Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian VII
Penulis:Kebaikan, Dicipta: 2019-03-26 10:52:49, Dikemas kini:Dalam artikel terakhir mengenai siri Event-Driven Backtester, kami telah mempertimbangkan hierarki ExecutionHandler asas. Dalam artikel ini kami akan membincangkan cara menilai prestasi strategi selepas backtest menggunakan kurva ekuiti DataFrame yang telah dibina sebelumnya dalam objek Portfolio.
Metrik Prestasi
Kami telah mempertimbangkan nisbah Sharpe dalam artikel sebelumnya. Dalam artikel itu saya menggariskan bahawa nisbah Sharpe (taunan) dikira melalui: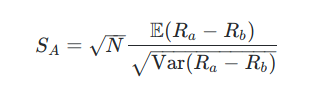
Di mana Ra adalah aliran pulangan kurva ekuiti dan Rb adalah penanda aras, seperti kadar faedah atau indeks ekuiti yang sesuai.
Pengeluaran maksimum dan tempoh pengeluaran adalah dua ukuran tambahan yang sering digunakan pelabur untuk menilai risiko dalam portfolio.
Dalam artikel ini kita akan melaksanakan nisbah Sharpe, pengeluaran maksimum dan tempoh pengeluaran sebagai ukuran prestasi portfolio untuk digunakan dalam Suite Ujian Kembali Berbasis Peristiwa berasaskan Python.
Pelaksanaan Python
Tugas pertama adalah untuk membuat fail baruperformance.py, yang menyimpan fungsi untuk mengira nisbah Sharpe dan maklumat drawdown. Seperti kebanyakan kelas berat pengiraan kita perlu mengimport NumPy dan panda:
# performance.py
import numpy as np
import pandas as pd
Perhatikan bahawa nisbah Sharpe adalah ukuran risiko untuk ganjaran (sebenarnya ia adalah salah satu daripada banyak!) Ia mempunyai satu parameter, iaitu bilangan tempoh yang perlu disesuaikan apabila meningkatkan nilai tahunan.
Biasanya nilai ini ditetapkan kepada 252, yang merupakan bilangan hari dagangan di AS setiap tahun. Walau bagaimanapun, jika strategi anda berdagang dalam satu jam, anda perlu menyesuaikan Sharpe untuk mempertajamnya dengan betul. Oleh itu, anda perlu menetapkan tempoh kepada 252
Fungsi create_sharpe_ratio beroperasi pada objek Siri panda yang dipanggil pulangan dan hanya mengira nisbah purata pulangan peratusan tempoh dan peratusan pulangan standard deviasi tempoh yang diskalakan oleh faktor tempoh:
# performance.py
def create_sharpe_ratio(returns, periods=252):
"""
Create the Sharpe ratio for the strategy, based on a
benchmark of zero (i.e. no risk-free rate information).
Parameters:
returns - A pandas Series representing period percentage returns.
periods - Daily (252), Hourly (252*6.5), Minutely(252*6.5*60) etc.
"""
return np.sqrt(periods) * (np.mean(returns)) / np.std(returns)
Walaupun nisbah Sharpe mencirikan berapa banyak risiko (seperti yang ditakrifkan oleh penyimpangan standard laluan aset) yang diambil setiap unit pulangan,
Fungsi create_drawdowns di bawah sebenarnya memberikan kedua-dua pengeluaran maksimum dan tempoh pengeluaran maksimum. Yang pertama adalah penurunan puncak ke bawah terbesar yang disebutkan di atas, sementara yang terakhir ditakrifkan sebagai bilangan tempoh di mana penurunan ini berlaku.
Terdapat beberapa kehalusan yang diperlukan dalam penafsiran tempoh pengeluaran kerana ia mengira tempoh dagangan dan oleh itu tidak boleh diterjemahkan secara langsung ke dalam unit masa seperti
Fungsi ini bermula dengan membuat dua objek siri panda yang mewakili penurunan dan tempoh pada setiap perdagangan
Penarikan kemudian hanya perbezaan antara HWM semasa dan lengkung ekuiti. Jika nilai ini negatif maka tempoh meningkat untuk setiap bar yang berlaku sehingga HWM seterusnya dicapai. Fungsi kemudian hanya mengembalikan maksimum setiap dua Siri:
# performance.py
def create_drawdowns(equity_curve):
"""
Calculate the largest peak-to-trough drawdown of the PnL curve
as well as the duration of the drawdown. Requires that the
pnl_returns is a pandas Series.
Parameters:
pnl - A pandas Series representing period percentage returns.
Returns:
drawdown, duration - Highest peak-to-trough drawdown and duration.
"""
# Calculate the cumulative returns curve
# and set up the High Water Mark
# Then create the drawdown and duration series
hwm = [0]
eq_idx = equity_curve.index
drawdown = pd.Series(index = eq_idx)
duration = pd.Series(index = eq_idx)
# Loop over the index range
for t in range(1, len(eq_idx)):
cur_hwm = max(hwm[t-1], equity_curve[t])
hwm.append(cur_hwm)
drawdown[t]= hwm[t] - equity_curve[t]
duration[t]= 0 if drawdown[t] == 0 else duration[t-1] + 1
return drawdown.max(), duration.max()
Untuk menggunakan ukuran prestasi ini, kita memerlukan cara untuk mengira mereka selepas ujian backtest telah dilakukan, iaitu apabila lengkung ekuiti yang sesuai tersedia!
Kita juga perlu mengaitkan pengiraan dengan hierarki objek tertentu. Memandangkan langkah-langkah prestasi dikira berdasarkan portfolio, masuk akal untuk melampirkan pengiraan prestasi kepada kaedah pada hierarki kelas portfolio yang kita bincangkan dalam artikel ini.
Tugas pertama adalah untuk membukaportfolio.pyseperti yang dibincangkan dalam artikel sebelumnya dan mengimport fungsi prestasi:
# portfolio.py
.. # Other imports
from performance import create_sharpe_ratio, create_drawdowns
Oleh kerana Portfolio adalah kelas asas abstrak, kita ingin melampirkan kaedah ke salah satu kelas turunan, yang dalam kes ini akan NaivePortfolio. Oleh itu kita akan membuat kaedah yang dipanggil output_summary_stats yang akan bertindak pada kurva ekuiti portfolio untuk menjana maklumat Sharpe dan penarikan.
Kaedah ini mudah. Ia hanya menggunakan dua langkah prestasi dan menerapkannya terus ke pandas dataframe, mengeluarkan statistik sebagai senarai tuples dengan cara yang mesra format:
# portfolio.py
..
..
class NaivePortfolio(object):
..
..
def output_summary_stats(self):
"""
Creates a list of summary statistics for the portfolio such
as Sharpe Ratio and drawdown information.
"""
total_return = self.equity_curve['equity_curve'][-1]
returns = self.equity_curve['returns']
pnl = self.equity_curve['equity_curve']
sharpe_ratio = create_sharpe_ratio(returns)
max_dd, dd_duration = create_drawdowns(pnl)
stats = [("Total Return", "%0.2f%%" % ((total_return - 1.0) * 100.0)),
("Sharpe Ratio", "%0.2f" % sharpe_ratio),
("Max Drawdown", "%0.2f%%" % (max_dd * 100.0)),
("Drawdown Duration", "%d" % dd_duration)]
return stats
Jelas ini adalah analisis prestasi yang sangat mudah untuk portfolio. ia tidak mengambil kira analisis peringkat perdagangan atau ukuran lain risiko / ganjaran.performance.pydan kemudian menggabungkannya ke output_summary_stat seperti yang diperlukan.
- Panduan Pemula untuk Analisis Siri Masa
- Ujian semula Strategi Ramalan untuk S & P500 di Python dengan panda
Selalu faham bila untuk berhenti 6 strategi keluar - FMZ Komuniti Interaktif
- Apakah pelbagai jenis dana kuant?
- Pengujian Kembali Strategi Pasangan Pembalikan Rata-rata Intraday Antara SPY Dan IWM
- Uji balik crossover purata bergerak di Python dengan panda
- Cara Mengenal pasti Strategi Dagangan Algoritma
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian VIII
- Siri Pelaburan Kuantitatif Blockchain - Strategi Keseimbangan Dinamik
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian VI
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian V
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian IV
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian III
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian II
- Pengujian Kembali yang Dikendalikan Acara dengan Python - Bahagian I
- Permohonan untuk menambah API kucoin
- Berjaya Backtesting Strategi Dagangan Algoritma - Bahagian II
- hbdm dan ok kontrak menggunakan websocket pada masa yang sama, huobi keluar pong tidak bertindak balas
- Ujian Balik Berjaya Strategi Dagangan Algoritma - Bahagian I