Penggunaan teknologi pembelajaran mesin dalam transaksi
Penulis:Kebaikan, Dicipta: 2019-08-29 09:42:00, Dikemas kini: 2023-10-19 21:02:44
Artikel ini diilhamkan oleh pengamatan saya terhadap beberapa amaran dan perangkap yang biasa berlaku selepas saya cuba menggunakan teknologi pembelajaran mesin untuk masalah perdagangan semasa menjalankan kajian data di platform kuantiti pencipta.
Jika anda belum membaca artikel saya sebelum ini, kami cadangkan anda membaca panduan saya mengenai persekitaran penyelidikan data automatik dan kaedah sistemik untuk membuat strategi dagangan yang dibina di platform kuantiti pencipta sebelum artikel ini.
Di sini adalah alamatnya:https://www.fmz.com/digest-topic/4187danhttps://www.fmz.com/digest-topic/4169 这两篇文章.
Mengenai pembinaan persekitaran penyelidikan
Tutorial ini direka untuk digunakan oleh peminat, jurutera, dan saintis data dari semua peringkat kemahiran. Sama ada anda seorang ahli industri atau pengaturcara kecil, satu-satunya kemahiran yang anda perlukan adalah pengetahuan asas mengenai bahasa pengaturcaraan Python dan pengetahuan yang mencukupi mengenai operasi baris arahan (untuk menubuhkan projek sains data)
- Memasang Inventor Quantify Host dan menyediakan Anaconda
发明者量化平台FMZ.COM除了提供优质的各大主流交易所的数据源,还提供一套丰富的API接口以帮助我们在完成数据的分析后进行自动化交易。这套接口包括查询账户信息,查询各个主流交易所的高,开,低,收价格,成交量,各种常用技术分析指标等实用工具,特别是对于实际交易过程中连接各大主流交易所的公共API接口,提供了强大的技术支持。
Semua ciri-ciri yang disebutkan di atas telah dibungkus ke dalam sistem seperti Docker, dan apa yang perlu kita lakukan ialah membeli atau menyewa perkhidmatan awan anda sendiri dan kemudian anda boleh menggunakan sistem Docker ini.
Dalam nama rasmi platform kuantiti pencipta, sistem Docker ini dikenali sebagai sistem hosts.
Untuk maklumat mengenai cara menggunakan pentadbir dan bot, sila rujuk artikel saya sebelum ini:https://www.fmz.com/bbs-topic/4140
Untuk pembaca yang ingin membeli pelayan pelayaran pelayaran awan mereka sendiri, lihat artikel ini:https://www.fmz.com/bbs-topic/2848
Selepas berjaya menggunakan perkhidmatan dan sistem pentadbir awan yang baik, seterusnya kita akan memasang python terbesar: Anaconda
Untuk mewujudkan semua persekitaran program yang berkaitan yang diperlukan untuk artikel ini (dependencies, version management, dan lain-lain), cara yang paling mudah adalah dengan menggunakan Anaconda. Ia adalah ekosistem sains data Python yang terbungkus dan pengurus perpustakaan bergantung.
Oleh kerana kami memasang Anaconda pada perkhidmatan awan, kami mengesyorkan pelayan awan memasang versi Anaconda pada sistem Linux dengan baris perintah.
Untuk cara memasang Anaconda, sila lihat panduan rasmi Anaconda:https://www.anaconda.com/distribution/
Jika anda seorang pengaturcara Python yang berpengalaman dan tidak mahu menggunakan Anaconda, tidak ada masalah. Saya akan menganggap anda tidak memerlukan bantuan dalam memasang persekitaran bergantung yang diperlukan, anda boleh melangkau bahagian ini.
Mengembangkan strategi perdagangan
Output akhir strategi dagangan harus menjawab soalan berikut:
Arahan: Menentukan sama ada aset itu murah, mahal atau bernilai adil.
开仓条件:如果资产价格便宜或者昂贵,你应该做多或者做空.
Perdagangan neraca: Jika harga aset adalah wajar dan kami memegang kedudukan dalam aset tersebut (pembelian atau penjualan sebelumnya), adakah anda harus neraca
Julat harga: harga (atau julat) untuk perdagangan terbuka
Jumlah: Jumlah dana yang diperdagangkan (misalnya jumlah mata wang digital atau jumlah tangan pada masa hadapan komoditi)
Pembelajaran mesin boleh digunakan untuk menjawab setiap soalan di atas, tetapi untuk bahagian yang lain dalam artikel ini, kami akan memberi tumpuan kepada soalan pertama, iaitu arah perdagangan.
Kaedah Strategik
Untuk membina strategi, terdapat dua jenis pendekatan, satu adalah berdasarkan model; yang lain adalah berdasarkan penggalian data. Kedua-duanya adalah pendekatan yang sangat bertentangan.
Dalam pembinaan strategi berasaskan model, kita bermula dengan model kecekapan rendah pasaran, membina ungkapan matematik (seperti harga, keuntungan) dan menguji keberkesanannya dalam kitaran masa yang lebih lama. Model ini biasanya merupakan versi yang disederhanakan dari model yang benar-benar kompleks, yang memerlukan pengesahan makna dan kestabilan kitaran panjangnya.
Sebaliknya, kita mula mencari corak harga dan cuba menggunakan algoritma dalam kaedah perlombongan data; sebab-sebab yang menyebabkan corak-corak ini tidak penting, kerana hanya corak-corak tertentu yang akan terus berulang pada masa akan datang. Ini adalah kaedah analisis buta, yang memerlukan pemeriksaan yang ketat untuk mengenal pasti corak yang benar dari corak rawak. Corak eksperimen berulang-ulang, corak corak corak corak corak corak corak corak corak corak corak corak corak corak corak dan ciri-ciri corak banyak regresi tergolong dalam kategori ini.
Jelasnya, pembelajaran mesin mudah digunakan untuk kaedah perlombongan data. Mari kita lihat bagaimana menggunakan pembelajaran mesin untuk membuat isyarat dagangan melalui perlombongan data.
Contoh kod menggunakan alat penyesuaian berdasarkan platform kuantiti pencipta dan antarmuka API urus niaga automatik. Setelah anda mengimplementasikan hoster dan memasang Anaconda di bahagian di atas, anda hanya perlu memasang perpustakaan analisis sains data yang anda perlukan dan model pembelajaran mesin terkenal scikit-learn. Kami tidak akan membincangkan apa yang ada di bahagian ini.
pip install -U scikit-learn
Menggunakan pembelajaran mesin untuk mencipta isyarat strategi dagangan
- Penggalian data
Sebelum kita mula, satu sistem masalah pembelajaran mesin standard adalah seperti yang ditunjukkan di bawah:
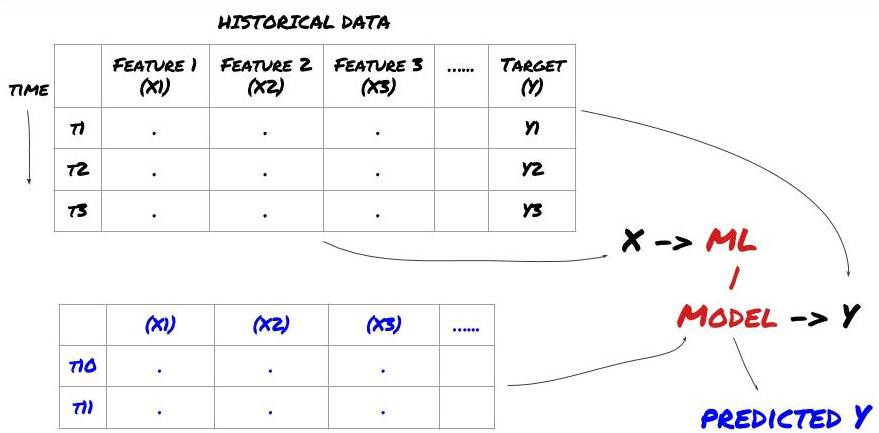
Sistem masalah pembelajaran mesin
Ciri-ciri yang akan kita cipta mesti mempunyai beberapa keupayaan ramalan (x), kita mahu ramalan pembolehubah sasaran (y), dan menggunakan data sejarah untuk melatih model ML yang boleh meramalkan Y sebagai hampir dengan nilai sebenar. Akhirnya, kita menggunakan model ini untuk meramalkan data baru yang tidak diketahui oleh y. Ini membawa kita ke langkah pertama:
Langkah 1: Tetapkan masalah anda
- Apakah ramalan yang anda ingin buat? Apakah ramalan yang baik? Bagaimana anda menilai hasil ramalan?
Maksud saya, dalam kerangka di atas, apa Y?
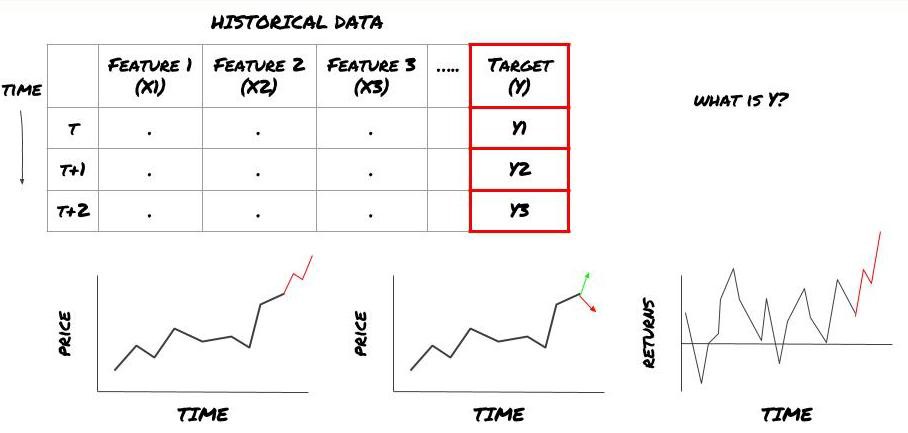
Apa yang anda mahu ramalkan?
Adakah anda ingin meramalkan harga masa depan, pulangan masa depan / Pnl, isyarat beli / jual, mengoptimumkan peruntukan portfolio dan cuba melaksanakan perdagangan dengan cekap?
Katakan kita cuba meramalkan harga pada waktu berikutnya. Dalam kes ini, Y ((t) = harga ((t + 1)). Sekarang kita boleh melengkapkan rangka kerja kita dengan data sejarah.
Perhatikan bahawa Y (t) hanya diketahui dalam retrospeksi, tetapi apabila kita menggunakan model kita, kita tidak akan tahu harga masa t (t + 1) ; kita menggunakan model kita untuk meramalkan Y (t) dan membandingkannya dengan nilai sebenar hanya pada masa t + 1; ini bermakna anda tidak boleh menggunakan Y sebagai ciri dalam model ramalan.
Setelah kita mengetahui sasaran Y, kita juga boleh membuat keputusan bagaimana menilai ramalan kita. Ini sangat penting untuk membezakan antara model yang berbeza yang akan kita uji data. Mengikut masalah yang kita selesaikan, pilih satu metrik yang mengukur kecekapan model kita. Sebagai contoh, jika kita meramalkan harga, kita boleh menggunakan kesalahan akar rata sebagai metrik.
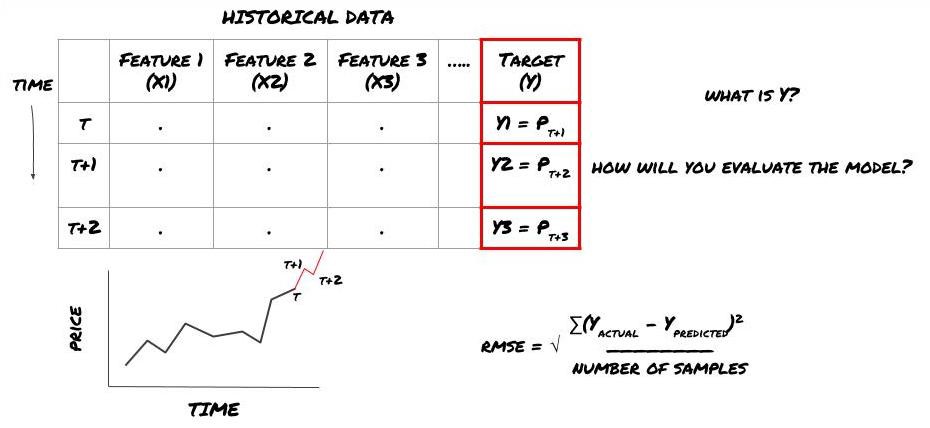
Rangka kerja ML untuk meramalkan harga masa depan
Untuk demonstrasi, kita akan membuat model ramalan untuk meramalkan nilai asas jangka masa depan yang dijangkakan untuk suatu aset yang diasumsikan, di mana:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Oleh kerana ini adalah masalah regresi, kita akan menilai model pada RMSE (kesesatan akar persamaan); kita juga akan menggunakan Total Pnl sebagai kriteria penilaian
Nota: Untuk pengetahuan matematik mengenai RMSE, sila rujuk Ensiklopedia
- 我们的目标:创建一个模型,使预测值尽可能接近Y.
Langkah 2: Kumpulkan data yang boleh dipercayai
Mengumpul dan membersihkan data yang boleh membantu anda menyelesaikan masalah yang anda hadapi
Jika kita meramalkan harga, anda boleh menggunakan data harga tanda pelaburan, data jumlah dagangan tanda pelaburan, data serupa tanda pelaburan yang berkaitan, indeks indeks keparitahanan pasaran keseluruhan, harga aset lain yang berkaitan, dan sebagainya.
Anda perlu menetapkan keizinan akses data untuk ini dan memastikan data anda adalah tepat dan tidak salah, dan menyelesaikan data yang hilang (masalah yang sangat biasa); sambil memastikan data anda tidak berat sebelah dan mewakili sepenuhnya semua keadaan pasaran (contohnya, jumlah yang sama senario keuntungan dan kerugian) untuk mengelakkan penyimpangan dalam model; anda mungkin juga perlu membersihkan data untuk mendapatkan dividen, pembahagian tanda pelaburan, kesinambungan, dan lain-lain.
Jika anda menggunakan platform kuantiti pencipta (FMZ.COM), kita boleh mengakses data global percuma dari Google, Yahoo, NSE, dan Quandl; data mendalam mengenai niaga hadapan komoditi domestik seperti CTP dan EOS; dan data dari pertukaran mata wang digital utama seperti Binance, OKEX, Huobi, dan BitMex. Platform kuantiti pencipta juga membersihkan dan menapis data ini terlebih dahulu, seperti pemisahan tanda pelaburan dan data perbelanjaan mendalam, dan membentangkannya kepada pemaju strategi dalam format yang mudah difahami oleh pekerja kuantiti.
Untuk memudahkan demonstrasi artikel ini, kami menggunakan data berikut sebagai tanda pelaburan maya untuk ketumbar MQK, dan kami juga menggunakan alat pengukuran yang sangat mudah yang dipanggil Alat Alat Ketumbar Auquan, untuk maklumat lanjut, sila lihat:https://github.com/Auquan/auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Dengan kod di atas, Auquan
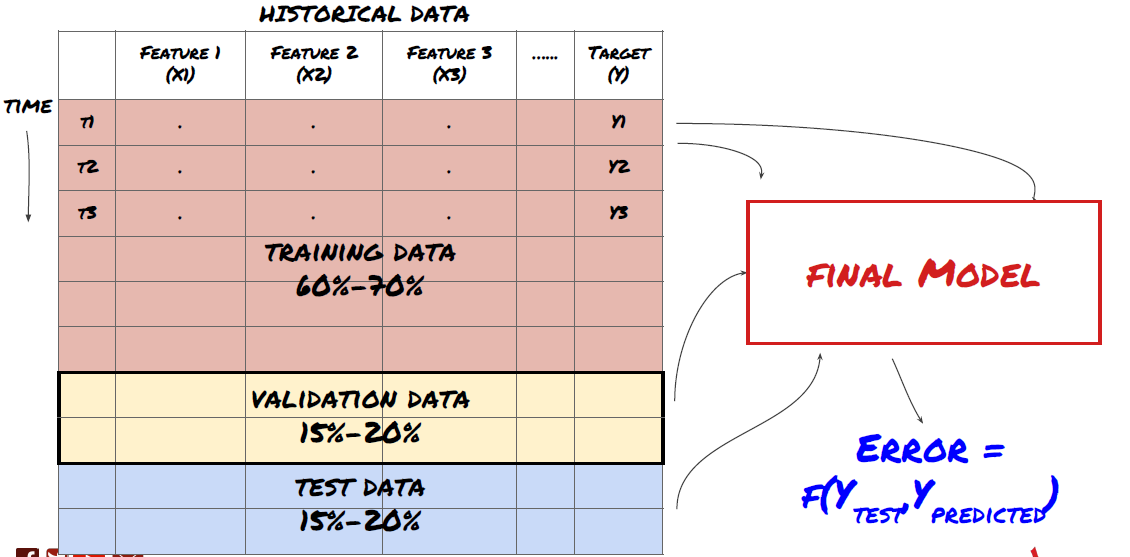
Langkah ketiga: Memisahkan data
- Buat set latihan dari data, cross-validate dan uji set ini
Ini adalah langkah yang sangat penting!Sebelum kita teruskan, kita harus membahagikan data kepada set data latihan untuk melatih model anda; set data ujian untuk menilai prestasi model; disyorkan untuk membahagikan kepada: 60-70% set latihan dan 30-40% set ujian
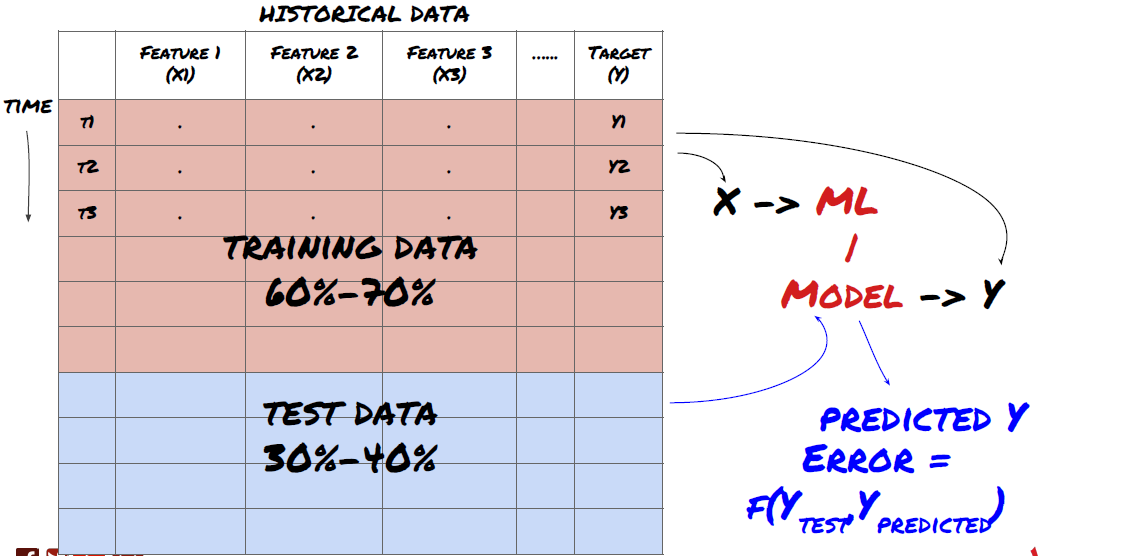
Memisahkan data kepada kumpulan latihan dan kumpulan ujian
Oleh kerana data latihan digunakan untuk menilai parameter model, model anda mungkin terlalu sesuai dengan data latihan ini, dan data latihan akan menyesatkan prestasi model. Jika anda tidak menyimpan data ujian yang berasingan dan menggunakan semua data untuk latihan, anda tidak akan tahu seberapa baik atau buruk model anda melaksanakan data baru yang tidak kelihatan. Ini adalah salah satu sebab utama mengapa model ML yang terlatih gagal dengan data masa nyata: orang melatih semua data yang tersedia dan teruja dengan indikator data latihan, tetapi model itu tidak dapat membuat sebarang ramalan yang bermakna terhadap data masa nyata yang tidak terlatih.
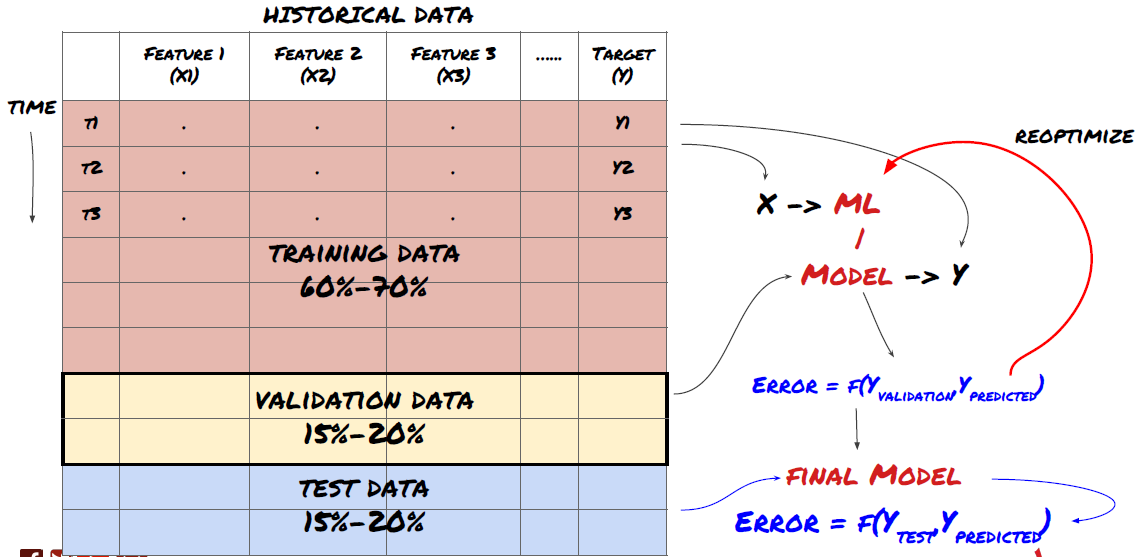
Memisahkan data kepada kumpulan latihan, kumpulan pengesahan dan kumpulan ujian
Terdapat masalah dengan pendekatan ini. Jika kita berulang kali melatih data latihan, menilai prestasi data ujian dan mengoptimumkan model kita sehingga kita berpuas hati dengan prestasi, kita secara tidak langsung menjadikan data ujian sebagai sebahagian daripada data latihan. Akhirnya, model kita mungkin berfungsi dengan baik pada kumpulan data latihan dan ujian ini, tetapi tidak dapat menjamin ia dapat meramalkan data baru dengan baik.
Untuk menyelesaikan masalah ini, kita boleh membuat satu set data pengesahan yang berasingan. Sekarang, anda boleh melatih data, menilai prestasi data pengesahan, mengoptimumkan sehingga anda berpuas hati dengan prestasi, dan akhirnya menguji data ujian. Dengan cara ini, data ujian tidak akan tercemar, dan kita tidak akan menggunakan apa-apa maklumat dalam data ujian untuk memperbaiki model kami.
Ingatlah bahawa apabila prestasi data ujian telah diperiksa, jangan kembali dan cuba mengoptimumkan model lebih lanjut. Jika anda mendapati model anda tidak memberikan hasil yang baik, buang model itu sepenuhnya dan mulakan semula. Ia disyorkan untuk membahagikan 60% data latihan, 20% data pengesahan dan 20% data ujian.
Untuk soalan kami, kami mempunyai tiga set data yang tersedia, dan kami akan menggunakan satu sebagai set latihan, satu sebagai set pengesahan, dan satu sebagai set ujian kami.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Untuk masing-masing, kita menambah pembolehubah sasaran Y, yang ditakrifkan sebagai purata lima nilai asas seterusnya.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Langkah keempat: Senibina ciri
Menganalisis tingkah laku data dan mencipta ciri-ciri yang boleh diramalkan
Sekarang, pembinaan sebenar telah bermula. Aturan emas pemilihan ciri adalah bahawa kemampuan untuk meramalkan datang terutamanya dari ciri, bukan model. Anda akan mendapati bahawa pilihan ciri mempunyai kesan yang jauh lebih besar terhadap prestasi daripada pilihan model.
Jangan memilih sekumpulan ciri secara rawak tanpa meneroka hubungan dengan pembolehubah sasaran.
Keadaan yang kurang atau tidak berkaitan dengan pembolehubah sasaran boleh menyebabkan pemasangan berlebihan
Ciri-ciri yang anda pilih mungkin sangat berkaitan antara satu sama lain, dan dalam kes ini, bilangan ciri yang lebih kecil juga boleh menerangkan matlamat.
Saya biasanya membuat ciri-ciri intuitif untuk melihat bagaimana pemboleh ubah sasaran berkaitan dengan ciri-ciri ini, dan bagaimana mereka berkaitan untuk memutuskan mana yang akan digunakan.
Anda juga boleh cuba mengurutkan ciri calon berdasarkan MIC, melakukan analisis bahan utama (PCA) dan kaedah lain.
Pergeseran ciri/normalizasi:
Model ML sering melakukan dengan baik dalam hal standardisasi. Walau bagaimanapun, normalizasi sukar apabila memproses data siri masa kerana jangkauan data masa depan tidak diketahui. Data anda mungkin berada di luar jangkauan standardisasi dan menyebabkan kesilapan model.
Meningkatkan: Ciri-ciri pembahagian mengikut perbezaan standard atau empat digit
Penduduk: Kurangkan purata sejarah daripada nilai semasa
Penyatuan: dua tempoh retrospektif ((x - mean) / stdev di atas
Penyerapan biasa: standardkan data dalam jangka masa rektum ((x-min) / ((max-min) dari -1 hingga +1 dan tentukan semula pusat
Perhatikan bahawa kerana kita menggunakan purata berturut-turut sejarah, kelainan standard, maksimum atau minimum melebihi tempoh retrospektif, nilai standardisasi yang disamakan ciri akan menunjukkan nilai sebenar yang berbeza pada masa yang berlainan. Sebagai contoh, jika nilai semasa ciri adalah 5, purata 30 kitaran berturut-turut adalah 4.5, maka ia akan ditukar kepada 0.5 selepas berada; selepas itu, jika purata 30 kitaran berturut-turut berubah menjadi 3, maka nilai 3.5 akan menjadi 0.5; ini mungkin menyebabkan kesilapan model. Oleh itu, normalisasi sukar, dan anda mesti mencari tahu apa yang sebenarnya meningkatkan prestasi model (jika ada).
Untuk iterasi pertama dalam masalah kami, kami menggunakan parameter campuran untuk mencipta banyak ciri. Kami akan cuba melihat jika bilangan ciri dapat dikurangkan kemudian.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Langkah 5: Pilih model
Memilih model statistik/ML yang sesuai mengikut soalan yang dipilih
Pemilihan model bergantung kepada bagaimana masalah itu dibina. Adakah anda menyelesaikan masalah pengawasan (setiap titik X dalam matriks ciri dipetakan kepada pembolehubah sasaran Y) atau masalah pembelajaran tanpa pengawasan (tidak ada pemetaan yang diberikan, model cuba mempelajari pola yang tidak diketahui)? Adakah anda menyelesaikan masalah regresi (memprediksi harga sebenar pada masa akan datang) atau masalah klasifikasi (hanya meramalkan arah harga pada masa akan datang) (meningkatkan / mengurangkan))

Pengawasan atau pembelajaran tanpa pengawasan

Kembali or Kategori
Beberapa algoritma pembelajaran pengawasan yang biasa digunakan dapat membantu anda memulakan:
Regresi linear (parameter, regresi)
Logistic regression (parameter, klasifikasi)
K berdekatan (KNN) algoritma (Berdasarkan contoh, regresi)
SVM, SVR (parameter, klasifikasi dan regresi)
Pokok Keputusan
Hutan Keputusan
Saya cadangkan untuk memulakan dengan model yang mudah, seperti linear atau logical regression, dan membina model yang lebih kompleks dari sana jika perlu. Saya juga cadangkan anda membaca matematik di sebalik model, dan bukannya menggunakannya secara buta sebagai kotak hitam.
Langkah 6: Latihan, pengesahan dan pengoptimuman (ulang langkah 4-6)
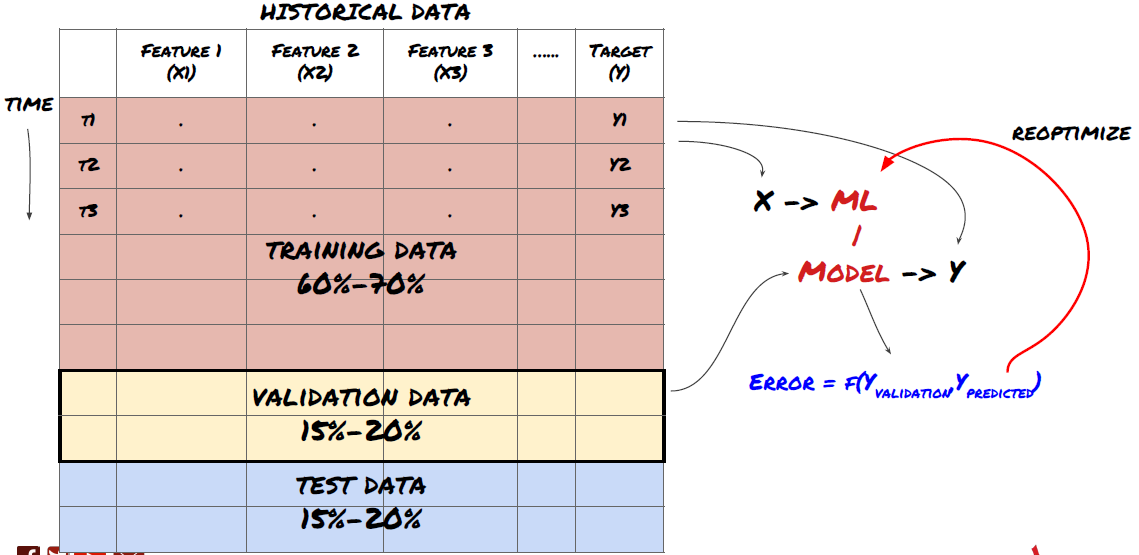
Latih dan optimumkan model anda dengan menggunakan latihan dan pengesahan dataset
Sekarang, anda sudah bersedia untuk membina model akhir. Pada peringkat ini, anda benar-benar hanya mengulangi model dan parameter model. Latih model anda pada data latihan, mengukur prestasi pada data pengesahan, dan kemudian kembali, mengoptimumkan, melatih semula, dan menilai. Jika anda tidak berpuas hati dengan prestasi model, cuba menggunakan model lain.
Hanya apabila anda mempunyai model yang anda sukai, teruskan dengan langkah seterusnya.
Untuk masalah persembahan kita, mari kita mulakan dengan regresi linear yang mudah.
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
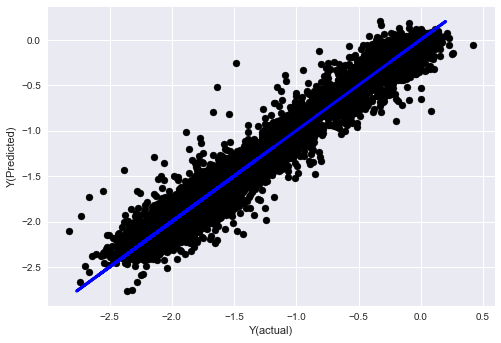
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
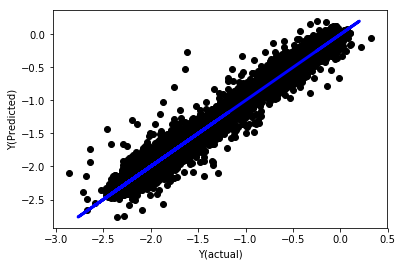
Regresi linear tanpa penyatuan
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Lihatlah faktor model. Kita tidak boleh benar-benar membandingkannya atau mengatakan mana yang penting, kerana mereka semua berada pada skala yang berbeza. Mari kita cuba mengintegrasikan mereka supaya mereka sesuai dengan nisbah yang sama dan juga memaksa beberapa keteraturan.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
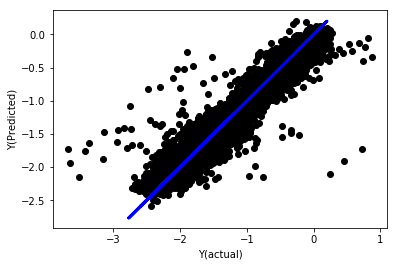
Kembali linear kepada integrasi
Mean squared error: 0.05
Variance score: 0.90
Model ini tidak meningkatkan model sebelumnya, tetapi juga tidak lebih buruk. Sekarang kita boleh membandingkan faktor yang sebenarnya dan melihat faktor mana yang sebenarnya penting.
Mari kita lihat kepada pekali.
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Hasilnya ialah:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Kita dapat melihat dengan jelas bahawa ciri-ciri tertentu mempunyai faktor yang lebih tinggi berbanding ciri-ciri lain dan mungkin mempunyai keupayaan ramalan yang lebih kuat.
Mari kita lihat hubungan antara ciri-ciri yang berbeza.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
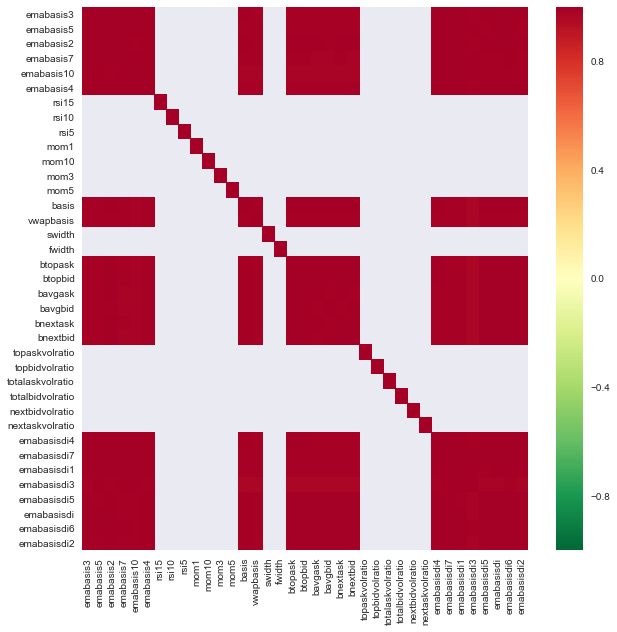
Kaitan antara ciri
Kawasan merah gelap menunjukkan pembolehubah yang sangat berkaitan. Mari kita mencipta/mengubah beberapa ciri lagi dan cuba memperbaiki model kita.
例如,我可以轻松地丢弃像emabasisdi7这样的特征,这些特征只是其他特征的线性组合.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
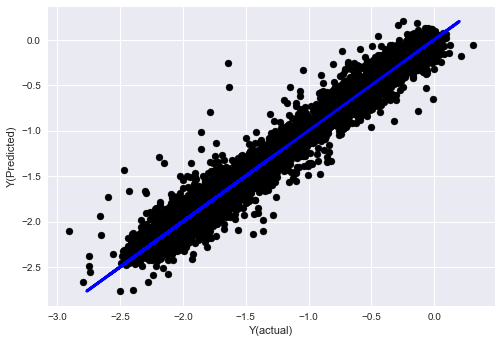
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Lihat, prestasi model kami tidak berubah, kami hanya memerlukan beberapa ciri untuk menerangkan pembolehubah sasaran kami. Saya cadangkan anda mencuba lebih banyak ciri di atas, cuba kombinasi baru, dan sebagainya, untuk melihat apa yang dapat meningkatkan model kami.
我们还可以尝试更复杂的模型,看看模型的变化是否可以提高性能.
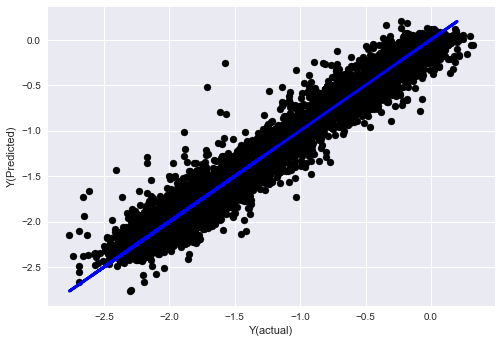
- Algoritma K berdekatan (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
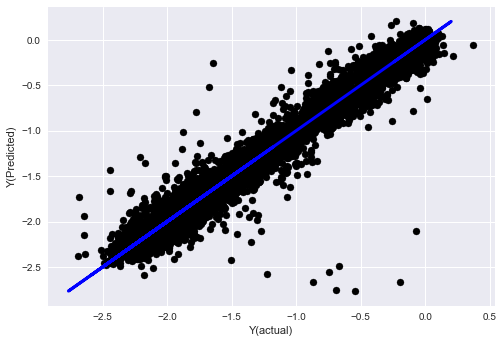
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Pokok Keputusan
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Langkah 7: Uji semula data ujian
Memeriksa prestasi data sampel sebenar
Prestasi retest pada dataset ujian (tidak lagi disentuh)
Ini adalah masa penting. Kami mulakan dari langkah terakhir data ujian untuk menjalankan model pengoptimuman akhir kami, dan kami mengetepikannya pada mulanya, data yang belum dihubungi setakat ini.
Ini memberi anda jangkaan yang praktikal tentang bagaimana model anda akan menjalankan data baru dan yang belum dilihat apabila anda mula berdagang secara langsung. Oleh itu, adalah penting untuk memastikan anda mempunyai satu set data yang bersih yang tidak digunakan untuk melatih atau mengesahkan model.
Jika anda tidak suka hasil uji semula data ujian, sila buang model dan mulakan semula. Jangan kembali untuk mengoptimumkan semula model anda, ini akan menyebabkan terlalu banyak kesesuaian!
Di sini, kita masih akan menggunakan Alat Perkakasan Auquan.
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
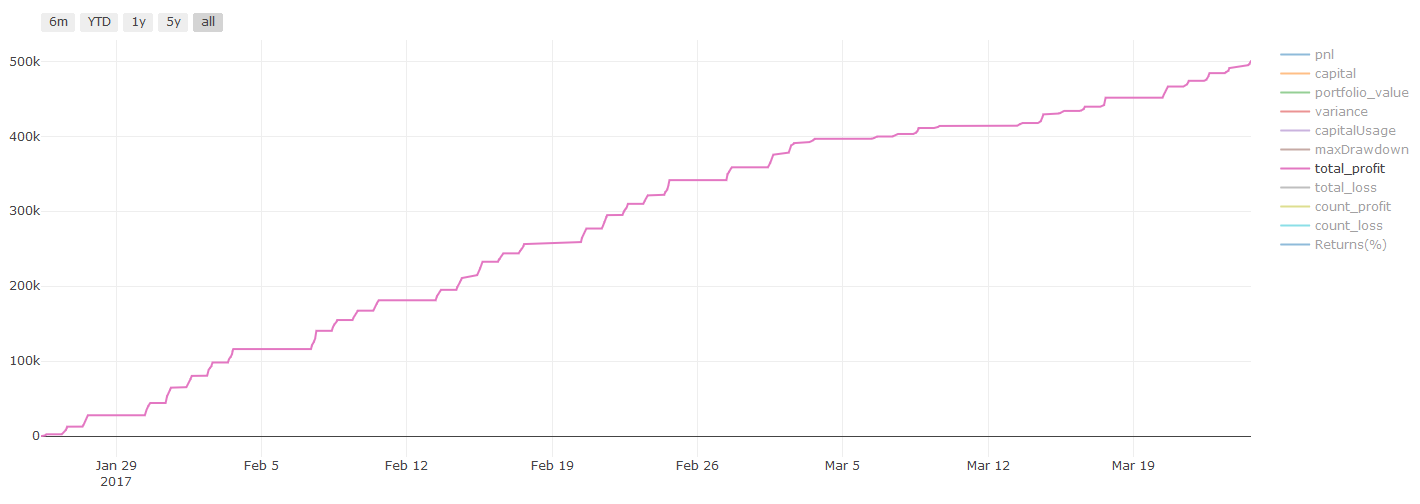
Hasil ujian semula, Pnl dalam dolar (Pnl tidak termasuk kos urus niaga dan kos lain)
Langkah 8: Cara lain untuk memperbaiki model
Pengujian bergulir, pembelajaran kumpulan, Bagging dan Boosting
Selain mengumpul lebih banyak data, mencipta ciri yang lebih baik atau mencuba lebih banyak model, ini adalah beberapa perkara yang boleh anda cuba untuk memperbaiki.
1. Pengesahan bergulir
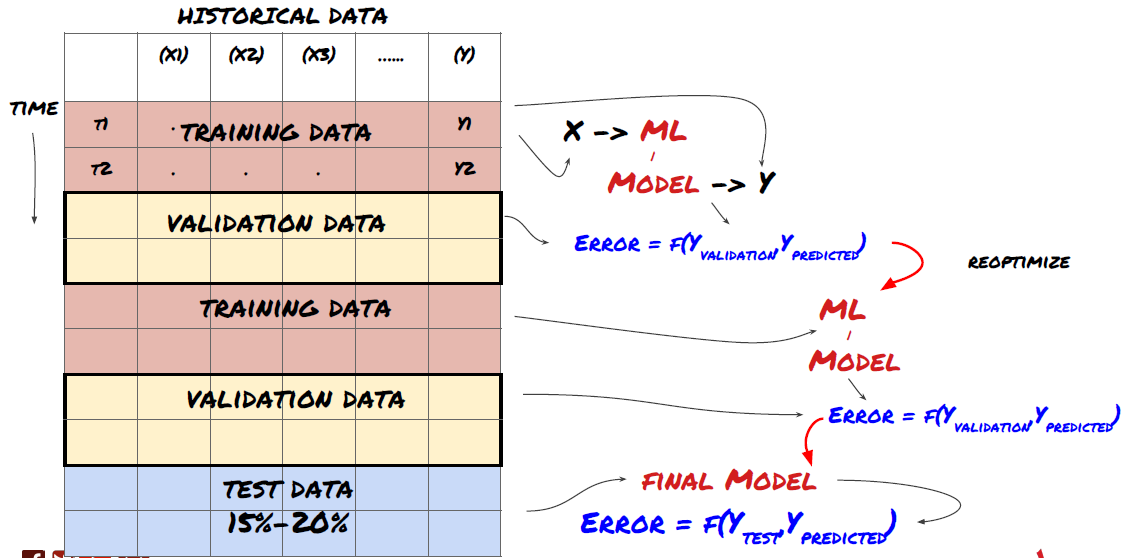
Pengesahan bergulir
Keadaan pasaran jarang berubah. Jika anda mempunyai data setahun dan anda melatih dengan data Januari hingga Ogos, dan menggunakan data September hingga Disember untuk menguji model anda, anda mungkin akhirnya melatih untuk satu set keadaan pasaran yang sangat spesifik. Mungkin tidak ada turun naik pasaran pada separuh pertama tahun, beberapa berita ekstrem menyebabkan pasaran meningkat dengan ketara pada bulan September, model anda tidak dapat mempelajari corak ini dan akan memberikan anda ramalan sampah.
Mungkin lebih baik untuk mencuba pengesahan bergulir ke hadapan, latihan Januari hingga Februari, pengesahan Mac, latihan semula April hingga Mei, pengesahan Jun, dan sebagainya.
2. Pembelajaran bersama
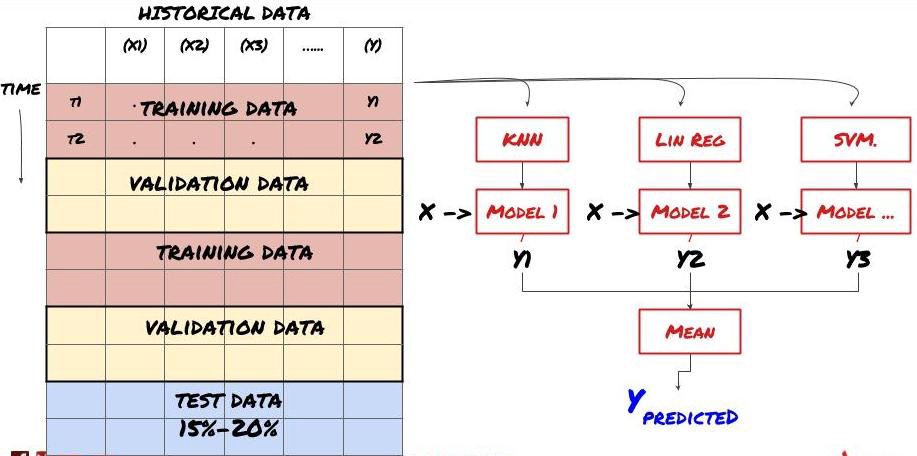
Pembelajaran Bersama
Sesetengah model mungkin berfungsi dengan baik dalam meramalkan beberapa senario, tetapi dalam meramalkan beberapa senario lain atau dalam keadaan tertentu, model mungkin sangat terlalu sesuai. Salah satu kaedah untuk mengurangkan kesilapan dan terlalu sesuai adalah dengan menggunakan kumpulan model yang berbeza. Ramalan anda akan menjadi purata ramalan yang dibuat oleh banyak model, dan kesalahan model yang berbeza mungkin akan diimbangi atau dikurangkan. Beberapa kaedah pengumpulan yang biasa adalah Bagging dan Boosting.
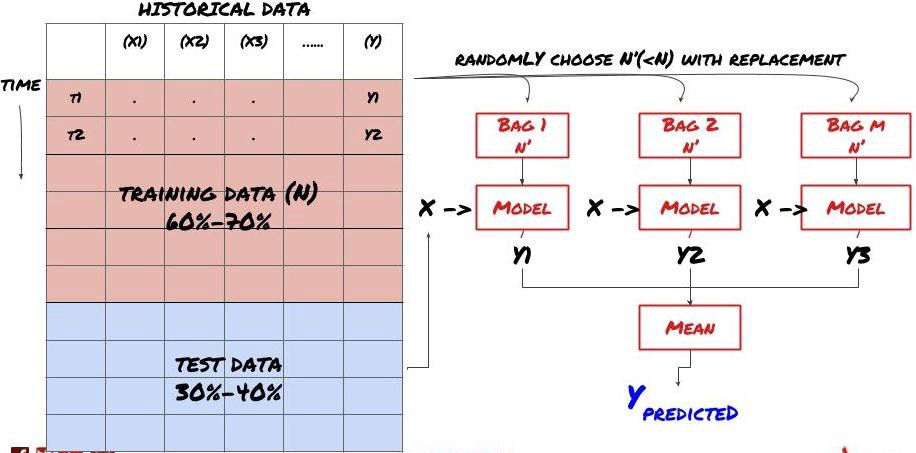
Pengemas
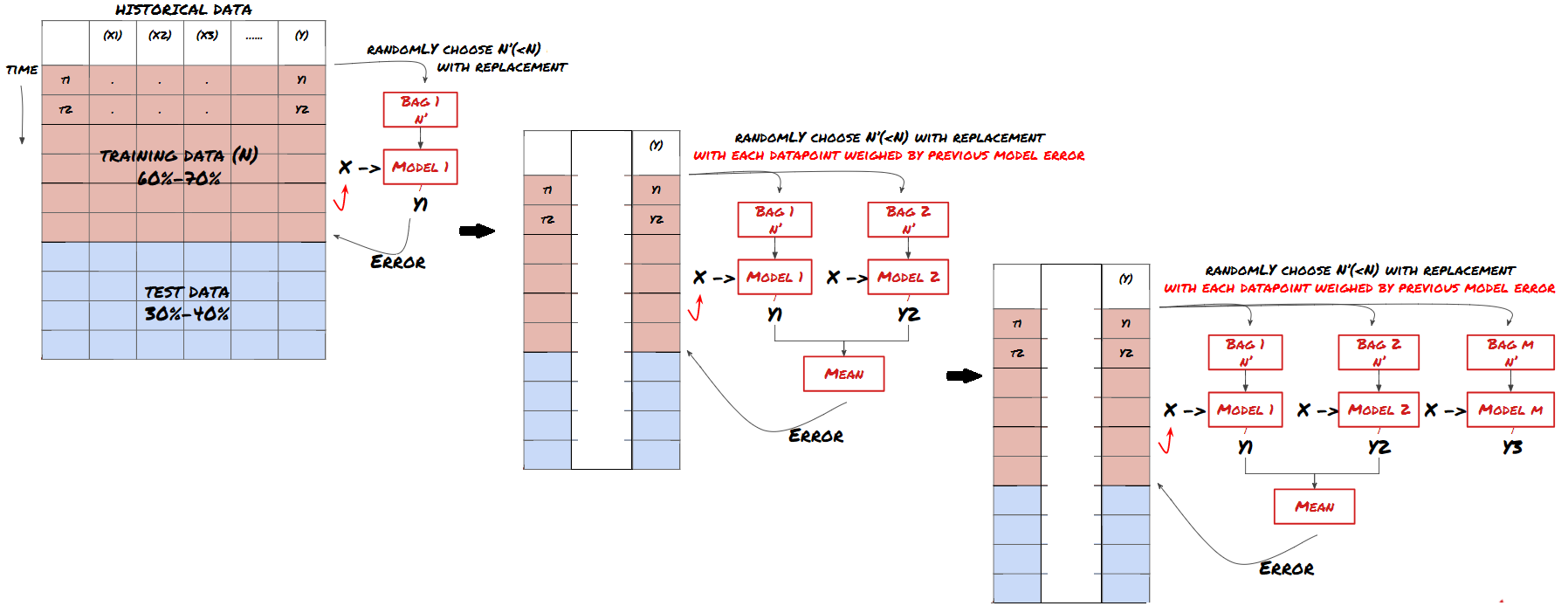
Meningkatkan
Untuk permulaan yang ringkas, saya akan melangkau kaedah ini, tetapi anda boleh mencari maklumat yang lebih berkaitan di internet.
Mari kita cuba satu pendekatan kumpulan untuk masalah kita.
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Kami telah mengumpulkan banyak pengetahuan dan maklumat setakat ini. Mari kita lihat semula dengan cepat:
Menguruskan Masalah Anda
Mengumpul data yang boleh dipercayai dan membersihkan data
Memisahkan data kepada kumpulan latihan, pengesahan dan ujian
Mencipta ciri dan menganalisis tingkah lakunya
Memilih model latihan yang sesuai berdasarkan tingkah laku
Gunakan data latihan untuk melatih model anda dan membuat ramalan
Memeriksa prestasi dan mengoptimumkan semula set simpanan
Memeriksa prestasi akhir kit ujian
Adakah anda fikir ini adalah awal? Tetapi belum selesai, anda hanya mempunyai satu model ramalan yang boleh dipercayai sekarang. Ingat apa yang kita benar-benar mahu dalam strategi kami?
Membangunkan isyarat berdasarkan model ramalan untuk mengenal pasti arah dagangan
Mengembangkan strategi khusus untuk mengenal pasti kedudukan terbuka
Sistem pelaksanaan untuk mengenal pasti kedudukan dan harga
Semua ini perlu digunakan untuk platform Kuantiti Pencipta (FMZ.COM), di platform Kuantiti Pencipta, dengan antarmuka API yang sangat lengkap dan sempurna, dan fungsi pesanan bawah dan perdagangan yang boleh dipanggil secara global, tanpa anda perlu menyambung secara individu dan menambahkan antara muka API pertukaran yang berbeza, di Dataran Strategi Platform Kuantiti Pencipta, terdapat banyak strategi alternatif yang matang dan lengkap, dengan menggunakan kaedah pembelajaran mesin dalam artikel ini, akan menjadikan strategi khusus anda seperti burung harimau. Dataran Strategi terletak di:https://www.fmz.com/square
Maklumat penting mengenai kos transaksi:你的模型会告诉你所选资产何时是做多或做空。然而,它没有考虑费用/交易成本/可用交易量/止损等。交易成本通常会使有利可图的交易成为亏损。例如,预期价格上涨0.05美元的资产是买入,但如果你必须支付0.10美元进行此交易,你将最终获得净亏损$0.05。在你考虑经纪人佣金,交换费和点差后,我们上面看起来很棒的盈利图实际上是这样的:
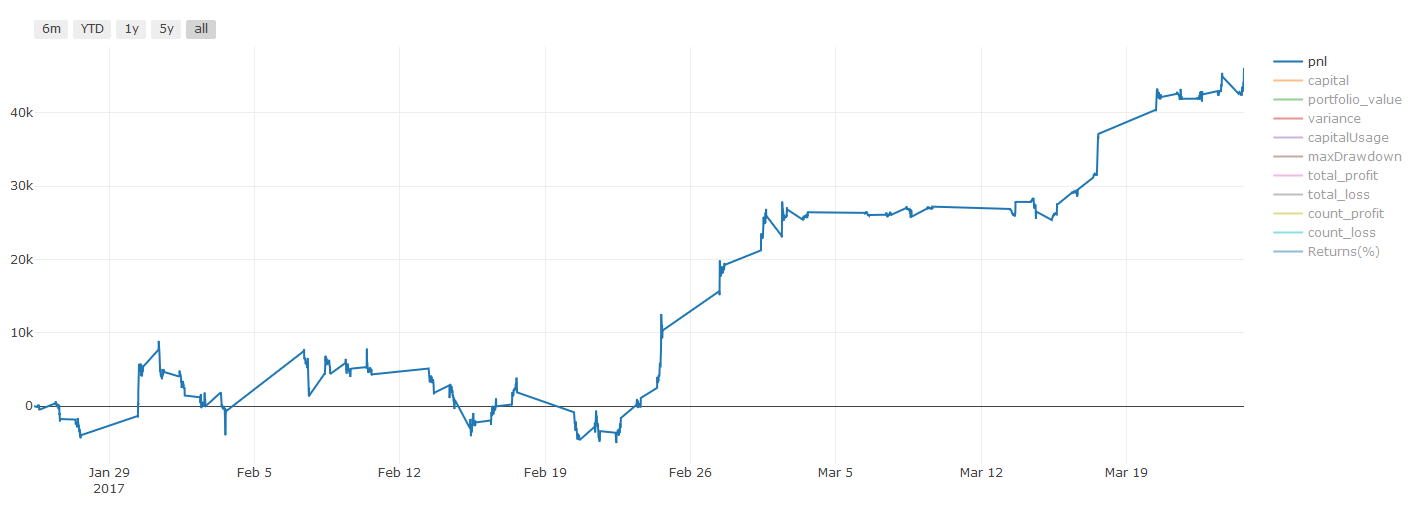
Pnl dalam dolar Amerika Syarikat
Bayaran transaksi dan perbezaannya adalah lebih daripada 90% daripada PNL kami! Kami akan membincangkannya secara terperinci dalam artikel seterusnya.
Akhirnya, mari kita lihat beberapa perangkap biasa.
Apa yang boleh dan tidak boleh dilakukan
Cubalah untuk mengelakkan kesesuaian yang berlebihan!
Jangan melatih semula selepas setiap titik data: Ini adalah kesilapan yang biasa dilakukan oleh orang dalam pembangunan pembelajaran mesin. Jika model anda perlu melatih semula selepas setiap titik data, maka ia mungkin bukan model yang sangat baik. Maksudnya, ia perlu melatih semula secara berkala, hanya dengan kekerapan yang munasabah (misalnya, jika anda membuat ramalan pada siang hari, melatih semula pada akhir minggu)
Mengelakkan penyimpangan, terutamanya penyimpangan prospektif: Ini adalah sebab lain untuk model tidak berfungsi, pastikan anda tidak menggunakan apa-apa maklumat masa depan. Dalam kebanyakan kes, ini bermaksud tidak menggunakan pembolehubah sasaran Y sebagai ciri dalam model. Anda boleh menggunakannya semasa ujian mundur, tetapi tidak akan dapat digunakan semasa menjalankan model sebenarnya, yang akan membuat model anda tidak dapat digunakan.
Berhati-hati dengan penyimpangan penggalian data: Oleh kerana kami sedang mencuba untuk melakukan satu siri pemodelan pada data kami untuk menentukan kesesuaian, jika tidak ada sebab khusus, pastikan anda menjalankan ujian yang ketat untuk memisahkan pola rawak dari pola sebenar yang mungkin berlaku. Sebagai contoh, regresi linear menjelaskan dengan baik pola trend ke atas, yang mungkin menjadi sebahagian kecil daripada peredaran rawak yang lebih besar!
Mengelakkan pemasangan yang berlebihan
Ini sangat penting, dan saya rasa perlu untuk mengulangi.
Persaingan yang berlebihan adalah satu daripada perangkap yang paling berbahaya dalam strategi perdagangan.
Algoritma yang rumit mungkin sangat baik dalam analisis semula, tetapi gagal dengan data baru yang tidak dapat dilihat, algoritma ini tidak benar-benar mendedahkan apa-apa trend dalam data dan tidak mempunyai keupayaan yang benar untuk meramalkan; ia sangat sesuai dengan data yang dilihatnya.
Pastikan sistem anda semudah mungkin. Jika anda mendapati anda memerlukan banyak fungsi yang rumit untuk menterjemahkan data, anda mungkin terlalu sesuai.
Pisahkan data yang ada kepada data latihan dan ujian, dan sentiasa periksa prestasi data sampel yang sebenarnya sebelum menggunakan model untuk berdagang secara langsung.
- Amalan Kuantitatif Bursa DEX (2) -- Panduan Pengguna Hyperliquid
- DEX Exchange Quantitative Practice ((2) -- Panduan Penggunaan Hyperliquid
- Amalan Kuantitatif Bursa DEX (1) -- Panduan Pengguna dYdX v4
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (3)
- DEX Exchange Quantitative Practice ((1) -- panduan pengguna dYdX v4
- Pengenalan suite Lead-Lag dalam mata wang digital (3)
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (2)
- Pendahuluan mengenai Lead-Lag dalam mata wang digital (2)
- Perbincangan mengenai Penerimaan Isyarat Luaran Platform FMZ: Penyelesaian Lengkap untuk Menerima Isyarat dengan Perkhidmatan Http Terbina dalam Strategi
- Penyelidikan penerimaan isyarat luaran platform FMZ: strategi penyelesaian lengkap untuk penerimaan isyarat perkhidmatan HTTP terbina dalam
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (1)
- Tangan tangan mengajar anda bagaimana untuk memberikan satu strategi lama yang seamlessly menghubungkan websocket pasar antara muka
- Strategi mengambil keuntungan peratusan pelbagai peringkat
- Perbezaan antara API niaga hadapan komoditi dan pertukaran mata wang digital
- Penggunaan bahagian bayangan K-line dalam strategi perdagangan
- Konfigurasi pertukaran strategi perdagangan kuantitatif cryptocurrency
- Mekanisme pencocokan urus niaga tahap Tick yang dibangunkan untuk pengujian strategi frekuensi tinggi
- Pengalaman pembangunan strategi dagangan
- Pemprosesan data baris K dalam perdagangan kuantitatif
- Strategi perdagangan kuantitatif mata wang digital
- "Versi C ++ strategi lindung nilai kontrak niaga hadapan OKEX" yang membawa anda melalui strategi kuantitatif hardcore
- Membawa anda belajar strategi hardcore "C++ OKEX Strategi Hedging Kontrak"
- Strategi hak-hak yang seimbang dengan pelbagai ruang yang disusun dengan teratur
- Perdagangan berpasangan berdasarkan teknologi yang didorong data
- Pengkajian kuantitatif pasaran mata wang digital
- Melaksanakan strategi transaksi kuantitatif mata wang digital Dual Thrust dengan Python
- Pengolahan data K-Line dalam transaksi berprogram
- Strategi perdagangan kuantitatif untuk menganalisis dinamika harga menggunakan Python
- Analisis data urutan masa dan pengulangan data Tick
- Rancangan Perdagangan
- Pengiraan dan penggunaan penunjuk DMI
BerjayaTerima kasih sayang.
congcong009Artikel, idea dan ringkasan yang hebat untuk pemula.
lalalademaxiyaBerani!