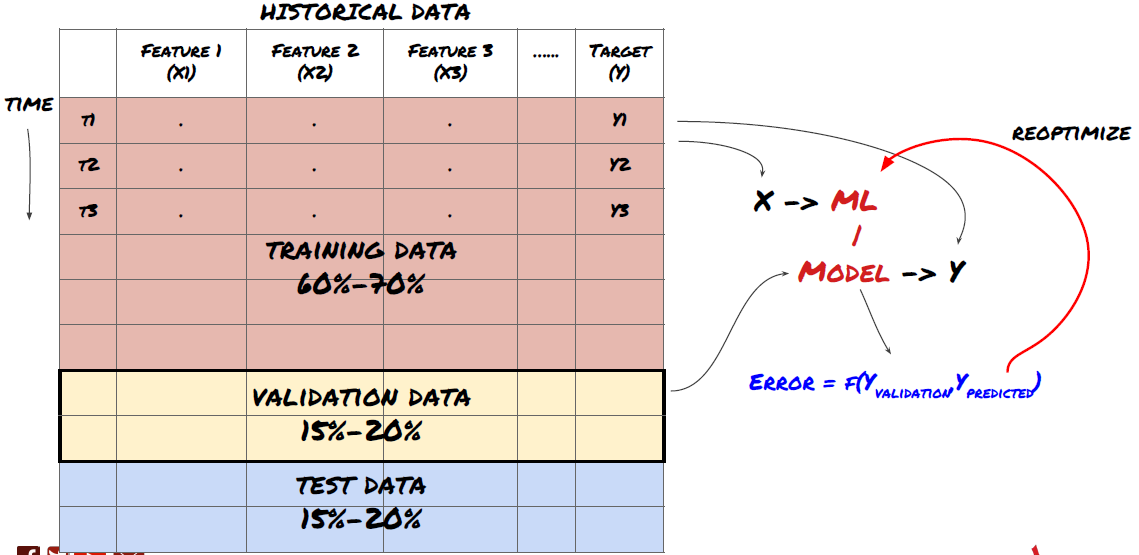
학습 및 검증 데이터 세트를 사용하여 모델을 학습하고 최적화합니다.
이제 마침내 모델을 만들 준비가 되었습니다. 이 단계에서는 모델과 모델 매개변수를 반복하는 작업만 진행합니다. 훈련 데이터로 모델을 훈련하고, 검증 데이터로 성능을 측정한 다음, 다시 돌아가 최적화하고, 재훈련하고, 평가합니다. 모델의 성능에 만족하지 못하는 경우 다른 모델을 사용해 보세요. 여러분은 마침내 만족스러운 모델을 얻을 때까지 이 단계를 여러 번 반복합니다.
마음에 드는 모델을 찾은 후에 다음 단계로 넘어가세요.
우리의 데모 문제를 위해 간단한 선형 회귀로 시작해 보겠습니다.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
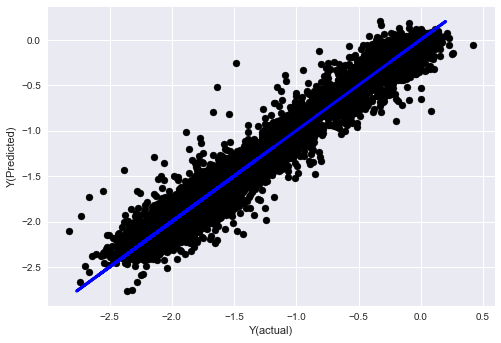
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
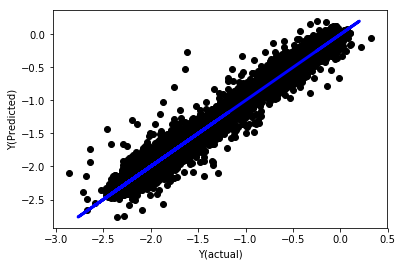
정규화 없는 선형 회귀
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
모델 계수를 살펴보세요. 우리는 그것들을 실제로 비교할 수 없고 어느 것이 중요한지 말할 수 없습니다. 왜냐하면 그것들은 모두 다른 척도에 있기 때문입니다. 동일한 척도로 맞추기 위해 정규화를 시도하고 어느 정도 안정성을 유지해 보겠습니다.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
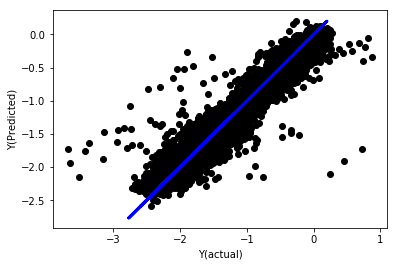
정규화된 선형 회귀
Mean squared error: 0.05
Variance score: 0.90
이 모델은 이전 모델보다 개선된 것은 아니지만, 나쁘지도 않습니다. 이제 우리는 실제로 계수를 비교하여 어느 계수가 실제로 중요한지 확인할 수 있습니다.
계수를 살펴보자
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
결과는 다음과 같습니다.
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
우리는 일부 기능이 다른 기능에 비해 계수가 더 높고 예측 능력이 더 강할 가능성이 있음을 분명히 알 수 있습니다.
다양한 특성 간의 상관관계를 살펴보겠습니다.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
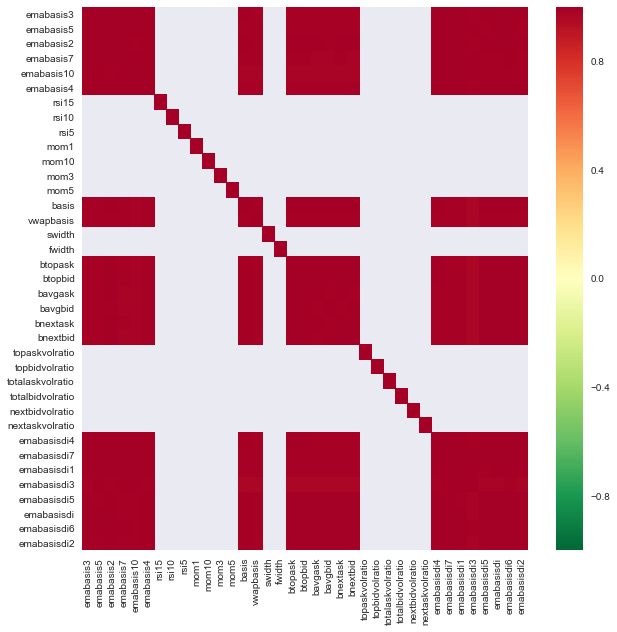
특징 간의 상관관계
진한 빨간색 부분은 상관관계가 높은 변수를 나타냅니다. 다시 몇 가지 기능을 생성/수정하여 모델을 개선해 보겠습니다.
예를 들어, 다른 특성의 선형 조합일 뿐인 emabasisdi7과 같은 특성은 쉽게 삭제할 수 있습니다.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
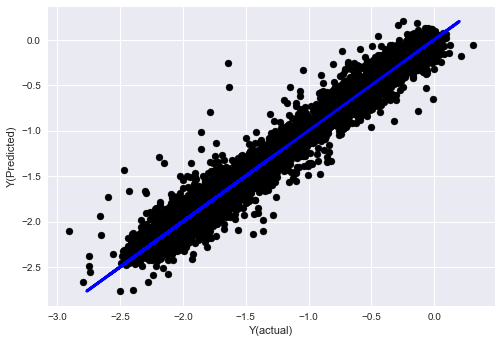
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
보시다시피, 우리 모델 성능에는 변화가 없습니다. 단지 목표 변수를 설명하는 몇 가지 특징이 필요할 뿐입니다. 위의 기능을 더 많이 시도해 보시고, 새로운 조합 등을 시도해 보시고 모델을 개선할 수 있는 부분이 무엇인지 확인해 보세요.
또한, 모델을 변경하면 성능이 향상되는지 확인하기 위해 더 복잡한 모델을 시도해 볼 수도 있습니다.
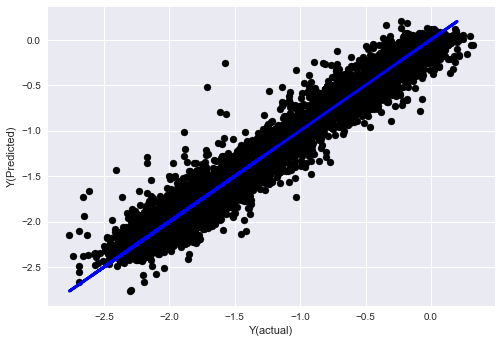
- K-최근접 이웃(KNN) 알고리즘
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
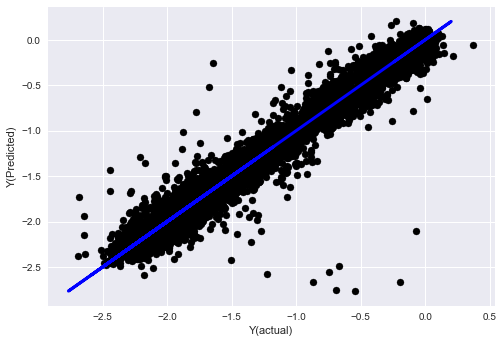
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- 의사결정 트리
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
7단계: 테스트 데이터 백테스트
실제 샘플 데이터에서 성능 확인
(손대지 않은) 테스트 데이터 세트에 대한 백테스트 성능
지금은 중요한 순간입니다. 우리는 처음에 따로 보관해 두었지만 아직 건드리지 않은 테스트 데이터를 사용하여 최종 최적화된 모델을 실행하여 마지막 단계부터 시작합니다.
이를 통해 라이브로 거래를 시작할 때 새롭고 보이지 않는 데이터에 따라 모델이 어떻게 수행될지에 대한 현실적인 기대치를 얻을 수 있습니다. 따라서 모델을 학습하거나 검증하는 데 사용되지 않은 정리된 데이터 세트가 있는지 확인하는 것이 필요합니다.
테스트 데이터의 백테스트 결과가 마음에 들지 않으면 모델을 버리고 다시 시작하세요. 절대로 뒤로 돌아가 모델을 다시 최적화하지 마세요. 그러면 과잉적합이 발생합니다! (또한 이 데이터 세트는 오염되었으므로 새로운 테스트 데이터 세트를 만드는 것이 좋습니다. 모델을 삭제하더라도 이미 데이터 세트에 대한 내용을 어느 정도 알고 있기 때문입니다.)
여기서도 우리는 여전히 Auquan의 도구 상자를 사용할 것입니다.
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
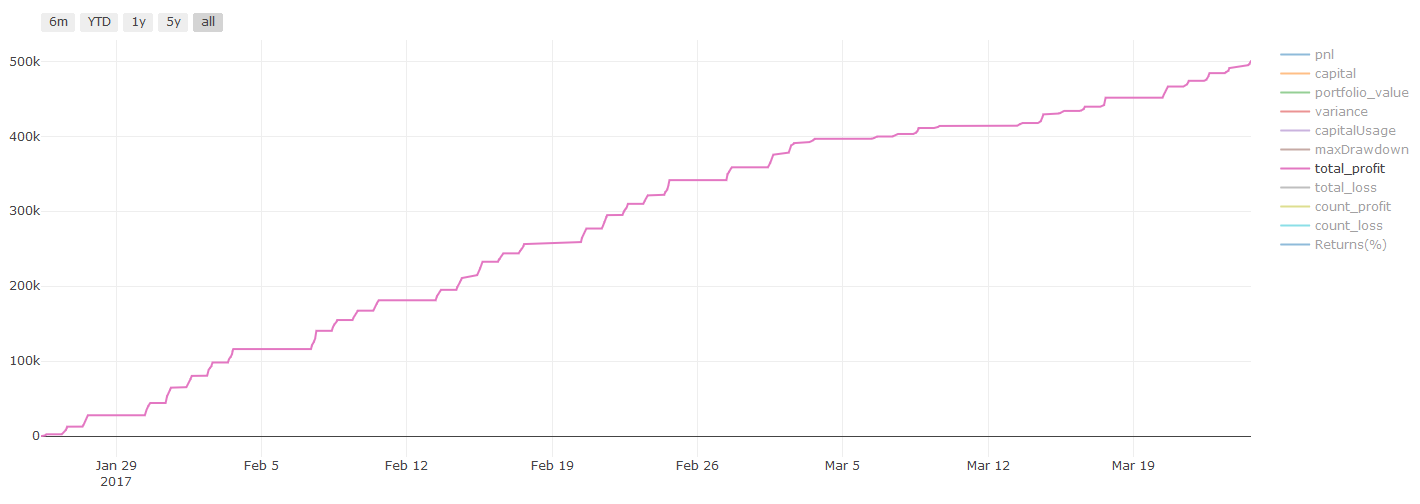
백테스트 결과, Pnl은 미국 달러로 계산됩니다(Pnl에는 거래 비용 및 기타 수수료가 포함되지 않습니다)
8단계: 모델을 개선하는 다른 방법
롤링 검증, 앙상블 학습, 배깅 및 부스팅
더 많은 데이터를 수집하고, 더 나은 기능을 만들고, 더 많은 모델을 시도하는 것 외에도 개선을 위해 시도할 수 있는 몇 가지 사항은 다음과 같습니다.
1. 롤링 검증
롤링 검증
시장 상황은 거의 일정하게 유지되지 않습니다. 예를 들어 1년치 데이터가 있고 1월부터 8월까지의 데이터를 훈련에 사용하고 9월부터 12월까지의 데이터를 모델 테스트에 사용한다면 매우 구체적인 시장 상황에 맞춰 훈련을 하게 될 수 있습니다. 아마도 상반기에는 시장 변동성이 없었고, 극단적인 뉴스로 인해 9월에 시장이 급등했을 수도 있습니다. 귀하의 모델은 이 패턴을 학습할 수 없고 쓰레기 예측 결과를 제공할 것입니다.
1~2월에 교육하고, 3월에 검증하고, 4~5월에 재교육하고, 6월에 검증하는 식으로 순차적으로 검증을 시도하는 것이 나을 수도 있습니다.
2. 앙상블 학습
앙상블 학습
일부 모델은 특정 시나리오를 예측하는 데 효과적일 수 있지만, 다른 시나리오나 특정 상황을 예측하는 데는 상당히 과적합될 수 있습니다. 오류와 과잉적합을 줄이는 한 가지 방법은 다양한 모델의 앙상블을 사용하는 것입니다. 귀하의 예측은 많은 모델에서 내린 예측의 평균이 되며, 다른 모델의 오류는 상쇄되거나 줄어들 수 있습니다. 일반적인 앙상블 방법으로는 배깅(Bagging)과 부스팅(Boosting)이 있다.
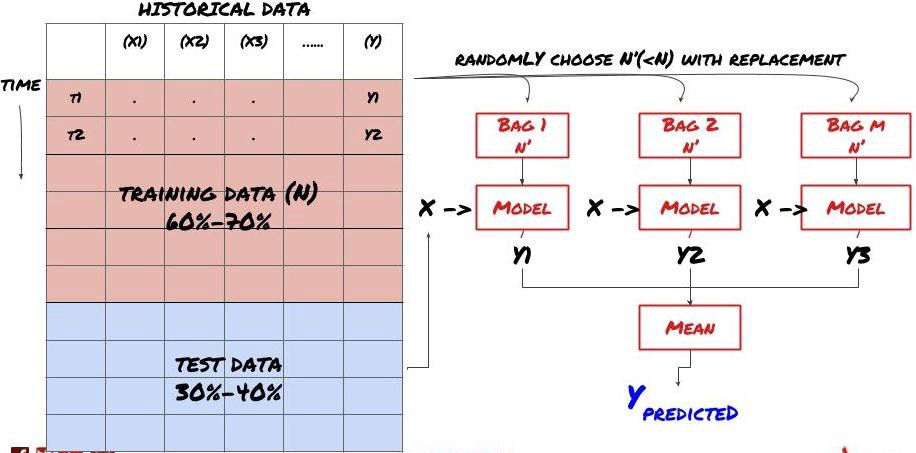
Bagging
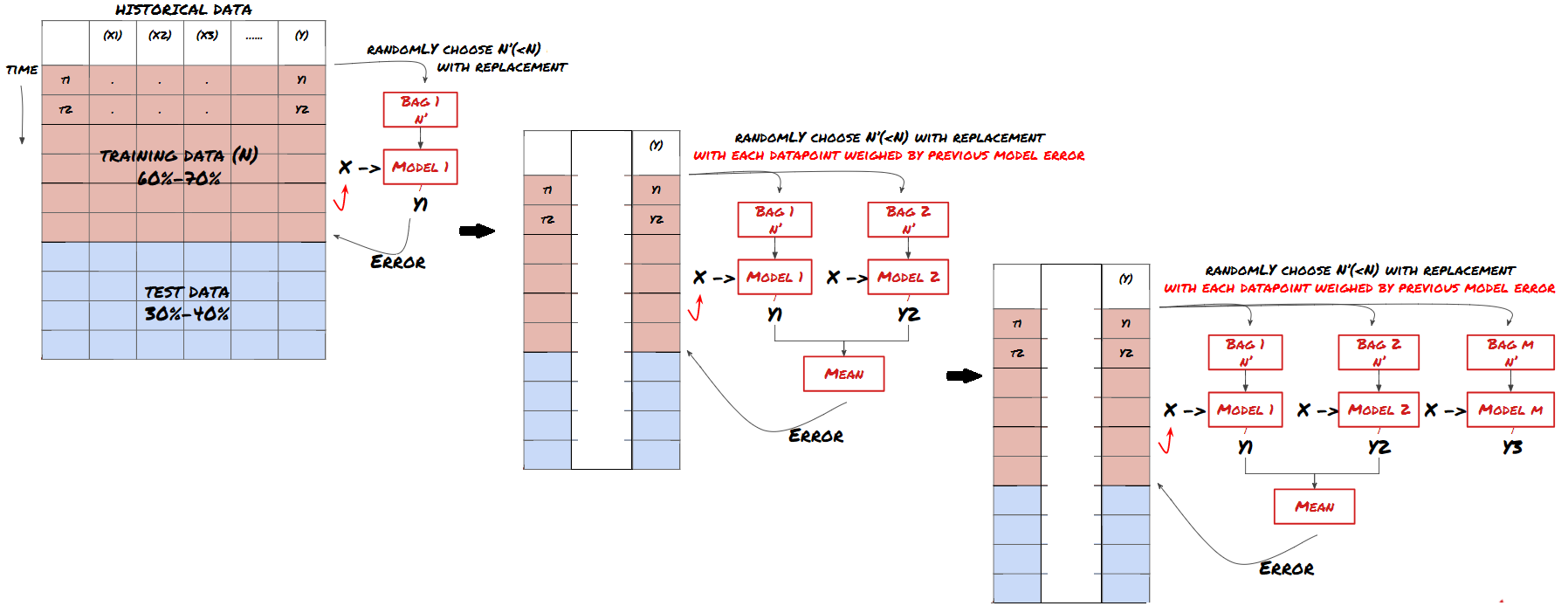
Boosting
간결하게 설명하기 위해 이 방법은 건너뛰겠지만, 온라인에서 이 방법에 대한 자세한 정보를 찾을 수 있습니다.
우리의 문제에 대해 앙상블 방법을 시도해 보자
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
우리는 지금까지 많은 지식과 정보를 축적했습니다. 간단히 살펴보겠습니다.
문제를 해결하세요
신뢰할 수 있는 데이터 수집 및 데이터 정리
데이터를 훈련, 검증 및 테스트 세트로 분할합니다.
기능을 생성하고 해당 기능을 분석합니다.
행동에 따라 적절한 훈련 모델을 선택하세요
훈련 데이터를 사용하여 모델을 훈련하고 예측을 수행합니다.
검증 세트의 성능을 확인하고 다시 최적화합니다.
테스트 세트에서 최종 성능 검증
꽤 신나는 일이지 않나요? 하지만 아직 끝나지 않았습니다. 이제 신뢰할 수 있는 예측 모델만 있습니다. 우리의 전략에서 정말 원했던 것이 무엇인지 기억하시나요? 아직은 필요하지 않습니다:
거래 방향을 식별하기 위한 예측 모델 기반 신호 개발
개방 및 폐쇄 포지션을 식별하기 위한 특정 전략 개발
포지션과 가격을 식별하기 위한 실행 시스템
위의 모든 것은 Inventor Quantitative Platform(FMZ.COM)을 사용해야 합니다. Inventor Quantitative Platform에는 고도로 캡슐화되고 완전한 API 인터페이스와 전역적으로 호출 가능한 주문 및 거래 기능이 있으므로 연결하고 하나씩 추가합니다. 다양한 거래소의 API 인터페이스, Inventor Quantitative Platform의 Strategy Square에는 성숙하고 완전한 대안 전략이 많이 있습니다. 이 기사의 머신 러닝 방법을 사용하면 특정 전략이 더욱 강력해질 것입니다. . Strategy Square는 https:// www.fmz.com/square에 있습니다.
거래 비용에 대한 중요한 참고 사항: 귀하의 모델은 귀하가 선택한 자산에 대해 언제 롱 포지션을 취해야 할지 또는 숏 포지션을 취해야 할지 알려줍니다. 하지만 수수료/거래 비용/가능 거래량/손절매 등은 고려되지 않습니다. 거래 비용은 종종 수익성 있는 거래를 손실로 바꿀 수 있습니다. 예를 들어, 가격이 0.05달러 상승할 것으로 예상되는 자산은 매수이지만, 이 거래를 위해 0.10달러를 지불해야 하는 경우 순손실은 0.05달러가 됩니다. 위의 멋진 수익 그래프는 브로커 수수료, 거래소 수수료, 스프레드를 고려하면 실제로 다음과 같습니다.
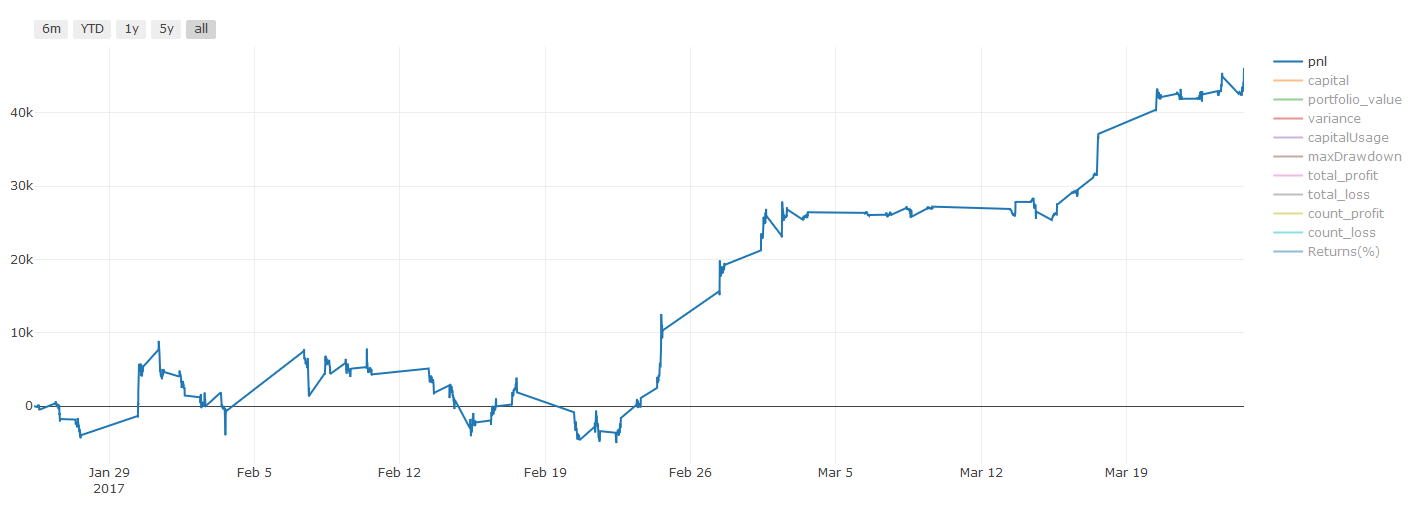
거래 수수료 및 스프레드 이후 백테스트 결과, Pnl은 USD입니다.
거래 수수료와 스프레드가 당사 손익의 90% 이상을 차지합니다! 이에 대해서는 후속 기사에서 자세히 논의하겠습니다.
마지막으로 몇 가지 흔한 함정을 살펴보겠습니다.
해야 할 일과 하지 말아야 할 일
온 힘을 다해 과잉적합을 피하세요!
모든 데이터 포인트 후에 재교육하지 마세요. 이것은 사람들이 머신 러닝 개발에서 저지르는 일반적인 실수입니다. 모델이 모든 데이터 포인트 후에 다시 학습되어야 한다면 아마도 그다지 좋은 모델이 아닐 것입니다. 즉, 의미 있는 빈도(예: 일중 예측을 하는 경우 매주 말)만큼 주기적으로 재교육해야 합니다.
편향을 피하세요, 특히 예측 편향을 피하세요: 이는 모델이 작동하지 않는 또 다른 이유입니다. 미래의 정보를 사용하지 않도록 하세요. 대부분의 경우 이는 모델의 특징으로 대상 변수 Y를 사용하지 않는다는 것을 의미합니다. 백테스팅 중에는 사용할 수 있지만, 실제로 모델을 실행할 때는 사용할 수 없으므로 모델이 쓸모없게 됩니다.
데이터 마이닝 편향에 주의하세요: 우리는 데이터가 적합한지 확인하기 위해 일련의 모델링을 수행하려고 하기 때문에 특별한 이유가 없다면 무작위 패턴과 실제 패턴을 구분하기 위해 엄격한 테스트를 실행해야 합니다. 발생할 수 있는 일입니다. 예를 들어, 상승 추세 패턴은 선형 회귀로 잘 설명되지만, 더 큰 무작위 흐름의 작은 부분일 가능성이 큽니다!
과잉 맞춤을 피하세요
이 내용은 매우 중요하므로 다시 언급해야 한다고 생각합니다.
오버피팅(Overfitting)은 트레이딩 전략에서 가장 위험한 함정입니다.
복잡한 알고리즘은 백테스팅에서 매우 좋은 성과를 낼 수 있지만 새로운 보이지 않는 데이터에서는 비참하게 실패할 수 있습니다. 알고리즘은 실제로 데이터의 추세를 보여주지 않으며 실제 예측 능력이 없습니다. 이는 자신이 보는 데이터에 매우 적합합니다.
시스템을 최대한 단순하게 유지하세요. 데이터를 설명하기 위해 복잡한 기능이 많이 필요한 경우 과적합이 발생할 수 있습니다.
사용 가능한 데이터를 훈련 데이터와 테스트 데이터로 나누고, 라이브 거래에 모델을 사용하기 전에 항상 실제 샘플 데이터에서 성능을 확인하세요.