Perbincangan Kaedah Pengujian Strategi Berdasarkan Penjana Pasaran Rawak
 0
304
0
304
[TOC]

Mukadimah
Sistem ujian belakang Platform Dagangan Kuantitatif Pencipta ialah sistem ujian belakang yang sentiasa berulang, mengemas kini dan menaik taraf Daripada fungsi ujian belakang asas, ia menambah fungsi secara beransur-ansur dan mengoptimumkan prestasi. Semasa platform berkembang, sistem ujian belakang akan terus dioptimumkan dan dinaik taraf Hari ini kita akan membincangkan topik berdasarkan sistem ujian belakang: “Pengujian strategi berdasarkan keadaan pasaran rawak”.
perlukan
Dalam bidang perdagangan kuantitatif, pembangunan dan pengoptimuman strategi tidak boleh dipisahkan daripada pengesahan data pasaran sebenar. Walau bagaimanapun, dalam aplikasi sebenar, disebabkan persekitaran pasaran yang kompleks dan berubah, bergantung pada data sejarah untuk ujian belakang mungkin mempunyai kekurangan, seperti kekurangan liputan keadaan pasaran yang melampau atau senario khas. Oleh itu, mereka bentuk penjana pasaran rawak yang cekap menjadi alat yang berkesan untuk pembangun strategi kuantitatif.
Apabila kita perlu menguji balik strategi pada pertukaran atau mata wang tertentu menggunakan data sejarah, kita boleh menggunakan sumber data rasmi platform FMZ untuk ujian balik. Kadang-kadang kita juga ingin melihat prestasi strategi dalam pasaran yang benar-benar “tidak dikenali” Pada masa ini, kita boleh “membuat” beberapa data untuk menguji strategi.
Kepentingan menggunakan data pasaran rawak ialah:
- 1. Menilai kemantapan strategi Penjana pasaran rawak boleh mencipta pelbagai kemungkinan senario pasaran, termasuk turun naik yang melampau, turun naik yang rendah, pasaran arah aliran dan pasaran yang tidak menentu. Menguji strategi dalam persekitaran simulasi ini boleh membantu menilai sama ada prestasinya stabil di bawah keadaan pasaran yang berbeza. Contohnya:
Bolehkah strategi menyesuaikan diri dengan penukaran arah aliran dan kejutan? Adakah strategi tersebut akan mengakibatkan kerugian yang besar dalam keadaan pasaran yang melampau?
- 2. Kenal pasti potensi kelemahan dalam strategi anda Dengan mensimulasikan beberapa situasi pasaran yang tidak normal (seperti kejadian angsa hitam hipotesis), potensi kelemahan dalam strategi boleh ditemui dan diperbaiki. Contohnya:
Adakah strategi terlalu bergantung pada struktur pasaran tertentu? Adakah terdapat risiko untuk melebihkan parameter?
-
- Mengoptimumkan parameter strategi Data yang dijana secara rawak menyediakan persekitaran ujian yang lebih pelbagai untuk penalaan parameter strategi tanpa perlu bergantung sepenuhnya pada data sejarah. Ini membolehkan julat parameter strategi yang lebih komprehensif dan mengelak daripada terhad kepada corak pasaran tertentu dalam data sejarah.
-
- Mengisi jurang dalam data sejarah Dalam sesetengah pasaran (seperti pasaran baru muncul atau pasaran yang berdagang mata wang kecil), data sejarah mungkin tidak mencukupi untuk merangkumi semua kemungkinan keadaan pasaran. Rawak boleh menyediakan sejumlah besar data tambahan untuk memudahkan ujian yang lebih komprehensif.
-
- Pembangunan berulang yang cepat Menggunakan data rawak untuk ujian pantas boleh mempercepatkan lelaran pembangunan strategi tanpa bergantung pada keadaan pasaran masa nyata atau pembersihan dan organisasi data yang memakan masa.
Walau bagaimanapun, ia juga perlu untuk menilai strategi secara rasional Untuk data pasaran yang dijana secara rawak, sila ambil perhatian:
- 1. Walaupun penjana pasaran rawak berguna, kepentingannya bergantung pada kualiti data yang dijana dan reka bentuk senario sasaran:
- 2. Logik penjanaan perlu dekat dengan pasaran sebenar: Jika keadaan pasaran yang dijana secara rawak benar-benar tidak sesuai dengan realiti, keputusan ujian mungkin kekurangan nilai rujukan. Sebagai contoh, penjana boleh direka bentuk dalam kombinasi dengan ciri statistik pasaran sebenar (seperti pengagihan turun naik, nisbah trend).
- 3. Ia tidak boleh menggantikan sepenuhnya ujian data sebenar: data rawak hanya boleh menambah pembangunan dan pengoptimuman strategi Strategi akhir masih perlu disahkan untuk keberkesanannya dalam data pasaran sebenar.
Setelah mengatakan semua itu, bagaimana kita boleh “membuat” beberapa data. Bagaimanakah kita boleh “membuat” data dengan mudah, cepat dan mudah untuk digunakan dalam sistem ujian belakang?
Idea reka bentuk
Artikel ini direka untuk menyediakan titik permulaan untuk perbincangan dan menyediakan pengiraan penjanaan pasaran rawak yang agak mudah Malah, terdapat pelbagai algoritma simulasi, model data dan teknologi lain yang boleh digunakan Oleh kerana ruang perbincangan yang terhad , kami tidak akan menggunakan kaedah simulasi data yang sangat kompleks.
Menggabungkan fungsi sumber data tersuai sistem ujian belakang platform, kami menulis program dalam Python.
- 1. Hasilkan satu set data K-line secara rawak dan tuliskannya ke dalam fail CSV untuk rakaman berterusan, supaya data yang dijana boleh disimpan.
- 2. Kemudian buat perkhidmatan untuk menyediakan sokongan sumber data untuk sistem ujian belakang.
- 3. Paparkan data garis K yang dijana dalam carta.
Untuk beberapa piawaian generasi dan storan fail data K-line, kawalan parameter berikut boleh ditakrifkan:
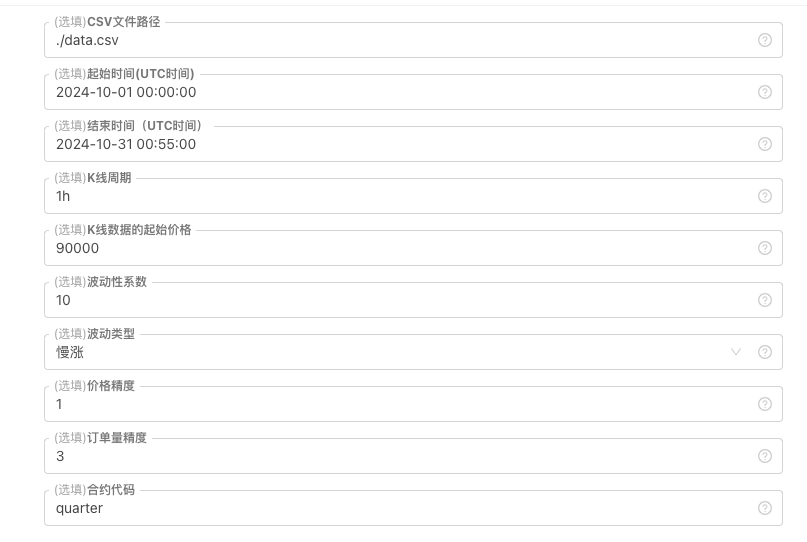
Corak data yang dijana secara rawak Untuk mensimulasikan jenis turun naik data K-line, reka bentuk ringkas hanya dilakukan menggunakan kebarangkalian berbeza bagi nombor rawak positif dan negatif Apabila data yang dijana tidak besar, corak pasaran yang diperlukan mungkin tidak dapat dilihat. Jika ada cara yang lebih baik, anda boleh menggantikan bahagian kod ini. Berdasarkan reka bentuk ringkas ini, melaraskan julat penjanaan nombor rawak dan beberapa pekali dalam kod boleh menjejaskan kesan data yang dijana.
Pengesahan data Data K-line yang dijana juga perlu disemak untuk rasional, untuk menyemak sama ada harga pembukaan tinggi dan penutupan rendah melanggar definisi, untuk menyemak kesinambungan data K-line, dsb.
Penjana Sebut Harga Rawak Sistem Ujian Belakang
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Berlatih dalam sistem ujian belakang
- Buat contoh dasar di atas, konfigurasikan parameter dan jalankannya.
- Pasaran sebenar (contoh strategi) perlu dijalankan pada hos yang digunakan pada pelayan, kerana IP awam diperlukan untuk sistem ujian belakang mengaksesnya dan mendapatkan data.
- Klik butang interaktif dan strategi akan mula menjana data pasaran rawak secara automatik.

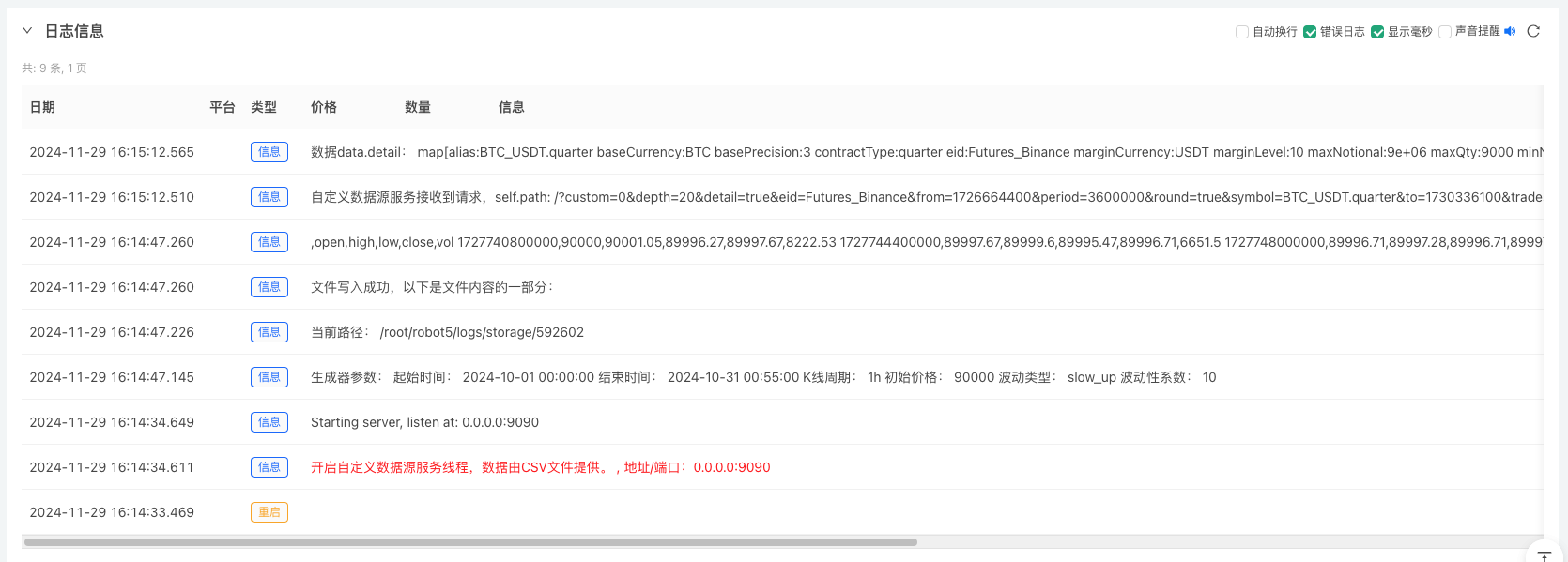
- Data yang dijana akan dipaparkan pada carta untuk pemerhatian yang mudah dan data akan direkodkan dalam fail data.csv tempatan
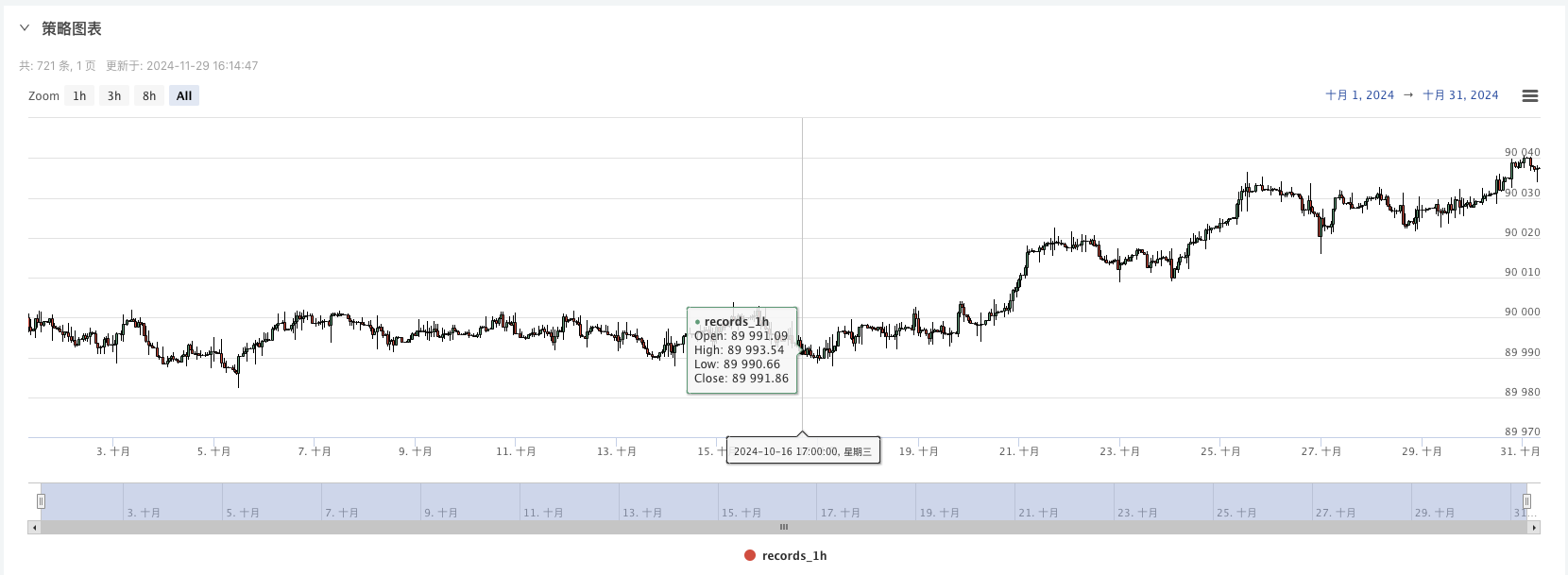
- Kini kita boleh menggunakan data yang dijana secara rawak ini dan menggunakan sebarang strategi untuk ujian balik
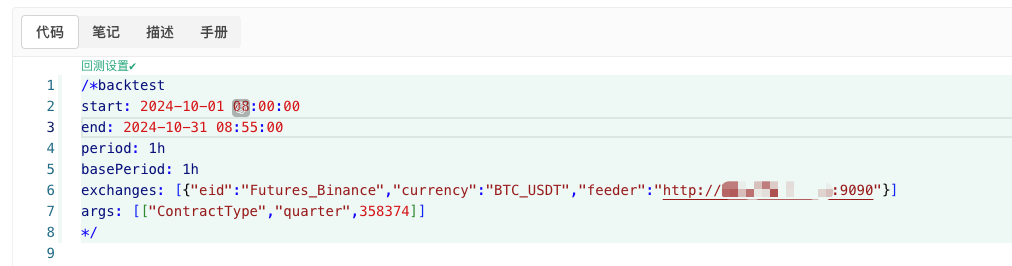
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Konfigurasikan mengikut maklumat di atas dan buat pelarasan khusus.http://xxx.xxx.xxx.xxx:9090Ia adalah alamat IP pelayan dan port terbuka cakera sebenar strategi penjanaan pasaran rawak.
Ini ialah sumber data tersuai Anda boleh merujuk kepada bahagian sumber data tersuai dalam dokumentasi API platform untuk mendapatkan maklumat lanjut.
- Selepas sistem backtest menyediakan sumber data, anda boleh menguji data pasaran rawak
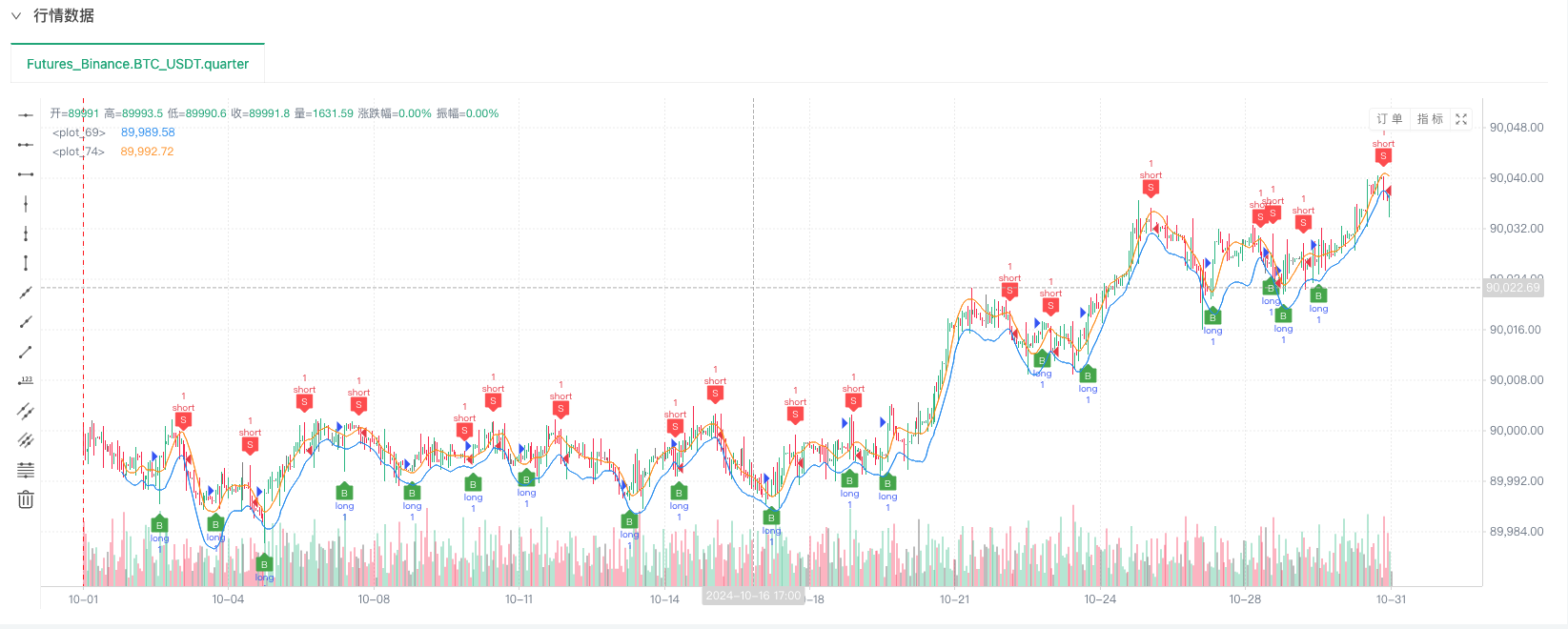
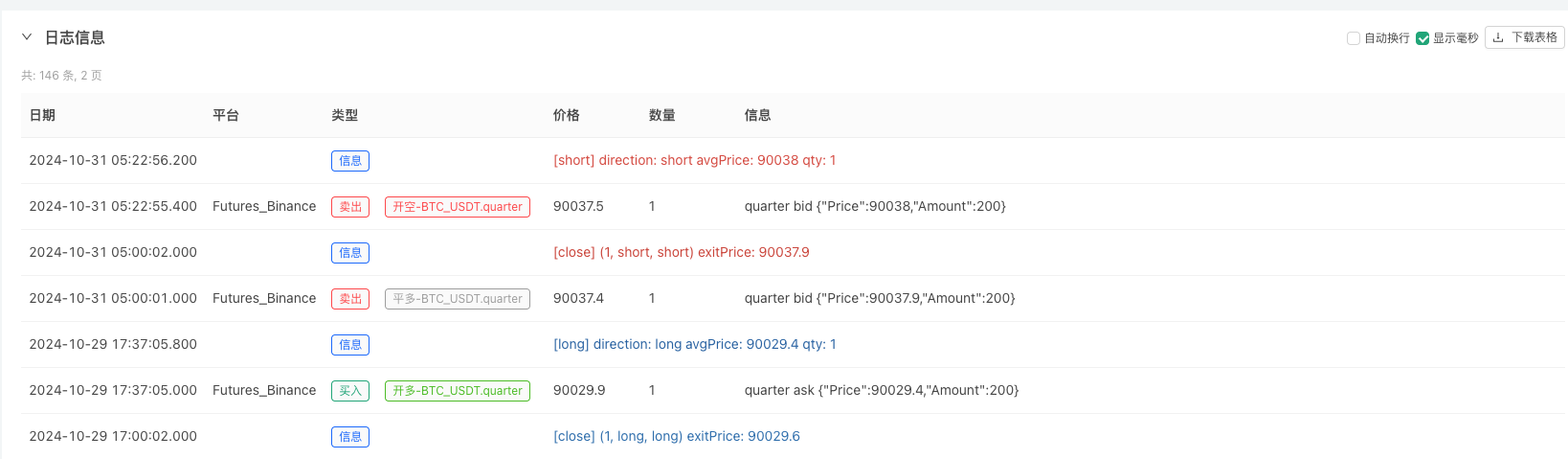
Pada ketika ini, sistem ujian belakang diuji menggunakan data simulasi “rekaan” kami. Menurut data dalam carta pasaran semasa ujian belakang, bandingkan data dalam carta masa nyata yang dijana oleh keadaan pasaran rawak Masa ialah 17:00 pada 16 Oktober 2024. Data adalah sama.
- Oh ya, saya hampir terlupa untuk mengatakannya! Sebab program Python penjana pasaran rawak ini mencipta pasaran sebenar adalah untuk memudahkan demonstrasi, operasi dan paparan data K-line yang dijana. Dalam aplikasi sebenar, anda boleh menulis skrip python bebas, jadi anda tidak perlu menjalankan cakera sebenar.
Kod sumber strategi:Penjana Sebut Harga Rawak Sistem Ujian Belakang
Terima kasih atas sokongan dan pembacaan anda.